

Bibliometric Analysis of Automated Assessment in Programming Education: A Deeper Insight into Feedback

Abstract
:1. Introduction
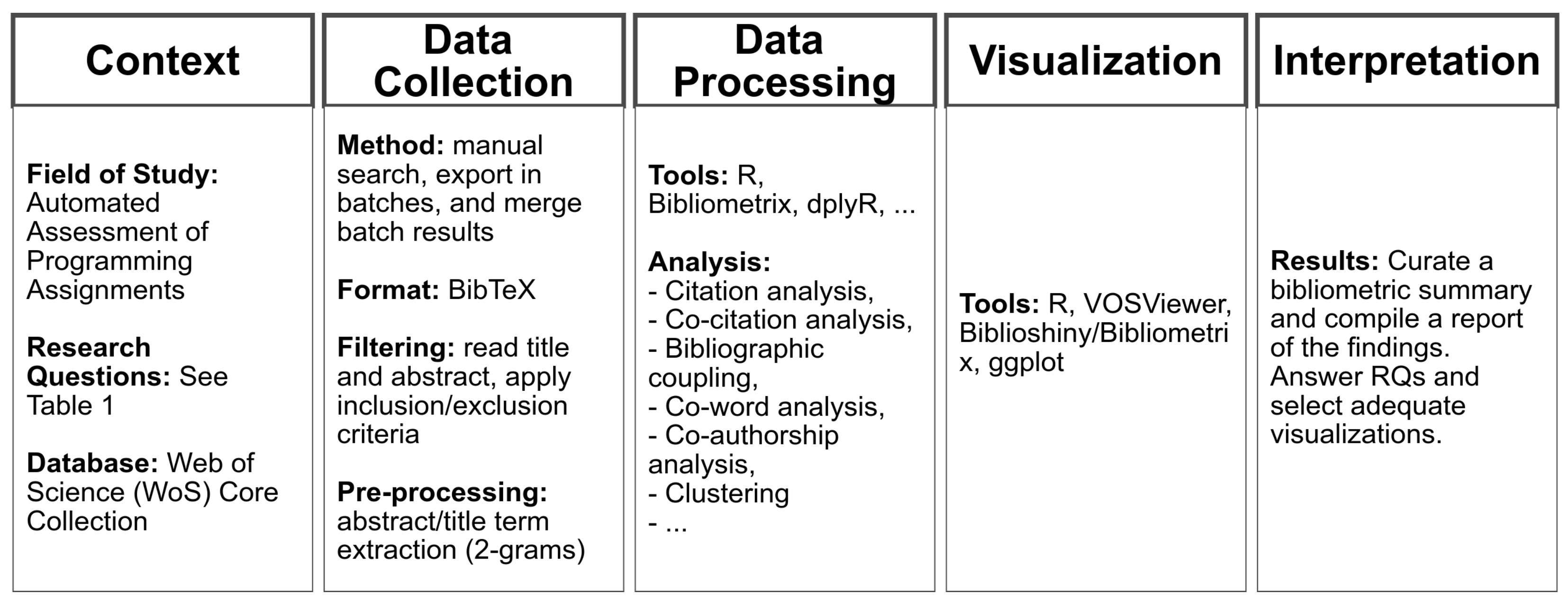
2. Methodology
3. Results
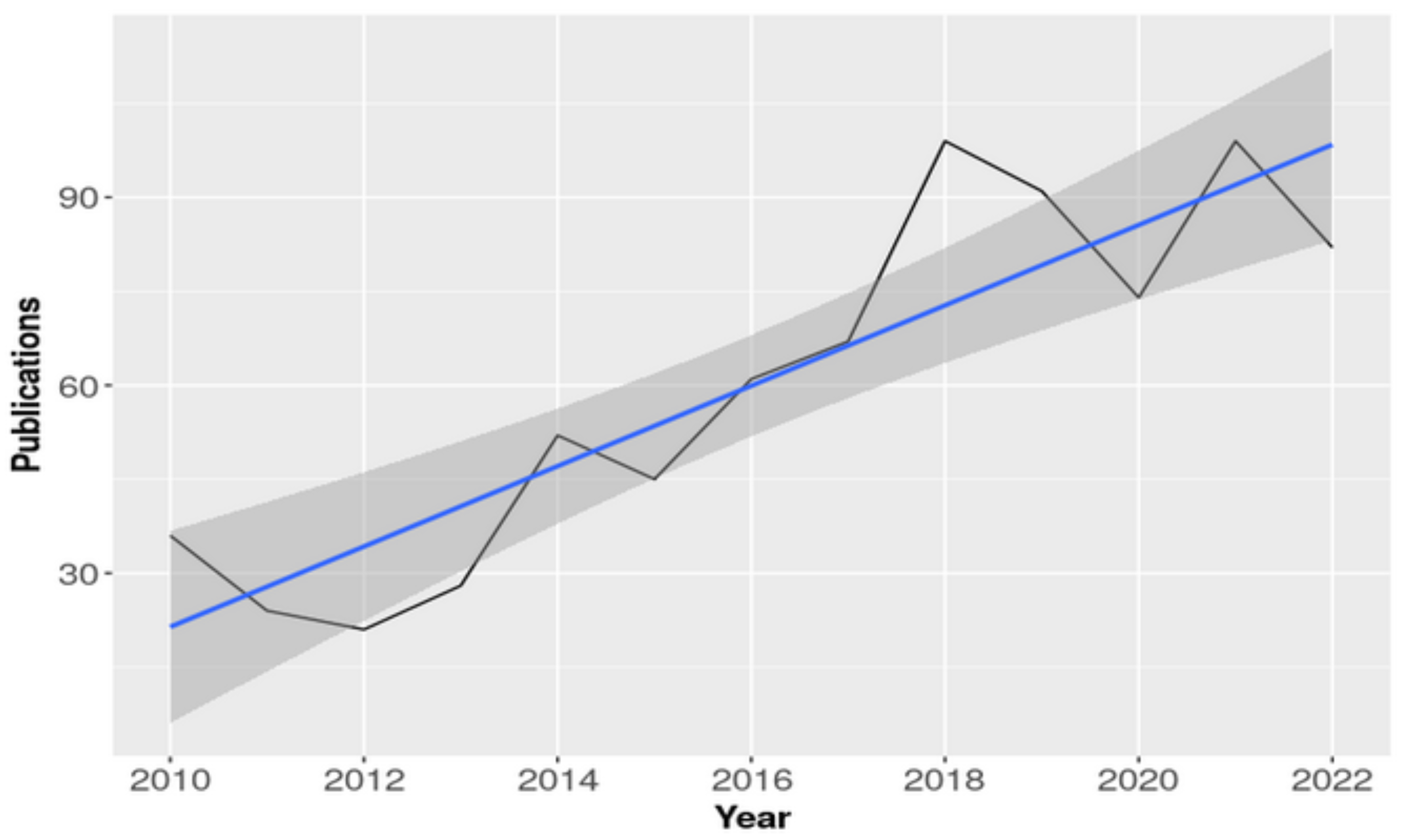
3.1. Data Summary
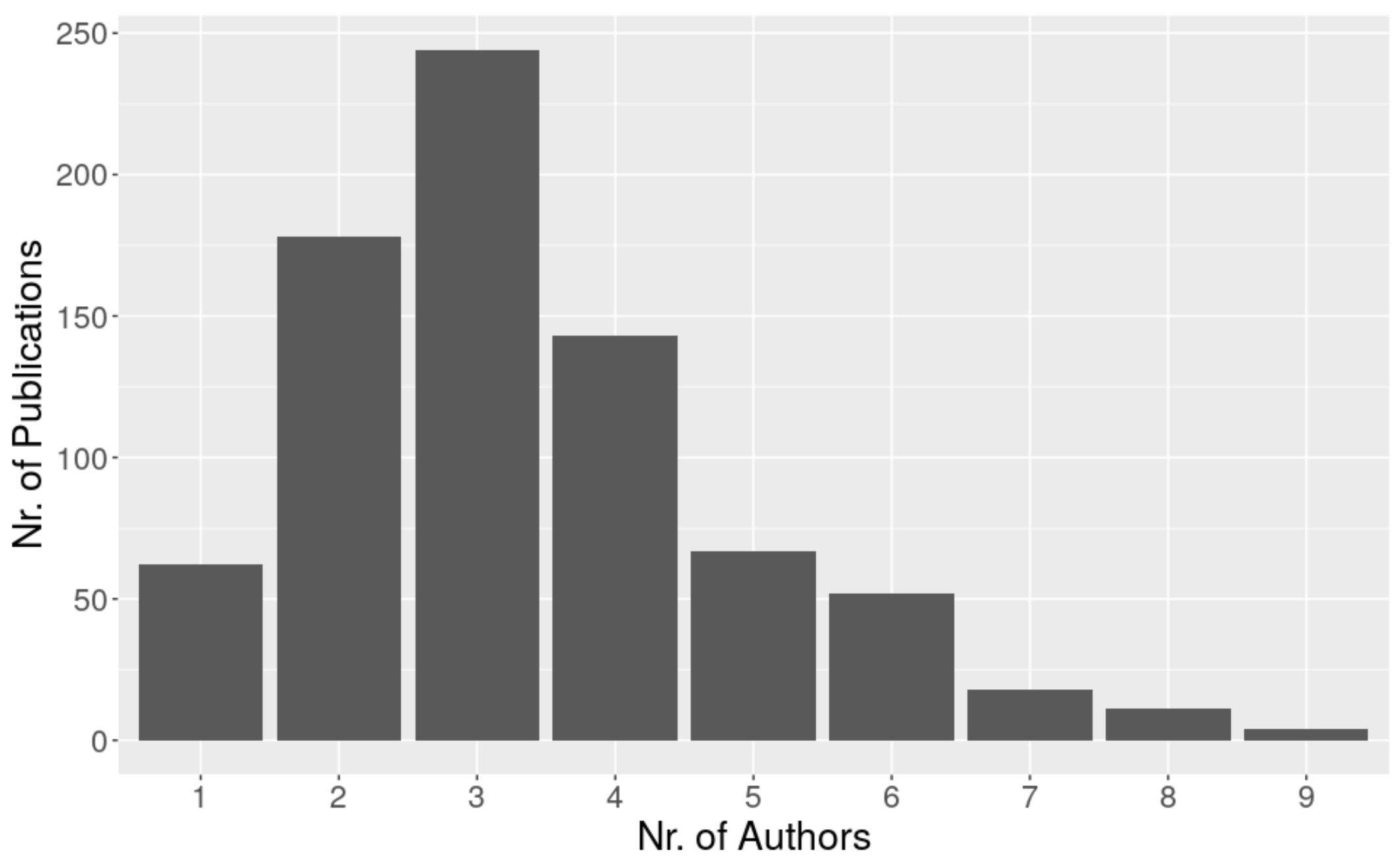
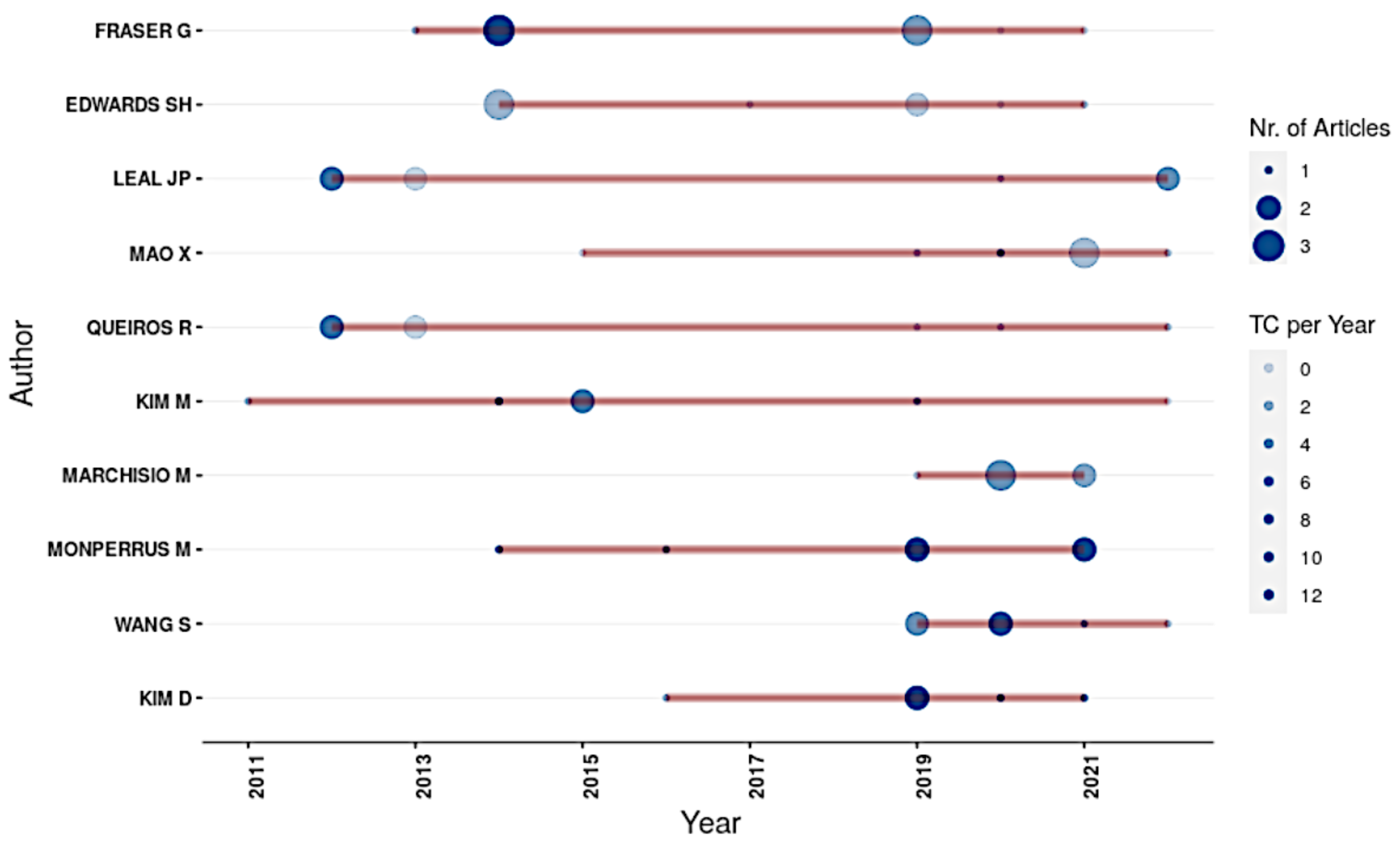
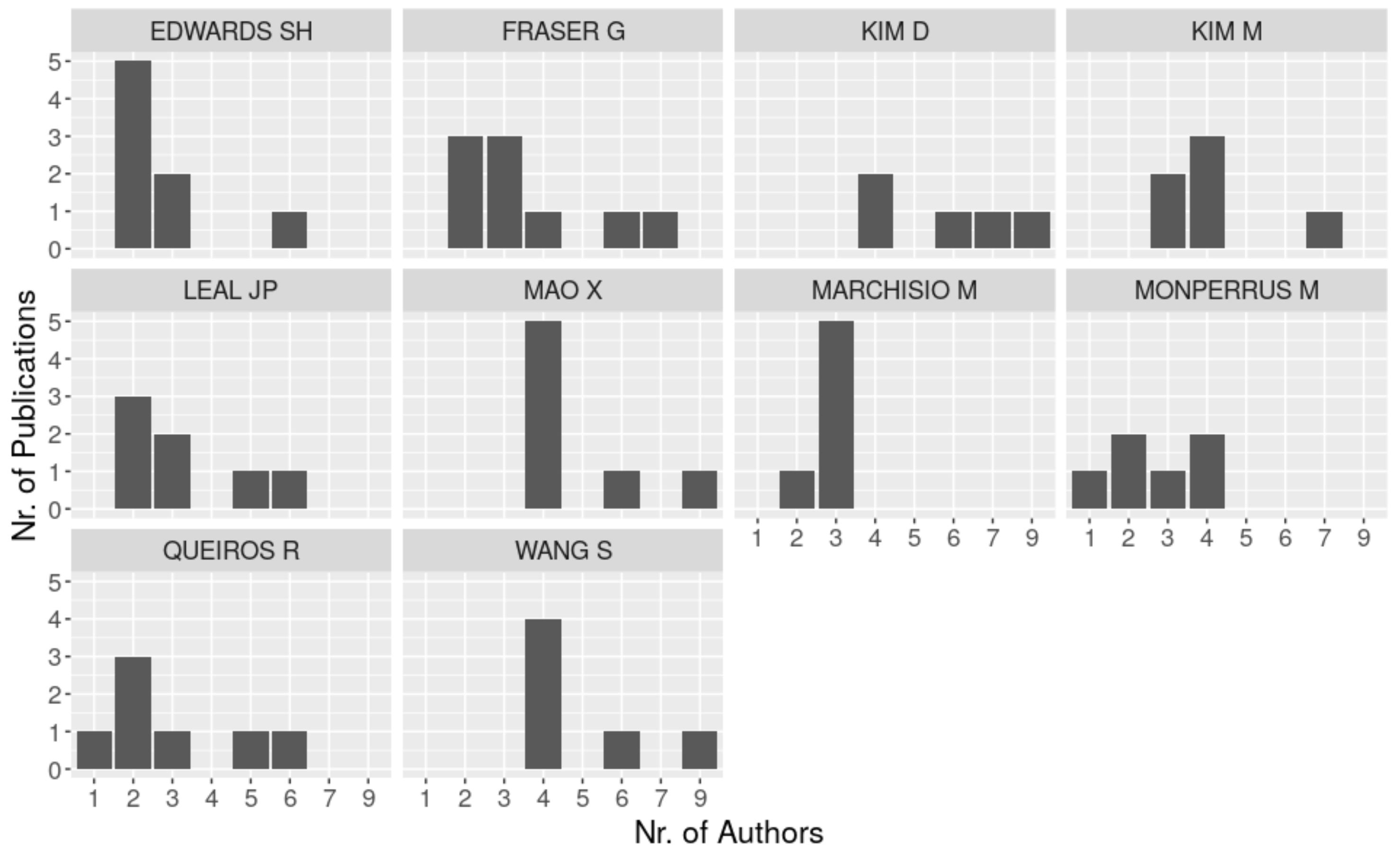
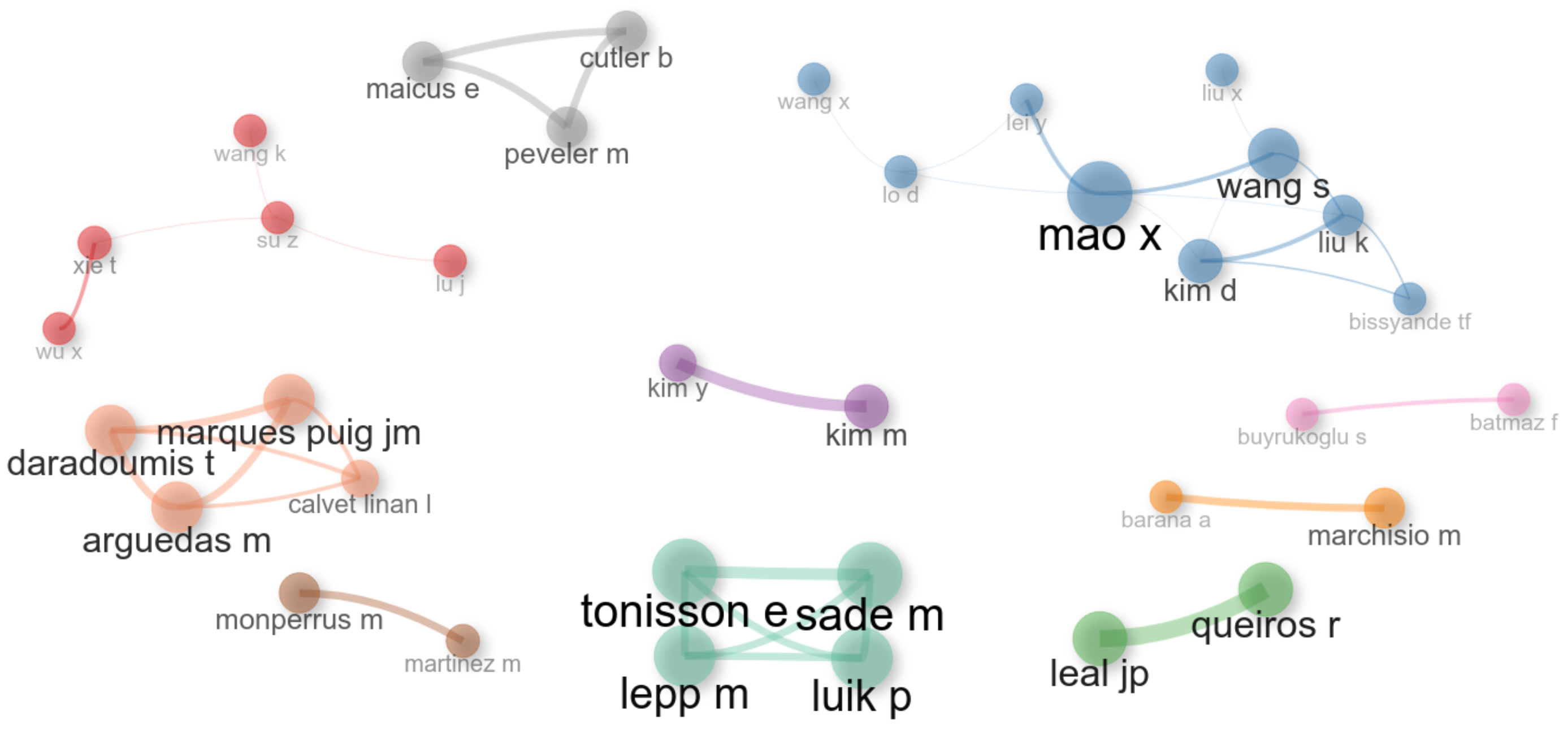
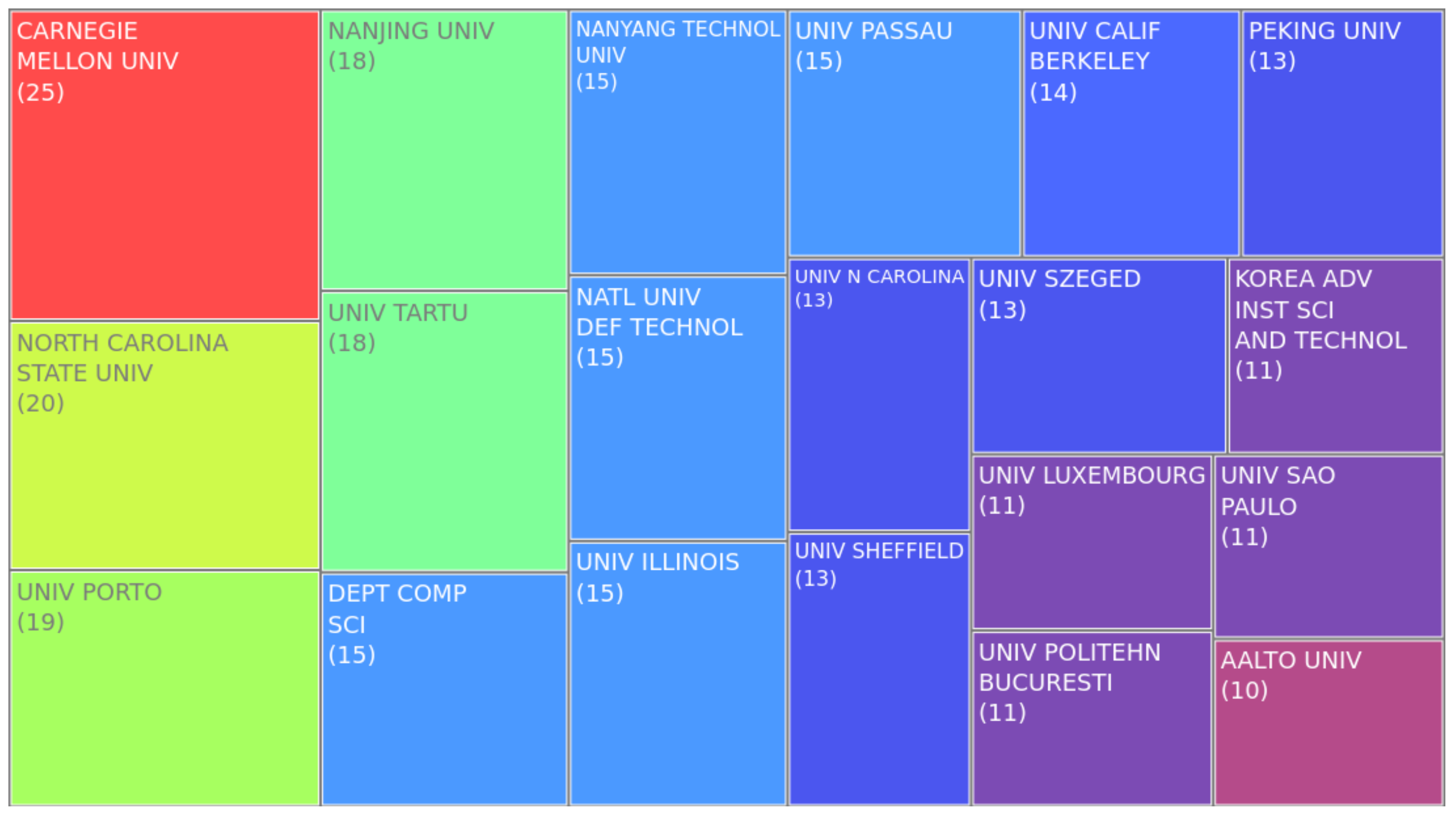
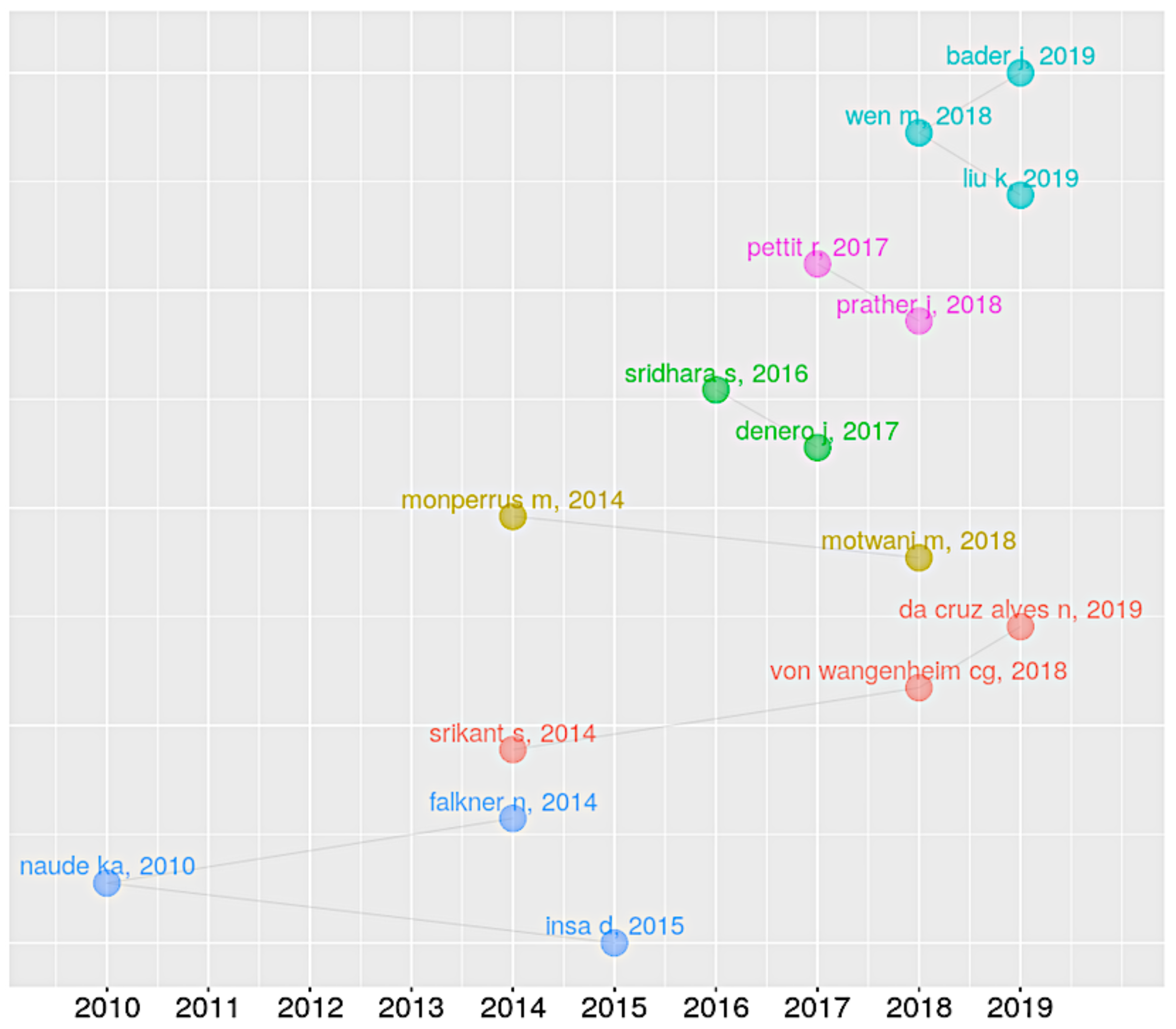
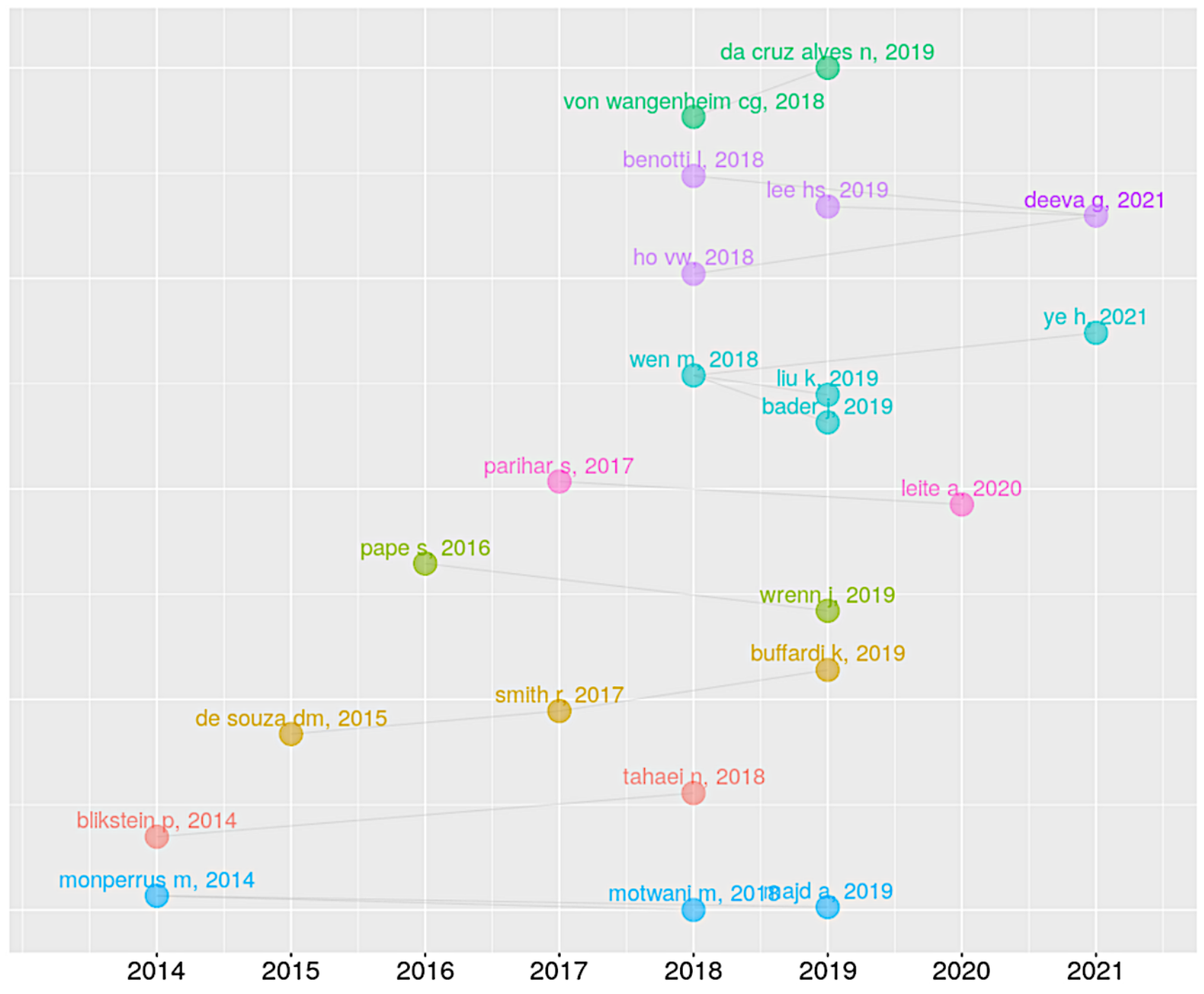
3.2. Authors
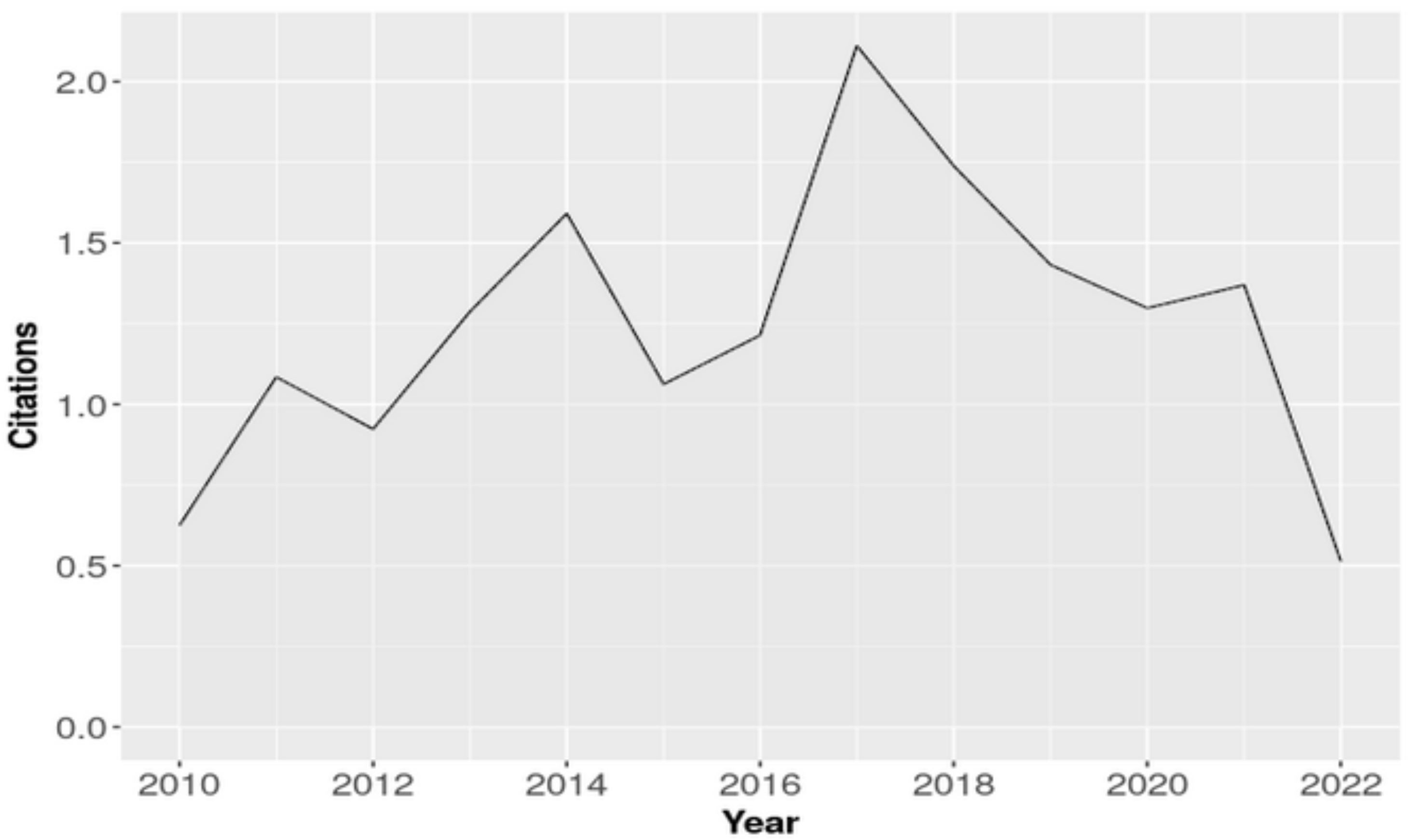
3.3. Citations
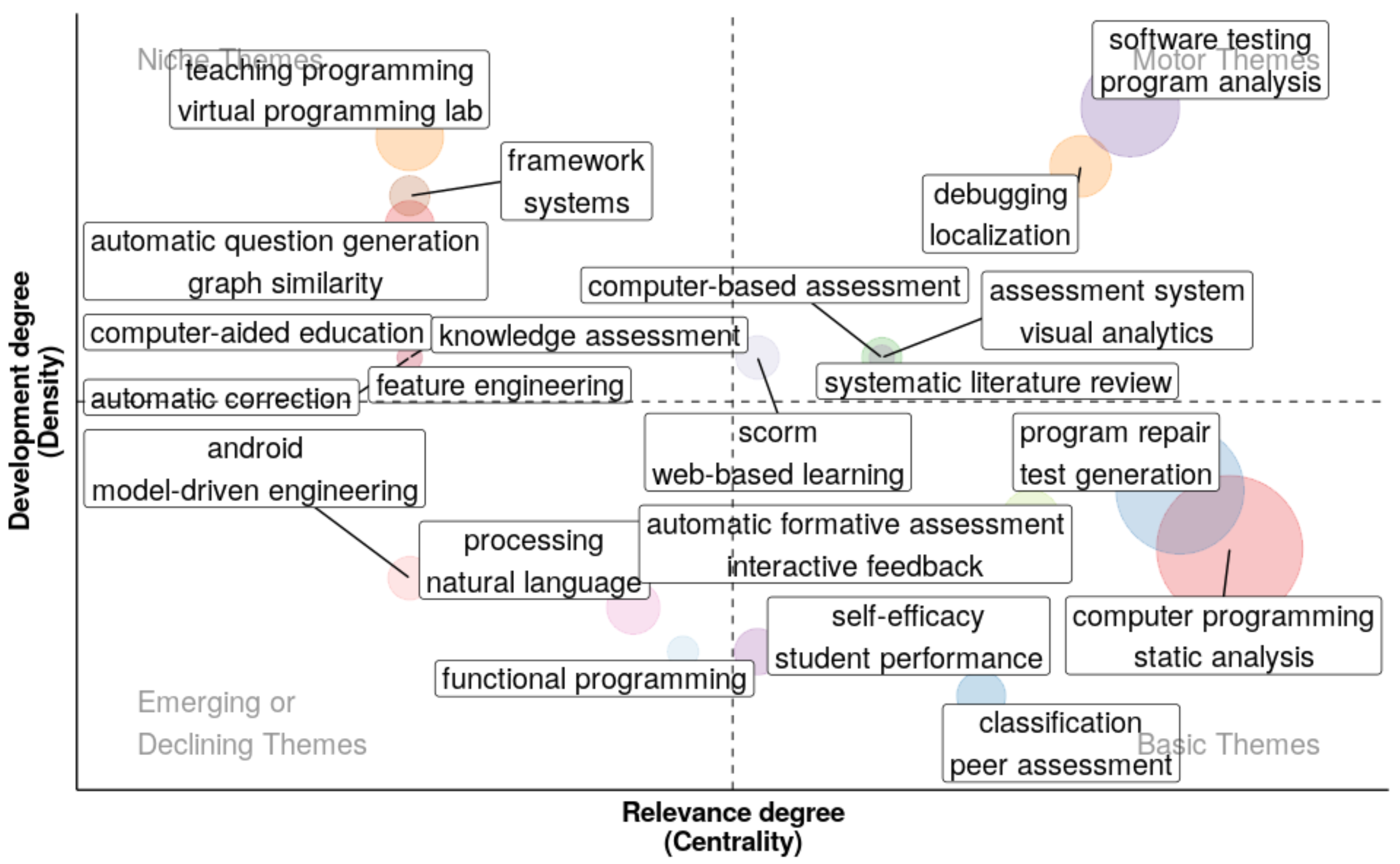
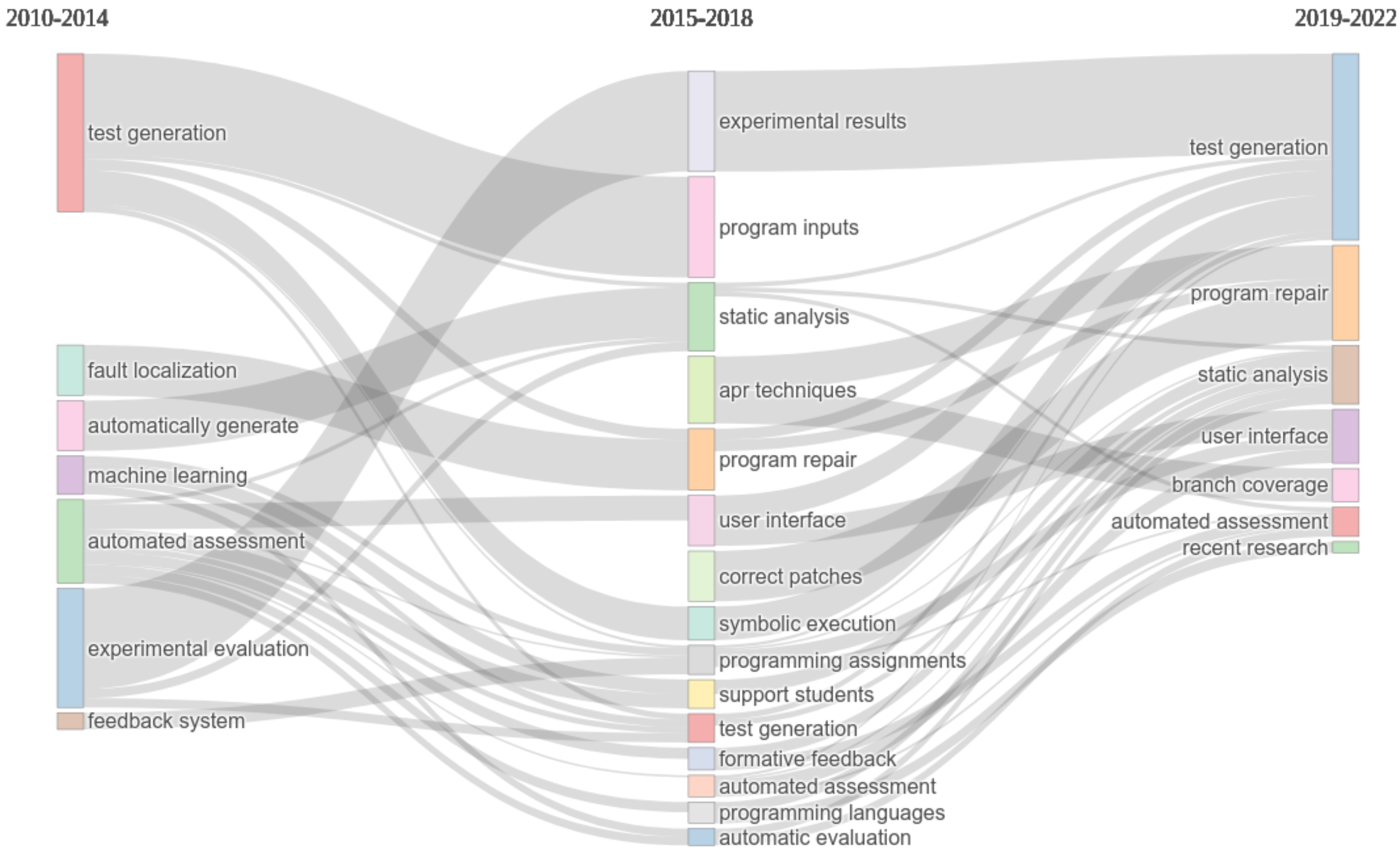
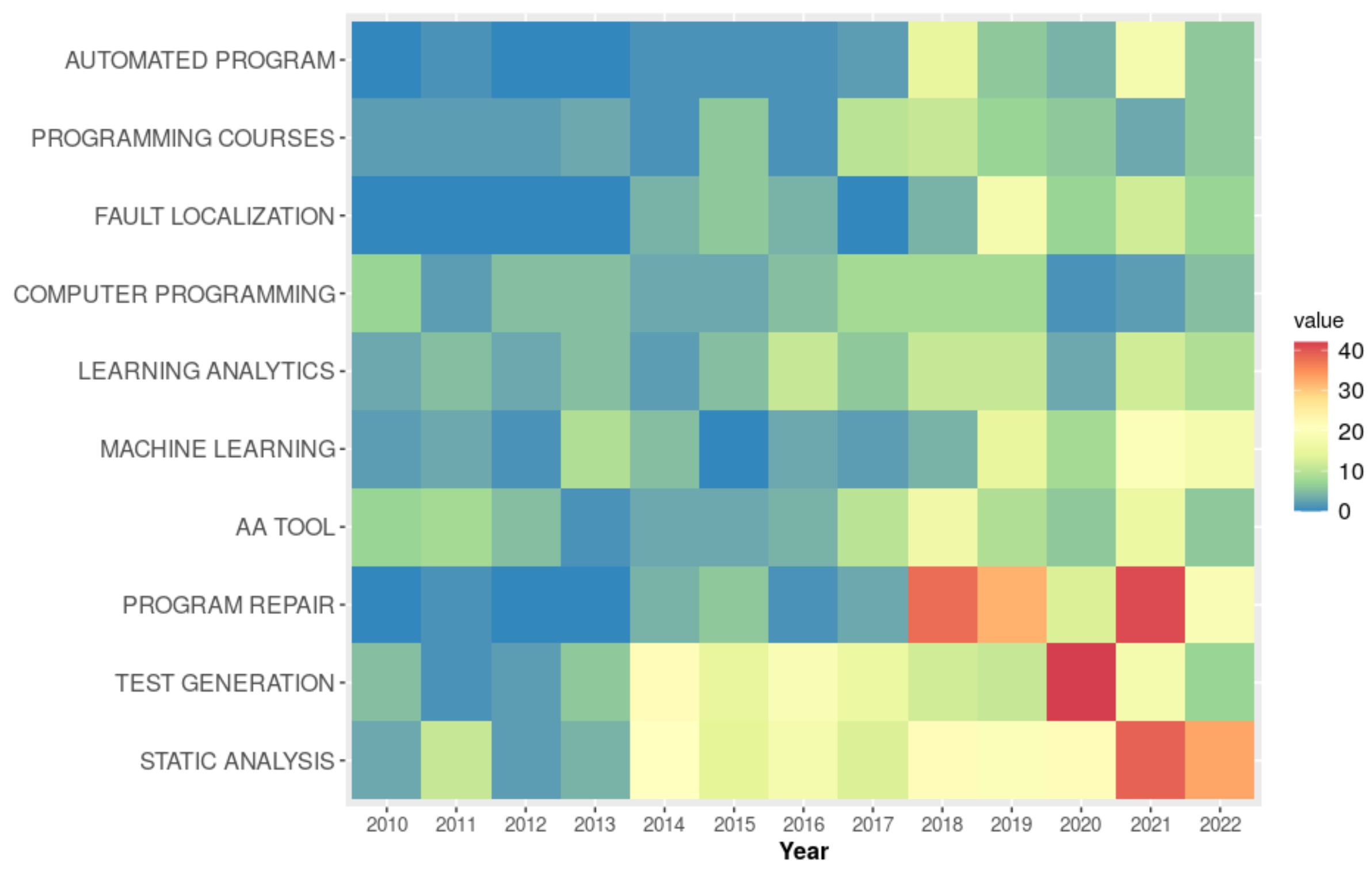
3.4. Topics and Keywords
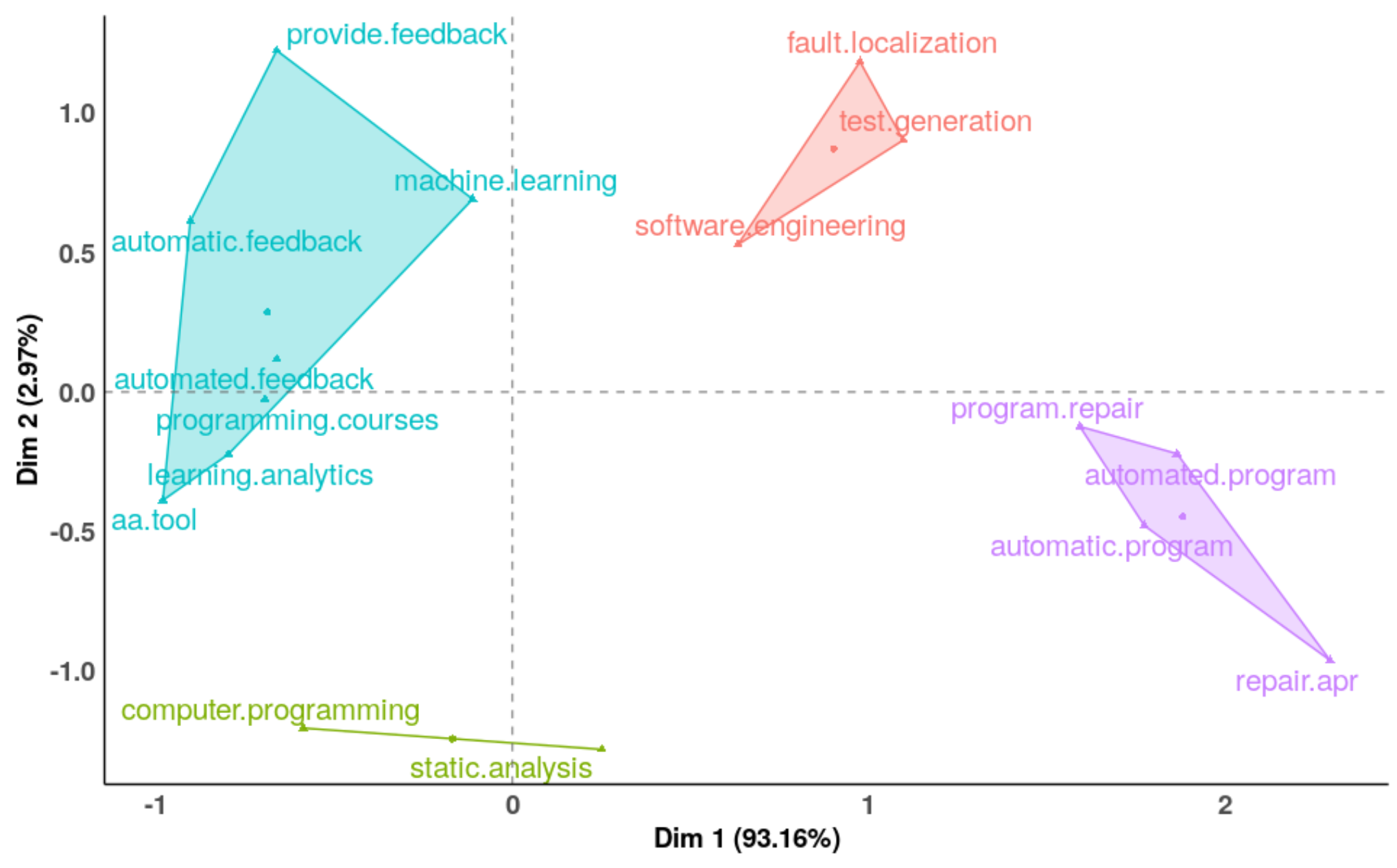
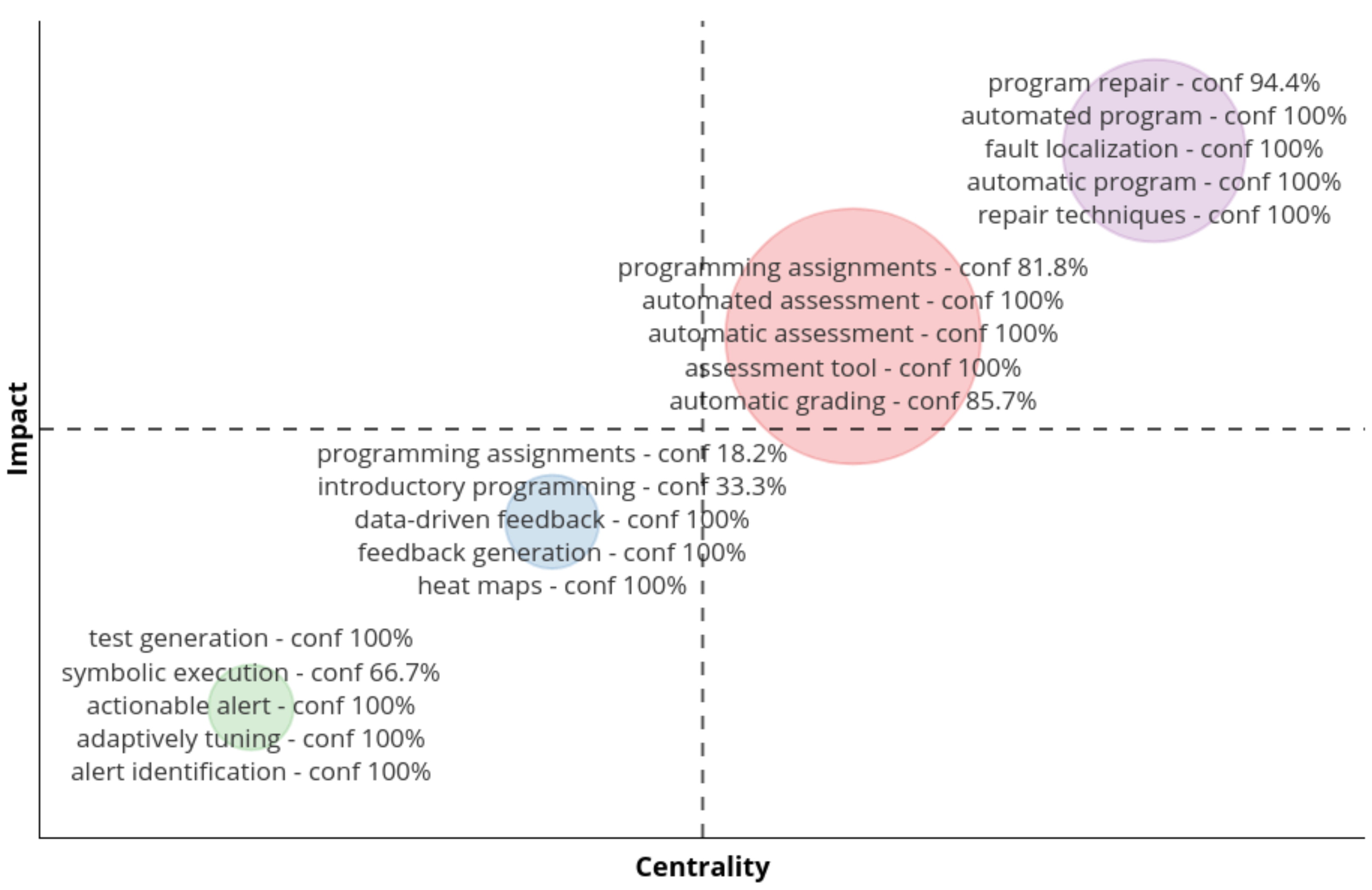
3.5. Feedback
4. Discussion
4.1. Authors
4.2. Citations
4.3. Topics
4.4. Feedback
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Robins, A.; Rountree, J.; Rountree, N. Learning and Teaching Programming: A Review and Discussion. Comput. Sci. Educ. 2003, 13, 137–172. [Google Scholar] [CrossRef]
- Mouza, C.; Codding, D.; Pollock, L. Investigating the impact of research-based professional development on teacher learning and classroom practice: Findings from computer science education. Comput. Educ. 2022, 186, 104530. [Google Scholar] [CrossRef]
- Saikkonen, R.; Malmi, L.; Korhonen, A. Fully Automatic Assessment of Programming Exercises. SIGCSE Bull. 2001, 33, 133–136. [Google Scholar] [CrossRef]
- Ala-Mutka, K.M. A Survey of Automated Assessment Approaches for Programming Assignments. Comput. Sci. Educ. 2005, 15, 83–102. [Google Scholar] [CrossRef]
- Paiva, J.C.; Leal, J.P.; Figueira, A. Automated Assessment in Computer Science Education: A State-of-the-Art Review. ACM Trans. Comput. Educ. 2022, 22, 34. [Google Scholar] [CrossRef]
- Ihantola, P.; Ahoniemi, T.; Karavirta, V.; Seppälä, O. Review of recent systems for automatic assessment of programming assignments. In Proceedings of the 10th Koli Calling International Conference on Computing Education Research—Koli Calling’10, Koli, Finland, 28–31 October 2010; ACM Press: Berlin, Germany, 2010; pp. 86–93. [Google Scholar] [CrossRef]
- Souza, D.M.; Felizardo, K.R.; Barbosa, E.F. A Systematic Literature Review of Assessment Tools for Programming Assignments. In Proceedings of the 2016 IEEE 29th International Conference on Software Engineering Education and Training (CSEET), Dallas, TX, USA, 5–6 April 2016; IEEE: Dallas, TX, USA, 2016; pp. 147–156. [Google Scholar] [CrossRef]
- Paiva, J.C.; Figueira, Á.; Leal, J.P. Automated Assessment in Computer Science: A Bibliometric Analysis of the Literature. In Proceedings of the Advances in Web-Based Learning—ICWL 2022, Tenerife, Spain, 21–23 November 2022; Springer International Publishing: Cham, Switzerland, 2022. [Google Scholar]
- Andrés, A. Measuring Academic Research; Chandos Publishing (Oxford): Witney, UK, 2009. [Google Scholar]
- Clarivate. Web of Science Core Collection. 2022. Available online: https://www.webofscience.com/wos/woscc/summary/f82ac75a-44c0-4873-a40d-c59e1e79ef4e-79ee7f28/relevance/1 (accessed on 19 March 2023).
- Aria, M.; Cuccurullo, C. bibliometrix: An R-tool for comprehensive science mapping analysis. J. Inf. 2017, 11, 959–975. [Google Scholar] [CrossRef]
- Wen, M.; Chen, J.; Wu, R.; Hao, D.; Cheung, S.C. Context-Aware Patch Generation for Better Automated Program Repair. In Proceedings of the 40th International Conference on Software Engineering, ICSE’18, Gothenburg, Sweden, 27 May–3 June 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 1–11. [Google Scholar] [CrossRef]
- Naudé, K.A.; Greyling, J.H.; Vogts, D. Marking student programs using graph similarity. Comput. Educ. 2010, 54, 545–561. [Google Scholar] [CrossRef]
- Verdú, E.; Regueras, L.M.; Verdú, M.J.; Leal, J.P.; de Castro, J.P.; Queirós, R. A distributed system for learning programming on-line. Comput. Educ. 2012, 58, 1–10. [Google Scholar] [CrossRef]
- Liu, K.; Koyuncu, A.; Kim, D.; Bissyandé, T.F. TBar: Revisiting Template-Based Automated Program Repair. In Proceedings of the 28th ACM SIGSOFT International Symposium on Software Testing and Analysis, ISSTA 2019, Beijing, China, 15–19 July 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 31–42. [Google Scholar] [CrossRef]
- Srikant, S.; Aggarwal, V. A System to Grade Computer Programming Skills Using Machine Learning. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD’14, New York, NY, USA, 24–27 August 2014; Association for Computing Machinery: New York, NY, USA, 2014; pp. 1887–1896. [Google Scholar] [CrossRef]
- Lemieux, C.; Padhye, R.; Sen, K.; Song, D. PerfFuzz: Automatically Generating Pathological Inputs. In Proceedings of the 27th ACM SIGSOFT International Symposium on Software Testing and Analysis, ISSTA 2018, Amsterdam, The Netherlands, 16–21 July 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 254–265. [Google Scholar] [CrossRef]
- Singh, R.; Gulwani, S.; Solar-Lezama, A. Automated Feedback Generation for Introductory Programming Assignments. In Proceedings of the 34th ACM SIGPLAN Conference on Programming Language Design and Implementation, PLDI’13, Seattle, WA, USA, 16–19 June 2013; Association for Computing Machinery: New York, NY, USA, 2013; pp. 15–26. [Google Scholar] [CrossRef]
- Xiong, Y.; Wang, J.; Yan, R.; Zhang, J.; Han, S.; Huang, G.; Zhang, L. Precise Condition Synthesis for Program Repair. In Proceedings of the 39th International Conference on Software Engineering, ICSE’17, Buenos Aires, Argentina, 20–28 May 2017; IEEE Press: Piscataway, NJ, USA, 2017; pp. 416–426. [Google Scholar] [CrossRef]
- Garfield, E. Historiographic Mapping of Knowledge Domains Literature. J. Inf. Sci. 2004, 30, 119–145. [Google Scholar] [CrossRef]
- Bader, J.; Scott, A.; Pradel, M.; Chandra, S. Getafix: Learning to Fix Bugs Automatically. Proc. ACM Program. Lang. 2019, 3, 159. [Google Scholar] [CrossRef]
- Pettit, R.S.; Homer, J.; Gee, R. Do Enhanced Compiler Error Messages Help Students? Results Inconclusive. In Proceedings of the 2017 ACM SIGCSE Technical Symposium on Computer Science Education, SIGCSE’17, Seattle, WA, USA, 8–11 March 2017; Association for Computing Machinery: New York, NY, USA, 2017; pp. 465–470. [Google Scholar] [CrossRef]
- Prather, J.; Pettit, R.; McMurry, K.; Peters, A.; Homer, J.; Cohen, M. Metacognitive Difficulties Faced by Novice Programmers in Automated Assessment Tools. In Proceedings of the 2018 ACM Conference on International Computing Education Research, ICER’18, Espoo, Finland, 13–15 August 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 41–50. [Google Scholar] [CrossRef]
- DeNero, J.; Sridhara, S.; Pérez-Quiñones, M.; Nayak, A.; Leong, B. Beyond Autograding: Advances in Student Feedback Platforms. In Proceedings of the 2017 ACM SIGCSE Technical Symposium on Computer Science Education, SIGCSE’17, Seattle WA, USA, 8–11 March 2017; Association for Computing Machinery: New York, NY, USA, 2017; pp. 651–652. [Google Scholar] [CrossRef]
- Sridhara, S.; Hou, B.; Lu, J.; DeNero, J. Fuzz Testing Projects in Massive Courses. In Proceedings of the Third (2016) ACM Conference on Learning @ Scale, L@S’16, Edinburgh, UK, 25–26 April 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 361–367. [Google Scholar] [CrossRef]
- Monperrus, M. A Critical Review of “Automatic Patch Generation Learned from Human-Written Patches”: Essay on the Problem Statement and the Evaluation of Automatic Software Repair. In Proceedings of the 36th International Conference on Software Engineering, ICSE 2014, Hyderabad, India, 31 May–7 June 2014; Association for Computing Machinery: New York, NY, USA, 2014; pp. 234–242. [Google Scholar] [CrossRef]
- Motwani, M.; Sankaranarayanan, S.; Just, R.; Brun, Y. Do Automated Program Repair Techniques Repair Hard and Important Bugs? Empirical Softw. Engg. 2018, 23, 2901–2947. [Google Scholar] [CrossRef]
- von Wangenheim, C.G.; Hauck, J.C.R.; Demetrio, M.F.; Pelle, R.; da Cruz Alves, N.; Barbosa, H.; Azevedo, L.F. CodeMaster—Automatic Assessment and Grading of App Inventor and Snap! Programs. Inform. Educ. 2018, 17, 117–150. [Google Scholar] [CrossRef]
- da Cruz Alves, N.; Wangenheim, C.G.V.; Hauck, J.C.R. Approaches to Assess Computational Thinking Competences Based on Code Analysis in K-12 Education: A Systematic Mapping Study. Inform. Educ. 2019, 18, 17–39. [Google Scholar] [CrossRef]
- Falkner, N.; Vivian, R.; Piper, D.; Falkner, K. Increasing the Effectiveness of Automated Assessment by Increasing Marking Granularity and Feedback Units. In Proceedings of the 45th ACM Technical Symposium on Computer Science Education, SIGCSE’14, Atlanta, GA, USA, 5–8 March 2014; Association for Computing Machinery: New York, NY, USA, 2014; pp. 9–14. [Google Scholar] [CrossRef]
- Insa, D.; Silva, J. Semi-Automatic Assessment of Unrestrained Java Code: A Library, a DSL, and a Workbench to Assess Exams and Exercises. In Proceedings of the 2015 ACM Conference on Innovation and Technology in Computer Science Education, ITiCSE’15, Vilnius, Lithuania, 4–8 July 2015; Association for Computing Machinery: New York, NY, USA, 2015; pp. 39–44. [Google Scholar] [CrossRef]
- Cobo, M.; López-Herrera, A.; Herrera-Viedma, E.; Herrera, F. An approach for detecting, quantifying, and visualizing the evolution of a research field: A practical application to the Fuzzy Sets Theory field. J. Inf. 2011, 5, 146–166. [Google Scholar] [CrossRef]
- Deeva, G.; Bogdanova, D.; Serral, E.; Snoeck, M.; De Weerdt, J. A review of automated feedback systems for learners: Classification framework, challenges and opportunities. Comput. Educ. 2021, 162, 104094. [Google Scholar] [CrossRef]
- Benotti, L.; Aloi, F.; Bulgarelli, F.; Gomez, M.J. The Effect of a Web-Based Coding Tool with Automatic Feedback on Students’ Performance and Perceptions. In Proceedings of the 49th ACM Technical Symposium on Computer Science Education, SIGCSE’18, Baltimore, MA, USA, 21–24 February 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 2–7. [Google Scholar] [CrossRef]
- Ho, V.W.; Harris, P.G.; Kumar, R.K.; Velan, G.M. Knowledge maps: A tool for online assessment with automated feedback. Med. Educ. Online 2018, 23, 1457394. [Google Scholar] [CrossRef]
- Lee, H.S.; Pallant, A.; Pryputniewicz, S.; Lord, T.; Mulholland, M.; Liu, O.L. Automated text scoring and real-time adjustable feedback: Supporting revision of scientific arguments involving uncertainty. Sci. Educ. 2019, 103, 590–622. [Google Scholar] [CrossRef]
- Ye, H.; Martinez, M.; Monperrus, M. Automated patch assessment for program repair at scale. Empir. Softw. Eng. 2021, 26, 20. [Google Scholar] [CrossRef]
- Parihar, S.; Dadachanji, Z.; Singh, P.K.; Das, R.; Karkare, A.; Bhattacharya, A. Automatic Grading and Feedback Using Program Repair for Introductory Programming Courses. In Proceedings of the 2017 ACM Conference on Innovation and Technology in Computer Science Education, ITiCSE’17, Bologna, Italy, 3–5 July 2017; Association for Computing Machinery: New York, NY, USA, 2017; pp. 92–97. [Google Scholar] [CrossRef]
- Leite, A.; Blanco, S.A. Effects of Human vs. Automatic Feedback on Students’ Understanding of AI Concepts and Programming Style. In Proceedings of the 51st ACM Technical Symposium on Computer Science Education, SIGCSE’20, Portland, OR, USA, 11–14 March 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 44–50. [Google Scholar] [CrossRef]
- Pape, S.; Flake, J.; Beckmann, A.; Jürjens, J. STAGE: A Software Tool for Automatic Grading of Testing Exercises: Case Study Paper. In Proceedings of the 38th International Conference on Software Engineering Companion, ICSE’16, Austin, TX, USA, 14–22 May 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 491–500. [Google Scholar] [CrossRef]
- Wrenn, J.; Krishnamurthi, S. Executable Examples for Programming Problem Comprehension. In Proceedings of the 2019 ACM Conference on International Computing Education Research, ICER’19, Toronto, ON, Canada, 12–14 August 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 131–139. [Google Scholar] [CrossRef]
- Souza, D.M.D.; Isotani, S.; Barbosa, E.F. Teaching novice programmers using ProgTest. Int. J. Knowl. Learn. 2015, 10, 60–77. [Google Scholar] [CrossRef]
- Smith, R.; Tang, T.; Warren, J.; Rixner, S. An Automated System for Interactively Learning Software Testing. In Proceedings of the 2017 ACM Conference on Innovation and Technology in Computer Science Education, ITiCSE’17, Bologna, Italy, 3–5 July 2017; Association for Computing Machinery: New York, NY, USA, 2017; pp. 98–103. [Google Scholar] [CrossRef]
- Buffardi, K.; Valdivia, P.; Rogers, D. Measuring Unit Test Accuracy. In Proceedings of the 50th ACM Technical Symposium on Computer Science Education, SIGCSE’19, Minneapolis, MN, USA, 27 February–2 March 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 578–584. [Google Scholar] [CrossRef]
- Blikstein, P.; Worsley, M.; Piech, C.; Sahami, M.; Cooper, S.; Koller, D. Programming Pluralism: Using Learning Analytics to Detect Patterns in the Learning of Computer Programming. J. Learn. Sci. 2014, 23, 561–599. [Google Scholar] [CrossRef]
- Tahaei, N.; Noelle, D.C. Automated Plagiarism Detection for Computer Programming Exercises Based on Patterns of Resubmission. In Proceedings of the 2018 ACM Conference on International Computing Education Research, ICER’18, Espoo, Finland, 13–15 August 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 178–186. [Google Scholar] [CrossRef]
- Majd, A.; Vahidi-Asl, M.; Khalilian, A.; Baraani-Dastjerdi, A.; Zamani, B. Code4Bench: A multidimensional benchmark of Codeforces data for different program analysis techniques. J. Comput. Lang. 2019, 53, 38–52. [Google Scholar] [CrossRef]
- Yi, J.; Tan, S.H.; Mechtaev, S.; Böhme, M.; Roychoudhury, A. A Correlation Study between Automated Program Repair and Test-Suite Metrics. Empirical Softw. Engg. 2018, 23, 2948–2979. [Google Scholar] [CrossRef]
- Adler, F.; Fraser, G.; Grundinger, E.; Korber, N.; Labrenz, S.; Lerchenberger, J.; Lukasczyk, S.; Schweikl, S. Improving Readability of Scratch Programs with Search-based Refactoring. In Proceedings of the 2021 IEEE 21st International Working Conference on Source Code Analysis and Manipulation (SCAM), Luxembourg, 27–28 September 2021; IEEE Computer Society: Los Alamitos, CA, USA, 2021; pp. 120–130. [Google Scholar] [CrossRef]
- Porfirio, A.; Pereira, R.; Maschio, E. Automatic Source Code Evaluation: A Systematic Mapping; Technical report; Federal University of Technology (UTFPR): Paraná, Brazil, 2021. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Group | No. | Question |
|---|---|---|
| RQ1 | 1 | What is the annual scientific production? |
| 2 | What is the average time interval for a new publication to obtain the first citation? | |
| 3 | Which are the main journals/conferences for finding literature in the area? | |
| RQ2 | 1 | What is the common team size per publication? |
| 2 | Which are the most productive, active, and impactful authors? | |
| 3 | Do those authors publish alone or in a group? | |
| 4 | Which are the most evident author collaboration partnerships? | |
| 5 | What are the authors’ main affiliations? | |
| RQ3 | 1 | Which are the most influential citations? |
| 2 | Which are the most relevant co-citations? | |
| RQ4 | 1 | Which are the basic, niche, motor, and emerging topics? |
| 2 | How did topics evolve during the analyzed time span? | |
| 3 | Which are the frequent terms being used? | |
| 4 | What is the yearly frequency of the most frequent terms? | |
| RQ5 | 1 | Which are the active sub-topics within feedback? |
| 2 | Which are the active research lines within feedback? |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Paiva, J.C.; Figueira, Á.; Leal, J.P. Bibliometric Analysis of Automated Assessment in Programming Education: A Deeper Insight into Feedback. Electronics 2023, 12, 2254. https://doi.org/10.3390/electronics12102254
Paiva JC, Figueira Á, Leal JP. Bibliometric Analysis of Automated Assessment in Programming Education: A Deeper Insight into Feedback. Electronics. 2023; 12(10):2254. https://doi.org/10.3390/electronics12102254
Chicago/Turabian StylePaiva, José Carlos, Álvaro Figueira, and José Paulo Leal. 2023. "Bibliometric Analysis of Automated Assessment in Programming Education: A Deeper Insight into Feedback" Electronics 12, no. 10: 2254. https://doi.org/10.3390/electronics12102254