
An Extreme Value Analysis-Based Systemic Approach in Healthcare Information Systems: The Case of Dietary Intake

Abstract
:1. Introduction
1.1. Nutritional Variables and Data Collection Strategies
1.2. Scope of the Study
2. Literature Review and Related Work
2.1. Nutritional Biomarkers and Bioinformatics
2.2. Epidemiology and Nutrition
2.3. Research Continuity
2.4. Theory and Application Highlights of Extreme Value Analysis
3. Key Issues and Challenges
3.1. Patient’s Journey
3.2. The Golden Circle of Innovation Adapted for Machine Learning
3.2.1. The What
3.2.2. The Why
3.2.3. The How
4. Methodology
4.1. Technical Overview
Dietary EVA Algorithm
4.2. EVA-Based Decision-Making Algorithm
4.3. Business Issue and Systemisation
5. Implementation
5.1. Overview
- Vitamin C for the overweight category.
- Alcohol for the obese category.
5.2. Descriptive Analytics
5.3. Results
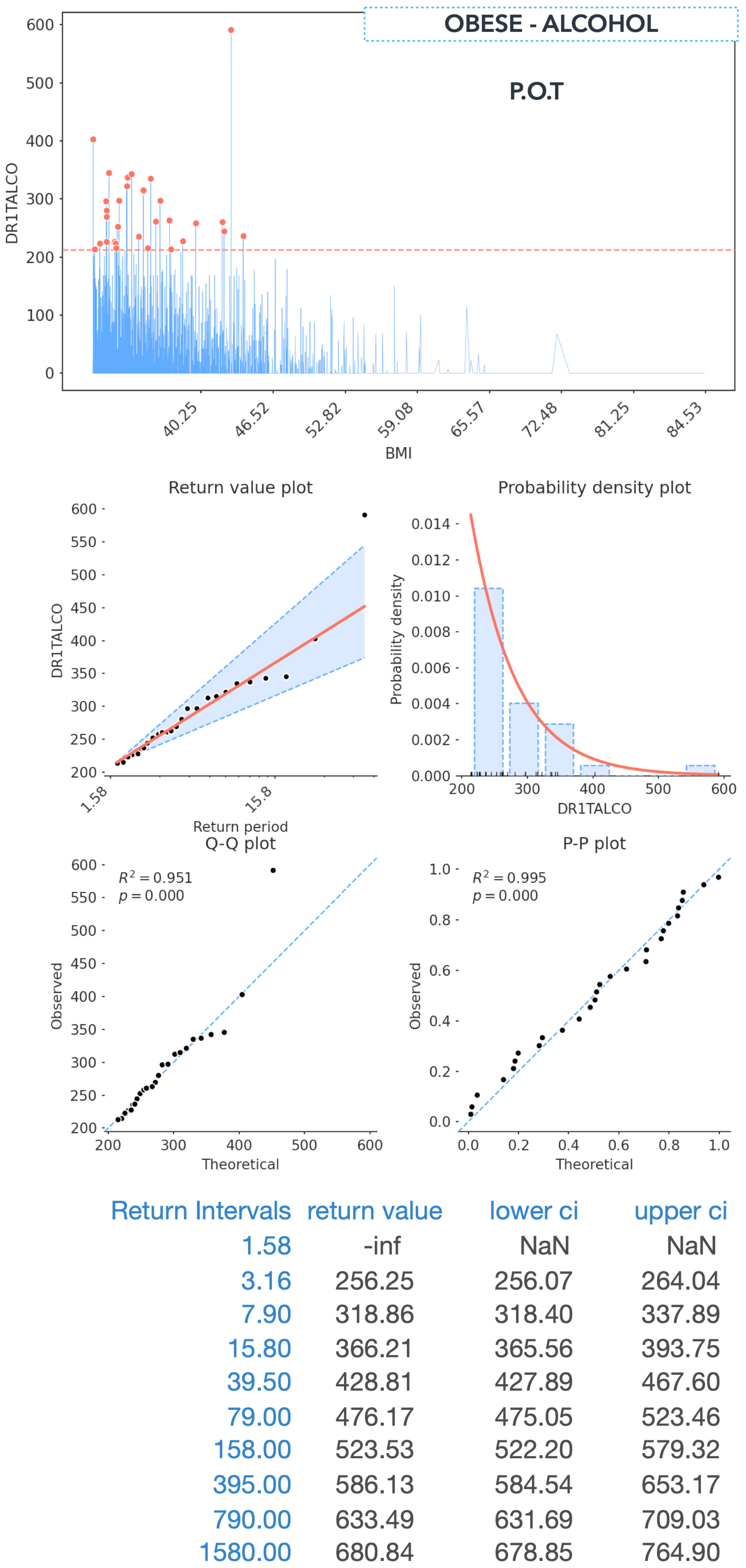
5.4. System Analysis and Pipeline Outputs
5.4.1. Vitamin C–Overweight Status
5.4.2. Alcohol–Obese Status
5.5. Proposed Report and Recommendation Prototype
- There is extreme consumption of the dietary variable (x), as per the EVA pipeline.When the dietary intake of (x) is greater than that of (n) for weight class (g), for a BMI increase by (s), dietary intake may increase by (s’) and vice versa.
- When consumption of dietary variable (x) decreases by (s”), BMI can decrease by (s”’).
- When dietary intake of (x) is extreme, the most affected blood variables are (Bn).
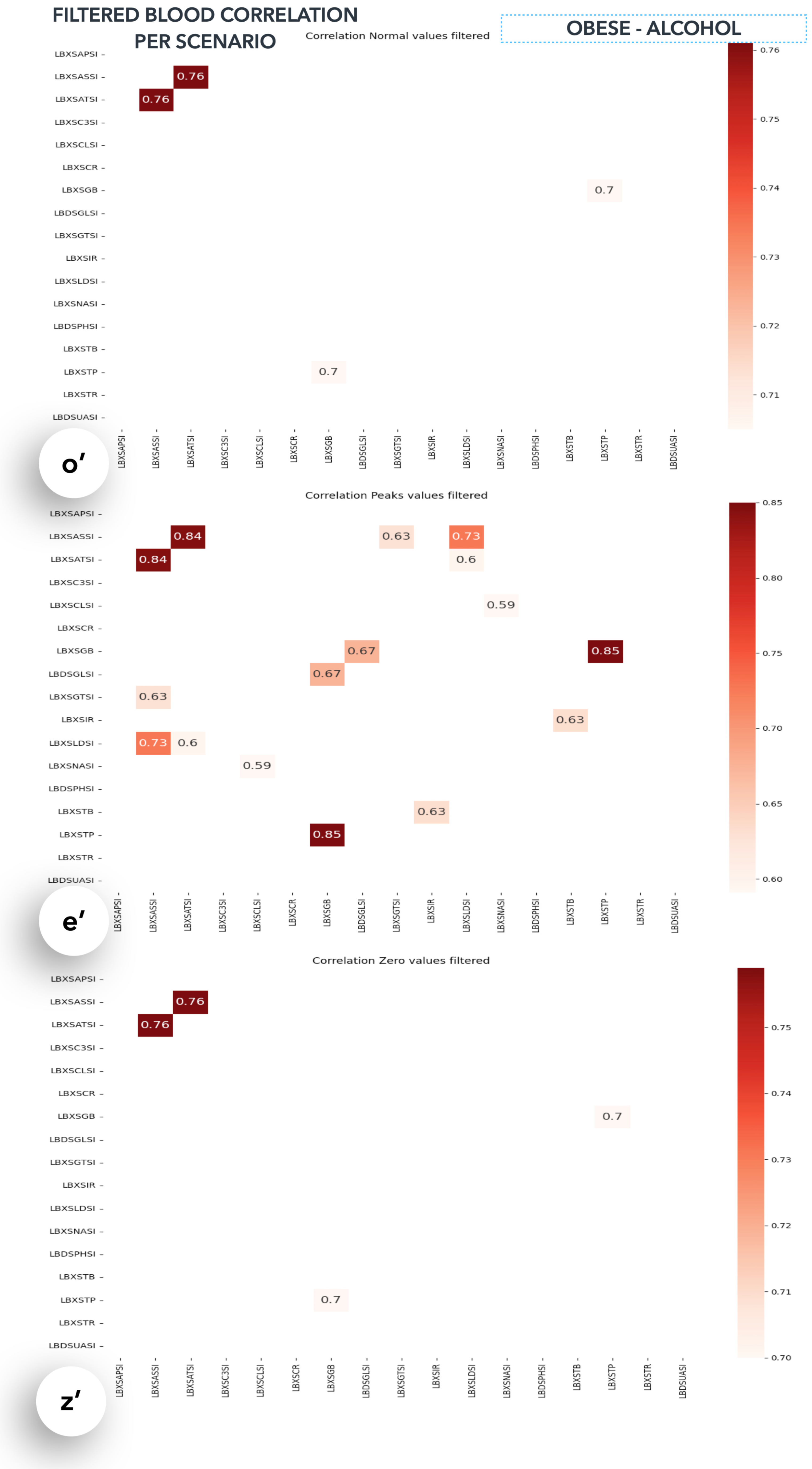
- When dietary intake (x) is extreme, there is a stronger correlation between blood variables B(n) and B(n’).
- The blood variables, B(n), are mostly associated with organs, O(n).
- There is generally a positive (negative) relation between blood variable B(n) and dietary variable (x); the more prominent relations are dietary variable (x) and blood exam B-filtered(n).
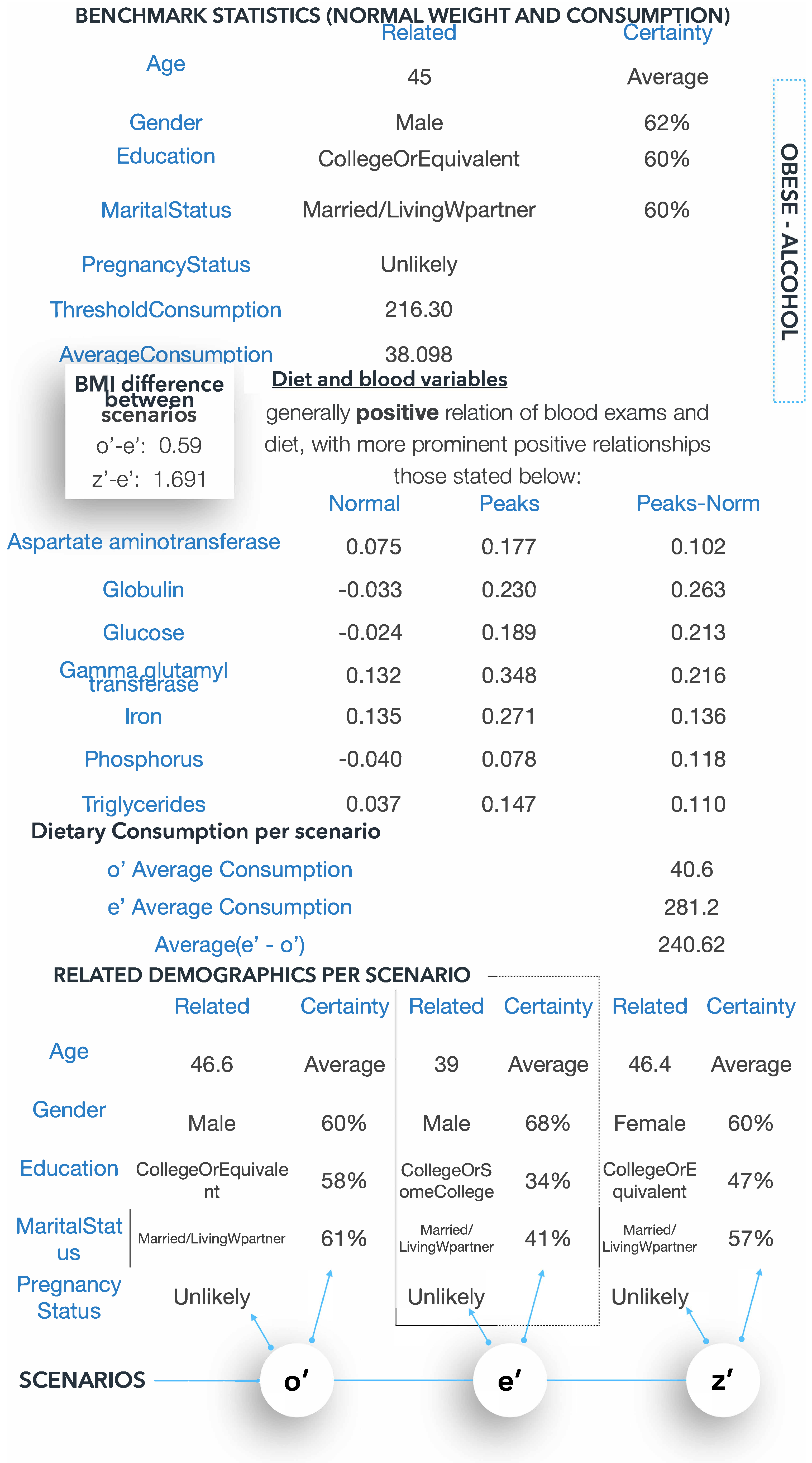
- Your related age is AGE your gender is GENDER, your education is EDU, your marital status is STATUS and you are a (non)smoker.
5.6. Discussion of Results and Medical Ontologies
5.6.1. Knowledge Extraction—Vitamin C and Overweight Status
5.6.2. Overconsumption of Vitamin C
5.6.3. Knowledge Extraction—Alcohol and Obese Status
5.6.4. Alcohol and Obesity
5.6.5. How Diet Affects Blood Variables
6. Conclusions and Future Research Endeavours
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| BMI | Body mass index |
| EVA | Extreme value analysis |
| EVT | Extreme value theory |
| POT | Peaks over threshold |
| A.M.S. | Annual maxima series |
| P.D.F. | Probability density plot |
| R.V. | Return value-level |
| FFQ | Food frequency questionnaires |
| DALYs | Disability-adjusted life years |
| F.B.D.G. | Food-based dietary guidelines |
| Y.L.L. | Years of life lost from mortality |
| Y.L.D. | Years lost due to disability |
| CDC | Center for Disease Control and Prevention |
| NHANES | National Health and Nutrition Examination Survey |
| WHO | World Health Organisation |
| PCC | Pearson correlation coefficient |
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Alias | Name (Measurement) |
|---|---|
| LBXSAPSI | Alkaline phosphatase (IU/L) |
| LBXSASSI | Aspartate aminotransferase AST (IU/L) |
| LBXSATSI | Alanine aminotransferase ALT (IU/L) |
| LBXSC3SI | Bicarbonate (mmol/L) |
| LBXSCLSI | Chloride (mmol/L) |
| LBXSCR | Creatinine (mg/dL) |
| LBXSGB | Globulin (g/dL) |
| LBDSGLSI | Glucose, refrigerated serum (mmol/L) |
| LBXSGTSI | Gamma glutamyl transferase (U/L) |
| LBXSIR | Iron, refrigerated serum (ug/dL) |
| LBXSLDSI | Lactate dehydrogenase (U/L) |
| LBXSNASI | Sodium (mmol/L) |
| LBDSPHSI | Phosphorus (mmol/L) |
| LBXSTB | Total bilirubin (mg/dL) |
| LBXSTP | Total protein (g/dL) |
| LBXSTR | Triglycerides, refrigerated (mg/dL) |
| LBDSUASI | Uric acid (umol/L) |
References
- Dao, M.C.; Subar, A.F.; Warthon-Medina, M.; Cade, J.E.; Burrows, T.; Golley, R.K.; Forouhi, N.G.; Pearce, M.; Holmes, B.A. Dietary assessment toolkits: An overview. Public Health Nutr. 2019, 22, 404–418. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cámara, M.; Giner, R.M.; González-Fandos, E.; López-García, E.; Mañes, J.; Portillo, M.P.; Rafecas, M.; Domínguez, L.; Martínez, J.A. Food-Based Dietary Guidelines around the World: A Comparative Analysis to Update AESAN Scientific Committee Dietary Recommendations. Nutrients 2021, 13, 3131. [Google Scholar] [CrossRef] [PubMed]
- Herforth, A.; Arimond, M.; Álvarez-Sánchez, C.; Coates, J.; Christianson, K.; Muehlhoff, E. A global review of food-based dietary guidelines. Adv. Nutr. 2019, 10, 590–605. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Potischman, N.; Freudenheim, J.L. Biomarkers of nutritional exposure and nutritional status: An overview. J. Nutr. 2003, 133, 873S–874S. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Panagoulias, D.P.; Virvou, M.; Tsihrintzis, G.A. Regulation and Validation Challenges in Artificial Intelligence-empowered Healthcare Applications—The Case of Blood-retrieved Biomarkers. In Proceedings of the 14th International Joint Conference on Knowledge-Based Software Engineering (JCKBSE 2022), Larnaca, Cyprus, 22–24 August 2022. [Google Scholar]
- Qiao, J.; Lin, X.; Wu, Y.; Huang, X.; Pan, X.; Xu, J.; Wu, J.; Ren, Y.; Shan, P.F. Global burden of non-communicable diseases attributable to dietary risks in 1990–2019. J. Hum. Nutr. Diet. 2022, 35, 202–213. [Google Scholar] [CrossRef] [PubMed]
- World Health Organization—Disability-Adjusted Life Years. Available online: https://www.who.int/data/gho/indicator-metadata-registry/imr-details/158 (accessed on 17 November 2022).
- Cornelis, M.C.; Hu, F.B. Systems epidemiology: A new direction in nutrition and metabolic disease research. Curr. Nutr. Rep. 2013, 2, 225–235. [Google Scholar] [CrossRef] [Green Version]
- Dansinger, M.L.; Gleason, J.A.; Griffith, J.L.; Selker, H.P.; Schaefer, E.J. Comparison of the Atkins, Ornish, Weight Watchers, and Zone diets for weight loss and heart disease risk reduction: A randomized trial. JAMA 2005, 293, 43–53. [Google Scholar] [CrossRef]
- Jebb, S.A. Dietary strategies for the prevention of obesity. Proc. Nutr. Soc. 2005, 64, 217–227. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Panagoulias, D.P.; Sotiropoulos, D.N.; Tsihrintzis, G.A. Biomarker-based deep learning for personalized nutrition. In Proceedings of the 2021 IEEE 33rd International Conference on Tools with Artificial Intelligence (ICTAI), Washington, DC, USA, 1–3 November 2021; pp. 306–313. [Google Scholar]
- Panagoulias, D.P.; Sotiropoulos, D.N.; Tsihrintzis, G.A. Nutritional biomarkers and machine learning for personalized nutrition applications and health optimization. In Proceedings of the 2021 12th International Conference on Information, Intelligence, Systems & Applications (IISA), Chania Crete, Greece, 12–14 July 2021; pp. 1–6. [Google Scholar]
- Panagoulias, D.P.; Sotiropoulos, D.N.; Tsihrintzis, G.A. Nutritional biomarkers and machine learning for personalized nutrition applications and health optimization (extended journal version). Intell. Decis. Technol. 2021, 15, 645–653. [Google Scholar] [CrossRef]
- Panagoulias, D.P.; Sotiropoulos, D.N.; Tsihrintzis, G.A. SVM-Based Blood Exam Classification for Predicting Defining Factors in Metabolic Syndrome Diagnosis. Electronics 2022, 11, 857. [Google Scholar] [CrossRef]
- Panagoulias, D.P.; Virvou, M.; Tsihrintzis, G.A. A microservices-based iterative development approach for usable, reliable and explainable A.I.-infused medical applications using R.U.P. In Proceedings of the 34th IEEE Conference on Tools with Artificial Intelligence (ICTAI 2022), Conference Proceedings, Virtually, 31 October–2 November 2022. [Google Scholar]
- Panagoulias, D.P.; Virvou, M.; Tsihrintzis, G.A. NUHEALTHSOFT: A Nutritional and Health Data Processing Software Tool. In Proceedings of the 2022 16th International Conference on Signal Image Technology and Internet Based Systems (SITIS), Dijon, France, 19–21 October 2022. [Google Scholar]
- Panagoulias, D.P.; Sotiropoulos, D.N.; Tsihrintzis, G.A. Extreme value analysis for dietary intake based on weight class. In Proceedings of the 2022 13th International Conference on Information, Intelligence, Systems & Applications (IISA), Corfu, Greece, 18–20 July 2022. [Google Scholar]
- Coles, S.; Bawa, J.; Trenner, L.; Dorazio, P. An Introduction to Statistical Modeling of Extreme Values; Springer: Berlin/Heidelberg, Germany, 2001; Volume 208. [Google Scholar]
- Xu, S. Proceedings of 2013 World Agricultural Outlook Conference; Springer: Berlin/Heidelberg, Germany, 2014. [Google Scholar]
- Thomas, M.; Lemaitre, M.; Wilson, M.L.; Viboud, C.; Yordanov, Y.; Wackernagel, H.; Carrat, F. Applications of extreme value theory in public health. PLoS ONE 2016, 11, e0159312. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chiu, Y.; Chebana, F.; Abdous, B.; Bélanger, D.; Gosselin, P. Mortality and morbidity peaks modeling: An extreme value theory approach. Stat. Methods Med. Res. 2018, 27, 1498–1512. [Google Scholar] [CrossRef] [PubMed]
- Flegal, K.M.; Wei, R.; Ogden, C.L.; Freedman, D.S.; Johnson, C.L.; Curtin, L.R. Characterizing extreme values of body mass index–for-age by using the 2000 Centers for Disease Control and Prevention growth charts. Am. J. Clin. Nutr. 2009, 90, 1314–1320. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tsihrintzis, G.A.; Nikias, C.L. Fast estimation of the parameters of alpha-stable impulsive interference. IEEE Trans. Signal Process. 1996, 44, 1492–1503. [Google Scholar] [CrossRef]
- Arsenault, E.; Wang, Y.; Chapman, M.P. Towards Scalable Risk Analysis for Stochastic Systems Using Extreme Value Theory. arXiv 2022, arXiv:2203.12689. [Google Scholar] [CrossRef]
- Szigeti, M.; Ferenci, T.; Kovács, L. The use of block maxima method of extreme value statistics to characterise blood glucose curves. In Proceedings of the 2020 IEEE 15th International Conference of System of Systems Engineering (SoSE), Budapest, Hungary, 2–4 June 2020; pp. 433–438. [Google Scholar]
- Huss, R.; Grunkin, M. Artificial Intelligence Applications in Human Pathology; WSPC: UK, London, 2022. [Google Scholar]
- Spruijt, J.; Spanjaard, T.; Demouge, K. The Golden Circle of Innovation: What Companies Can Learn from NGOs When It Comes to Innovation. In Modern Marketing for Non-Profit Organizations: International Perspectives; Smyczek, S., Ed.; University of Economics in Katowice Publishing House, Forthcoming: Katowice, Poland, 2013. [Google Scholar]
- Panagoulias, D.P.; Sotiropoulos, D.N.; Tsihrintzis, G.A. Towards Personalized Nutrition Applications with Nutritional Biomarkers and Machine Learning. In Advances in Assistive Technologies: Selected Papers in Honour of Professor Nikolaos G. Bourbakis; Tsihrintzis, G.A., Virvou, M., Esposito, A., Jain, L.C., Eds.; Springer: Berlin/Heidelberg, Germany, 2022; pp. 73–122. [Google Scholar]
- Pyextremes—Python Library. Available online: https://georgebv.github.io/pyextremes/ (accessed on 28 May 2022).
- Baek, J.W.; Kim, J.C.; Chun, J.; Chung, K. Hybrid clustering based health decision-making for improving dietary habits. Technol. Health Care 2019, 27, 459–472. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kochenderfer, M.J.; Wheeler, T.A.; Wray, K.H. Algorithms for Decision Making; MIT Press: Cambridge, MA, USA, 2022. [Google Scholar]
- Johnson, C.L.; Dohrmann, S.M.; Burt, V.L.; Mohadjer, L.K. National Health and Nutrition Examination Survey: Sample Design, 2011–2014; Number 2014; US Department of Health and Human Services, Centers for Disease Control and Prevention: Atlanta, GA, USA, 2014. [Google Scholar]
- Cedeno-Moreno, D.; Vargas-Lombardo, M. An ontology-based knowledge methodology in the medical domain in the Latin america: The study case of republic of Panama. Acta Inform. Med. 2018, 26, 98. [Google Scholar] [CrossRef] [PubMed]
- Studer, R.; Benjamins, V.R.; Fensel, D. Knowledge engineering: Principles and methods. Data Knowl. Eng. 1998, 25, 161–197. [Google Scholar] [CrossRef] [Green Version]
- Mayo Clinic—Nutrition and Healthy Eating. Available online: https://www.mayoclinic.org/healthy-lifestyle/nutrition-and-healthy-eating/expert-answers/vitamin-c/faq-20058030/ (accessed on 17 November 2022).
- Hoschar, S.; Albarqouni, L.; Ladwig, K.H. A systematic review of educational interventions aiming to reduce prehospital delay in patients with acute coronary syndrome. Open Heart 2020, 7, e001175. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- World Health Organization—Alcohol Use and Your Health. Available online: https://www.cdc.gov/alcohol/fact-sheets/alcohol-use.htm/ (accessed on 17 November 2022).
- Libre Texts Medicine—Nutrients Are Essential for Organ Function. Available online: https://tinyurl.com/yxsf45bs/ (accessed on 17 November 2022).
- Papacharissi, Z. A Networked Self: Identity, Community, and Culture on Social Network Sites; Routledge: London, UK, 2010. [Google Scholar]
- Kent, R. Social media and self-tracking: Representing the ‘health self’. In Self-Tracking; Springer: Berlin/Heidelberg, Germany, 2018; pp. 61–76. [Google Scholar]
- Uses of the Data. Available online: https://www.cdc.gov/nchs/nhanes/about_nhanes.htm#data/ (accessed on 17 November 2022).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]













| Range | Category |
|---|---|
| less than 18 | underweight |
| between 18 and 25 | normal |
| between 25 and 30 | overweight |
| above 30 | obese |
| Name | Name |
|---|---|
| Alpha-carotene (mcg) | Alcohol (gm) |
| Vitamin E (mg) | vitamin B12 (mg) |
| Beta-carotene (mcg) | Caffeine (mg) |
| Calcium (mg) | Carbohydrate (gm |
| Total choline (mg) | Cholesterol (mg) |
| Copper (mg) | Beta-cryptoxanthin (mcg) |
| Folic acid (mcg) | Folate equivalents (mcg) |
| Food folate (mcg) | Dietary fiber (gm) |
| Total folate (mcg) | Iron (mg) |
| Energy (kcal) | Lycopene (mcg) |
| Lutein + zeaxanthin (mcg) | MFA (16–22):1 (gm) |
| Magnesium (mg) | fatty acids (gm) |
| Moisture (gm) | Niacin (mg) |
| Phosphorus (mg) | Potassium (mg) |
| Protein (gm) | Retinol (mcg) |
| Selenium (mcg) | fatty acids (gm) |
| Sodium (mg) | Total sugars (gm) |
| Total fat (gm) | Theobromine (mg) |
| Vitamin A (mcg) | Vitamin B1 (mg) |
| Vitamin B12 (mcg) | Vitamin C (mg) |
| Vitamin D (D2 + D3) (mcg) | Vitamin K (mcg) |
| Selenium (mcg) | Zinc (mg) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Panagoulias, D.P.; Sotiropoulos, D.N.; Tsihrintzis, G.A. An Extreme Value Analysis-Based Systemic Approach in Healthcare Information Systems: The Case of Dietary Intake. Electronics 2023, 12, 204. https://doi.org/10.3390/electronics12010204
Panagoulias DP, Sotiropoulos DN, Tsihrintzis GA. An Extreme Value Analysis-Based Systemic Approach in Healthcare Information Systems: The Case of Dietary Intake. Electronics. 2023; 12(1):204. https://doi.org/10.3390/electronics12010204
Chicago/Turabian StylePanagoulias, Dimitrios P., Dionisios N. Sotiropoulos, and George A. Tsihrintzis. 2023. "An Extreme Value Analysis-Based Systemic Approach in Healthcare Information Systems: The Case of Dietary Intake" Electronics 12, no. 1: 204. https://doi.org/10.3390/electronics12010204