1. Introduction
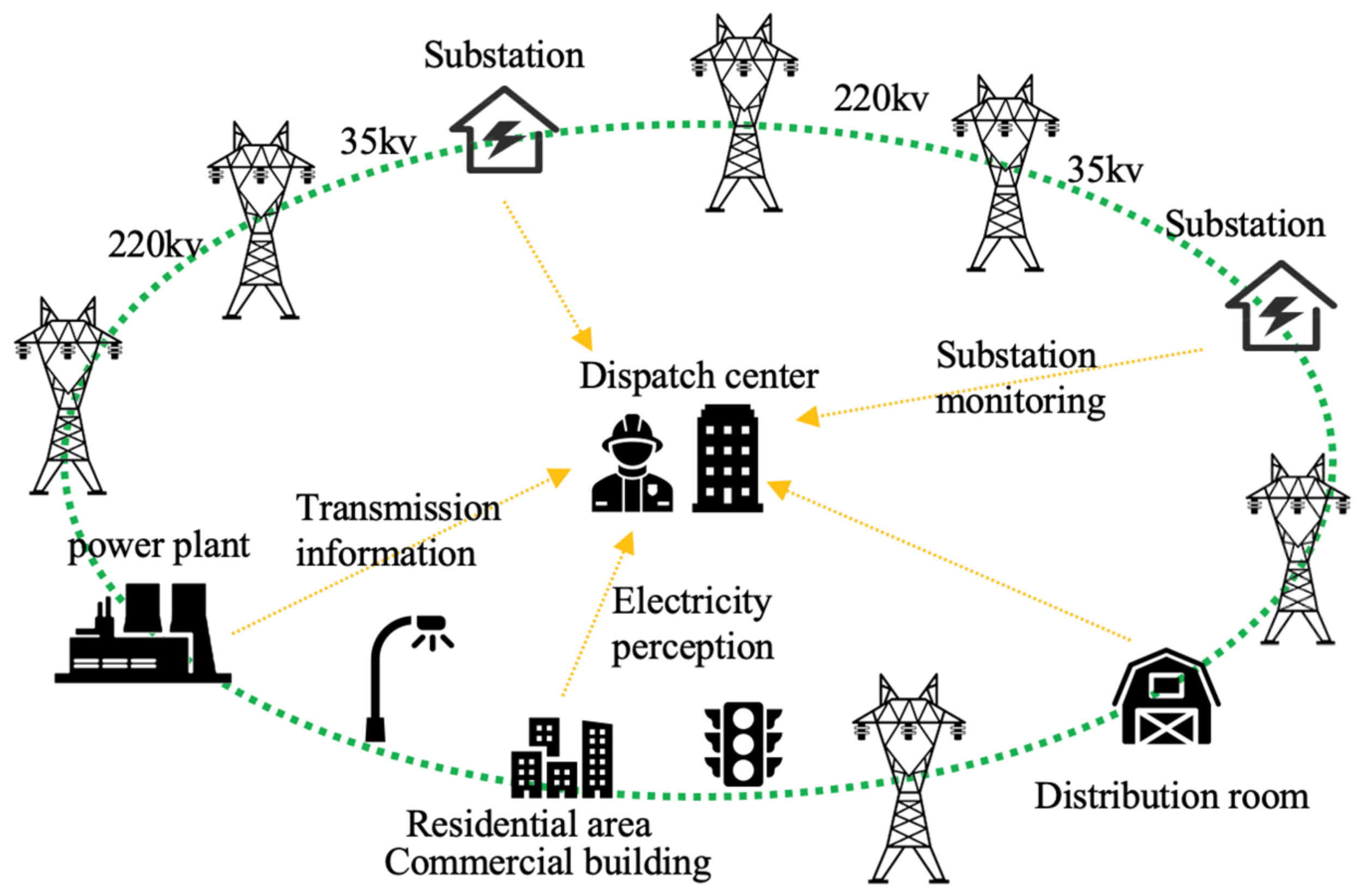
The industrial internet of things (IIoT) deploys a large number of perception and communication devices [
1], which realize the real-time state perception of physical space–information space interaction and the normal operation of the system. Once a fault occurs, it is easy to cause problems, such as energy resource scheduling, distribution and out of control transmission. It will seriously endanger the operation safety of the integrated energy system [
2]. Therefore, it is of great significance to accurately extract equipment fault information, locate the entity relationship of fault equipment, construct the fault knowledge graph of IIoT communication equipment [
3,
4] and realize real-time fault analysis and efficient troubleshooting of IIoT communication equipment.
Named entity recognition and relationship extraction are two key technologies to realize knowledge extraction [
5]. Named entity recognition techniques are divided into three main approaches in terms of implementation techniques: rule-based, probabilistic graph and deep learning [
6]. Rule-based learning relies more on manual or domain dictionaries, which not only lack flexibility, but also has poor recognition efficiency. With the development of probabilistic graphs, the learning of entity sequence information is carried out through directed and undirected graphs [
7]. It reduces manual involvement and provides some improvement in efficiency, but generalization capability is poor and the efficiency of entity recognition needs to be improved [
8]. Deep learning techniques build multiple models to learn grammatical features through neural networks, which convert text into vectors covering contextual semantics [
9]. It effectively improves on these shortcomings and greatly enhances the recognition of entities and relationship extraction [
10,
11,
12]. The mainstream algorithms for relationship extraction tasks consist of two main types: manual annotation and remote supervision [
13]. The former requires more human involvement but is also not generalizable, while the latter combines methods, such as deep learning to improve the accuracy and efficiency of relationship extraction [
14,
15]. In the process of domain-oriented knowledge extraction, deep learning greatly improves the generalization ability of knowledge extraction algorithms, which facilitates the process of building knowledge graphs in various domains, such as power [
16] and geography [
17].
Although the knowledge extraction effect of the current entity relation extraction model has been improved [
18], the pipeline extraction method leads to the lack of relevance between entity extraction and relationship extraction [
19,
20], resulting in the loss of information. When facing the text of the fault of the IIoT communication equipment, because of the complex subordinate relationship between the equipment, confusion and misjudgment of the relationship between multi-fault entities can easily occur. The main reasons are: (1) when the traditional word embedding model maps the text, it is easy to cause the loss of time series information in the text [
21]. Therefore, the relationship prediction cannot be well carried out in the follow-up tasks. (2) Most of the existing knowledge extraction is pipelined operation [
22], and most of them establish independent models for entity extraction and relationship prediction [
11,
12,
13,
14,
15,
16,
17,
18,
19,
20,
21,
22,
23]. Therefore, when facing the terms and relationships that appear in the professional field, the relational model cannot be combined with entity features to predict. This can easily lead to confusion in the labeling of multi-entity relationships [
24,
25,
26].
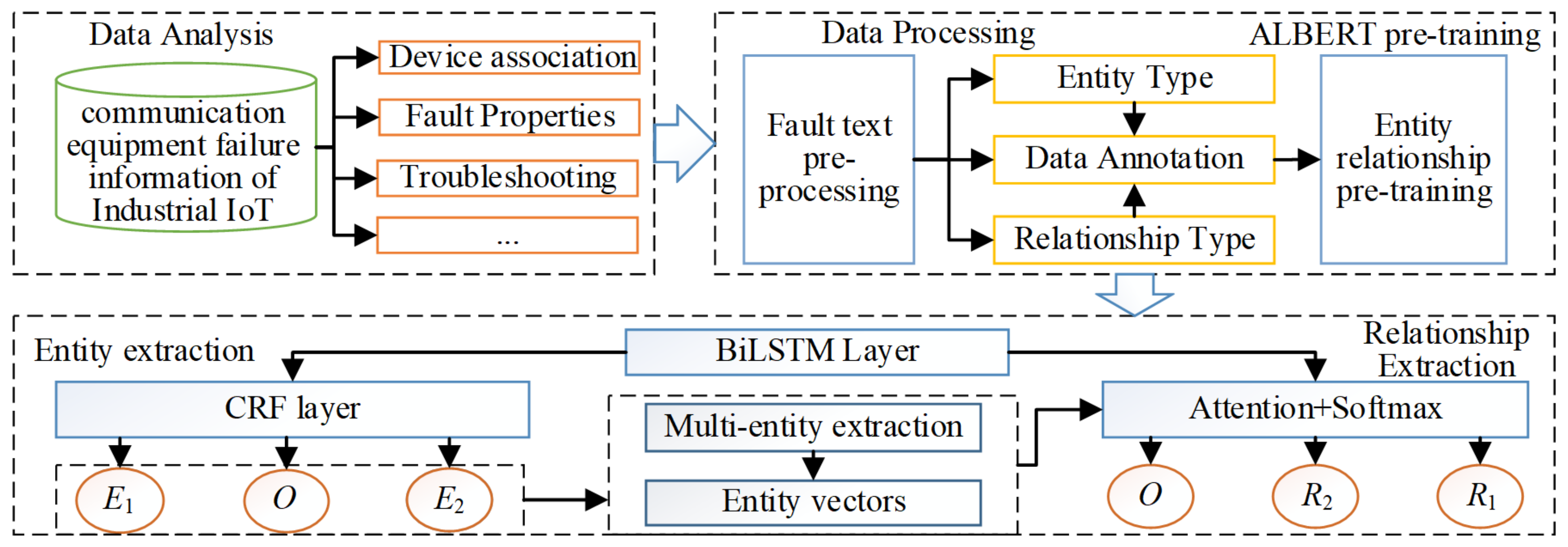
This paper designs a knowledge extraction method for IIoT communication equipment faults, which can achieve fast and accurate indexing and localization for fault entities with relationship categories. The main contributions of this paper are as follows.
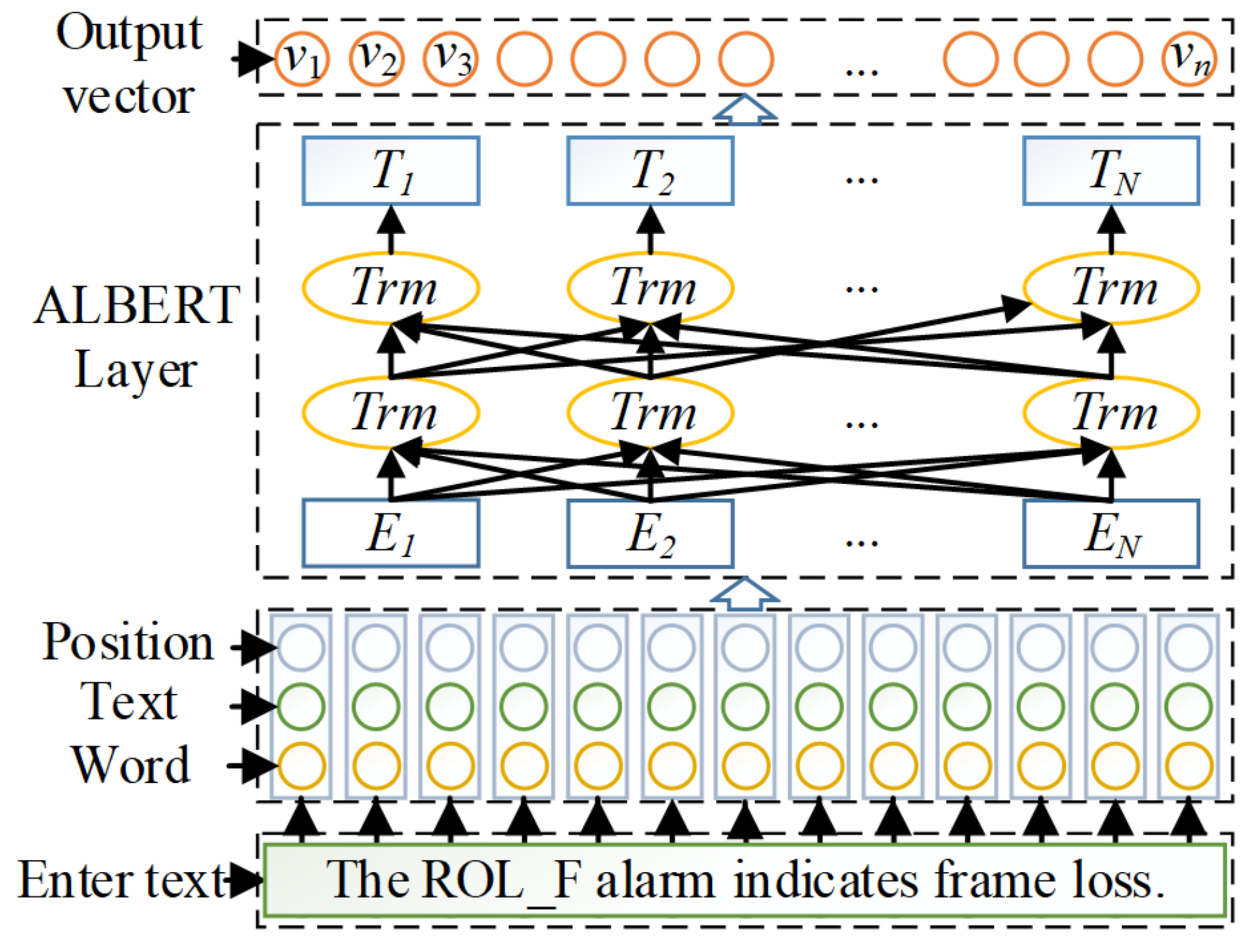
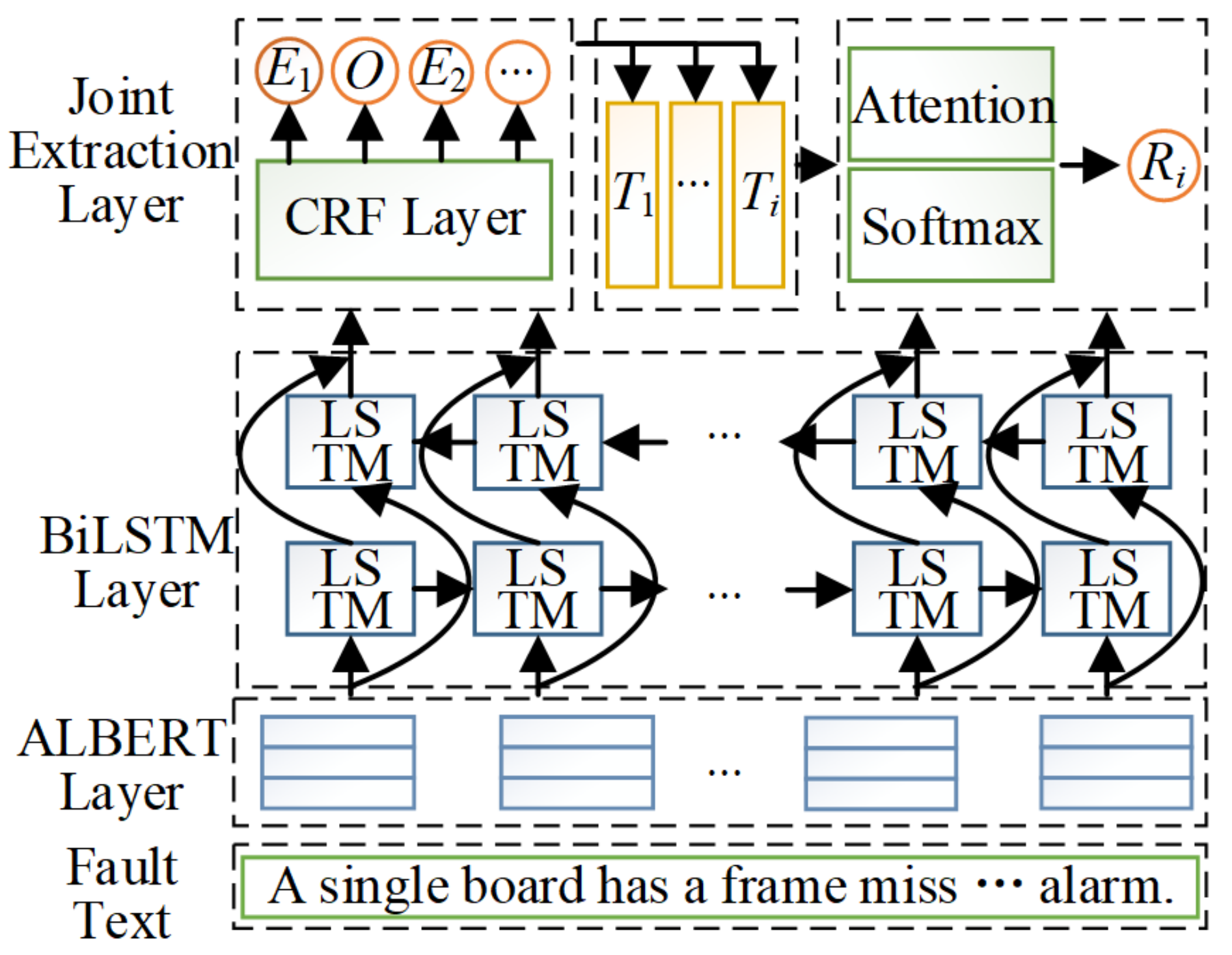
We propose the ALBERT fault pre-training model for embedding the fault data, which solves the loss problem of fault text information.
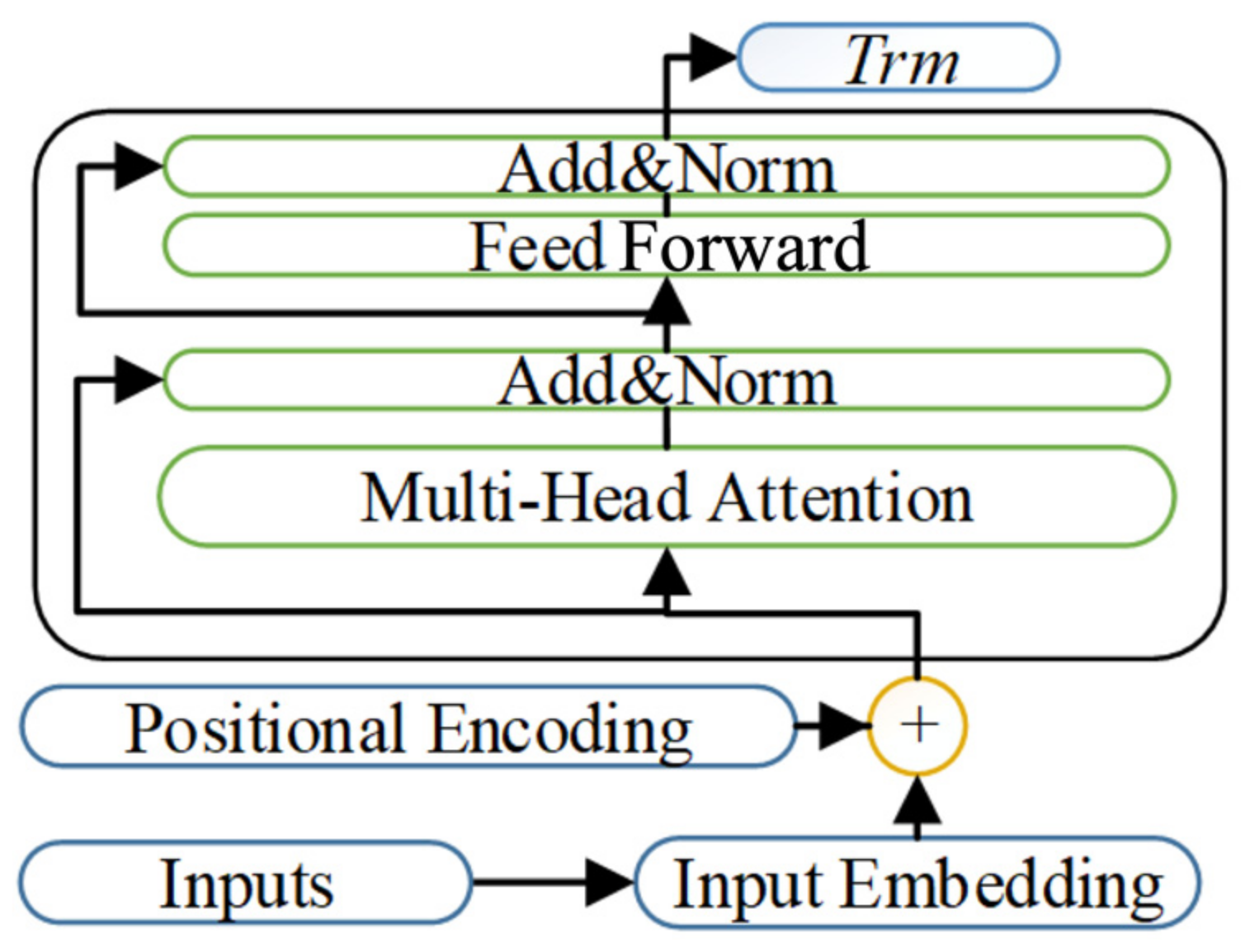
We build a joint coding model for fault text. The ALBERT-BilSTM network structure in the model enhances the coupling between subsystems, which effectively improves the accuracy of knowledge extraction.
We have designed a joint extraction method of relationships between multiple entities. It can be simultaneously extracted on the relationship between multiple entities in a corpus.
The rest of the paper is organized as follows.
Section 2 focuses on reviewing relevant research.
Section 3 shows the system architecture and application scenarios of the joint extraction model, and the knowledge combination extraction algorithm is expounded, which is the main contribution of this article.
Section 4 is the situational analysis of experimental simulations.
Section 5 is a summary and a prospect for the next steps.
2. Related Work
Knowledge extraction is the basis for the construction of knowledge maps and is also the basis for knowledge visualization and recommended algorithms. Knowledge extraction usually contains two sub-tasks: named entity recognition and relationship extraction. In the above summary, we summarized the advantages and disadvantages and main branches of existing knowledge extraction techniques. Hereinafter, we focus on the research status of naming entity identification and relational extraction and discuss the differences between the algorithms proposed herein and existing algorithms [
11,
27,
28,
29].
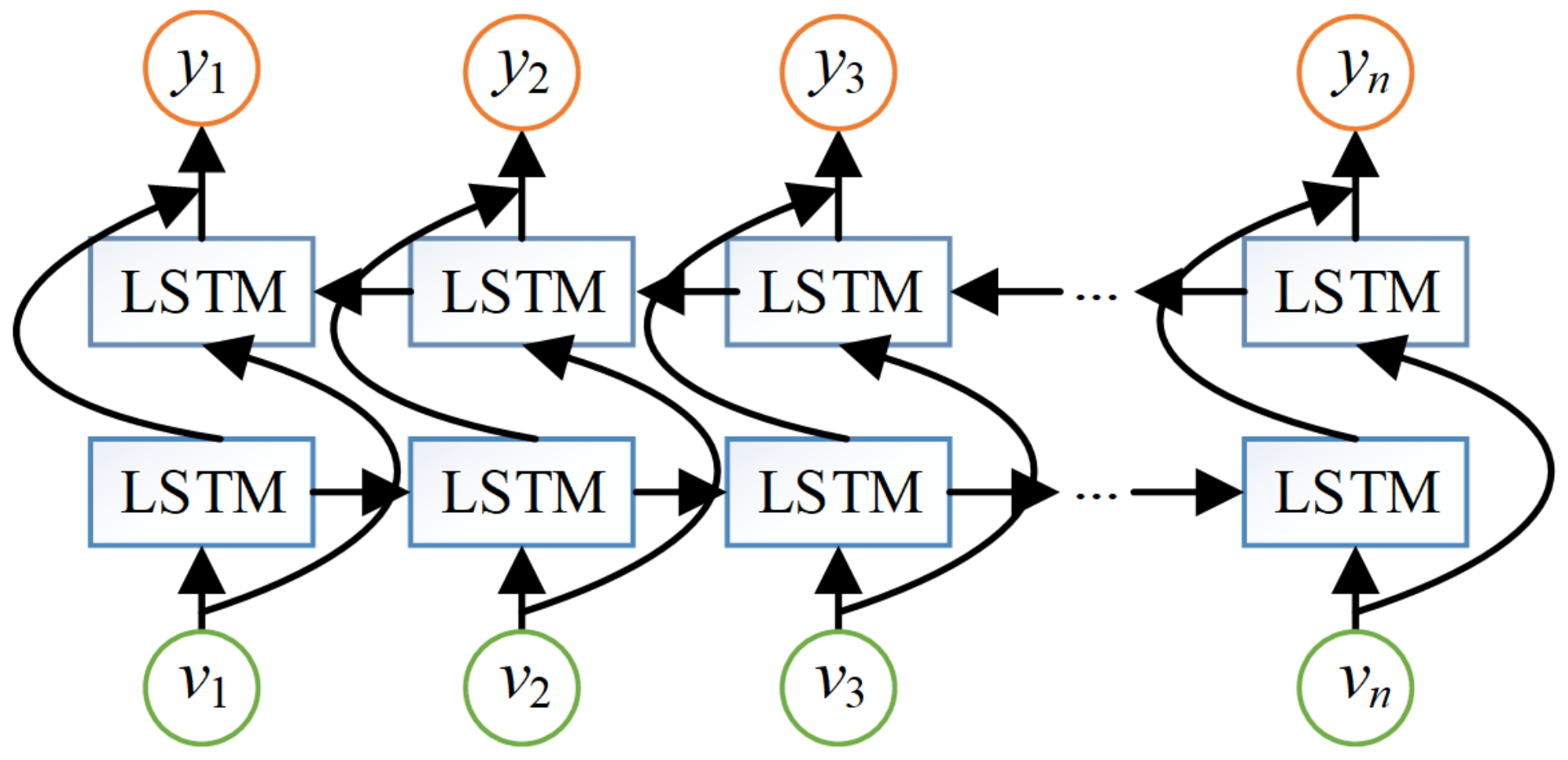
In the aspect of named entity recognition, rule-based and statistics-based methods are mainly used in the early stage, but the portability is poor, and a lot of manpower is spent on tagging. With the development of machine learning, many existing models have significantly improved the efficiency of entity recognition, such as perceptron model, conditional random field model and so on. In recent years, deep learning-based methods have become mainstream due to their excellent performance, for example, the bidirectional LSTM (long-and short-term memory) CRF model proposed by R. Grishman et al. [
6]. The BiLSTM (bidirectional long short-term memory) model proposed by G. Lample et al. [
7] integrates the self-attention mechanism, and CNNs (convolutional neural networks) process the word vector to identify military entities. The BiLSTM and CRF methods proposed by J. Li et al. [
8] are used to extract entities from clinical symptoms of traditional Chinese medicine. The BiLSTM-CRF model is used to mark the motor entities sequentially [
9]. In other fields, Kcm B et al. [
17] have proposed a novel LSTM framework for short-term fog forecasting. Y. An. et al. [
18] proposed a multi-head self-attention based bi-directional long short-term memory conditional random field (MUSA-BiLSTM-CRF) model, which is expected to greatly improve the performance of Chinese clinical named entity recognition.
In the aspect of entity relationship extraction, supervised relationship extraction is often used in the early stage. It includes the method based on CRF, but it needs a lot of manual labeling [
11]. Y. Gu et al. [
12] proposed a multi-instance, multi-label method to model relationship extraction and extract the situation, in which there may be multiple relationships in the entity pair. M. Surdeanu et al. [
13] proposed the use of a multi-instance, multi-label and Bayesian network for relationship extraction. Although the effect has been improved, the number of model parameters has also greatly increased the training scale. On the other hand, the lightweight ALBERT [
14] model proposed by Google can effectively reduce the number of model parameters, and the effect of knowledge extraction is better. In applications for power and beyond, S. Wang [
15] and W. Shi [
16] present new research ideas in terms of processing frameworks and hierarchical structures. B. Aha et al. [
19] created a biomedical Knowledge Graph using Natural Language Processing models for relationship extraction. The generated biomedical knowledge graphs (KGs) are then used for question answering.
The proposed model designed in this paper uses a pre-trained model to reduce the number of training parameters and improve the representativeness of text information compared with the traditional model. Meanwhile, parameter sharing and multi-entity segmentation are used to achieve joint acquisition of fault knowledge. It provides data support and effective knowledge extraction means for forming fault database or fault knowledge graph [
24]. It helps to assist fault repairers in decision making and rapid fault localization to improve the efficiency of fault investigation and diagnosis.
4. Experiment Analysis
4.1. Experimental Environment and Data
There are two sets of data sources for this paper. One set is the fault log data from the operation of the Southern China Power Grid, and also includes the power operation and maintenance manuals of the equipment and expert cases. It is taken from the alarm and performance event manual of the OptixOSN7500, a grid communication device. Through the preliminary manual screening, 15,000 sentences can be used in the experimental data. It includes 530 entities and 16 failure relationships. The other set is the Chinese dataset CLUENER, where the comparison experiments are conducted, which includes category labels for 10 life scenes and has a total corpus sample size of 12,091 items.
The configuration used in this article in the experimental environment is shown in the following
Table 1.
4.2. Data Preprocessing
First, the corpus is segmented, and missing words and blank lines are deleted. After that, the corpus is segmented and filled to a uniform word length. The word length is set to 200. Finally, the fault text data characteristics of IIoT communication equipment are combined. Some entities and relationships are shown in
Table 2 and
Table 3.
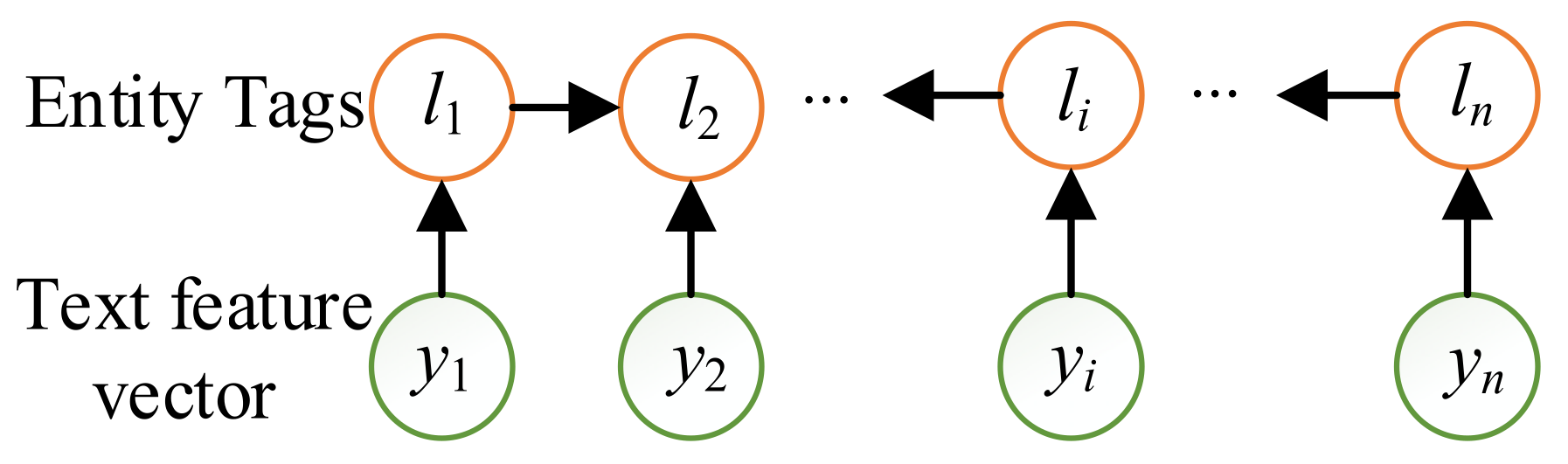
This article uses the “BIO” label strategy. Mark each element as “B-X”, “I-X” or “O”. Among them, “B” represents the beginning of the marked entity or relationship, “I” represents the middle, and “O” indicates that the text does not belong to any type of entity or relationship.
Table 4 shows an example of fault corpus tagging.
4.3. Evaluation Index
In this paper, the accuracy P (Precision), recall rate R (Recall) and F1 value (F1-score) are used as the evaluation criteria for the extraction results of entities and relationships.
In the above formula, TP (True Positive) indicates the number of positive samples predicted as positive samples. TN (True Negative) means to predict the number of negative samples as negative samples. FP (False Negative) means to predict the number of positive samples as negative samples. Finally, calculate the F1 value according to Equation (15). The higher the value, the better the classification effect.
4.4. Model Parameter Training
In terms of experimental parameters, this article chose different parameter settings for comparison. Finally, we determine the best parameter settings, where the dimension of the word vector is 200, the size is 256, the number of layers of the BiLSTM model is 2, the value of dropout is 0.8, the head h of self-attention is set to 6, and the bias variable is set to 10.
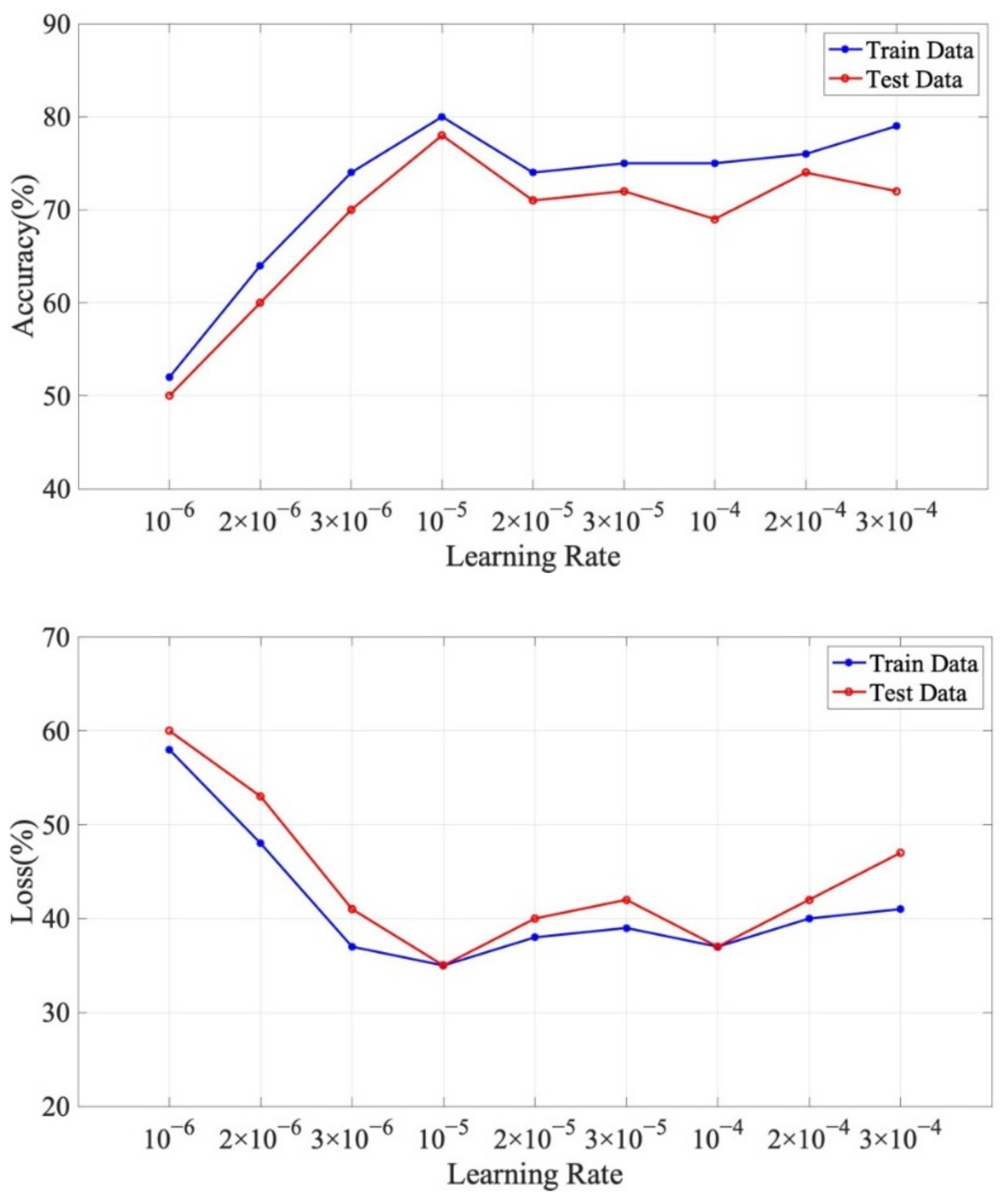
In the experimental part, we optimize the joint extraction model by adjusting the learning rate and the number of iterations. Among them, the learning rate will directly affect the speed and accuracy of the model convergence. When the learning rate is set too large, although the model learning speed is fast, it may cause oscillations (A too large learning rate setting leads to a non-convergence of the training process, and parameters such as accuracy show large fluctuations during the training process.). If the learning rate is too small, it may fall into a local optimum (A too small learning rate setting will result in a recent extreme point in the training process and cannot jump out of the local range to achieve the overall optimal.). Similarly, the number of iterations represents the entire process of model training. When the number of iterations is too few, the model training will not be mature enough, which will lead to a larger loss value, and too many iterations will cause over-fitting and reduce the accuracy rate. Among them, Acc_train represents the accuracy of the training set, Loss represents the verification error and Acc_test represents the accuracy of the test set.
As shown in
Figure 9, when the learning rate is 1 × 10
−5 and 2 × 10
−4, the accuracy of the model training set is higher, but the prediction effect of the latter verification set is slightly lower. Similarly, the loss rate of the model is lower when the learning rate is 1 × 10
−5 and 1 × 10
−4. In the case of taking into account both the accuracy of model knowledge extraction and the loss rate, 1 × 10
−5 is the best learning rate.
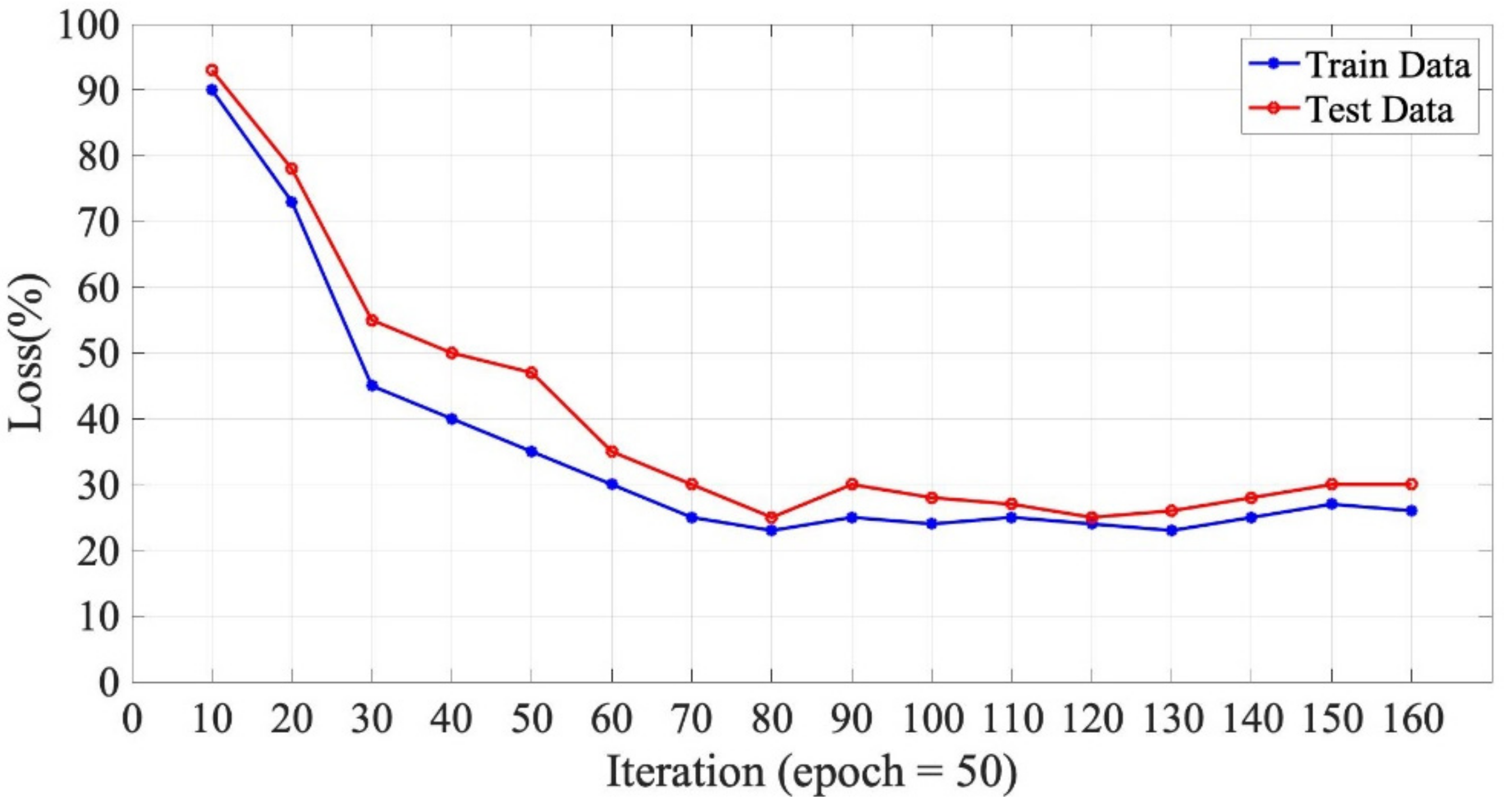
As shown in
Figure 10, according to the trend of the line chart, the accuracy of the model improves rapidly in the training processes, and the accuracy is the highest when the number of iterations reaches 70, and then tends to be stable. The model loss rate varies with the number of model training iterations. As can be seen from the diagram, the loss rate of the model decreases rapidly in the iterations. When the number of training is 70, the loss effect of training set and verification set is better. When the training time is 80, the loss rate of the training set is the lowest, but the loss of the verification set is larger. The iterative effect of comprehensive accuracy and loss rate preserves the model parameters with training times of 70.
4.5. Comparative Analysis of Model Results
In order to verify the model experimental effect, four groups of comparison experimental groups are set up in this paper: BiLSTM-CRF [
11], LSTM-Attention-CRF [
27], BERT-LSTM-CRF [
28] and BERT joint extraction model [
29] as knowledge extraction effect control. The experiments have compared the CLUENER dataset and the Failure Text dataset of industrial network communication equipment.
Table 5 shows the evaluation results for named entity recognition of device fault text with the CLUENER dataset by various classical models. As we can see from the table, the left side shows the evaluation results of named entity recognition for faulty text, and the performance of the MEKJE model proposed in this paper is on average 3% better in terms of both accuracy, recall and F1 value compared with models such as BiLSTM-CRF. Our comparison experiments with the CLUENER dataset on the right side show that the MEKJE model also performs well, with an average improvement of 5% in F1 values compared to other models. This also proves that the pre-trained model can produce a greater help in the named entity recognition accuracy improvement. Although the model named entity recognition results are similar to the Bert model, the advantage of this model is the reduction of training parameters and the significant reduction of training cost. This also shows that the model is not only for the electric power field, but also for other datasets with good recognition results and strong generalizability.
As shown in
Table 6. The MEKJE model proposed in this paper is higher than other classic models in relational extraction. Whether in the Fault Text dataset or the CLUENER dataset, the model’s performance is the best. In particular, it has increased 6.1% and 6.2% in the precision and recall compared with the optimal BERT joint extraction model, and the F1 value reached 78.6%. In order to verify the generality of the model, the experiment also tests on the CLUENER dataset. The experimental results show that the MEKJE model also achieves the best results on the open-source Chinese dataset. It increased by 8.3%, 6.9% and 8.3% on the accuracy, recall and F1 score. Experiments show that the MEKJE model can deeply explore the relationship between the multi-entity entities, improve the accuracy of the relationship extraction.
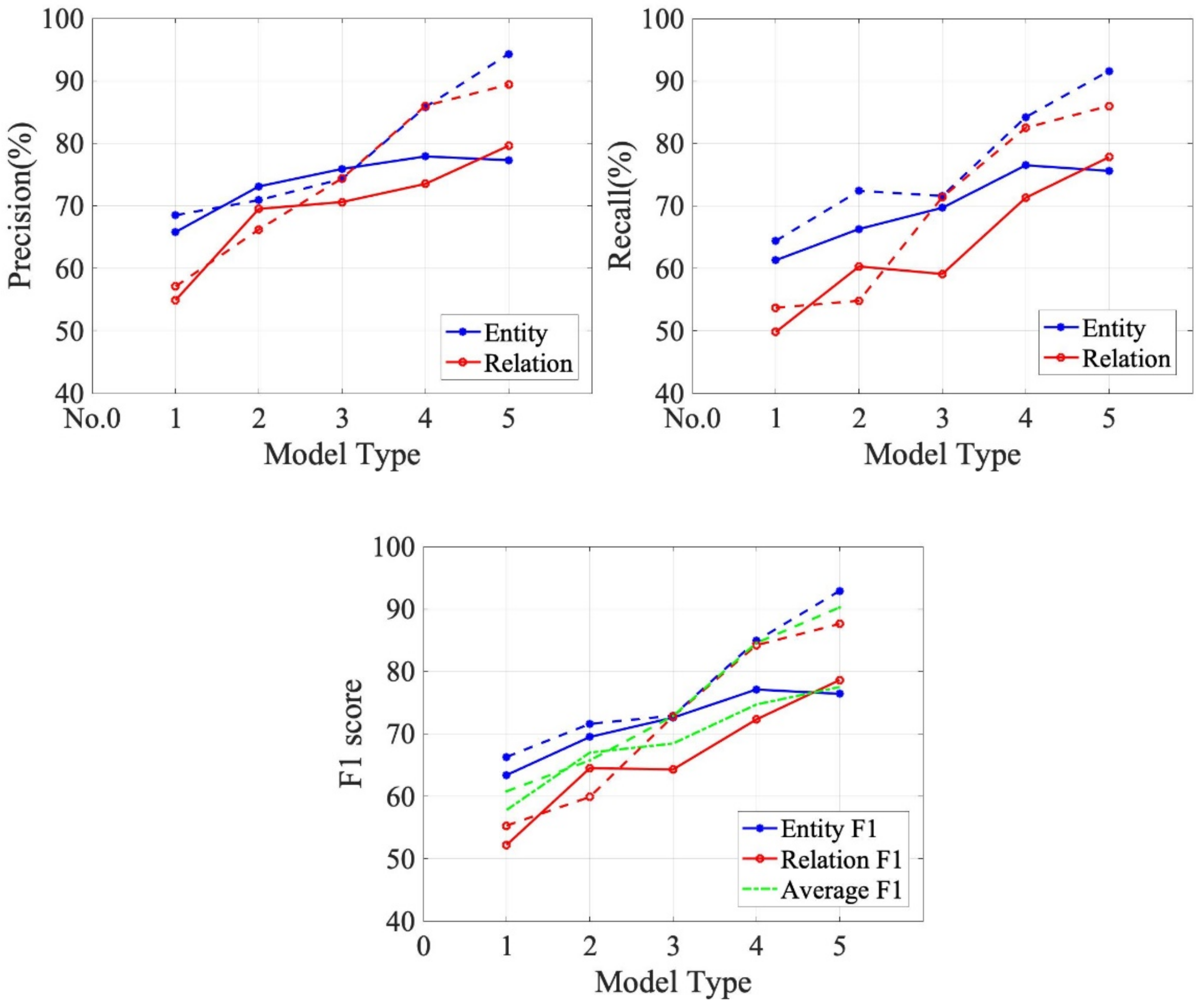
Figure 11 shows the performance of each model in terms of entity and relationship extraction accuracy, where the solid line represents the entity and relationship extraction accuracy for the Faulty Text dataset. The dashed line represents the entity and relationship extraction accuracy for the CLUENER dataset. As can be seen from the graph, the entity extraction accuracy of the MEKJE model is almost the same as that of the BERT joint extraction model, while the accuracy of relational extraction is significantly higher than that of the latter.
Similarly, it shows the performance of each model in terms of recall rates for entity and relationship extraction. As can be seen from the graph, the entity extraction recall rate of the MEKJE model is slightly lower than that of the BERT joint extraction model, while the accuracy of relational extraction is much higher than the latter.
By calculating the accuracy of the model and the recall rate, a comprehensive assessment of each model can be obtained for F1 values. As shown in
Figure 11, the blue line represents the F1 value extracted by the entity, the red line represents the F1 value extracted, and the green line represents the average F1 value of each model. In the comparison of the entity relationship with several classic models, this model is optimized by the entity relationship with several classic models, and improves model application efficiency.
4.6. Analysis of Sample Prediction Results
According to the prediction results in
Table 7, the input sample will output the prediction results of the fault entity and relationship after knowledge extraction through the model. According to the predefined entity relationship label, the number and name of the faulty entity in the model output text. At the same time, the prediction of the relationship between the two entities is realized and expressed in the form of combination.
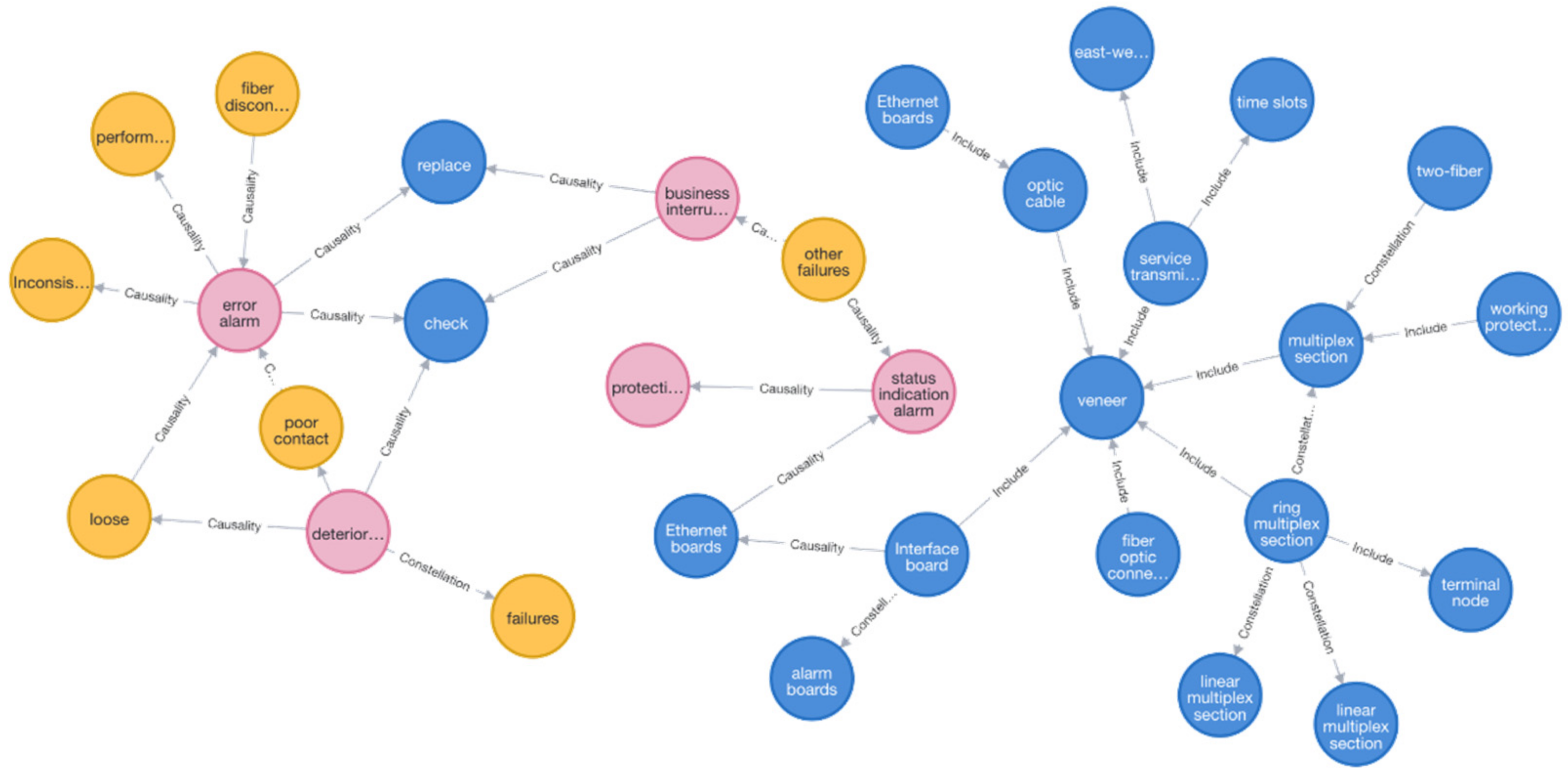
Figure 12 shows the fault knowledge graph constructed from the entities and relationships of the IIoT communication device faults. The knowledge extraction of the fault text is performed by means of a federated model, and we will simulate and model the resulting entities and relations by means of Neo4j. Entities are represented by dots and relationships are represented by arrow connecting lines between two entities. For example, pink represents the fault phenomenon, blue represents the fault treatment and orange represents the cause of the fault.
When an equipment fault occurs, the maintenance worker can refer to the power knowledge map to search for fault handling cases and the relationships between related equipment to locate the cause of the fault as quickly as possible. Thus, the knowledge map shows the correlation between equipment more vividly, which is helpful for fault handling.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}