
A Cascade Framework for Privacy-Preserving Point-of-Interest Recommender System


Abstract
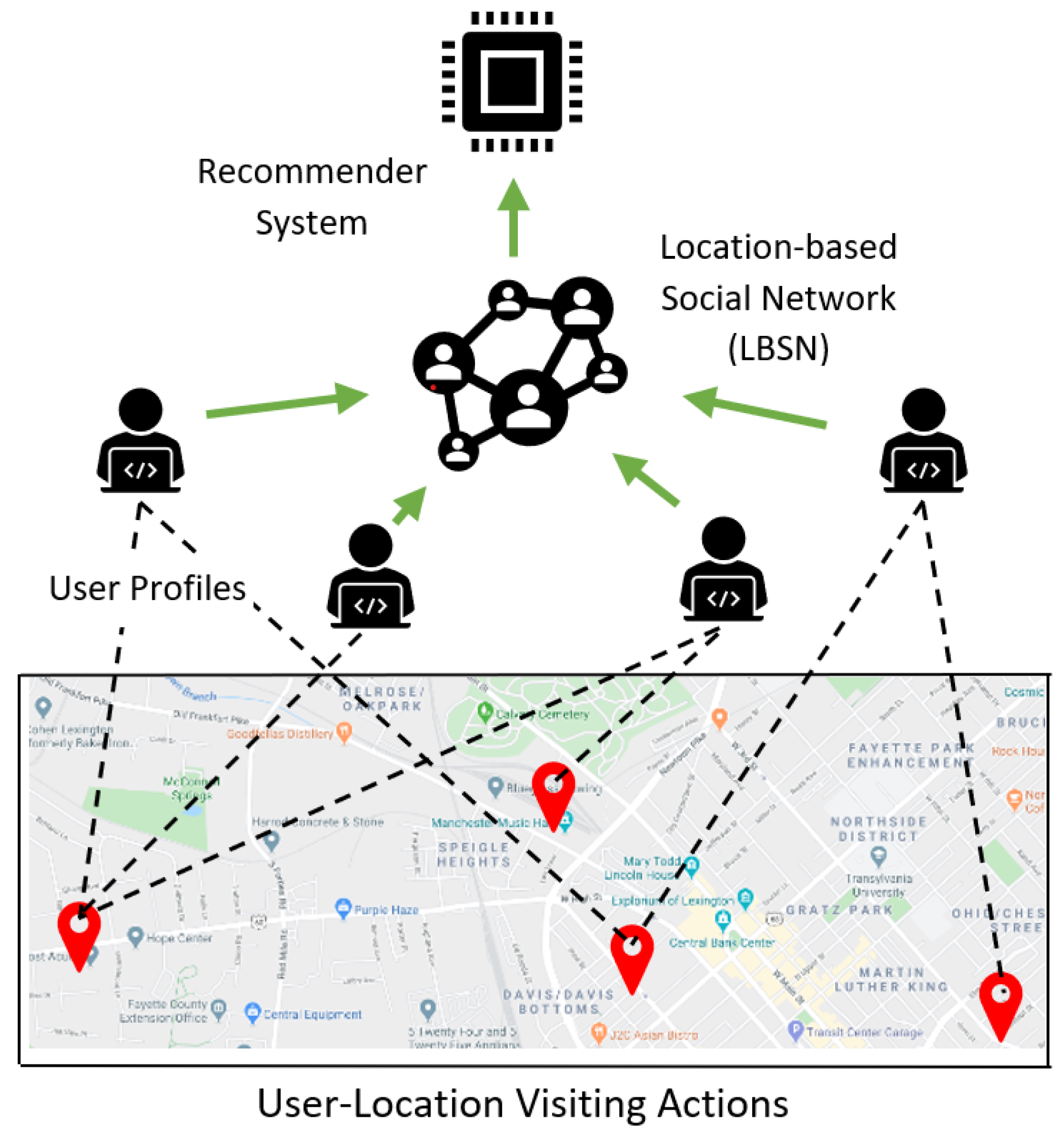
:1. Introduction
- We propose a cascade recommendation framework for POI recommendation, whereby sensitive user information is processed at different levels to accommodate the gradually unsecured environment. The multiple aggregator servers added to the model ease the extra computational privacy cost on the central server and user devices.
- We propose to sever the connection between contextual information such as text comments and user identity while keeping it serviceable. Our model collects and uses such information, but when the processed information is fed to the central server, the highly processed information cannot retrace the customers.
- We conduct experiments on real-world publicly available datasets, and the results demonstrate the effectiveness and a reasonable trade-off.
2. Related Work
2.1. Conventional Recommender Systems
2.2. Privacy-Preserving Recommender Systems
2.3. Clustering Method
2.4. User Comments and Word Embedding
3. Proposed Model and Methodology
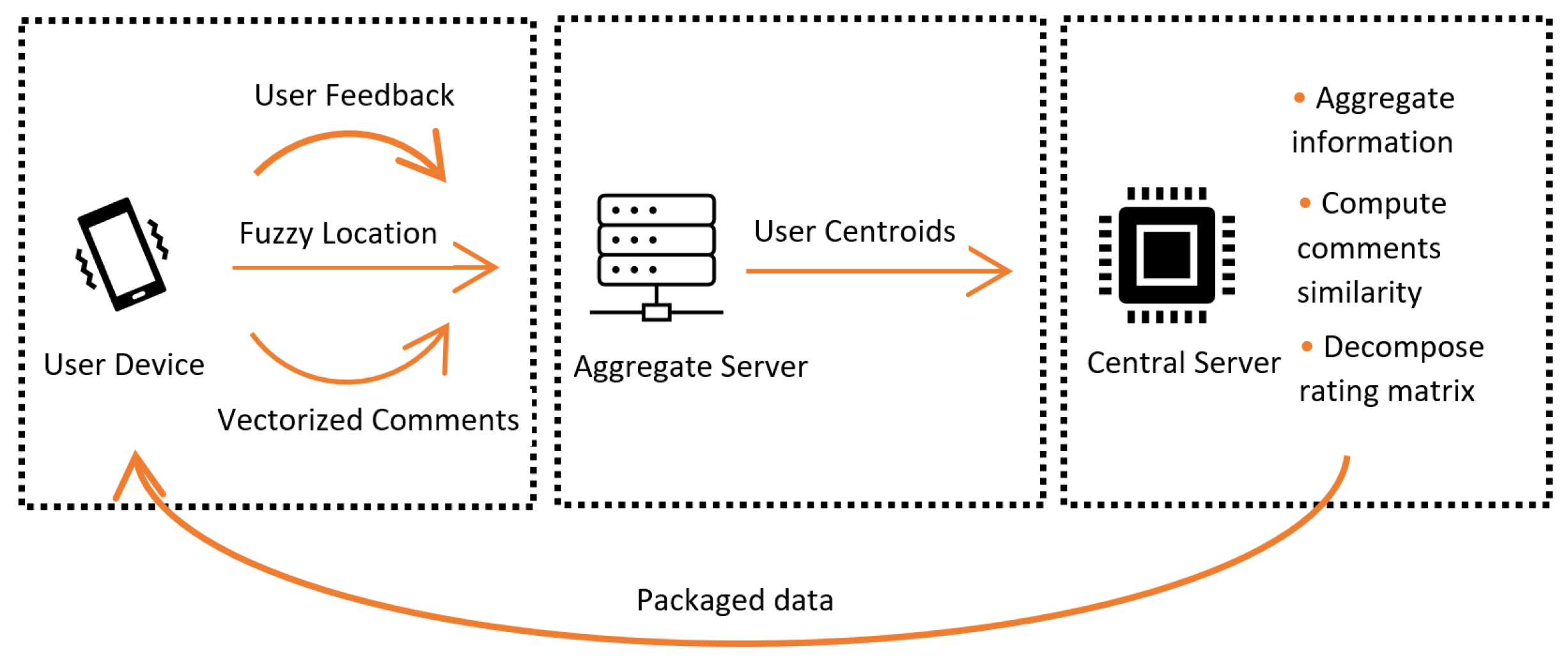
3.1. Overall Structure
3.2. Notations and Problem Definitions
3.3. Implementation
4. Datasets and Experiment Results
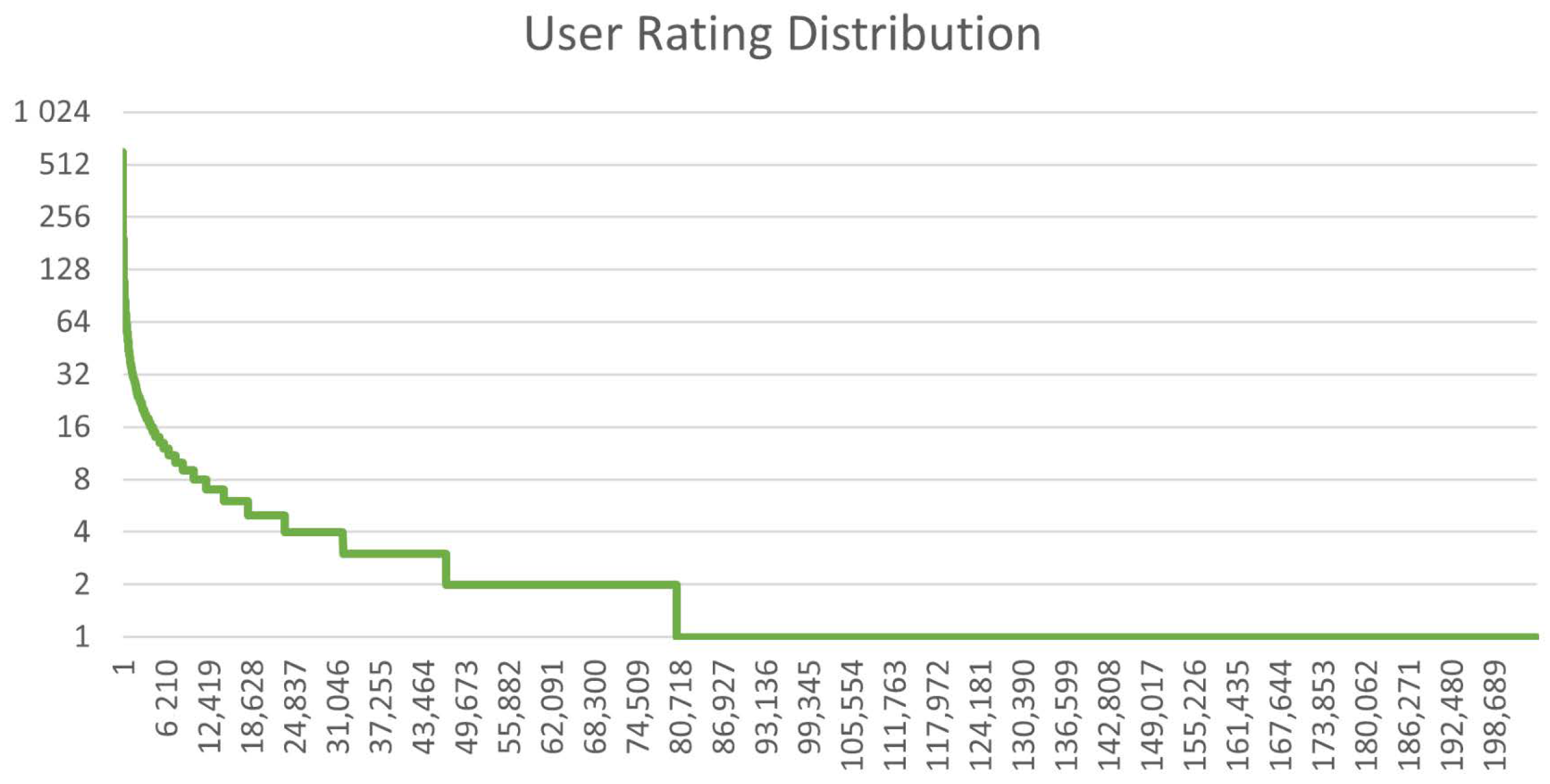
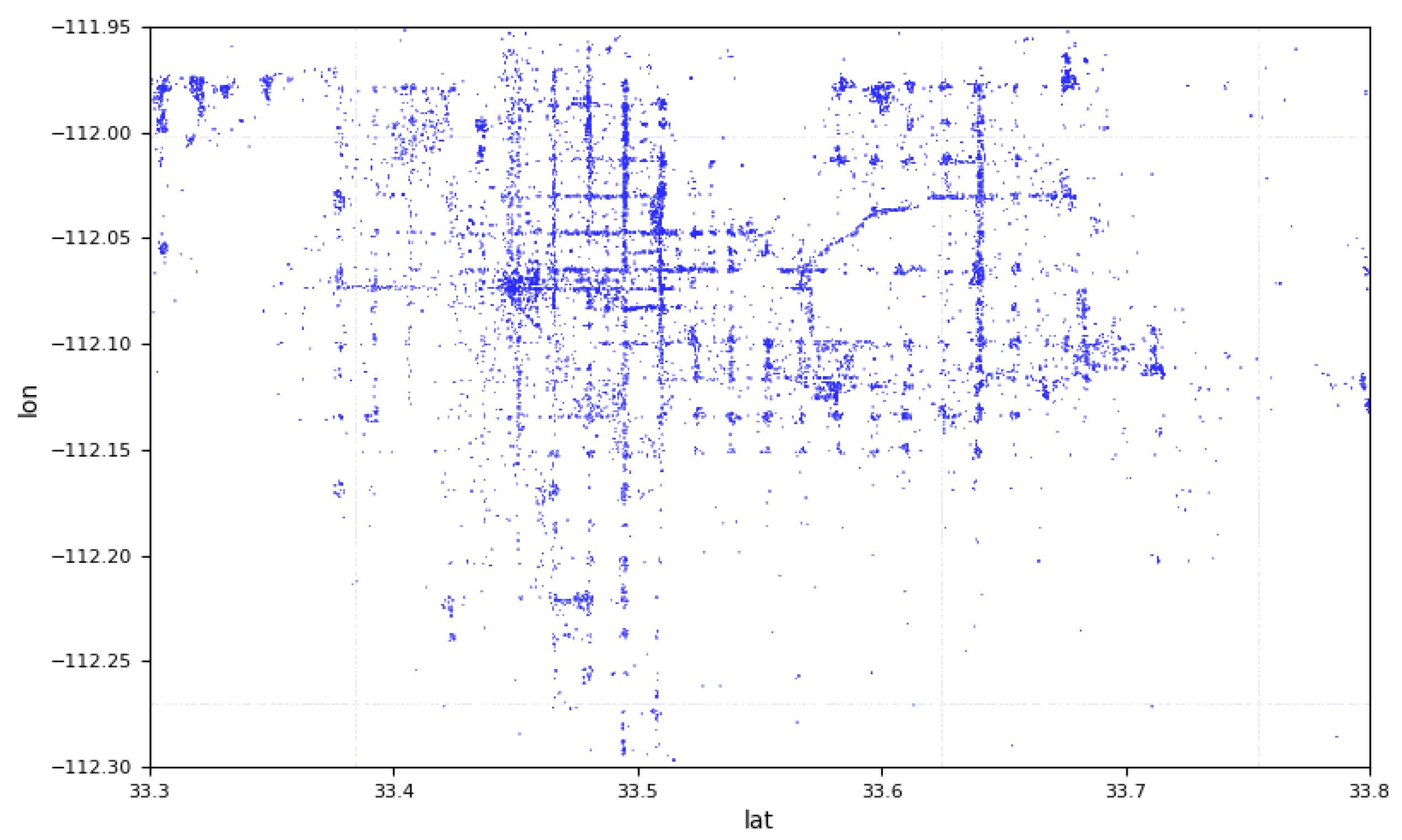
4.1. Datasets
4.2. Metrics and Evaluation Methods
| Algorithm 1: CRS Model Training/Testing Algorithm. |
 |
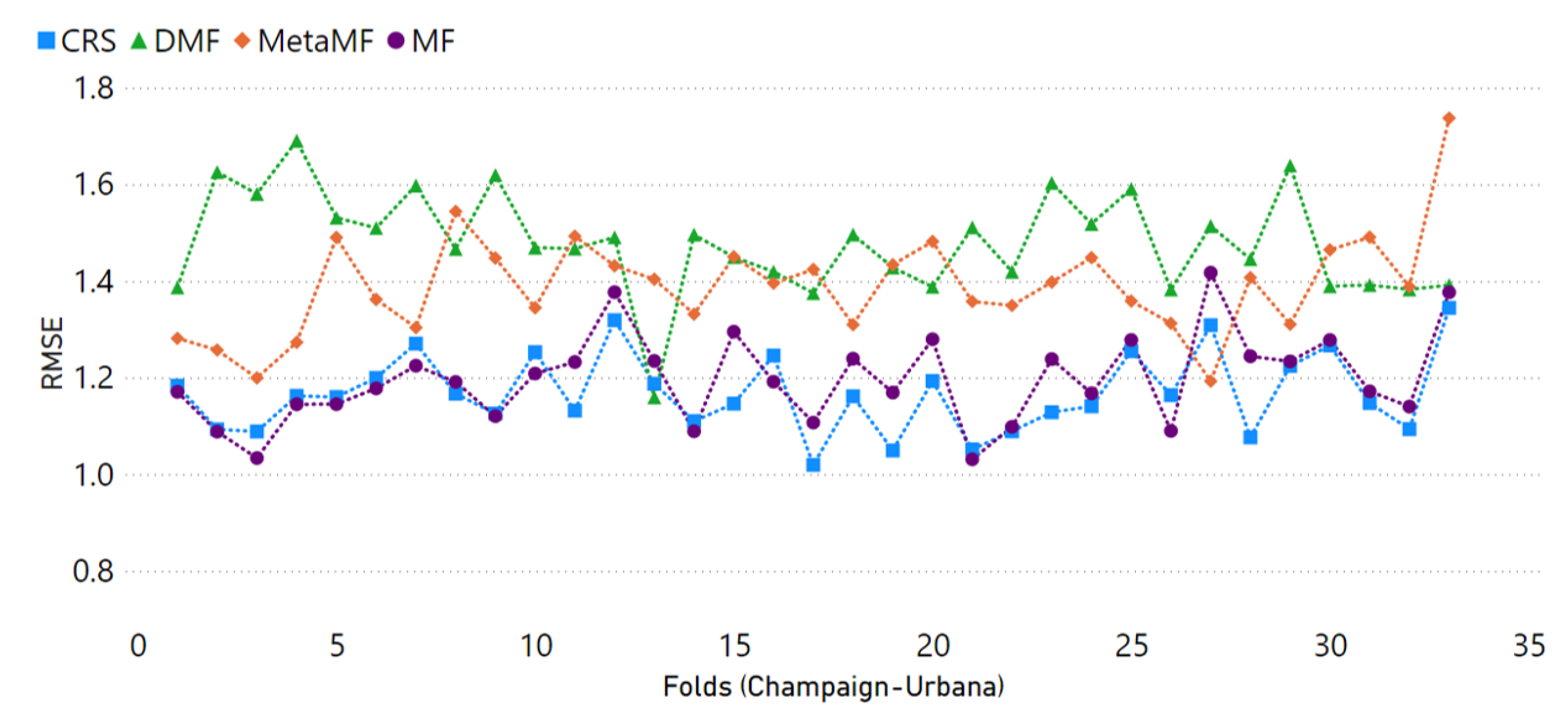
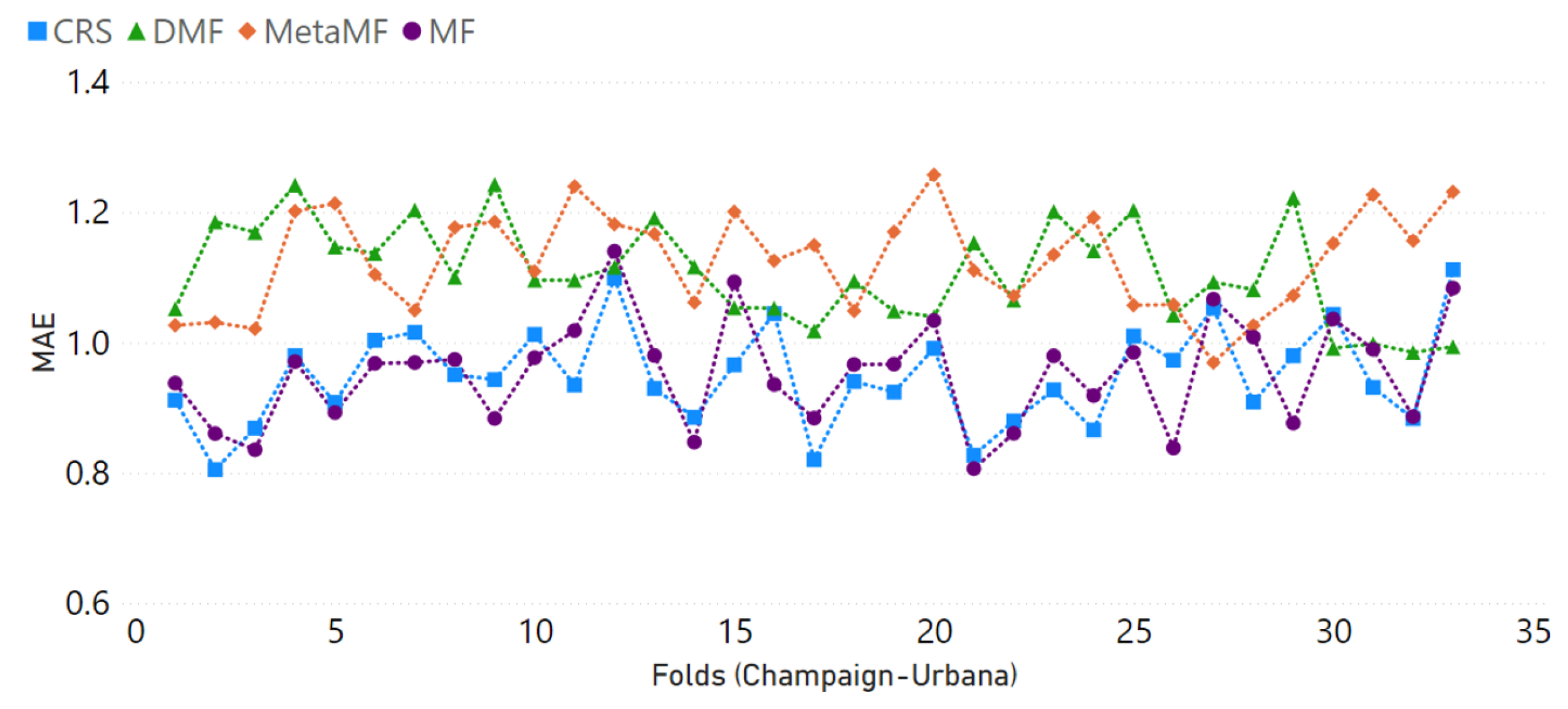
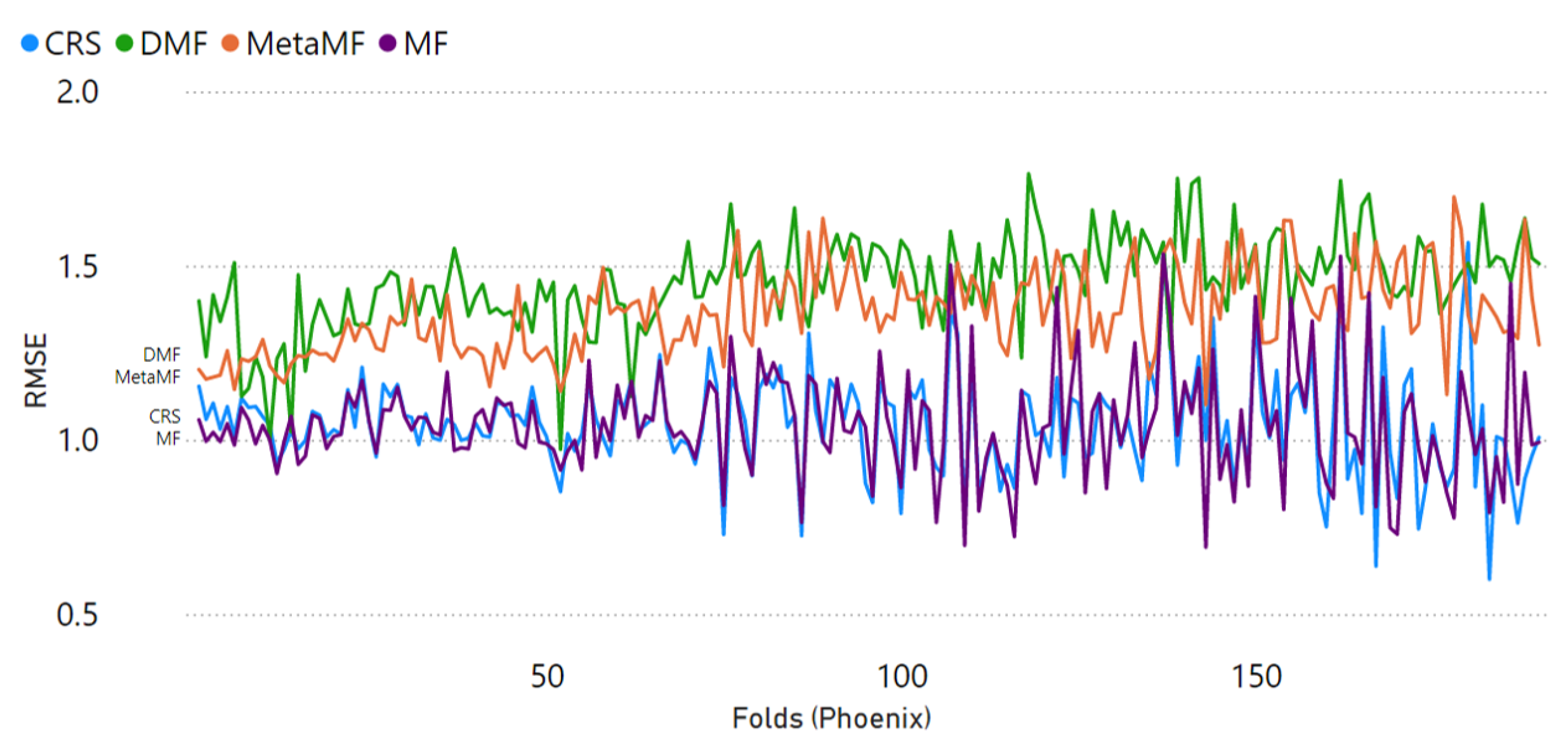
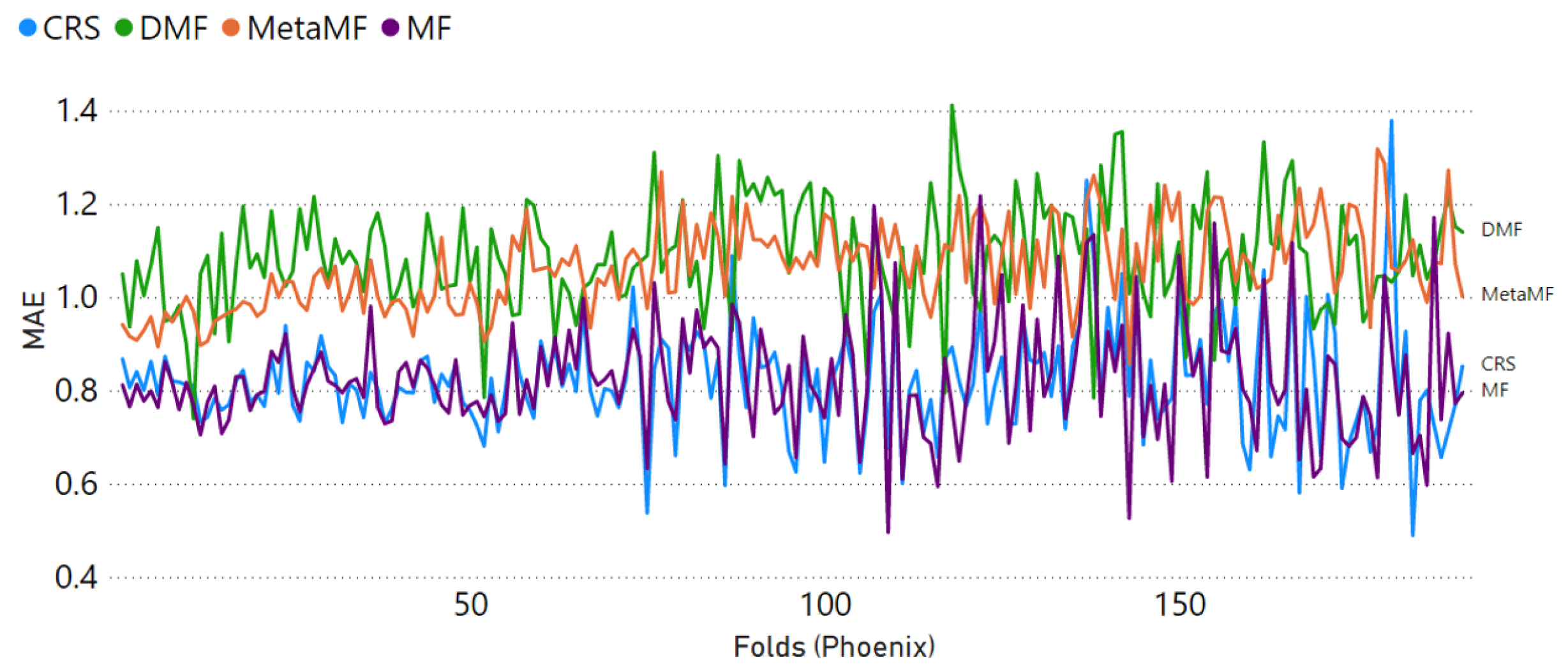
4.3. Results and Comparison
- We start by choosing the well-known biased matrix factorization (MF) [4] as the baseline model. It is a non-privacy centralized RS model with simple structures and reliable performance, and this model was thoroughly studied and constantly compared.
- The federated recommender system, MetaMF [23], has a distinct advantage in terms of privacy protection and providing exceptionally accurate predictions. Despite requiring a global model on a central server, this method distributes its training to multiple local devices, reducing the risk of leaking private user data.
- The decentralized recommender system (DMF) [8] is a purely distributed privacy-preserving recommender system that relies on matrix factorization and gradient exchange. Due to its distributive framework, the only leakage risk of data is the loss function’s gradient. Each user has a dynamic global and personal model combined, making the hacking even harder.
4.4. Parameters and Tuning
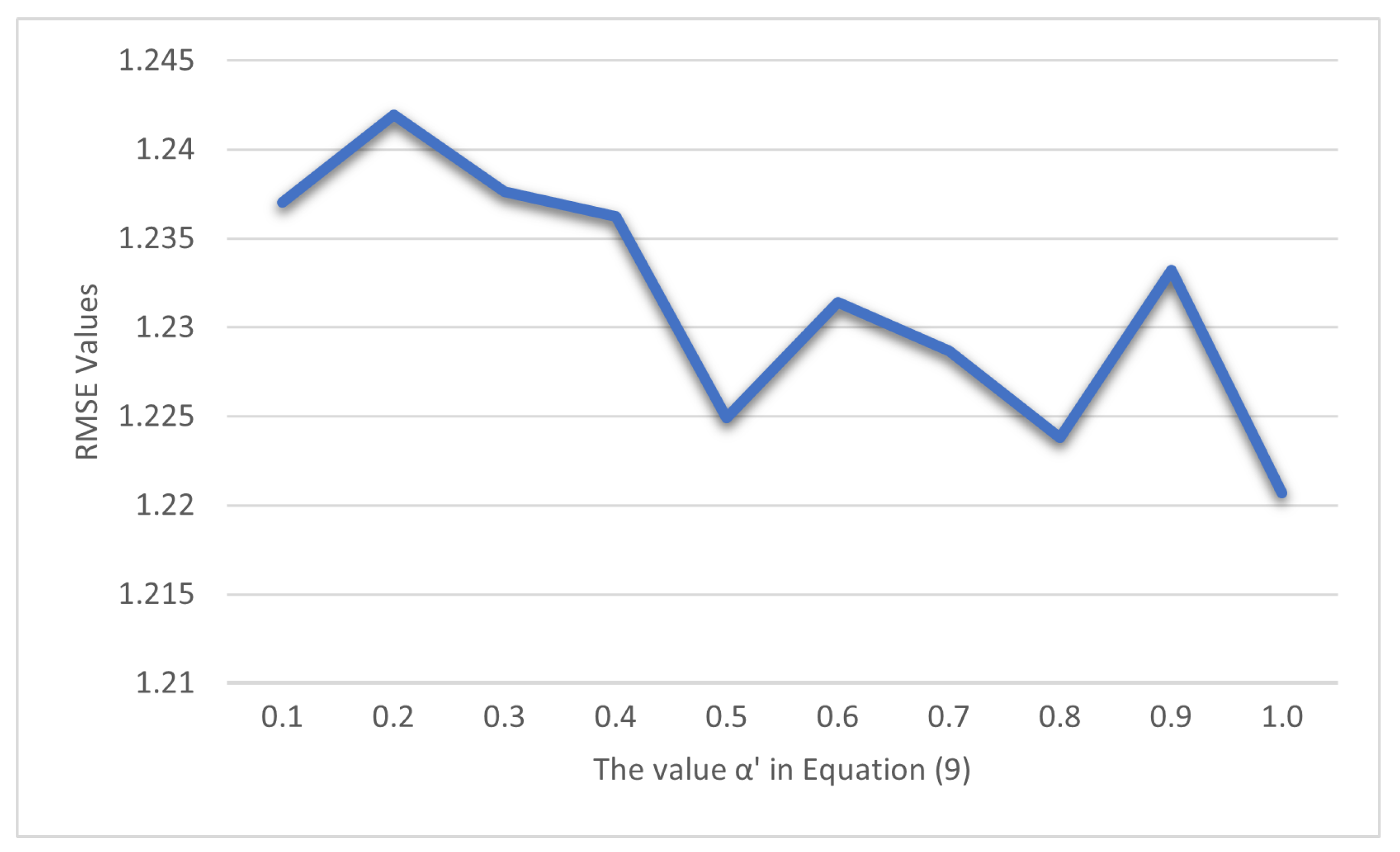
- During the aggregation stage, there are two crucial parameters. First, the performing of the clustering is based on the affinity matrix according to the Equation (9). In this equation, denotes the ratio or weight of either part in building the final affinity matrix. Second, the number of centroids, , is required due to the clustering method we chose.
- On the central server, we have the number of latent factors k, the global learning rate , and each specific learning rate and of each term from the loss function. We used to denote the number of epochs used in SGD for each training process.
- On users’ mobile devices, after users reconstruct the imputed rating matrix, they will compute their personalized predictions according to Equation (13). During our experiment, we found that not including all centroids yields more accurate results. Here, we use to denote the number of centroids involved.
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Voigt, P.; Von dem Bussche, A. The EU General Data Protection Regulation (GDPR); A Practical Guide; Springer International Publishing: Cham, Switzerland, 2017; Volume 10. [Google Scholar]
- Goldman, E. An introduction to the California consumer privacy act (CCPA). Santa Clara Univ. Legal Studies Research Paper. 2020. Available online: https://ssrn.com/abstract=3211013 (accessed on 1 September 2021).
- Determann, L.; Ruan, Z.J.; Gao, T.; Tam, J. China’s draft personal information protection law. J. Data Prot. Priv. 2021, 4, 235–259. [Google Scholar]
- Koren, Y.; Bell, R.; Volinsky, C. Matrix factorization techniques for recommender systems. Computer 2009, 42, 30–37. [Google Scholar] [CrossRef]
- Koren, Y. Collaborative filtering with temporal dynamics. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Paris, France, 28 June 2009–1 July 2009; pp. 447–456. [Google Scholar]
- Rendle, S. Factorization Machines. In Proceedings of the 2010 IEEE International Conference on Data Mining, Sydney, Australia, 13 December 2010; pp. 995–1000. [Google Scholar]
- Chen, C.; Zhang, M.; Liu, Y.; Ma, S. Neural attentional rating regression with review-level explanations. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018; pp. 1583–1592. [Google Scholar]
- Chen, C.; Liu, Z.; Zhao, P.; Zhou, J.; Li, X. Privacy preserving point-of-interest Recommendation using decentralized Matrix Factorization. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Wei, R.; Tian, H.; Shen, H. Improving k-anonymity based privacy preservation for collaborative filtering. Comput. Electr. Eng. 2018, 67, 509–519. [Google Scholar] [CrossRef]
- Wang, X.; Zhang, J.; Wang, Y. Trust-aware privacy-preserving recommender system. In Proceedings of the 9th EAI International Conference on Mobile Multimedia Communications, Xi’an, China, 18–20 June 2016; pp. 107–115. [Google Scholar]
- Wang, X.; Nguyen, M.; Carr, J.; Cui, L.; Lim, K. A group preference-based privacy-preserving POI recommender system. ICT Express 2020, 6, 204–208. [Google Scholar] [CrossRef]
- Lau, J.H.; Baldwin, T. An empirical evaluation of doc2vec with practical insights into document embedding generation. arXiv 2016, arXiv:1607.05368. [Google Scholar]
- Pazzani, M.J.; Billsus, D. Content-based recommendation systems. In The Adaptive Web; Springer: Berlin/Heidelberg, Germany, 2007; pp. 325–341. [Google Scholar]
- Herlocker, J.L.; Konstan, J.A.; Terveen, L.G.; Riedl, J.T. Evaluating collaborative filtering recommender systems. ACM Trans. Inf. Syst. 2004, 22, 5–53. [Google Scholar] [CrossRef]
- Agarwal, D.; Chen, B.C. Regression-based latent factor models. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Paris, France, 28 June 2009–1 July 2009; pp. 19–28. [Google Scholar]
- Rendle, S.; Freudenthaler, C.; Gantner, Z.; Schmidt-Thieme, L. BPR: Bayesian personalized ranking from implicit feedback. arXiv 2012, arXiv:1205.2618. [Google Scholar]
- Xue, H.J.; Dai, X.; Zhang, J.; Huang, S.; Chen, J. Deep matrix factorization models for recommender systems. In Proceedings of the 2017 International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017; Volume 17, pp. 3203–3209. [Google Scholar]
- Raza, S.; Ding, C. Progress in context-aware recommender systems—An overview. Comput. Sci. Rev. 2019, 31, 84–97. [Google Scholar] [CrossRef]
- Levandoski, J.J.; Sarwat, M.; Eldawy, A.; Mokbel, M.F. Lars: A location-aware recommender system. In Proceedings of the 2012 IEEE 28th International Conference on Data Engineering, Arlington, VA, USA, 1–5 April 2012; pp. 450–461. [Google Scholar]
- Camacho, L.A.G.; Alves-Souza, S.N. Social network data to alleviate cold-start in recommender system: A systematic review. Inf. Process. Manag. 2018, 54, 529–544. [Google Scholar] [CrossRef]
- Sojahrood, Z.B.; Taleai, M. A POI group recommendation method in location-based social networks based on user influence. Expert Syst. Appl. 2021, 171, 114593. [Google Scholar] [CrossRef]
- Chen, C.; Zhou, J.; Wu, B.; Fang, W.; Wang, L.; Qi, Y.; Zheng, X. Practical privacy preserving POI recommendation. ACM Trans. Intell. Syst. Technol. (TIST) 2020, 11, 1–20. [Google Scholar] [CrossRef]
- Lin, Y.; Ren, P.; Chen, Z.; Ren, Z.; Yu, D.; Ma, J.; Rijke, M.d.; Cheng, X. Meta matrix factorization for federated rating predictions. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Xi’an, China, 11–15 July 2020; pp. 981–990. [Google Scholar]
- Shokri, R.; Pedarsani, P.; Theodorakopoulos, G.; Hubaux, J.P. Preserving privacy in collaborative filtering through distributed aggregation of offline profiles. In Proceedings of the Third ACM Conference on Recommender Systems, New York, NY, USA, 23–25 October 2009; pp. 157–164. [Google Scholar]
- Shin, H.; Kim, S.; Shin, J.; Xiao, X. Privacy enhanced matrix factorization for recommendation with local differential privacy. IEEE Trans. Knowl. Data Eng. 2018, 30, 1770–1782. [Google Scholar] [CrossRef]
- Cui, L.; Wang, X.; Zhang, J. Vendor-Based Privacy-Preserving POI Recommendation Network. In Proceedings of the International Conference on Mobile Multimedia Communications, Online, 23–25 July 2021; pp. 477–490. [Google Scholar]
- Kikuchi, H.; Kizawa, H.; Tada, M. Privacy-preserving collaborative filtering schemes. In Proceedings of the 2009 International Conference on Availability, Reliability and Security, Fukuoka, Japan, 16–19 March 2009; pp. 911–916. [Google Scholar]
- Erkin, Z.; Beye, M.; Veugen, T.; Lagendijk, R. Privacy-preserving content-based recommendations through homomorphic encryption. In Proceedings of the Information Theory in the Benelux and The 2nd Joint WIC/IEEE Symposium on Information Theory and Signal Processing in the Benelux, Boekelo, The Netherlands, 24–25 May 2012; p. 71. [Google Scholar]
- Badsha, S.; Yi, X.; Khalil, I. A practical privacy-preserving recommender system. Data Sci. Eng. 2016, 1, 161–177. [Google Scholar] [CrossRef] [Green Version]
- Ravi, L.; Subramaniyaswamy, V.; Devarajan, M.; Ravichandran, K.; Arunkumar, S.; Indragandhi, V.; Vijayakumar, V. SECRECSY: A secure framework for enhanced privacy-preserving location recommendations in cloud environment. Wirel. Pers. Commun. 2019, 108, 1869–1907. [Google Scholar] [CrossRef]
- Ng, A.; Jordan, M.; Weiss, Y. On spectral clustering: Analysis and an algorithm. Adv. Neural Inf. Process. Syst. 2001, 14, 849–856. [Google Scholar]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the KDD, Portland, OR, USA, 2–4 August 1996; Volume 96, pp. 226–231. [Google Scholar]
- Bezdek, J.C.; Ehrlich, R.; Full, W. FCM: The fuzzy c-means clustering algorithm. Comput. Geosci. 1984, 10, 191–203. [Google Scholar] [CrossRef]
- Collobert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuoglu, K.; Kuksa, P. Natural language processing (almost) from scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- Zhang, Y.; Tan, Y.; Zhang, M.; Liu, Y.; Chua, T.S.; Ma, S. Catch the black sheep: Unified framework for shilling attack detection based on fraudulent action propagation. In Proceedings of the The Twenty-Fourth International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015. [Google Scholar]
- McAuley, J.; Leskovec, J. Hidden factors and hidden topics: Understanding rating dimensions with review text. In Proceedings of the 7th ACM International Conference on Recommender Systems, Hong Kong, China, 12–16 October 2013; pp. 165–172. [Google Scholar]
- Ling, G.; Lyu, M.R.; King, I. Ratings meet reviews, a combined approach to recommend. In Proceedings of the 8th ACM Conference on Recommender Systems, Foster City, CA, USA, 6–10 October 2014; pp. 105–112. [Google Scholar]
- Zhang, Y.; Lai, G.; Zhang, M.; Zhang, Y.; Liu, Y.; Ma, S. Explicit factor models for explainable Recommendation based on phrase-level sentiment analysis. In Proceedings of the 37th International ACM SIGIR Conference on Research & Development in Information Retrieval, New York, NY, USA, 6–11 July 2014; pp. 83–92. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A.; Bengio, Y. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Volume 1. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Yelp Dataset. Available online: https://www.yelp.com/dataset (accessed on 1 March 2020).
- Harper, F.M.; Konstan, J.A. The movielens datasets: History and context. ACM Trans. Interact. Intell. Syst. 2015, 5, 1–19. [Google Scholar] [CrossRef]
- Roman, R.C.; Precup, R.E.; Petriu, E.M. Hybrid data-driven fuzzy active disturbance rejection control for tower crane systems. Eur. J. Control 2021, 58, 373–387. [Google Scholar] [CrossRef]
- Zhu, Z.; Pan, Y.; Zhou, Q.; Lu, C. Event-triggered adaptive fuzzy control for stochastic nonlinear systems with unmeasured states and unknown backlash-like hysteresis. IEEE Trans. Fuzzy Syst. 2020, 29, 1273–1283. [Google Scholar] [CrossRef]
- Nogueira, F. Bayesian Optimization: Open Source Constrained Global Optimization Tool for Python. 2014. Available online: https://github.com/fmfn/BayesianOptimization (accessed on 1 October 2021).
- Snoek, J.; Larochelle, H.; Adams, R.P. Practical bayesian optimization of machine learning algorithms. Adv. Neural Inf. Process. Syst. 2012, 25, 2960–2968. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| User (centroid) set | |
| Item (POI) set | |
| Rating matrix | |
| r | Observed rating |
| Predicted rating | |
| The column vector representing the latent factors of user u | |
| The column vector representing the latent factors of item i | |
| User (centroid) bias | |
| Item (POI) bias | |
| Neighbor set of item i | |
| Loss function | |
| e | The error between the observed rating and predicted rating |
| Global learning rate | |
| Similarity between item (POI) i and item (POI) j | |
| Similarity matrix based on comments | |
| Similarity matrix based on ratings | |
| Similarity matrix based on locations | |
| The mean rating of all ratings from user a | |
| The estimated latitude of user u | |
| The estimated longitude of user u | |
| A real user (cannot be considered a centroid) | |
| The similarity vector between a real user and all centroids | |
| Training set | |
| Test set |
| Area | Users | POIs | Ratings | Density |
|---|---|---|---|---|
| Champaign-Urbana | 11,953 | 1579 | 33,990 | 0.1802% |
| Phoenix | 204,887 | 17,213 | 576,700 | 0.0163% |
| Champaign-Urbana | ||||
| Model Name | Biased MF | CRS | MetaMF | DMF |
| RMSE | 1.1966 | 1.1685 | 1.3942 | 1.4984 |
| MAE | 0.9537 | 0.9494 | 1.1268 | 1.2018 |
| Phoenix | ||||
| Model Name | Biased MF | CRS | MetaMF | DMF |
| RMSE | 1.0463 | 1.0482 | 1.3647 | 1.4534 |
| MAE | 0.8247 | 0.8235 | 1.0647 | 1.0872 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cui, L.; Wang, X. A Cascade Framework for Privacy-Preserving Point-of-Interest Recommender System. Electronics 2022, 11, 1153. https://doi.org/10.3390/electronics11071153
Cui L, Wang X. A Cascade Framework for Privacy-Preserving Point-of-Interest Recommender System. Electronics. 2022; 11(7):1153. https://doi.org/10.3390/electronics11071153
Chicago/Turabian StyleCui, Longyin, and Xiwei Wang. 2022. "A Cascade Framework for Privacy-Preserving Point-of-Interest Recommender System" Electronics 11, no. 7: 1153. https://doi.org/10.3390/electronics11071153