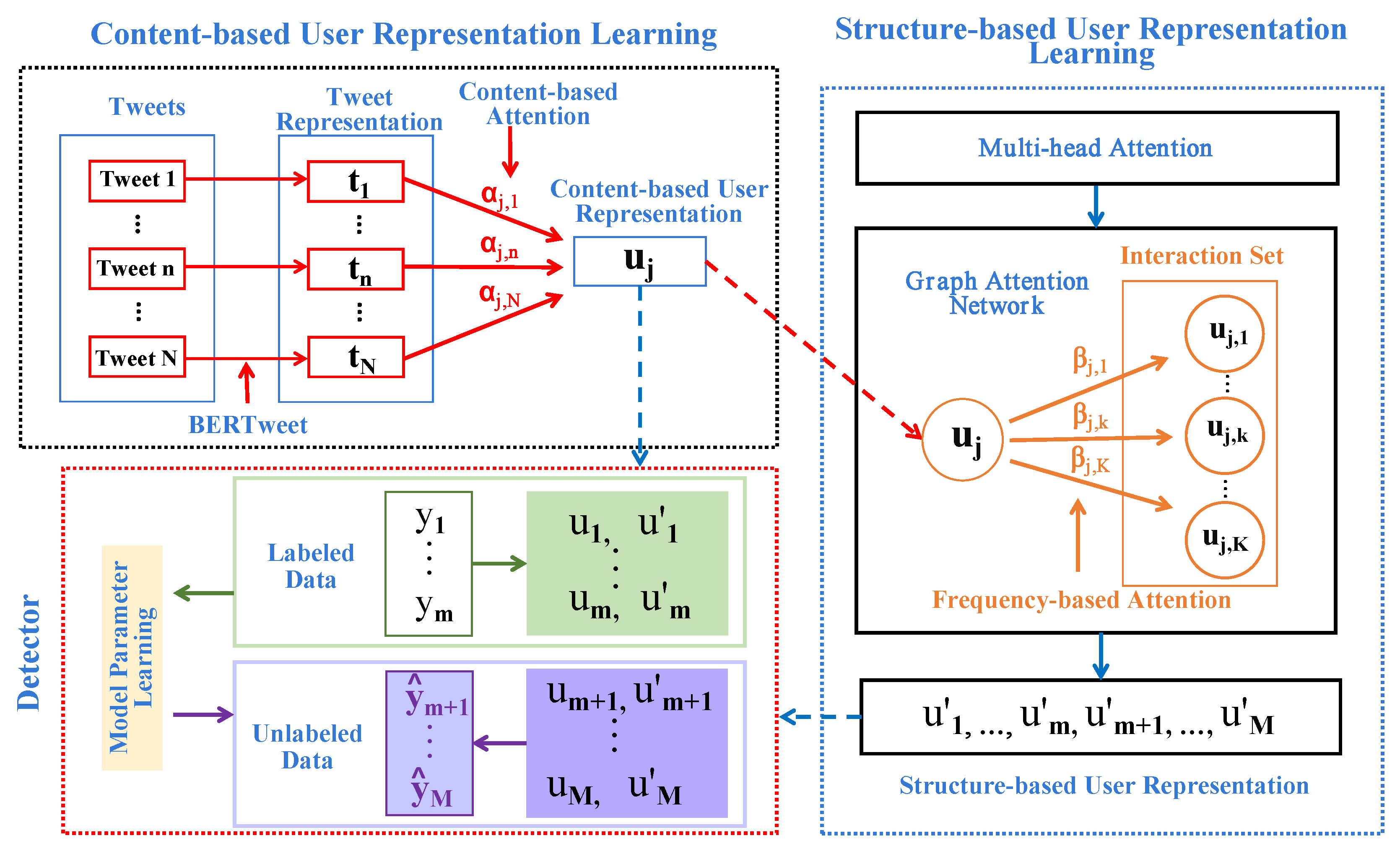
In this section, we first introduce the dataset used in this paper and then describe the overview of the proposed ASpamDetector, and the pretraining model BERTweet. Next, we introduce the proposed attention mechanism to learn content-based user representations and present the frequency-based graph attention network to learn structure-based user presentations. Finally, a detector is used to predict the label of each user.
3.1. Dataset
In this paper, we used a real-world Twitter dataset, which is constructed by two datasets, i.e., Twitter social honeypot dataset [
19] and the Kwak’s dataset [
20]. The Twitter social honeypot dataset provides the ground truth label for each user, and the Kwak’s dataset contains user tweets. When constructing the dataset, we first identified common users in these two datasets and then extracted their corresponding tweets. Finally, we filtered out non-English tweets. If the number of remaining tweets was larger than 1, then we kept the user; otherwise, we removed this user from the dataset.
After obtaining the Twitter dataset, we then extracted the interaction graph among these users. In particular, if a user,
, mentioned or retweeted the tweets of another user,
, then there exists a directed interaction link from
to
. We also counted the frequency of interactions from
to
, which is used in the proposed frequency-based graph attention network (fGAT) in
Section 3.4.
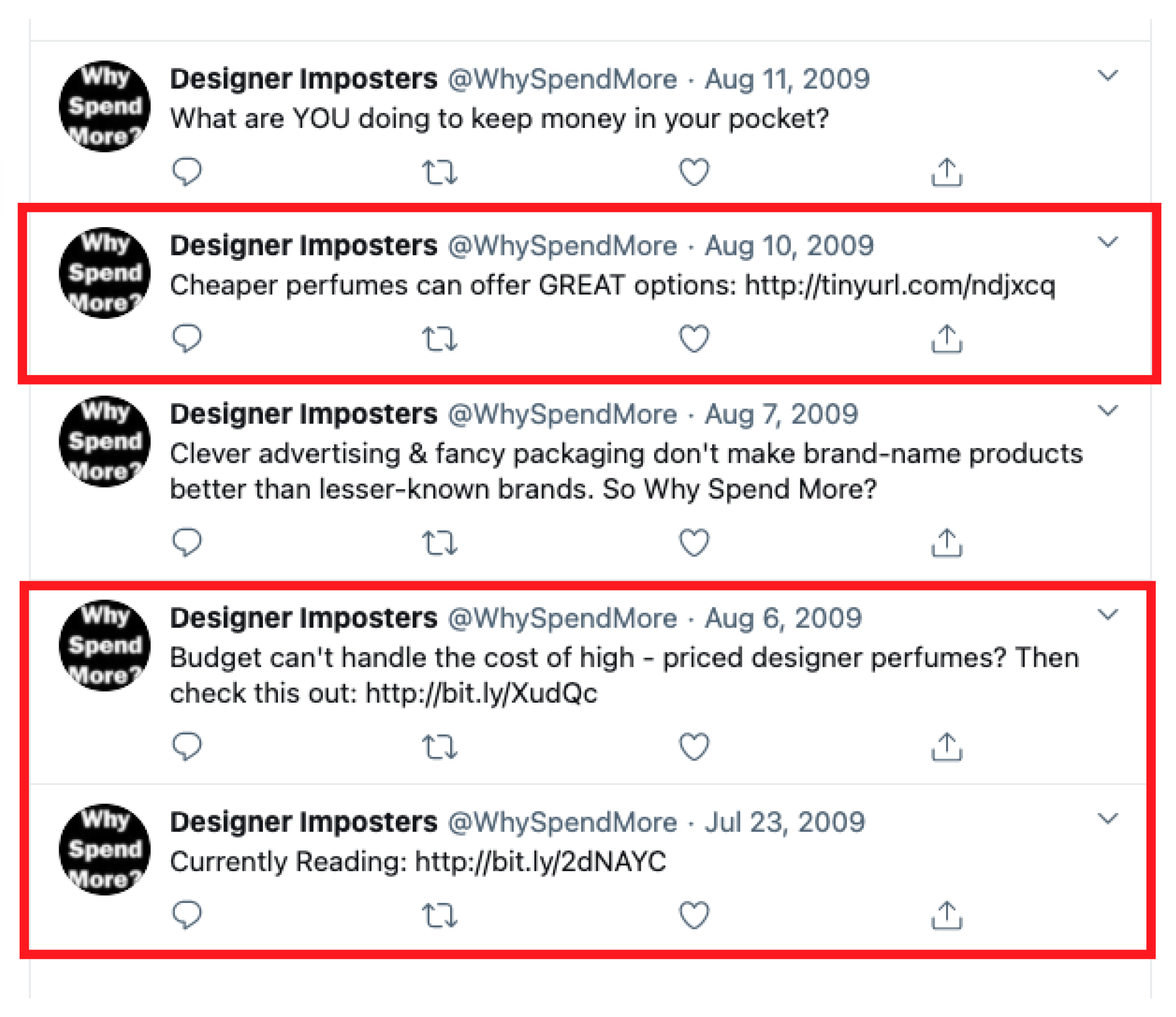
Next, we use an example to demonstrate the procedure of extracting the interaction graph.
Table 1 lists four tweets posted by two users. From the first tweet, we can extract a interaction link between
ChipotleTweets and
CashApp, and we denote the interaction frequency as 1. We ignore some tweets, such as the second tweet, since there is no interaction. From the third tweet, we can extract another interaction link from the user
NEFF303 to
ChipotleTweets. This user also retweeted the first tweet, then the interaction frequency between
NEFF303 and
ChipotleTweets is 2.
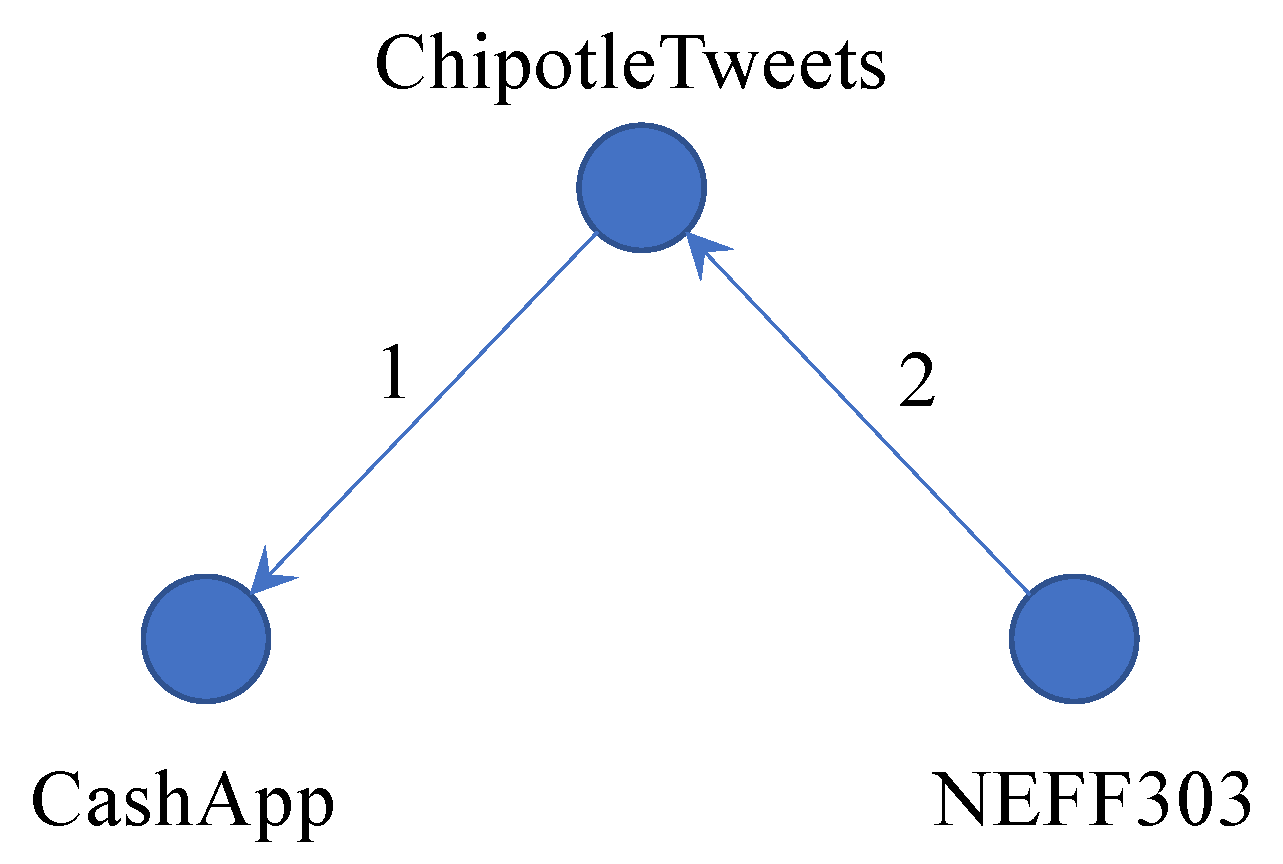
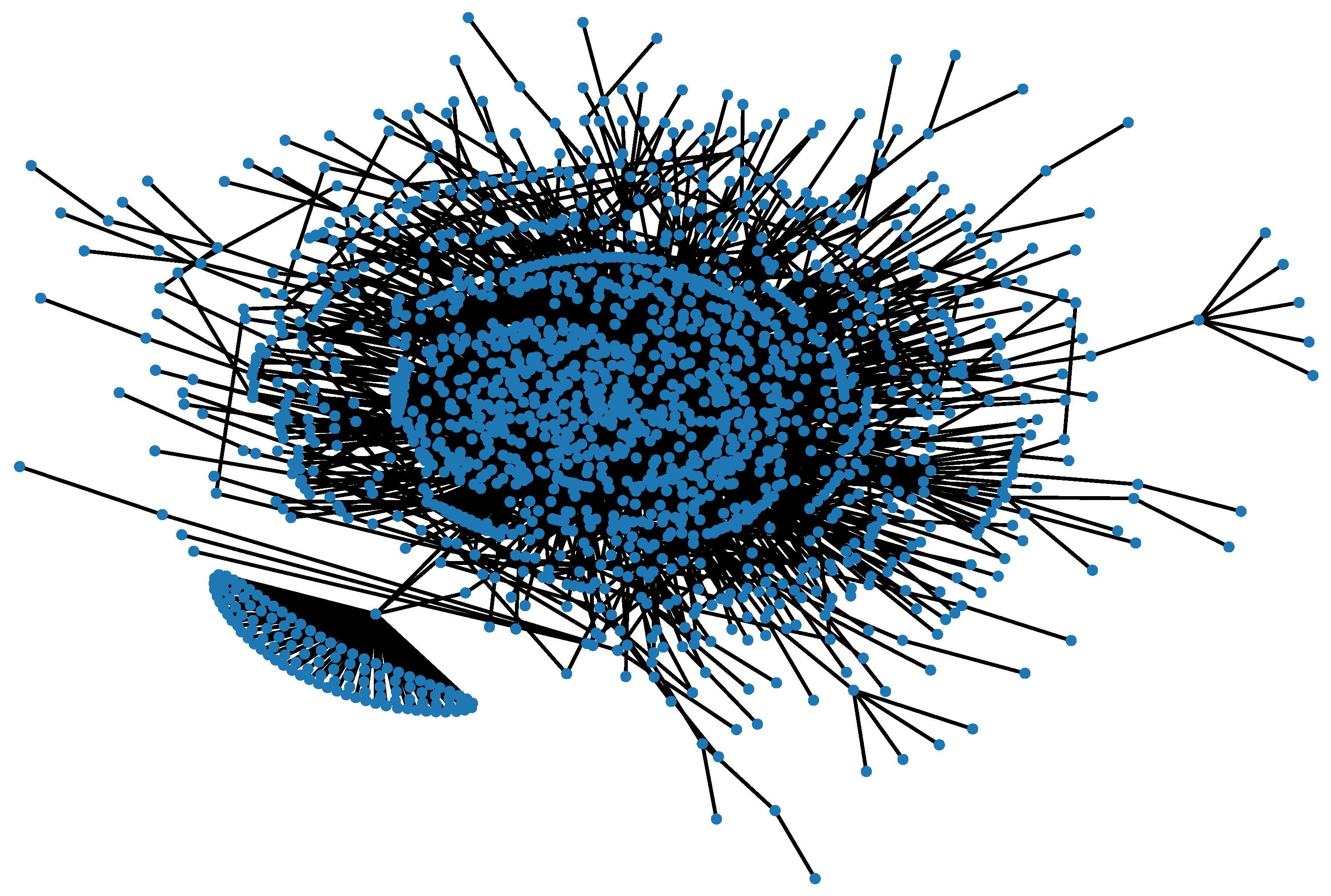
Figure 2 shows the interaction graph extracted from the example listed in
Table 1, and the graph visualization of the whole dataset is shown in
Figure 3.
3.4. Structure-Based User Representation Learning
Our previous work has shown the effectiveness of incorporating social interactions [
4]. However, it uses optimization-based techniques to model the social relations as a regularization term. Differently, in this paper, we propose the use of a more advanced technique to model social interactions, which is graph neural network [
24,
25]. However, it is challenging to directly apply state-of-the-art graph neural network models, such as graph convolutional networks (GCNs) [
26] and graph attention networks [
12].
Intuitively, spammers aim to mimic the behaviors of legitimate users, and they will frequently post tweets, mention other users, and retweet posts published by others, especially legitimate and verified users who have a huge number of followers. However, legitimate users seldom mention spammers and retweet their posts. Moreover, spammers collude with their accomplices to construct the criminal communities for hiding themselves, and many legitimate users may follow spammers out of courtesy [
27]. In our dataset, about 7% of legitimate users (217 among 3012) follow spammers back. Thus, the social interactions are asymmetric in Twitter, which motives us to consider the direction of interaction relation between a pair of users.
In addition, the frequency of interactions between a pair of users also influences the user representation learning. In general, one user, , mentions an other user, , multiple times, or retweets their tweets frequently, which indicates that user ’s behaviors are significantly influenced by those of user . Thus, when ASpamDetector learns the representation of user , it is reasonable to assign a larger weight to user .
Based on these motivations, we propose a new frequency-based graph attention network (fGAT), which takes interaction frequency into consideration when learning the attention weight between a pair of users who have social interactions. In particular, let represent the set of users that are mentioned by user or whose tweets are retweeted by user , where the size of directly interacted or first-order neighbors is K. Note that . We then follow the graph attention network to learn attention weight for each neighbor. However, we also consider the interaction frequency between them. Let denote the frequency vector, where and is the relative frequency, by normalizing the natural logarithm of the real frequency.
fGAT first maps the content-based user representations
and
to latent representations as follows:
where
is the parameter, and
is the content-based neighbor user representation learned by Equation (3). To incorporate the social interaction into the proposed model, we then learn the attention coefficient using the structural information by concatenating the two latent representations using Equation (
4) as follows:
where
is the parameter, and
denotes the concatenation operation. After obtaining the attention coefficients, we need to normalize them by applying the LeakyReLU nonlinearity (with negative input slope as 0.2), as follows:
The proposed fGAT considers not only the learned attention coefficient but also the interaction frequency to update user representations. Then, we propose to calibrate the learned attention weights using the relative frequency
, as follows:
Based on the frequency-based attention weights, we can obtain the structure-based user representation, as follows:
where
is the nonlinear function, and we use sigmoid in this paper.
Note that, following [
12], we also use multi-head attention mechanism [
28] to boost the learning of structure-based user representations. Specifically,
P-independent attention mechanisms execute the transformation of Equation (
8), and then their features are concatenated, resulting in the following output feature representation:
Since the concatenation operation for the final (prediction) layer is not sensible, we then average all the representations as follows:
3.5. Social Spam Detector
The outputs from the proposed fGAT are the structure-based user representations
, where
M is the total number of users, and
m denotes the number of labeled users. For each user, we can predict a label distribution, as follows:
where
,
,
,
,
, and
are parameters. Note that, in the prediction stage, we use both the learned content-based user representation,
, and the structure-based user representation,
, by mapping them to the same space first and then concatenating them together. Finally, a softmax function is used upon the nonlinear transformation to learn the label distribution
.
In the model parameter learning, we only calculate the cross entropy (CE) loss on the training data, as follows:
where
(
) is the one-hot ground truth vector. After training all the data, we can directly estimate the labels for unlabeled data,
, based on the learned
.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




