
Less Is More: Robust and Novel Features for Malicious Domain Detection


Abstract
:1. Introduction
2. Related Work
3. Methodology
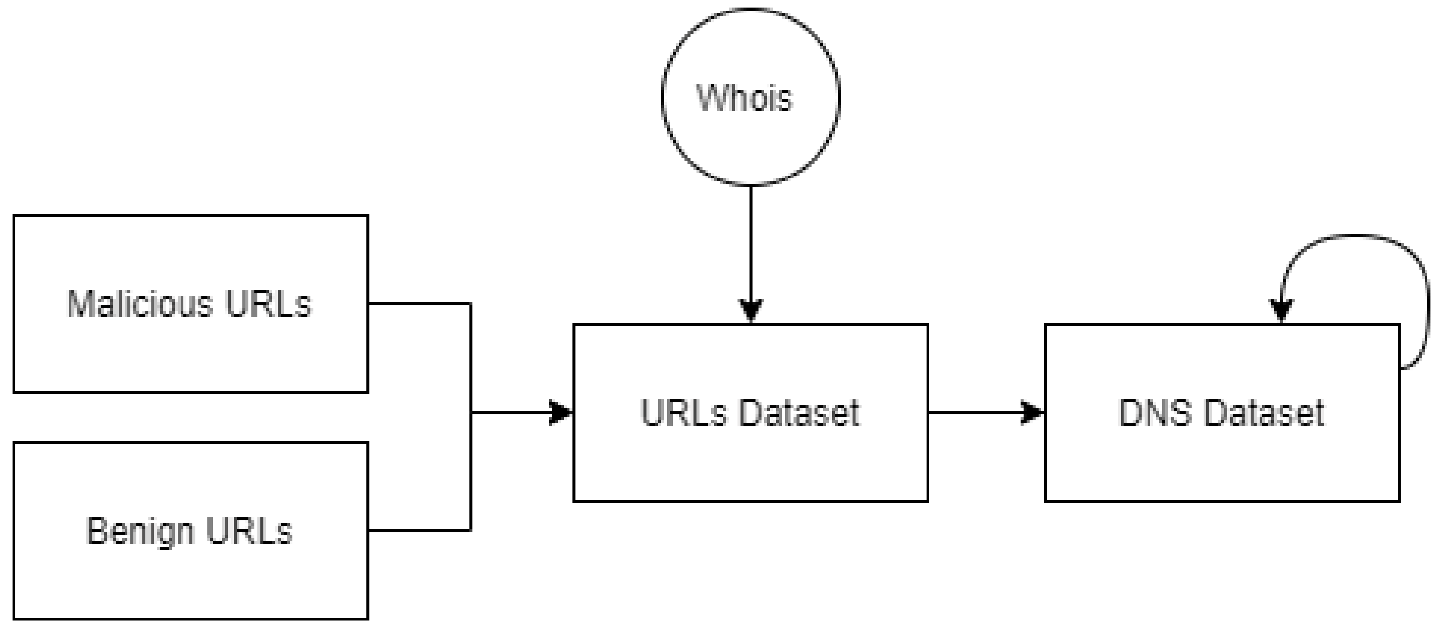
3.1. Data Collection
3.2. Evaluation Metrics
3.3. Feature Engineering
- Length of domain: The length of a domain is calculated by the domain name followed by the TLD (gTLD or ccTLD). Hence, the minimum length of a domain is four since the domain name needs to be at least one character (most domain names have at least three characters), and the TLD (gTLD or ccTLD) is composed of at least three characters (including the dot character) as well. For example, for the URL http://www.ariel-cyber.co.il; accessed on 20 March 2022, the length of the domain is 17 (the number of characters for the domain name—”ariel-cyber.co.il”).
- Number of consecutive characters: This is the maximum number of consecutive repeated characters in the domain. This includes the domain name and the TLD (gTLD or ccTLD). For example, for the domain “caabbbccccd.com” the maximum number of consecutive repeated characters value is 4, due to the four consecutive “c” characters.
- Entropy of the domain: The entropy of a domain is defined as: , where each consists of distinct characters . For example, for the domain “google.com”, the entropy is The domain has 5 characters that appear once (“l”, “e”, “.”, “c”, and “m”), one character that appears twice (“g”) and one character that appears three times (“o”).
- Number of IP addresses: This is the number of distinct IP addresses in the domain’s DNS record. For example, for the list [“1.1.1.1”, “1.1.1.1”, and ”2.2.2.2”], the number of distinct IP addresses is 2.
- Distinct geo-locations of the IP addresses: For each IP address in the DNS record, the countries for each IP were listed and the number of different countries was counted. For example, for the list of IP addresses [“1.1.1.1”, “1.1.1.1”, and ”2.2.2.2”] the list of countries is [“Australia”, “Australia”, and “France”] and the number of distinct countries is 2. Note that this feature relates to the number of different countries and not the country itself.
- Mean TTL value: For all the DNS records of the domain in the DNS dataset, the TTL values were averaged. For example, if a domain’s DNS records were checked 30 times, and in 20 of them the TTL value was “60” and in 10 the TTL value was “1200”, the mean is .
- Standard deviation of the TTL: The standard deviations of the TTL values for all the DNS records of the domain in the DNS dataset were calculated. For the “Mean TTL value” example above, the standard deviation of the TTL values is .
- Lifetime of domain: This is the interval between a domain’s expiration date and creation date in years. For example, the domain “ariel-cyber.co.il”, according to Whois information, which was updated on 4 June 2018, was created on 14 May 2015 and expires on 14 May 2022. Therefore, the lifetime of the domain is the number of years from 14 May 2015 to 14 May 2022, i.e., 8.
- Active time of domain: Similar to the lifetime of a domain, the active time of a domain is calculated as the interval between a domain’s updated date and creation date in years. Using the same example as in the “Lifetime of domain”, the active time of the “ariel-cyber.co.il” domain is the number of years between 14 May 2015 and 14 May 2021, i.e., 6.
3.4. Robust Feature Selection
- 1.
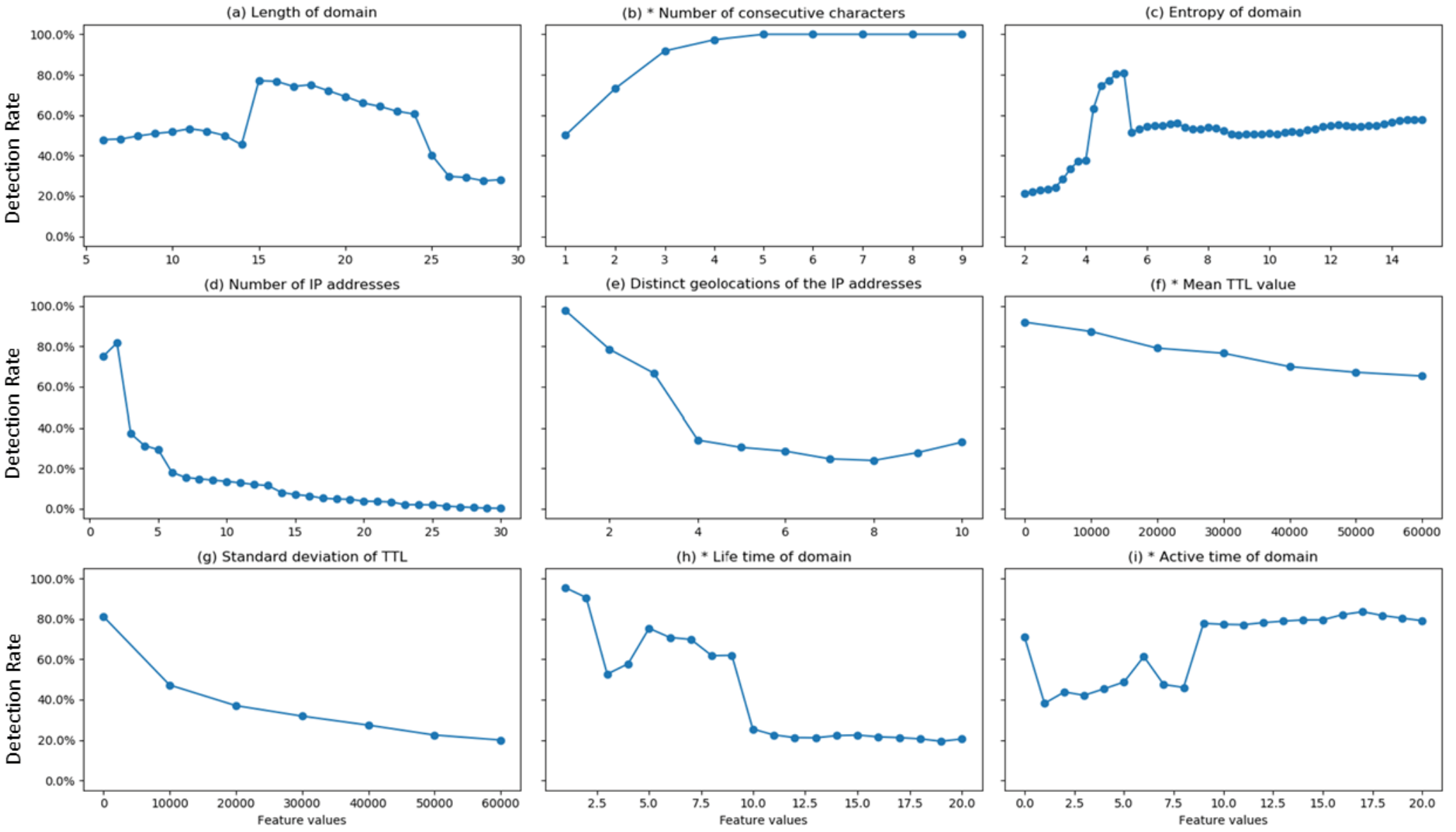
- “Length of domain”: an adversary can easily purchase a short or long domain to result in a benign classification for a malicious domain; hence, this feature was classified as non-robust.
- 2.
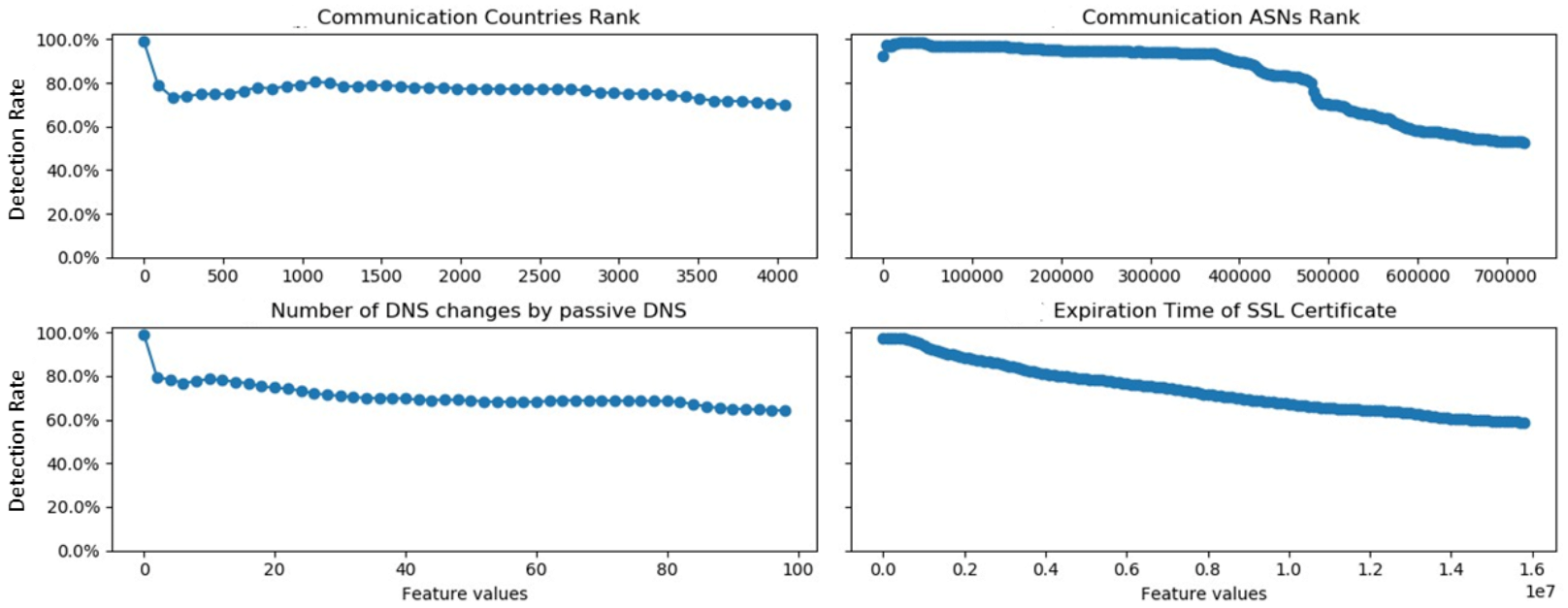
- “Number of consecutive characters”: as depicted in Figure 3, manipulating the “Number of consecutive characters” feature can significantly lower the prediction percentage (e.g., move from three consecutive characters to one or two). Still, as depicted in Table 2, on average, there were 1.46 consecutive characters in malicious domains (with a low standard deviation). Therefore, as this feature’s minimal value is 1, it is considered to be a robust feature.
- 3.
- “Entropy of the domain”: in order to manipulate the “Entropy of the domain” feature as a benign domain entropy, the adversary can create a domain name with an entropy of less than 4. For example, the domain “ddcd.cc” is available for purchase. The entropy for this domain is . This value falls precisely in the entropy area of the benign domains defined by the trained model. This example breaks the model and causes a malicious domain to look like a benign URL. Hence, this feature was classified as non-robust.
- 4.
- “Number of IP addresses”: note that an adversary can add many A records to the DNS zone file of its domain to imitate a benign domain. Thus, to manipulate the number of IP addresses, an intelligent adversary only needs to have several different IP addresses and add them to the zone file. This fact causes this feature to be classified as non-robust.
- 5.
- “Distinct Geo-locations of the IP addresses”: in order to be able to circumvent the model with the “Distinct Geolocations of the IP addresses” feature, the adversary needs to use several IP addresses from different geo-locations. Suppose the adversary can determine how many different countries are sufficient to mimic the number of distinct countries of benign domains. In that case, he will be able to append this number of IP addresses (a different IP address from each geo-location) in the DNS zone file. Moreover, because this feature counts the number of the countries, the attacker can choose a set of countries to meet the desired number. Thus, this feature was also classified as non-robust (this assumption gave us the motivation for one of our novel features which is based on the rank of the countries and not only the number of the countries).
- 6.
- “Mean TTL value” and “Standard deviation of the TTL”: there is a clear correlation between the “Mean TTL value” and the “Standard deviation of the TTL” features since the value manipulated by the adversary is the TTL itself. Thus, it makes no difference if the adversary cannot manipulate the “Mean TTL value” feature if the model uses both. In order to robustify the model, it is better to use the “Mean TTL value” feature without the “Standard deviation of the TTL”. Solely in terms of the “Mean TTL value” feature, Figure 3 shows that manipulation will not result in a false classification since the prediction percentage does not drop dramatically, even when this feature is drastically manipulated. Therefore, this feature (“Mean TTL value”) is considered to be robust.An adversary can set the DNS TTL values to [0,120,000] (according to the RFC 2181 [71] the TTL value range is from 0 to ). Figure 3 shows that even manipulating the value of this feature to 60,000 will deceive the model and cause a malicious domain to be wrongly classified as a benign URL. Therefore, the “Standard deviation of the TTL” is considered a non-robust feature.
- 7.
- “Lifetime of domain”: As for the lifetime of domains, based on Shi et al. [23], we know that a benign domain’s lifetime is typically much longer than a malicious domain’s lifetime. In order to deceive the model by manipulating the “Lifetime of domain” feature, the adversary must buy an old domain that is available on the market. Even though it is possible to buy an appropriate domain, it is expensive (if feasible). Hence, we considered this to be a robust feature.
- 8.
- “Active time of domain”: Similar to the previous feature, in order to overcome the “Active time of domain” feature, an adversary has to find a domain with a particular active time, which is much more tricky. It is complex, expensive, and perhaps unfeasible. Therefore we considered it to be a robust feature.
3.5. Novel Features
- Communication Countries Rank (CCR): This feature looks at the communication countries with respect to the communication IPs, and uses the countries ratio table to rank a specific URL. The motivation is to gain a broader perspective.
- Communication ASNs Rank (CAR): Similarly, this feature analyzes the communication ASNs with respect to the communication IPs, and uses the ASNs ratio table to rank a specific URL. While there is some correlation between the ASNs and the countries, the second feature examines each Autonomous System (AS) within each country to gain a broader perspective.
- Number of passive DNS changes: When inspecting the passive DNS records, benign domains emerged as having much more significant DNS changes that the sensors (of the company that collects the DNS records) could identify, unlike malicious domains (i.e., 26.4 vs. 8.01, as reported in Table 3). The number of DNS record changes was counted for the “Number of passive DNS changes”, which is somewhat similar to other features described in other works [11,25]. Nonetheless, these features require much more elaborated information, which is not publicly available. On the other hand, this feature can be extracted from passive DNS records obtained from VirusTotal, which are scarce (in terms of record types).
- Expiration time of SSL certificate: When installing an SSL certificate, a Certificate Authority (CA) conducts a validation process. Depending on the type of certificate, the CA verifies the organization’s identity before issuing the certificate. When analyzing our data, it was noted that most malicious domains do not use valid SSL certificates and those that only use one for a short period. Therefore, this feature was engineered in order to represent the time the SSL certificate remains valid. The “Expiration time of SSL certificate”, in contrast to the binary feature version used by Ranganayakulu et al. [69], extends the scope and represents both the existence of an SSL certificate and the remaining time until the SSL certificate expires.
| Algorithm 1 Communication Rank |
Input: URL, Threshold, Type Output: Rank (CCR or CAR)
|
4. Empirical Analysis and Evaluation
4.1. Experimental Design
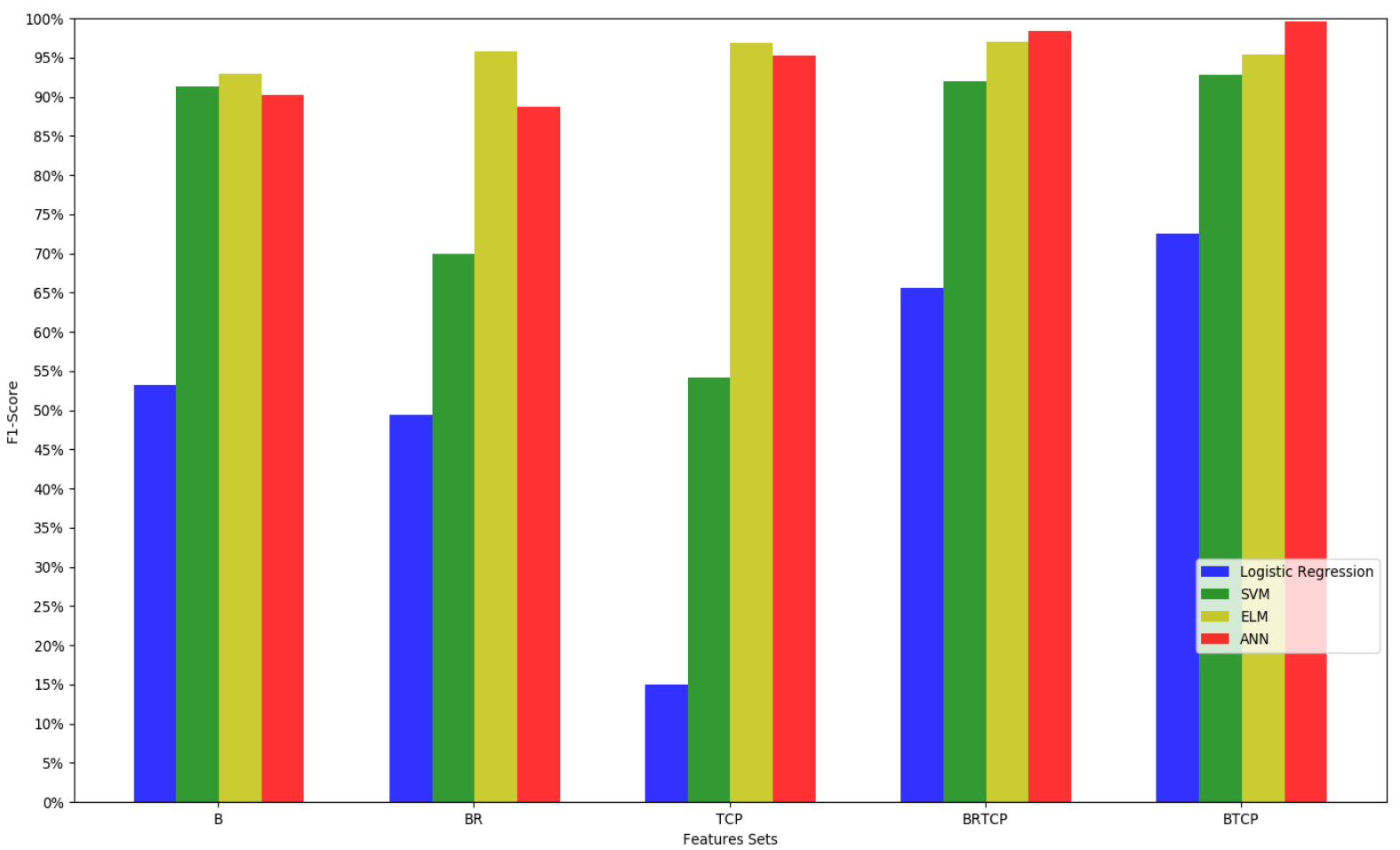
- Base (B)—the set of commonly used features in previous works (see Table 2 for more details).
- Base Robust (BR)—the subset of robust base features (marked with a * in Figure 3).
- “TCP” (TCP)—the four novel features: Time of SSL certificate, Communication ranks (CCR and CAR) and PassiveDNS changes (see Table 3).
- Base Robust + “TCP” (BRTCP)—the combination (union) of BR and TCP, the robust subset of all features.
- Base + “TCP” (BTCP)—the union of B and TCP.
4.2. Experimental Results
4.2.1. Logistic Regression
4.2.2. Support Vector Machine (SVM)
4.2.3. ELM
4.2.4. ANN
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Vincent, N.E.; Pinsker, R. IT risk management: Interrelationships based on strategy implementation. Int. J. Account. Inf. Manag. 2020, 28, 553–575. [Google Scholar] [CrossRef]
- Blum, A.; Wardman, B.; Solorio, T.; Warner, G. Lexical feature based phishing URL detection using online learning. In Proceedings of the Workshop on Artificial Intelligence and Security, Krakow, Poland, 15–18 February 2010; pp. 54–60. [Google Scholar]
- Khonji, M.; Iraqi, Y.; Jones, A. Phishing detection: A literature survey. IEEE Commun. Surv. Tutor. 2013, 15, 2091–2121. [Google Scholar] [CrossRef]
- Le, A.; Markopoulou, A.; Faloutsos, M. Phishdef: Url Names Say It All. In Proceedings of the 2011 IEEE INFOCOM, Shanghai, China, 10–15 April 2011; pp. 191–195. [Google Scholar]
- Prakash, P.; Kumar, M.; Kompella, R.R.; Gupta, M. Phishnet: Predictive Blacklisting to Detect Phishing Attacks. In Proceedings of the 2010 IEEE INFOCOM, San Diego, CA, USA, 14–19 March 2010; pp. 1–5. [Google Scholar]
- Sheng, S.; Wardman, B.; Warner, G.; Cranor, L.F.; Hong, J.; Zhang, C. An empirical analysis of phishing blacklists. In Proceedings of the Conference on Email and Anti-Spam, Mountain View, CA, USA, 16–17 July 2009. [Google Scholar]
- Sandell, N.; Varaiya, P.; Athans, M.; Safonov, M. Survey of decentralized control methods for large scale systems. IEEE Trans. Autom. Control 1978, 23, 108–128. [Google Scholar] [CrossRef]
- Canali, D.; Cova, M.; Vigna, G.; Kruegel, C. Prophiler: A fast filter for the large-scale detection of malicious web pages. In Proceedings of the International Conference on World Wide Web, Hyderabad, India, 28 March–1 April 2011; pp. 197–206. [Google Scholar]
- Hason, N.; Dvir, A.; Hajaj, C. Robust Malicious Domain Detection. In Cyber Security Cryptography and Machine Learning; Dolev, S., Kolesnikov, V., Lodha, S., Weiss, G., Eds.; Springer: Cham, Switzerland, 2020; pp. 45–61. [Google Scholar]
- Ahmed, M.; Khan, A.; Saleem, O.; Haris, M. A Fault Tolerant Approach for Malicious URL Filtering. In Proceedings of the International Symposium on Networks, Computers and Communications, Rome, Italy, 19–21 June 2018; pp. 1–6. [Google Scholar]
- Antonakakis, M.; Perdisci, R.; Dagon, D.; Lee, W.; Feamster, N. Building a Dynamic Reputation System for DNS. In Proceedings of the 19th USENIX conference on Security, Washington, DC, USA, 11–13 August 2010; pp. 273–290. [Google Scholar]
- Berger, H.; Dvir, A.Z.; Geva, M. A wrinkle in time: A case study in DNS poisoning. Int. J. Inf. Secur. 2021, 20, 313–329. [Google Scholar] [CrossRef]
- Bilge, L.; Sen, S.; Balzarotti, D.; Kirda, E.; Kruegel, C. Exposure: A Passive DNS Analysis Service to Detect and Report Malicious Domains. Trans. Inf. Syst. Secur. 2014, 16, 1–28. [Google Scholar] [CrossRef]
- Caglayan, A.; Toothaker, M.; Drapeau, D.; Burke, D.; Eaton, G. Real-time detection of fast flux service networks. In Proceedings of the Conference For Homeland Security, Cybersecurity Applications and Technology, Washington, DC, USA, 3–4 March 2009; pp. 285–292. [Google Scholar]
- Choi, H.; Zhu, B.B.; Lee, H. Detecting Malicious Web Links and Identifying Their Attack Types. WebApps 2011, 11, 218. [Google Scholar]
- Dolberg, L.; François, J.; Engel, T. Efficient Multidimensional Aggregation for Large Scale Monitoring. In Proceedings of the 26th Large Installation System Administration Conference, Washington, DC, USA, 3–8 November 2013; pp. 163–180. [Google Scholar]
- Harel, N.; Dvir, A.; Dubin, R.; Barkan, R.; Shalala, R.; Hadar, O. MiSAL-A minimal quality representation switch logic for adaptive streaming. Multimed. Tools Appl. 2019, 78, 1–26. [Google Scholar]
- Hu, Z.; Chiong, R.; Pranata, I.; Susilo, W.; Bao, Y. Identifying malicious web domains using machine learning techniques with online credibility and performance data. In Proceedings of the Congress on Evolutionary Computation (CEC), Vancouver, BC, Canada, 24–29 July 2016; pp. 5186–5194. [Google Scholar]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Nelms, T.; Perdisci, R.; Ahamad, M. ExecScent: Mining for New C&C Domains in Live Networks with Adaptive Control Protocol Templates. In Proceedings of the 22nd USENIX Security Symposium, Washington, DC, USA, 14–16 August 2013; pp. 589–604. [Google Scholar]
- Peng, T.; Harris, I.; Sawa, Y. Detecting phishing attacks using natural language processing and machine learning. In Proceedings of the International Conference on Semantic Computing, Laguna Hills, CA, USA, 31 January–2 Februay 2018; pp. 300–301. [Google Scholar]
- Rahbarinia, B.; Perdisci, R.; Antonakakis, M. Efficient and accurate behavior-based tracking of malware-control domains in large ISP networks. ACM Trans. Priv. Secur. 2016, 19, 4. [Google Scholar] [CrossRef]
- Shi, Y.; Chen, G.; Li, J. Malicious Domain Name Detection Based on Extreme Machine Learning. Neural Process. Lett. 2017, 48, 1–11. [Google Scholar] [CrossRef]
- Sun, X.; Tong, M.; Yang, J.; Xinran, L.; Heng, L. HinDom: A Robust Malicious Domain Detection System based on Heterogeneous Information Network with Transductive Classification. In Proceedings of the International Symposium on Research in Attacks, Intrusions and Defenses, Beijing, China, 23–25 September 2019; pp. 399–412. [Google Scholar]
- Torabi, S.; Boukhtouta, A.; Assi, C.; Debbabi, M. Detecting Internet Abuse by Analyzing Passive DNS Traffic: A Survey of Implemented Systems. Commun. Surv. Tutor. 2018, 20, 3389–3415. [Google Scholar] [CrossRef]
- Yadav, S.; Reddy, A.K.K.; Reddy, A.L.N.; Ranjan, S. Detecting Algorithmically Generated Domain-flux Attacks with DNS Traffic Analysis. Trans. Netw. 2012, 20, 1663–1677. [Google Scholar] [CrossRef]
- Antonakakis, M.; Perdisci, R.; Lee, W.; Vasiloglou, N.; Dagon, D. Detecting Malware Domains at the Upper DNS Hierarchy. In Proceedings of the 20th USENIX Security Symposium, San Francisco, CA, USA, 8–12 August 2011; Volume 11, pp. 1–16. [Google Scholar]
- Perdisci, R.; Corona, I.; Giacinto, G. Early detection of malicious flux networks via large-scale passive DNS traffic analysis. IEEE Trans. Dependable Secur. Comput. 2012, 9, 714–726. [Google Scholar] [CrossRef]
- Papernot, N.; McDaniel, P.; Wu, X.; Jha, S. Distillation as a Defense to Adversarial Perturbations against Deep Neural Networks. In Proceedings of the IEEE Symposium on Security and Privacy, San Jose, CA, USA, 22–26 May 2016. [Google Scholar]
- Tong, L.; Li, B.; Hajaj, C.; Xiao, C.; Zhang, N.; Vorobeychik, Y. Improving Robustness of ML Classifiers against Realizable Evasion Attacks Using Conserved Features. In Proceedings of the 28th USENIX Security Symposium, Santa Clara, CA, USA, 14–16 August 2019. [Google Scholar]
- Jung, J.; Sit, E. An empirical study of spam traffic and the use of DNS black lists. In Proceedings of the SIGCOMM Conference on Internet Measurement, Taormina Sicily, Italy, 25–27 October 2004; pp. 370–375. [Google Scholar]
- Mishsky, I.; Gal-Oz, N.; Gudes, E. A topology based flow model for computing domain reputation. In Proceedings of the IFIP Annual Conference on Data and Applications Security and Privacy, Fairfax, VA, USA, 13–15 July 2015; pp. 277–292. [Google Scholar]
- Othman, H.; Gudes, E.; Gal-Oz, N. Advanced Flow Models for Computing the Reputation of Internet Domains. In Proceedings of the IFIP International Conference on Trust Management, Toronto, ON, Canada, 9–13 July 2017; pp. 119–134. [Google Scholar]
- Dey, S.; Jain, E.; Das, A. Machine Learning Features for Malicious URL Filtering—The Survey. arXiv 2019, arXiv:2019.0621. [Google Scholar]
- Sahoo, D.; Liu, C.; Hoi, S.C. Malicious URL detection using machine learning: A survey. arXiv 2017, arXiv:1701.07179. [Google Scholar]
- Shahzad, H.; Sattar, A.R.; Skandaraniyam, J. From Real Malicious Domains to Possible False Positives in DGA Domain Detection. In Proceedings of the 2021 IEEE 13th International Conference on Computer Research and Development (ICCRD), Beijing, China, 5–7 January 2021; pp. 6–10. [Google Scholar] [CrossRef]
- Zhang, S.; Zhou, Z.; Li, D.; Zhong, Y.; Liu, Q.; Yang, W.; Li, S. Attributed Heterogeneous Graph Neural Network for Malicious Domain Detection. In Proceedings of the 2021 IEEE 24th International Conference on Computer Supported Cooperative Work in Design (CSCWD), Dalian, China, 5–7 May 2021; pp. 397–403. [Google Scholar] [CrossRef]
- Iwahana, K.; Takemura, T.; Cheng, J.C.; Ashizawa, N.; Umeda, N.; Sato, K.; Kawakami, R.; Shimizu, R.; Chinen, Y.; Yanai, N. MADMAX: Browser-Based Malicious Domain Detection Through Extreme Learning Machine. IEEE Access 2021, 9, 78293–78314. [Google Scholar] [CrossRef]
- Kumi, S.; Lim, C.; Lee, S.G. Malicious url detection based on associative classification. Entropy 2021, 23, 182. [Google Scholar] [CrossRef]
- Janet, B.; Kumar, R.J.A. Malicious URL Detection: A Comparative Study. In Proceedings of the 2021 International Conference on Artificial Intelligence and Smart Systems (ICAIS), Coimbatore, India, 25–27 March 2021; pp. 1147–1151. [Google Scholar]
- Srinivasan, S.; Vinayakumar, R.; Arunachalam, A.; Alazab, M.; Soman, K. DURLD: Malicious URL detection using deep learning-based character level representations. In Malware Analysis Using Artificial Intelligence and Deep Learning; Springer: Berlin/Heidelberg, Germany, 2021; pp. 535–554. [Google Scholar]
- Cyprienna, R.A.; Zo Lalaina Yannick, R.; Randria, I.; Raft, R.N. URL Classification based on Active Learning Approach. In Proceedings of the 2021 3rd International Cyber Resilience Conference (CRC), Langkawi Island, Malaysia, 29–31 January 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples; In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015.
- Nelson, B.; Barreno, M.; Chi, F.J.; Joseph, A.D.; Rubinstein, B.I.; Saini, U.; Sutton, C.A.; Tygar, J.D.; Xia, K. Exploiting Machine Learning to Subvert Your Spam Filter. LEET 2008, 8, 1–9. [Google Scholar]
- Fogla, P.; Sharif, M.I.; Perdisci, R.; Kolesnikov, O.M.; Lee, W. Polymorphic Blending Attacks. In Proceedings of the 15th USENIX Security Symposium, Austin, TX, USA, 10–12 August 2006; pp. 241–256. [Google Scholar]
- Newsome, J.; Karp, B.; Song, D. Paragraph: Thwarting signature learning by training maliciously. In Proceedings of the International Workshop on Recent Advances in Intrusion Detection, Hamburg, Germany, 20–22 September 2006; pp. 81–105. [Google Scholar]
- Rodrigues, R.N.; Ling, L.L.; Govindaraju, V. Robustness of multimodal biometric fusion methods against spoof attacks. J. Vis. Lang. Comput. 2009, 20, 169–179. [Google Scholar] [CrossRef]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards Deep Learning Models Resistant to Adversarial Attacks. In Proceedings of the Sixth International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Raghunathan, A.; Steinhardt, J.; Liang, P. Certified Defenses against Adversarial Examples. In Proceedings of the Sixth International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Song, Y.; Kim, T.; Nowozin, S.; Ermon, S.; Kushman, N. Pixeldefend: Leveraging Generative Models to Understand and Defend against Adversarial Examples. In Proceedings of the Sixth International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Berger, H.; Hajaj, C.; Mariconti, E.; Dvir, A. Crystal Ball: From Innovative Attacks to Attack Effectiveness Classifier. IEEE Access 2022, 10, 1317–1333. [Google Scholar] [CrossRef]
- Papernot, N.; McDaniel, P.; Goodfellow, I.; Jha, S.; Celik, Z.B.; Swami, A. Practical black-box attacks against machine learning. In Proceedings of the Asia Conference on Computer and Communications Security, Abu Dhabi, United Arab Emirates, 2–6 April 2017; pp. 506–519. [Google Scholar]
- Shahpasand, M.; Hamey, L.; Vatsalan, D.; Xue, M. Adversarial Attacks on Mobile Malware Detection. In Proceedings of the International Workshop on Artificial Intelligence for Mobile, Hangzhou, China, 24–24 February 2019; pp. 17–20. [Google Scholar]
- Brückner, M.; Scheffer, T. Stackelberg games for adversarial prediction problems. In Proceedings of the International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 21–24 August 2011; pp. 547–555. [Google Scholar]
- Singh, A.; Lakhotia, A. Game-theoretic design of an information exchange model for detecting packed malware. In Proceedings of the International Conference on Malicious and Unwanted Software, Fajardo, PR, USA, 18–19 October 2011; pp. 1–7. [Google Scholar]
- Zolotukhin, M.; Hämäläinen, T. Support vector machine integrated with game-theoretic approach and genetic algorithm for the detection and classification of malware. In Proceedings of the Globecom Workshops, Atlanta, GA, USA, 9–13 December 2013; pp. 211–216. [Google Scholar]
- Xu, H.; Caramanis, C.; Mannor, S. Robustness and regularization of support vector machines. J. Mach. Learn. D 2009, 10, 1485–1510. [Google Scholar]
- Li, B.; Vorobeychik, Y. Evasion-robust classification on binary domains. Trans. Knowl. Discov. Data 2018, 12, 50. [Google Scholar] [CrossRef]
- Nissim, N.; Moskovitch, R.; BarAd, O.; Rokach, L.; Elovici, Y. ALDROID: Efficient update of Android anti-virus software using designated active learning methods. Knowl. Inf. Syst. 2016, 49, 795–833. [Google Scholar] [CrossRef]
- Chen, X.; Li, C.; Wang, D.; Wen, S.; Zhang, J.; Nepal, S.; Xiang, Y.; Ren, K. Android HIV: A study of repackaging malware for evading machine-learning detection. IEEE Trans. Inf. Forensics Secur. 2019, 15, 987–1001. [Google Scholar] [CrossRef] [Green Version]
- Fidel, G.; Bitton, R.; Katzir, Z.; Shabtai, A. Adversarial robustness via stochastic regularization of neural activation sensitivity. arXiv 2020, arXiv:2009.11349. [Google Scholar]
- Alexa. Available online: https://www.alexa.com (accessed on 1 February 2022).
- PhishTank. Available online: https://www.phishtank.com (accessed on 1 February 2022).
- ScumWare. Available online: https://www.scumware.org (accessed on 1 February 2022).
- WEBROOT. Available online: https://mypage.webroot.com/rs/557-FSI-195/images/2020%20Webroot%20Threat%20Report_US_FINAL.pdf (accessed on 1 February 2022).
- A Study of Whois Privacy and Proxy Service Abuse. Available online: https://gnso.icann.org/sites/default/files/filefield_41831/pp-abuse-study-20sep13-en.pdf (accessed on 1 February 2022).
- VirusTotal. Available online: https://www.virustotal.com (accessed on 1 February 2022).
- urlscan.io. Available online: https://www.urlscan.io (accessed on 1 February 2022).
- Ranganayakulu, D.; Chellappan, C. Detecting malicious URLs in E-mail–An implementation. AASRI 2013, 4, 125–131. [Google Scholar] [CrossRef]
- Xiang, G.; Hong, J.; Rose, C.P.; Cranor, L. Cantina+: A feature-rich machine learning framework for detecting phishing web sites. Trans. Inf. Syst. Secur. 2011, 14, 21. [Google Scholar] [CrossRef]
- Clarifications to the DNS Specification. Available online: https://tools.ietf.org/html/rfc2181 (accessed on 1 February 2022).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Prediction Outcome | ||||
|---|---|---|---|---|
| Positive | Negative | Total | ||
| Actual Value | Positive | True Positive | False Negative | TP + FN |
| Negative | False Positive | True Negative | FP + TN | |
| Total | P | N | ||
| Feature | Benign Mean (std) | Malicious Mean (std) |
|---|---|---|
| Length of domain | 14.38 (4.06) | 15.54 (4.09) |
| Number of consecutive characters * | 1.29 (0.46) | 1.46 (0.5) |
| Entropy of the domain | 4.85 (1.18) | 5.16 (1.34) |
| Number of IP addresses | 2.09 (1.25) | 1.94 (0.94) |
| Distinct geo-locations of the IP | ||
| addresses | 1.00 (0.17) | 1.02 (0.31) |
| Mean TTL value * | 7578.13 (17,781.47) | 8039.92 (15,466.29) |
| Standard deviation of the TTL | 2971.65 (8777.26) | 2531.38 (7456.62) |
| Lifetime of domain * | 10.98 (7.46) | 6.75 (5.77) |
| Active time of domain * | 8.40 (6.79) | 4.64 (5.66) |
| Feature | Benign Mean (std) | Malicious Mean (std) |
|---|---|---|
| Communication Countries Rank (CCR) | 31.31 (91.16) | 59.40 (215.15) |
| Communication ASNs Rank (CAR) | 935.59 (12,258.99) | 12,979.38 (46,384.86) |
| Number of passive DNS changes | 26.40 (111.99) | 8.01 (16.63) |
| Expiration time of SSL certificate | () | () |
| Feature Set | Accuracy | Recall | F1-Score |
|---|---|---|---|
| Base | 89.99% | 38.82% | 53.21% |
| Robust Base | 88.33% | 38.87% | 49.42% |
| TCP | 86.20% | 8.30% | 14.99% |
| BRTCP | 88.82% | 52.46% | 65.57% |
| BTCP | 92.86% | 64.14% | 72.48% |
| Feature Set | Accuracy | Recall | F1-Score |
|---|---|---|---|
| Base | 96.49% | 91.20% | 91.36% |
| Robust Base | 90.14% | 56.51% | 69.93% |
| TCP | 83.10% | 60.21% | 54.21% |
| BRTCP | 96.78% | 91.37% | 92.02% |
| BTCP | 97.95% | 90.73% | 92.83% |
| Feature Set | Accuracy | Recall | F1-Score |
|---|---|---|---|
| Base | 98.17% | 88.81% | 92.92% |
| Robust Base | 98.83% | 92.24% | 95.81% |
| TCP | 98.88% | 94.64% | 96.84% |
| BRTCP | 98.86% | 95.82% | 97.07% |
| BTCP | 98.19% | 93.09% | 95.34% |
| Feature Set | Accuracy | Recall | F1-Score |
|---|---|---|---|
| Base | 97.20% | 88.03% | 90.23% |
| Robust Base | 95.71% | 83.63% | 88.78% |
| TCP | 98.03% | 96.83% | 95.24% |
| BRTCP | 99.36% | 98.77% | 98.42% |
| BTCP | 99.82% | 99.47% | 99.56% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hajaj, C.; Hason, N.; Dvir, A. Less Is More: Robust and Novel Features for Malicious Domain Detection. Electronics 2022, 11, 969. https://doi.org/10.3390/electronics11060969
Hajaj C, Hason N, Dvir A. Less Is More: Robust and Novel Features for Malicious Domain Detection. Electronics. 2022; 11(6):969. https://doi.org/10.3390/electronics11060969
Chicago/Turabian StyleHajaj, Chen, Nitay Hason, and Amit Dvir. 2022. "Less Is More: Robust and Novel Features for Malicious Domain Detection" Electronics 11, no. 6: 969. https://doi.org/10.3390/electronics11060969