
Data Preprocessing Combination to Improve the Performance of Quality Classification in the Manufacturing Process



Abstract
:1. Introduction
2. Literature Review
2.1. Machine Learning Studies Using the SECOM Dataset
2.2. Mutiple Imputation Studies for Missing Data
2.3. Data Imblance Studies
3. Theoretical Background
3.1. Data Imputation Methodology
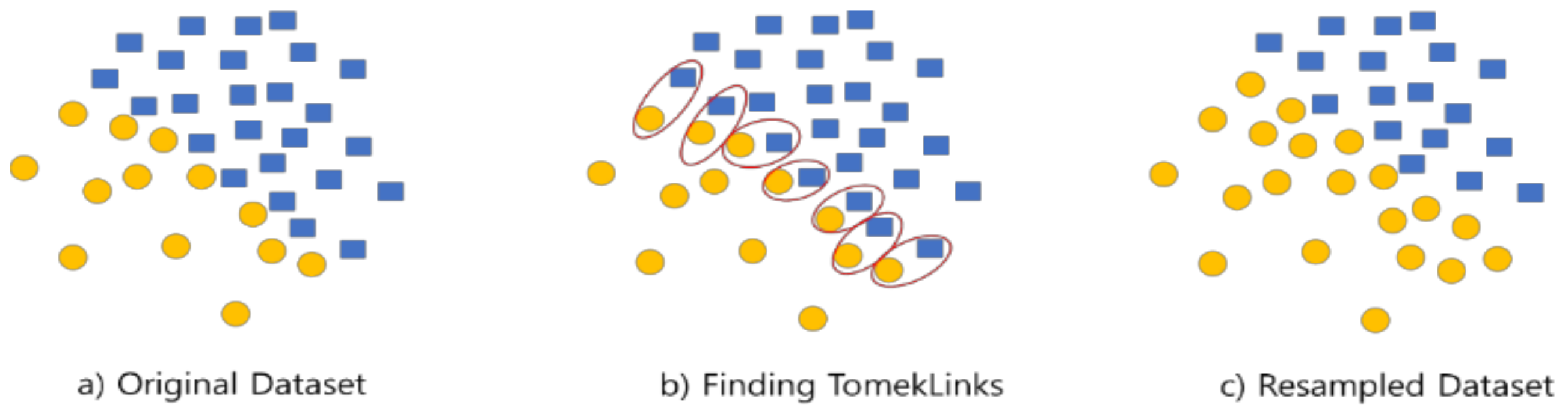
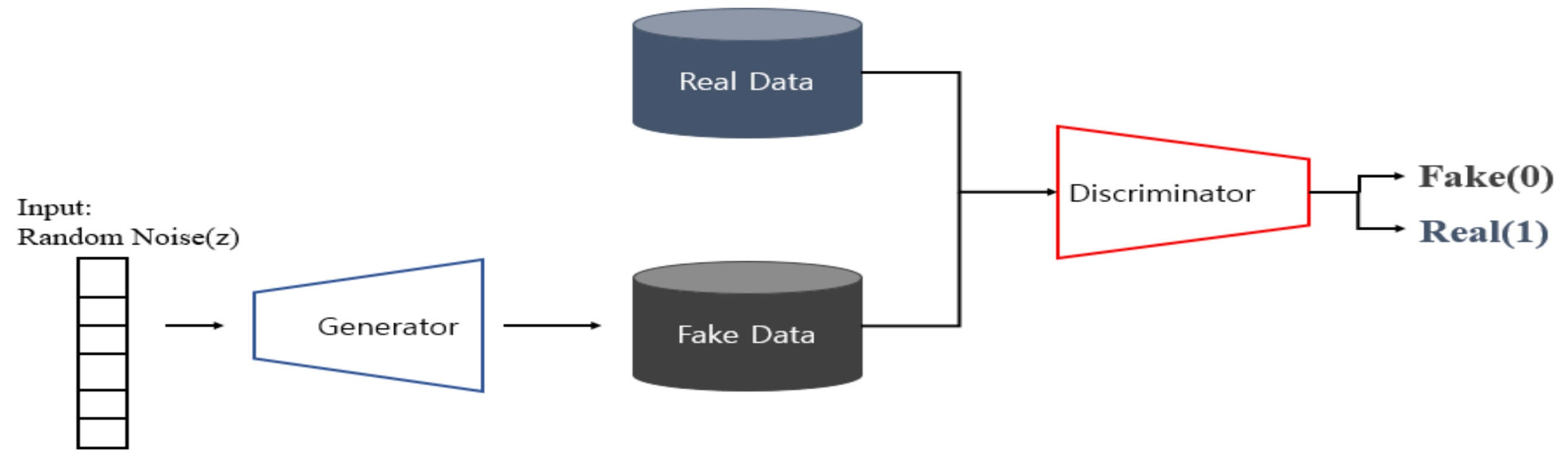
3.2. Methodologies for Handling Data Imbalances
3.3. Machine Learning Classification Methodologies
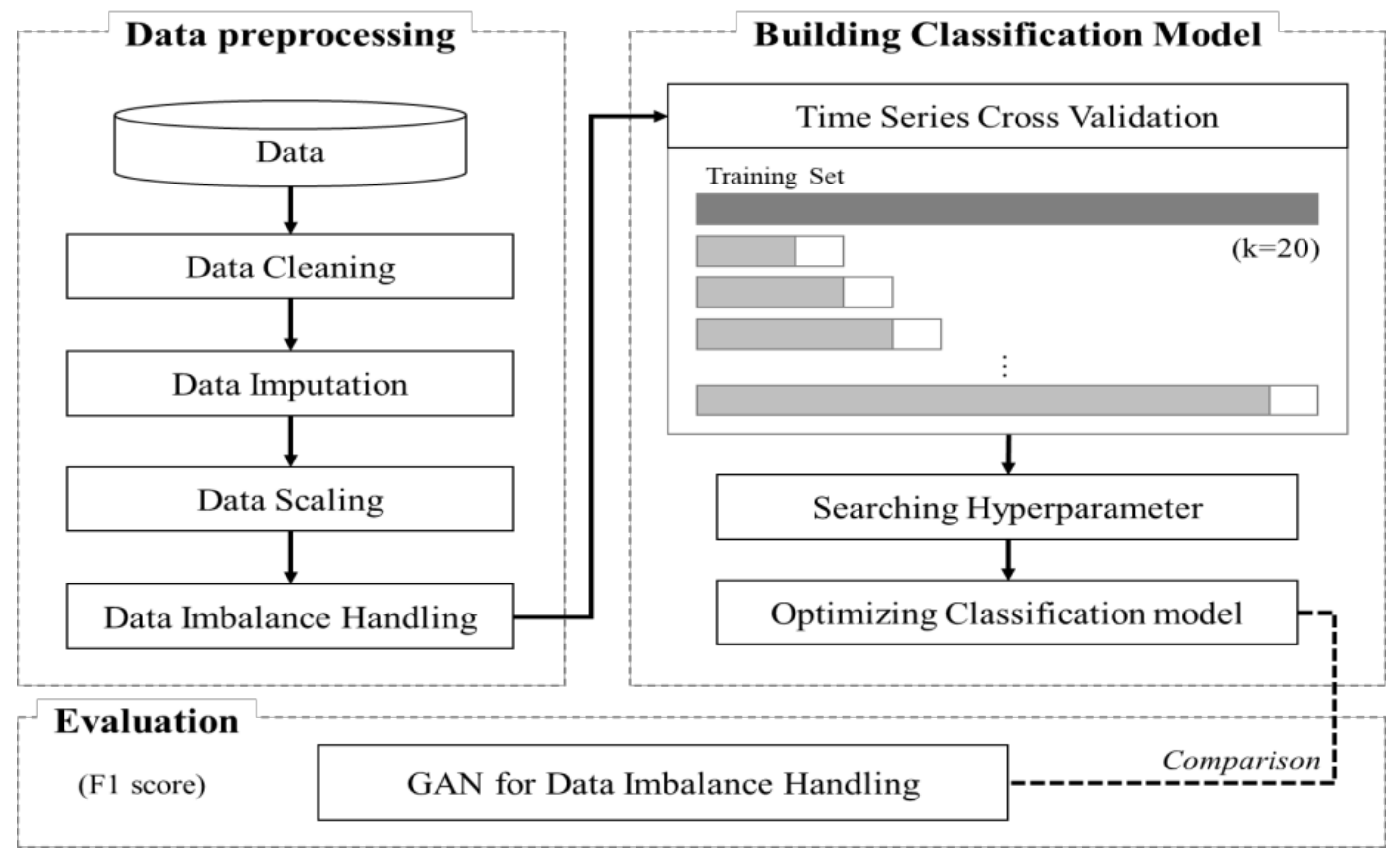
4. Proposed Methodology
4.1. Data Preprocessing
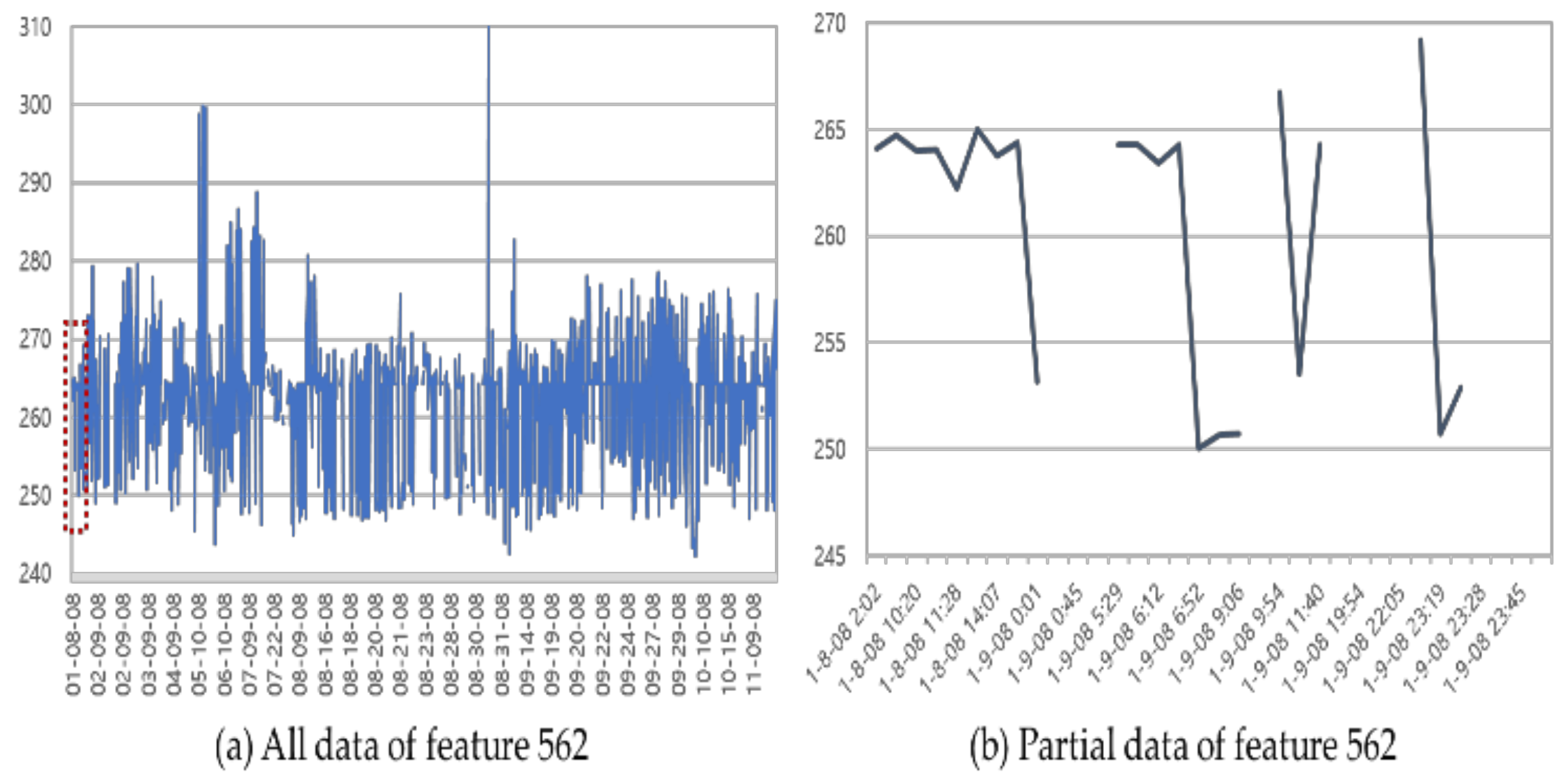
4.1.1. Data Cleansing
4.1.2. Data Imputation
4.1.3. Data Scaling
4.1.4. Data Imbalance Handling
4.2. Building the Classifcation Model and Evaluation
5. Experimental Setting and Results
5.1. Dataset
5.2. Experimental Settings
5.3. Results
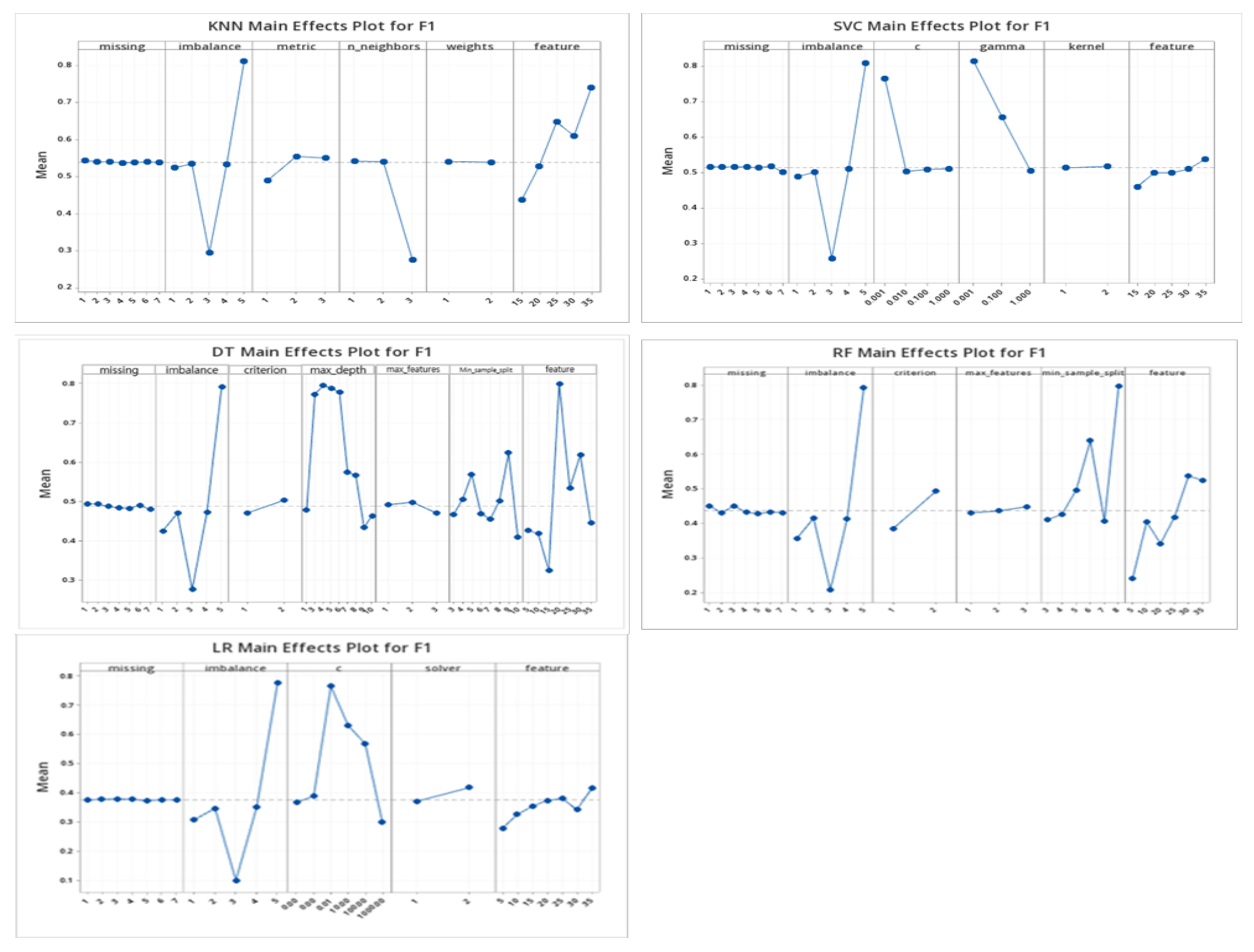
5.3.1. Performance Evaluation of Classification Models
5.3.2. Evaluation of Combinations of Classification Models for Data Preprocessing
6. Conclusions and Future Research
Author Contributions
Funding
Conflicts of Interest
References
- Kim, H.; Lee, H. Fault Detect and Classification Framework for Semiconductor Manufacturing Processes using Missing Data Estimation and Generative Adversary Network. J. Korean Inst. Intell. Syst. 2018, 28, 393–400. [Google Scholar]
- Randolph-Gips, M. A new neural network to process missing data without Imputation. In Proceedings of the 2008 Seventh International Conference on Machine Learning and Applications, San Diego, CA, USA, 11–13 December 2008; pp. 756–762. [Google Scholar]
- O’Brien, R.; Ishwaran, H. A random forests quantile classifier for class imbalanced data. Pattern Recognit. 2019, 90, 232–249. [Google Scholar] [CrossRef] [PubMed]
- Napierała, K.; Stefanowski, J. Addressing imbalanced data with argument based rule learning. Expert Syst. Appl. 2015, 42, 9468–9481. [Google Scholar] [CrossRef]
- Munirathinam, S.; Ramadoss, B. Predictive models for equipment fault detection in the semiconductor manufacturing process. IACSIT Int. J. Eng. Technol. 2016, 8, 273–285. [Google Scholar] [CrossRef] [Green Version]
- Moldovan, D.; Cioara, T.; Anghel, I.; Salomie, I. Machine learning for sensor-based manufacturing processes. In Proceedings of the 2017 13th IEEE International Conference on Intelligent Computer Communication and Processing (ICCP), Cluj-Napoca, Romania, 7–9 September 2017; pp. 147–154. [Google Scholar]
- Chomboon, K.; Kerdprasop, K.; Kerdprasop, N. Rare class discovery techniques for highly imbalance data. In Proceedings of the International MultiConference of Engineers and Computer Scientists, Hong Kong, China, 13–15 March 2013; Volume 1. [Google Scholar]
- Kerdprasop, K.; Kerdprasop, N. Feature selection and boosting techniques to improve fault detection accuracy in the semiconductor manufacturing process. In Proceedings of the International MultiConference of Engineering and Computer Scientists 2011 (IMECS 2011), Hong Kong, China, 16–18 March 2011; Volume 1. [Google Scholar]
- Kim, J.; Han, Y.; Lee, J. Data imbalance problem solving for smote based oversampling: Study on fault detection prediction model in semiconductor manufacturing process. Adv. Sci. Technol. Lett. 2016, 133, 79–84. [Google Scholar]
- García-Laencina, P.J.; Sancho-Gómez, J.L.; Figueiras-Vidal, A.R.; Verleysen, M. K nearest neighbours with mutual information for simultaneous classification and missing data imputation. Neurocomputing 2009, 72, 1483–1493. [Google Scholar] [CrossRef]
- Stekhoven, D.J.; Bühlmann, P. MissForest—Non-parametric missing value imputation for mixed-type data. Bioinformatics 2012, 28, 112–118. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schmitt, P.; Mandel, J.; Guedj, M. A comparison of six methods for missing data imputation. J. Biom. Biostat. 2015, 6, 1. [Google Scholar]
- García-Laencina, P.J.; Abreu, P.H.; Abreu, M.H.; Afonoso, N. Missing data imputation on the 5-year survival prediction of breast cancer patients with unknown discrete values. Comput. Biol. Med. 2015, 59, 125–133. [Google Scholar] [CrossRef] [PubMed]
- Bauer, J.; Angelini, O.; Denev, A. Imputation of multivariate time series data-performance benchmarks for multiple imputation and spectral techniques. SSRN Electron. J. 2017. [Google Scholar] [CrossRef]
- Van Hulse, J.; Khoshgoftaar, T.M.; Napolitano, A. Experimental perspectives on learning from imbalanced data. In Proceedings of the 24th International Conference on Machine Learning, Corvallis, OR, USA, 20–24 June 2007; pp. 935–942. [Google Scholar]
- Son, M.; Jung, S.; Hwang, E. Oversampling scheme using Conditional GAN. In Proceedings of the Korea Information Processing Society Conference, Pusan, Korea; Korea Information Processing Society, 2018; pp. 609–612. [Google Scholar]
- Lamari, M.; Azizi, N.; Hammami, N.E.; Boukhamla, A.; Cheriguene, S.; Dendani, N.; Benzebouchi, N.E. SMOTE–ENN-Based Data Sampling and Improved Dynamic Ensemble Selection for Imbalanced Medical Data Classification. In Advances on Smart and Soft Computing; Springer: Singapore, 2020; pp. 37–49. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Batista, G.E.; Prati, R.C.; Monard, M.C. A study of the behavior of several methods for balancing machine learning training data. ACM SIGKDD Explor. Newsl. 2004, 6, 20–29. [Google Scholar] [CrossRef]
- Liang, G. An effective method for imbalanced time series classification: Hybrid sampling. In Australasian Joint Conference on Artificial Intelligence; Springer: Cham, Switzerland, 2013; pp. 374–385. [Google Scholar]
- Branco, P.; Torgo, L.; Ribeiro, R. A survey of predictive modelling under imbalanced distributions. arXiv 2015, arXiv:1505.01658. [Google Scholar]
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–6 June 2008; pp. 1322–1328. [Google Scholar]
- Boser, B.E.; Guyon, I.M.; Vapnik, V.N. A training algorithm for optimal margin classifiers. In Proceedings of the Fifth Annual Workshop on Computational Learning Theory, Pittsburgh, PA, USA, 27–29 July 1992; pp. 144–152. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Questions | Approaches |
|---|---|
| How can missing values in the data be replaced? | Use single and multiple imputation methods to replace missing data |
| Which methodology can one use to address data imbalances? | Use legacy simple oversampling, hybrid sampling, and a GAN |
| How does one evaluate the performance of quality classification? | Use the F1 score as an evaluation indicator considering the characteristics of imbalanced data |
| Author | Algorithm |
|---|---|
| Lamari et al. [17] | Hybrid sampling method using SMOTE-ENN |
| Chawla et al. [18] | Combination of methods |
| Batista et al. [19] | SMOTE-Tomek and SMOTE-ENN |
| Liang [20] | Hybrid sampling method using bagging |
| Branco et al. [21] | Research on the imbalanced data problem |
| Ratio of Missing Values | 91.2% | 85.6% | 65% | 60.6% | 50.7% | ≤17.4% |
| Number of Features | 4 | 4 | 12 | 4 | 8 | 558 |
| Feature Number | 0 | 7 | 9 | |
| Before Scaling | 3026.640 | 0.118 | 0.013 | |
| 2980.840 | 0.123 | −0.009 | ||
| 2847.810 | 0.123 | −0.008 | ||
| 3056.050 | 0.123 | −0.004 | ||
| Average | 3024.392 | 0.122 | −0.001 | |
| Variance | 141.456 | 0 | 0 | |
| After Scaling | 0.031 | 0.596 | −0.261 | |
| −0.457 | 0.059 | 0.309 | ||
| −2.267 | 0.463 | 0.717 | ||
| 0.567 | 0.134 | 1.448 | ||
| Average | 0 | 0 | 0 | |
| Variance | 1 | 1 | 1 | |
| Package | Version | Description |
|---|---|---|
| numpy | 1.18.1 | Provides useful functions for scientific calculations, especially for handling multidimensional arrays |
| pandas | 0.25.3 | Widely used for data analysis |
| scikit-learn | 0.23.0 | Machine learning library |
| imbalanced-learn | 0.7.0 | Implements various sampling methods to solve the imbalanced data problem |
| mlxtend | 0.17.3 | Composed of useful tools for common data science tasks |
| tqdm | 4.42.1 | Creates a progress bar on the fly and predicts the Time to Completion (TTC) of a function or loop |
| keras | 2.2.4 | Makes it easy to handle deep learning engines such as TensorFlow with python |
| Method | Hyperparameter | Range | Level | Setting Value |
|---|---|---|---|---|
| Logistic Regression | C | [0.0001, 0.001, 0.01, 1, 10, 100, 1000] | 7 | |
| solver | [liblinear, newton-cg] | 2 | 1,2 | |
| Feature | 7 | 5,10,15,20,25,30,35 | ||
| KNN | metric | [manhattan, euclidean, minkowski] | 3 | 1,2,3 |
| weights | [uniform, distance] | 2 | 1,2 | |
| n_neighbors | 1 <= k <= 21 | 3 | 1,2,3 | |
| Feature | 5 | 15,20,25,30,35 | ||
| SVC | C | [0.001, 0.01, 0.1, 1] | 4 | |
| gamma | [0.01, 0.1, 1] | 3 | ||
| kernel | [poly, rbf, linear] | 3 | 1,2,3 | |
| Feature | 5 | 15,20,25,30,35 | ||
| Decision Tree | max_features | [auto, sqrt, log2] | 3 | 1,2,3 |
| min_samples_split | 3 <= n <= 10 | 8 | 3,4,5,6,7,8,9,10 | |
| max_depth | 1 <= n <= 10 | 9 | 1,3,4,5,6,7,8,9,10 | |
| criterion | [gini, entropy] | 2 | 1,2 | |
| Feature | 7 | 5,10,15,20,25,30,35 | ||
| Random Forest | max_features | [auto, sqrt, log2] | 3 | 1,2,3 |
| min_samples_split | 3 <= n <= 10 | 6 | 3,4,5,6,7,8 | |
| criterion | [gini, entropy] | 2 | 1,2 | |
| Feature | 6 | 5,10, 20,25,30,35 |
| Random Oversampling | SMOTE | SMOTE-Tomek | SMOTE- ENN | ADASYN | GAN | ||
|---|---|---|---|---|---|---|---|
| Linear Interpolation | 0.292 | 0.532 | 0.534 | 0.815 | 0.517 | 0.898 | |
| Poly Interpolation | 0.293 | 0.535 | 0.529 | 0.818 | 0.531 | 0.899 | |
| KNN (k = 2) | 0.302 | 0.540 | 0.537 | 0.818 | 0.531 | 0.904 | |
| KNN (k = 4) | 0.301 | 0.535 | 0.538 | 0.814 | 0.530 | 0.912 | |
| KNN (k = 6) | 0.301 | 0.534 | 0.538 | 0.814 | 0.535 | 0.915 | |
| MICE | 0.301 | 0.542 | 0.536 | 0.795 | 0.529 | 0.907 | |
| MissForest | 0.301 | 0.540 | 0.538 | 0.817 | 0.519 | 0.889 | |
| Method | Source | Degrees of Freedom | AdjSS | AdjMS | F-Value | p-Value | |
|---|---|---|---|---|---|---|---|
| KNN | Factors | Missing | 6 | 0.001 | 0.000 | 9.440 | 0.000 |
| Imbalance | 4 | 5.175 | 1.294 | 56,839.100 | 0.000 | ||
| metric | 2 | 0.000 | 0.000 | 2.530 | 0.081 | ||
| n_neighbors | 2 | 0.001 | 0.000 | 13.580 | 0.000 | ||
| weights | 1 | 0.000 | 0.000 | 1.850 | 0.175 | ||
| Number of Features | 4 | 0.002 | 0.001 | 23.060 | 0.000 | ||
| Error | 330 | 0.008 | 0.000 | ||||
| SVC | Factors | Missing | 6 | 0.007 | 0.001 | 4.450 | 0.000 |
| Imbalance | 4 | 9.766 | 2.442 | 9539.580 | 0.000 | ||
| C | 3 | 0.019 | 0.006 | 24.160 | 0.000 | ||
| gamma | 2 | 0.002 | 0.001 | 4.740 | 0.009 | ||
| kernel | 1 | 0.000 | 0.000 | 1.330 | 0.249 | ||
| Number of Features | 4 | 0.024 | 0.006 | 23.880 | 0.000 | ||
| Error | 329 | 0.084 | 0.000 | ||||
| Decision Tree | Factors | Missing | 6 | 0.006 | 0.001 | 19.800 | 0.000 |
| Imbalance | 4 | 3.458 | 0.864 | 16,731.730 | 0.000 | ||
| criterion | 1 | 0.000 | 0.000 | 2.490 | 0.116 | ||
| max_depth | 8 | 0.002 | 0.000 | 5.960 | 0.000 | ||
| max_features | 2 | 0.000 | 0.000 | 0.430 | 0.653 | ||
| min_sample_split | 7 | 0.001 | 0.000 | 1.740 | 0.099 | ||
| Number of Features | 6 | 0.001 | 0.000 | 2.730 | 0.013 | ||
| Error | 315 | 0.016 | 0.000 | ||||
| Random Forest | Factors | Missing | 6 | 0.026 | 0.004 | 88.110 | 0.000 |
| Imbalance | 4 | 7.185 | 1.796 | 37,046.710 | 0.000 | ||
| criterion | 1 | 0.000 | 0.000 | 0.000 | 0.960 | ||
| max_depth | 2 | 0.000 | 0.000 | 1.830 | 0.162 | ||
| min_sample_split | 5 | 0.001 | 0.000 | 3.650 | 0.003 | ||
| Number of Features | 5 | 0.002 | 0.000 | 6.160 | 0.000 | ||
| Error | 326 | 0.016 | 0.000 | ||||
| Logistic Regression | Factors | Missing | 6 | 0.002 | 0.000 | 1.710 | 0.118 |
| Imbalance | 4 | 15.107 | 3.777 | 25,898.740 | 0.000 | ||
| C | 5 | 0.078 | 0.016 | 107.180 | 0.000 | ||
| solver | 1 | 0.001 | 0.001 | 4.440 | 0.036 | ||
| Number of Features | 6 | 0.039 | 0.006 | 43.980 | 0.000 | ||
| Error | 327 | 0.048 | 0.000 | ||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cho, E.; Chang, T.-W.; Hwang, G. Data Preprocessing Combination to Improve the Performance of Quality Classification in the Manufacturing Process. Electronics 2022, 11, 477. https://doi.org/10.3390/electronics11030477
Cho E, Chang T-W, Hwang G. Data Preprocessing Combination to Improve the Performance of Quality Classification in the Manufacturing Process. Electronics. 2022; 11(3):477. https://doi.org/10.3390/electronics11030477
Chicago/Turabian StyleCho, Eunnuri, Tai-Woo Chang, and Gyusun Hwang. 2022. "Data Preprocessing Combination to Improve the Performance of Quality Classification in the Manufacturing Process" Electronics 11, no. 3: 477. https://doi.org/10.3390/electronics11030477