1. Introduction
With the progress of combat mode and the expansion of combat scale, modern air combat gradually extends from the within visual range (WVR) air combat to the beyond visual range (BVR) air combat [
1]. Unmanned aerial vehicles (UAVs) are more and more widely used in military tasks such as investigation, monitoring and target attack [
2] because of their low cost, strong mobility and high concealment. Due to the limitations of a single UAV’s mission and combat capability, autonomous multi-UAV cooperative air combats have become a research hotspot in recent years [
3].
Autonomous air combat maneuver decision making refers to the process of automatically generating the maneuver control decisions of UAVs based on mathematical optimization and artificial intelligence [
4], which requires that UAVs have independent capabilities for autonomous sensing, information processing and decision-making abilities [
5]. At present, there are many autonomous decision making methods for UAV air combat maneuver control, which can be roughly divided into two categories: Analytical solution methods and intelligent optimization methods. Analytical solutions include matrix games, influence diagrams, differential games, etc. Matrix game method [
6] uses a linear program to find the optimal solution in a short decision time, which cannot guarantee global optimization. In addition, this method needs to introduce expert experience to design the income matrix in line with the actual air combat, which is time consuming and laborious. The maneuver decision making method based on influence graph [
7,
8] can intuitively express the air combat model of key factors such as threat, situation and pilot’s subjective preference through influence graph, but it is difficult to obtain the analytical solution by this method, and the calculation time is long. So the influence graph cannot meet the real-time performance of air combat decision making. In [
9,
10], the knowledge of game theory is introduced into air combat to realize the one-to-one autonomous maneuver decision of UAV, and the method in [
9] solved the curse of dimension problem by using fuzzy theory. However, the method in [
9] does not take into account the current state of the enemy aircraft when designing the state, and lacks confrontation simulation results. The method used in [
10] has complex calculation and poor real-time performance, and is not suitable for the high dynamic environment. The differential game method [
11] is the most practical decision making model for studying air combat games. However, due to the difficulty in setting the performance function, the huge amount of calculation and the ill condition after the model is simplified, although the differential game theory has been developed for many years, it has not produced a more reasonable description of actual air combat. In [
12], researchers propose an air-to-air confrontation method based on uncertain interval information, but only analyze the influence of different factors on air combat effect, and do not consider the maneuver model of UAV. In addition, the method in [
12] needs to calculate the revenue and expenditure matrix, which is cumbersome and has low real-time performance. In short, the analytical solution method needs to accurately model and describe the decision model, which cannot be applied to the air combat scene without model or incomplete environment information, and cannot meet the requirements of intelligent air combat.
Intelligent optimization methods mainly include expert system method [
13], neural network method [
14] and some other optimization algorithms such as fuzzy tree, particle swarm optimization [
15] and reinforcement learning. The maneuver decision making method based on the expert system has mature technology and is easy to implement, but its disadvantage is that the establishment of the knowledge base is complex and it is difficult to fully cover all air combat situations. The maneuver decision making based on the neural network has strong robustness and learning ability, but it is a supervised learning method, which cannot be applied without a training set. While the application of neural networks in air combat decision making has practical value, it is worth further exploration and improvement. A maneuver decision making method based on the fuzzy tree is proposed in [
16], which can guide UAVs to make more targeted maneuver decisions according to a real-time combat situation. However, the design of fuzzy tree is difficult and the hyper-parameters are complex and diverse, and expert experience needs to be introduced. In [
17], researchers use dynamic game and particle swarm optimization to realize multi-agent task allocation and confrontation. This method will make the payment matrix of both parties become huge with the increase of the number of agents, and the income matrix needs to be designed manually. Therefore, subjective factors have a great impact on the experimental results. In addition, the simulation result is a two-dimensional plane without considering the maneuver control model of UAV, which is very different from the real maneuver.
Reinforcement learning [
18] is an intelligent optimization method that uses the “trial and error” method to interact with the environment, learns from the environment and improves the performance with time [
19]. It overcomes the shortcomings of complex modeling, difficult sample marking and cumbersome solutions of other methods, and can produce a series of decision sequences considering long-term effects through self-interactive training without manual intervention. It is a feasible modeling method for autonomous decision making of air combat maneuvers in artificial intelligence [
20,
21]. The autonomous maneuver decision making problem of air combat based on deep reinforcement learning is studied in [
22,
23,
24,
25,
26]. In [
22,
23], researchers verify the performance of the algorithm by building a high simulation combat platform, and has good experimental results. However, the reward function in [
23] is sparse, and the reward is 0 in most states of each round, which is not conducive to network training. The robust multi-agent reinforcement learning (MARL) algorithm framework is used in [
24] to solve the problem that the reinforcement learning algorithm cannot converge due to the unstable environment in the training process. However, the simulation environment in [
24] is a two-dimensional plane and the simulation test initialization is fixed, which makes it hard to be applied in the dynamic confrontation scenarios. Many aspects of UAV situation assessment is considered in [
25], but UAV uses absolute coordinates as the state input, which is highly dependent on spatial characteristics. In [
26], researchers use Monte Carlo reinforcement learning to carry out research. The biggest problem is that the agent needs to complete a complete air combat process to evaluate the reward. Moreover, the above references consider the one-to-one air combat scenario, which has limited reference value for the research of multi-aircraft cooperative autonomous control. There are few studies on multi-agent confrontation using reinforcement learning algorithms. In [
27], a novel autonomous aerial combat maneuver strategy generation algorithm based on state-adversarial deep deterministic policy gradient algorithm (SA-DDPG) is proposed, which considers the error of the airborne sensor and uses a reward shaping method based on maximum entropy inverse reinforcement learning algorithm. However, the reliance on expert knowledge in the design of reward functions in this paper is not conducive to extension to more complex air combat environments. In [
28] researchers propose an air combat decision-making model based on reinforcement learning framework, and use long short-term memory (LSTM) to generate a new displacement prediction. However, the simulation experiments in [
28] rely on an off-the-shelf game environment, which is not conducive to the extension of the study and it studies the air combat problem of searching for observation station in a non-threatening environment, which differs significantly from the air combat mission of this paper. Based on the MARL method, the simulation in [
29] of multiple UAVs arriving at their destinations from any departure points in a large-scale complex environment is realized. However, the modeling environment is planar, and a sparse reward function is used, and only distance penalty is considered. The method for maneuver decision making of multi-UAV formation air combat in [
30] is robust. However, there are no simulation results, and there are only three maneuver behaviors. The deep deterministic policy gradient (DDPG) algorithm is used in [
31] to realize the maneuver decision of the dynamic change of UAV quantity in the process of swarm air combat. The algorithm has robustness and expansibility, but the waypoint model is used in this paper, which cannot describe the maneuver characteristics of UAV. Other researches on air combat based on reinforcement learning, the intelligent decision making technology for multi-UAV prevention and control proposed in [
21,
32]. The control method of UAV autonomous avoiding missile threat based on deep reinforcement learning introduced in [
33,
34]. Deep reinforcement learning is used in [
35] to build an intelligent command framework and so on. These studies focus on the feasibility of reinforcement learning methods in solving some air combat problems, which has little correlation with our autonomous maneuver decision making problem, but provides some ideas for our research. In addition, uniform sampling is used in [
21,
22,
23,
24,
25,
26,
29,
30,
32], which means that the probability of all experiences in the experience pool being extracted and utilized is the same, thus ignoring the different importance of each experience, resulting in long training time and extremely unstable.
Generally speaking, at present, the research on air combat maneuver decision making based on reinforcement learning mainly focuses on single UAV confrontation tasks, and the research on multi-UAV confrontation and multi-UAV cooperation are in the initial exploration stage. These studies have one or more of the following problems: Dimension explosion, rewards are sparse and delayed, simple simulation environment, lack of maneuver model, incomplete situation assessment and random uniform sampling leads to slow training.
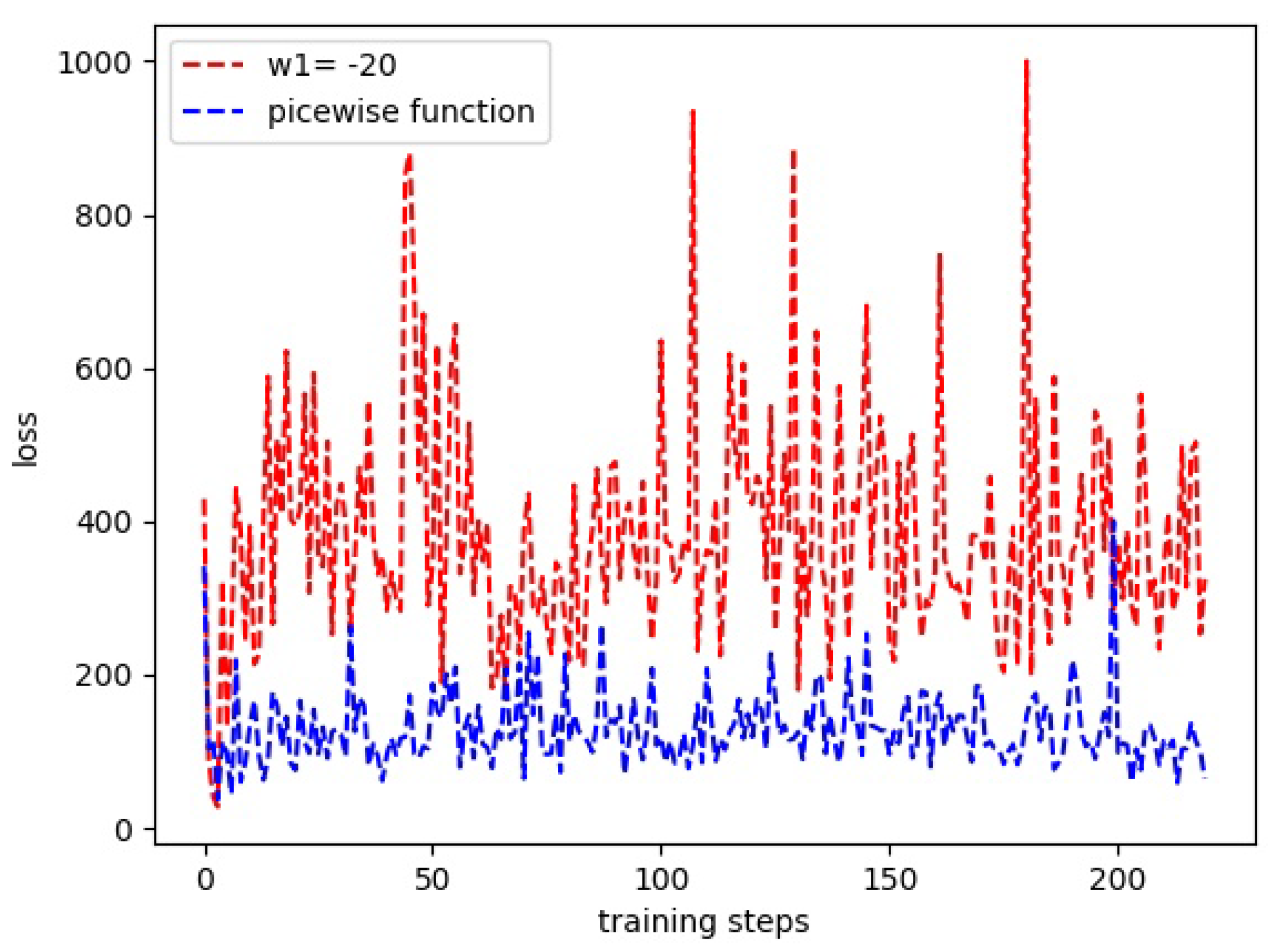
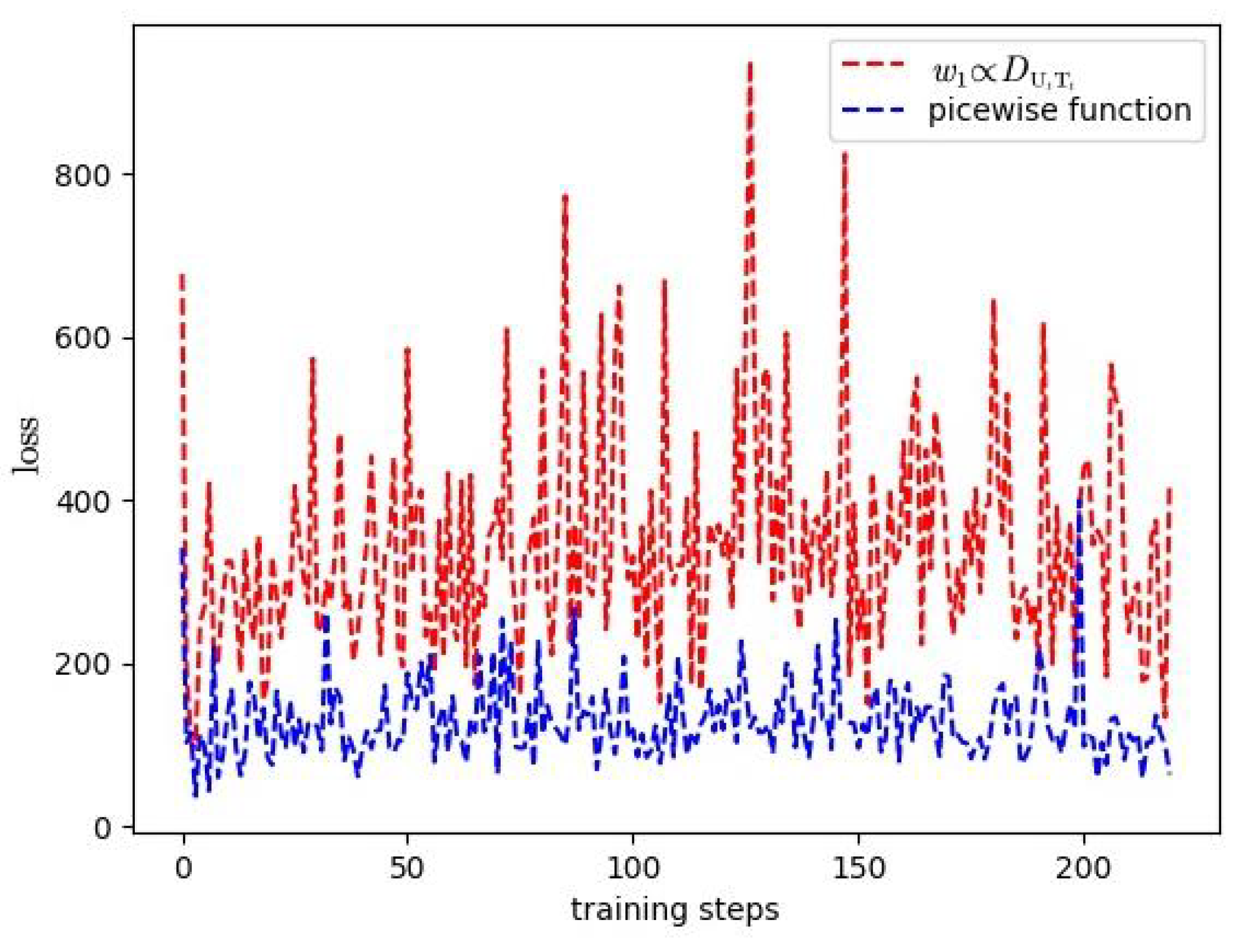
In this paper, an autonomous maneuver decision making method based on deep reinforcement learning is proposed for dual-UAV cooperative air combat. The main contributions are as follows. First, aiming at the problems of dimension explosion, sparse and delayed rewards and incomplete situation assessment, we discretize the continuous air combat state space into 13 dimensions for dimension reduction and quantitative description of air combat states. Then the situation assessment model is established based on the relative location between the UAV and the target. Second, a reward function is designed according to the situation assessment results which includes the real-time gain due to maneuver and the final combat winning/losing gain. Such a design helps to solve the problem of sparse and delayed reward in the games of long-running time for ending. Third, aiming at the problem of slow convergence caused by random sampling in conventional DQN learning, an improved priority sampling strategy is proposed to accelerate the convergence of the DQN network training. Fourth, we apply and modify the designed autonomous maneuver decision making method for the typical task of dual-UAV olive formation air combat, which enables the UAVs to own the capability of collision avoidance, formation and confrontation. Finally, the proposed method is validated by simulation using practical fixed-wing UAV models and compared with the DQN learning method without priority sampling. The simulation results show that our method can make the two UAVs defeat the enemy effectively and improve the performance in terms of the convergence speed.
The following parts are arranged as follows:
Section 2 is the problem formulation.
Section 3 is the air combat confrontation algorithm based on deep reinforcement learning.
Section 4 is the description of typical air combat scenarios and the design of dual-UAV cooperative autonomous maneuver strategy.
Section 5 conducts simulation analysis.
Section 6 summarizes the full paper.
















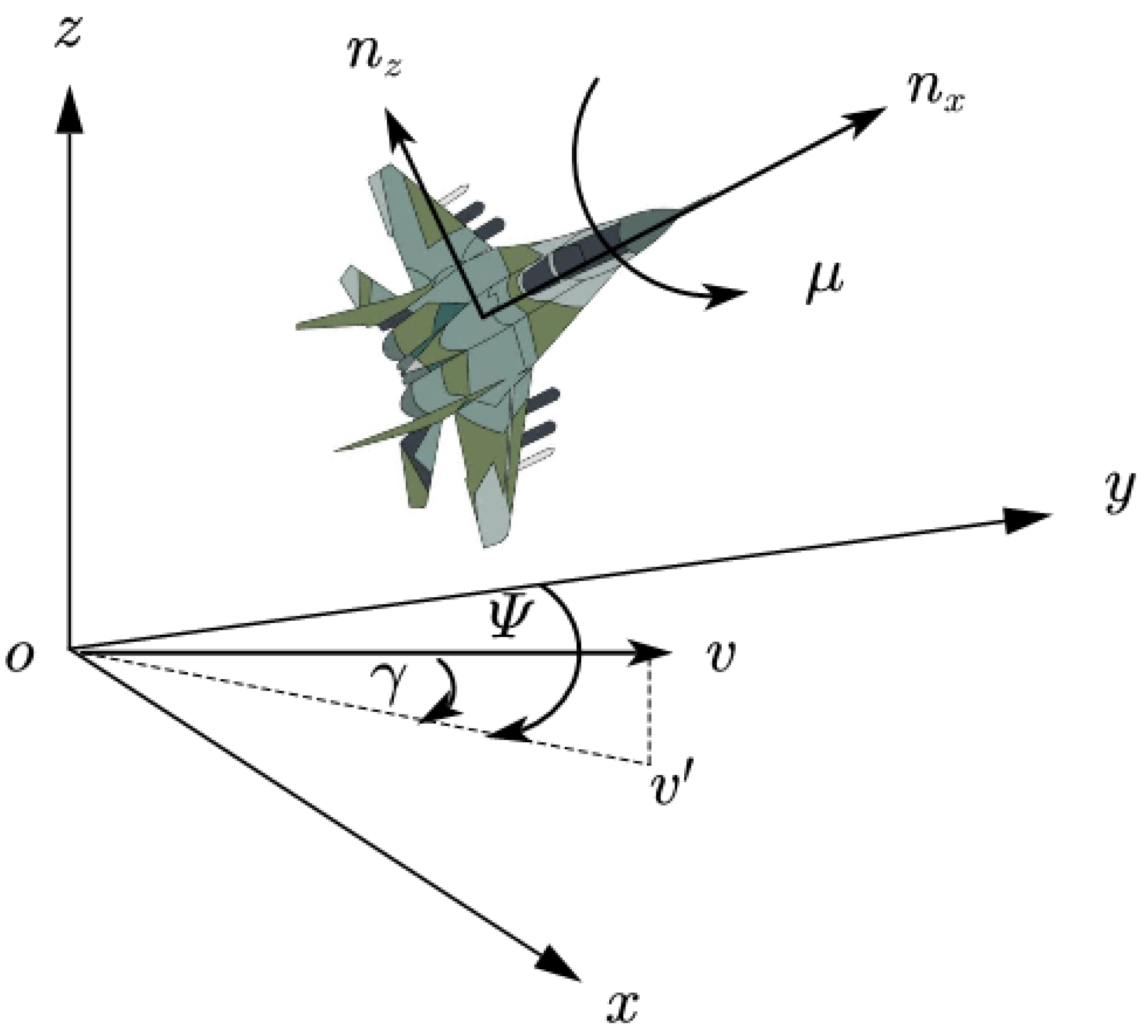{kind=link}
{kind=link}
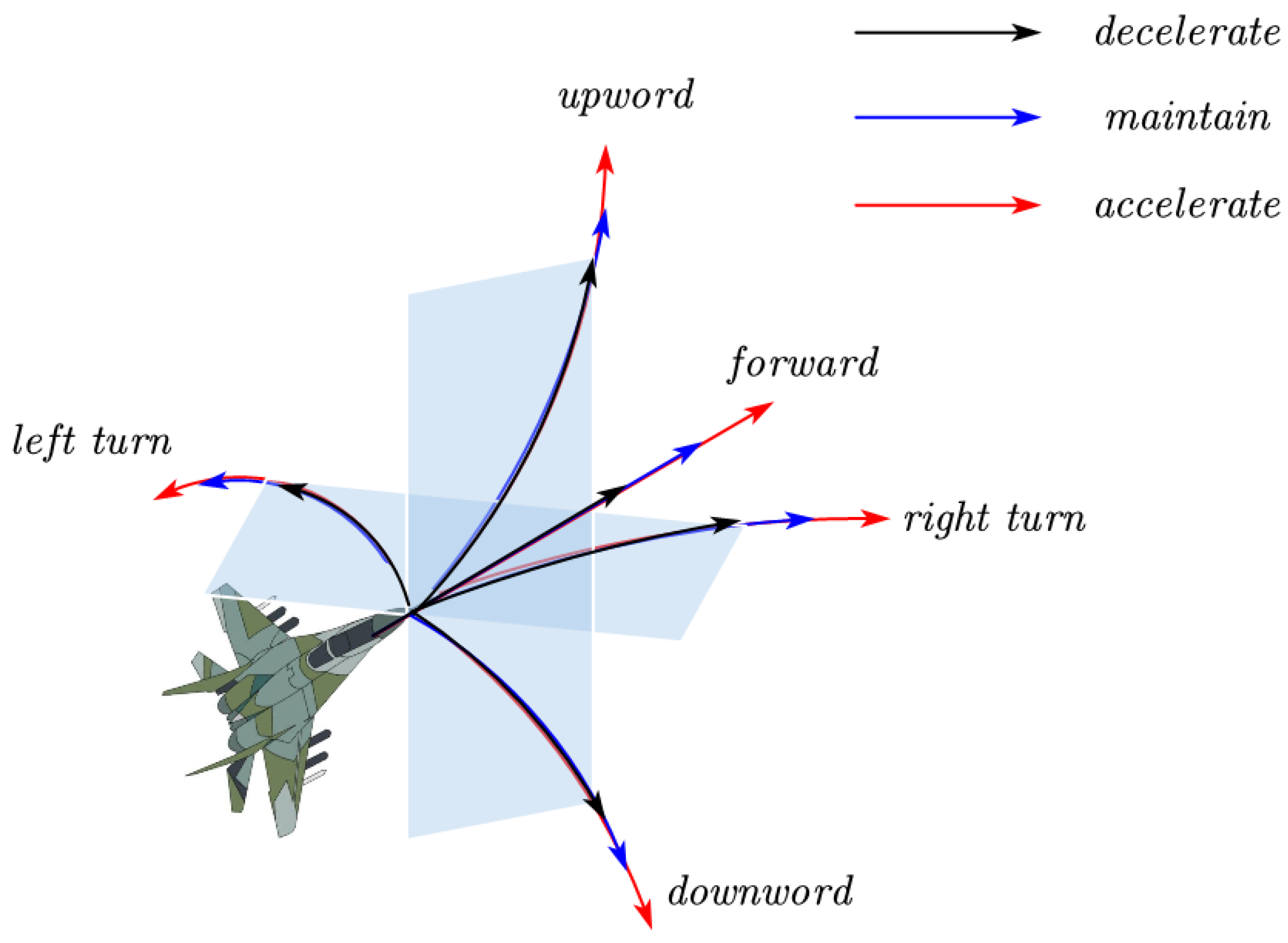{kind=link}
{kind=link}
{kind=link}
{kind=link}
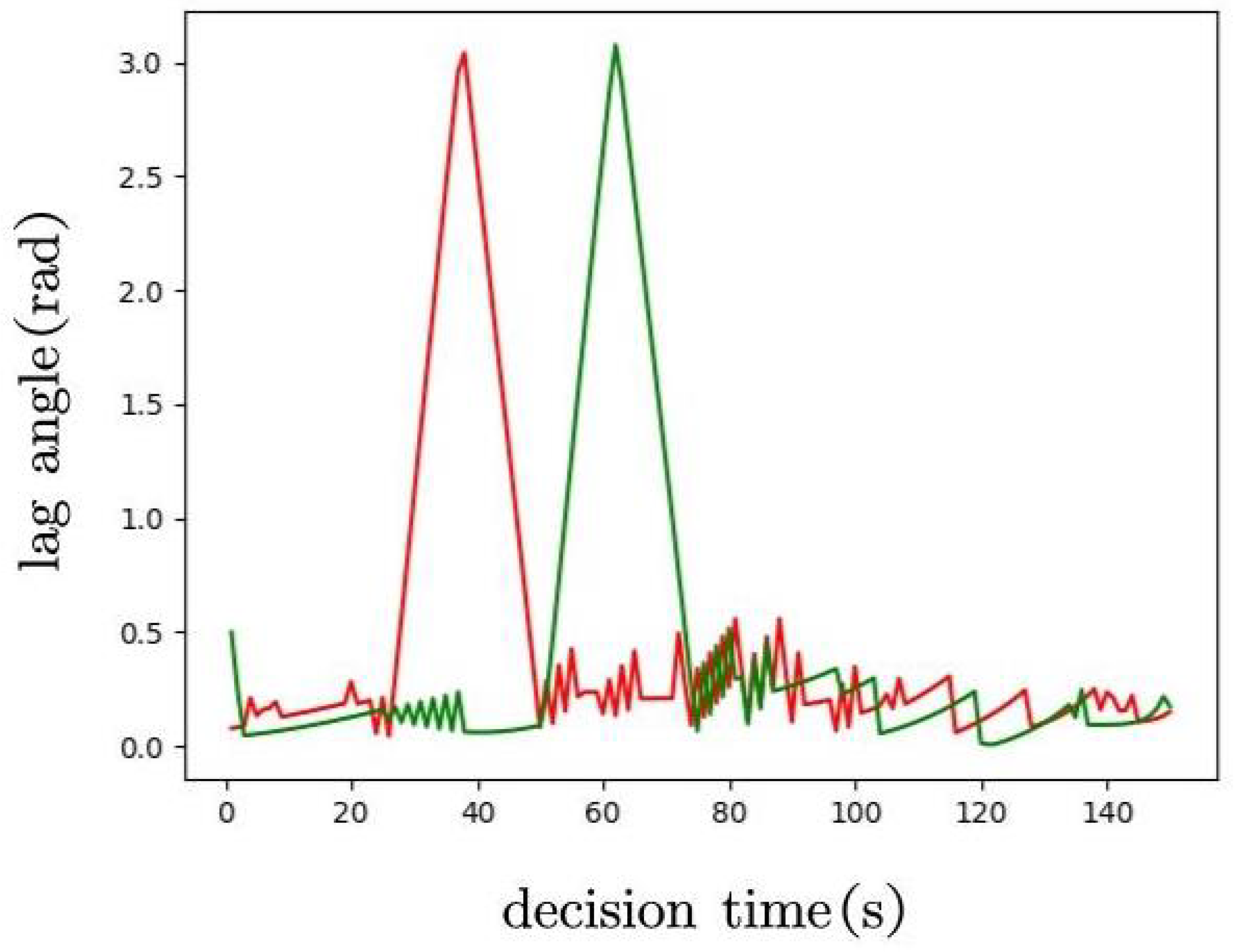{kind=link}
{kind=link}
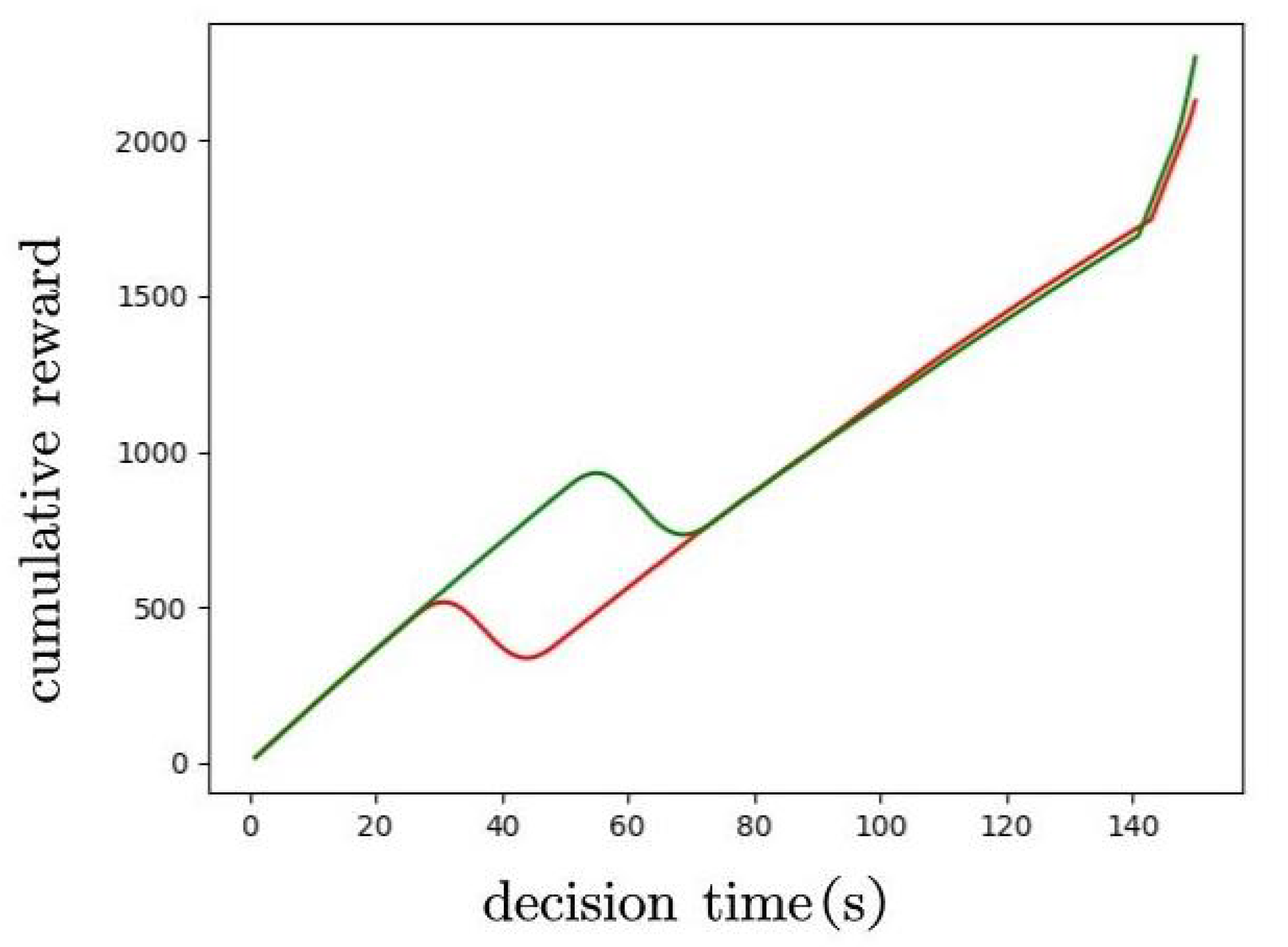{kind=link}
{kind=link}
{kind=link}
{kind=link}