
A Systematic Review on Machine Learning Techniques for Early Detection of Mental, Neurological and Laryngeal Disorders Using Patient’s Speech
 , ,
, ,
Abstract
:1. Introduction
2. Related Work
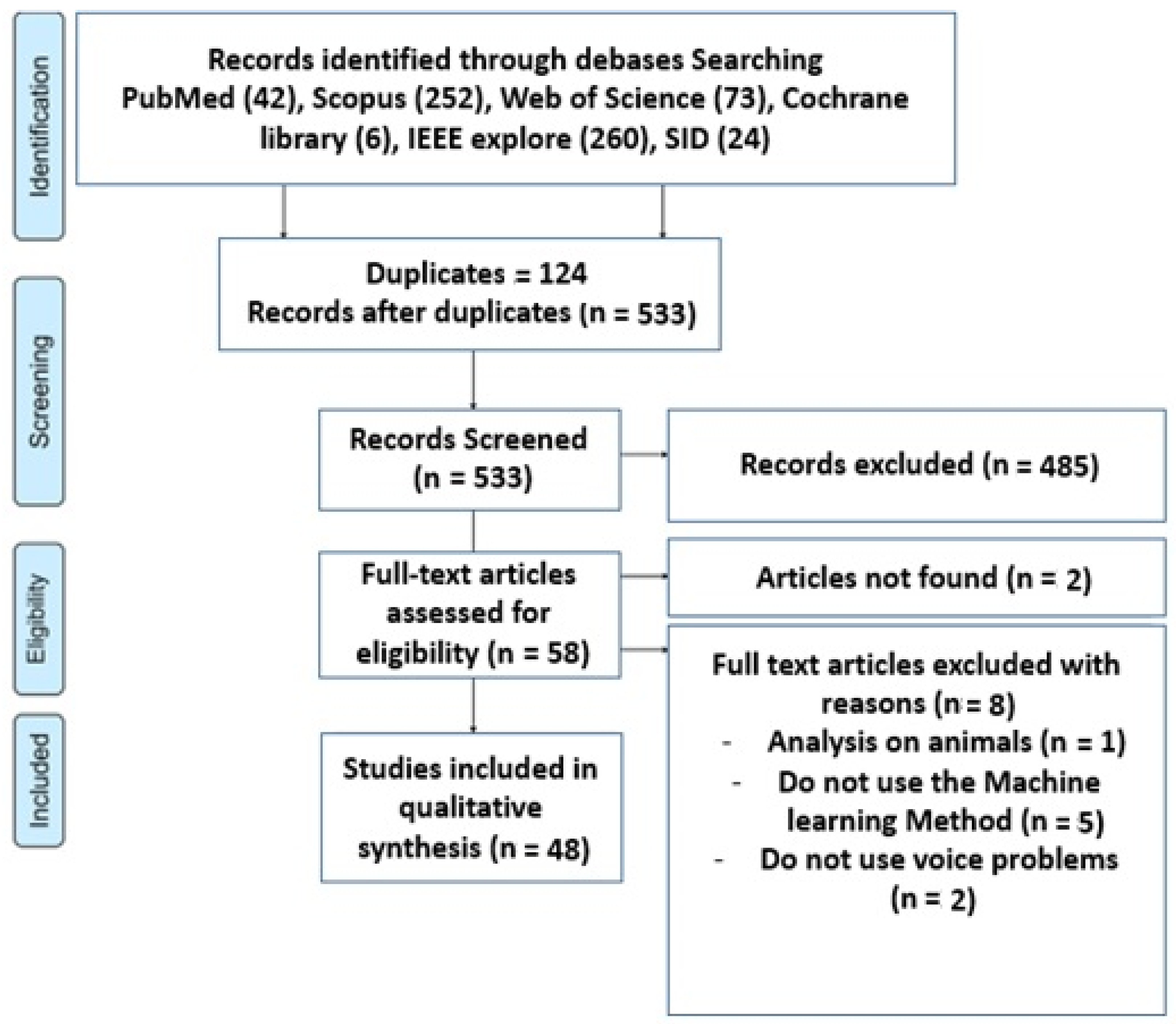
Materials and Methods
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Guntuku, S.C.; Yaden, D.B.; Kern, M.L.; Ungar, L.H.; Eichstaedt, J.C. Detecting depression and mental illness on social media: An integrative review. Curr. Opin. Behav. Sci. 2017, 18, 43–49. [Google Scholar] [CrossRef]
- Shin, D.; Cho, W.I.; Park, C.H.K.; Rhee, S.J.; Kim, M.J.; Lee, H.; Kim, N.S.; Ahn, Y.M. Detection of minor and major depression through voice as a biomarker using machine learning. J. Clin. Med. 2021, 10, 3046. [Google Scholar] [CrossRef] [PubMed]
- Espinola, C.W.; Gomes, J.C.; Pereira, J.M.S.; dos Santos, W.P. Detection of major depressive disorder using vocal acoustic analysis and machine learning—An exploratory study. Res. Biomed. Eng. 2021, 37, 53–64. [Google Scholar] [CrossRef]
- Ghasemzadeh, H.; Tajik Khass, M.; Khalil Arjmandi, M.; Pooyan, M. Detection of vocal disorders based on phase space parameters and Lyapunov spectrum. Biomed. Signal Process Control 2015, 22, 135–145. [Google Scholar] [CrossRef]
- Rahman, A.; Rizvi, S.S.; Khan, A.; Abbasi, A.A.; Khan, S.U.; Chung, T.S. Parkinson’s disease diagnosis in cepstral domain using MFCC and dimensionality reduction with SVM classifier. Mob. Inf. Sys. 2021, 2021, 8822069. [Google Scholar] [CrossRef]
- Vigneswari, D.A.; Aravinth, J. (Eds.) Parkinson’s disease Diagnosis using Voice Signals by Machine Learning Approach. In Proceedings of the 2021 International Conference on Recent Trends on Electronics, Information, Communication & Technology (RTEICT), Karnataka, India, 27–28 August 2021. [Google Scholar]
- Abdel-Hamid, O.; Mohamed, A.R.; Jiang, H.; Deng, L.; Penn, G.; Yu, D. Convolutional neural networks for speech recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 1533–1545. [Google Scholar] [CrossRef] [Green Version]
- Farhoumandi, N.; Mollaey, S.; Heysieattalab, S.; Zarean, M.; Eyvazpour, R. Facial emotion recognition predicts alexithymia using machine learning. Comput. Intell. Neurosci. 2021, 2021, 2053795. [Google Scholar] [CrossRef]
- Punithavathi, R.; Sharmila, M.; Avudaiappan, T.; Raj, I.I.; Kanchana, S.; Mamo, S.A. Empirical investigation for predicting depression from different machine learning based voice recognition techniques. Evid. Based Complement. Altern. Med. eCAM 2022, 2022, 6395860. [Google Scholar] [CrossRef]
- Li, M.; Tang, D.; Zeng, J.; Zhou, T.; Zhu, H.; Chen, B.; Zou, X. An automated assessment framework for atypical prosody and stereotyped idiosyncratic phrases related to autism spectrum disorder. Comput. Speech Lang. 2019, 56, 80–94. [Google Scholar] [CrossRef]
- Sumali, B.; Mitsukura, Y.; Liang, K.C.; Yoshimura, M.; Kitazawa, M.; Takamiya, A.; Fujita, T.; Mimura, M.; Kishimoto, T. Speech quality feature analysis for classification of depression and dementia patients. Sensors 2020, 20, 3599. [Google Scholar] [CrossRef]
- Izumi, K.; Minato, K.; Shiga, K.; Sugio, T.; Hanashiro, S.; Cortright, K.; Kudo, S.; Fujita, T.; Sado, M.; Maeno, T.; et al. Unobtrusive sensing technology for quantifying stress and well-being using pulse, speech, body motion, and electrodermal data in a workplace setting: Study concept and design. Front. Psychiatry 2021, 12, 611243. [Google Scholar] [CrossRef] [PubMed]
- Weintraub, M.J.; Posta, F.; Arevian, A.C.; Miklowitz, D.J. Using machine learning analyses of speech to classify levels of expressed emotion in parents of youth with mood disorders. J. Psychiatr. Res. 2021, 136, 39–46. [Google Scholar] [CrossRef] [PubMed]
- Xu, Z.J.; Wang, R.F.; Wang, J.; Yu, D.H. Parkinson’s disease detection based on spectrogram-deep convolutional generative adversarial network sample augmentation. IEEE Access 2020, 8, 206888–206900. [Google Scholar] [CrossRef]
- Hernández-Domínguez, L.; García-Cano, E.; Ratté, S.; Sierra, G. (Eds.) Detection of Alzheimer’s disease based on automatic analysis of common objects descriptions. In Proceedings of the 7th Workshop on Cognitive Aspects of Computational Language Learning, Berlin, Germany, 11 August 2016. [Google Scholar]
- Bachu, R.; Kopparthi, S.; Adapa, B.; Barkana, B. (Eds.) Separation of voiced and unvoiced using zero crossing rate and energy of the speech signal. In American Society for Engineering Education (ASEE) Zone Conference Proceedings; Society for Engineering Education: Washington, DC, USA, 2008. [Google Scholar]
- Porritt, K.; Gomersall, J.; Lockwood, C. JBI’s systematic reviews: Study selection and critical appraisal. AJN Am. J. Nurs. 2014, 114, 47–52. [Google Scholar] [CrossRef]
- Benba, A.; Jilbab, A.; Hammouch, A. Analysis of multiple types of voice recordings in cepstral domain using MFCC for discriminating between patients with Parkinson’s disease and healthy people. Int. J. Speech Technol. 2016, 19, 449–456. [Google Scholar] [CrossRef]
- Vasquez-Correa, J.C.; Arias-Vergara, T.; Orozco-Arroyave, J.R.; Eskofier, B.; Klucken, J.; Noth, E. Multimodal assessment of parkinson’s disease: A deep learning approach. IEEE J. Biomed. Health Informat. 2016, 23, 1618–1630. [Google Scholar] [CrossRef]
- Jeancolas, L.; Mangone, G.; Petrovska-Delacrétaz, D.; Benali, H.; Benkelfat, B.E.; Arnulf, I.; Corvol, J.C.; Vidailhet, M.; Lehéricy, S. Voice characteristics from isolated rapid eye movement sleep behavior disorder to early Parkinson’s disease. Park. Relat. Disord. 2022, 95, 86–91. [Google Scholar] [CrossRef]
- Zahid, L.; Maqsood, M.; Durrani, M.Y.; Bakhtyar, M.; Baber, J.; Jamal, H.; Mehmood, I.; Song, O.-Y. A spectrogram-based deep feature assisted computer-aided diagnostic system for parkinson’s disease. IEEE Access 2020, 8, 35482–35495. [Google Scholar] [CrossRef]
- Berus, L.; Klancnik, S.; Brezocnik, M.; Ficko, M. Classifying parkinson’s disease based on acoustic measures using artificial neural networks. Sensors 2019, 19, 16. [Google Scholar] [CrossRef] [Green Version]
- Ma, C.; Ouyang, J.; Chen, H.L.; Zhao, X.H. An efficient diagnosis system for parkinson’s disease using kernel-based extreme learning machine with subtractive clustering features weighting approach. Comput. Math. Methods Med. 2014, 2014, 985789. [Google Scholar] [CrossRef]
- Eni, M.; Dinstein, I.; Ilan, M.; Menashe, I.; Meiri, G.; Zigel, Y. Estimating Autism Severity in Young Children From Speech Signals Using a Deep Neural Network. IEEE Access 2020, 8, 139489–139500. [Google Scholar] [CrossRef]
- Lin, Y.; Gau, S.S.; Lee, C. A multimodal interlocutor-modulated attentional BLSTM for classifying autism subgroups during clinical interviews. IEEE J. Sel. Top. Signal Process. 2020, 14, 299–311. [Google Scholar] [CrossRef]
- Mahmoud, S.S.; Kumar, A.; Li, Y.; Tang, Y.; Fang, Q. Performance evaluation of machine learning frameworks for aphasia assessment. Sensors 2021, 21, 2582. [Google Scholar] [CrossRef] [PubMed]
- Fonseca, E.S.; Guido, R.C.; Scalassara, P.R.; Maciel, C.D.; Pereira, J.C. Wavelet time-frequency analysis and least squares support vector machines for the identification of voice disorders. Comput. Biol. Med. 2007, 37, 571–578. [Google Scholar] [CrossRef]
- Verikas, A.; Gelzinis, A.; Bacauskiene, M.; Hållander, M.; Uloza, V.; Kaseta, M. Combining image, voice, and the patient’s questionnaire data to categorize laryngeal disorders. Artif. Intell. Med. 2010, 49, 43–50. [Google Scholar] [CrossRef]
- Järvelin, A.; Juhola, M. Comparison of machine learning methods for classifying aphasic and non-aphasic speakers. Comput. Methods Programs Biomed. 2011, 104, 349–357. [Google Scholar] [CrossRef]
- Ali, S.M.; Karule, P.T. MFCC, LPCC, formants and pitch proven to be best features in diagnosis of speech disorder using neural networks and SVM. Int. J. Appl. Eng. Res. 2016, 11, 897–903. [Google Scholar]
- Corcoran, C.M.; Carrillo, F.; Fernández-Slezak, D.; Bedi, G.; Klim, C.; Javitt, D.C.; Bearden, C.E.; Cecchi, G.A. Prediction of psychosis across protocols and risk cohorts using automated language analysis. World Psychiatry 2018, 17, 67–75. [Google Scholar] [CrossRef] [Green Version]
- Behroozi, M.; Sami, A. A Multiple-classifier framework for parkinson’s disease detection based on various vocal tests. Int. J. Telemed. Appl. 2016, 2016, 6837498. [Google Scholar] [CrossRef] [Green Version]
- Bedi, G.; Cecchi, G.A.; Slezak, D.F.; Carrillo, F.; Sigman, M.; de Wit, H. A window into the intoxicated mind? Speech as an index of psychoactive drug effects. Neuropsychopharmacol. Off. Publ. Am. Coll. Neuropsychopharmacol. 2014, 39, 2340–2348. [Google Scholar] [CrossRef]
- Zhao, Z.; Bao, Z.; Zhang, Z.; Deng, J.; Cummins, N.; Wang, H.; Tao, J.; Schuller, B. Automatic assessment of depression from speech via a hierarchical attention transfer network and attention autoencoders. IEEE J. Sel. Top. Signal Process. 2020, 14, 423–434. [Google Scholar] [CrossRef]
- Bedi, G.; Carrillo, F.; Cecchi, G.A.; Slezak, D.F.; Sigman, M.; Mota, N.B.; Ribeiro, S.; Javitt, D.C.; Copelli, M.; Corcoran, C.M. Automated analysis of free speech predicts psychosis onset in high-risk youths. NPJ Schizophr. 2015, 1, 15030. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rezaii, N.; Walker, E.; Wolff, P. A machine learning approach to predicting psychosis using semantic density and latent content analysis. NPJ Schizophr. 2019, 5, 9. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gavrilescu, M.; Vizireanu, N. Feedforward neural network-based architecture for predicting emotions from speech. Data 2019, 4, 101. [Google Scholar] [CrossRef] [Green Version]
- Goldberg, S.B.; Flemotomos, N.; Martinez, V.R.; Tanana, M.J.; Kuo, P.B.; Pace, B.T.; Villatte, J.L.; Georgiou, P.G.; Van Epps, J.; Imel, Z.E.; et al. Machine learning and natural language processing in psychotherapy research: Alliance as example use case. J. Couns. Psychol. 2020, 67, 438–448. [Google Scholar] [CrossRef]
- Zhang, Y.; Qin, X.; Lin, Y.; Li, Y.; Wang, P.; Zhang, Z.; Li, X. Psychosis speech recognition algorithm based on deep embedded sparse stacked autoencoder and manifold ensemble. J. Biomed. Eng. 2021, 38, 655–662. [Google Scholar]
- Song, I.; Diederich, J. Speech analysis for mental health assessment using support vector machines. In Mental Health Informatics; Studies in Computational Intelligence; Springer: Berlin, Germany, 2014; pp. 79–105. [Google Scholar]
- Fischer, J.; Hammerschmidt, K. Ultrasonic vocalizations in mouse models for speech and socio-cognitive disorders: Insights into the evolution of vocal communication. Genes Brain Behav. 2011, 10, 17–27. [Google Scholar] [CrossRef] [Green Version]
- Di, Y.; Wang, J.; Li, W.; Zhu, T. Using i-vectors from voice features to identify major depressive disorder. J. Affective Disord. 2021, 288, 161–166. [Google Scholar] [CrossRef]
- McGinnis, E.W.; Anderau, S.P.; Hruschak, J.; Gurchiek, R.D.; Lopez-Duran, N.L.; Fitzgerald, K.; Rosenblum, K.L.; Muzik, M.; McGinnis, R.S. Giving voice to vulnerable children: Machine learning analysis of speech detects anxiety and depression in early childhood. IEEE J. Biomed. Health Informat. 2019, 23, 2294–2301. [Google Scholar] [CrossRef]
- Wang, J.; Zhang, L.; Liu, T.; Pan, W.; Hu, B.; Zhu, T. Acoustic Differences between healthy and depressed people: A cross situation study. BMC Psychiatry Res. Artic. 2019, 8, 300. [Google Scholar] [CrossRef] [Green Version]
- He, L.; Cao, C. Automated depression analysis using convolutional neural networks from speech. J. Biomed. Inform. 2018, 83, 103–111. [Google Scholar] [CrossRef]
- Jenei, A.Z.; Kiss, G. Severity estimation of depression using convolutional neural network. Period Polytech. Electr. Eng. Comput. sci. 2021, 65, 227–234. [Google Scholar] [CrossRef]
- Huang, Y.J.; Lin, Y.T.; Liu, C.C.; Lee, L.E.; Hung, S.H.; Lo, J.K.; Fu, L.C. Assessing schizophrenia patients through linguistic and acoustic features using deep learning techniques. IEEE Trans. Neural. Syst. Rehabil. Eng. 2022, 30, 947–956. [Google Scholar] [CrossRef] [PubMed]
- Xu, W.; Wang, W.; Portanova, J.; Chander, A.; Campbell, A.; Pakhomov, S.; Ben-Zeev, D.; Cohen, T. Fully automated detection of formal thought disorder with Time-series Augmented Representations for Detection of Incoherent Speech (TARDIS). J. Biomed. Inform. 2022, 126, 103998. [Google Scholar] [CrossRef] [PubMed]
- Fisher, D.J.; Labelle, A.; Knott, V.J. Auditory hallucinations and the mismatch negativity: Processing speech and non-speech sounds in schizophrenia. Int. J. Psychophysiol. 2008, 70, 3–15. [Google Scholar] [CrossRef]
- Todd, J.; Michie, P.T.; Schall, U.; Karayanidis, F.; Yabe, H.; Näätänen, R. Deviant matters: Duration, frequency, and intensity deviants reveal different patterns of mismatch negativity reduction in early and late schizophrenia. Biol. Psychiatry 2008, 63, 58–64. [Google Scholar] [CrossRef]
- Arevian, A.C.; Bone, D.; Malandrakis, N.; Martinez, V.R.; Wells, K.B.; Miklowitz, D.J.; Narayanan, S. Clinical state tracking in serious mental illness through computational analysis of speech. PLoS ONE 2020, 15, e0225695. [Google Scholar] [CrossRef]


{kind=link}
| Machine Learning | Speech | Neurological, Mental or Laryngeal | Diagnosis or Screening |
|---|---|---|---|
| Machine learning OR artificial intelligence OR deep learning OR neural networks OR data mining OR text mining | Speech or voice | Neurological or mental or laryngeal | Prediction OR diagnosis OR detection OR screening OR predict |
| Row | Disorders | Articles % (n) | |
|---|---|---|---|
| 1 | Neurological disorders | PD–autism | 25 (12) |
| 2 | Laryngeal disorders | Aphasia–speech | 12.5 (6) |
| 3 | Mental disorders | MDD–anxiety and depression–schizophrenia–bipolar | 62.5 (30) |
| Author (Ref#) | Country | Year | Disease (Category) | Algorithm (Metric) | Features |
|---|---|---|---|---|---|
| Low et al. [1] | 2017 | MDD (Mental) | SVM (AUC = 89%) | Prosodic | |
| Shin et al. [2] | Korea | 2021 | Anxiety, stress and minor depression (Mental) | MLP (AUC = 65.9%) | Acoustic |
| Espinola et al. [3] | Brazil | 2021 | MDD (Mental) | SVM (ACC = 89.14%) | Prosodic |
| Ghasemzadeh et al. [4] | Iran | 2015 | Voca l(Laryngeal) | SVM (ACC = 99.3%) | Acoustic |
| Rahman et al. [5] | Pakistan | 2021 | Parkinson (Neurological) | SVM | Acoustic |
| Vigneswari et al. [6] | Canada | 2021 | Parkinson (Neurological) | Gradient boosting (ACC = 95.16%) | Acoustic |
| Osman et al. [7] | 2014 | Anxiety, stress and minor depression (Mental) | SVM (ACC = 77.5) | Acoustic | |
| Farhoumandi et al. [8] | Iran | 2021 | MDD (Mental) | SVM (ACC = 81.81%) | Acoustic |
| Punithavathi et al. [9] | 2022 | Anxiety, stress and minor depression (Mental) | Deep learning (ACC = 90.5) | Acoustic | |
| Ming ET AL. [10] | 2019 | Autism (Neurological) | SVM | Prosodic | |
| Sumali et al. [11] | Korea | 2021 | Anxiety, stress and minor depression (Mental) | SVM (ACC = 67.2) | Acoustic |
| Izumi et al. [12] | China | 2021 | Anxiety, stress and minor depression (Mental) | Gradient boosting | Prosodic |
| Weintraub et al. [13] | USA | 2021 | Bipolar (Mental) | Decision tree (ACC = 81.8%) | Prosodic |
| Xu et al. [14] | China | 2020 | Parkinson (Neurological) | Deep learning (ACC = 91.25%) | Acoustic |
| Benba et al. [18] | 2016 | Parkinson (Neurological) | SVM | Acoustic | |
| Vasquez-Correa et al. [19] | Colombia | 2019 | Parkinson (Neurological) | Deep learning (ACC = 97.3%) | Acoustic |
| Jeancolas et al. [20] | France | 2022 | Parkinson (Neurological) | SVM (ACC = 89%) | Prosodic |
| Zahid et al. [21] | Pakistan | 2020 | Parkinson (Neurological) | Deep learning (ACC = 99.7%) | Acoustic |
| Berus et al. [22] | 2018 | Parkinson (Neurological) | Artificial neural networks | Acoustic | |
| Chao et al. [23] | 2014 | Parkinson (Neurological) | SVM | Acoustic | |
| Eni et al. [24] | Israel | 2020 | Autism (Neurological) | Deep learning (RMSE = 4.65) | Prosodic |
| Lin et al. [25] | Taiwan | 2020 | Autism (Neurological) | SVM (ACC = 66.8) | Acoustic |
| Mahmoud et al. [26] | 2021 | Aphasia (Laryngeal) | Deep learning (ACC = 99.3) | Acoustic | |
| Fonseca et al. [27] | Brazil | 2007 | Aphasia (Laryngeal) | SVM (ACC = 90%) | Acoustic |
| Verikas et al. [28] | Litvania | 2010 | Aphasia (Laryngeal) | SVM (ACC = 72.1%) | Acoustic |
| Antti et al. [29] | 2011 | Aphasia (Laryngeal) | KNN (90.5%) | Acoustic | |
| Ali et al. [30] | 2016 | Speech disorders (Laryngeal) | SVM (ACC = 100%) | Acoustic | |
| Corcoran et al. [31] | USA | 2018 | MDD (Mental) | UCLA classifier | Acoustic |
| Behroozi et al. [32] | 2016 | MDD (Mental) | SVM (ACC = 87.5%) | Acoustic | |
| Bedi et al. [33] | USA | 2014 | MDD (Mental) | SVM (ACC = 88%) | Prosodic |
| Zhao et al. [34] | China | 2020 | MDD (Mental) | Neural network (RMSE = 5.51) | Prosodic |
| Bedi et al. [35] | USA | 2015 | Schizophrenia | LSA | Prosodic |
| Rezaii et al. [36] | USA | 2019 | MDD (Mental) | Neural network (ACC = 93%) | Prosodic |
| Gavrilescu et al. [37] | Romania | 2019 | MDD (Mental) | Neural network (ACC = 80.75) | Prosodic |
| Goldberg et al. [38] | USA | 2020 | MDD (Mental) | NLP | Acoustic |
| Zhang et al. [39] | China | 2021 | MDD (Mental) | Deep learning | Acoustic |
| Song et al. [40] | Singapore | 2014 | MDD (Mental) | SVM | Acoustic |
| Fischer et al. [41] | Germany | 2011 | MDD (Mental) | Acoustic | |
| Di et al. [42] | China | 2021 | MDD (Mental) | i-Vector | Acoustic |
| McGinnis et al. [43] | India | 2019 | Anxiety, stress and minor depression (Mental) | SVM (ACC = 80%) | Acoustic |
| Wang et al. [44] | 2019 | Anxiety, stress and minor depression (Mental) | MANCOVA | Acoustic | |
| He et al. [45] | China | 2018 | Anxiety, stress and minor depression (Mental) | CNN (RMSE = 10.44) | Acoustic |
| Jenei et al. [46] | Hungary | 2021 | Anxiety, stress and minor depression (Mental) | CNN (ACC = 85.2%) | Acoustic |
| Huang et al. [47] | China | 2020 | Schizophrenia (Mental) | Deep learning (ACC = 84%) | Prosodic |
| Xu et al. [48] | 2022 | Schizophrenia (Mental) | Time series | Prosodic | |
| Fisher et al. [49] | Canada | 2008 | Schizophrenia (Mental) | Mismatch negative (ACC = 82–99%) | Prosodic |
| Juanita et al. [50] | 2007 | Schizophrenia (Mental) | Mismatch negative | Prosodic | |
| Arevian et al. [51] | USA | 2020 | Schizophrenia (Mental) | SVM (AUC = 81%) | Prosodic |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sayadi, M.; Varadarajan, V.; Langarizadeh, M.; Bayazian, G.; Torabinezhad, F. A Systematic Review on Machine Learning Techniques for Early Detection of Mental, Neurological and Laryngeal Disorders Using Patient’s Speech. Electronics 2022, 11, 4235. https://doi.org/10.3390/electronics11244235
Sayadi M, Varadarajan V, Langarizadeh M, Bayazian G, Torabinezhad F. A Systematic Review on Machine Learning Techniques for Early Detection of Mental, Neurological and Laryngeal Disorders Using Patient’s Speech. Electronics. 2022; 11(24):4235. https://doi.org/10.3390/electronics11244235
Chicago/Turabian StyleSayadi, Mohammadjavad, Vijayakumar Varadarajan, Mostafa Langarizadeh, Gholamreza Bayazian, and Farhad Torabinezhad. 2022. "A Systematic Review on Machine Learning Techniques for Early Detection of Mental, Neurological and Laryngeal Disorders Using Patient’s Speech" Electronics 11, no. 24: 4235. https://doi.org/10.3390/electronics11244235