
Suspicious Actions Detection System Using Enhanced CNN and Surveillance Video

 ,
,  , ,
, ,
Abstract
:1. Introduction
2. Related Works
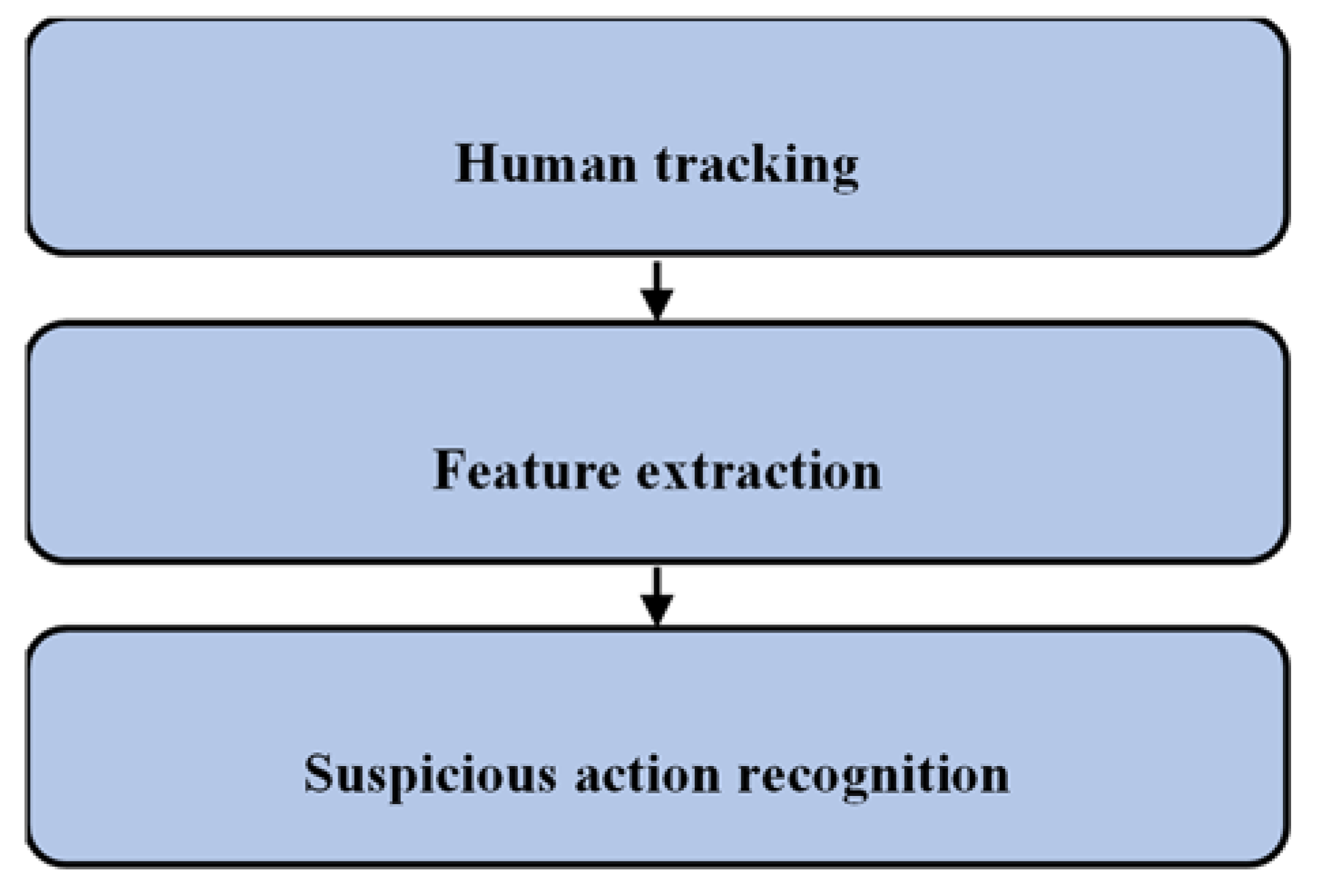
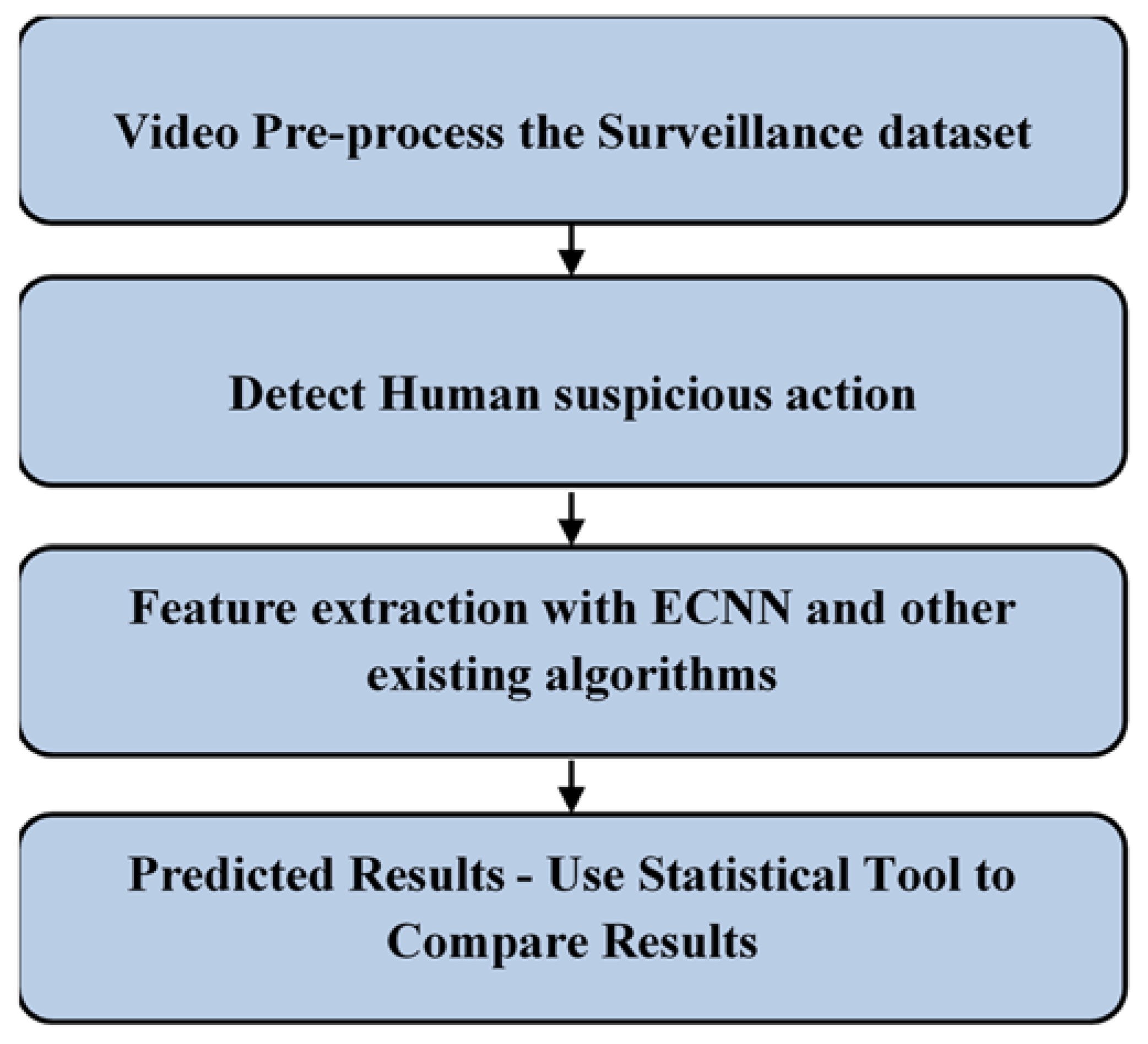
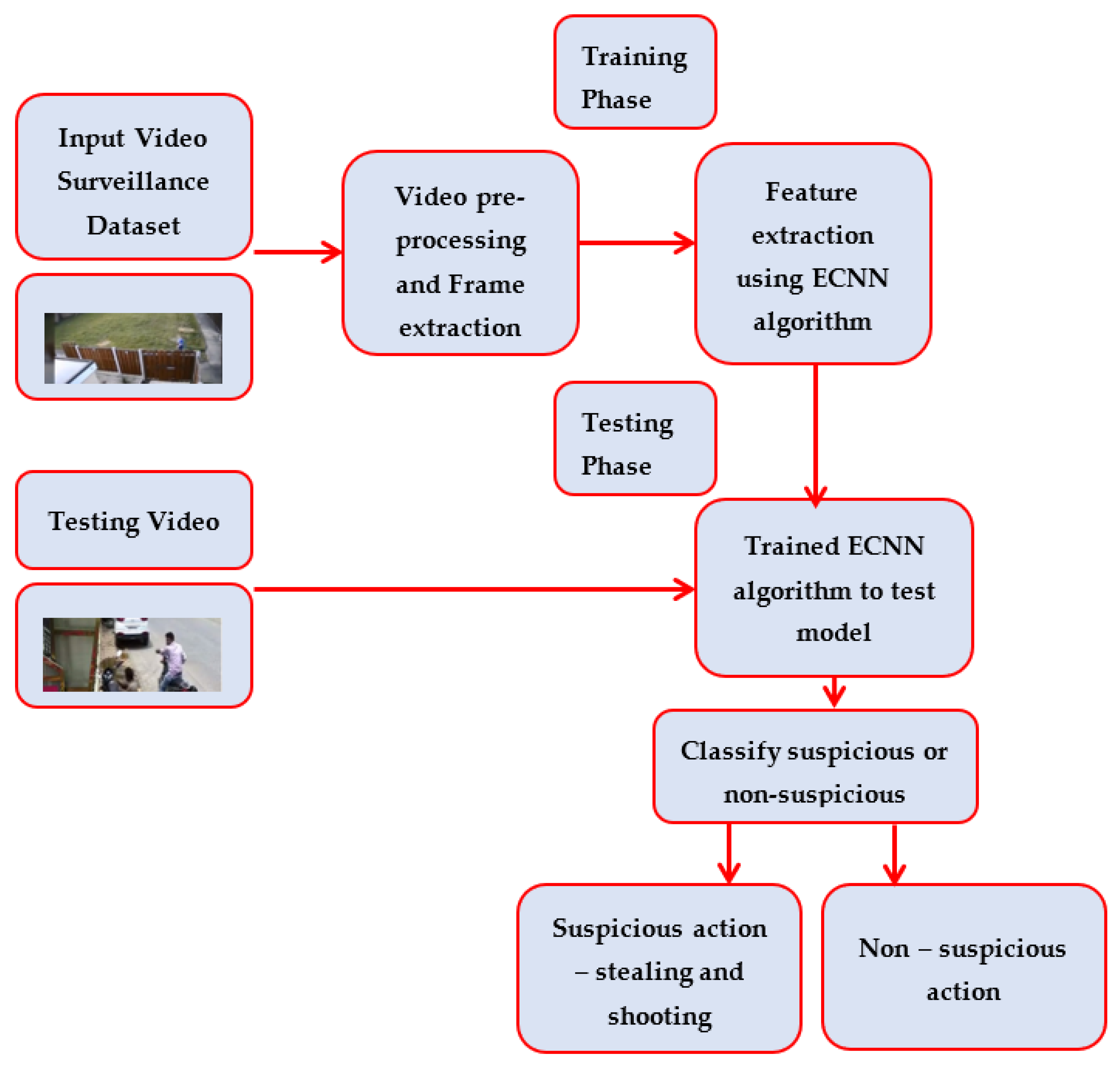
3. Materials and Methods
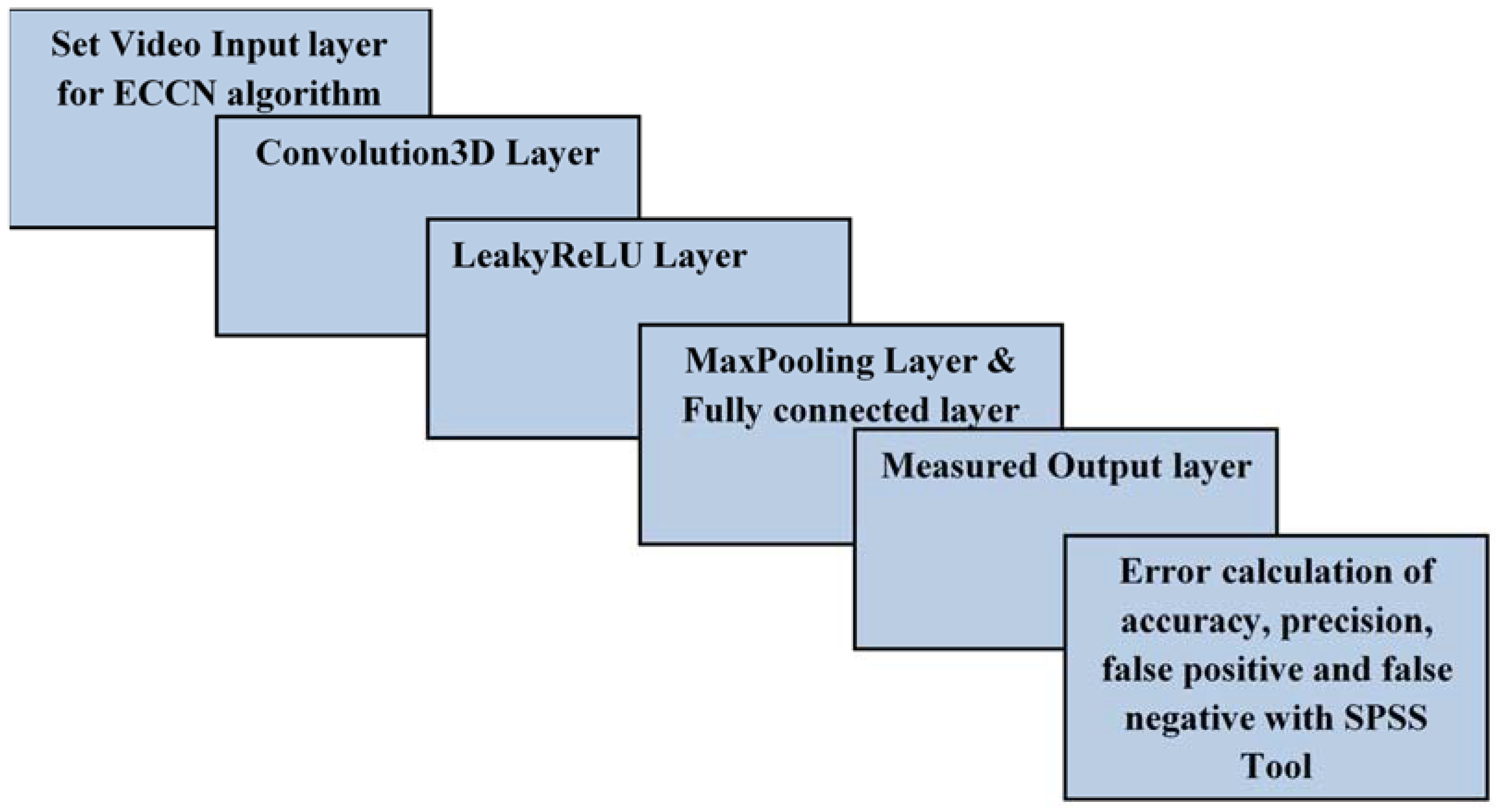
3.1. Proposed Algorithm: ECNN
3.2. Experiment Setup and System Specification
| Algorithm 1: Proposed ECNN algorithm |
| //call all package import numpy, Activation, Conv3D, Dense, Dropout, Flatten, MaxPooling3D import MaxPooling2D, LeakyReLU, categorical_crossentropy import Sequential, Adam, np_utils, ModelCheckpoint, Model, Input, define ecnn() // define Enhanced CNN model { set Input(video to framed image) // preprocess done apply Conv3D() function // feature map input is feed to kernel 3 × 3 size as filter apply LeakyReLU() function // convert negative value to positive value as activation function for set of vector values for threshold apply Conv3D() // feature map input is feed to kernel 3 × 3 size as filter execute LeakyReLU() // convert negative value to positive value as activation function for set of vector values } // parallel compute and train video data For i = 1 to 3) { |
| apply Conv3D() // feature map input is feed to kernel 3 × 3 size as filter |
| execute LeakyReLU() // convert negative value to positive value as activation function for set of vector values threshold |
| apply MaxPooling3D() // extract the maximum value from 3 × 3 vector apply Conv3D() // feature map input is feed to kernel 3 × 3 size as filter |
| apply LeakyReLU() // convert negative value to positive value as activation function for set of vector values threshold |
| apply MaxPooling3D() // extract the maximum value from 3 × 3 vector apply Conv3D() // feature map input is feed to kernel 3 × 3 size as filter |
| execute LeakyReLU() // convert negative value to positive value as activation function for set of vector values threshold |
| apply MaxPooling3D() // extract the maximum value from 3 × 3 vector |
| } apply conv3D(i) // feature map input is feed to kernel 3 × 3 size as filter apply MaxPooling3D() // extract the maximum value from 3 × 3 vector apply Flatten() // from fully convolution of matrix value to vector row apply Dense() // for each neuron set input, weight and bias and find a output |
3.3. Performance Parameters for Suspicious-Action Detection
4. Results and Experiment
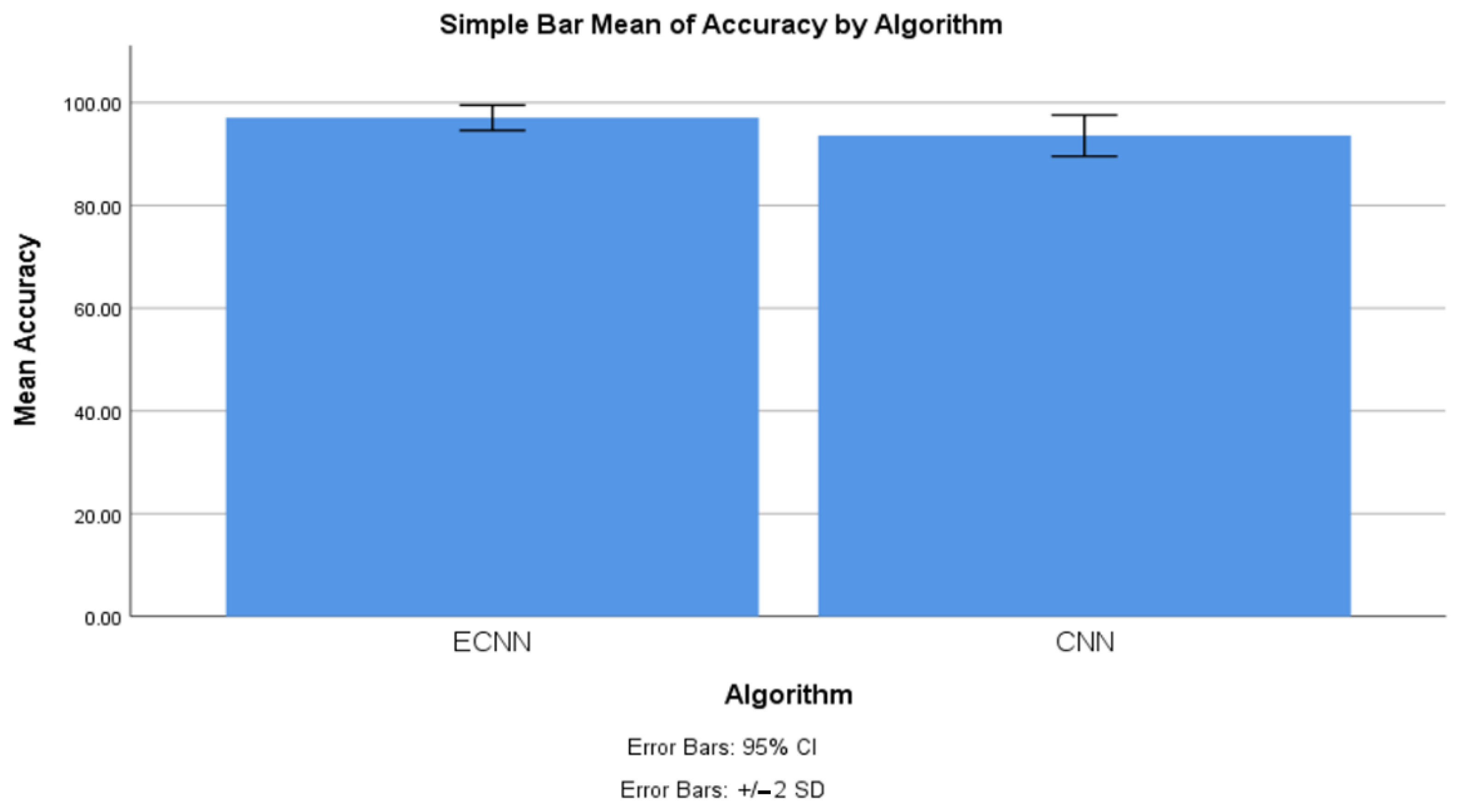
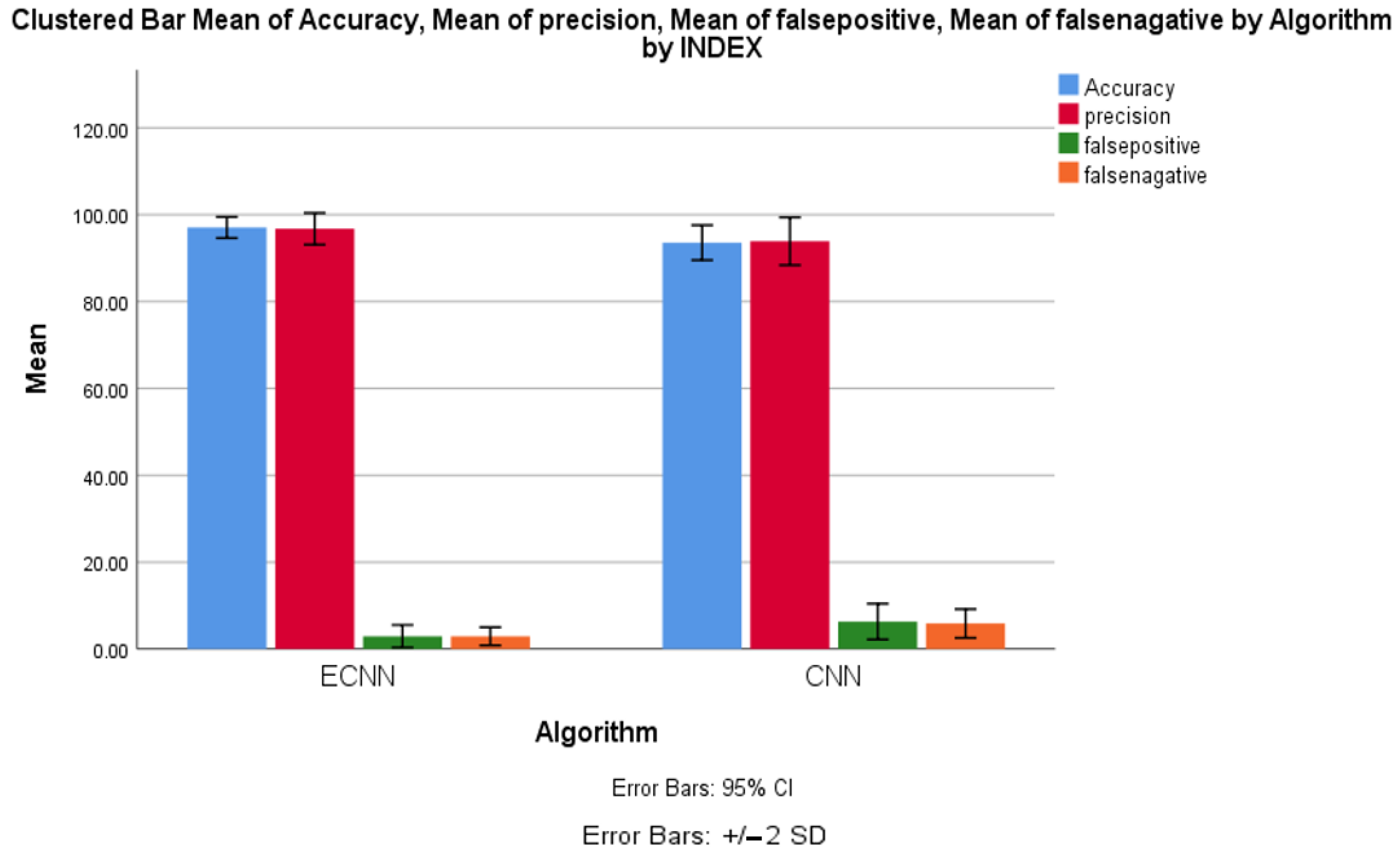
4.1. Accuracy between ECNN and CNN
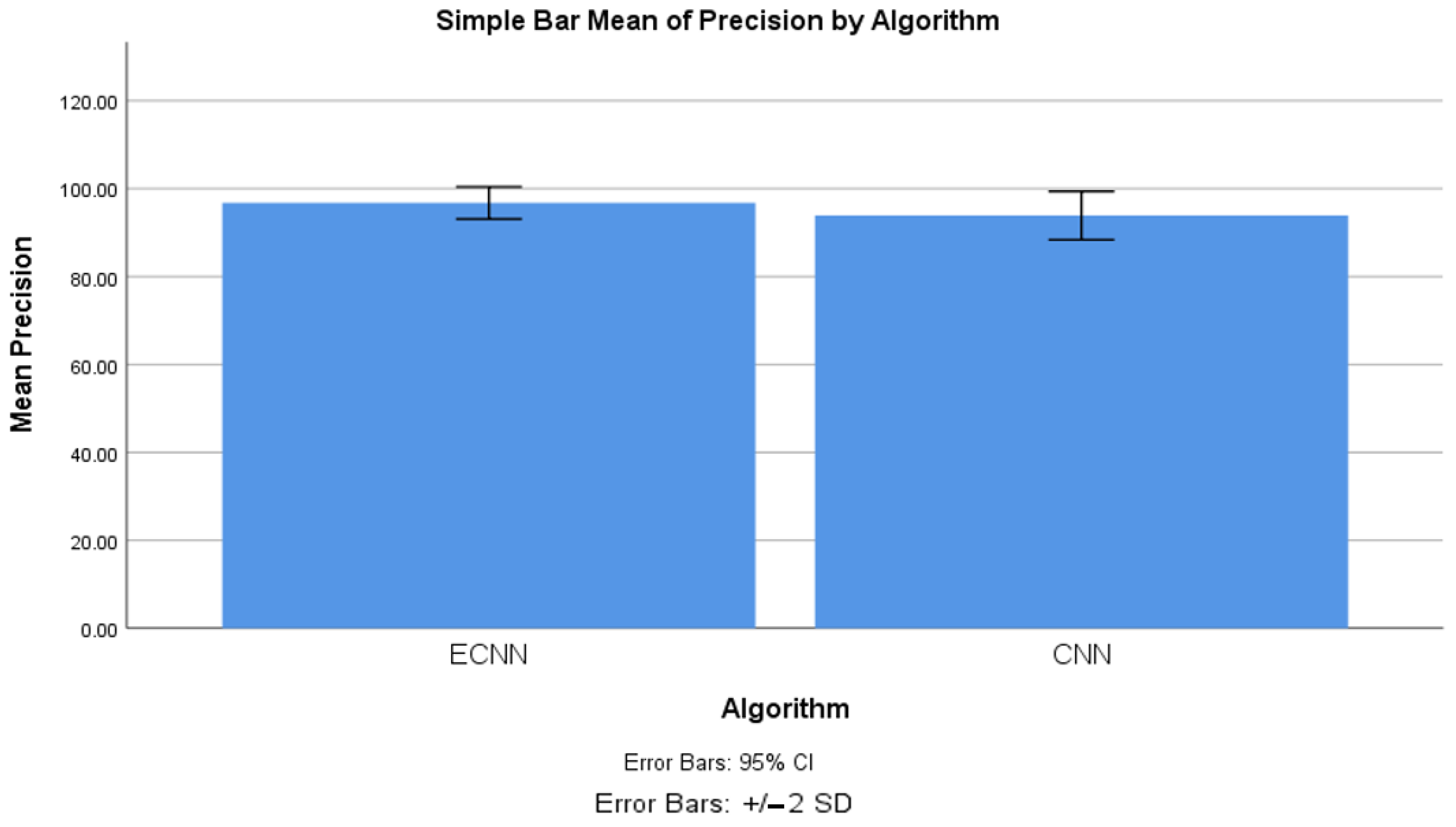
4.2. Precision between ECNN and CNN
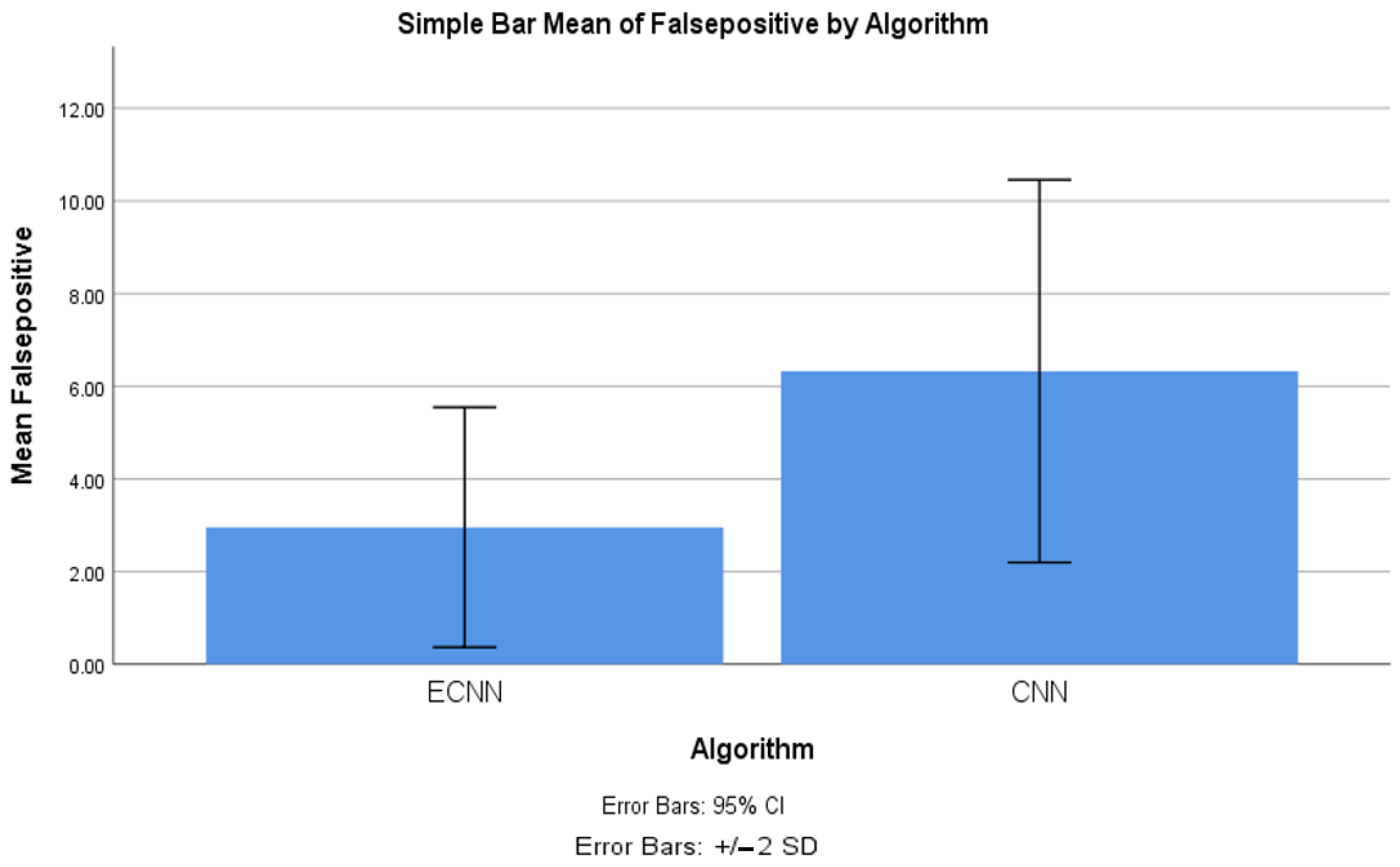
4.3. False Positive between ECNN and CNN
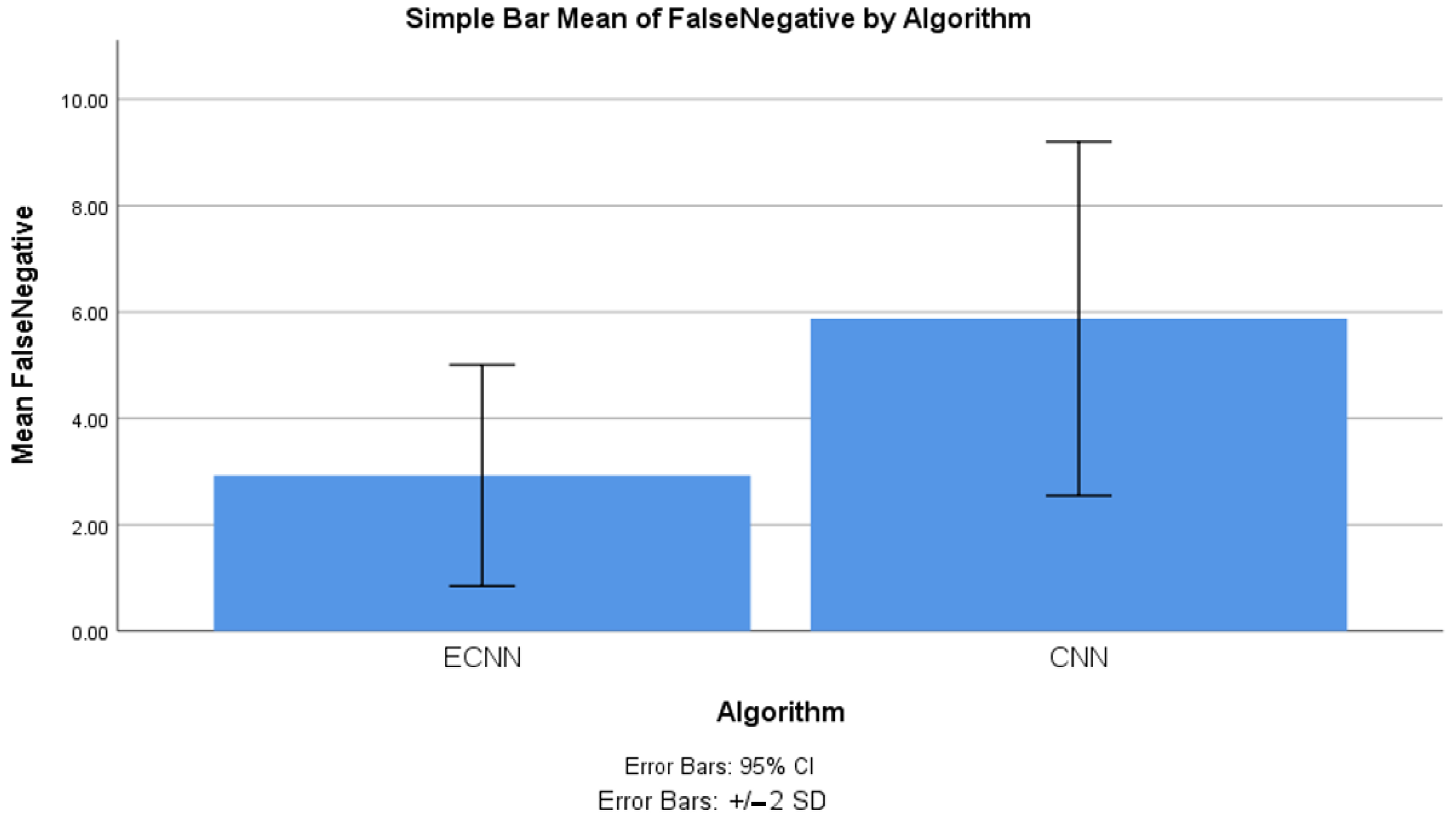
4.4. False Negative between ECNN and CNN
5. Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Bouma, H.; Baan, J.; Burghouts, G.J.; Eendebak, P.; Van Huis, J.R.; Dijk, J.; Van Rest, J.H.C. Rest Automatic detection of suspicious behavior of pickpockets with track-based features in a shopping mall. In Optics and Photonics for Counterterrorism, Crime Fighting, and Defence X; and Optical Materials and Biomaterials in Security and Defence Systems Technology XI; SPIE: Washington, DC, USA, 2014; Volume 9253. [Google Scholar] [CrossRef]
- Bouma, H.; Schutte, K.; Hove, J.-M.T.; Burghouts, G.J.; Baan, J. Flexible human-definable automatic behavior analysis for suspicious activity detection in surveillance cameras to protect critical infrastructures. In Counterterrorism, Crime Fighting, Forensics, and Surveillance Technologies II; SPIE: Washington, DC, USA, 2018; Volume 108020N. [Google Scholar] [CrossRef]
- Kadam, P.; Gawande, S.; Thorat, A.; Mule, R. Suspicious Activity Detection using Image Processing. J. Sci. Technol. 2021, 6, 114–119. [Google Scholar] [CrossRef]
- Scaria, E.; Aby Abahai, T.; Isaac, E. Suspicious Activity Detection in Surveillance Video using Discriminative Deep Belief Network. Int. J. Control Theory Appl. 2016, 9, 1–7. [Google Scholar]
- Loganathan, S.; Kariyawasam, G.; Sumathipala, P. Suspicious Activity Detection in Surveillance Footage. In Proceedings of the 2019 International Conference on Electrical and Computing Technologies and Applications (ICECTA), Ras Al Khaimah, United Arab Emirates, 19–21 November 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Bora, T.S.; Rokade, M.D. Human suspicious activity detection system using CNN model for video surveillance. Int. J. Adv. Res. Innov. Ideas Educ. 2021, 7, 688–694. [Google Scholar]
- Shivthare, K.V.; Bhujbal, P.D.; Darekar, A.P. Suspicious activity detection network for video surveillance using machine learning. Int. J. Adv. Sci. Res. Eng. Trends 2021, 6, 88–90. [Google Scholar]
- Elhamod, M.; Levine, M.D. Automated Real-Time Detection of Potentially Suspicious Behavior in Public Transport Areas. IEEE Trans. Intell. Transp. Syst. 2013, 14, 688–699. [Google Scholar] [CrossRef]
- Alavudeen Basha, A.; Parthasarathy, P.; Vivekanandan, S. Detection of Suspicious Human Activity based on CNN-DBNN Algorithm for Video Surveillance Applications. In Innovations in Power and Advanced Computing Technologies (i-PACT); IEEE: Toulouse, France, 2019; pp. 1–7. [Google Scholar] [CrossRef]
- Amrutha, C.; Jyotsna, C.; Amudha, J. Deep Learning Approach for Suspicious Activity Detection from Surveillance Video. In Proceedings of the 2nd International Conference on Innovative Mechanisms for Industry Applications (ICIMIA), Bangalore, India, 5–7 March 2020; pp. 335–339. [Google Scholar] [CrossRef]
- Singh, V.; Singh, S.; Gupta, P. Real-Time Anomaly Recognition Through CCTV Using Neural Networks. Procedia Comput. Sci. 2020, 173, 254–263. [Google Scholar] [CrossRef]
- Saba, T.; Rehman, A.; Latif, R.; Fati, S.M.; Raza, M.; Sharif, M. Suspicious Activity Recognition Using Proposed Deep L4-Branched-Actionnet with Entropy Coded Ant Colony System Optimization. In IEEE Access; IEEE: Toulouse, France, 2021; Volume 9, pp. 89181–89197. [Google Scholar] [CrossRef]
- Mehmood, A. LightAnomalyNet: A Lightweight Framework for Efficient Abnormal Behavior Detection. Sensors 2021, 21, 8501. [Google Scholar] [CrossRef] [PubMed]
- Martínez-Mascorro, G.A.; Abreu-Pederzini, J.R.; Ortiz-Bayliss, J.C.; Garcia-Collantes, A.; Terashima-Marín, H. Criminal Intention Detection at Early Stages of Shoplifting Cases by Using 3D Convolutional Neural Networks. Computation 2021, 9, 24. [Google Scholar] [CrossRef]
- Phyo, C.N.; Zin, T.T.; Tin, P. Deep Learning for Recognizing Human Activities Using Motions of Skeletal Joints. IEEE Trans. Consum. Electron. 2019, 65, 243–252. [Google Scholar] [CrossRef]
- Ramzan, M.; Abid, A.; Khan, H.U.; Awan, S.M.; Ismail, A.; Ahmed, M.; Ilyas, M.; Mahmood, A. A Review on State-of-the-Art Violence Detection Techniques. In IEEE Access; IEEE: Toulouse, France, 2019; Volume 7, pp. 107560–107575. [Google Scholar] [CrossRef]
- Ullah, F.U.M.; Muhammad, K.; Haq, I.U.; Khan, N.; Heidari, A.A.; Baik, S.W.; de Albuquerque, V. AI-Assisted Edge Vision for Violence Detection in IoT-Based Industrial Surveillance Networks. IEEE Trans. Ind. Inform. 2022, 18, 5359–5370. [Google Scholar] [CrossRef]
- Zhang, T.; Aftab, W.; Mihaylova, L.; Langran-Wheeler, C.; Rigby, S.; Fletcher, D.; Maddock, S.; Bosworth, G. Recent Advances in Video Analytics for Rail Network Surveillance for Security, Trespass and Suicide Prevention—A Survey. Sensors 2022, 22, 4324. [Google Scholar] [CrossRef]
- Sharma, V.; Gupta, M.; Pandey, A.K.; Mishra, D.; Kumar, A. A Review of Deep Learning-based Human Activity Recognition on Benchmark Video Datasets. Appl. Artif. Intell. 2022, 36, 2093705. [Google Scholar] [CrossRef]
- Sultani, W.; Chen, C.; Shah, M. Real-world anomaly detection in surveillance videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; Center for Research in Computer Vision (CRCV); IEEE: Toulouse, France, 2018; pp. 1–10. [Google Scholar]
- Available online: https://docs.opencv.org/3.4/d0/da7/videoio_overview.html (accessed on 6 September 2022).
- Lee, D.-G.; Suk, H.-I.; Park, S.-K.; Lee, S.-W. Motion Influence Map for Unusual Human Activity Detection and Localization in Crowded Scenes. In IEEE Transactions on Circuits and Systems for Video Technology; IEEE: Toulouse, France, 2015; Volume 25, pp. 1612–1623. [Google Scholar] [CrossRef]
- Rolando Jesus Cardenas, T.; César, A. Beltrán Castañón and Juan Carlos Gutiérrez Cáceres. Face Detection on real Low Resolution Surveillance Videos. In Proceedings of the 2nd International Conference on Compute and Data Analysis (ICCDA 2018), DeKalb, IL, USA, 23–25 March 2018; Association for Computing Machinery ACM: New York, NY, USA, 2018; pp. 52–59. [Google Scholar] [CrossRef]
- Ayuni, M.N.; Asyraf, Z.M. Moving object detection via TV-L1 optical flow in fall-down videos. Bull. Electr. Eng. Inform. 2019, 8, 839–846. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Techniques | Performance Parameters | Applications | Dataset | Advantage | Drawback |
|---|---|---|---|---|---|
| Background subtraction, CNN, and DDBN methods [4] | Accuracy | Shopping mall | Shopping mall footage | Coined with 3 algorithms | Less accuracy |
| DNN [5] | Accuracy | Luggage back check at transport area | CCTV footage | DNN-based frame-by-frame check | Less accuracy |
| Real-time blob-matching technique [8] | Complexity | Public area security | Public transport | Low complexity | Only for public transport |
| Background subtraction, CNN, and DDBN methods [9] | Accuracy | Video surveillance | Video surveillance | Coined with 3 algorithms | Less accuracy |
| 2D CNN algorithm [10] | Accuracy | Educational sector video surveillance | Academic institute CCTV footage | 2D CNN prediction | Less accuracy |
| CNN and RNN [11] | Accuracy and loss | Real-world threat-alert system | 128 h of real-world CCTV recording | Threat-alert system | Limited for violent action detection |
| L4-Branched-ActionNet [12] | Accuracy | Real work surveillance | CIFAR-100 | High accuracy | More complexity |
| 3D CNN-based LightAnomalyNet [13] | Accuracy | Video surveillance | Public dataset | Lightweight | More space complexity |
| 3D CNN | Recall and precision | Shopping mall | Shopping mall | More precision | Less recall |
| Identification Approach | Has Suspicious Action | Does Not Have Suspicious Action |
|---|---|---|
| Identified as a suspicious action | TP | FP |
| Not identified as suspicious | FN | TN |
| Algorithm | Accuracy | Precision | FNR | FNR |
|---|---|---|---|---|
| ECNN | 98.14 | 98.54 | 2.46 | 1.66 |
| 96.07 | 97.41 | 3.59 | 2.59 | |
| 96.35 | 95.01 | 2.99 | 2.49 | |
| 94.45 | 92.78 | 5.22 | 5.22 | |
| 98.02 | 98.42 | 1.58 | 3.58 | |
| 97.35 | 95.95 | 3.05 | 2.05 | |
| 98.38 | 96.98 | 2.02 | 3.02 | |
| 98.01 | 98.41 | 2.59 | 2.59 | |
| 97.25 | 97.75 | 1.25 | 2.25 | |
| 96.48 | 96.18 | 4.82 | 3.82 | |
| CNN | 89.96 | 87.96 | 9.04 | 8.54 |
| 91.75 | 91.75 | 9.25 | 8.25 | |
| 92.98 | 92.98 | 8.02 | 7.02 | |
| 92.88 | 93.88 | 6.12 | 6.12 | |
| 93.87 | 94.97 | 6.03 | 5.03 | |
| 93.75 | 95.75 | 5.25 | 4.25 | |
| 92.65 | 92.65 | 7.35 | 6.35 | |
| 96.88 | 97.88 | 3.12 | 4.12 | |
| 95.88 | 95.98 | 4.02 | 4.02 | |
| 94.95 | 94.95 | 5.05 | 5.05 |
| Group Statistics | |||||
|---|---|---|---|---|---|
| Algorithm | N | Mean | Std. Deviation | Std. Error Mean | |
| Accuracy | ECNN | 10 | 97.050 | 1.224 | 0.387 |
| CNN | 10 | 93.555 | 2.009 | 0.635 | |
| Independent-Samples Test | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Levene’s Test for Equality of Variances | t-Test for Equality of Means | |||||||||
| F | Sig. | t | Df | Sig. (2-Tailed) | Mean Difference | Std. Error Difference | 95% Confidence Interval of the Difference | |||
| Lower | Upper | |||||||||
| Accuracy | Equal variances assumed | 1.499 | 0.237 | 4.698 | 18 | 0.000 | 3.495 | 0.744 | 1.932 | 5.058 |
| Equal variances not assumed | 4.698 | 14.872 | 0.000 | 3.495 | 0.744 | 1.908 | 5.082 | |||
| Group Statistics | |||||
|---|---|---|---|---|---|
| Algorithm | N | Mean | Std. Deviation | Std. Error Mean | |
| Precision | ECNN | 10 | 96.743 | 1.825 | 0.577 |
| CNN | 10 | 93.875 | 2.752 | 0.870 | |
| Independent-Samples Test | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Levene’s Test for Equality of Variances | t-Test for Equality of Means | |||||||||
| F | Sig. | t | Df | Sig. (2-Tailed) | Mean Difference | Std. Error Difference | 95% Confidence Interval of the Difference | |||
| Lower | Upper | |||||||||
| Precision | Equal variances assumed | 0.941 | 0.345 | 2.747 | 18 | 0.013 | 2.868 | 1.044 | 0.674 | 5.062 |
| Equal variances not assumed | 2.747 | 15.636 | 0.015 | 2.868 | 1.044 | 0.650 | 5.086 | |||
| Group Statistics | |||||
|---|---|---|---|---|---|
| Algorithm | N | Mean | Std. Deviation | Std. Error Mean | |
| False positive | ECNN | 10 | 2.957 | 1.294 | 0.409 |
| CNN | 10 | 6.325 | 2.064 | 0.653 | |
| Independent-Samples Test | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Levene’s Test for Equality of Variances | t-Test for Equality of Means | |||||||||
| F | Sig. | t | df | Sig. (2-Tailed) | Mean Difference | Std. Error Difference | 95% Confidence Interval of the Difference | |||
| Lower | Upper | |||||||||
| False positive | Equal variances assumed | 2.731 | 0.116 | −4.372 | 18 | 0.000 | −3.368 | 0.770 | −4.986 | −1.749 |
| Equal variances not assumed | −4.372 | 15.128 | 0.001 | −3.368 | 0.770 | −5.008 | −1.727 | |||
| Group Statistics | |||||
|---|---|---|---|---|---|
| Algorithm | N | Mean | Std. Deviation | Std. Error Mean | |
| False negative | ECNN | 10 | 2.927 | 1.040 | 0.329 |
| CNN | 10 | 5.875 | 1.663 | 0.526 | |
| Independent-Samples Test | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Levene’s Test for Equality of Variances | t-Test for Equality of Means | |||||||||
| F | Sig. | t | Df | Sig. (2-Tailed) | Mean Difference | Std. Error Difference | 95% Confidence Interval of the Difference | |||
| Lower | Upper | |||||||||
| False negative | Equal variances assumed | 3.392 | 0.082 | −4.752 | 18 | 0.00 | −2.948 | 0.620 | −4.251 | −1.645 |
| Equal variances not assumed | −4.752 | 15.108 | 0.00 | −2.948 | 0.620 | −4.269 | −1.627 | |||
| Method | Dataset Used | Detection Information | Accuracy |
|---|---|---|---|
| DNN [5] | CCTV footage | A suspicious activity like gun shot | 91.3% |
| Background subtraction, CNN and DDBN [9] | Video surveillance | Suspicious human-action detection | 90.00% |
| 2D CNN [10] | CAVIAR dataset | Mobile usage, fighting, or normal | 87.15% |
| LightAnomalyNet [13] | Public dataset | Violent action detection | 95.28% |
| Proposed ECNN | DCSASS dataset [20] | Detecting shooting and stealing actions | 98.38% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Selvi, E.; Adimoolam, M.; Karthi, G.; Thinakaran, K.; Balamurugan, N.M.; Kannadasan, R.; Wechtaisong, C.; Khan, A.A. Suspicious Actions Detection System Using Enhanced CNN and Surveillance Video. Electronics 2022, 11, 4210. https://doi.org/10.3390/electronics11244210
Selvi E, Adimoolam M, Karthi G, Thinakaran K, Balamurugan NM, Kannadasan R, Wechtaisong C, Khan AA. Suspicious Actions Detection System Using Enhanced CNN and Surveillance Video. Electronics. 2022; 11(24):4210. https://doi.org/10.3390/electronics11244210
Chicago/Turabian StyleSelvi, Esakky, Malaiyalathan Adimoolam, Govindharaju Karthi, Kandasamy Thinakaran, Nagaiah Mohanan Balamurugan, Raju Kannadasan, Chitapong Wechtaisong, and Arfat Ahmad Khan. 2022. "Suspicious Actions Detection System Using Enhanced CNN and Surveillance Video" Electronics 11, no. 24: 4210. https://doi.org/10.3390/electronics11244210