1. Introduction
Nowadays, gait recognition plays a significant role in personal identification, and different from other biometrics such as the face, fingerprint, and iris, the human gait is the only one that can be captured in long-distance conditions and the recognition process does not need the subject’s cooperation. Therefore, with the popularization of video surveillance equipment, gait recognition technology has broad applications in crime prevention, forensic identification, and social security. However, in real-world scenarios, the performance of gait recognition suffers from many conditions such as changing clothing, carrying conditions, and the camera’s viewpoint.
Recently, lots of deep convolutional neural-network-based methods have been proposed to address these issues. Zhang et al. [
1] proposed a new auto-encoder framework to explicitly separate posture and appearance features from RGB images and then used LSTMs to model the temporal changes of gait sequence. Chao et al. [
2] hypothesized that the appearance of a silhouette contains position information and the sequence information of gait was unnecessary for recognition, so they proposed a novel network named GaitSet that regarded gait silhouettes as a set to extract temporal information. Fan et al. [
3] employed partial features for a human body description and proposed a new model named GaitPart, which focuses on the short-range temporal features rather than the redundant long-range features for gait cycles. Li et al. [
4] enhanced the fine-grained learning of human partial features by segmenting and associating adjacent body parts from top to bottom. Lin et al. [
5] assumed that the representations based on global information often neglect the details of the gait frame, while local region-based descriptors cannot capture the relations among neighboring regions, and thus designed a new global and local feature extraction module to address this issue.
These previous methods [
3,
4] extract fine-grained features from human body parts and model short-term motion patterns, effectively improving the performance of gait recognition models. However, from observation, we find that the differences in the pedestrian walking speed and camera frame rate have resulted in inconsistent frame length of the gait cycle (as shown in
Figure 1), and thus the single temporal modeling approach cannot adapt to the diversity of motion.
Furthermore, unlike face recognition [
6,
7], fingerprint recognition [
8,
9], etc., which extracts identity information from a single image, gait recognition technology is based on video sequences. In the early days, most methods [
10,
11,
12] fused sequence features by generating template images. In recent years, video sequence-based methods [
2,
3,
4,
5] aggregate sequence-level features by simple temporal pooling of frame-level features; however, this adaptive fusion method ignores the differences in the quality of frames (as shown in
Figure 1), which affects the performance of the gait recognition model in various scenarios.
To alleviate these issues, we propose a novel gait recognition framework, which consists of two well-designed novel components, namely Multi-scale Temporal Aggregation (MTA) and Metric-based Frame Attention Mechanism (MFAM). MTA aggregates multi-scale context information through gait temporal modeling. MFAM calculates the importance score of each frame according to the Euclidean distance between it and the aggregated sequence features.
In summary, the major works of this paper are as follows:
- (1)
We propose the Multi-scale Temporal Aggregation module, which models gait temporal information in multiple scales, to accommodate diverse representations of motion;
- (2)
We introduce the Metric-based Frame Attention Mechanism, which assigns weights to each frame with an importance score calculated by the distance between frame-level features and sequence-level features;
- (3)
The proposed method has been evaluated on the widely used CASIA-B [
13] and OU-MVLP [
14] gait benchmark datasets. The experimental results of our method achieve high recognition accuracies under cross-view and various walking conditions.
3. Proposed Method
In this section, we first overview the framework of the proposed method. Then introduce the Multi-scale Temporal Aggregation (MTA) and the Metric-based Frame Attention Mechanism (MFAM). Finally, we introduce the details of training and testing. The framework of the proposed algorithm is shown in
Figure 2.
3.1. Overview
As shown in
Figure 2, the input of the framework is a sequence of gait silhouettes, which has a dimension of
, where
represents the number of channels for the input frame,
represents the frame number of sequences, and
represent the height and width dimensions, respectively. In the framework, a 3D convolution is used to extract shallow features from the original input sequence, and the extracted shallow features dimensions are
. Then, the Multi-scale Temporal Aggregation (MTA) module is designed with several parallel temporal convolutional layers, which aggregate temporal features from multiple different scales. The output dimensions of the MTA module are
. After that, the encoder network is used to extract frame-level features which are denoted as
with the dimension of
. In this paper, we adopt the GLFE proposed by Lin et al. [
5] as the encoder. Specifically, the encoder consists of a global feature extraction branch and a local feature extraction branch, each containing 3 convolutional layers. There is a pooling layer after the first convolutional layer. The features of the two branches are fused using an addition or concatenation operation, and the concatenation operation is only performed after the last layer of convolution.
Then, we employ two parallel branches to process frame-level features separately. On the one hand, temporal pooling (TP) operation is adopted to aggregate frame-level features into a sequence-level feature which is denoted as
and with the dimension of
. Similar operations were commonly used in [
2,
3,
4]. Then, in order to reduce the redundancy of data, the Generalized-Mean pooling (GeM) [
5] operation is used to map the sequence-level feature (
) into 1D feature vector (denoted as
with the dimension of
). On the other hand, the GeM operations are also used directly to reduce data redundancy for frame-level features.
Finally, the Metric-based Frame Attention Mechanism (MFAM) is designed to calculate the importance score for each frame and thus re-weight for all frames; the weighted features are encoded into high-dimensional vectors using several separate FC layers as gait representations.
3.2. Multi-Scale Temporal Aggregation
As discussed in
Section 2.2, existing methods [
2,
3,
4] either only focus on spatial modeling and thus ignore the inter-frame dependence, or focus on the short-term features of gait cycles, which cannot adapt to the changes of complex motion and environmental factors. Therefore, we designed the Multi-scale Temporal Aggregation (MTA) module, which aims at aggregating contextual information at different scales.
As shown in
Figure 3, the input of MTA module has a dimension of
, which represents the number of channels, sequence length, and size of each frame, respectively. In order to capture the temporal features with different scales, which are denoted as
,
, and
, respectively, MTA employs three parallel convolutions, which adopt different sizes of the kernel. The specific parameter settings of the convolutional layers are shown in
Table 1, especially, the three convolutions stride are all three.
After that, MTA applies information flowing from small scale to large scale among temporal features by average pooling (
), and the formula is as follows:
Finally, MTA adopts max pooling (
max) to aggregate context information at different scales.
Based on the MTA module, the model aggregates context information of different time scales, provides multiple time receptive fields through information exchange and fusion between features, and can effectively adapt to the diverse expression of human motion.
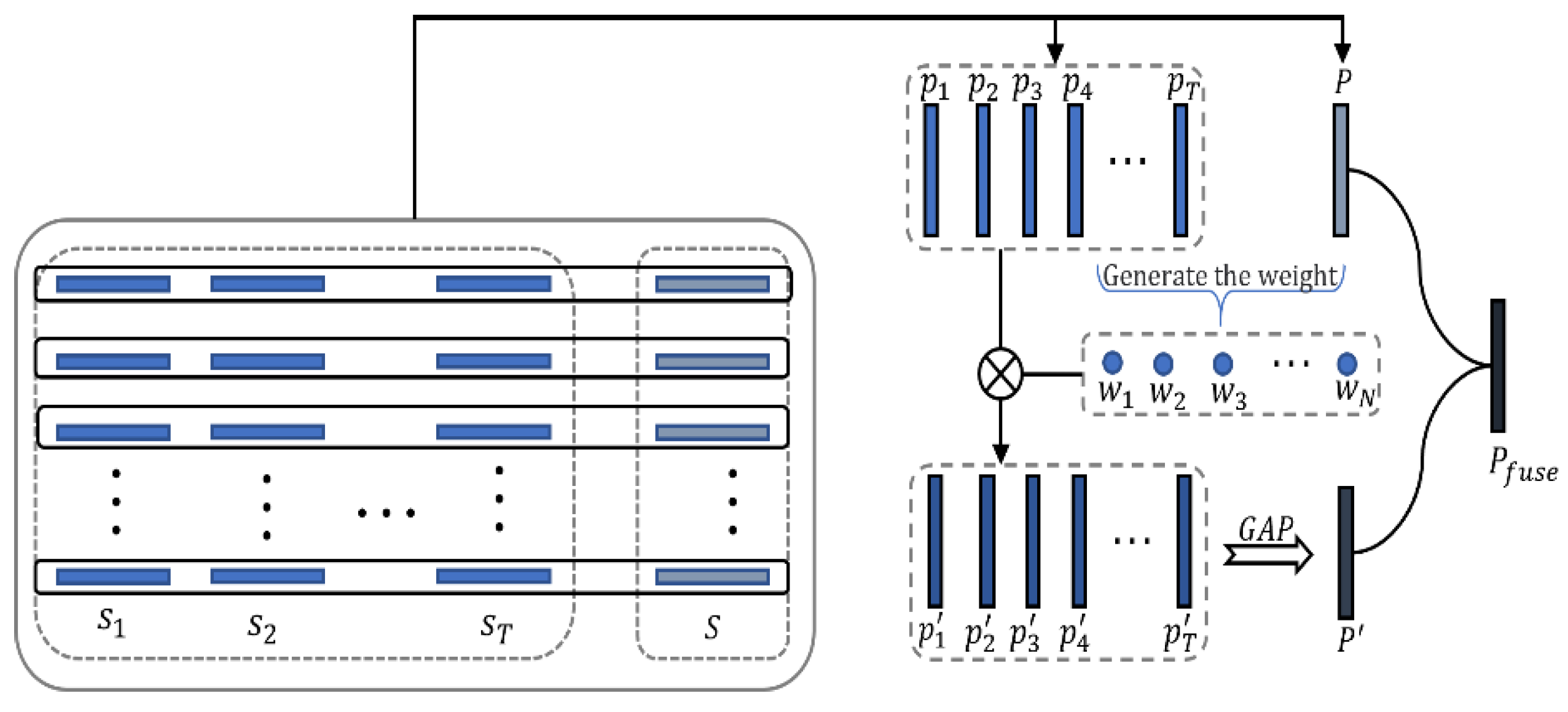
3.3. Metric-Based Frame Attention Mechanism
The rich spatiotemporal features in video sequences provide more discriminative information for recognition tasks; however, redundant information in videos will also affect recognition accuracy. Therefore, researchers [
4,
27,
28,
29] focus on extracting key information from videos to improve the performance of the model. In this paper, we obtained the importance score of each frame by calculating the similarity between frame-level features and sequence-level features obtained by temporal pooling, and then weighted each frame and aggregated it into sequence features.
As shown in
Figure 4, the input of MFAM module can divide into a frame-level feature vector and sequence-level feature vector, with dimensions of
and
, respectively, where
represents the number of channels,
represents the sequence length, and
represents the number of preset body parts.
In order to assess the importance of each frame, MFAM first calculates the Euclidean distance between frame-level feature vectors and sequence-level feature vectors and uses max-min normalized processing of the numeric distance. Then, we take the negative of these numeric distances and apply the sigmoid activation function to capture the score (denoted as
) of each frame. The score of each frame is calculated as follows:
where
represents the sigmoid function and
and
represent the minimum and maximum scores, respectively.
After that, all frames are weighted by the importance score, and the re-weight frame-level features (denoted as
) are aggregated into re-weight sequence-level features (denoted as
) by temporal pooling (
). In this paper, temporal pooling module employs global max pooling (GAP) operation to aggregate features. The calculation processes are as follows:
Finally, MFAM fuses the initial sequence-level features with weighted sequence-level features as the final sequence-level features (denoted as
).
3.4. Training and Testing
During the training stage, we input a gait sequence into the network and obtained the gait feature descriptors; the batch size of the input training data is
, where
represents the number of persons and
represents the number of training samples of each person in the batch. Then, the Batch All (BA+) triplet loss [
30] and cross-entropy loss are employed to optimize the model.
During the Testing Stage, the test dataset is divided into gallery set and probe set, and we input the whole gait sequences into the network to generate gait feature descriptors. To calculate rank-1 accuracy, the gallery set is regarded as the standard view to be retrieved, and the descriptors of the probe are used to match the descriptors from the gallery view based on the average Euclidean distance.
4. Experimental Results
4.1. Dataset
We use two open databases, CASIA-B [
13] and OU-MVLP [
14], to evaluate the performance of the proposed method.
CASIA-B. Contains the gait sequences of 124 subjects, CASIA-B is a widely applied gait dataset, and each subject contains 3 walking conditions and 11 views (0°~180°, with an interval of 18°). The walking condition contains normal (NM) (six sequences per subject), walking with a bag (BG) (two sequences per subject), and wearing a coat or jacket (CL) (two sequences per subject). In other words, each subject contains 11 × (6 + 2 + 2) = 110 sequences. As there is no official partition of training and test sets of this dataset, we conduct large-sample training (LT), medium-sample training (MT), and small-sample training (ST) according to Chao et al. [
2] During the testing stage, the first four sequences of the NM condition (NM#1–4) are stored in the gallery set and the remaining six sequences (NM#5–6, BG#1–2 and Cl#1–2) are stored in the probe set.
OU-MVLP. Contains the gait sequences of 10307 subjects, OU-MVLP is so far the world’s largest public gait dataset, and each subject contains two sequences (#00 and #01), with fourteen views (0°, 15°,…, 90°, 180°, 195°,…, 270°) for each sequence. The sequences are divided into training and test sets by subjects (5153 subjects for training and 5154 subjects for testing). During the testing stage, sequences with index #01 are kept in a gallery and those with index #00 are used as probes.
4.2. Training and Testing Details
In all the experiments, the silhouettes are directly provided by the datasets and are aligned by the method proposed by Takemura et al. [
14] and resized to the size of 64 × 44. In the training stage, we choose Adam [
31] as an optimizer and set the margin in Batch All (BA+) triplet loss to 0.2. For CASIA-B, the batch size parameters P and K are set to 8 and 10. In the setting of ST, MT, and LT, the epoch number is set to 60 K, 80 K, and 80 K, respectively, and the learning rate is set to 1 × 10
−4. For OUMVLP, the batch size parameters P and K are set to 32 and 10, respectively, and the epoch number is set to 250 K. The learning rate is first set to 1 × 10
−4, and reset to 1 × 10
−5 and 5 × 10
−6 after 180 K and 230 K iterations, respectively.
4.3. Comparison with State-of-the-Art Methods
4.3.1. Experimental Results on CASIA-B Dataset
In order to verify the efficacy and superiority of our method, we compare the performance of our model with other state-of-the-art gait recognition models, including CNN-LB [
32], MGAN [
33], GaitSet [
2], GaitSlice [
4], and GaitGL [
5] on the CASIA-B gait dataset based on the rank-1 accuracy. The experimental results are shown in
Table 2,
Table 3 and
Table 4, and
Figure 5. Except for ours, other results are directly taken from their original papers. All the results are averaged on the 11 gallery views and the identical views are excluded.
As can be seen from
Table 2, our model obtains very nice results by using LT. Under the three walking conditions NM, BG, and CL, the average recognition accuracy reached 97.6%, 94.7%, and 84.9%, which outperformed GaitGL [
5] by 0.2%, 0.3%, and 1.3%, respectively. Comparison results show that the biggest breakthrough of our method is to improve recognition accuracy under CL conditions. Due to the presence of occlusion, the recognition rate of the existing models under CL conditions is low, but in our method, the acquisition of key frames reduces the interference of redundant information, and thus improves the recognition accuracy.
From
Table 3 and
Table 4, it can be seen that under ST and MT settings, compared with existing methods, our model does not achieve an absolute advantage in NM and BG conditions. However, in the CL condition, our model has an average recognition accuracy of 80.0%(MT) and 60.0%(ST), and when compared with the best-performing GaitGL [
5], the recognition accuracy is improved by 1.7%(MT) and 2.6%(ST).
Moreover, compared with other views, the existing models have the lowest recognition rate in the view of 0° and 180° due to excessive interference information. In this paper, our method improves the recognition rate in most views, especially at 0° and 180°. For example, compared with GaitGL, the recognition rate in the three walking conditions was improved by 1.2%, 0.4%, and 3.9%, respectively, in the 180° view and LT setting.
In summary, the results of the comparative analysis show that our model outperforms the existing gait recognition models in the LT, MT, and ST settings, especially in complex application scenarios (such as coat-wearing walking conditions and the view of 0° and 180°); this demonstrates the effectiveness and superiority of our model.
4.3.2. Experimental Results on OU-MVLP Dataset
In order to verify the generalization of the proposed method, we further evaluate the performance of our method on the OUMVLP dataset. As shown in
Table 5, compared with the existing models (including GEINet [
34], GaitSet [
2], GaitPart [
3], GaitSlice [
4], and GaitGL [
5]), our model achieves the highest accuracy in various views. Especially in the view with less discriminative information and too much redundant information, such as 0°, 90°, 180°, and 270°. The comparative analysis results on the OU-MVLP dataset show that our model has good generalization.
4.4. Ablation Experiment
To verify the effectiveness of MTA and MFAM in the proposed framework, several ablation studies with various settings will be conducted on CASIA-B. In MTA, we study the influence of different size convolution on the model performance. In MFAM, we studied the influence of different distance measurement methods and different data normalization methods on the recognition rate. The experimental results and analysis are as follows.
4.4.1. Efficacy of MTA
In order to aggregate context information with different scales and adapt the model to complex human motion patterns, we introduced the Multi-scale Temporal Aggregation module in the proposed method. To analyze the appropriate parameter setting in MTA operation, three controlled experiments are conducted in experiment Group A.
As shown in
Table 6, to verify the effectiveness of the MTA module, we design the comparison experiment by implementing methods with different convolutional strategies on the LT setting. Specifically, experiments A-a, b, and c only adopted one convolution kernel with different sizes, and the comparison results with experiment A-d demonstrates the effectiveness of aggregating multi-scale contextual information operations. In addition, the comparison of experiments A-a, b, and c show that the expansion of the convolution size in MTA will lead to a decrease in the recognition accuracy of the model in complex scenes. Therefore, we choose the parameter settings in experiment A-b as the convolution combination.
4.4.2. Efficacy of MFAM
Video sequences are rich in semantic information but they also bring too many redundant features. In this paper, we introduced the Metric-based Frame Attention Mechanism to extract key frame features from sequences. As discussed in
Section 3.3, MFAM calculates the importance score of each frame by measuring the Euclidean distance between frame-level features and sequence-level features. To analyze the rationality of the MFAM using Euclidean distance to calculate the importance score, we employ cosine similarity instead of Euclidean distance, as follows:
Moreover, normalization of the data can eliminate the undesirable effects caused by odd sample data. In this section, we introduced the Z-score normalized processing of the numeric distance, the formula is expressed as:
where
and
represent the mean and variance of the numerics, respectively.
As shown in
Table 7, to verify the effectiveness of the MFAM module, we design the comparison experiment by implementing methods with different importance score calculation strategies on the LT setting.
On the one hand, the comparison shows that employing Euclidean distance to measure the similarity between features is conducive to obtaining better performance of the model. This is because the model employs Euclidean distance as the accuracy evaluation standard. On the other hand, the comparison results of different data normalization methods show that a Z-score normalized is only applicable to NM scenarios. In complex application scenarios such as BG and CL, max-min normalized shows superior recognition accuracy. Therefore, we chose the combination of Euclidean distance and max-min normalized to calculate the importance score of each frame.
4.5. Practicality Experiments
In real-world settings, it may be difficult to acquire a sufficient number of frames for gait recognition. To verify the practicability of the proposed model, we select a certain number of frames for each subject during the testing phase.
As shown in
Table 8, we selected different numbers of frames as input. The results show that the model achieves accuracies of 57.4%, 50.4%, and 33.2% in the three walking conditions when inputting 10 frames. This is because the model uses an encoder composed of 3D convolutions. When the input frame is insufficient, it is difficult for the model to extract gait temporal features. When the input reaches 30 frames, the model recognition accuracies also achieve 94.5%, 90.1%, and 76.6%. When the input exceeds 70 frames, the model recognition accuracy also tends to be stable.
4.6. Portability Experiments
It is worth noting that our MFAM operation can be used in some state-of-the-art gait recognition models [
2,
3,
4,
5]. In the GaitSlice model proposed by Li et al., the RFAM module is designed to calculate the importance score of each frame by the frame attention network. To compare the performance differences between the two attention mechanisms, three controlled experiments are conducted. In the experiments, we use the experimental results of the GaitSlice [
4] model (denoted as GaitSlice* and achieves accuracies of 96.6%, 91.7%, and 80.7%, respectively, under three walking conditions) with the RFAM module removed as the baseline.
As shown in
Figure 6, under the action of a single RFAM module, the recognition rates of the three walking scenarios are increased by 0.06%, 0.71%, and 0.86%, respectively. Under the action of our MFAM module, the recognition rates are increased by 0.16%, 0.75%, and 1.13%, which outperform RFAM by 0.1%, 0.04%, and 0.27%, respectively. Under the joint action of the two attention modules, the recognition rate is increased by 0.25%, 0.81%, and 1.28%, respectively. The above results demonstrate the effectiveness and superiority of our proposed MFAM operation.
4.7. Visualization
In order to better understand the role of the MFAM module, the importance scores of several frames are given in
Figure 7. It is worth noting that we horizontally divide the human body into 32 parts in the model, then calculate each part’s importance score. For the convenience of illustration, the average of the importance scores of the adjacent eight parts is calculated in
Figure 7. In other words, we show the weights of the four parts of the human body. It can be seen from
Figure 7 that the importance scores of each frame in the sequence are different, indicating that the frames contain different degrees of semantic information.
5. Conclusions
In this paper, we propose a new gait recognition framework, which models gait temporal features and highlights the key frames in the sequence to improve recognition accuracy. Specifically, the proposed MTA module extracts multi-scale context information through parallel convolution and carries out information exchange and fusion, so that the model can adapt to the changes of complex motion and realistic factors. In MFAM, the importance score of each frame is calculated by the distance between frame-level features and sequence-level features. After that, more discriminative gait features are extracted by reweighting key frames for each frame. Finally, experiments are conducted on the widely adopted public databases, CASIA-B and OUMVLP, which experimentally demonstrate the superiority of the proposed method. Nevertheless, the CASIA-B and OU-MVLP datasets were collected in an indoor environment. Although they include different walking conditions such as viewing angles, clothing, and carrying objects, there are still differences with the pedestrian data under real conditions. In future work, the model will be optimized for the dataset collected in the open environment.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}