1. Introduction
1.1. Research Background
Globally, the proportion of renewable energy generation is increasing due to concerns about the depletion of fossil fuels, the need to reduce carbon emissions, and concerns about environmental pollution. In line with this trend, the Korean government is also promoting the ’Renewable Energy 3020 Implementation Plan (2017)’, which increases the proportion of new and renewable energy generation to 20% by 2030. It also announced plans to supply wind power. In addition, in line with the ‘Korean New Deal Comprehensive Plan’ announced in 2020, the intermediate target for solar and wind power facilities has been raised to 91% of the total renewable energy, proving that the importance and expectations for new and renewable energy are increasing.
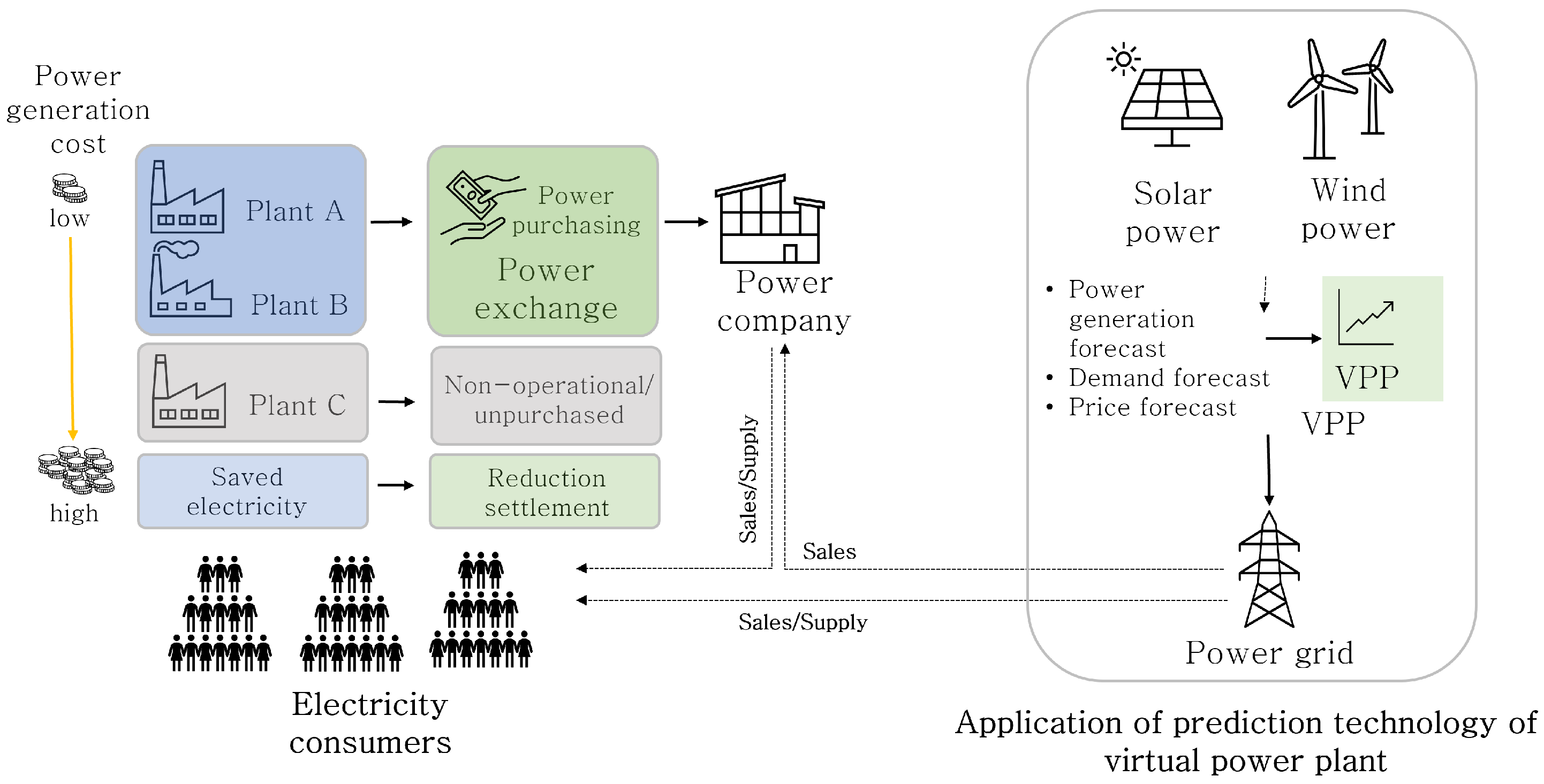
As shown in
Figure 1, in the case of the currently produced electricity in Republic of Korea, it is collected by the network manager, Korea Electric Power Corporation, through the transmission network and then delivered to the user through the distribution network. Such a centralized management system is now changing to a distributed power generation system to compensate for the limitations in managing distributed power sources of various sizes distributed nationwide. The distributed power generation system supplies distributed resources to consumers by using small-scale power generation facilities in the vicinity of the consumers. However, when operating as such a distributed power source, each individual power source participates in the supply of electricity, and in this case, an error in the prediction of the amount of electricity generation increases, resulting in system operation problems. To solve this problem, the Korean government opened the power brokerage market in February 2019, and a Virtual Power Plant (VPP) that plays the role of brokerage transaction was created in this market.
Even if the VPP is operated, it does not fundamentally solve the problem of forecasting electricity generation from wind power. Forecasting wind power generation is crucial because inaccurate predictions of wind power generation result in unstable electricity supplies. The uncertainty on the electricity supply gives rise to the inaccurate plan of electricity supply. This could result in a blackout, which happens when demand exceeds supply. Additionally, it can result in an oversupply if there is little demand and lots of supply. In the latter scenario, the quality of the electricity degrades when an excess power supply occurs because it deviates from the conventional electric frequency (e.g., 60 ± 0.5 Hz in Republic of Korea). In particular, this overstock issue has a significant impact on the advanced precision industry, such as semiconductors with nano-scale circuits.
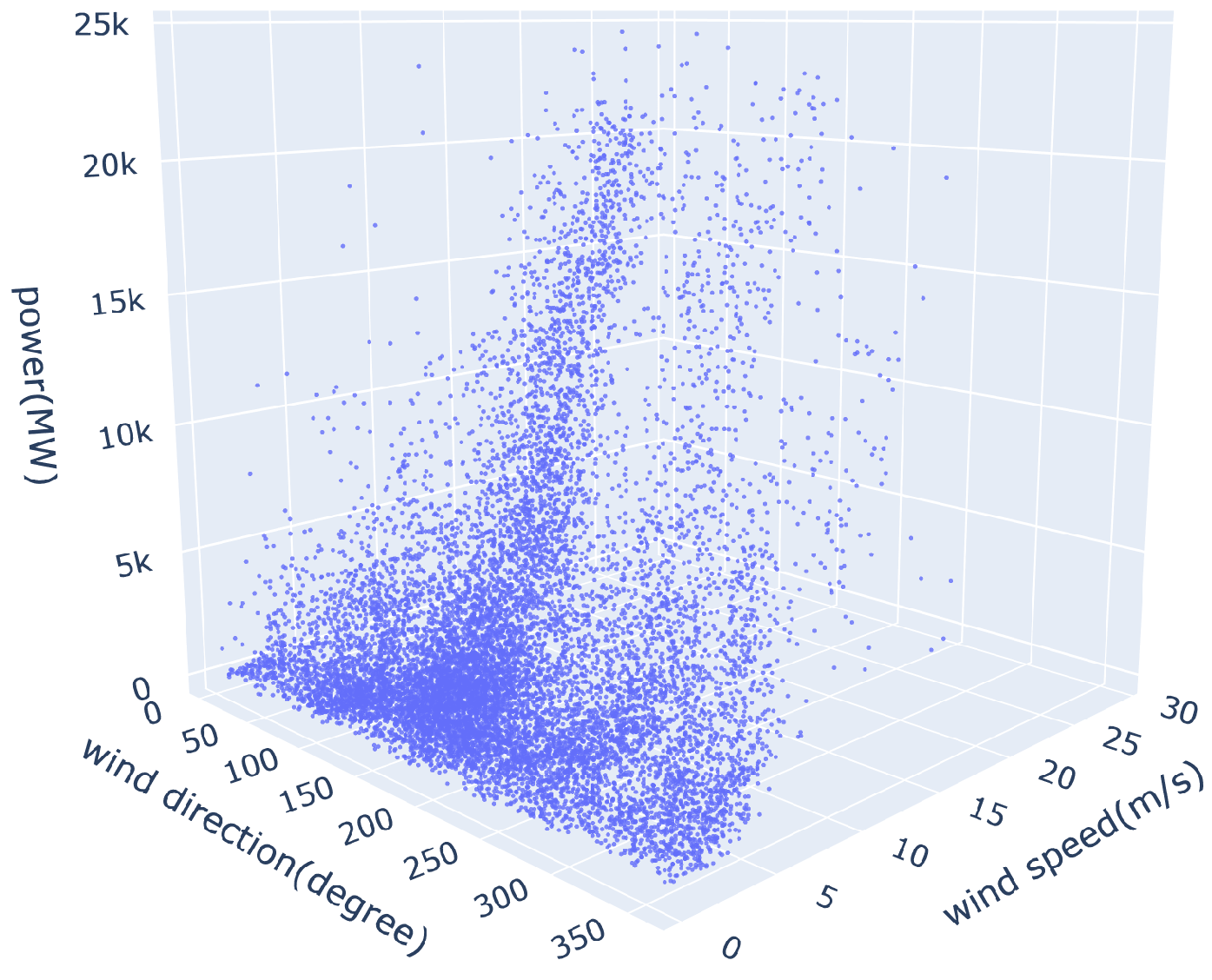
In general, wind power refers to a power generation method that uses wind energy to produce electricity, and it operates on the principle of converting mechanical energy generated by rotating blades into electrical energy through a generator. Since the output of the wind turbine is greatly affected by the wind speed, it is not easy to generate the desired amount of electricity at the desired time. The output characteristics of the wind power generator are divided into three main categories: the starting point wind speed at which the wind power generator starts producing output, the rated output wind speed at which the rated output occurs, and the wind speed at the output end point at which power is no longer generated for device protection while maintaining the rating.
1.2. Purpose of This Study
Solar power based on solar radiation can be predicted relatively reliably, but in the case of wind power generation, generated power varies rapidly due to the fluctuation of various factors such as weather and location, as well as wind speed and direction, which do not have a uniform pattern. It is also dependent on terrain, humidity, date and time of the day [
1]. Thus, it is difficult to predict the wind power generation and is highly likely to cause power system instability, which brings great difficulty in stable system operation. Moreover, since the number of new wind power generators has rapidly increased in recent years, it is essential to accurately predict the amount of power generation of these new generators for stable and efficient wind power system linkages and system operations.
Wind Power Forecasting (shortly called WPF) involves a physical approach that builds sophisticated numerical models, analyzes and predicts the correlations between wind power and related variables, and a data-driven approach based on a vast amount of historical data. In this study, we deal with a mid-term wind power forecasting problem. The electricity market is largely divided into a day exhibition market, a real-time market, and an auxiliary service market. In this study, we developed an algorithm that predicts power generation one day ahead in line with the day-ahead market currently being implemented in the Korean market. For one-day-ahead forecasting, we intend to use a data-driven approach that can effectively analyze nonlinear data such as wind power output, weather data, etc. This is due to the fact that, in addition to wind speed and other observable physical features, it is also required to take into account numerous climatic conditions, and the data-driven approach can foresee these various properties. In this study, we try to develop a deep learning model based on actual weather forecast data and historical data on wind power generation and then use transfer learning to predict the quantity of wind power generation from a new generator with less data.
In order to properly demonstrate the performance of a data-driven approach, an important factor is securing sufficient training data. However, it takes a lot of time or an excessive cost to obtain data, and in most cases, it is difficult to obtain sufficient data for an experiment in a short period of time. In this case, it is difficult to apply a data-driven approach. However, this problem can be overcome through the concept of transfer learning, in which the content learned in a specific field is reused in a new field. Because transfer learning does not require training a neural network model from the beginning thanks to knowledge transfer, the basic performance can be improved, and the model development and learning time are improved to bring improved final performance even when data are insufficient. It can be used effectively in any situation. Transfer learning using pre-learning results has been mainly used in image classification problems, but recently, it is also widely used in linear regression. The advantage of transfer learning is that it can solve the problem of wind power generation forecasting, in which a lot of new wind power generators are being generated, but the prediction accuracy is low due to the lack of data.
In this study, the effectiveness of the proposed transfer learning approach will be verified for wind power generators installed in two wind power complexes. After learning the power generation data of a wind power generator in a wind power complex where data have been accumulated for a relatively long period of time using the transfer learning approach, we apply it to predicting the mid-term (one day ahead) power generation amount of a wind power generator in a new wind power complex where the generation data are insufficient shortly after it was built.
2. Previous Works
So far, a number of studies have been conducted in relation to WPF. There have been some review works on WPF. For example, Monteiro et al. (2009) [
2] have reviewed and analyzed detailed WPF approaches and their applications to power system operations. Hanifi et al. (2020) [
1] systematically reviewed the state-of-the-art approaches of WPF with regard to physical, statistical (time series and artificial neural networks) and hybrid methods, including factors that affect accuracy and computational time in the predictive modeling efforts. Maldonado-Correa et al. (2021) [
3] reviewed the predictive models of wind energy, aiming to establish the baseline for the development of a short-term wind energy prediction model that employs artificial intelligence tools.
Hu et al. (2016) [
4] classified the WPF research methods into four categories: (i) physical models, (ii) conventional statistical models, (iii) spatial correlation models, and (iv) artificial intelligence and new models. Broadly classifying them, they can be divided into physics-based, statistics, and data-driven approaches. Physical methods use detailed physical characterization to model wind turbines/farms. This modeling effort was often carried out by down-scaling the Numerical Weather Prediction (NWP) data, which requires a description of the area, such as roughness and obstacles, as well as weather forecasting data of temperature, pressure, etc. [
1]. Even though this method is perhaps the best choice for medium to long-term wind power prediction, it is computationally complex and, therefore, needs considerable computing resources [
1,
5].
Some previous works applied a statistical approach to WPF. For example, Choy et al. (2016) [
6] derived a regression equation using wind speed and output data of the Jeju wind farm and predicted wind power generation. As a result of the regression analysis, it was shown that there was a high correlation between the predicted result and the actual output. Fang and Chiang (2016) [
7] proposed a forecasting model consisting of the Gaussian process with a novel composite covariance function for high-accuracy wind power forecasting. They showed the effectiveness of the proposed model for the 2012 global energy forecasting competition wind power forecasting data. Furthermore, Chen (2018) [
8] compared conventional (Autoregressive Moving Average (ARMA)) and two artificial intelligence methods (Artificial Neural Networks (ANNs) and Adaptive Neuro-fuzzy Inference Systems (ANFIS)) for wind power forecasting. In their experiments, they showed that ANNs and ANFIS were suitable for the very short-term (10 min ahead) wind speed and power forecasting, and the ARMA was suitable for the short-term (1 h ahead) wind speed and power forecasting.
Recently, many studies have been conducted in relation to WPF using a data-driven approach. For example, Park and Kim (2016) [
9] compared the neural network model with the time series model and suggested a better model. Wind speed and wind direction data were used for model fit, and the neural network model and time series model were evaluated using the Mean Absolute Error (MAE). As a result, the ARMA-GARCH or ARMAX model performed better for predictions 1–3 h before, and the neural network model performed better for predictions after 6 h. Kim et al. (2017) [
10] proposed a WPF method that reflects wind characteristics to improve the accuracy of wind power generation prediction. To extract the wind characteristics, correlation analysis of power generation, wind direction and wind speed was used. Based on the correlation, K-means clustering was performed to extract feature vectors. In addition, machine learning was performed using Support Vector Regression (SVR) to predict wind power generation. Root Mean Square Error (RMSE) was used as a performance evaluation index. Furthermore, Eissa et al. (2018) [
11] devised a hybrid model for wind power forecasting through analytical data, multiple linear regressions and least square methods. ARMA, SVM, and ANN were used to verify the devised model, and it was concluded that the prediction accuracy using the hybrid model is generally superior to the accuracy using the individual model. Tian et al. (2018) [
12] proposed a short-term wind power prediction method based on Empirical Mode Decomposition (EMD) and Extreme Learning Machine (ELM) for accurate wind power prediction. Through EMD, the wind power time series was decomposed based on fluctuations or trends of different scales, and an ELM model was built according to the characteristics of each component. Zhang et al. (2019) [
5] used a deep learning network to forecast the wind turbine power based on a Long Short-Term Memory network (LSTM) algorithm and used the Gaussian Mixture Model (GMM) to analyze the error distribution characteristics of short-term WPF.
In addition, Lee et al. (2020) [
13] implemented a model for predicting the output of a wind power complex which is located at Jeju island in Republic of Korea. In their model, an LSTM model, a type of Recurrent Neural Network (RNN) model, was used for 8 months of data. RMSE and Mean Absolute Percentage Error (MAPE) were used to determine the accuracy of the implemented model. As a result of the study, it was confirmed that the LSTM model has higher accuracy than the ANN and SVR models. Yang et al. (2021) [
14] proposed an improved Fuzzy C-means (FCM) clustering algorithm to increase the accuracy of prediction results and reduce the complexity of the model. The FCM method classifies wind turbines with similar output characteristics into several categories and predicts the amount of power generation by applying the power curve representing each category. Dong et al. (2021) [
15] proposed an ensemble learning model based on the stacking framework for WPF. In their model, first, an optimal decomposition method was selected to preprocess the wind data source, and second, a quadratic interpolation method based on state transition algorithm was proposed to optimize the parameters of the polynomial model and the weights of the neural network. Finally, a two-layer stack ensemble model was proposed. Experimental results showed that the proposed model has higher prediction accuracy and stability than other single prediction models. Wang and Wang (2021) [
16] proposed an ensemble model of Multi-Layer Perceptron (MLP) to prevent overfitting and reduce the variance of a single MLP model. To predict solar power generation,
k-MLP models were created by clustering days with similar power generation patterns, and predicted values were calculated by weighting
k models. The proposed ensemble method performed better than a single MLP model.
There were also transfer learning approaches for WPF. For example, Hu et al. (2016) [
4] proposed a deep learning approach using a transfer learning strategy for wind speed prediction. In their work, for transfer learning, they used a shared-hidden-layer deep neural network (DNN) architecture in which the hidden layers are shared across the domains and the output layers are different in each domain. They showed that the proposed architecture is highly beneficial for a wind farm with insufficient training data. Qureshi et al. (2017) [
17] proposed a DNN model using transfer learning and ensemble techniques. A deep auto-encoder acts as a base-regressor, and a Deep Belief Network (DBN) is used as a meta-regressor. Furthermore, Cao et al. (2018) [
18] proposed a transfer learning strategy for short-term WPF. They applied a nearest-neighbors approach to select highly relevant historical data from other wind farms. In order to enrich the training dataset, the K-Nearest Neighbors (KNN) algorithm is applied to select data from the other wind farm. Based on the new training dataset, four data-mining algorithms, Jaya-XGBoost, SVM, Least Absolute Shrinkage and Selection Operator (LASSO) and neural networks, were utilized to develop the wind forecasting model with different time horizons. In addition, Qureshi and Khan (2019) [
19] proposed Adaptive Transfer Learning (ATL-DNN) for WPF. Using transfer learning, it was confirmed that the model learned from other wind farms can be applied, and ATL-DNN not only helps to provide weight initialization but also helps to provide an effective learning method. Deng et al. (2020) [
20] looked into how deep learning, reinforcement learning and transfer learning are applied in wind speed and wind power forecasting, especially in the areas of data processing of wind power, input features selection, forecasting model framework establishment and model structure optimization. They compared deep-learning-related approaches including feed-forward network and RNN, and determined their strengths and applicability in the context of wind modeling methods. Luo et al. (2022) [
21] used the KNN algorithm to form clusters according to the generation pattern and proposed a model combining separate transfer learning and LSTM algorithms (C-LSTM) for each cluster. They claimed that the performance of the model combining transfer learning and the LSTM model was improved by up to 68.4% compared to the standard LSTM model.
Table 1 briefly summarizes the previous works related to a data-driven approach and transfer learning approach.
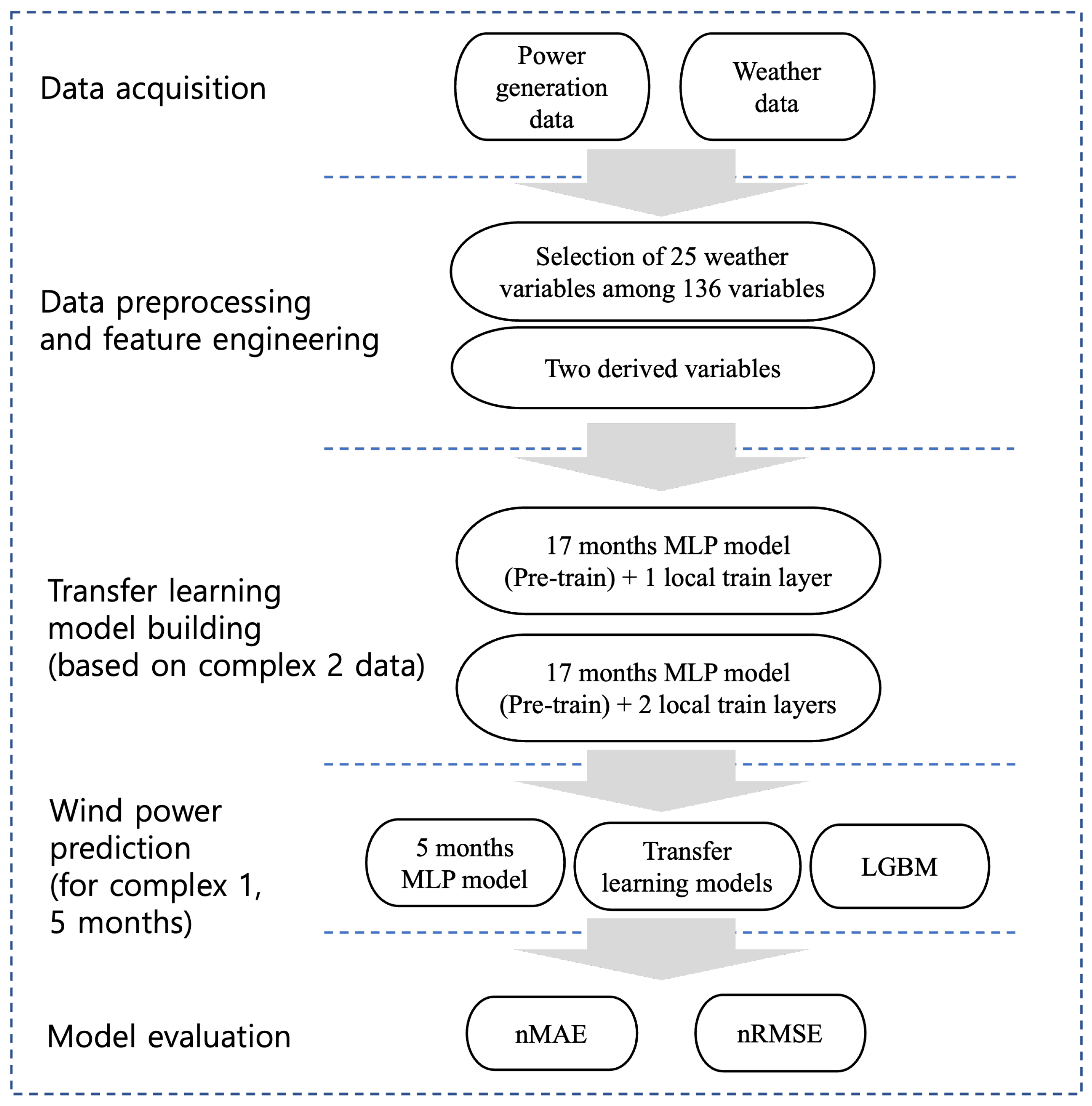
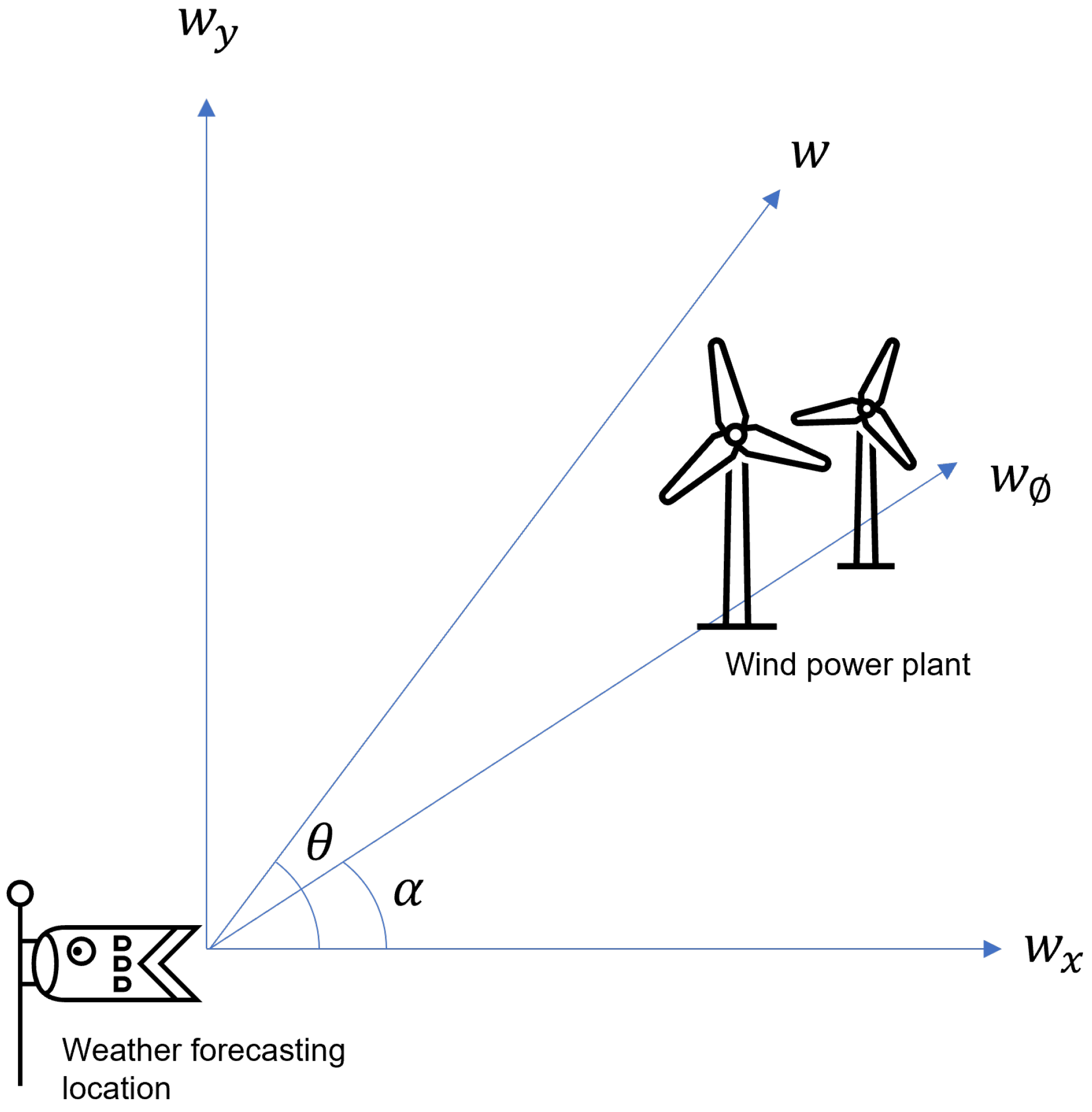
Although there has been quite a few data-driven approaches or transfer-learning-related studies on WPF problems so far, the differences between this study and previous studies related to data-driven approaches and transfer learning are as follows. First, WPF algorithms based on deep learning among previous data-driven approaches basically require a lot of data. However, these algorithms are not suitable for the problem of predicting the generation amount of a wind power plant with little operational data. As reviewed in previous studies, to overcome these problems, many transfer learning methods have been proposed for wind power generation forecasting, and they have been particularly used for short-term forecasting problems. However, this study focuses on the mid-term forecasting problem. Furthermore, in this study, in order to predict the amount of wind power generation more precisely, not only the existing weather observation data but also two derived variables were additionally considered and used for prediction. One of the derived variables is a variable that calculates the estimated wind speed value at the actual location of the wind power generator, not the wind speed data at the meteorological observation location, and the other derived variable is a variable related to the wind speed time point data considering the correlation with the wind power generation. This can also be said to be a differentiating point from previous transfer learning approaches. Finally, in deep learning or transfer learning, there are many research cases based on user experience or intuition for hyperparameter optimization, but in this study, grid search was used for hyperparameter optimization required for transfer learning.
In summary, the contributions of this study are summarized as follows. In this study, a case study was conducted in which the transfer learning technique was applied to the mid-term wind power generation prediction problem of a wind farm in Korea. Although the wind power generation prediction method applying the transfer learning method has been used in several previous studies, it is meaningful in that it verified the usefulness of the transfer learning method for wind power generation prediction based on the actual operation data of wind farms and the electricity market situation in Korea. In particular, as a result of the verification experiment, it was found that the deep-learning-based transfer learning method showed better performance in predicting the mid-term wind power generation of a newly completed wind power generator than a simple machine learning algorithm.
4. Experimental Results
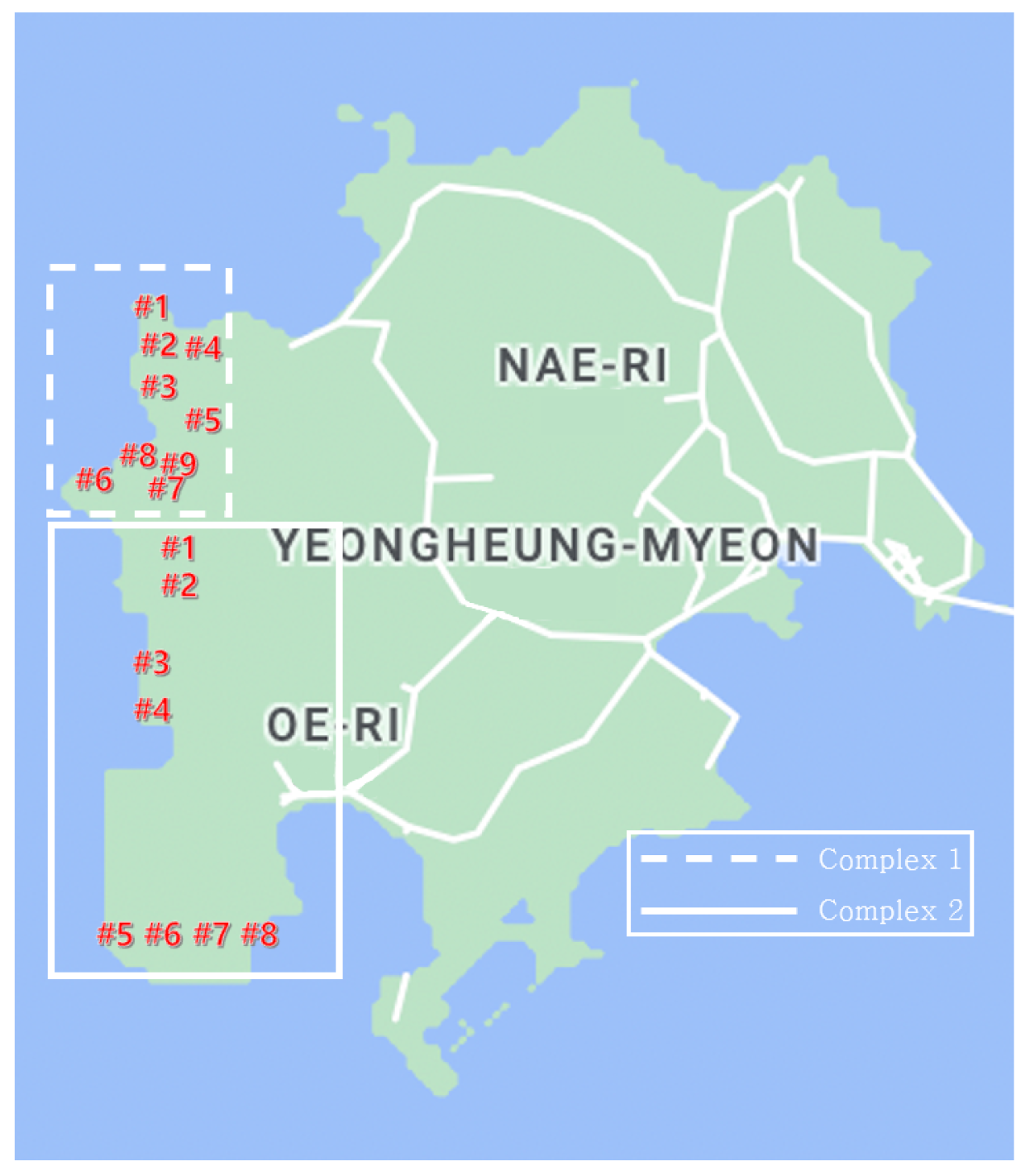
The experimental environment of this study was based on Python 3.9 and Tensorflow (deep learning open-source library). In this study, transfer learning of the pre-trained model in Yeongheung wind power complex 2 is carried out to improve the prediction of the performance of the Yeongheung wind power complex 1 because complex 1 is newly built, and there is very little historical data. To evaluate the performance of the proposed transfer learning approach, a model (called Model 1) using only data from Yeongheung wind power complex 1 in a new environment is compared with the transfer learning models that have been previously trained with data from Yeongheung wind power complex 2. In the case of the transfer learning models that were pre-training with data from Yeongheung Complex 2, they were divided into Model 2 and Model 3, which added one layer and two layers to the pre-training model, respectively. In addition, for performance comparison with machine learning, a model applied with LGBM, which is well-known for its speed and accuracy among tree-based learning algorithms, was additionally tested and the performance was compared. The following is a summary of the models used in the experiment for performance comparison.
Model 1: simple MLP model only using data obtained from the new environment, i.e., Yeongheung wind power complex 1.
Model 2: MLP-based transfer learning model that additionally added one layer into the pre-training model, which has learned the information of Yeongheung wind power complex 2 in advance.
Model 3: MLP-based transfer learning model that additionally added two layers into the pre-training model, which has learned the information of Yeongheung wind power complex 2 in advance.
LGBM: Light Gradient Boosting Machine.
The results of the models are shown in
Table 7. As the results of computational experiments, the nMAE and nRMSE of Model 1 without transfer learning were 8.90 and 12.73, and those of transfer learning models 2 and 3 were 7.87, 11.26, 7.89, and 11.28, respectively. Model 2 and Model 3 showed higher performance than Model 1 in both evaluation indicators, which seems to be because information learned in advance in a similar environment was used. Furthermore, looking at the results of LGBM, nMAE and nRMSE were 8.29 and 11.31, which showed better performance than the deep learning model without transfer learning (Model 1), but inferior in performance to Model 2 and Model 3 with transfer learning. Furthermore, it was discovered that the learning time was shortened by almost three times in the case of transfer learning. The performances of LGBM are better than those of Model 1, but inferior to transfer learning models. In general tabular data, the deep learning method is not often used well due to overfitting, but in this study, the deep-learning-based transfer learning approach showed better performance than LGBM. Comparing the performance of Model 2 and Model 3 to which the transfer learning approach is applied, it can be seen that the performance of Model 2, which is learned by adding only one layer to the pre-training model, is better.
In order to confirm the effect of transfer learning, a paired
t-test was performed with the result index derived from 30 tests based on Model 1 and Model 2, as shown in
Table 8. As a result, the paired
t-test statistic of nMAE was calculated as 2.42, and the
p-value was 0.01, confirming that there was a significant difference between Model 1 and Model 2 under the significance level of 5%. In terms of nRMSE, slightly different results were obtained compared to those of
Table 7. The average nRMSE value of Model 2 was slightly small compared to that of Model 1, but the standard deviation of Model 2 was calculated to be slightly larger at 1.51, and it was difficult to see that there was a significant difference under the 5% significance level. Unlike the results in
Table 7, the reason why the difference between Model 1 and Model 2 was not statistically significant in nRMSE because the data sets used in the experiment were different. That is, in the experiment in
Table 7, the latest 20% of the data in Yeongheung Complex 1 was extracted and configured as a test-set, whereas in the experiment in
Table 8, 20% of the data in Yeongheung Complex 1 was randomly extracted and the experiment was repeated 30 times. As a result of a more objective paired
t-test, although there was no significant difference in the nRMSE index, the effect of transfer learning on the nMAE index appears to be statistically significant. For reference, since nMAE is selected as the performance indicator used in the power generation prediction system currently implemented by the Korean Power Exchange, it can be said that Model 2, with good performance of the nMAE indicator, is more meaningful in reality.
5. Conclusions
In this study, to develop an efficient wind power forecast model, a transfer learning model based on MLP was proposed. It was used to predict the power generation amount of the Yeongheungdo wind power generation complex 1, which is newly built and does not have many operational data. In the case of MLP, for the pre-training model with 17 months of data of complex 2, when the activation function was , with four hidden layers, and the number of nodes was 100, 300, 300, and 300, it showed the best performance. In the case of transfer learning, the best results were obtained from the model in which all four existing layers applied in the pre-training model were retrained, and then one additional layer was trained. Under these conditions, it was confirmed that the prediction performance was improved in predicting the power generation amount using transfer learning after learning the Yeongheung wind power complex 2 than when predicting the Yeongheung wind power complex 1 by MLP alone.
As the linkage of new and renewable energy sources to the existing power system increases, the importance of the system operation stabilization system increases. Accordingly, technology that can predict power supply and demand is becoming more important. Sufficient data are needed to train a predictive model that can predict power generation, but in reality, newly introduced systems have a limitation in that they lack initial data. To overcome this limitation, in this study, transfer learning was used to solve this problem, and transfer learning was applied to the prediction of wind power generation and showed better results than the method without transfer learning. As the result, it is expected that the prediction accuracy of a new wind power generator will be improved by using transfer learning, and it will be possible to reach the power system stabilization more quickly.
Despite this meaningful achievement, this study has some shortcomings in the following points, so it is necessary to consider them as future research issues. First, statistical and probabilistic analysis approaches are needed for more data and cases. For example, it is necessary to verify statistically whether wind speed/generation amount predictions of wind power complexes 1 and 2 can be statistically similar. Furthermore, in feature selection, a more statistical verification method is needed for the used correlation analysis part. Second, in this study, only relatively simple and well-known deep learning and machine learning models have been applied, but it is necessary to further verify the performance of transfer learning by applying other machine learning models and deep learning models. For example, we could consider a subject that increases the prediction accuracy by using a model such as Conv-LSTM, which combines CNN and LSTM, which is easy to predict time series data. Third, since the wind speed variable that has the greatest influence on the amount of wind power generation is the day-ahead forecast data, an error correction model for forecast variables should be preceded. However, in this study, there is a limitation that an error correction model could not be developed because the measured wind speed observed at the wind power plant site was missing. Finally, since the amount of electricity production shows different characteristics depending on the region, such as the input factors used according to the climate, season, and topography according to the wind power generation region, it is also necessary to take into account the improvement of the accuracy of wind power generation forecasting by reflecting it after analyzing the cause of the difference in the power generation according to the difference in the input factors by region.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}