
A Federated Learning Framework for Breast Cancer Histopathological Image Classification
Abstract
:1. Introduction
2. Related Work
2.1. Breast Cancer Diagnosis
2.2. Federated Learning
3. Federated Learning Framework
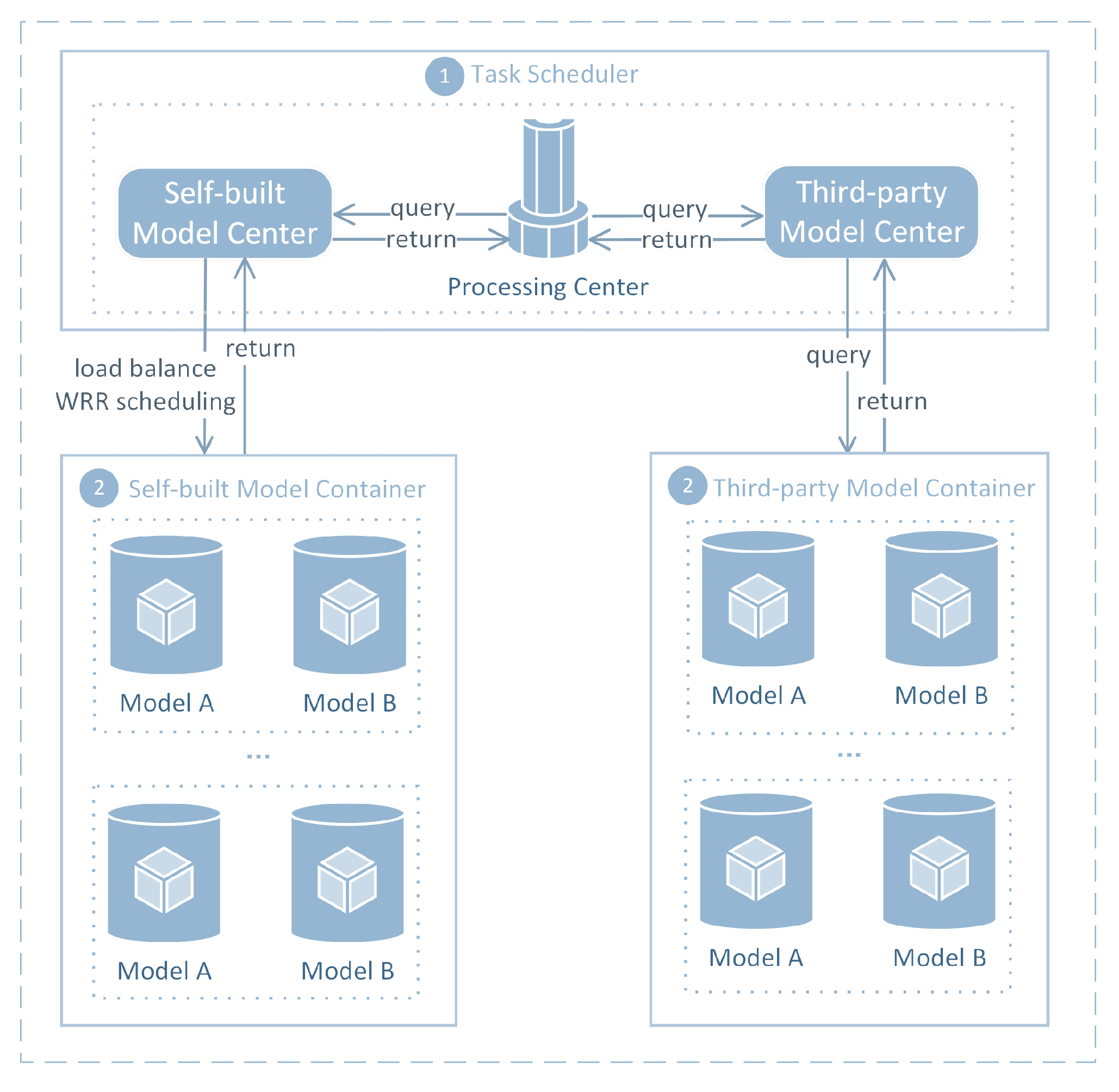
3.1. Overview
3.2. Workflow
3.3. Robustness
4. Experiments
4.1. Data
4.2. Models
4.2.1. ResNet-152
4.2.2. DenseNet-201
4.2.3. MobileNet-v2-100
4.2.4. EfficientNet-b7
4.3. Metrics
4.3.1. ACC_IL
4.3.2. ACC_PL
4.3.3. F1
4.3.4. DOR
4.3.5. Kappa
4.4. Implementation
 |
4.5. Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Greenspan, H.; Van Ginneken, B.; Summers, R.M. Guest editorial deep learning in medical imaging: Overview and future promise of an exciting new technique. IEEE Trans. Med. Imaging 2016, 35, 1153–1159. [Google Scholar] [CrossRef]
- Shin, H.C.; Roberts, K.; Lu, L.; Demner-Fushman, D.; Yao, J.; Summers, R.M. Learning to read chest x-rays: Recurrent neural cascade model for automated image annotation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2497–2506. [Google Scholar]
- Haralick, R.M.; Shanmugam, K.; Dinstein, I. Textural Features for Image Classification. IEEE Trans. Syst. Man Cybern. 1973, SMC-3, 610–621. [Google Scholar] [CrossRef] [Green Version]
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Xie, J.; Liu, R.; Luttrell, J.; Zhang, C. Deep Learning Based Analysis of Histopathological Images of Breast Cancer. Front. Genet. 2019, 10, 80. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ojansivu, V.; Heikkilä, J. Blur Insensitive Texture Classification Using Local Phase Quantization. In Proceedings of the Image and Signal Processing—3rd International Conference, ICISP 2008, Cherbourg-Octeville, France, 1–3 July 2008. [Google Scholar]
- Guo, Z.; Zhang, L.; Zhang, D. A completed modeling of local binary pattern operator for texture classification. IEEE Trans. Image Process. 2010, 19, 1657–1663. [Google Scholar]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet Classification with Deep Convolutional Neural Networks. Adv. Neural Inf. Process. Syst. 2012, 25, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Spanhol, F.A.; Oliveira, L.S.; Petitjean, C.; Heutte, L. Breast cancer histopathological image classification using convolutional neural networks. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 2560–2567. [Google Scholar]
- Bayramoglu, N.; Kannala, J.; Heikkilä, J. Deep learning for magnification independent breast cancer histopathology image classification. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancún, Mexico, 4–6 December 2016; pp. 2440–2445. [Google Scholar]
- Abdullah-Al, N.; Ali, M.M.; Kong, Y. Histopathological Breast Cancer Image Classification by Deep Neural Network Techniques Guided by Local Clustering. Biomed Res. Int. 2018, 2018, 2362108. [Google Scholar]
- Zhu, C.; Song, F.; Wang, Y.; Dong, H.; Liu, J. Breast cancer histopathology image classification through assembling multiple compact CNNs. BMC Med. Inform. Decis. Mak. 2019, 19, 198. [Google Scholar] [CrossRef] [Green Version]
- Zaalouk, A.M.; Ebrahim, G.A.; Mohamed, H.K.; Hassan, H.M.; Zaalouk, M.M. A deep learning computer-aided diagnosis approach for breast cancer. Bioengineering 2022, 9, 391. [Google Scholar] [CrossRef]
- Hameed, Z.; Zahia, S.; Garcia-Zapirain, B.; Javier Aguirre, J.; María Vanegas, A. Breast cancer histopathology image classification using an ensemble of deep learning models. Sensors 2020, 20, 4373. [Google Scholar] [CrossRef]
- Zheng, Y.; Li, C.; Zhou, X.; Chen, H.; Xu, H.; Li, Y.; Zhang, H.; Li, X.; Sun, H.; Huang, X.; et al. Application of Transfer Learning and Ensemble Learning in Image-level Classification for Breast Histopathology. arXiv 2022, arXiv:2204.08311. [Google Scholar] [CrossRef]
- Desai, M.; Shah, M. An anatomization on breast cancer detection and diagnosis employing multi-layer perceptron neural network (MLP) and Convolutional neural network (CNN). Clin. eHealth 2021, 4, 1–11. [Google Scholar] [CrossRef]
- Mridha, M.F.; Hamid, M.A.; Monowar, M.M.; Keya, A.J.; Ohi, A.Q.; Islam, M.R.; Kim, J.M. A comprehensive survey on deep-learning-based breast cancer diagnosis. Cancers 2021, 13, 6116. [Google Scholar] [CrossRef]
- Lu, M.Y.; Chen, R.J.; Kong, D.; Lipkova, J.; Singh, R.; Williamson, D.F.; Chen, T.Y.; Mahmood, F. Federated learning for computational pathology on gigapixel whole slide images. Med. Image Anal. 2022, 76, 102298. [Google Scholar] [CrossRef]
- Scheibner, J.; Ienca, M.; Kechagia, S.; Troncoso-Pastoriza, J.R.; Raisaro, J.L.; Hubaux, J.P.; Fellay, J.; Vayena, E. Data protection and ethics requirements for multisite research with health data: A comparative examination of legislative governance frameworks and the role of data protection technologies. J. Law Biosci. 2020, 7, lsaa010. [Google Scholar] [CrossRef]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated machine learning: Concept and applications. ACM Trans. Intell. Syst. Technol. (TIST) 2019, 10, 1–19. [Google Scholar] [CrossRef]
- Damgård, I.; Pastro, V.; Smart, N.P.; Zakarias, S. Multiparty Computation from Somewhat Homomorphic Encryption. IACR Cryptol. EPrint Arch. 2011, 2011, 535. [Google Scholar]
- Mohassel, P.; Zhang, Y. SecureML: A System for Scalable Privacy-Preserving Machine Learning. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2017; pp. 19–38. [Google Scholar]
- Kilbertus, N.; Gascón, A.; Kusner, M.; Veale, M.; Gummadi, K.; Weller, A. Blind justice: Fairness with encrypted sensitive attributes. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 2630–2639. [Google Scholar]
- Dwork, C.; Roth, A. The Algorithmic Foundations of Differential Privacy. Found. Trends Theor. Comput. Sci. 2014, 9, 211–407. [Google Scholar] [CrossRef]
- Abadi, M.; Chu, A.; Goodfellow, I.J.; McMahan, H.B.; Mironov, I.; Talwar, K.; Zhang, L. Deep Learning with Differential Privacy. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; pp. 308–318. [Google Scholar]
- McMahan, H.B.; Ramage, D.; Talwar, K.; Zhang, L. Learning Differentially Private Language Models without Losing Accuracy. arXiv 2017, arXiv:1710.06963. [Google Scholar]
- Stenkvist, B.; Westman-Naeser, S.; Holmquist, J.; Nordin, B.; Fox, C.H. Computerized nuclear morphometry as an objective method for characterizing human cancer cell populations. Cancer Res. 1979, 38, 4688–4697. [Google Scholar]
- Kowal, M.; Filipczuk, P.; Obuchowicz, A.; Korbicz, J.; Monczak, R. Computer-aided diagnosis of breast cancer based on fine needle biopsy microscopic images. Comput. Biol. Med. 2013, 43, 1563–1572. [Google Scholar] [CrossRef]
- Filipczuk, P.; Fevens, T.; Krzyzak, A.; Monczak, R. Computer-Aided Breast Cancer Diagnosis Based on the Analysis of Cytological Images of Fine Needle Biopsies. IEEE Trans. Med. Imaging 2013, 32, 2169–2178. [Google Scholar] [CrossRef]
- George, Y.; Zayed, H.; Roushdy, M.; Elbagoury, B. Remote Computer-Aided Breast Cancer Detection and Diagnosis System Based on Cytological Images. IEEE Syst. J. 2013, 8, 949–964. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, B.; Coenen, F.; Lu, W. Breast cancer diagnosis from biopsy images with highly reliable random subspace classifier ensembles. Mach. Vis. Appl. 2013, 24, 1405–1420. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, B.; Coenen, F.; Xiao, J.; Lu, W. Erratum to: One-class kernel subspace ensemble for medical image classification. J. Adv. Signal Process. 2015, 88. [Google Scholar] [CrossRef]
- Spanhol, F.A.; Oliveira, L.S.; Petitjean, C.; Heutte, L. A dataset for breast cancer histopathological image classification. IEEE Trans. Biomed. Eng. 2015, 63, 1455–1462. [Google Scholar] [CrossRef]
- Nikolaenko, V.; Weinsberg, U.; Ioannidis, S.; Joye, M.; Boneh, D.; Taft, N. Privacy-preserving ridge regression on hundreds of millions of records. In Proceedings of the 2013 IEEE Symposium on Security and Privacy, San Francisco, CA, USA, 19–22 May 2013; pp. 334–348. [Google Scholar]
- Zhao, L.; Ni, L.; Hu, S.; Chen, Y.; Zhou, P.; Xiao, F.; Wu, L. Inprivate digging: Enabling tree-based distributed data mining with differential privacy. In Proceedings of the IEEE INFOCOM 2018—IEEE Conference on Computer Communications, Honolulu, HI, USA, 15–19 April 2018; pp. 2087–2095. [Google Scholar]
- Cheng, K.; Fan, T.; Jin, Y.; Liu, Y.; Chen, T.; Papadopoulos, D.; Yang, Q. Secureboost: A lossless federated learning framework. IEEE Intell. Syst. 2021, 36, 87–98. [Google Scholar] [CrossRef]
- Li, Q.; Wen, Z.; He, B. Practical federated gradient boosting decision trees. In Proceedings of the AAAI conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 4642–4649. [Google Scholar]
- Konečnỳ, J.; McMahan, H.B.; Ramage, D.; Richtárik, P. Federated optimization: Distributed machine learning for on-device intelligence. arXiv 2016, arXiv:1610.02527. [Google Scholar]
- Konečnỳ, J.; McMahan, H.B.; Yu, F.X.; Richtárik, P.; Suresh, A.T.; Bacon, D. Federated learning: Strategies for improving communication efficiency. arXiv 2016, arXiv:1610.05492. [Google Scholar]
- Bonawitz, K.; Eichner, H.; Grieskamp, W.; Huba, D.; Ingerman, A.; Ivanov, V.; Kiddon, C.; Konečnỳ, J.; Mazzocchi, S.; McMahan, B.; et al. Towards federated learning at scale: System design. Proc. Mach. Learn. Syst. 2019, 1, 374–388. [Google Scholar]
- Yu, H.; Liu, Z.; Liu, Y.; Chen, T.; Cong, M.; Weng, X.; Niyato, D.; Yang, Q. A sustainable incentive scheme for federated learning. IEEE Intell. Syst. 2020, 35, 58–69. [Google Scholar] [CrossRef]
- Zhang, C.; Li, S.; Xia, J.; Wang, W.; Yan, F.; Liu, Y. BatchCrypt: Efficient homomorphic encryption for Cross-Silo federated learning. In Proceedings of the 2020 USENIX Annual Technical Conference (USENIX ATC 20), online, 15–17 July 2020; pp. 493–506. [Google Scholar]
- Standard, N.F. Announcing the advanced encryption standard (aes). Fed. Inf. Process. Stand. Publ. 2001, 197, 3. [Google Scholar]
- Cheon, J.H.; Kim, A.; Kim, M.; Song, Y. Homomorphic encryption for arithmetic of approximate numbers. In Proceedings of the International Conference on the Theory and Application of Cryptology and Information Security, Hong Kong, China, 3–7 December 2017; pp. 409–437. [Google Scholar]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Hirsch, P.D. Task Scheduling Using Improved Weighted Round Robin Techniques. U.S. Patent 10,324,755, 18 June 2019. [Google Scholar]
- Zaharia, M.; Chowdhury, M.; Franklin, M.J.; Shenker, S.; Stoica, I. Spark: Cluster computing with working sets. HotCloud 2010, 10, 95. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 22–25 July 2017; pp. 4700–4708. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; pp. 6105–6114. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Types of Tumors | Subtypes of Tumors | 40× | 100× | 200× | 400× | Total | # Patients |
|---|---|---|---|---|---|---|---|
| Benign | adenosis (A) | 114 | 113 | 111 | 106 | 444 | 4 |
| fibroadenoma (F) | 253 | 260 | 264 | 237 | 1014 | 10 | |
| phyllodes tumor (PT) | 149 | 150 | 140 | 130 | 569 | 7 | |
| tubular adenoma (TA) | 109 | 121 | 108 | 115 | 453 | 3 | |
| Total | 625 | 644 | 623 | 588 | 2480 | 24 | |
| Malignant | ductal carcinoma (DC) | 864 | 903 | 896 | 788 | 3451 | 38 |
| lobular carcinoma (LC) | 156 | 170 | 163 | 137 | 626 | 5 | |
| mucinous carcinoma (MC) | 205 | 222 | 196 | 169 | 792 | 9 | |
| papillary carcinoma (PC) | 145 | 142 | 135 | 138 | 560 | 6 | |
| Total | 1370 | 1437 | 1390 | 1232 | 5429 | 58 |
| Dataset | # Images | # Patients (B) | # Patients (M) |
|---|---|---|---|
| Training | 5590 | 16 | 40 |
| Testing | 2319 | 8 | 18 |
| Model | 40× | 100× | 200× | 400× | All |
|---|---|---|---|---|---|
| ResNet-152 | 85.82/85.46/77.13 | 87.34/83.39/75.16 | 87.73/86.03/76.49 | 84.14/82.65/76.87 | 86.33/84.39/76.97 |
| DenseNet-201 | 91.59/91.23/77.68 | 92.05/90.81/76.31 | 91.45/93.19/77.58 | 85.43/88.66/77.12 | 90.28/91.06/77.20 |
| MobileNet-v2-100 | 83.02/83.77/63.49 | 85.89/90.18/65.86 | 85.38/86.22/67.00 | 89.52/89.52/67.18 | 85.87/87.38/65.62 |
| EfficientNet-b7 | 82.55/83.81/73.10 | 83.80/83.63/73.43 | 84.66/86.07/73.85 | 80.69/82.43/66.92 | 82.98/84.02/72.26 |
| Model | 40× | 100× | 200× | 400× | All |
|---|---|---|---|---|---|
| ResNet-152 | 86.23/86.48/79.15 | 89.63/85.59/78.62 | 88.64/86.65/77.01 | 87.17/85.31/79.69 | 88.07/86.01/77.52 |
| DenseNet-201 | 92.19/92.15/79.30 | 92.58/90.94/79.83 | 91.50/93.80/80.49 | 87.39/90.77/83.04 | 91.06/91.87/81.03 |
| MobileNet-v2-100 | 83.40/83.05/64.06 | 83.34/87.90/64.99 | 83.23/85.93/68.42 | 87.58/88.41/68.13 | 84.19/86.17/65.48 |
| EfficientNet-b7 | 81.63/83.47/75.79 | 83.50/83.25/78.63 | 85.54/86.38/76.59 | 80.97/82.86/73.24 | 83.06/84.09/75.61 |
| Model | 40× | 100× | 200× | 400× | All |
|---|---|---|---|---|---|
| ResNet-152 | 72.79/69.85/53.44 | 76.19/64.65/55.06 | 77.64/72.11/61.16 | 67.92/62.65/56.19 | 73.95/67.45/55.99 |
| DenseNet-201 | 84.49/84.24/55.63 | 85.89/83.65/60.51 | 85.55/88.89/61.87 | 76.32/82.72/55.09 | 83.16/84.97/58.61 |
| MobileNet-v2-100 | 74.79/71.10/39.09 | 76.97/81.97/40.45 | 76.16/74.69/50.55 | 84.43/82.07/51.11 | 77.98/77.38/42.17 |
| EfficientNet-b7 | 70.34/72.05/45.83 | 69.74/69.90/43.39 | 74.03/76.70/45.70 | 69.88/72.17/32.69 | 71.03/72.78/40.74 |
| Model | 40× | 100× | 200× | 400× | All |
|---|---|---|---|---|---|
| ResNet-152 | 53.15/453.89/9.85 | 106.21/0.00/9.54 | 63.56/135.56/8.75 | 47.50/64.70/8.03 | 63.03/168.54/10.36 |
| DenseNet-201 | 372.36/151.37/8.98 | 162.37/105.57/13.25 | 167.55/218.40/8.89 | 29.21/52.03/8.31 | 97.96/99.81/9.85 |
| mobilenet-v2-100 | 21.35/24.20/2.98 | 31.34/71.32/2.19 | 27.28/42.92/3.03 | 65.63/99.94/3.54 | 31.10/48.02/2.75 |
| EfficientNet-b7 | 19.34/24.98/5.80 | 22.35/20.97/6.39 | 25.08/31.66/5.52 | 14.10/17.98/3.08 | 19.38/23.00/4.98 |
| Model | 40× | 100× | 200× | 400× | All |
|---|---|---|---|---|---|
| ResNet-152 | 63.69/61.34/41.26 | 68.02/55.50/37.84 | 69.42/63.56/43.78 | 58.27/52.93/42.17 | 65.16/58.42/41.42 |
| DenseNet-201 | 78.87/78.27/42.03 | 80.41/77.33/40.94 | 79.56/84.01/46.81 | 65.84/74.28/42.22 | 76.42/78.64/43.91 |
| MobileNet-v2-100 | 62.06/60.07/12.65 | 66.85/75.25/13.93 | 65.62/65.51/23.37 | 76.54/24.67/20.55 | 67.59/68.79/20.37 |
| EfficientNet-b7 | 58.18/60.90/29.56 | 58.91/58.83/27.31 | 63.21/66.80/28.65 | 55.69/59.37/11.75 | 59.09/61.58/23.68 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, L.; Xie, N.; Yuan, S. A Federated Learning Framework for Breast Cancer Histopathological Image Classification. Electronics 2022, 11, 3767. https://doi.org/10.3390/electronics11223767
Li L, Xie N, Yuan S. A Federated Learning Framework for Breast Cancer Histopathological Image Classification. Electronics. 2022; 11(22):3767. https://doi.org/10.3390/electronics11223767
Chicago/Turabian StyleLi, Lingxiao, Niantao Xie, and Sha Yuan. 2022. "A Federated Learning Framework for Breast Cancer Histopathological Image Classification" Electronics 11, no. 22: 3767. https://doi.org/10.3390/electronics11223767