
Enhancing Sentiment Analysis via Random Majority Under-Sampling with Reduced Time Complexity for Classifying Tweet Reviews
 ,
,  , and
, and
Abstract
:1. Introduction
- Proposing a detailed model for enhanced sentiment analysis that handles class imbalance while utilizing random majority under-sampling to reduce time complexity.
- Manual selection of pre-eminent features for sentiment analysis with respect to the dataset.
- Determining the effective text preprocessing order for Twitter to enable accurate under-sampling without leading to the issue of under-fitting.
- Exploring the actual impact of under-sampling against non-under-sampled data.
- Section 2 discusses the literature review in detail. It includes ML and DL techniques for sentiment analysis.
- Section 3 presents the methodology of our model with a step-by-step process.
- Section 4 lists the details of the dataset and presents the results with various classifiers.
- Section 5 showcases the results with visualizations.
2. Literature Review
3. Methodology
3.1. Proposed Model
3.1.1. Feature Selection
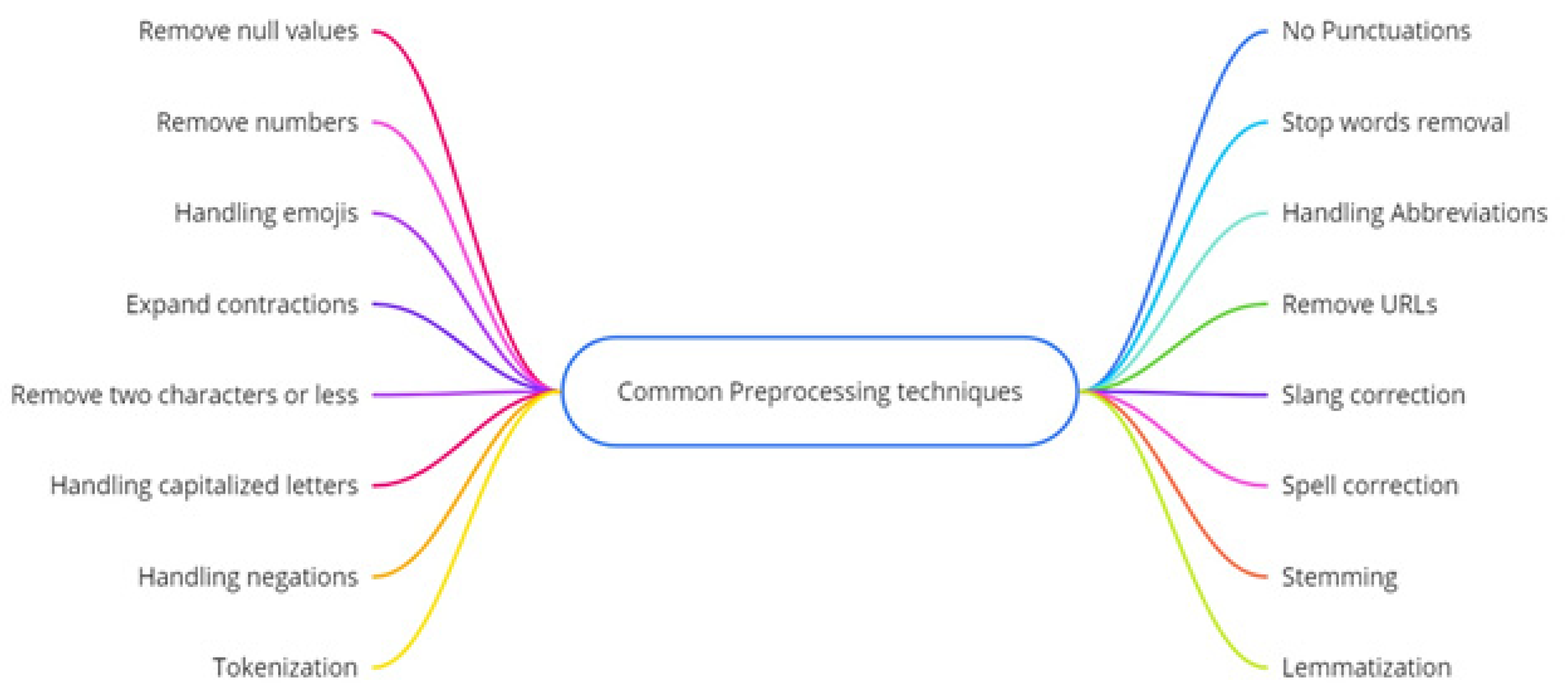
3.1.2. Text Cleaning
- Transform to lowercase:
- Dealing with contractions:
- Tokenization:
- Removing words less than two characters:
- Delete repetitive words:
- Deleting punctuations:
- Digit Deletion:
- Abbreviations and Slangs:
- Removing Stop-words:
- Spelling mistakes:
3.1.3. Text Normalization
3.1.4. Word Representation
3.1.5. Under-Sampling
3.1.6. Sentiment Classification
3.2. Dataset
4. Results and Discussion
4.1. Experimental Setup
4.2. Evaluation Metrics
4.3. Classification Results
4.4. Comparison: Under-Sampling vs. No Oversampling
5. Discussion with Visualization
5.1. Positive Tweets before and after Preprocessing
5.2. Neutral Tweets before and after Preprocessing
5.3. Negative Tweets before and after Preprocessing
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Medhat, W.; Hassan, A.; Korashy, H. Sentiment analysis algorithms and applications: A survey. Ain Shams Eng. J. 2014, 5, 1093–1113. [Google Scholar] [CrossRef] [Green Version]
- Alwakid, G.; Osman, T.; El Haj, M.; Alanazi, S.; Humayun, M.; Sama, N.U. MULDASA: Multifactor Lexical Sentiment Analysis of Social-Media Content in Nonstandard Arabic Social Media. Appl. Sci. 2022, 12, 3806. [Google Scholar] [CrossRef]
- Wang, C.; Zhang, P. The Evolution of Social Commerce: The People, Management, Technology, and Information Dimensions. Commun. Assoc. Inf. Syst. 2012, 31, 5. [Google Scholar] [CrossRef]
- Davies, A.; Ghahramani, Z. Language-independent Bayesian sentiment mining of Twitter. In Proceedings of the 5th SNA-KDD Workshop, San Diego, CA, USA, 21 August 2011; pp. 99–107. [Google Scholar]
- Pang, B.; Lee, L. Opinion Mining and Sentiment Analysis. Found. Trends Inf. Retr. 2008, 2, 1–135. [Google Scholar] [CrossRef] [Green Version]
- Taboada, M.; Brooke, J.; Tofiloski, M.; Voll, K.; Stede, M. Lexicon-Based Methods for Sentiment Analysis. 2011. Available online: http://direct.mit.edu/coli/article-pdf/37/2/267/1798865/coli_a_00049.pdf (accessed on 20 August 2022).
- Jain, P.K.; Pamula, R.; Srivastava, G. A systematic literature review on machine learning applications for consumer sentiment analysis using online reviews. Comput. Sci. Rev. 2021, 41, 10043. [Google Scholar] [CrossRef]
- Yadav, A.; Vishwakarma, D.K. Sentiment analysis using deep learning architectures: A review. Artif. Intell. Rev. 2019, 53, 4335–4385. [Google Scholar] [CrossRef]
- Ali, I.; Hameed, N. Hybrid Tools and Techniques for Sentiment Analysis: A Review. Int. J. Multidiscip. Sci. Eng. 2017, 8. Available online: https://www.researchgate.net/publication/318351105 (accessed on 22 August 2022).
- Arabnia, H.R.; Deligiannidis, L.; Hashemi, R.R.; Tinetti, F.G. Information and Knowledge Engineering; CSREA Press, Center for the Study of Race and Ethnicity in America: Providence, RI, USA, 2018. [Google Scholar]
- Rustam, F.; Khalid, M.; Aslam, W.; Rupapara, V.; Mehmood, A.; Choi, G.S. A performance comparison of supervised machine learning models for COVID-19 tweets sentiment analysis. PLoS ONE 2021, 16, e0245909. [Google Scholar] [CrossRef]
- Vashishtha, S.; Susan, S. Fuzzy rule based unsupervised sentiment analysis from social media posts. Expert Syst. Appl. 2019, 138, 112834. [Google Scholar] [CrossRef]
- Wassan, S.; Chen, X.; Shen, T.; Waqar, M.; Jhanjhi, N.Z. Amazon Product Sentiment Analysis using Machine Learning Techniques Amazon Product Sentiment Analysis using Machine Learning Techniques View project employing recent technologies for digital governance View project Amazon Product Sentiment Analysis using Machine Learning Techniques. Rev. Argent. 2021, 30, 695–703. [Google Scholar] [CrossRef]
- Jing, N.; Wu, Z.; Wang, H. A hybrid model integrating deep learning with investor sentiment analysis for stock price prediction. Expert Syst. Appl. 2021, 178, 115019. [Google Scholar] [CrossRef]
- Dzisevic, R.; Sesok, D. Text Classification using Different Feature Extraction Approaches. In Proceedings of the 2019 Open Conference of Electrical, Electronic and Information Sciences (eStream), Vilnius, Lithuania, 25 April 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Humayun, M.; Alsayat, A. Prediction Model for Coronavirus Pandemic Using Deep Learning. Comput. Syst. Sci. Eng. 2022, 40, 947–961. [Google Scholar] [CrossRef]
- Yang, L.; Li, Y.; Wang, J.; Sherratt, R.S. Sentiment Analysis for E-Commerce Product Reviews in Chinese Based on Sentiment Lexicon and Deep Learning. IEEE Access 2020, 8, 23522–23530. [Google Scholar] [CrossRef]
- Chakraborty, K.; Bhatia, S.; Bhattacharyya, S.; Platos, J.; Bag, R.; Hassanien, A.E. Sentiment Analysis of COVID-19 tweets by Deep Learning Classifiers—A study to show how popularity is affecting accuracy in social media. Appl. Soft Comput. 2020, 97, 106754. [Google Scholar] [CrossRef] [PubMed]
- Dogra, V.; Singh, A.; Verma, S.; Kavita; Jhanjhi, N.Z.; Talib, M.N. Analyzing DistilBERT for Sentiment Classification of Banking Financial News. In Intelligent Computing and Innovation on Data Science; Springer: Singapore, 2021; pp. 501–510. [Google Scholar] [CrossRef]
- Zainuddin, N.; Selamat, A.; Ibrahim, R. Hybrid sentiment classification on twitter aspect-based sentiment analysis. Appl. Intell. 2017, 48, 1218–1232. [Google Scholar] [CrossRef]
- Birjali, M.; Kasri, M.; Beni-Hssane, A. A comprehensive survey on sentiment analysis: Approaches, challenges and trends. Knowl.-Based Syst. 2021, 226, 107134. [Google Scholar] [CrossRef]
- Hussein, D.M.E.-D.M. A survey on sentiment analysis challenges. J. King Saud Univ.-Eng. Sci. 2018, 30, 330–338. [Google Scholar] [CrossRef]
- Humayun, M.; Khalil, M.I.; Alwakid, G.; Jhanjhi, N.Z. Superlative Feature Selection Based Image Classification Using Deep Learning in Medical Imaging. J. Healthc. Eng. 2022, 2022, 7028717. [Google Scholar] [CrossRef]
- Almuayqil, S.N.; Humayun, M.; Jhanjhi, N.Z.; Almufareh, M.F.; Javed, D. Framework for Improved Sentiment Analysis via Random Minority Oversampling for User Tweet Review Classification. Electronics 2022, 11, 3058. [Google Scholar] [CrossRef]
- Hasan, A.; Moin, S.; Karim, A.; Shamshirband, S. Machine Learning-Based Sentiment Analysis for Twitter Accounts. Math. Comput. Appl. 2018, 23, 11. [Google Scholar] [CrossRef] [Green Version]
- Prusa, J.; Khoshgoftaar, T.M.; Dittman, D.J.; Napolitano, A. Using Random Undersampling to Alleviate Class Imbalance on Tweet Sentiment Data. In Proceedings of the 2015 IEEE International Conference on Information Reuse and Integration, San Francisco, CA, USA, 13–15 August 2015; pp. 197–202. [Google Scholar] [CrossRef]
- Sayyed, Z.A. Study of Sampling Methods in Sentiment Analysis of Imbalanced Data. 2021. Available online: http://arxiv.org/abs/2106.06673 (accessed on 27 August 2022).
- Ghosh, K.; Banerjee, A.; Chatterjee, S.; Sen, S. Imbalanced Twitter Sentiment Analysis using Minority Oversampling. In Proceedings of the 2019 IEEE 10th International Conference on Awareness Science and Technology (iCAST), Morioka, Japan, 23–25 October 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Rao, K.N.; Reddy, C.S. A novel under sampling strategy for efficient software defect analysis of skewed distributed data. Evol. Syst. 2019, 11, 119–131. [Google Scholar] [CrossRef]
- Zhou, S.; Li, X.; Dong, Y.; Xu, H. A Decoupling and Bidirectional Resampling Method for Multilabel Classification of Imbalanced Data with Label Concurrence. Sci. Program. 2020, 2020, 8829432. [Google Scholar] [CrossRef]
- Aljarah, I.; Al-Shboul, B.; Hakh, H. Online Social Media-Based Sentiment Analysis for US Airline Companies. 2017. Available online: https://www.researchgate.net/publication/315643035 (accessed on 5 September 2022).
- Liu, Y.; Bi, J.-W.; Fan, Z.-P. Multi-class sentiment classification: The experimental comparisons of feature selection and machine learning algorithms. Expert Syst. Appl. 2017, 80, 323–339. [Google Scholar] [CrossRef] [Green Version]
- Catal, C.; Nangir, M. A sentiment classification model based on multiple classifiers. Appl. Soft Comput. 2017, 50, 135–141. [Google Scholar] [CrossRef]
- Eler, D.M.; Grosa, D.; Pola, I.; Garcia, R.; Correia, R.; Teixeira, J. Analysis of Document Pre-Processing Effects in Text and Opinion Mining. Information 2018, 9, 100. [Google Scholar] [CrossRef] [Green Version]
- Obiedat, R.; Qaddoura, R.; Al-Zoubi, A.M.; Al-Qaisi, L.; Harfoushi, O.; Alrefai, M.; Faris, H. Sentiment Analysis of Customers’ Reviews Using a Hybrid Evolutionary SVM-Based Approach in an Imbalanced Data Distribution. IEEE Access 2022, 10, 22260–22273. [Google Scholar] [CrossRef]
- Bibi, M.; Abbasi, W.A.; Aziz, W.; Khalil, S.; Uddin, M.; Iwendi, C.; Gadekallu, T.R. A novel unsupervised ensemble framework using concept-based linguistic methods and machine learning for twitter sentiment analysis. Pattern Recognit. Lett. 2022, 158, 80–86. [Google Scholar] [CrossRef]
- Mubarok, M.S.; Adiwijaya; Aldhi, M.D. Aspect-based sentiment analysis to review products using Naïve Bayes. In AIP Conference Proceedings; AIP Publishing: Melville, NY, USA, 2017. [Google Scholar] [CrossRef] [Green Version]
- Bahadir, C.D.; Wang, A.Q.; Dalca, A.V.; Sabuncu, M.R. Deep-Learning-Based Optimization of the Under-Sampling Pattern in MRI. IEEE Trans. Comput. Imaging 2020, 6, 1139–1152. [Google Scholar] [CrossRef]
- Guzmán-Ponce, A.; Valdovinos, R.M.; Sánchez, J.S.; Marcial-Romero, J.R. A New Under-Sampling Method to Face Class Overlap and Imbalance. Appl. Sci. 2020, 10, 5164. [Google Scholar] [CrossRef]
- Ghazi, D.; Szpakowicz, S. Prior versus Contextual Emotion of a Word in a Sentence. Association for Computational Linguistics. 2012. Available online: www.wjh.harvard.edu/ (accessed on 7 September 2022).
- Agarwal, B.; Mittal, N. LNCS 7817-Optimal Feature Selection for Sentiment Analysis. In Computational Linguistics and Intelligent Text Processing; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Badjatiya, P.; Gupta, S.; Gupta, M.; Varma, V. Deep Learning for Hate Speech Detection in Tweets. In Proceedings of the 26th International Conference on World Wide Web Companion, Perth, Australia, 3–7 April 2017; pp. 759–760. [Google Scholar] [CrossRef] [Green Version]
- Dablain, D.; Krawczyk, B.; Chawla, N.V. DeepSMOTE: Fusing Deep Learning and SMOTE for Imbalanced Data. IEEE Trans. Neural Netw. Learn. Syst. 2022, 1–15. [Google Scholar] [CrossRef]
- Mukherjee, A.; Mukhopadhyay, S.; Panigrahi, P.K.; Goswami, S. Utilization of Oversampling for multiclass sentiment analysis on Amazon Review Dataset. In Proceedings of the 2019 IEEE 10th International Conference on Awareness Science and Technology (iCAST), Morioka, Japan, 23–25 October 2019. [Google Scholar] [CrossRef]
- Alnatara, W.D.; Khodra, M.L. Imbalanced Data Handling in Multi-label Aspect Categorization using Oversampling and Ensemble Learning. In Proceedings of the 2020 International Conference on Advanced Computer Science and Information Systems (ICACSIS), Depok, Indonesia, 17–18 October 2020; pp. 165–170. [Google Scholar] [CrossRef]
- Grandini, M.; Bagli, E.; Visani, G. Metrics for Multi-Class Classification: An Overview. 2020. Available online: http://arxiv.org/abs/2008.05756 (accessed on 10 September 2022).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cite | Purpose | Positive | Findings |
|---|---|---|---|
| [25] | A ensemble technique which utilizes a sentiment analyzer via techniques based on machine learning for the purpose of sentiment analysis | A unique contrast of opinion lexicons including Senti_Word_Net and Text_Blob is shown to reveal the most useful one that can be used. | The study only provides accuracy as a performance measure. Other measures might be needed to validate the results. |
| [26] | Study examines the impact of sampling through the use of random under-sampling with multiple splits of +ve/−ve class distribution. | Experimental results reveal that Random Under-sampling enhances classification performance considerably when compared to no data sampling. | This technique may lead to underfitting on certain datasets. |
| [27] | This paper looks at the various sampling techniques for sentiment analysis on two different severely unbalanced datasets. One dataset comprises online user evaluations from the food portal Epicurious, while the other contains comments sent to Planned Parenthood. | An information gain-based attribute selection approach is utilized to limit the number of attributes to a manageable space. A variety of sample approaches were then used to ameliorate the class imbalance problem, which were then examined. | None |
| [28] | In opinion mining, real user tweets were utilized to systematically check the impact of class inequality problem. To deal with challenge of class inequality, the up-sampling of the less dominant class was utilized. | Results reveal that minority over-sampling dependent approaches can deal with the challenge of class label inequality to a considerable margin. | Approach was not checked for the problems of multi-class classification. |
| [29] | The study focuses on fixing the problem of class imbalance and reduce the least useful instances from the dominant subgroups. | The study detects the most mis-classified instances based on KNN successfully. | The approach may not perform as well for certain smaller datasets |
| [30] | The study decreases the label variation by separating the hugely coeval item of the pre-dominant and less-dominant instances and checking the impact of those instances during re-sampling. | The study shows the usefulness of the algorithm especially with data that have decent disparity between dominant and less dominant instances. | The parameters used in the study directly influences the results of the algorithm |
| [31] | This study performs Sentiment Analysis on the replies of the customers regarding different airlines through feature engineering and ML. | Feature engineering technique is utilized to select the most useful attributes, that not only increases the usefulness of the model but also reduces the time required to train. | The label inequality in the classes in some of the bigger datasets can lead to problem of overfitting |
| [32] | A feature engineering method is used in order to detect the most useful attributes which can be utilized for training an ML based technique. | This study provides enhanced accuracy in comparison to the base method via effective feature selection. | The approach might not work well for imbalanced datasets. |
| [33] | In this study, the influence of various categorization systems on Turkish opinion mining is being investigated. | The results show that using different classifiers can enhance the results for singular classifiers | Multi-classification models can offer promising results, but it is not yet fully matured. |
| [34] | The implementation of an appropriate preprocessing method may result in enhanced sentiment categorization results. | This study successfully demonstrates that combining numerous preprocessing techniques is crucial in selecting the best classification outcomes. | Datasets with class inequality are not explored. |
| [35] | It provides a hybrid technique that combines SVM algorithm with PSO and multiple up-sampling approaches to handle the class imbalance problem. | The research proves that the advised technique is useful and provides better results when compared to the other options in every parameter investigated. | Languages other than Arabic can be investigated for this technique. |
| [36] | An original unsupervised machine learning strategy formed on hierarchical categorization is advised for sentiment analysis on Twitter network. | The results acquired using this unsupervised learning approach are comparable to those obtained using other supervised learning methods. | Unigrams are used to examine Boolean and TF-IDF functions. Different versions of n-gram can also be studied. Larger datasets could also be investigated. |
| [37] | Sentiment analysis was utilized to assess and find sentiment polarity from reviews of various products depending on a specific product feature. | This study was divided into three phases: data pretreatment with POS tagging, selection of features with Chi Square, and sentiment polarity classification with Nave Bayes. | Review dataset was small. Experimentation on larger dataset might reveal different results |
| [38] | Providing a formulation that allows a data-driven optimized under-sampling pattern at a particular sparsity level. | Under-sampling masks are data-dependent, and they vary based on the imaged anatomy, but their performance is good with different reconstruction methods | None |
| [39] | 2-stage under-sampling strategy that integrates a clustering algorithm for removing noisy samples and cleaning the decision boundary with the minimal spanning tree algorithm for dealing with class inequality | An exhaustive experimental analysis demonstrates that the novel algorithm outperforms other under-sampling approaches using conventional classification models. | Strategy is only tested for binary classification problems. Its performance on multi-classification problems still needs to be explored |
| [40] | Provide a strategy for classifying sentences by emotion classes that takes into account the contextual emotion of a word as well as the structure of the phrase. | This potential strategy surpasses both a Bag-of-Words representation-based method and a model based solely on the preceding emotions of words. | Automatically differentiating between antecedent and contextual emotionwith an emphasis on investigating aspects are important. |
| [41] | Unigrams and bigrams are retrieved from the text and used to construct composite features. Adjectives and adverbs based on Part of Speech (POS) are also retrieved. To extract important features, several feature selection approaches are applied. The impact of different feature sets on sentiment categorization is also examined using ML approaches. | The effects of various feature categories are studied using four typical datasets. Experiment findings reveal that composite features derived from dominant unigram and bigram features outperform other features in sentiment categorization. | With respect to accuracy and execution time, the Boolean-MNB method outperforms the Support Vector Machine for sentiment analysis. |
| [42] | The purpose of this study is to be able to identify a tweet as racist, sexist, or neither, considering the challenges associated with the natural language. | Experiments are performed with various DL algorithms to learn semantic word embeddings so that the complexity can be dealt with. | None |
| Text | Negative Reasons |
|---|---|
| @VirginAmerica it’s really aggressive to blast obnoxious “entertainment” in your guests faces & they have little recourse | Bad Flight |
| @VirginAmerica you guys messed up my seating... I reserved seating with my friends and you guys gave my seat away... I want free internet | Customer Service Issue |
| Sample Text | After Lowercase | Sentiment |
|---|---|---|
| This was a wonderful experience. I must commend you for a wonderful Flight | this was a wonderful experience. i must commend you for a wonderful flight | Positive |
| Sample Text | Dealing with Contractions | Sentiment |
|---|---|---|
| they shouldn’t have delayed the flight now i won’t be able to reach on time | they should not have delayed the flight now i will not be able to reach on time | Negative |
| Sample Text | Tokenization | Sentiment |
|---|---|---|
| they should not have delayed the flight | ‘they’ ‘should’ ‘not’ ‘have’ ‘delayed’ ‘the’ ‘flight’ | Negative |
| Sample Text | Removing Repeating Words | Sentiment |
|---|---|---|
| we should fly and go before the rain starts | should fly and before the rain starts | Negative |
| Sample Text | Removing Repeating Words | Sentiment |
|---|---|---|
| @JetBlue they should not have delayed the flight | they should not have delayed the flight | Negative |
| Sample Text | Deleting Punctuations | Sentiment |
|---|---|---|
| flight was amazing, but took longer than expected. | flight was amazing but took longer than expected | Neutral |
| Sample Text | Digit Deletion | Sentiment |
|---|---|---|
| was flight 717 delayed should have been the air 30 min ago | was flight delayed should have been air min ago | Negative |
| Sample Text | Handling Slangs and Abbreviations | Sentiment |
|---|---|---|
| your flight vouchers never seem apply nyc flights | your flight vouchers never seem apply new york city flights | Negative |
| Sample Text | Removing Stop-Words | Sentiment |
|---|---|---|
| your flight vouchers never seem to apply to new york city flights | flight vouchers never seem apply new york city flights | Negative |
| Sample Text | Spell Correction | Sentiment |
|---|---|---|
| flight went well many thanks wondrful expirince | flight went well many thanks wonderful experience | Positive |
| Dataset Attributes | Details |
|---|---|
| Text | Text of the tweet as typed by the user. |
| Airline | Official name of the airline |
| Airline-Sentiment-Confidence | A numbered attribute which shows the trust rate of grouping the text to one of the categories. |
| Airline-Sentiment | Class label of tweets (+ve, neutral, −ve). |
| Negative Reason | The reason to consider a tweet as −ve as per the experts. |
| Negative-Reason-Confidence | The amount of trust in deciding the −ve reason with respect to a −ve text. |
| Retweet Count | A numerical value that represents retweets for a tweet. |
| Classifiers | Accuracy | Weighted F1-Score | ||||||
|---|---|---|---|---|---|---|---|---|
| RMU | RMU Time (Seconds) | No-Resampling | NR Time (Seconds) | RMU | RMU Time (Seconds) | No-Resampling | NR Time (Seconds) | |
| XGB | 86.5% | 96 s | 88.8% | 177 s | 0.874 | 102 s | 0.883 | 180 s |
| RF | 86.2% | 234 s | 88.3% | 456 s | 0.872 | 244 s | 0.881 | 460 s |
| SVM | 84.7% | 126 s | 85.9% | 345 s | 0.865 | 132 s | 0.875 | 355 s |
| GB | 83.5% | 324 s | 84.4% | 846 s | 0.855 | 320 s | 0.871 | 840 s |
| DT | 83.1% | 18 s | 83.8% | 30 s | 0.848 | 29 s | 0.857 | 48 s |
| NB | 76.5% | 4 s | 68.5% | 8 s | 0.728 | 15 s | 0.705 | 29 s |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Almuayqil, S.N.; Humayun, M.; Jhanjhi, N.Z.; Almufareh, M.F.; Khan, N.A. Enhancing Sentiment Analysis via Random Majority Under-Sampling with Reduced Time Complexity for Classifying Tweet Reviews. Electronics 2022, 11, 3624. https://doi.org/10.3390/electronics11213624
Almuayqil SN, Humayun M, Jhanjhi NZ, Almufareh MF, Khan NA. Enhancing Sentiment Analysis via Random Majority Under-Sampling with Reduced Time Complexity for Classifying Tweet Reviews. Electronics. 2022; 11(21):3624. https://doi.org/10.3390/electronics11213624
Chicago/Turabian StyleAlmuayqil, Saleh Naif, Mamoona Humayun, N. Z. Jhanjhi, Maram Fahaad Almufareh, and Navid Ali Khan. 2022. "Enhancing Sentiment Analysis via Random Majority Under-Sampling with Reduced Time Complexity for Classifying Tweet Reviews" Electronics 11, no. 21: 3624. https://doi.org/10.3390/electronics11213624