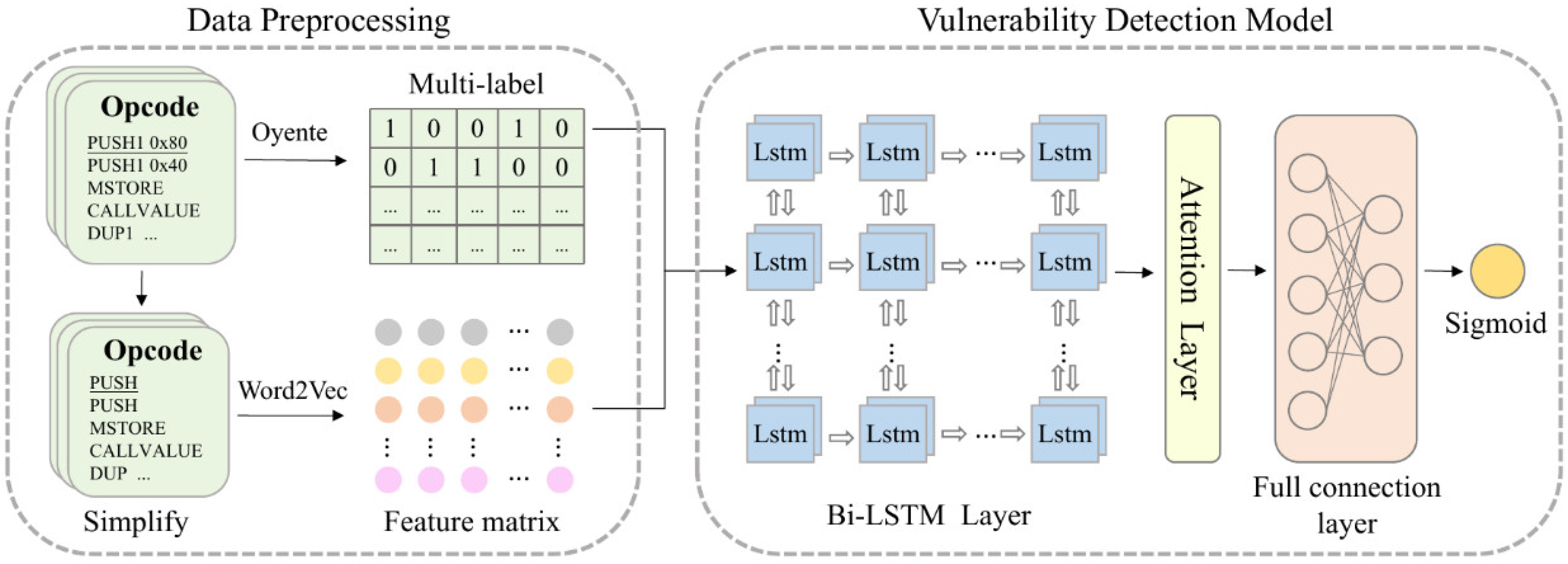
To address the problems of poor detection, incomplete automation, and slow detection in traditional detection methods for smart contract vulnerability detection, the goal of this paper was to design a method that can accurately and automatically detect whether a smart contract contains multiple vulnerabilities. The multi-label vulnerability detection framework proposed in this paper consists of two parts, as shown in
Figure 2: the data pre-processing module and the vulnerability detection model. The data pre-processing starts with converting the smart contract bytecode into opcodes using the Opcode-tool, followed by converting the opcodes into a word embedding matrix for input to the neural network model using the word embedding model Word2Vec, while we add multi-label vectors to the generated word embedding matrix using Oyente, a static detection tool based on symbolic execution, and the word embedding matrix and multi-label vectors together form the dataset for model training and testing. The training set is fed into the vulnerability detection model for training to obtain a neural network model with high classification accuracy, and the model is finally validated on a test set. The vulnerability detection model consisted of a Bi-LSTM layer, an attention layer, a fully-connected layer and a sigmoid function to implement multi-label vulnerability detection for smart contracts classification.
4.1. Data Preprocessing
In the field of natural language processing (NLP), syntactic analysis, dependency analysis, lexical analysis, and machine translation are indispensable for processing text data. Ordinary text is unstructured data, and unstructured text needs to be “structured” for further analysis and understanding. Structured data makes it easier to extract semantic features in both machine learning and deep learning domains. Word embedding is the main and common approach to solving this problem, which involves embedding a high-dimensional space of all words into a continuous vector space of lower dimensionality, where each word or phrase is mapped to a vector over the real number field [
43]. Commonly used word embedding methods are Word2Vec, GloVe, etc. The GloVe is based on traditional statistical methods and does not use neural networks, and the computation is relatively complex, and common Python toolkits do not integrate GloVe. Smart contract opcodes are composed of operation instructions and opcodes, and each opcode can be regarded as a word, which belongs to the textual form of data. To be able to extract and accurately characterize the smart contract vulnerabilities, we chose the Word2Vec model for word embedding operations.
4.1.1. Feature Extraction
Among the more than 140 operation instructions specified by EVM, not all of the opcodes can affect the vulnerability detection results of smart contracts. Opcodes with similar functions can be grouped into the same category to avoid dimensional disasters and reduce computation. For example, by deleting the number 1 after the PUSH1 operation instruction, the partially simplified opcodes were obtained, and are shown in
Table 3.
The simplified opcodes were vectorized by the Word2Vec model, which is a lightweight neural network consisting of an input layer, a hidden layer, and an output layer. The input layer was the one-hot encoding of the opcode
, and according to the simplified set of operational instructions
, each opcode has a number
, and the One-hot encoding of
represents a vector of dimension
, where the
i-th element value is 1 and the rest of the elements are 0, such as
. The hidden layer sets a linear activation function, and when the model is trained, the neural network weights are obtained, and the number of weights is the same as the number of nodes in the hidden layer. Only the weight corresponding to position 1 is activated, thus generating a new vector to represent the operation code
. Equation (1) represents the feature matrix of the operation code of contract
p. The word vector dimension in this study was set to 300, where
represents the
i-th opcode in contract
p, since the number of opcodes differs for each contract,
denotes the maximum number of contract opcodes in the whole contract dataset, and the vacant position is filled to 0 when
.
4.1.2. Multi-Label
Smart contract multi-label classification is defined as follows: given a dataset , where , X refers to the feature space corresponding to the dataset, L refers to the label space of the dataset, N refers to the sample size of the dataset, d refers to the feature vector dimension size, and K refers to the dimension size of the label vector. For the sample , refers to the feature vector corresponding to the p-th contract in the dataset; that is, Equation (1), and accordingly, the label vector of the p-th contract consists of K labels, denoted as , when it contains the k-th label then it has , otherwise .
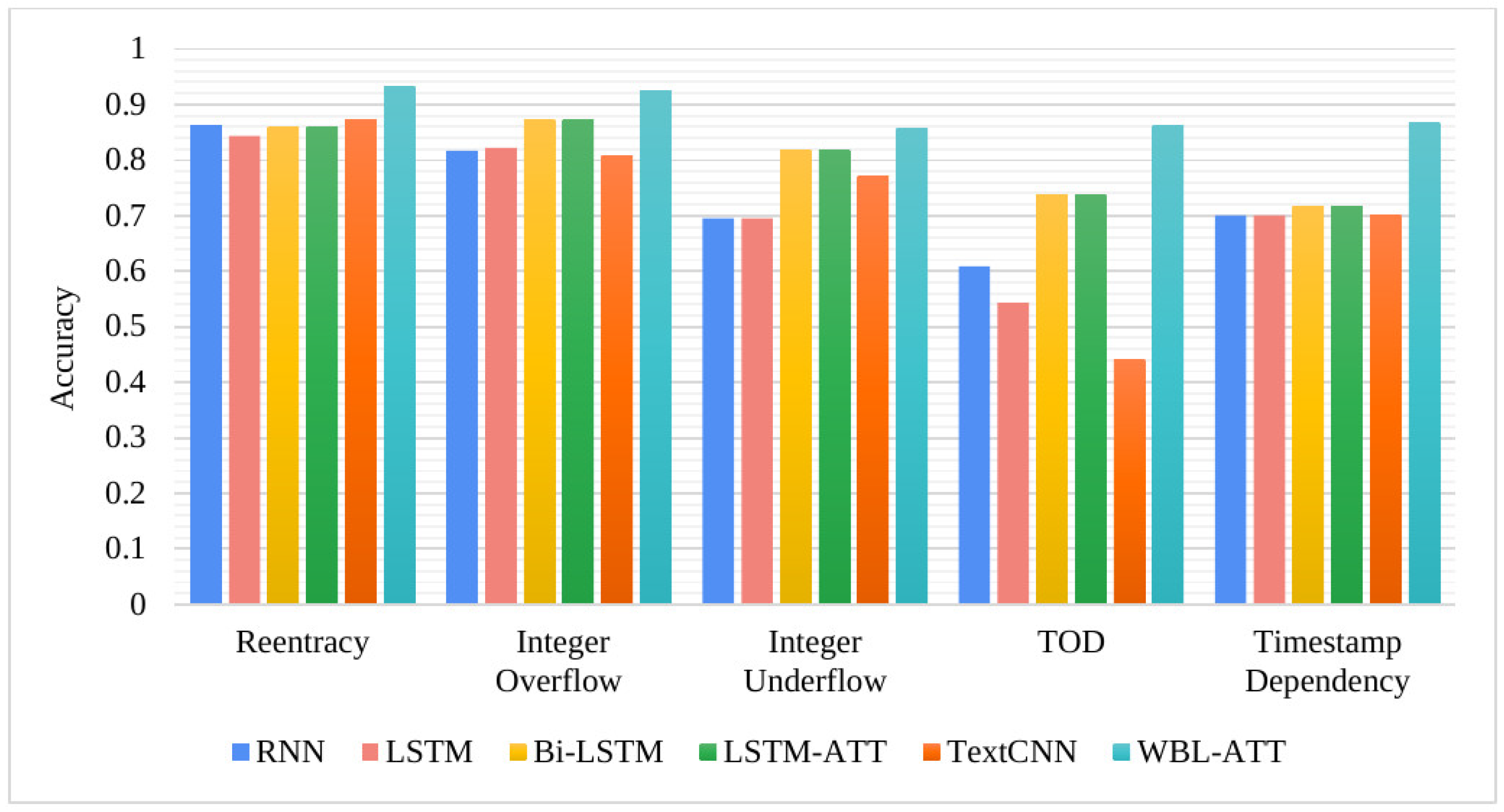
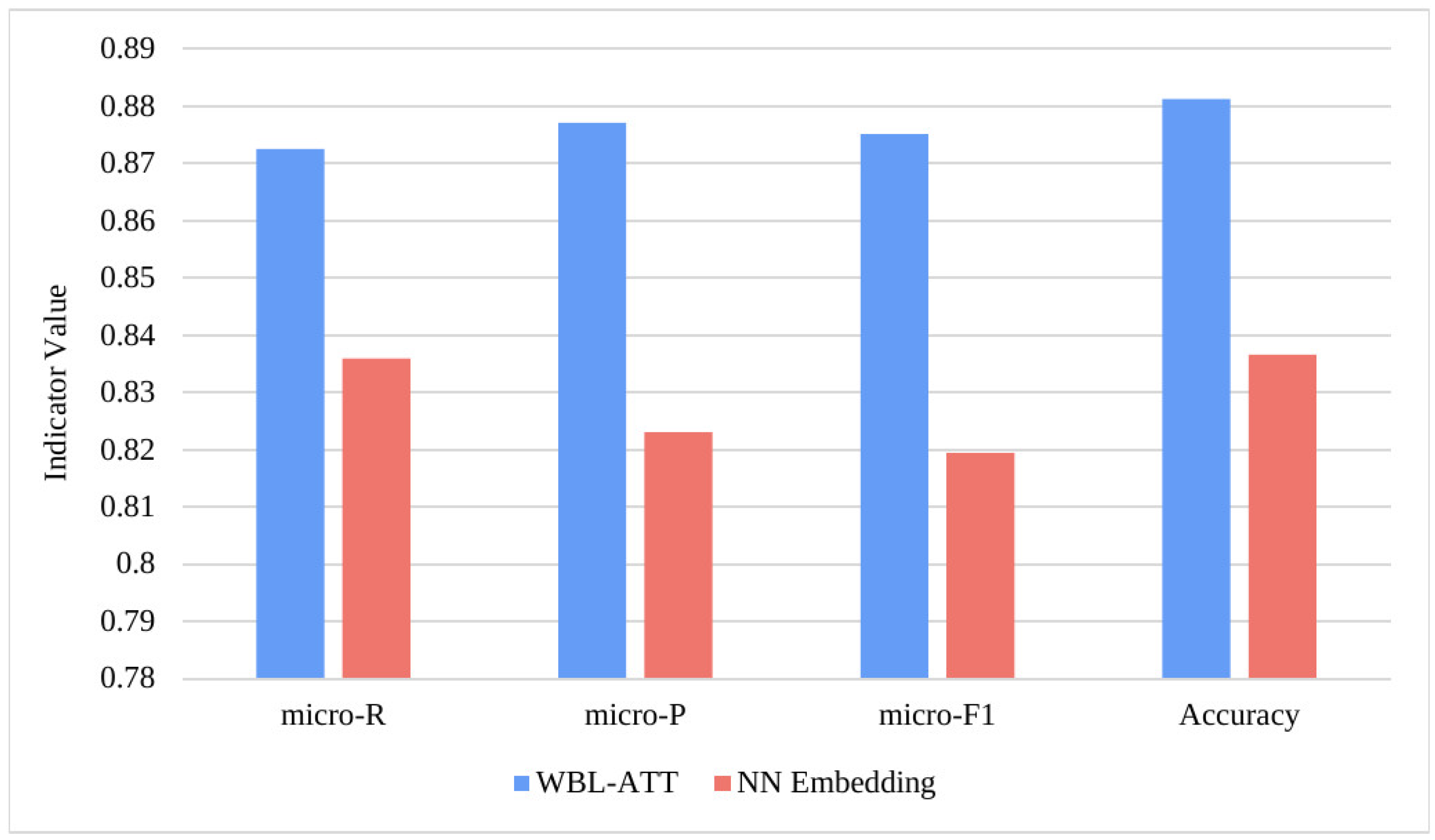
We collected a total of 5700 verified smart contracts from the Ether website and manually added labels to all contracts by the Oyente static detection tool. The model proposed in this paper detects five types of vulnerabilities, which are reentrancy, integer overflow, integer underflow, transaction order dependency, and timestamp dependency, so the above-K value is 5. A contract corresponds to five labels, and the value of each label is 0 or 1. When the value is 0, it means that the contract has no certain vulnerability, and when the value is 1, it means that there is a vulnerability of that type, and each vulnerability label is independent of the other. For example, the label of contract p is , which means contract p has reentrancy and integer underflow vulnerability.
4.2. Vulnerability Detection Model
The vulnerability detection model for smart contracts is the core module, which mainly designs and trains specific network models for the vulnerability detection framework, and adjusts the parameters of the models and algorithms in the training process in conjunction with the requirements to obtain the detection model with optimal parameters.
Recurrent neural networks (RNN are commonly used to process sequential data and are widely used in the field of NLP. As the number of network layers increases and the training time lengthens, the original RNN is prone to gradient disappearance and gradient explosion, and to solve this problem, S. Hochreiter and J. Schmidhuber proposed the long short-term memory neural network (LSTM) [
44].
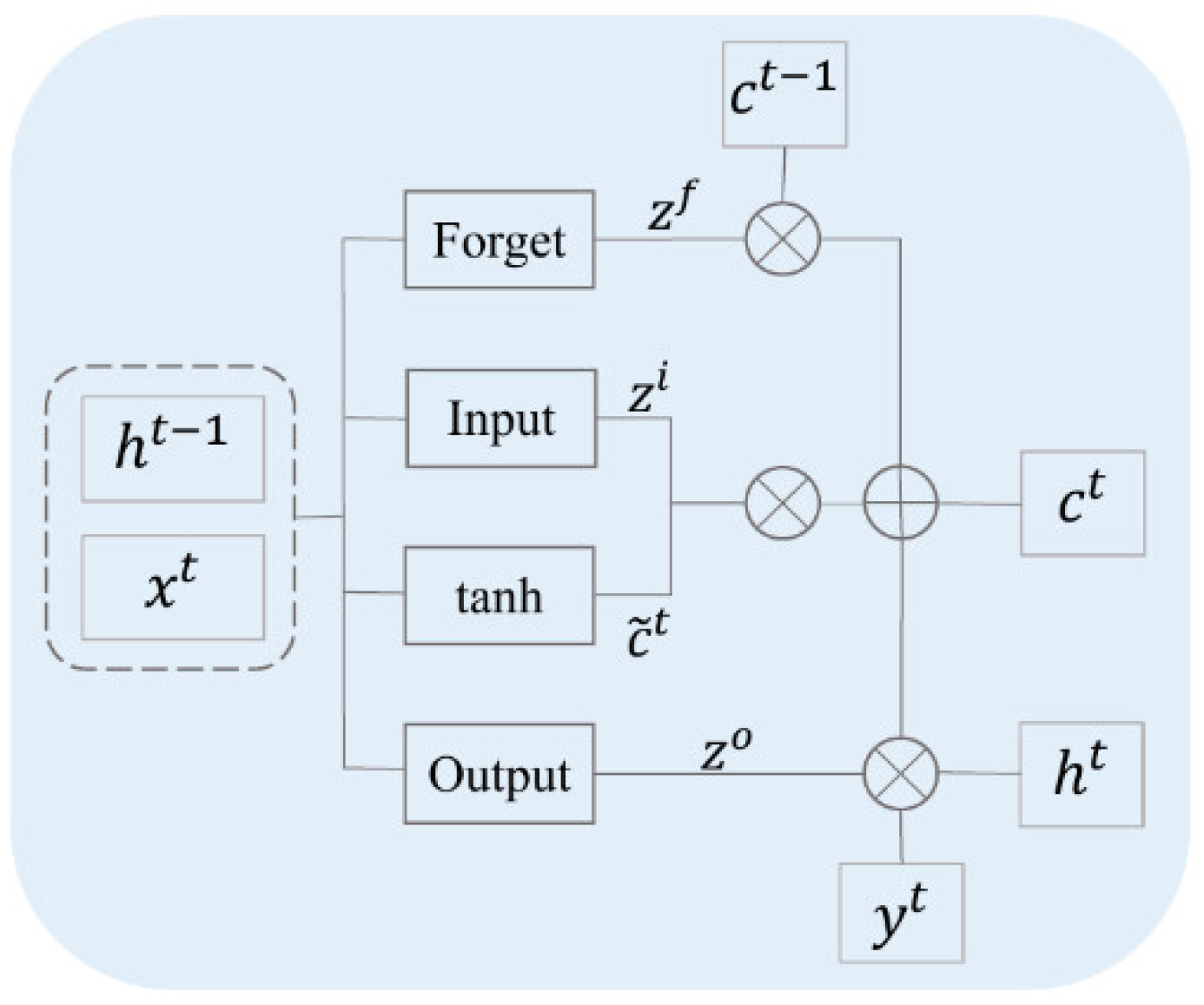
LSTM is an improved model based on a RNN, which can efficiently solve multiple learning problems associated with sequential data, better capture the dependencies between longer distance operands in contract sequences, and have better performance in handling long sequence data [
45]. The LSTM model is formed by connecting multiple LSTM cells. The cell structure of LSTM is shown in
Figure 3. Compared with an RNN, which has only one transmission state,
(cell state), LSTM adds a
(hidden state), including two transmission statuses. The input gate, output gate, and forget gate in the LSTM cell jointly realize the functions of long-term and short-term memory, and together with the cell state
constitute the LSTM cell. The input gate determines how much input information
is retained in the cell structure, the forget gate determines how much information
should be retained from the hidden state
at the previous moment to the current moment, and the output gate determines how much information
is output from the cell state
. Each gate completes the tasks of forgetting and remembering by regulating the cell information. The specific calculation formula is as follows:
where
and
are the transfer of the previous state and the current input respectively, and the transfer
and the current output
of the next unit are updated through three gating units,
,
,
,
are weights,
,
,
,
are bias vectors, and
is the activation function.
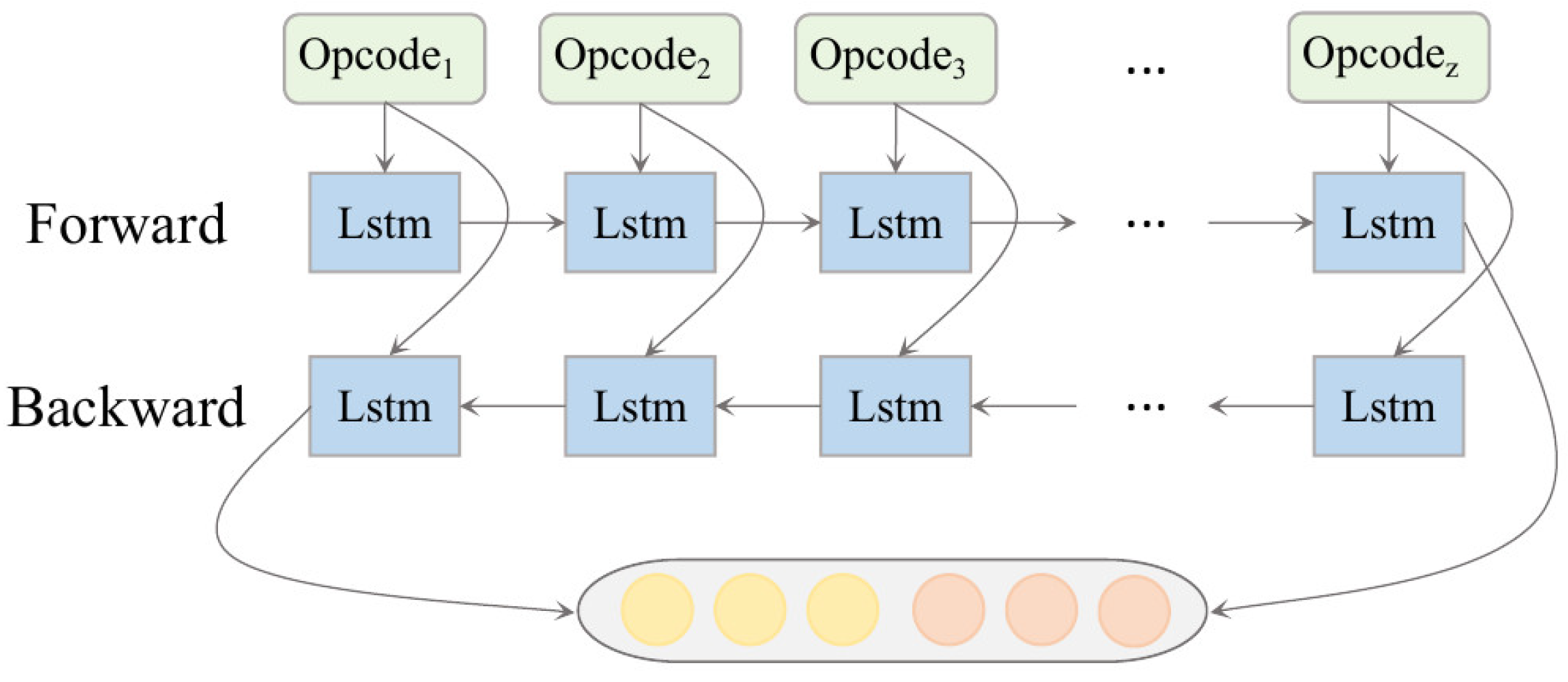
The data processing process of LSTM can be summarized as passing valuable information by forgetting and remembering the information in the transmission state, but it can only realize one-way information transmission, and cannot be analyzed when modeling smart contract datasets. Therefore, for our model we selected a bidirectional long short-term memory neural network (Bi-LSTM) [
46] to better capture bidirectional semantic dependencies. The data processing process of one layer of Bi-LSTM is shown in
Figure 4.
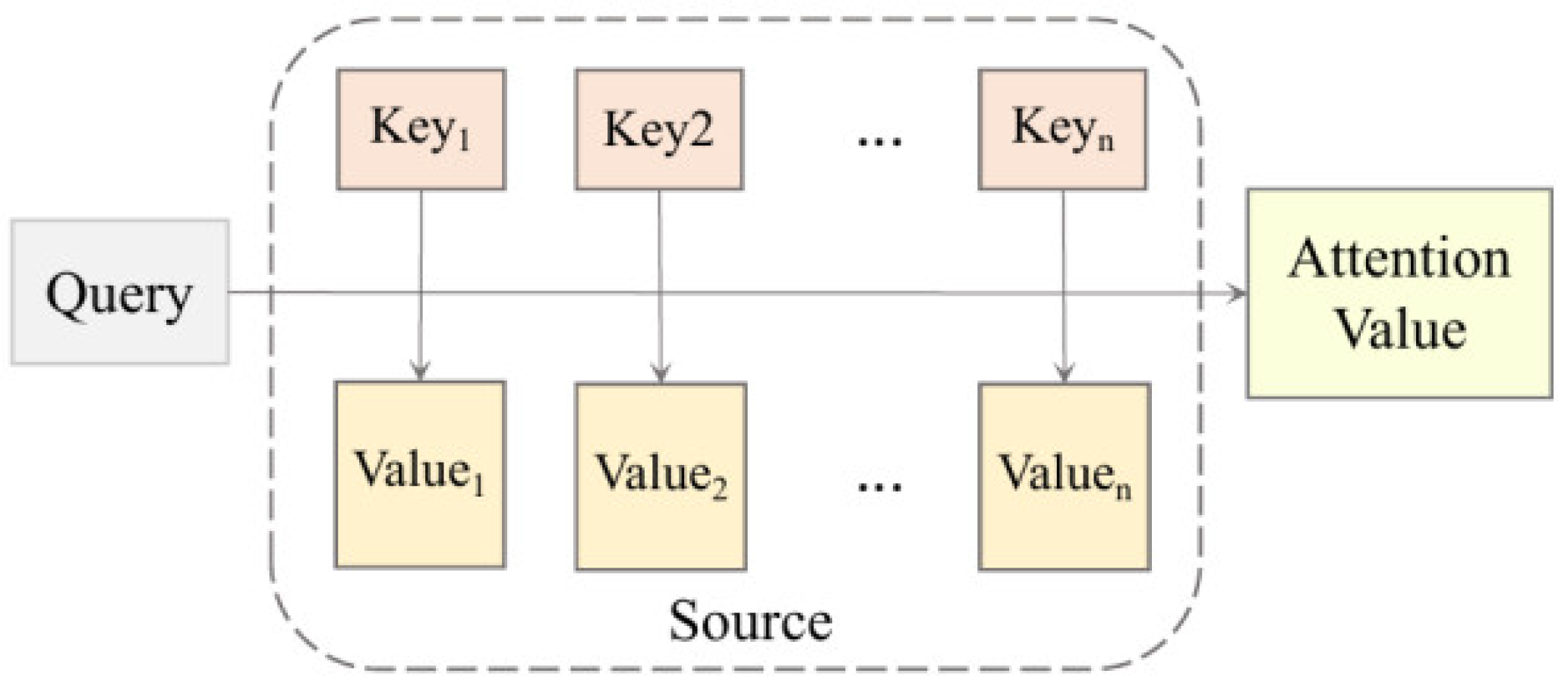
Whether it is LSTM or Bi-LSTM, when processing the contract dataset, it can only calculate the opcodes in the forward or reverse order. This mechanism will calculate the time step
t depending on the calculation result at the time of
t − 1, and the performance will drop dramatically when processing data sequences that are too long, so we introduced the attention mechanism [
47]. As shown in
Figure 5, its essence can be described as a query (query) to a series of (key-value) correct mappings. It focuses limited attention on important opcodes and assigns weights to them, thereby saving resources and quickly obtaining the most effective feature information. To highlight the important information implicit in the smart contract opcode, the attention layer first calculates the feature matrix
output from the Bi-LSTM layer to obtain its implicit representation
H, which is calculated as shown in Equation (9), and then calculates the similarity between
H and the random initialization parameter matrix
, normalizes the weight coefficients assigned to the input feature vector in the overall semantic scenario using the softmax function to obtain the weights
α, and finally multiplies the weight matrix
α with the feature matrix
to obtain the implicit features
Y of the opcode, as shown in the following equation.
where
denotes the attention layer weight matrix and
denotes the bias vector of the attention layer.
After the data are processed by the Bi-LSTM layer and attention layer, the output is still high-dimensional data compared to the classifiable vulnerability classes, and the output dimensions and parameters of each network layer are shown in
Table 4. We added a fully-connected layer to convert the output vector into the dimensionality of a multi-label vector. In contrast to the Bi-LSTM and attention layers, which extract features, the fully-connected layer serves to map the learned distributed feature representation into the sample label space. When processing sequential samples, the fully-connected layer maps the embedding space to the hidden space and then transforms the hidden space to the sample label space to achieve the classification effect, and in the multi-label classification task, the sigmoid function is used as the activation function of the output layer to model the classes’ Bernoulli probability distribution, as shown in Equation (12), and also use binary cross-entropy loss function as the activation function to calculate the loss for each label of a sample and take the average as the final loss to solve the multi-label classification problem, as shown in Equation (13). For the vector output by the fully connected layer, the calculation results of each category are respectively input into the sigmoid function, and the value of the vector is mapped to the probability value between
. We set the threshold probability to 0.5, and if the probability value is greater than 0.5, it is determined that the sample contains this type of vulnerability, and the output is assumed to be
, indicating that the sample contains reentrancy and timestamp dependency vulnerabilities.
where
z is the output of the fully connected layer,
is the true value (0 or 1) corresponding to the
k-th class, and
σ(
z) is the output value corresponding to the model; that is, the probability value corresponding to each vulnerability label.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}