
A High Flexible Shift Transformation Unit Design Approach for Coarse-Grained Reconfigurable Cryptographic Arrays


Abstract
:1. Introduction
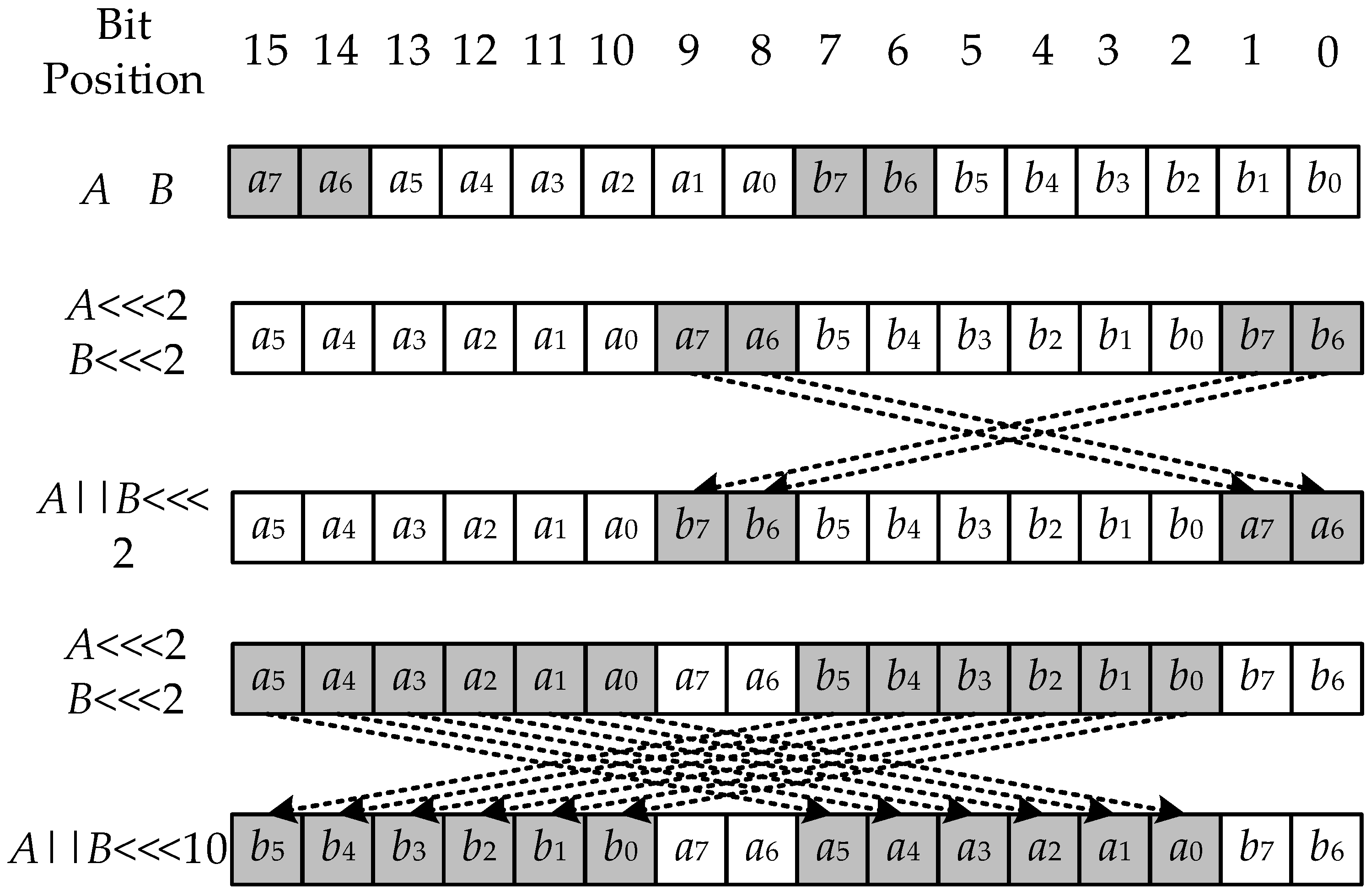
2. Mathematical Analysis of Shift Transformation
2.1. Background for Shift Transformation in Cryptography
2.2. Mathematical Properties of Shift Transformations
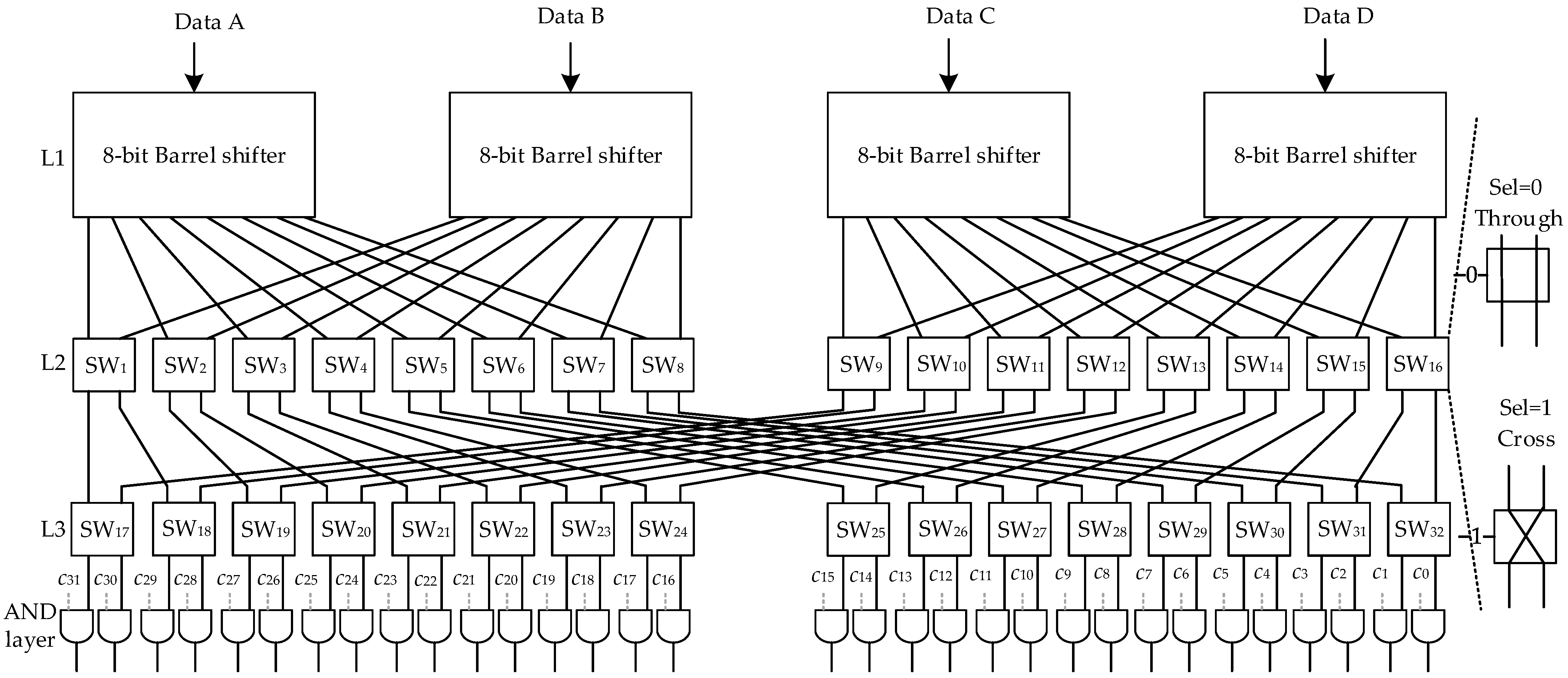
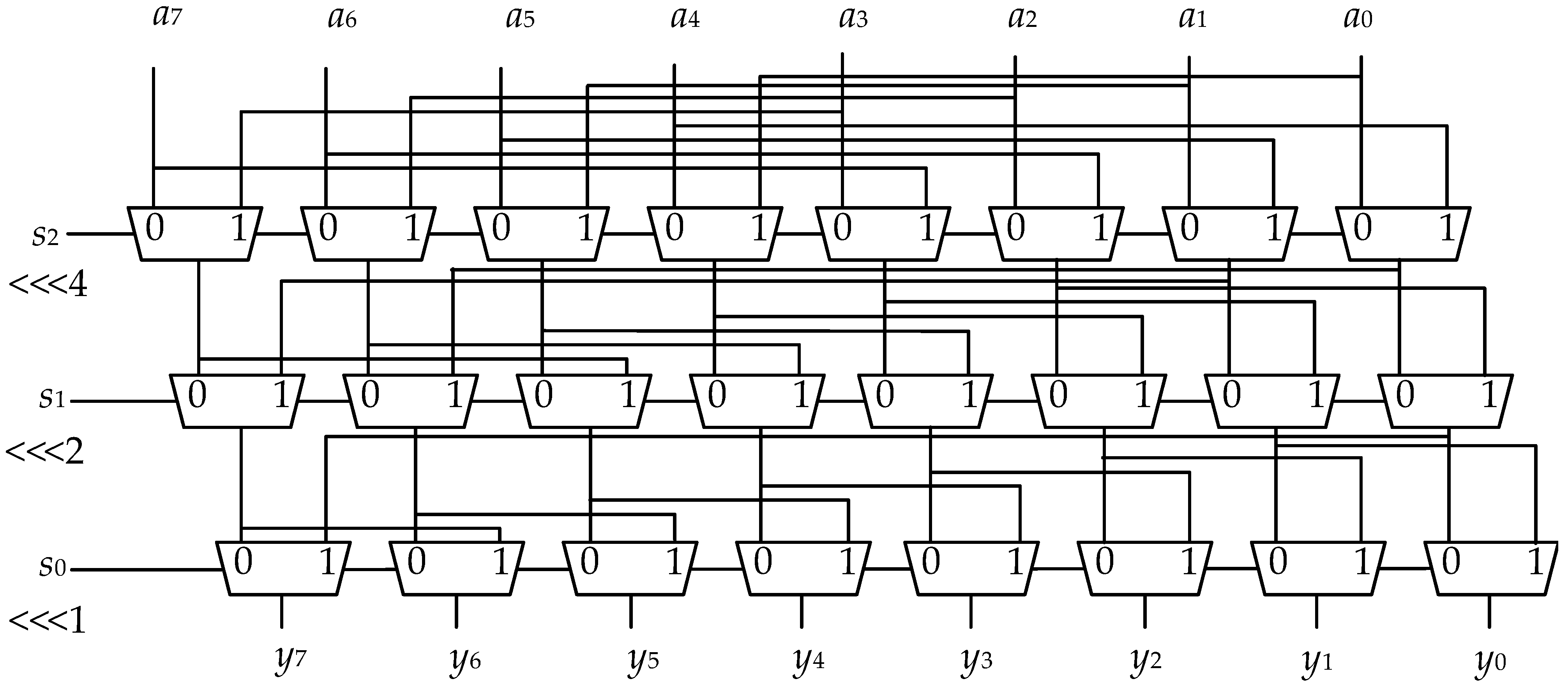
3. Reconfigurable Shift Transformation Unit Design and Data Path Analysis
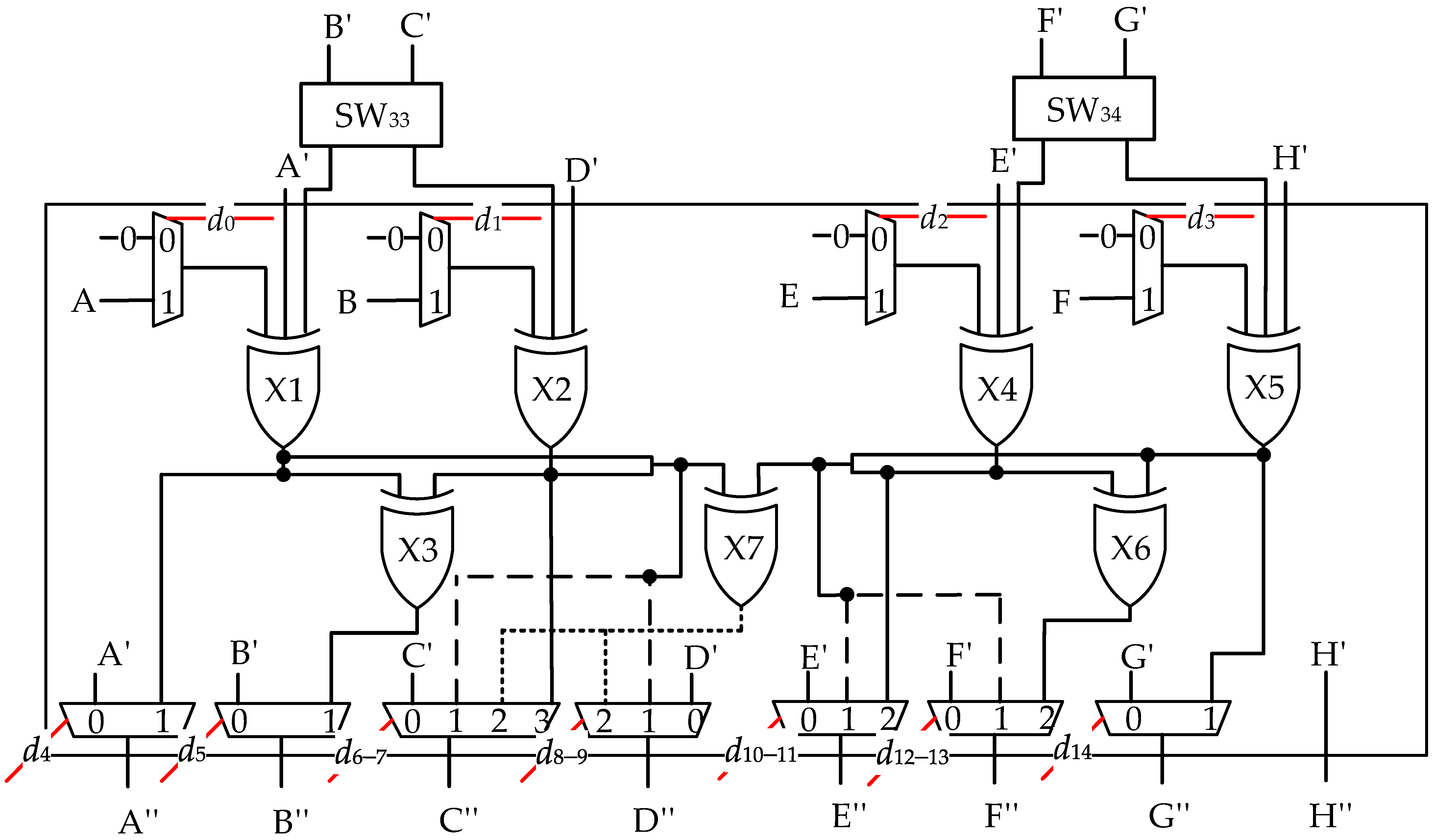
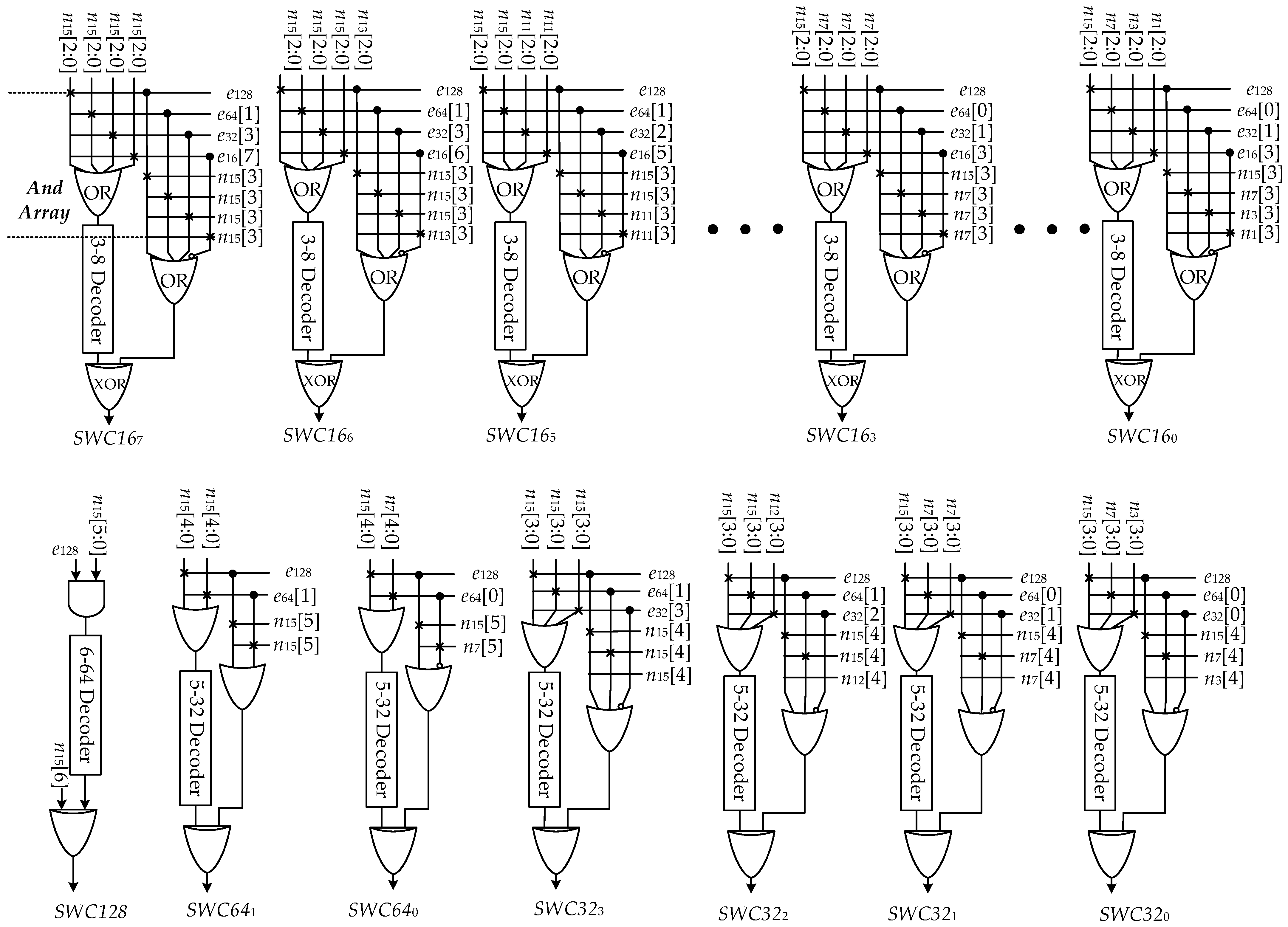
4. Control Information Generating Module Design
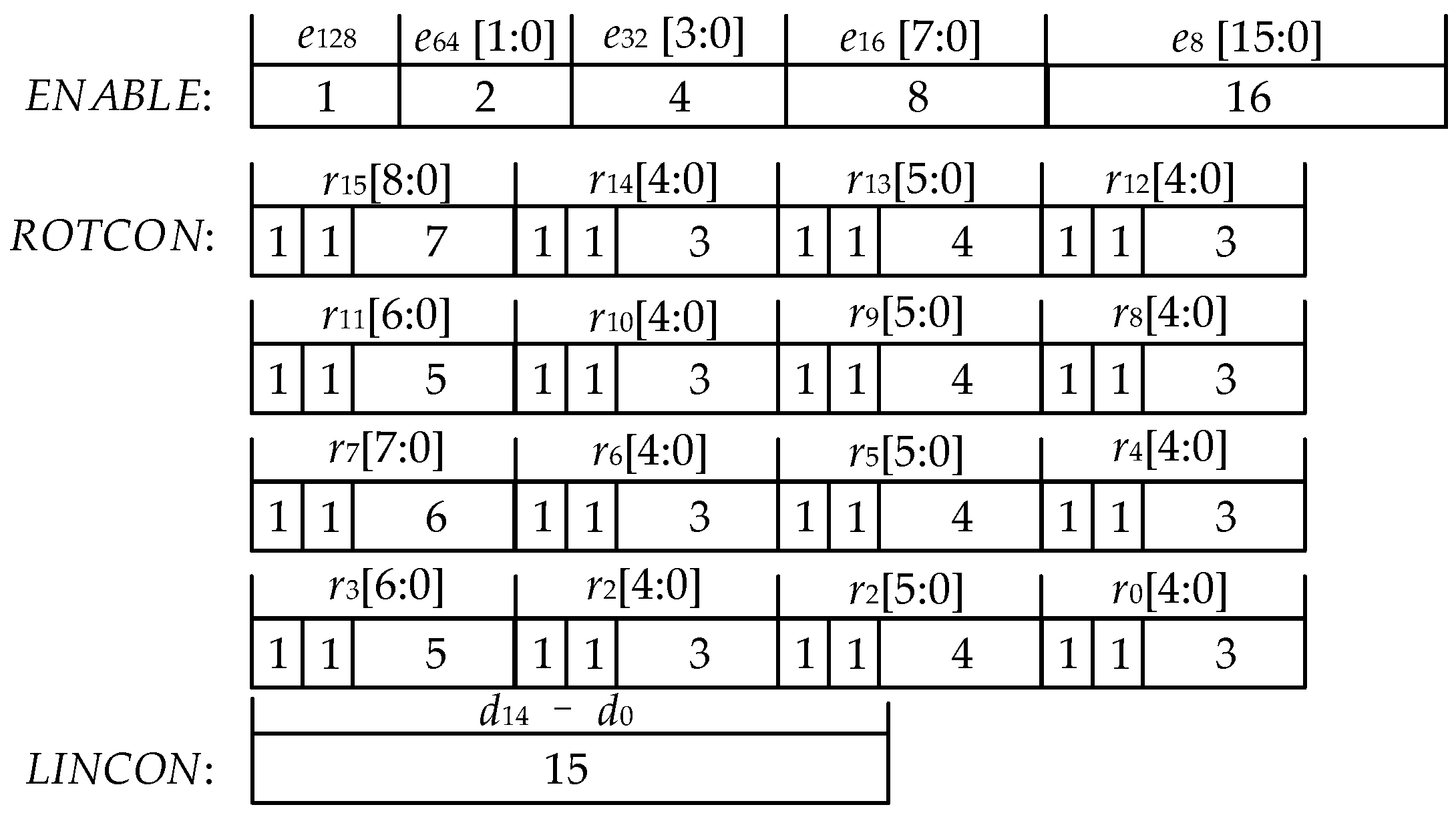
4.1. The Configuration Word Format of RSTU
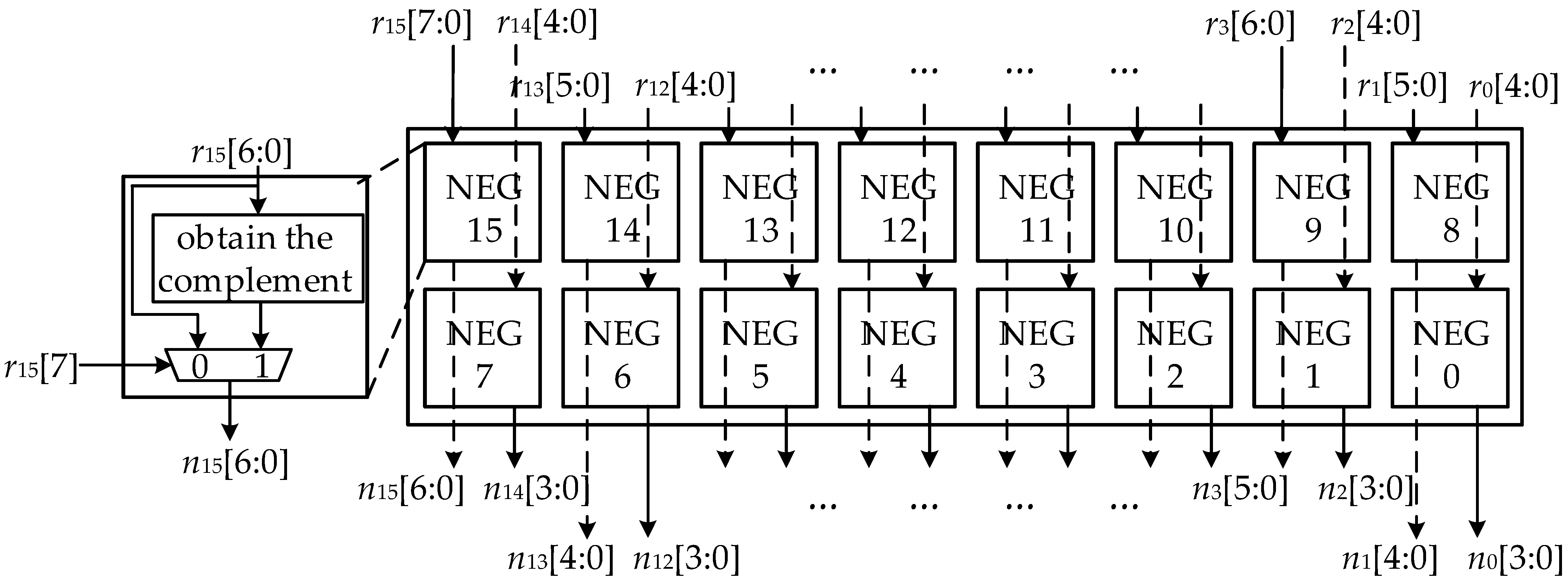
4.2. The Routing Algorithms for Generating Control Information and CIGM Architecture
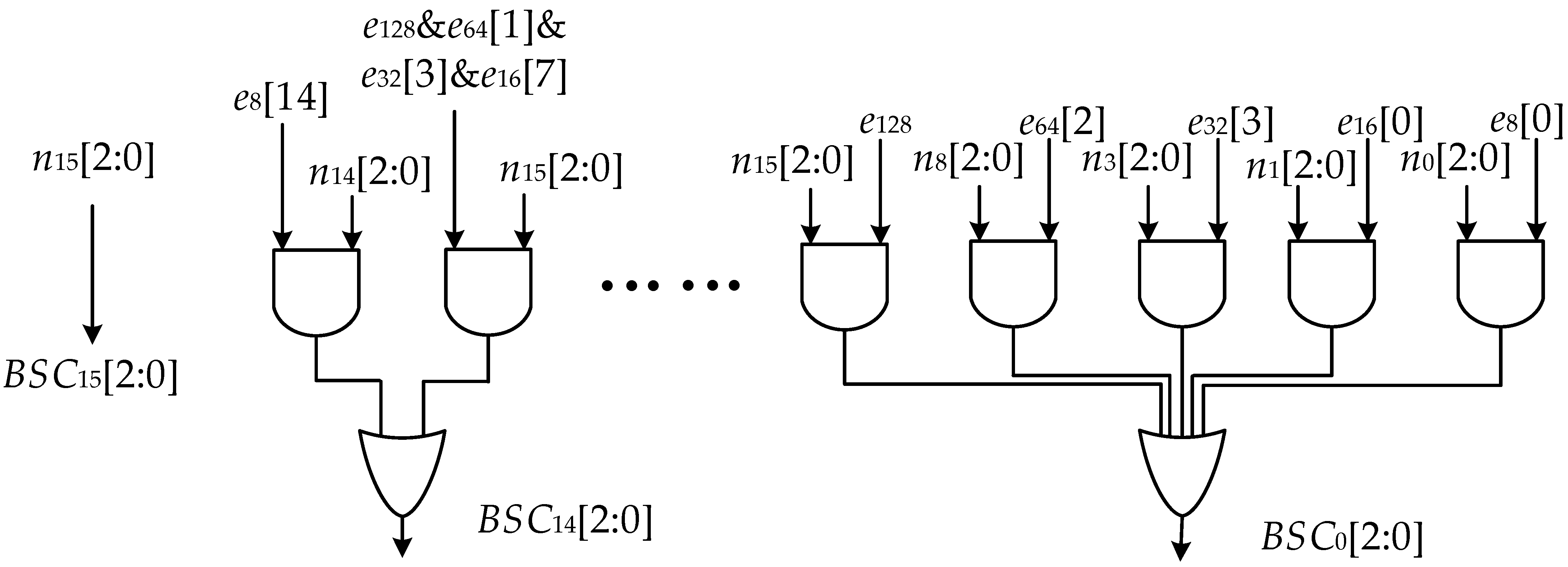
| Algorithm 1: The algorithm for generating BSC. Input: ENABLE, ROTCON, n15−n0; Output: BSC15−BSC0 (48 bit); |
Begin
|
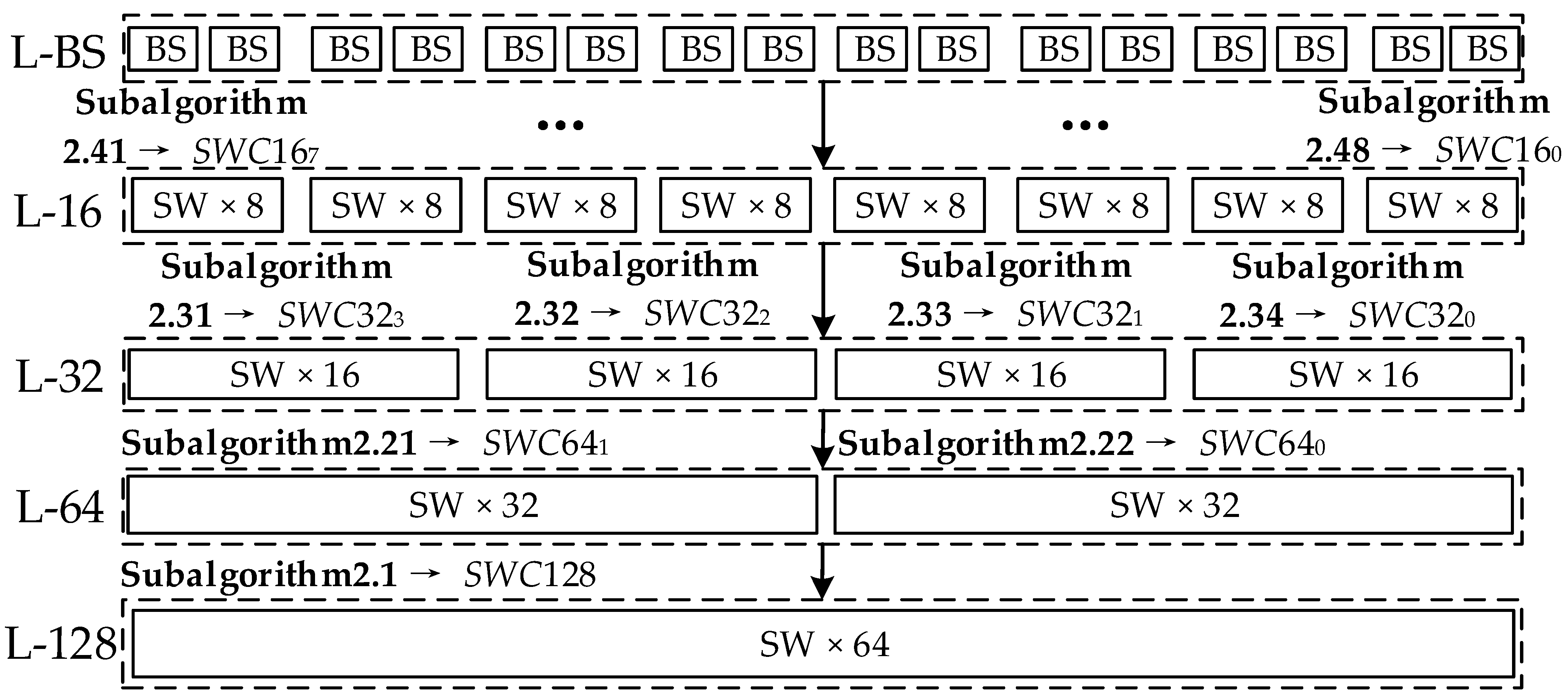
| Algorithm 2: The algorithms for generating SWC Input: ENABLE, ROTCON, n15−n0; Output: SWC128, SWC64, SWC32, SWC16 (256 bit); |
Sub-Algorithm 2.1. Begin:
Sub-Algorithm 2.21; Sub-Algorithm 2.22; …… Sub-Algorithm 2.48. Begin:
|
- Judge which shift mode the RSTU works in through ENABLE.
- Leverage the DEV and INV functions to generate the control information SWC160, in combination with the corresponding ROTCON sub-fields.
- Leverage the and gates array and ENABLE configuration bits to set the unused complement to 0;
- Input all the results of and array through the or gate to obtain the input of the decoder;
- Decode the complement to get SWC.
- Adjust the difference caused by the shift bit-width through the xor gate.
5. Functional and Performance Analysis
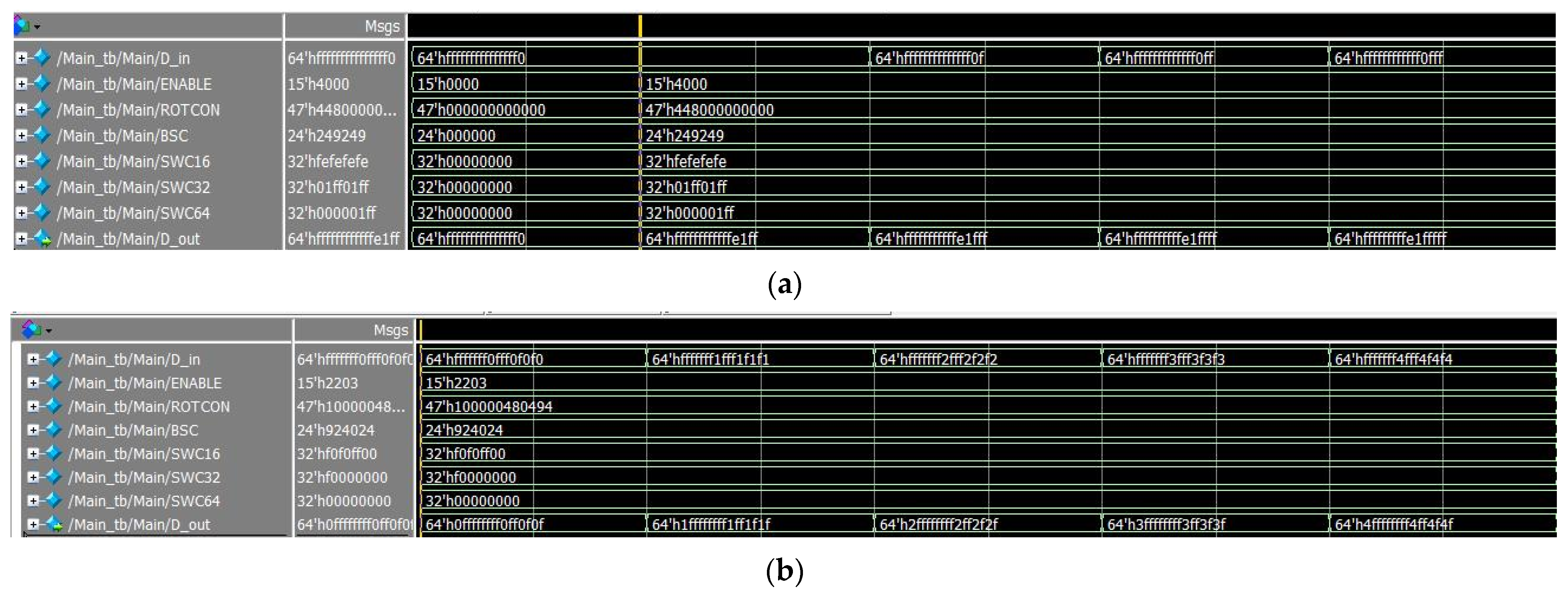
5.1. Functional Test and Comparison
5.2. Performance Comparisons and Analysis
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wijtvliet, M.; Waeijen, L.; Corporaal, H. Coarse Grained Reconfigurable Architectures in The Past 25 Years: Overview and Classification. SAMOS 2017. In Proceedings of the 2017 International Conference on Embedded Computer Systems: Architectures, Modeling and Simulation, Agios Konstantinos, Greece, 17–21 July 2016; pp. 235–244. [Google Scholar] [CrossRef]
- Zhu, J.; Wei, S.; Liu, L.; Li, Z. Reconfigurable computing: Toward software defined chips. Sci. Sin. Inf. 2020, 50, 1407–1426. [Google Scholar] [CrossRef]
- Bossuet, L.; Grand, M.; Gaspar, L.; Fischer, V.; Gogniat, G. Architectures of Flexible Symmetric Key Crypto Engines--A Survey: From Hardware Coprocessor to Multi-crypto-processor System on Chip. Acm Comput. Surv. 2013, 45, 1–32. [Google Scholar] [CrossRef]
- Gokhan, S.; Derek, C. Cryptoraptor: High Throughput Reconfigurable Cryptographic Processor. ICCAD 2014. In Proceedings of the 2014 International Conference on Computer Aided Design, San Jose, CA, USA, 2–6 November 2014; pp. 155–161. [Google Scholar] [CrossRef]
- Liu, L.; Wang, B.; Deng, C.; Zhu, M.; Yin, S.; Wei, S. Anole: A Highly Efficient Dynamically Reconfigurable Crypto-Processor for Symmetric-Key Algorithms. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 2018, 37, 3081–3094. [Google Scholar] [CrossRef]
- Deng, C.; Wang, B.; Liu, L.; Zhu, M.; Wu, Y.; Li, H.; Yin, S.; Wei, S. A 60 Gb/s-Level Coarse-Grained Reconfigurable Cryptographic Processor with Less Than 1W Power. IEEE Trans. Circuits Syst. II Express Briefs 2019, 67, 375–379. [Google Scholar] [CrossRef]
- Wang, B.; Liu, L.B. A Flexible and Energy-Efficient Reconfigurable Architecture for Symmetric Cipher Processing. ISCS 2015. In Proceedings of the 2015 IEEE International Symposium on Circuits and Systems, Lisbon, Portugal, 24–27 May 2015; pp. 1182–1185. [Google Scholar] [CrossRef]
- Du, Y.; Li, W.; Dai, Z.; Nan, L. PVHArray: An Energy-Efficient Reconfigurable Cryptographic Logic Array with Intelligent Mapping. IEEE Trans. Very Large Scale Integr. Syst. 2020, 28, 1302–1315. [Google Scholar] [CrossRef]
- Jinjiang, Y.; Wei, G.; Peng, C.; Jun, Y. An Area-Efficient Design of Reconfigurable S-box for Parallel Implementation of Block Ciphers. IEICE Electron. Express 2016, 13, 20160138. [Google Scholar] [CrossRef]
- Nan, L.; Zeng, X.; Wang, Z.; Du, Y.; Li, W. Research of a Reconfigurable Coarse-Grained Cryptographic Processing Unit Based on Different Operation Similar Structure. ASICON 2017. In Proceedings of the 2017 IEEE 12th International Conference on ASIC, Guiyang, China, 25–28 October 2017; pp. 191–194. [Google Scholar] [CrossRef]
- Bansod, G.; Raval, N.; Pisharoty, N. Implementation of a New Lightweight Encryption Design for Embedded Security. IEEE Trans. Inf. Secur. 2014, 10, 142–151. [Google Scholar] [CrossRef]
- Jolfaei, A.; Wu, X.W.; Muthukkumarasamy, V. On the Security of Permutation-Only Image Encryption Schemes. IEEE Trans. Inf. Secur. 2015, 11, 235–246. [Google Scholar] [CrossRef]
- Schwartz, S. Human–Mouse Alignments with BLASTZ. Genome Res. 2003, 13, 103–107. [Google Scholar] [CrossRef] [PubMed]
- Sanchez, A.C.; Sanchez, R.R. The Rijndael Block Cipher (AES proposal): A Comparison with DES. Iccst 2001. In Proceedings of the IEEE 35th Annual 2001 International Carnahan Conference on Security Technology, London, UK, 16–19 October 2001; pp. 229–234. [Google Scholar] [CrossRef]
- Orhanou, G.; El Hajji, S.; Lakbabi, A.; Bentaleb, Y. Analytical Evaluation of The Stream Cipher ZUC. ICMCS 2012. In Proceedings of the IEEE 12th International Conference on Multimedia Computing & Systems, Tangiers, Morocco, 10–12 May 2012. [Google Scholar] [CrossRef]
- Suhaili, S.B.; Watanabe, T. Design of High-Throughput SHA-256 Hash Function Based on FPGA. ICEEI 2017. In Proceedings of the 2017 6th International Conference on Electrical Engineering and Informatics, Langkawi, Malaysia, 25–27 November 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Chang, Z.; Dai, Z. Research on Extract-Shift-Reverse Routing Algorithm in Inverse Butterfly Network. CISCE 2017. In Proceedings of the International Conference on Communications, Information System and Computer Engineering, Haikou, China, 5–7 July 2019; pp. 206–209. [Google Scholar] [CrossRef]
- Hilewitz, Y.; Lee, R.B. A New Basis for Shifters in General-Purpose Processors for Existing and Advanced Bit Manipulations. IEEE Trans. Comput. 2009, 58, 1035–1048. [Google Scholar] [CrossRef]
- Ma, C.; Dai, Z.-B.; Li, W.; Zang, H.-J. A Highly Efficient Reconfigurable Rotation Unit Based on an Inverse Butterfly Network. Front. Inform. Technol. Electron. Eng. 2017, 18, 1784–1794. [Google Scholar] [CrossRef]
- Wu, C.; Tang, Y.; Wei, Y. A design of high-Speed SMS4 cipher circuit. AMTEI 2021. In Proceedings of the International Conference on Advanced Manufacturing Technology and Electronic Information, Zhuhai, China, 5 November 2021. [Google Scholar]
- Hong, D.; Sung, J.; Hong, S.; Lim, J.; Lee, S.; Koo, B.-S.; Lee, C.; Chang, D.; Lee, J.; Jeong, K.; et al. HIGHT: A New Block Cipher Suitable for Low-Resource Device. CHES 2016. In Proceedings of the International Workshop on Cryptographic Hardware and Embedded Systems, Yokohama, Japan, 10–13 October 2006; pp. 46–59. [Google Scholar] [CrossRef] [Green Version]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
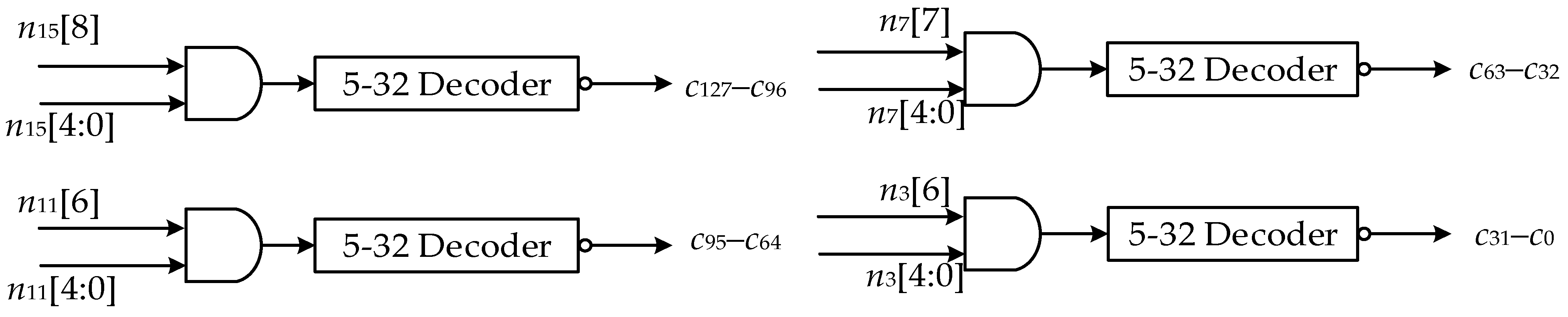{kind=link}
{kind=link}
| Operation | Barrel Shifter | Chang’s Shifter | Hilewitz’s Shifter | Ma’s Shifter | Our RSTU | Our Shifter with LT Module |
|---|---|---|---|---|---|---|
| 64-bit << & >> | √ * | √ | √ | √ | √ | √ |
| 64-bit <<< & >>> | √ | √ | √ | √ | √ | √ |
| 32-bit <<< & >>> | √ | √ | √ | |||
| 16-bit <<< & >>> | √ | √ | √ | |||
| 8-bit <<< & >>> | √ | √ | √ | |||
| Linear transformation | √ |
| Hardware Unit | Width (bits) | Total Area (μm2 ) | Relative Area | Latency (ns) | Relative Latency | ADP |
|---|---|---|---|---|---|---|
| Barrel shifter | 64 | 1875.32 | 1.00 | 0.53 | 1.00 | 1.00 |
| Chang’s shifter | 64 | 2906.75 | 1.55 | 0.58 | 1.11 | 1.72 |
| Hilewitz’s shifter | 64 | - | 1.38 | - | 1.18 | 1.63 |
| Ma’s shifter | 64 | 3038.40 | 1.62 | 0.60 | 1.13 | 1.83 |
| Our RSTU | 64 | 2579.56 | 1.37 | 0.54 | 1.01 | 1.38 |
| Algorithms | 4 | 8 | 32 | 64 | 128 | Linear Transformation |
|---|---|---|---|---|---|---|
| IDEA | √ | |||||
| AES | √ | |||||
| RC5 | √ | √ | ||||
| SMS4 | √ | √ | ||||
| Serpent | √ | √ | ||||
| Twofish | √ | |||||
| Safer+ | √ | |||||
| FEAL | √ | |||||
| ZUC | √ |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qu, T.; Dai, Z.; Liu, Y.; Chen, L. A High Flexible Shift Transformation Unit Design Approach for Coarse-Grained Reconfigurable Cryptographic Arrays. Electronics 2022, 11, 3144. https://doi.org/10.3390/electronics11193144
Qu T, Dai Z, Liu Y, Chen L. A High Flexible Shift Transformation Unit Design Approach for Coarse-Grained Reconfigurable Cryptographic Arrays. Electronics. 2022; 11(19):3144. https://doi.org/10.3390/electronics11193144
Chicago/Turabian StyleQu, Tongzhou, Zibin Dai, Yanjiang Liu, and Lin Chen. 2022. "A High Flexible Shift Transformation Unit Design Approach for Coarse-Grained Reconfigurable Cryptographic Arrays" Electronics 11, no. 19: 3144. https://doi.org/10.3390/electronics11193144