

Traffic Flow Prediction Based on Multi-Mode Spatial-Temporal Convolution of Mixed Hop Diffuse ODE
Abstract
:1. Introduction
- Neural networks typically perform better when stacking with more layers, while GNNs benefit little from depth. Ordinary GNNs have been shown to suffer from over-smoothing [16], with the increase in the number of layers of the graph convolution network, the features of all nodes tend to be more and more consistent.
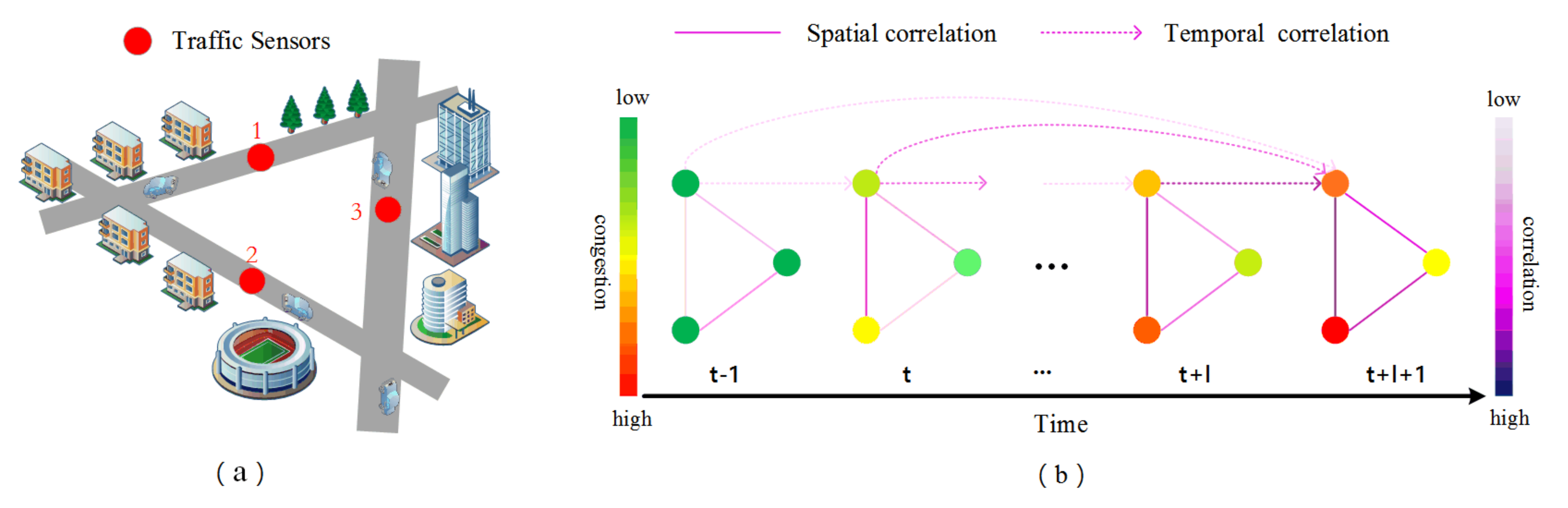
- The traffic flow in a traffic network is dynamic over time. For most areas in the road network, the traffic flow in a given time slice may be affected by the traffic flow in different historical periods, which makes the long-term flow dependence more complex, resulting in low prediction accuracy for a long time. As shown in Figure 1b traffic map signal tensor, the different colors of the sensors represent the level of congestion on the road. The sensor lines represent the correlation of the roads, the solid lines represent the spatial correlation of the roads and the dashed lines represent the correlation of the traffic at different time moments. The different colors of the sensor lines represent the degree of correlation between the roads. The congestion states of Road 1, Road 2, and Road 3 vary over time at different moments, which are both cyclical and subject to uncertainty in the long and short term. The short-term is affected by the timing of emergencies (e.g., sudden car accidents) and the long-term is affected by the time cycle (e.g., commuting), and the simultaneous long and short term makes the final traffic flow prediction tricky.
- In long-term forecasting, there is a lot of redundant information and hidden spatial dependencies in the traffic road network, which makes forecasting the future traffic flow very challenging. For example, in Figure 1a, the structure of the traffic road network, sensor 1 represents a road with residential areas and forested areas, sensor 2 represents a road with residential areas and stadiums, while sensor 3 represents a road with supermarkets and office buildings, while we cannot simply determine the relevance of roads by the difference in areas, and also the same road structure in different areas will show different spatial dependencies (the factors affecting these are economy, population, culture, etc.). This redundant information makes the spatial relevance of roads complex and varied.
- We propose an adaptive spatial-temporal convolution module that can extract the spatial-temporal features of traffic flow in short time steps using Gate TCN and adaptive graph convolution;
- We propose a spatial-temporal convolution module based on mixed hop diffuse ODE that uses the wider receptive field of the ODE graph convolution to extract new features while the mixed hop diffusion layer retains some of the original features and preventing transition smoothing, thereby extracting more spatial features over a longer time domain;
- We propose a new multi-mode spatial-temporal fusion module to integrate the hidden relationships between traffic data. We fuse the extracted features from different graph convolutions and can extract more hidden spatial-temporal dependencies;
- We evaluated our proposed model on two traffic datasets and conducted a large number of comparative experiments. The experimental results show that the MHODE performs better than other models in both datasets.
2. Related Work
2.1. Traffic Flow Forecasting Based on Statistical Methods
2.2. Traffic Flow Forecasting Based on Deep Learning Methods
3. Preliminary
4. Model
4.1. General Framework
4.2. Adaptive Spatial-Temporal Convolution Module
4.3. Mixed Hop Diffuse ODE Spatial-Temporal Convolution Module
4.4. Multi-Mode Spatial-Temporal Fusion Module
5. Experiments
5.1. Datasets and Pre-Processing
5.2. Experimental Setup
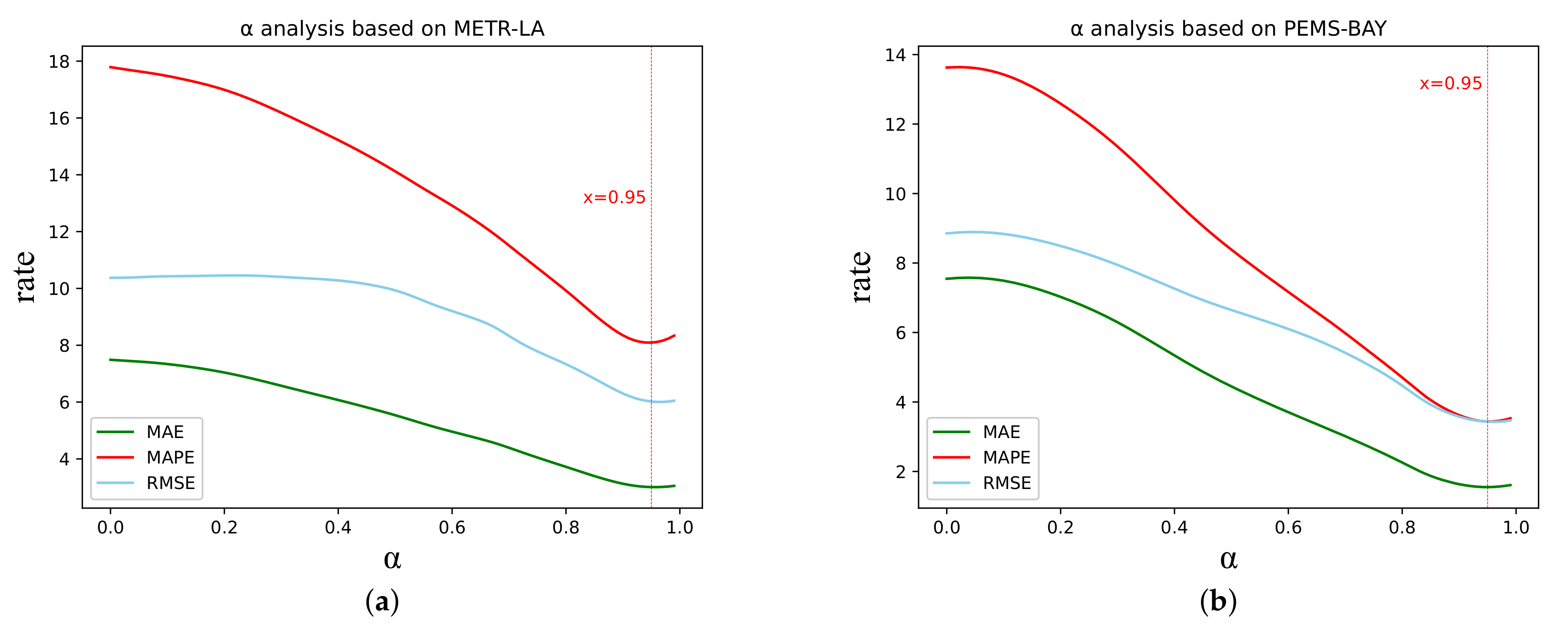
5.3. Hyperparametric Studies
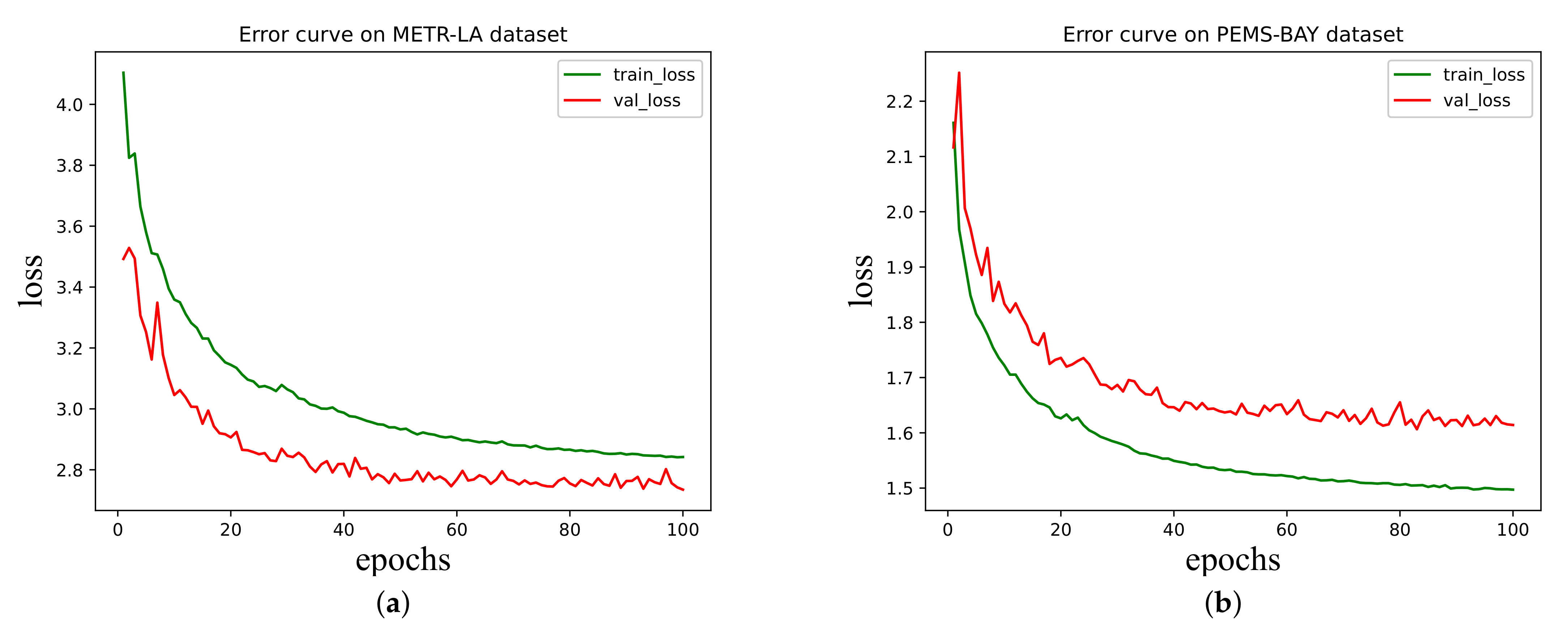
5.4. Convergence Analysis
5.5. Performance Comparison
5.6. Ablation Experiments
6. Case Study
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Tan, M.C.; Wong, S.C.; Xu, J.M.; Guan, Z.R.; Zhang, P. An aggregation approach to short-term traffic flow prediction. IEEE Trans. Intell. Transp. Syst. 2009, 10, 60–69. [Google Scholar]
- Lv, Y.; Duan, Y.; Kang, W.; Li, Z.; Wang, F.Y. Traffic flow prediction with big data: A deep learning approach. IEEE Trans. Intell. Transp. Syst. 2014, 16, 865–873. [Google Scholar] [CrossRef]
- Shu, W.; Cai, K.; Xiong, N.N. A Short-Term Traffic Flow Prediction Model Based on an Improved Gate Recurrent Unit Neural Network. IEEE Trans. Intell. Transp. Syst. 2022, 23, 16654–16665. [Google Scholar] [CrossRef]
- Shao, Y.; Wang, Q.J.; Schepen, A.; Ryu, D. Going with the trend: Forecasting seasonal climate conditions under climate change. Mon. Weather. Rev. 2021, 149, 2513–2522. [Google Scholar] [CrossRef]
- Tilman, D.; Fargione, J.; Wolff, B.; D’antonio, C.; Dobson, A.; Howarth, R.; Schindler, D.; Schlesinger, W.H.; Simberloff, D.; Swackhamer, D. Forecasting agriculturally driven global environmental change. Science 2001, 292, 281–284. [Google Scholar] [CrossRef] [PubMed]
- Crampin, S.; Evans, R.; Atkinson, B.K. Earthquake prediction: A new physical basis. Geophys. J. R. Astron. Soc. 2010, 76, 147–156. [Google Scholar] [CrossRef]
- Geller, R.J. Earthquake prediction: A critical review. Geophys. J. R. Astron. Soc. 2010, 131, 425–450. [Google Scholar] [CrossRef]
- Jiang, R.; Yin, D.; Wang, Z.; Wang, Y.; Deng, J.; Liu, H.; Cai, Z.; Deng, J.; Song, X.; Shibasaki, R. Dl-traff: Survey and benchmark of deep learning models for urban traffic prediction. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management, Online, 1–5 November 2021; pp. 4515–4525. [Google Scholar]
- Wu, Y.; Tan, H. Short-term traffic flow forecasting with spatial-temporal correlation in a hybrid deep learning framework. arXiv 2016, arXiv:1612.01022. [Google Scholar]
- Zhou, X.; Shen, Y.; Zhu, Y.; Huang, L. Predicting multi-step citywide passenger demands using attention-based neural networks. In Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining, Los Angeles, CA, USA, 5–9 February 2018; pp. 736–744. [Google Scholar]
- Song, X.; Kanasugi, H.; Shibasaki, R. Deeptransport: Prediction and simulation of human mobility and transportation mode at a citywide level. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence, New York, NY, USA, 9–15 July 2016; pp. 2618–2624. [Google Scholar]
- Wu, Z.; Pan, S.; Long, G.; Jiang, J.; Chang, X.; Zhang, C. Connecting the dots: Multivariate time series forecasting with graph neural networks. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual, 6–10 July 2020; pp. 753–763. [Google Scholar]
- Huang, R.; Huang, C.; Liu, Y.; Dai, G.; Kong, W. LSGCN: Long Short-Term Traffic Prediction with Graph Convolutional Networks. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, Yokohama, Japan, 7–15 January 2021; pp. 2355–2361. [Google Scholar]
- Fang, M.; Tang, L.; Yang, X.; Chen, Y.; Li, Q. FTPG: A Fine-Grained Traffic Prediction Method with Graph Attention Network Using Big Trace Data. IEEE Trans. Intell. Transp. Syst. 2022, 23, 5163–5175. [Google Scholar] [CrossRef]
- Zhang, X.; Huang, C.; Xu, Y.; Xia, L.; Dai, P.; Bo, L.; Zhang, J.; Zheng, Y. Traffic flow forecasting with spatial-temporal graph diffusion network. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 15008–15015. [Google Scholar]
- Fang, Z.; Long, Q.; Song, G.; Xie, K. Spatial-temporal graph ode networks for traffic flow forecasting. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Singapore, 14–18 August 2021; pp. 364–373. [Google Scholar]
- Wu, Z.; Pan, S.; Long, G.; Jiang, J.; Zhang, C. Graph WaveNet for Deep Spatial-Temporal Graph Modeling. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; pp. 1–7. [Google Scholar]
- Yin, X.; Wu, G.; Wei, J.; Shen, Y.; Qi, H.; Yin, B. Deep learning on traffic prediction: Methods, analysis and future directions. IEEE Trans. Intell. Transp. Syst. 2022, 23, 4927–4943. [Google Scholar] [CrossRef]
- Williams, B.M.; Hoel, L.A. Modeling and Forecasting Vehicular Traffic Flow as a Seasonal ARIMA Process: Theoretical Basis and Empirical Results. J. Transp. Eng. 2003, 129, 664–672. [Google Scholar] [CrossRef]
- Alghamdi, T.; Elgazzar, K.; Bayoumi, M.; Sharaf, T.; Shah, S. Forecasting traffic congestion using ARIMA modeling. In Proceedings of the 2019 15th International Wireless Communications & Mobile Computing Conference (IWCMC), Tangier, Morocco, 24–28 June 2019; pp. 1227–1232. [Google Scholar]
- Cai, P.; Wang, Y.; Lu, G.; Chen, P.; Ding, C.; Sun, J. A spatiotemporal correlative k-nearest neighbor model for short-term traffic multistep forecasting. Transp. Res. Part C Emerg. Technol. 2016, 62, 21–34. [Google Scholar] [CrossRef]
- Kulshreshtha, M.; Nag, B.; Kulshrestha, M. A multivariate cointegrating vector auto regressive model of freight transport demand: Evidence from Indian railways. Transp. Res. Part A 2008, 35, 29–45. [Google Scholar] [CrossRef]
- Agarap, A.F.M. A neural network architecture combining gated recurrent unit (GRU) and support vector machine (SVM) for intrusion detection in network traffic data. In Proceedings of the 2018 10th International Conference on Machine Learning and Computing, Macao, China, 26–28 February 2018; pp. 26–30. [Google Scholar]
- Yu, B.; Yin, H.; Zhu, Z. Spatio-temporal graph convolutional networks: A deep learning framework for traffic forecasting. In Proceedings of the 27th International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 3634–3640. [Google Scholar]
- Li, Y.; Yu, R.; Shahabi, C.; Liu, Y. Diffusion Convolutional Recurrent Neural Network: Data-Driven Traffic Forecasting. arXiv 2018, arXiv:1707.01926. [Google Scholar]
- Chen, W.; Chen, L.; Xie, Y.; Cao, W.; Gao, Y.; Feng, X. Multi-range attentive bicomponent graph convolutional network for traffic forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 3529–3536. [Google Scholar]
- Zheng, C.; Fan, X.; Wang, C.; Qi, J. Gman: A graph multi-attention network for traffic prediction. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 1234–1241. [Google Scholar]
- Park, C.; Lee, C.; Bahng, H.; Tae, Y.; Jin, S.; Kim, K.; Ko, S.; Choo, J. ST-GRAT: A novel spatio-temporal graph attention networks for accurately forecasting dynamically changing road speed. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, Virtual, 19–23 October 2020; pp. 1215–1224. [Google Scholar]
- Yu, F.; Koltun, V. Multi-Scale Context Aggregation by Dilated Convolutions. arXiv 2016, arXiv:1511.07122. [Google Scholar]
- Gasteiger, J.; Bojchevski, A.; Günnemann, S. Predict then Propagate: Graph Neural Networks meet Personalized Page Rank. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018; pp. 1–15. [Google Scholar]
- Pan, Z.; Liang, Y.; Wang, W.; Yu, Y.; Zheng, Y.; Zhang, J. Urban traffic prediction from spatio-temporal data using deep meta learning. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 1720–1730. [Google Scholar]
- Oreshkin, B.N.; Amini, A.; Coyle, L.; Coates, M. FC-GAGA: Fully connected gated graph architecture for spatio-temporal traffic forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 9233–9241. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | METR-LA | PEMS-BAY |
|---|---|---|
| Start time | 1 March 2012 | 1 January 2017 |
| End time | 30 June 2012 | 31 May 2017 |
| Time interval (min) | 5 | 5 |
| Total time (5 min) | 34,272 | 52,116 |
| Training set (5 min) | 23,990 | 36,481 |
| Validating set (5 min) | 3427 | 5211 |
| Testing set (5 min) | 6854 | 10,423 |
| Number of sensors | 207 | 325 |
| METR-LA | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| 15 min | 30 min | 60 min | |||||||
| MAE | RMSE | MAPE | MAE | RMSE | MAPE | MAE | RMSE | MAPE | |
| 1 | 2.69 | 5.15 | 6.90% | 3.07 | 6.17 | 8.34% | 3.51 | 7.25 | 9.992% |
| 0.95 | 2.69 | 5.17 | 6.88% | 3.04 | 6.15 | 8.23% | 3.47 | 7.21 | 9.77% |
| PEMS-BAY | |||||||||
| 15 min | 30 min | 60 min | |||||||
| MAE | RMSE | MAPE | MAE | RMSE | MAPE | MAE | RMSE | MAPE | |
| 1 | 1.296 | 2.72 | 2.67% | 1.61 | 3.62 | 3.55 % | 1.90 | 4.49 | 4.34% |
| 0.95 | 1.30 | 2.72 | 2.67% | 1.61 | 3.62 | 3.55% | 1.90 | 4.49 | 4.34% |
| Method | METR-LA | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Horizon 3 | Horizon 6 | Horizon 12 | |||||||
| MAE | RMSE | MAPE | MAE | RMSE | MAPE | MAE | RMSE | MAPE | |
| STGCN (2017) | 2.88 | 5.74 | 7.62% | 3.47 | 7.24 | 9.57% | 4.59 | 9.40 | 12.70% |
| DCRNN (2017) | 2.77 | 5.38 | 7.30% | 3.15 | 6.45 | 8.80% | 3.60 | 7.60 | 10.50% |
| Graph Wavenet (2019) | 2.69 | 5.15 | 6.90% | 3.07 | 6.22 | 8.37% | 3.53 | 7.37 | 10.01% |
| ST-MetaNet (2019) | 2.69 | 5.17 | 6.91% | 3.10 | 6.28 | 8.57% | 3.59 | 7.52 | 10.63% |
| MRA-BGCN (2019) | 2.67 | 5.12 | 6.80% | 3.06 | 6.17 | 8.30% | 3.49 | 7.30 | 10.00% |
| FC-GAGA (2020) | 2.75 | 5.34 | 7.25% | 3.10 | 6.30 | 8.57% | 3.51 | 7.31 | 10.14% |
| GMAN (2019) | 2.81 | 5.55 | 7.43% | 3.12 | 6.46 | 8.35% | 3.46 | 7.37 | 10.06% |
| STGRAT (2020) | 2.60 | 5.07 | 6.61% | 3.01 | 6.21 | 8.15% | 3.49 | 7.42 | 10.01% |
| MTGNN (2020) | 2.69 | 5.18 | 6.86% | 3.05 | 6.17 | 8.19% | 3.49 | 7.23 | 9.87% |
| MHODE | 2.69 | 5.17 | 6.88% | 3.04 | 6.15 | 8.23% | 3.47 | 7.21 | 9.77% |
| Method | PEMS-BAY | ||||||||
| Horizon 3 | Horizon 6 | Horizon 12 | |||||||
| MAE | RMSE | MAPE | MAE | RMSE | MAPE | MAE | RMSE | MAPE | |
| STGCN (2017) | 1.36 | 2.96 | 2.90% | 1.81 | 4.27 | 4.17% | 2.49 | 5.69 | 5.79% |
| DCRNN (2017) | 1.38 | 2.95 | 2.90% | 1.74 | 3.97 | 3.90% | 2.07 | 4.74 | 4.90% |
| Graph Wavenet (2019) | 1.30 | 2.74 | 2.73% | 1.63 | 3.70 | 3.67% | 1.95 | 4.52 | 4.63% |
| ST-MetaNet (2019) | 1.36 | 2.90 | 2.82% | 1.76 | 4.02 | 4.00% | 2.20 | 5.06 | 5.45% |
| MRA-BGCN (2019) | 1.29 | 2.72 | 2.90% | 1.61 | 3.67 | 3.80% | 1.91 | 4.46 | 4.60% |
| FC-GAGA (2020) | 1.36 | 2.86 | 2.87% | 1.68 | 3.80 | 3.80% | 1.97 | 4.52 | 4.67% |
| GMAN (2019) | 1.36 | 2.93 | 2.88% | 1.64 | 3.78 | 3.71% | 1.90 | 4.40 | 4.45% |
| STGRAT (2020) | 1.29 | 2.71 | 2.67% | 1.61 | 3.69 | 3.63% | 1.95 | 4.54 | 4.64% |
| MTGNN (2020) | 1.32 | 2.79 | 2.77% | 1.65 | 3.74 | 3.69% | 1.94 | 4.49 | 4.53% |
| MHODE | 1.30 | 2.72 | 2.67% | 1.61 | 3.62 | 3.55% | 1.90 | 4.49 | 4.34% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, X.; Lan, Y.; Ye, Y.; Wang, J.; Jiang, Y. Traffic Flow Prediction Based on Multi-Mode Spatial-Temporal Convolution of Mixed Hop Diffuse ODE. Electronics 2022, 11, 3012. https://doi.org/10.3390/electronics11193012
Huang X, Lan Y, Ye Y, Wang J, Jiang Y. Traffic Flow Prediction Based on Multi-Mode Spatial-Temporal Convolution of Mixed Hop Diffuse ODE. Electronics. 2022; 11(19):3012. https://doi.org/10.3390/electronics11193012
Chicago/Turabian StyleHuang, Xiaohui, Yuanchun Lan, Yuming Ye, Junyang Wang, and Yuan Jiang. 2022. "Traffic Flow Prediction Based on Multi-Mode Spatial-Temporal Convolution of Mixed Hop Diffuse ODE" Electronics 11, no. 19: 3012. https://doi.org/10.3390/electronics11193012