
An Improved RandLa-Net Algorithm Incorporated with NDT for Automatic Classification and Extraction of Raw Point Cloud Data
Abstract
:1. Introduction
- (1)
- The quantity of point cloud data is very large. Current point cloud semantic segmentation algorithms take a long time to train on large-scale data sets.
- (2)
- In order to quickly obtain complete road sections, trees and other components to make high-definition maps, most point cloud semantic segmentation algorithms segment data frame by frame to reduce the amount of computation. Therefore, it is necessary to construct the original data into a complete point cloud map, and then perform semantic segmentation. In this way, the complete information of the road section can be obtained.
- (3)
- The point cloud semantic segmentation is designed to assign labels to each point and classify points, though it is impossible to obtain point cloud sets from unclassified point data. In other words, the region of interest cannot be directly extracted, it is necessary to make labels for the point clouds, and then extract the corresponding point cloud data in turn according to the corresponding index.
- (1)
- Based on analyzing and comparing the existing registration and semantic segmentation methods, we chose to integrate NDT registration into the RandLa semantic segmentation algorithm to process original point cloud data.
- (2)
- (3)
- We give the description of the basic process of the improved RandLa-Net (network structure based on random sampling and local feature aggregation) algorithm incorporated with NDT, and use the improved method to perform many experiments on public datasets. The experimental results show that the data processed by our method can be directly used for the construction of a high-definition map.
2. Related Work
2.1. Methods for Point Cloud Data Registration and Semantic Segmentation
- (1)
- A registration method based on local feature description. The point feature histograms (PFH) methods proposed by Rusu et al. [7] use point feature histograms to characterize the local geometry of 3D points for registration;
- (2)
- Method based on probability distribution. The normal distributions transform (NDT) algorithm proposed by Biber [8] et al. is a rough registration method that uses range scanning first, that is, the normal distribution transformation is performed after point cloud matching. In recent years, point cloud registration methods based on deep learning have also been widely proposed and applied. Aoki [9] et al. used PointNet to map the found feature points to a high-dimensional space, and then regarded the vector formed by each feature point as an image in the high-dimensional space, and finally used the traditional image registration algorithm (Lucas-Kanada, LK) [10] for point cloud registration. Wang [11] et al. extracted the features of the point cloud to be registered; they used the improved transformer network to merge the information between the point clouds, calculated the soft matching between the point clouds, and then used the differentiable singular value decomposition module to extract the rigid body changes for point clouds. Here, cloud registration [12] was combined with keypoint detection to solve the non-convexity and local registration problems of registration.
- (1)
- Projection-based network [16]: due to the inhomogeneity of point cloud data, it is impossible to directly use the convolutional neural network on point cloud. To make use of two-dimensional convolutional neural network, the projection-based network chooses to project a three-dimensional point cloud onto a two-dimensional image and then input it into the network [17], but the projection process may lead to the loss of geometric information, and the method lacks the ability of non-local geometric features [18];
- (2)
- Voxelization-based network [19]: for the disorder and irregularity of the point cloud, the disordered point cloud is voxelized into an ordered voxel block, and then a three-dimensional convolutional neural network is used to process the ordered voxel block. The main limitation of the method is that the computational cost is too high, especially when dealing with large-scale point clouds. It cannot meet practical applications [20], and the volume setting of the voxel block will affect the final segmentation effect. Furthermore, due to the sparsity of the point cloud, there will be empty voxel blocks generated, wasting the computational cost [21];
- (3)
- Network based on the neural architecture: Hu Q [22] et al. designed an efficient neural architecture network structure based on random sampling and local feature aggregation (RandLa-Net). It can directly process large-scale point cloud data without any preprocessing.
2.2. Data Format Requirements in Unmanned High-Definition Map Construction
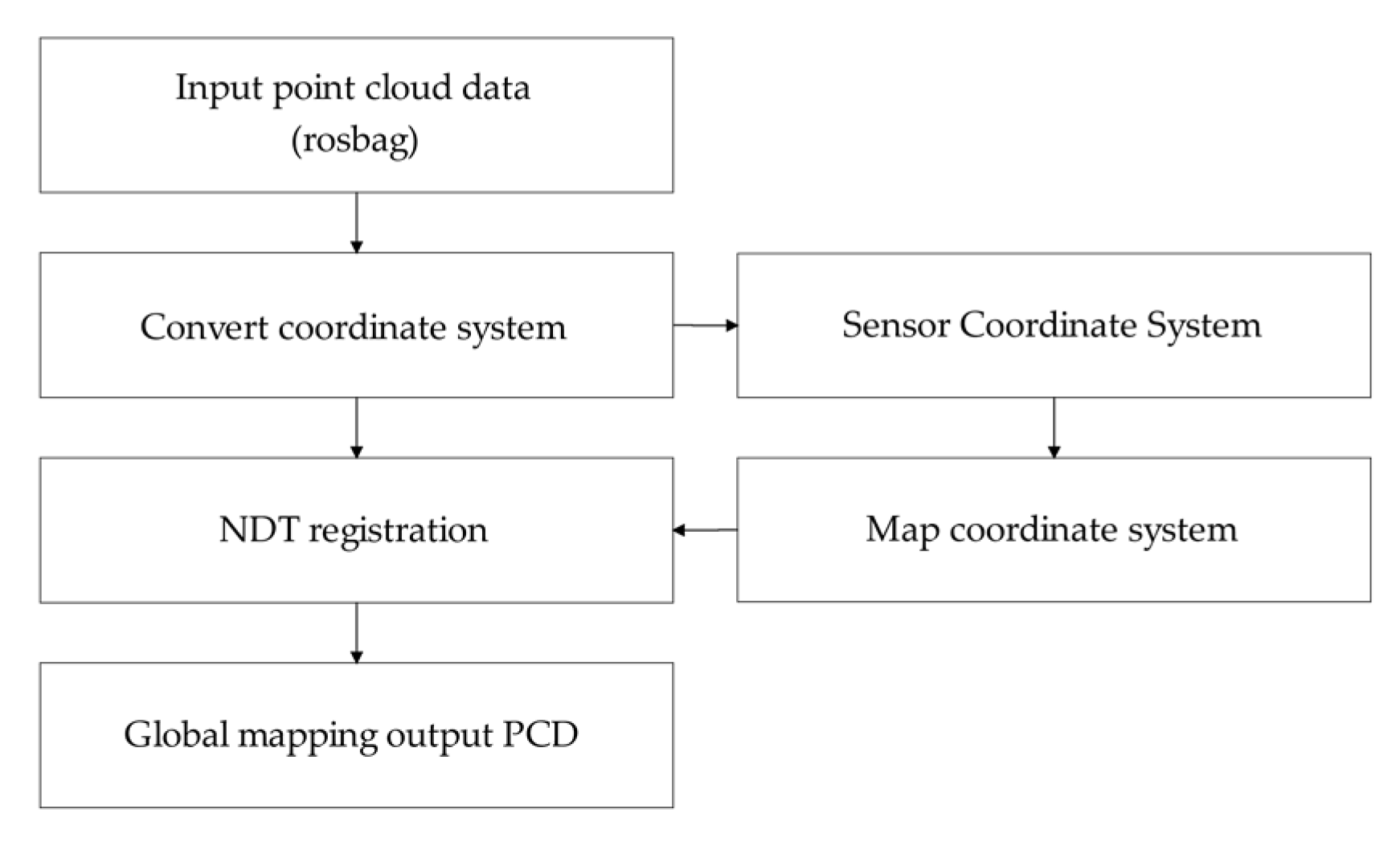
3. Creation of Global Map of Point Cloud Based on NDT
3.1. Registration Algorithm Based on NDT
3.2. Point Cloud Map Creation Based on NDT
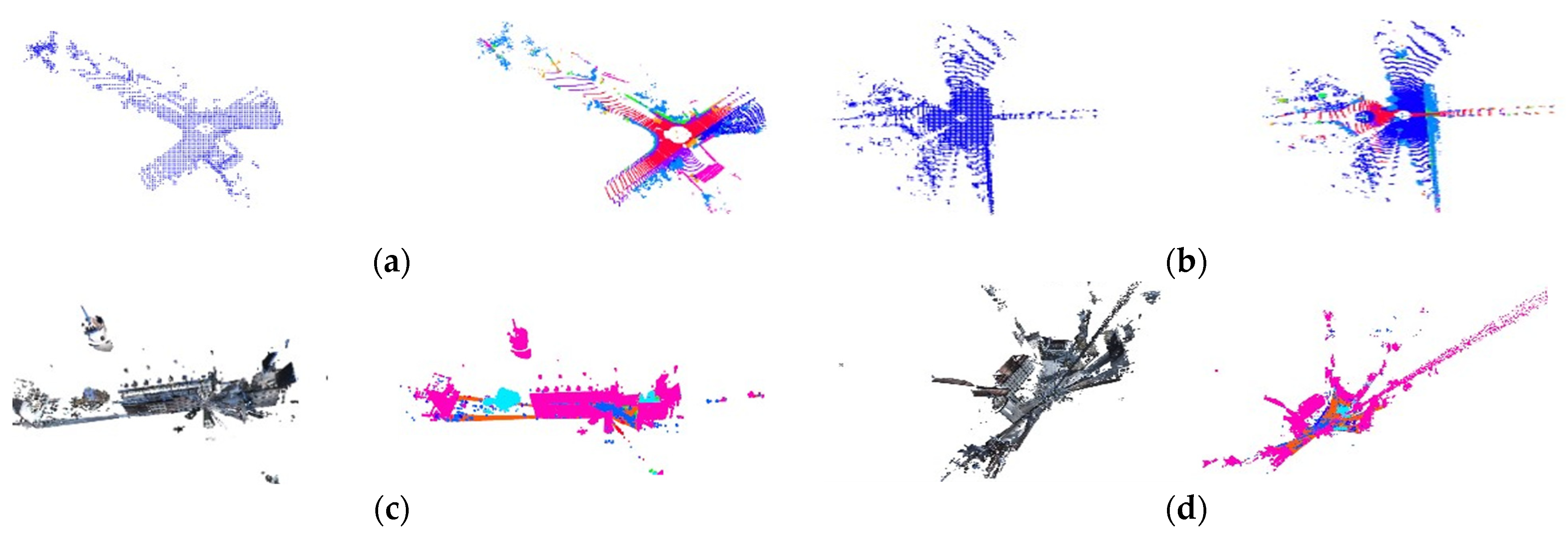
3.3. Test of NDT Global Mapping
3.3.1. Dataset Selection
3.3.2. Test Results
4. Point Cloud Semantic Segmentation Based on RandLa-Net
4.1. Point Cloud Semantic Segmentation Algorithm Based on RandLa-Net
4.1.1. Random Sampling
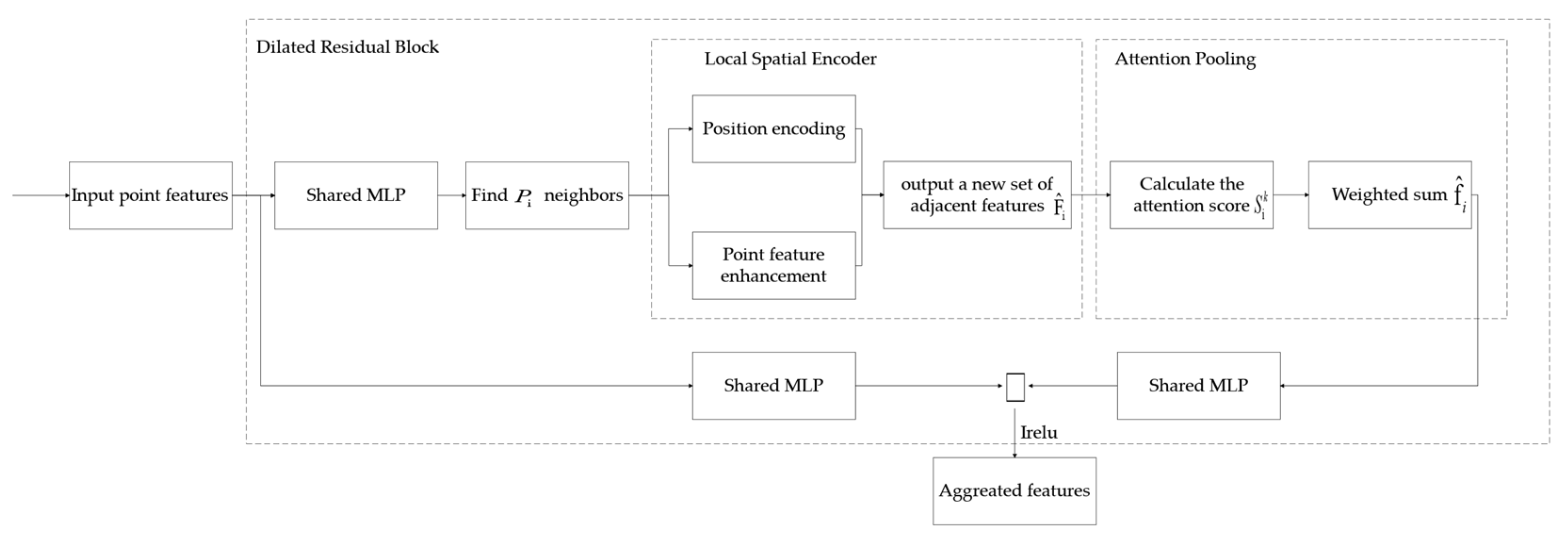
4.1.2. Local Feature Aggregator
- (1)
- Local Spatial Encoder
- (2)
- Attention Pooling Layer
- (3)
- Dilated Residual Block
4.2. Point Cloud Semantic Segmentation Test Based on RandLa-Net
4.2.1. Dataset Selection
4.2.2. Algorithm Testing
5. Comprehensive Test of Automatic Classification and Extraction of Raw Point Cloud Data
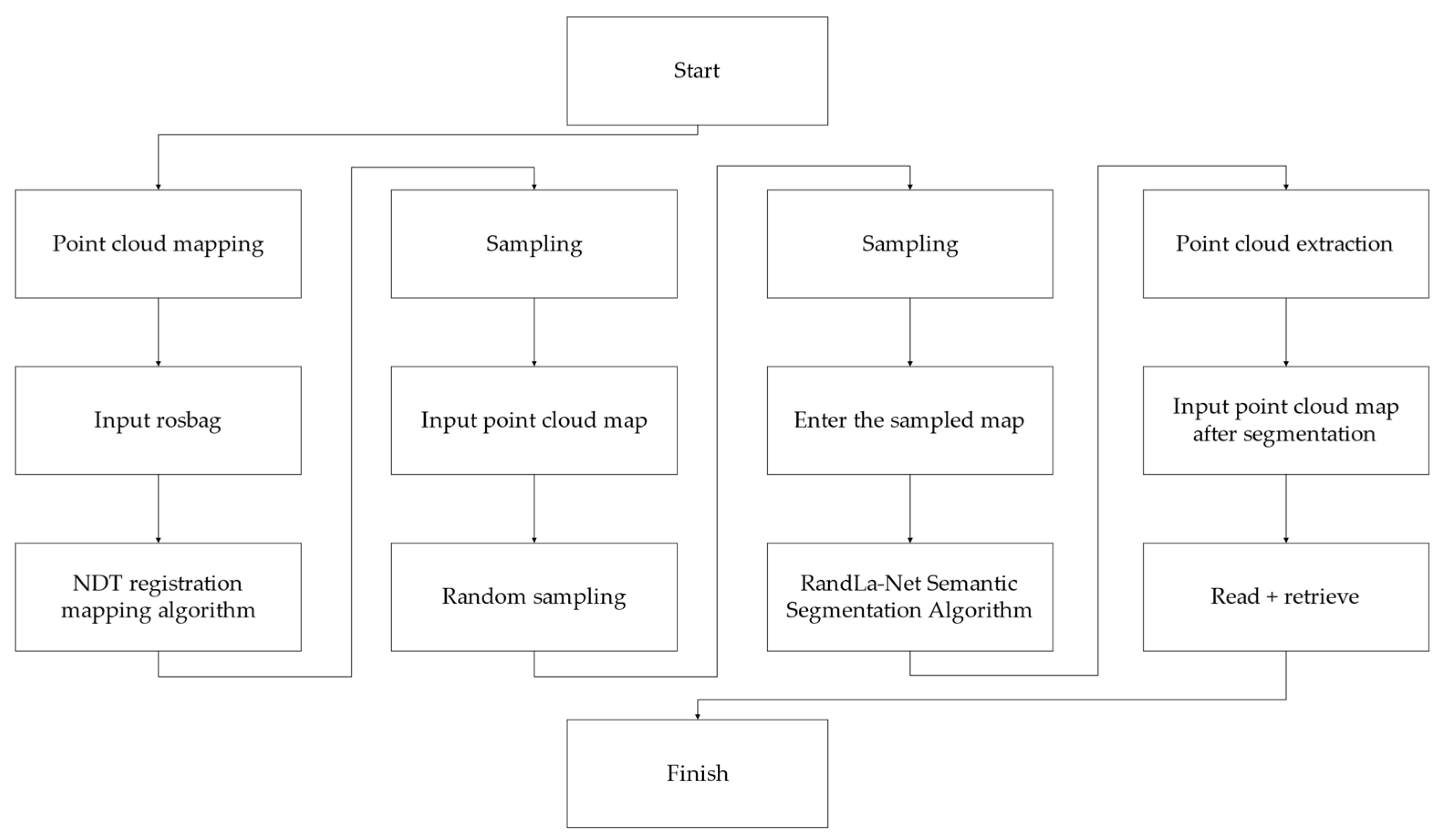
5.1. The Flow of the Algorithm
5.2. Test Data
5.3. Point Cloud Mapping
5.4. Random Sampling
5.5. Point Cloud Semantic Segmentation
5.6. Point Cloud Extraction
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Xu, J.; Hou, F.; Cao, G.H. High-definition road map production method and key technology. Surv. Mapp. Bull. 2022, 1, 155–158. [Google Scholar] [CrossRef]
- Wang, Y.; He, W.; Zhou, L.; Peng, X.T.; Li, W. High-definition road map production based on vehicle LiDAR data. Geospat. Inf. 2022, 20, 92–95. [Google Scholar]
- Andreas, G.; Philip, L.; Raquel, U. Are we ready for autonomous driving? The KITTI vision benchmark suite. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Hackel, T.; Savinov, N.; Ladicky, L.; Wegner, J.D.; Schindler, K.; Pollefeys, M. Semantic3d. net: A new large-scale point cloud classification benchmark. arXiv 2017, arXiv:1704.03847. [Google Scholar]
- Behley, J.; Garbade, M.; Milioto, A.; Quenzel, J.; Behnke, S.; Stachniss, C.; Gall, J. SemanticKITTI: A dataset for semantic scene understanding of lidar sequences. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November, 2019. [Google Scholar]
- Yuan, M.; Li, X.; Cheng, L.; Li, X.; Tan, H. A coarse-to-fine registration approach for point cloud data with bipartite graph structure. Electronics 2022, 11, 263. [Google Scholar] [CrossRef]
- Rusu, R.B.; Marton, Z.C.; Blodow, N.; Beetz, M. Persistent point feature histograms for 3Dpoint cloud. In Proceedings of the 10th International Conference on Intelligent Autonomous Systems (IAS-10), Baden-Baden, Germany, 2008; Volume 1, pp. 119–128. [Google Scholar]
- Biber, P.; Strasser, W. The normal distributions transform: A new approach to laser scan matching. In Proceedings of the 2003 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2003) (Cat. No. 03CH37453), Las Vegas, NV, USA, 27–31 October 2003; pp. 2743–2748. [Google Scholar]
- Aoki, Y.; Goforth, H.; Srivatsan, R.A.; Lucey, S. PointNetLK: Robust & efficient point cloud registration using pointnet. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 7163–7172. [Google Scholar]
- Lucas, D.D. An iterrative image registration technique with an application to stereo vision. In Proceedings of the 1981 International Conference on Imaging Understanding Workshop, Piscataway, NJ, USA, 24–28 August 1981; Volume 4, pp. 121–130. [Google Scholar]
- Wang, Y.; Solomon, J. Deep closest point: Learning representations for point cloud registration. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 3523–3532. [Google Scholar]
- Wang, Y.; Solomon, J. PRNet: Self-supervised learning for partial-to-partial registration. In Proceedings of the Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, Vancouver, BC, Canada, 8–14 December 2019; pp. 8814–8826. [Google Scholar]
- Shan, J.C.; Li, X.Z.; Zhang, X.Y.; Jia, S.M. Real-time 3D semantic map construction in indoor scenes. J. Instrum. 2019, 40, 240–248. [Google Scholar]
- Qiu, J.Y.; Lai, J.Z.; Li, Z.M.; Huang, K.; Liu, J.Y. LiDAR ground segmentation method for complex scenes. J. Instrum. 2020, 41, 244–251. [Google Scholar]
- Qian, Y.L.; Gai, S.Y.; Zheng, D.L.; Da, F.P. Fast 3D human ear recognition based on local and global information. J. Instrum. 2019, 40, 99–106. [Google Scholar]
- Su, H.; Maji, S.; Kalogerakis, E.; Learned-Miller, E. Multi-view convolutional neural networks for 3d shape recognition. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 945–953. [Google Scholar]
- Chen, X.; Ma, H.; Wan, J.; Li, B.; Xia, T. Multi-view 3d object detection network for autonomous driving. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1907–1915. [Google Scholar]
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beijbom, O. Pointpillars: Fast encoders for object detection from point clouds. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 12697–12705. [Google Scholar]
- Truc, L.; Ye, D. Pointgrid: A deep network for 3d shape understanding. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–21 June 2018; pp. 9204–9214. [Google Scholar]
- Meng, H.Y.; Gao, L.; Lai, Y.K.; Manocha, D. Vv-net: Voxel vae net with group convolutions for point cloud segmentation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–3 November 2019; pp. 8500–8508. [Google Scholar]
- Wang, C.Y.; Liao, H.Y.M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. Fast point r-cnn. In Proceedings of the 2019 IEEE/CVF International Conferenceon Computer Vision, Seoul, Korea, 27 October–3 November 2019; pp. 9775–9784. [Google Scholar]
- Hu, Q.; Yang, B.; Xie, L.; Rosa, S.; Guo, Y.; Wang, Z.; Markham, A. RandLa-Net: Efficient semantic segmentation of large-scale point clouds. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Loic, L.; Martin, S. Large-scale point cloud semantic segmentation with superpoint graphs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Milioto, A.; Vizzo, I.; Behley, J.; Stachniss, C. RangeNet++: Fast and accurate lidar semantic segmentation. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), The Venetian Macao, Macau, China, 4–8 November 2019. [Google Scholar]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | PointNet | PointNet++ | SqueezeSeg | DarkNet21Seg | RangeNet53++ | RandLa-Net |
|---|---|---|---|---|---|---|
| mIoU(%) | 14.1 | 19.8 | 28.8 | 45.6 | 52.1 | 53.7 |
| parameter (M) | 3 | 6 | 1 | 25 | 50 | 1.24 |
| road | 61.6 | 71 | 85.3 | 91.4 | 91.8 | 91.7 |
| side-walk | 35.5 | 41.3 | 54.1 | 73 | 74.2 | 77.1 |
| parking | 15.6 | 18.3 | 26.9 | 56 | 63.9 | 41.2 |
| other-ground | 1.2 | 5.2 | 4.4 | 26.4 | 27.8 | 38.9 |
| building | 41.2 | 61.5 | 56.3 | 81.9 | 87.4 | 88.2 |
| car | 46.1 | 53.7 | 68.5 | 85.1 | 90.4 | 93.3 |
| truck | 0.1 | 0.9 | 3.3 | 18.1 | 24.7 | 40.1 |
| bicycle | 1.3 | 1.9 | 15 | 26.2 | 25.7 | 15.5 |
| motorcycle | 0.3 | 0.2 | 4.1 | 26.5 | 34.4 | 28.8 |
| other-vehicle | 0.7 | 0.2 | 3.5 | 15.6 | 22.9 | 38.5 |
| vegetation | 30 | 46.5 | 60 | 77.6 | 80.5 | 84.5 |
| trunk | 4.6 | 13.8 | 24.3 | 47.4 | 55.1 | 40.1 |
| terrain | 17.6 | 30 | 53.7 | 63.6 | 64.5 | 72.1 |
| person | 0.2 | 0.9 | 12.9 | 31.8 | 38.3 | 53.4 |
| bicyclist | 0.2 | 1 | 13.1 | 33.6 | 38.8 | 53.36 |
| motorcyclist | 0 | 0 | 0.9 | 4 | 4.8 | 7.2 |
| fence | 12.9 | 16.9 | 29.9 | 52.3 | 58.6 | 44.5 |
| pole | 2.4 | 6 | 17.8 | 36 | 47.9 | 51.3 |
| traffic sign | 3.7 | 8.9 | 24.5 | 50 | 55.9 | 38.6 |
| Methods | SnapNet | ShellNet | GACNet | KPConv | RandLa-Net |
|---|---|---|---|---|---|
| mIoU(%) | 59 | 69.1 | 70.7 | 74.6 | 77.4 |
| OA(%) | 88.6 | 91.8 | 94 | 92.9 | 94.8 |
| man-made terrain | 81 | 86.4 | 96.4 | 90.9 | 94.2 |
| natural terrain | 77.2 | 77.7 | 92.6 | 82.8 | 91.4 |
| high vegetation | 79.7 | 88.5 | 87.9 | 84.1 | 82.9 |
| low vegetation | 22.9 | 60.6 | 44 | 47.8 | 52 |
| buildings | 91.1 | 94.2 | 83.2 | 94.5 | 94.7 |
| hard scape | 18.4 | 37.3 | 31 | 40 | 54.9 |
| scanning artefacts | 37.3 | 43.5 | 63.5 | 77.3 | 70.9 |
| Cars | 64.4 | 77.8 | 76.2 | 79.7 | 76.9 |
| Total Time (s) | Parameters (Millions) | Maximum Inference Points (Millions) | |
|---|---|---|---|
| PointNet | 192 | 0.8 | 0.49 |
| PointNet++ | 9831 | 0.97 | 0.98 |
| PointCNN | 8142 | 11 | 0.05 |
| SPG | 43584 | 0.25 | - |
| KPConv | 717 | 14.9 | 0.54 |
| RandLa-Net | 185 | 1.24 | 1.03 |
| Methods | RandLa-Net | Ours |
|---|---|---|
| mIoU(%) | 60.6 | 61.5 |
| parameter(M) | 1.24 | 1.24 |
| road | 92.1 | 92.3 |
| side-walk | 77.3 | 78.1 |
| parking | 42.6 | 43.9 |
| other-ground | 40.8 | 41.2 |
| building | 89.4 | 90.2 |
| car | 92.1 | 92.3 |
| truck | 50.8 | 51.3 |
| bicycle | 15.6 | 16.5 |
| motorcycle | 30.9 | 31.2 |
| other-vehicle | 41.7 | 41.5 |
| vegetation | 85.9 | 85.6 |
| trunk | 42.3 | 43.1 |
| terrain | 72.5 | 73.1 |
| person | 65.9 | 65.4 |
| bicyclist | 55.8 | 55.4 |
| motorcyclist | 8.9 | 9.7 |
| fence | 47.2 | 48.3 |
| pole | 53.1 | 53.3 |
| traffic sign | 40.4 | 41.7 |
| Numb | Object Type | Position Coordinates (x, y, z) | ||
|---|---|---|---|---|
| 1 | car | 20.354 | 40.375 | −2.404 |
| 20.356 | 40.374 | −2.404 | ||
| 20.359 | 40.374 | −2.399 | ||
| … | … | … | … | … |
| 6 | person | −0.847 | −34.686 | 3.215 |
| −0.852 | −34.683 | 3.212 | ||
| −0.852 | −34.683 | 3.215 | ||
| … | … | … | … | … |
| 9 | road | −0.003 | −31.752 | 0.002 |
| −0.001 | −31.756 | 0.002 | ||
| −0.002 | −31.759 | 0.002 | ||
| … | … | … | … | … |
| 15 | vegetation | −8.033 | −0.995 | −1.201 |
| −8.053 | −0.982 | −1.200 | ||
| −8.062 | −0.975 | −1.201 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, Z.; Li, J.; Liu, J.; Zeng, Y.; Wan, Y.; Zhang, J. An Improved RandLa-Net Algorithm Incorporated with NDT for Automatic Classification and Extraction of Raw Point Cloud Data. Electronics 2022, 11, 2795. https://doi.org/10.3390/electronics11172795
Ma Z, Li J, Liu J, Zeng Y, Wan Y, Zhang J. An Improved RandLa-Net Algorithm Incorporated with NDT for Automatic Classification and Extraction of Raw Point Cloud Data. Electronics. 2022; 11(17):2795. https://doi.org/10.3390/electronics11172795
Chicago/Turabian StyleMa, Zhongli, Jiadi Li, Jiajia Liu, Yuehan Zeng, Yi Wan, and Jinyu Zhang. 2022. "An Improved RandLa-Net Algorithm Incorporated with NDT for Automatic Classification and Extraction of Raw Point Cloud Data" Electronics 11, no. 17: 2795. https://doi.org/10.3390/electronics11172795