
A Typed Iteration Approach for Spoken Language Understanding

Abstract
:1. Introduction
- Due to the variety of slot labels, there are many out-of-vocabulary (OOV) words in some slot categories (contact names, song names, etc.), such as in Case 1, shown in Table 2: the joint model may not know what Adele means. The encoded information of the slot filling task is inaccurate at this time, and in-accurately encoded information can negatively affect the ID task.
- The specific meanings of the corresponding words in the slot can mislead the ID task (message text, recording content, etc.), as Case 2 shows in Table 2. The meaning of the message text slot in the two example sentences is entirely different, and the encoded information of the slot filling task is also different. However, their slot labels are the same and should obtain the exact representation for the ID task. Understanding the specific meaning of slot words cannot help the ID task but will mislead it.
- 3.
- We propose a typed abstraction mechanism. Through this mechanism, we can use the encoded information of the slot filling task to explicitly enhance the ID task while avoiding the negative impact of misleading information on the ID task.
- 4.
- We designed a typed iteration approach. This approach uses the typed abstraction mechanism and feature fusion mechanism to realize the bidirectional connection of the encoded information in the joint model. At the same time, it reduces the error propagation problem that the typed abstraction mechanism may bring through the iterative process. To the best of our knowledge, this is the first attempt to use the encoded information of two subtasks for simultaneous explicit enhancement and interaction.
- 5.
- We performed experiments on two public corpora, ATIS and SNIPS, and our approach achieved state-of-the-art performance on both corpora. The experimental results prove the effectiveness of our model.
2. Related Work
3. Approach
3.1. Typed Abstraction Mechanism
3.2. Typed Iteration Approach
| Algorithm 1 Typed iteration algorithm |
| Input: Input sentence X; Parameter: A random vector has the same shape with H; Max iteration number m; t: 0; A vector initialized to 0; A vector initialized to 0 Output: S, I flag←True H = BERT(X) while flag do if ( and or then else end if end while return S; I |
3.3. Joint Training
4. Experiments
4.1. Datasets
4.2. Evaluation Metrics
4.3. Experimental Settings
4.4. Overall Results
4.5. Ablation Experiment
5. Analysis
5.1. Selection of the Maximum Iteration Number
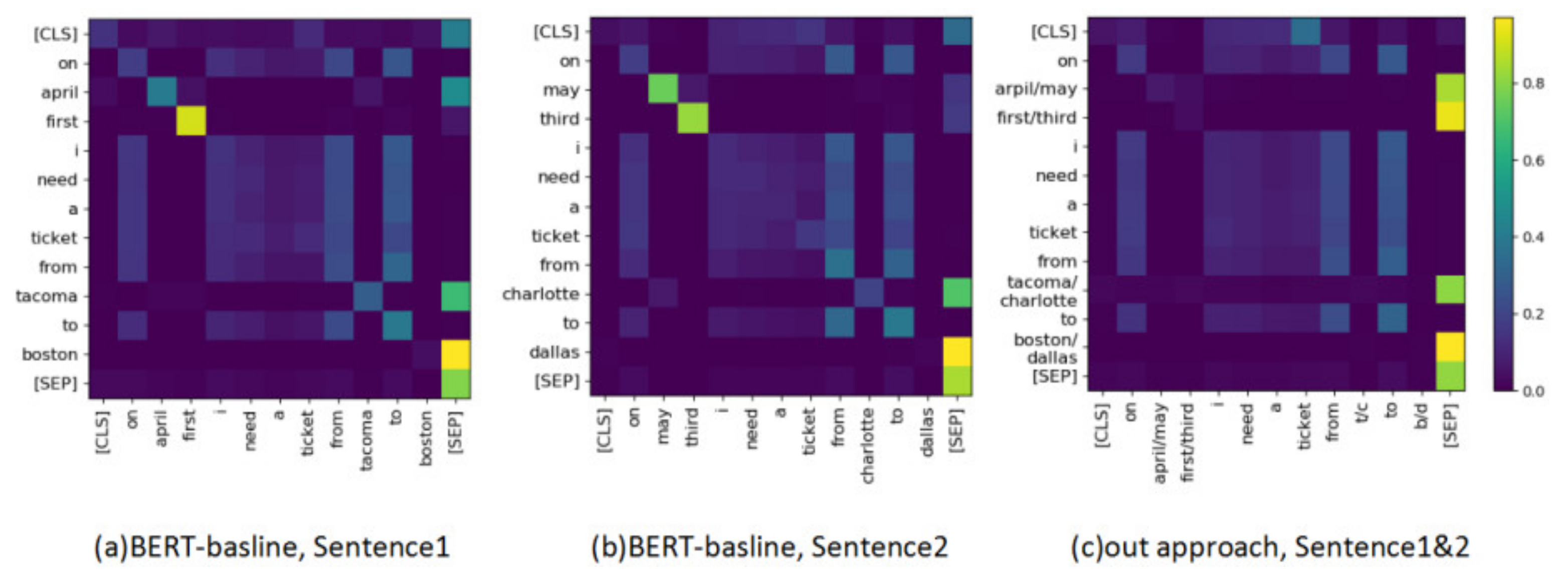
5.2. Effect of Typed Abstraction Mechanism
5.3. Case Study
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Tur, G.; de Mori, R. Spoken Language Understanding: Systems for Extracting Semantic Information from Speech; John Wiley & Sons: Hoboken, NJ, USA, 2011. [Google Scholar]
- Wu, J.; Harris, I.G.; Zhao, H. Spoken Language Understanding for Task-oriented Dialogue Systems with Augmented Memory Networks. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL 2021), Online, 6–11 June 2021; pp. 797–806. [Google Scholar]
- Chen, Y.N.; Hakanni-Tür, D.; Tur, G.; Celikyilmaz, A.; Guo, J.; Deng, L. Syntax or semantics? Knowledge-guided joint semantic frame parsing. In Proceedings of the 2016 IEEE Spoken Language Technology Workshop (SLT), San Diego, CA, USA, 13–16 December 2016; pp. 348–355. [Google Scholar]
- Zhang, X.; Wang, H. A joint model of intent determination and slot filling for spoken language understanding. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence (IJCAI-16), New York, NY, USA, 9–15 July 2016; pp. 2993–2999. [Google Scholar]
- Bing Liu and Ian Lane. Attention-based recurrent neural network models for joint intent detection and slot filling. In Proceedings of the 17th Annual Conference of the International Speech Communication Association (INTERSPEECH 2016), San Francisco, CA, USA, 8–12 September 2016; pp. 685–689.
- Qin, L.; Che, W.; Li, Y.; Wen, H.; Liu, T. A stack-propagation framework with token-level intent detection for spoken language understanding. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP & IJCNLP 2019), Hong Kong, China, 3–7 November 2019; pp. 2078–2087. [Google Scholar]
- Niu, P.; Chen, Z.; Song, M. A novel bi-directional interrelated model for joint intent detection and slot filling. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL 2019), Florence, Italy, 28 July–2 August 2019; pp. 5467–5471. [Google Scholar]
- Haffner, P.; Tur, G.; Wright, J.H. Optimizing svms for complex call classification. In Proceedings of the 2003 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP’03), Hong Kong, China, 6–10 April 2003; Volume 1. [Google Scholar]
- Lai, S.; Xu, L.; Liu, K.; Zhao, J. Recurrent convolutional neural networks for text classification. In Proceedings of the Twenty-ninth AAAI Conference on Artificial Intelligence (AAAI 2015), Austin, TX, USA, 25–30 January 2015; pp. 2267–2273. [Google Scholar]
- Raymond, C.; Riccardi, G. Generative and discriminative algorithms for spoken language understanding. In Proceedings of the Eighth Annual Conference of the International Speech Communication Association (INTERSPEECH 2007), Antwerp, Belgium, 27–31 August 2007; pp. 1605–1608. [Google Scholar]
- Xu, P.; Sarikaya, R. Convolutional neural network based triangular CRF for joint intent detection and slot filling. In Proceedings of the 2013 IEEE Workshop on Automatic Speech Recognition and Understanding, Olomouc, Czech Republic, 8–12 December 2013; pp. 78–83. [Google Scholar]
- Yao, K.; Peng, B.; Zhang, Y.; Yu, D.; Zweig, G.; Shi, Y. Spoken language understanding using long short-term memory neural networks. In Proceedings of the 2014 IEEE Spoken Language Technology Workshop (SLT), South Lake Tahoe, NV, USA, 7–10 December 2014; pp. 189–194. [Google Scholar]
- Wang, J.; Chen, K.; Shou, L.; Wu, S.; Chen, G. Effective Slot Filling via Weakly-Supervised Dual-Model Learning. In Proceedings of the Thirty-Fifth AAAI Conference on Artificial Intelligence (AAAI-21), Online, 2–9 February 2021; pp. 13952–13960. [Google Scholar]
- Hakkani-Tür, D.; Tür, G.; Celikyilmaz, A.; Chen, Y.N.; Gao, J.; Deng, L.; Wang, Y.Y. Multi-domain joint semantic frame parsing using bi-directional rnn-lstm. In Proceedings of the 17th Annual Meeting of the International Speech Communication Association (INTERSPEECH 2016), San Francisco, CA, USA, 8–12 September 2016; pp. 715–719. [Google Scholar]
- Goo, C.W.; Gao, G.; Hsu, Y.K.; Huo, C.L.; Chen, T.C.; Hsu, K.W.; Chen, Y.N. Slot-gated modeling for joint slot filling and intent prediction. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL 2018), Volume 2 (Short Papers), New Orleans, LV, USA, 1–6 June 2018; pp. 753–757. [Google Scholar]
- Li, C.; Li, L.; Qi, J. A self-attentive model with gate mechanism for spoken language understanding. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP 2018), Brussels, Belgium, 31 October–4 November 2018; pp. 3824–3833. [Google Scholar]
- Wang, Y.; Shen, Y.; Jin, H. A bi-Model based RNN semantic frame parsing model for intent detection and slot filling. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LV, USA, 1–6 June 2018; Volume 2, (Short Papers). pp. 309–314. [Google Scholar]
- Zhang, C.; Li, Y.; Du, N.; Fan, W.; Yu, P. Joint Slot Filling and Intent Detection via Capsule Neural Networks. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 5259–5267. [Google Scholar]
- Hui, Y.; Wang, J.; Cheng, N.; Yu, F.; Wu, T.; Xiao, J. Joint Intent Detection and Slot Filling Based on Continual Learning Model. In Proceedings of the 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 7643–7647. [Google Scholar]
- Wang, J.; Wei, K.; Radfar, M.; Zhang, W.; Chung, C. Encoding Syntactic Knowledge in Transformer Encoder for Intent Detection and Slot Filling. In Proceedings of the Thirty-Fifth AAAI Conference on Artificial Intelligence (AAAI-21), Online, 2–9 February 2021; pp. 13943–13951. [Google Scholar]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Chen, Q.; Zhuo, Z.; Wang, W. BERT for joint intent classification and slot filling. arXiv 2019, arXiv:1902.10909. [Google Scholar]
- Li, C.; Qiu, Z. Targeted BERT pre-training and fine-tuning approach for entity relation extraction. In Proceedings of the International Conference of Pioneering Computer Scientists, Engineers and Educators (ICPCSEE 2021), Communications in Computer and Information Science, Taiyuan, China, 17–20 September 2021; Volume 1452, pp. 116–125. [Google Scholar]
- Hemphill, C.T.; Godfrey, J.J.; Doddington, G.R. The ATIS spoken language systems pilot corpus. In Proceedings of the Speech and Natural Language, Hidden Valley, PA, USA, 24–27 June 1990; pp. 96–101. [Google Scholar]
- Coucke, A.; Saade, A.; Ball, A.; Bluche, T.; Caulier, A.; Leroy, D.; Doumouro, C.; Gisselbrecht, T.; Caltagirone, F.; Lavril, T.; et al. Snips voice platform: An embedded spoken language understanding system for private-by-design voice interfaces. arXiv 2018, arXiv:1805.10190. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sentence | Flights | from | Beijing | to | Shanghai |
| Slot | O | O | B-fromloc | O | B-toloc |
| Intent | atis_flight | ||||
| Case | Sentence | Result of Typed Abstraction | Intent |
|---|---|---|---|
| 1 | Play Adele’s Rolling in the deep. | Play the artist’s song | Play music |
| Play Taylor Swift’s Sparks Fly. | |||
| 2 | Send a message to Mr. Jack saying tonight Miss White has a date with him. | Send a message to name saying message_text | Send message |
| Send a message to Mrs. Tom saying remember to book two Taylor Swift concert tickets. |
| Dataset | ATIS | SNIPS |
|---|---|---|
| Vocabulary size | 722 | 11,241 |
| #Intents | 21 | 7 |
| #Slots | 120 | 72 |
| #Training samples | 4478 | 13,084 |
| #Validation samples | 500 | 700 |
| Dataset | SNIPS | ATIS | ||||
|---|---|---|---|---|---|---|
| Intent (acc) | Slot (F1) | Sentence (acc) | Intent (acc) | Slot (F1) | Sentence (acc) | |
| Joint Seq (Dilek et al., 2016) [14] | 96.9 | 87.3 | 73.2 | 92.6 | 94.3 | 80.7 |
| Attention BiRNN (Liu et al., 2016) [14] | 96.7 | 87.8 | 74.1 | 91.1 | 94.2 | 78.9 |
| Slot-Gated Full Atten (Goo et al., 2018) [15] | 97.0 | 88.8 | 75.5 | 93.6 | 94.8 | 82.2 |
| Slot-Gated Intent Atten (Goo et al., 2018) [15] | 96.8 | 88.3 | 74.6 | 94.1 | 95.2 | 82.6 |
| Self-Attentive Model (Li et al., 2018) [16] | 97.5 | 90.0 | 81.0 | 96.8 | 95.1 | 82.2 |
| Bi-Model (Wang et al., 2018) [17] | 97.2 | 93.5 | 83.8 | 96.4 | 95.5 | 85.7 |
| CAPSULE-NLU (Zhang et al., 2019) [18] | 97.3 | 91.8 | 80.9 | 95.0 | 95.2 | 83.4 |
| SF-ID Network (Haihong et al., 2019) [7] | 97.0 | 90.5 | 78.4 | 96.6 | 95.6 | 86.0 |
| Stack-propagation (Qin et al., 2019) [6] | 98.0 | 94.2 | 86.9 | 96.9 | 95.9 | 86.5 |
| BERT-baseline(Chen et al., 2019) [22] | 98.1 | 96.3 | 90.4 | 97.1 | 85.9 | 87.9 |
| Stack-propagation + BERT (Qin et al., 2019) [6] | 98.6 | 96.7 | 91.8 | 97.3 | 96.1 | 88.2 |
| Our model | 98.9 | 96.7 | 92.2 | 98.1 | 96.2 | 88.7 |
| Dataset | SNIPS | ATIS | ||||
|---|---|---|---|---|---|---|
| Intent (acc) | Slot (F1) | Sentence (acc) | Intent (acc) | Slot (F1) | Sentence (acc) | |
| BERT-baseline | 98.1 | 96.3 | 90.4 | 97.1 | 95.9 | 87.9 |
| +Typed Abstraction(TA) | 98.4 | 96.3 | 90.6 | 97.3 | 95.8 | 88.0 |
| +Feature Fusion(FF) | 98.0 | 96.1 | 89.9 | 97.1 | 95.4 | 87.5 |
| +TA&FF(M = 1) | 98.4 | 96.5 | 91.1 | 97.5 | 95.9 | 88.1 |
| M = 3 | 98.7 | 96.5 | 91.5 | 97.8 | 95.9 | 88.4 |
| M = 5 | 98.9 | 96.6 | 92.2 | 98.1 | 96.1 | 88.6 |
| FF by Mean Pooling | 98.6 | 96.4 | 91.8 | 97.8 | 95.9 | 88.4 |
| FF by Max Pooling | 98.6 | 96.5 | 92.0 | 97.7 | 95.6 | 86.1 |
| FF by Attention | 98.8 | 96.7 | 92.2 | 98.1 | 96.1 | 88.7 |
| Our model | 98.9 | 96.7 | 92.2 | 98.1 | 96.2 | 88.7 |
| Max Iteration Number M | Time for Training One Epoch | ||
|---|---|---|---|
| M = 3 | 72.49% | 27.51% | 2 m 04 s |
| M = 4 | 91.94% | 7.06% | 3 m 11 s |
| M = 5 | 92.33% | 7.06% | 3 m 58 s |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pang, Y.; Yu, P.; Zhang, Z. A Typed Iteration Approach for Spoken Language Understanding. Electronics 2022, 11, 2793. https://doi.org/10.3390/electronics11172793
Pang Y, Yu P, Zhang Z. A Typed Iteration Approach for Spoken Language Understanding. Electronics. 2022; 11(17):2793. https://doi.org/10.3390/electronics11172793
Chicago/Turabian StylePang, Yali, Peilin Yu, and Zhichang Zhang. 2022. "A Typed Iteration Approach for Spoken Language Understanding" Electronics 11, no. 17: 2793. https://doi.org/10.3390/electronics11172793