1. Introduction
Person re-identification (Re-ID) is a technology used to intelligently track pedestrians. It is intended to recognize specified pedestrians from many pedestrian images taken from non-overlapping cameras [
1,
2,
3]. When a query set is given, the Re-ID is a task to recognize specific images containing the same identity [
4]. The query set represents a set of images to be queried, and the gallery set represents a large set of images collected from multiple cameras for recognition. For Re-ID, scholars have proposed some supervised [
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
16], unsupervised and weakly supervised learning schemes [
17,
18,
19,
20,
21,
22,
23,
24], and the recently proposed deep feature learning using partial levels [
25,
26,
27,
28,
29], which can achieve a level of accuracy that approximates human eye discrimination [
30]. As the performance of Re-ID tasks improves, many scholars have started working on cross-domain Re-ID problems [
31,
32], which will substantially expand the applicable scenarios of Re-ID technology and improve recognition efficiency.
Most early studies of Re-ID involved single-modality Re-ID, and the images they processed were mostly visible images captured during the daytime. These early studies assumed that the visible images were taken in adequate illumination. However, we find this assumption to be too idealistic in the real-world application of Re-ID technology. For example, criminals generally choose to commit crimes in poorly lit environments or at night. In this case, visible cameras have difficulty capturing high-quality visible images. Thus, infrared cameras were introduced to help Re-ID capture clear pedestrian images in poor illumination [
33]. Currently, most cameras are equipped with both visible cameras and infrared cameras. Such a device can capture high-quality color pedestrian images during daytime and adequately illuminated infrared pedestrian images at night, or in poor illumination conditions, using an infrared camera, with better free Re-ID from lighting limitations. Therefore, visible–infrared person re-identification (VI Re-ID) has become a hot topic [
34]. VI Re-ID eliminates the limitation of illumination, but encounters many other challenges.
One of the main problems of VI Re-ID is inter-modality discrepancies. Visible samples contain three channels, while the infrared samples contain one channel. Moreover, the differences in wavelength ranges between visible and infrared images create large discrepancies between them, posing a great challenge to the VI Re-ID task.
VI Re-ID also has the problem of intra-modality variations, which also occur in the single-modality Re-ID task. In
Figure 1, we can observe that one pedestrian has been captured by different cameras; there are differences in the viewpoint position, photo angle, and lighting environment of these cameras, which inevitably leads to images of different backgrounds, poses, occlusions, etc. This will reduce the similarity between the images of one pedestrian, as well as the similarity between the images of different pedestrians, causing us to preferentially match pedestrians with different identities from the queried pedestrian during the query process.
Thus, VI Re-ID still presents a strong challenge. To address challenges in VI Re-ID, we propose the Local Features Leading Global Features Network (LoLeG-Net). The main idea is to combine the residual network ResNet50 and the non-local attention block to obtain modality-shareable features to alleviate inter-modality discrepancies, and we constrain local features through hetero-center loss and identity loss. Then, we use the local features to guide global features that are robust against complex environments, inevitable occlusion, and other noises, alleviating intra-modality variations.
Our main contributions can be found as follows:
To alleviate inter-modality discrepancies, LoLeG-Net is proposed to obtain modality-shareable features, converting cross-modality recognition to single-modality recognition;
To reduce intra-modality variations, the global feature constraints led by local features are proposed, enabling the final global features used in LoLeG-Net to have the advantages of local features, and enhancing the robustness of LoLeG-Net against background, occlusion and other noise.
The remaining contributions are shown below: the related work on VI Re-ID is introduced in
Section 2, LoLeG-Net is presented in
Section 3, the experiments on LoLeG-Net are expounded in
Section 4, and the conclusion is shown in
Section 5.
2. Related Work
Since 2017, deep learning has become popular in VI Re-ID tasks. Nguyen et al. [
35] proposed a combined visible and infrared pedestrian image method for Re-ID, employing infrared images in Re-ID tasks for the first time, and they also contributed the RegDB dataset.
Wu et al. [
36] disclosed the SYSU-MM01 dataset. They designed three network structures and a deep zero-padding method, which better alleviated cross-modality discrepancies. However, this method does not address the problem of intra-modality variations because it lacks the process of metric learning.
Ye et al. [
37] designed a ranking loss based on a dual-constrained structure to reduce inter-modality discrepancies. However, this approach presupposes that training samples and testing samples have the same data distributions, while in VI Re-ID tasks, their data distributions are not the same most of the time.
Wu et al. [
38] demonstrated different data distributions of training samples and testing samples in VI Re-ID by the t-SNE dimensionality reduction method. They converted the issue of extracting shared information in cross-modality recognition into the issue of preserving cross-modality similarity by constraining the similarity of samples across modalities. Additionally, they further alleviated cross-modality discrepancies by using modality gate nodes.
Ye et al. [
39] built schemes, including attention blocks, a specific average pooling method, and weighted regularized triplet loss. This baseline enhanced the representation of modality-shared features by acquiring information through the non-local attention block. However, the images had much interference, such as a complex environment and occlusion, and this method obtained modality-shared features based on global features only. Their method using only global features had less robustness against noise. Moreover, this method used a non-local attention block that focused only on global correlations and did not consider positional correlations, so the noise was also globally employed. This made it much more difficult for the model to learn global features with discriminability.
The extent to which the main problems are resolved via the existing methods described above can be summarized as follows:
For inter-modality discrepancies, existing methods mostly extract the shared features of both modalities by global representation learning to convert the cross-modality problem into a single-modality problem. However, the global features have poor robustness against noise, such as background and occlusion. In the method of enhancing feature robustness against noise, local features are able to divide the original features so that each block of local features contains information about relevant regions, and the noise in the relevant region is likewise divided, which makes local features much more robust against image noise. However, the camera has different views for each pedestrian sample, so selecting the appropriate division strategy becomes a major difficulty for local features.
For intra-modality variations, existing schemes focus on metric learning. Triplet loss is one of these schemes to control the distance of the sample [
40], while identity loss is employed to measure the classification precision of models. It is mutually beneficial for both of them to be used in representation learning [
39]. However, the simple triplet loss will dominate the entire distance metric learning process. Moreover, the triplet loss does not ensure that the samples of the same class between visible and infrared modalities are as close as possible.
We find that the main problems are alleviated to varying degrees with existing schemes. However, robustness against background, occlusion, and other noises needs to be further enhanced. Therefore, a method is needed to enhance robustness against noise and better alleviate the main problems of VI Re-ID.
3. Proposed Method
We propose a representation learning network LoLeG-Net based on a two-stream structure. The structure of LoLeG-Net is shown in
Figure 2. First, LoLeG-Net mainly includes three parts: the network for extracting modality-shared features, global features, and local features. Second, metric learning will be used to constrain LoLeG-Net. Specifically, LoLeG-Net is constrained via global feature constraints led by local features, including leading loss and global feature loss. Leading loss constrains local features through hetero-center loss and identity loss. Moreover, global feature loss includes identity loss and hard sample mining triplet loss, which is employed to ensure the effectiveness of global features.
Our LoLeG-Net includes two inputs and the samples of the two modalities. We presume that we have visible samples and infrared samples. represents the visible image and represents the infrared image. and represent the and corresponding identities, respectively. and indicate the visible sample and the infrared sample, respectively. Next, we take the visible modality samples and infrared modality samples of the same pedestrian as an example to introduce LoLeG-Net.
3.1. Extracting Shared Features
Before extracting shared features, we need to extract their shallow modality-specific features from visible and infrared images. Specifically, shallow modality-specific features and are extracted from the visible and infrared samples and via a corresponding convolution layer. The two convolution layers of the two modalities have the same structure and different parameters, which represent different modalities.
Then, the shallow specific features of the two modalities are fed into the network block with the same structure and parameters, obtaining the modality-shareable features marked and . The network block consists of non-local attention blocks and ResNet50.
The second and third layers of ResNet50 are followed by two layers of non-local attention blocks whose components can be seen in
Figure 3. First, the input
is separately dropped to half of the original channels through two
convolution operations to obtain
with
. Then, the similarity of
is measured with respect to itself by calculating their dot product similarity, which can be shown as Equation (1).
After that, the dot product similarity makes matrix multiplication with , which reduces the channel by another convolution operation. The obtained result performs a convolution to keep the same channels as , and then is fed into the BN layer to obtain . Finally, the output is obtained by adding to .
3.2. Extracting Global Features
The global features finally adopted in our method will be extracted from and .
First, the modality-shared features of the two modalities are pooled by the pooling operation of the global average, and from the result of the operation, we obtained the quasi-global features and .
Then, to avoid the gradient disappearance problem, the quasi-global features and are input into the batch normalization layer so that the data distribution is close to the normal distribution, and the final global features and are obtained.
3.3. Extracting Local Features
From the modality-shareable features and , we obtain local features.
First, the modality-shareable features and are subjected to the operation of a convolution to decrease channels to one quarter of the original to obtain and . Then, the shared features after the descending channel are divided into four parts according to the height, and the local feature groups and composed of 4 blocks are obtained. Finally, the 4 blocks are passed through the batch normalization layer to extract and .
3.4. Global Feature Constraints Led by Local Features
LoLeG-Net is constrained via metric learning. Specifically, it is constrained via global feature constraints led by local features, including leading loss and a global feature loss.
3.4.1. Leading Loss Function
The leading loss shows the constraints led by local ones, and the global features can obtain the advantages of local features with strong robustness to noise. First, we should ensure that the local features are valid to provide the correct guidance for the global features. Next, we should ensure that the distances between local features of two different modalities of one identity are as close as possible to further reduce intra-modality variations. Finally, the global features are made to be as close as possible to the local features so that the local features act as guides and increase the robustness of the global features against noise.
To ensure the validity of local features, we employ identity loss to measure the classification accuracy of the model and extend its scope to visible and infrared modalities. We presume that we optionally pick up
pedestrians, and we randomly select
visible and infrared samples from the corresponding pedestrians. In this way,
samples are picked up to build mini-batch training samples. The identity loss function can be shown as Equation (2).
In Equation (1),
represents features and
represents the possibility that
will be identified as
. Identity loss is calculated separately for each local feature block via local features
and
, and is shown in Equation (3).
After ensuring the validity of the local features, the intra-modality variations need to be further alleviated. We employ hetero-center loss function to make distances between local features of the same identity and different modalities as close as possible. Similar to the identity loss of local features, we also assume that we optionally pick up
pedestrians and we randomly select
visible and infrared samples from corresponding pedestrians. In this way,
samples are picked up to build mini-batch training samples. The hetero-center loss can be shown as Equation (4).
where
represents L2-norm normalization. Assuming the feature is
, the expression of
can be expressed as Equation (5).
After ensuring the reliability of local features and reducing intra-modality variations, local features need to be employed to guide the global features, allowing the merits of the local features to be obtained by global features. L2-norm loss is employed to evaluate the correlation of global with local features by calculating their 2-norm so that the local features can be guided. The L2-norm loss can be expressed in the form shown in Equation (6).
In this case, the local feature blocks of the local features are stitched together to lead the global features.
Ultimately, a guiding loss function is obtained, as shown in Equation (7).
3.4.2. Global Feature Loss Function
To ensure the validity of the global features, we employ identity loss to measure the classification accuracy of the model, employ hard sample mining triplet loss to further alleviate the intra-class variations of the global features, and extend the scope to the VI Re-ID task. Similar to the assumptions in the local features, we also assume that we optionally pick up pedestrians and we randomly select visible and infrared samples from the corresponding pedestrians. In this way, samples are picked up to build mini-batch training samples.
The hard sample mining triplet loss can be shown as Equation (8).
represents features. The anchor feature is selected from the samples of both modalities. The identity of and is the same, but has a different identity. The hard sample mining triplet loss traverses all images, finding a hard sample for each image. The hardest positive and negative samples are combined with the anchor image to form the hard triplet sample. The triplet loss formed by this method effectively alleviates intra-class variation.
Finally, the global feature loss function can be expressed as shown in Equation (9).
3.4.3. Total Loss Function
Ultimately, the loss function proposed in this paper for global feature constraints led by local features can be expressed in the form of Equation (10).
4. Experiment
We evaluate LoLeG-Net by experiments. First, we concisely describe the datasets and evaluation metrics to be employed in the experiments. Second, we perform detailed comparison experiments and ablation experiments on LoLeG-Net and analyze the segmentation strategy of local features.
4.1. Datasets
The SYSU-MM01 [
36] and RegDB [
35] datasets of VI Re-ID tasks will be used in our experiments.
4.1.1. SYSU-MM01
The SYSU-MM01 dataset is the first published cross-modality person re-identification dataset. The pedestrian images are collected by four RGB and two near-infrared cameras. In total, the training set contains 22,258 visible and 11,909 infrared images of 395 identities and the testing set includes 96 identities with 3808 infrared images for the query and 301 visible images as the gallery set. There are two evaluation modes because the images are captured in both indoor and outdoor environments. In All-Search mode, the gallery set contains all visible images. In Indoor-Search mode, the gallery set contains visible images captured by only two indoor visible cameras. For both modes, we adopt a single-shot setting and repeat the 10 evaluation trials with a random split of the gallery and probe set to obtain the most reliable experimental results.
4.1.2. RegDB
This dataset includes 412 identities, and 10 visible and infrared images in each corresponding identity. In the experiment, the two retrieval modes of visible image retrieval for infrared images (visible-to-infrared, V2I) and infrared image retrieval for visible images (infrared-to-visible, I2V) are employed, and the training and testing sets are selected via 10 random segmentations to record the average accuracy.
4.2. Evaluation Metrics
For fairness, following the approach of existing work, the cumulative matching characteristic (CMC) will be employed in this experiment. Rank-k in CMC indicates the performance of the right images in the first k results. We also employ the mean average precision (mAP), which captures the average performance of the method. In particular, the mean inverse negative penalty (mINP) is used to check the model performance to recognize the most difficult samples. The most difficult sample is the last correct sample that appears in the sequence of recognition results.
4.3. Experimental Configuration
The batchsize of this experiment is eight. Each batch of this experiment randomly selects four images for each pedestrian identity from each of the two modalities. We expand the channels of infrared images into the same three channels as the visible images in this experiment. The images are finally cut to 256 × 128, and the normalization of the images follows the normalization standards of ImageNet.
In this experiment, we employ
as the constraint, where
is 4,
is 0.3, and
is 8. In this experiment, the original learning rate is 0.01, with 80 epochs of training. The variation in the learning rate
with
is shown in Equation (11).
4.4. Comparison Experiments
We select some existing schemes for comparison with our method to verify the superiority of LoLeG-Net, consisting of zero-padding [
36], one-stream [
36], two-stream [
36], BDTR [
37], eBDTR [
41], HCML [
42], AlignGAN [
43], HI-CMD [
44], and AGW [
39].
4.4.1. Performance on SYSU-MM01
The performance in the two modes on the SYSU-MM01 dataset is shown in
Table 1 and
Table 2.
HCML [
42] learns modality-shareable features by improving the two-stream network. BDTR [
37] and eBDTR [
41] improve the loss function and distance metrics based on the two-stream network to optimize the distance of sample images in the feature space. AlignGAN [
43] and Hi-CMD [
44] use GAN to mitigate the differences between pedestrian images of different modalities. AGW [
39] builds a scheme, including attention blocks, a specific average pooling method, and the weighted regularized triplet loss to enhance the representation of modality-shared features. The experimental results show that LoLeG-Net has a better performance compared to BDTR [
37]. Rank-1 and mAP increase by 24.08% and 24.09% in the All-Search mode, and increase by 24.71% and 22.83% in the Indoor-Search mode. It can be seen that the modality-shared features can be considered global via non-local attention blocks.
In the comparison experiments in
Table 1 and
Table 2, the best method other than LoLeG-Net is AGW [
39]. In the All-Search mode, the Rank-1, mAP, and mINP of LoLeG-Net increase by 3.9%, 3.76%, and 3.43% in the All-Search mode and increase by 2.46%, 1.72%, and 1.46% in the Indoor-Search mode.
For a further comparison with AGW, we test the visual recognition results of AGW and LoLeG-Net on SYSU-MM01. We optionally pick three samples as a query set to test the results of the two methods, and the performance can be seen in
Figure 4. A correct recognition is marked with a green border, and a wrong recognition is marked with a red border. We find that AGW considers only global features, and has inferior robustness against image noise. Each part of the local features designed in this paper includes only the image knowledge of the corresponding block, which alleviates the noise effect on the samples. By using global feature constraints led by local features, LoLeG-Net can be considered to be robust against noise.
4.4.2. Performance of RegDB
Compared with AlignGAN [
43], our method does not employ GAN which brings extra noise, but proposes global feature constraints led by local features so that the features obtained by LoLeG-Net have better robustness against noise. In V2I mode, the Rank-1 and mAP of LoLeG-Net increase by 18.68% and 19.76%, respectively, while they increase by 18.20% and 18.48%, respectively, in I2V.
In the results of
Table 3 and
Table 4, the best method other than our method is AGW [
39]. In V2I mode, the Rank-1, the mAP, and the mINP of the method in this paper increase by 6.53%, 6.99%, and 12.09%, respectively, while they increase by 4.01%, 5.98%, and 8.71%, respectively, in I2V mode.
For further comparison with AGW, we test the visual recognition results of AGW and LoLeG-Net on RegDB. We randomly pick three examples for comparison, as shown in
Figure 5 and
Figure 6.
In
Figure 5, the images to be queried contain rich knowledge on color and texture but also contain background, occlusion and other noise. The matching results of the AGW algorithm considering only global features do not perform well. In contrast, the matching results of LoLeG-Net are excellent, which further indicates that the global feature constraints led by the local features method used in LoLeG-Net have better robustness against background, occlusion, and other noise.
In
Figure 6, the images to be queried are infrared images. The recognition difficulty is greatly increased because infrared images have no color information. In this mode, AGW pays attention to poses, which results in poor performance. LoLeG-Net is able to match the corresponding visible pedestrian images based on the limited pedestrian structure information, which further shows that LoLeG-Net builds an enhanced correlation between different modalities in the same pedestrian identity.
We find that LoLeG-Net outperforms AGW.
4.5. Ablation Experiments
We designed experiments to test the validity of the whole part of LoLeG-Net. The baseline used in this experiment is from the lightweight Re-ID library named Open-ReID, also compared by Luo et al. [
45]. From this baseline, several modules proposed in this paper are added in turn to the SYSU-MM01 dataset to evaluate the method. In this way, the enhancement effect of each part on the VI Re-ID task can be clearly demonstrated, as shown in
Table 5.
Model A is the baseline. In the VI Re-ID task, Model A was better for representation, learning by obtaining modality-shared features for both modalities based on the ResNet50 structure and metric learning.
Model B utilizes the method of non-local attention blocks based on Model A. The blocks consider all details about the global correlation, and are able to obtain global-rich features.
Table 5 shows that Model B outperforms Model A, indicating the validity of the non-local attention blocks.
Model C utilizes the method of global feature constraints led by local features based on Model A. Each local feature block includes only the image knowledge of the corresponding block, which alleviates the noise effect and uses global feature constraints led by local features to increase the robustness of the model against noise.
Table 5 shows that Model C outperforms Model A, indicating the validity of global feature constraints led by local features.
Model D is LoLeG-Net, which adds both global feature constraints led by local features and non-local attention blocks on the basis of the baseline. Thus, compared to the baseline, LoLeG-Net is able to obtain global-rich modality-shareable features on the one hand, and absorb the advantages of local features which make LoLeG-Net robust against background, occlusion and other noise on the other. From
Table 5, Model D outperforms the other three models, which shows the validity of the combination of non-local attention blocks and global feature constraints led by local features. Moreover, since Model D outperforms Model B, the global feature constraints led by local features improve the performance of the method based on non-local attention blocks, alleviating the problem that non-local attention blocks have no location correlation.
The local feature segmentation strategy used in this paper has four equal parts. To evaluate the validity of the segmentation strategy, strategies using one (i.e., no local features), two, four, and eight equal parts were evaluated, as shown in
Table 6.
From
Table 6, it can be observed that the four-equal-part performance was better than that of the others, so we finally adopted the four-equal-part strategy.










{kind=link}
{kind=link}
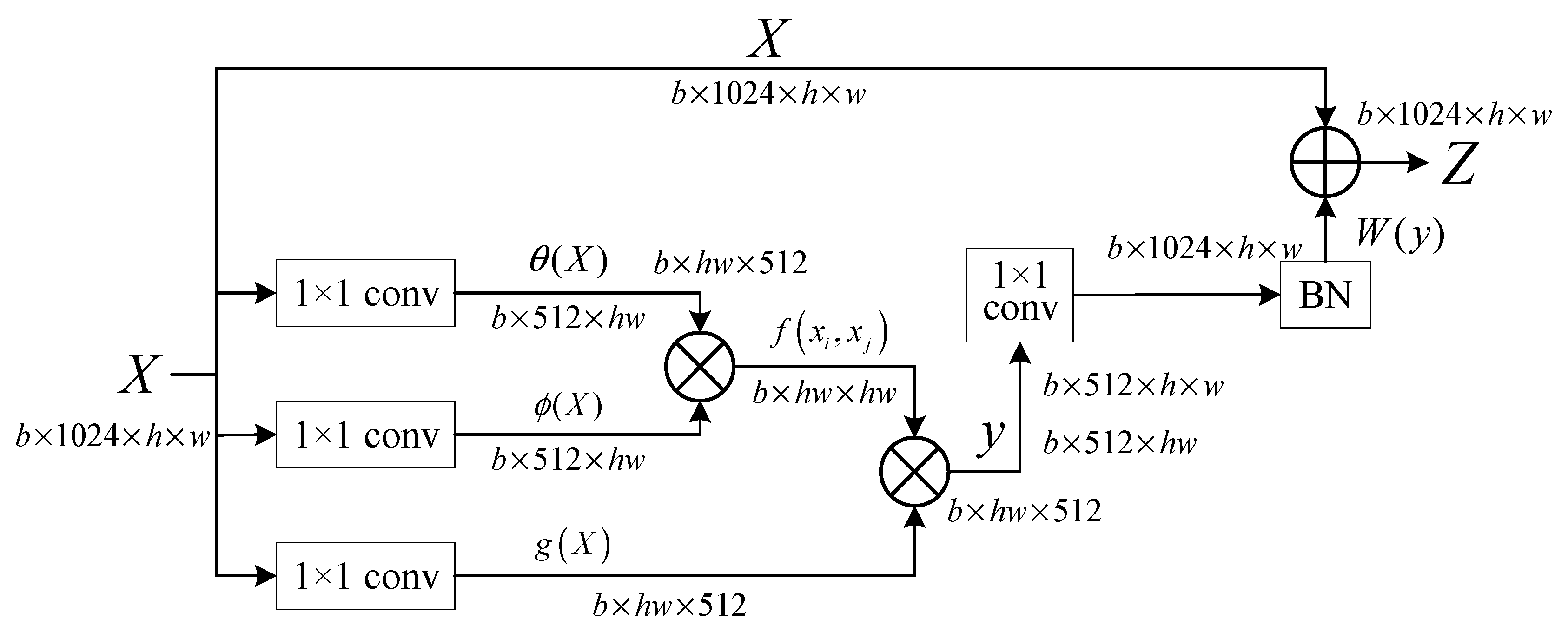{kind=link}
{kind=link}
{kind=link}
{kind=link}