
Training Vision Transformers in Federated Learning with Limited Edge-Device Resources


Abstract
:1. Introduction
2. Preliminaries
2.1. Vision Transformer (ViT)
2.2. Knowledge Distillation
2.3. Split Learning
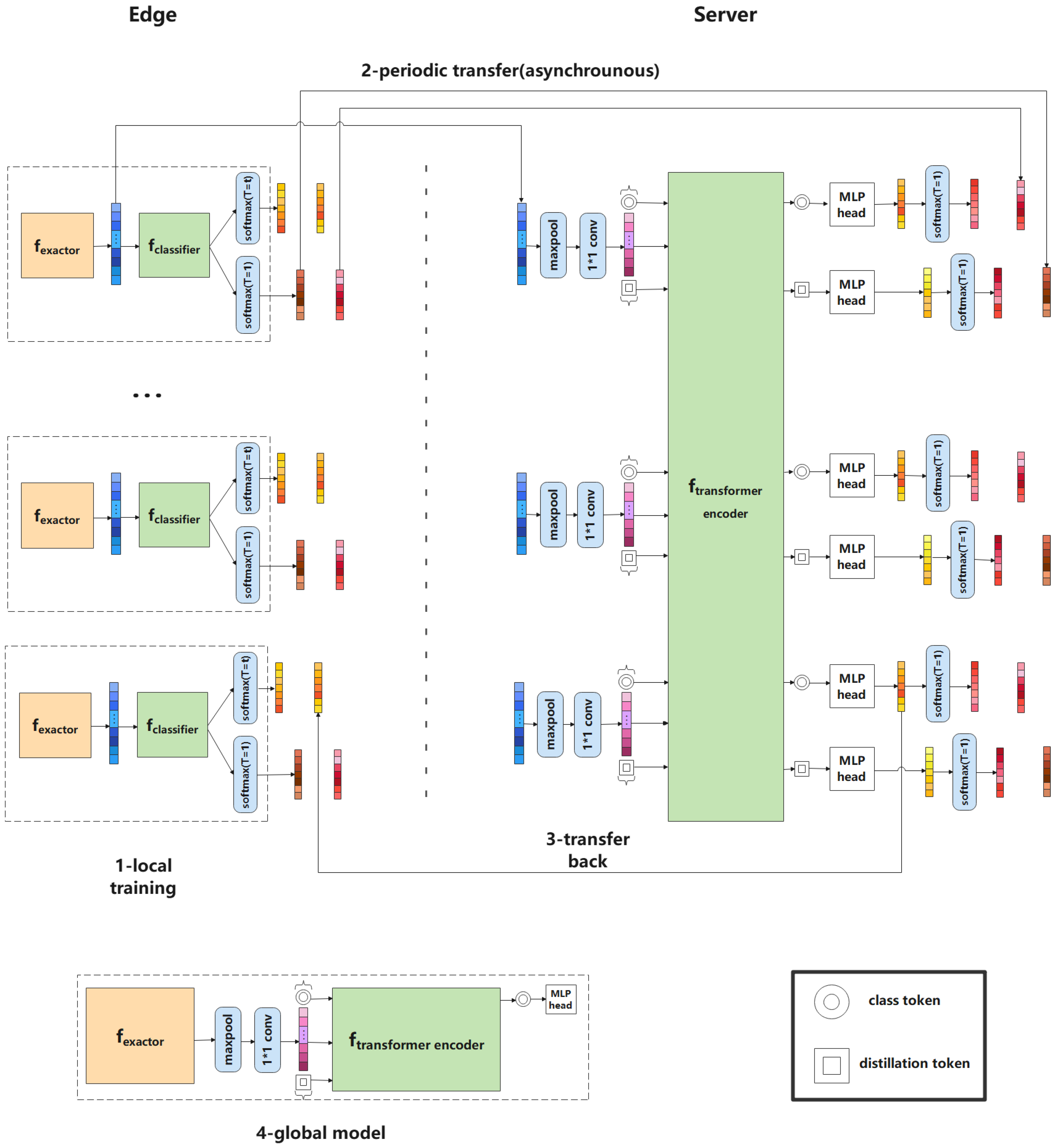
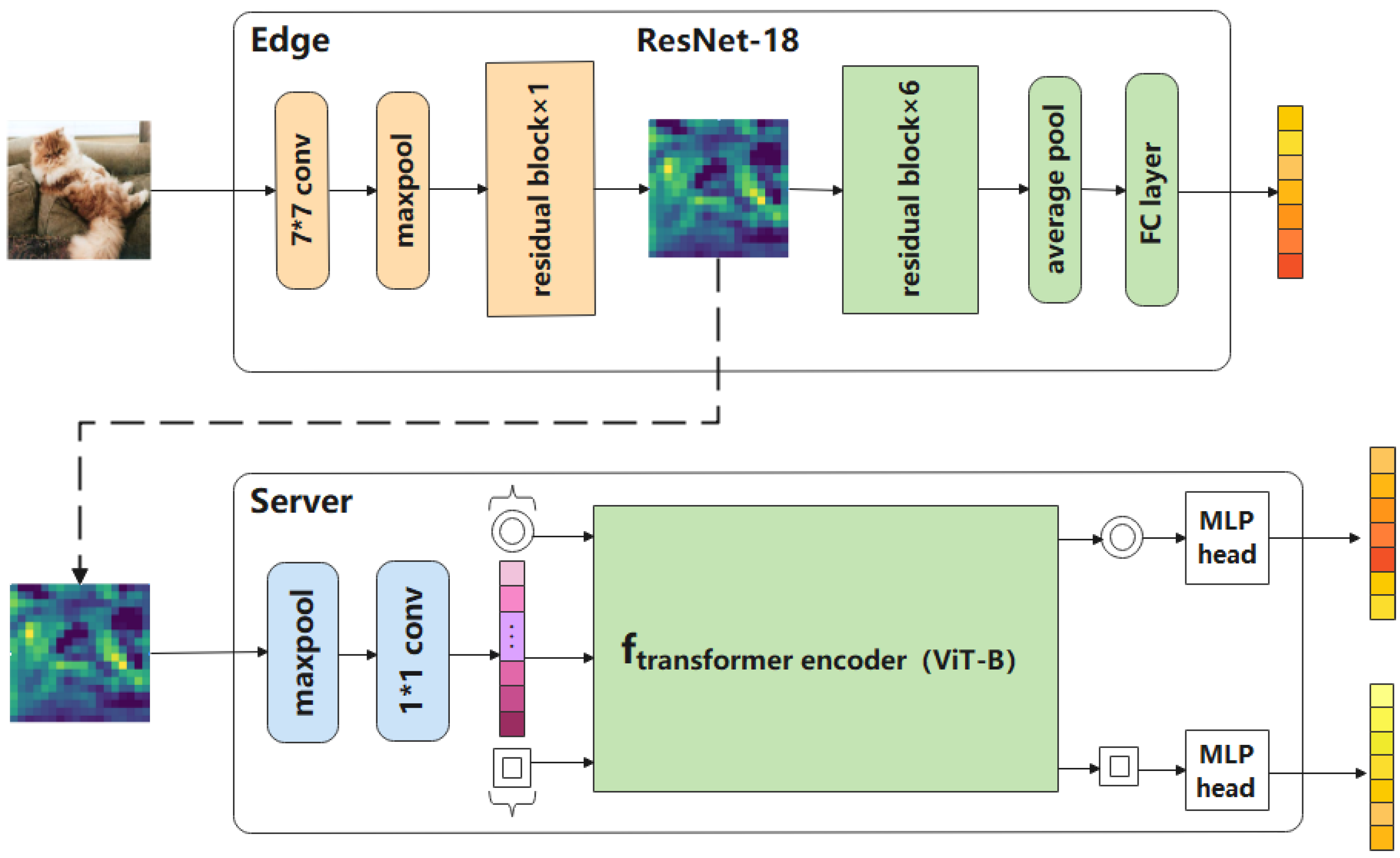
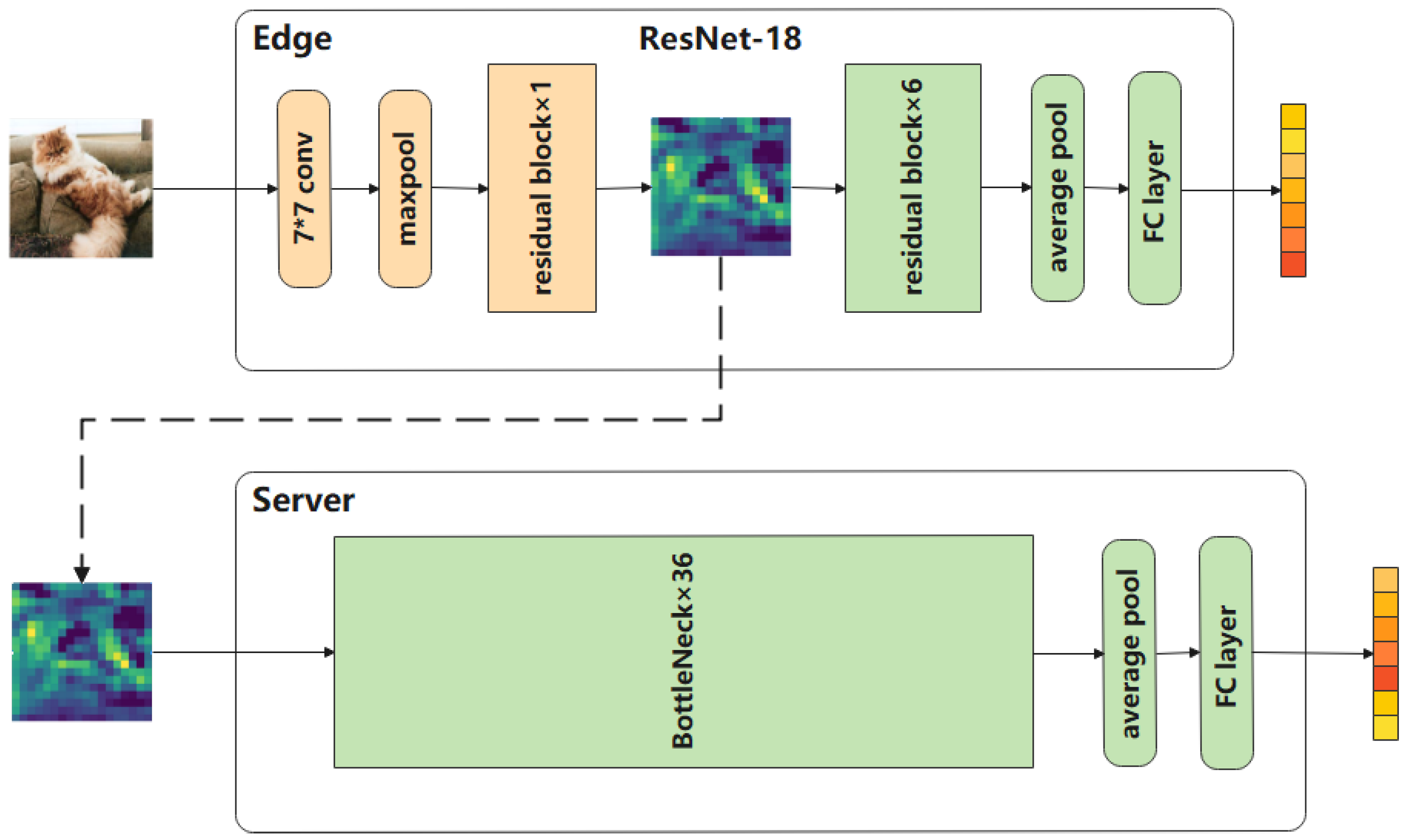
3. System Architecture
3.1. FedVKD Framework
3.2. Problem Formation
3.3. Training ViT in FL with KD
4. Experiments
4.1. Experimental Setup
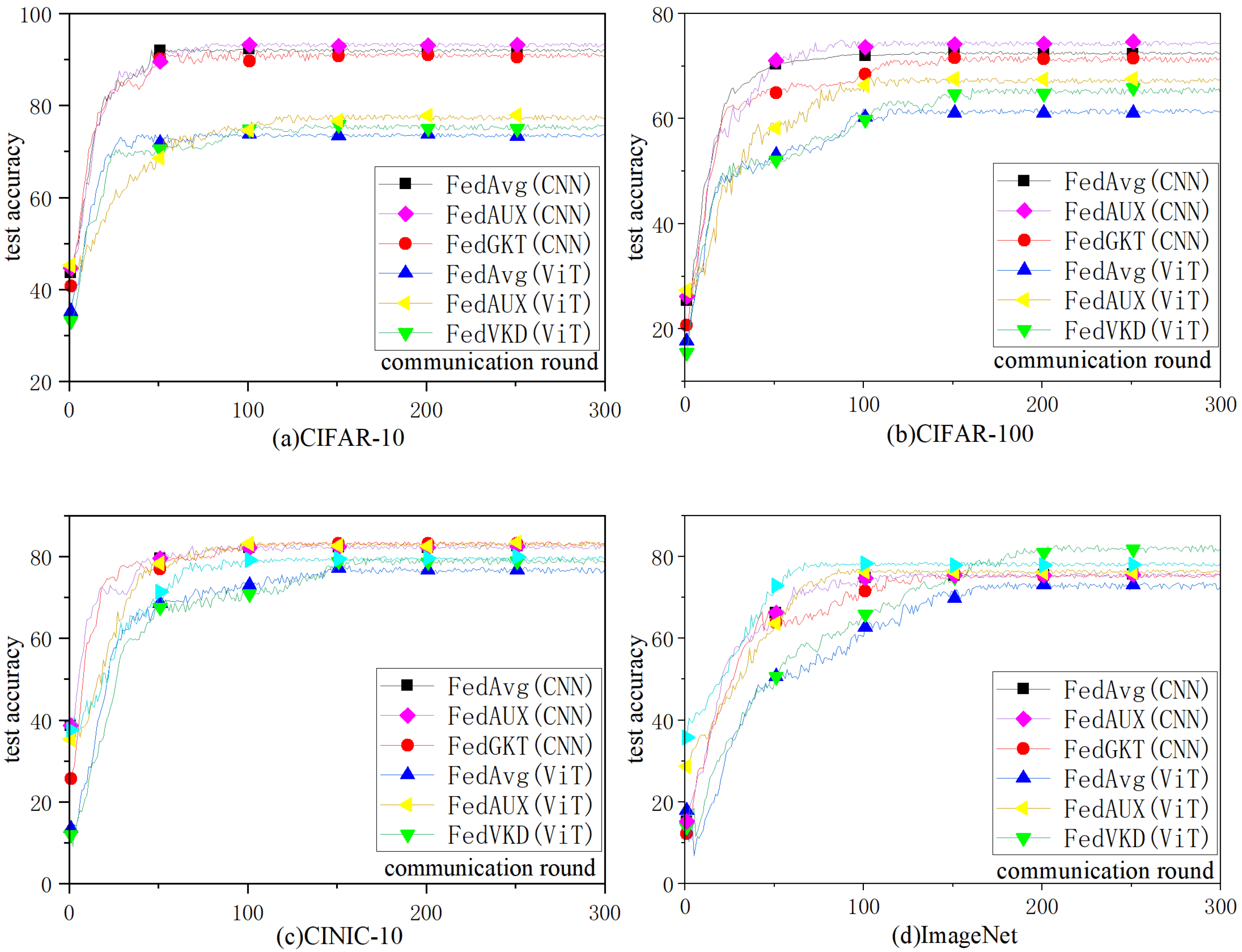
4.2. Experimental Results
5. Discussion and Conclusions
6. Limitations of the Study
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| Notations | Meanings |
| i-th training sample | |
| Corresponding label of , | |
| Sample number in dataset | |
| Network weights of a global model | |
| i-th edge’s local objective function | |
| ℓ | Loss function of the global model |
| General loss functions for the server-side model | |
| General loss functions for the edge-side model | |
| Server-side model | |
| i-th edge’s feature extractor | |
| i-th edge’s classifier | |
| Edge-side model including followed by | |
| Network weights of | |
| Network weights of | |
| Network weights of | |
| Combination of and | |
| i-th sample’s feature map (a hidden vector or tensor) | |
| Cross-entropy loss between the predicted values and ground truth labels | |
| Kullback–Leibler (KL) divergence function | |
| Output of the last fully connected layer in the server-side model | |
| Output of the last fully connected layer in the edge-side model | |
| T | Temperature hyperparameter of the softmax function |
| Class token | |
| Distillation token |
References
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16 × 16 words: Transformers for image recognition at scale. In Proceedings of the 9th International Conference on Learning Representations (ICLR 2021), Virtual Event, 3–7 May 2021. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. In Proceedings of the 34th Conference on Neural Information Processing Systems (NeurIPS 2020), Online, 6–12 December 2020; pp. 1877–1901. [Google Scholar]
- Lepikhin, D.; Lee, H.; Xu, Y.; Chen, D.; Firat, O.; Huang, Y.; Krikun, M.; Shazeer, N.; Chen, Z. Gshard: Scaling giant models with conditional computation and automatic sharding. In Proceedings of the 9th International Conference on Learning Representations (ICLR 2021), Virtual Event, 3–7 May 2021. [Google Scholar]
- Warnat-Herresthal, S.; Schultze, H.; Shastry, K.L.; Manamohan, S.; Mukherjee, S.; Garg, V.; Sarveswara, R.; Händler, K.; Pickkers, P.; Aziz, N.A.; et al. Swarm Learning for decentralized and confidential clinical machine learning. Nature 2021, 594, 265–270. [Google Scholar] [CrossRef] [PubMed]
- Froelicher, D.; Troncoso-Pastoriza, J.R.; Raisaro, J.L.; Cuendet, M.A.; Sousa, J.S.; Cho, H.; Berger, B.; Fellay, J.; Hubaux, J.-P. Truly privacy-preserving federated analytics for precision medicine with multiparty homomorphic encryption. Nat. Commun. 2021, 12, 5910. [Google Scholar] [CrossRef]
- McMahan, H.B.; Moore, E.; Ramage, D.; Hampson, S.; Arcas, B.A.Y. Communication-Efficient Learning of Deep Networks from Decentralized Data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics (AISTATS 2017), Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Peter, K.; McMahan, H.B.; Brendan, A.; Aurélien, B.; Mehdi, B.; Arjun Nitin, B.; Kallista, B.; Zachary, C.; Graham, C.; Rachel, C.; et al. Advances and Open Problems in Federated Learning. Found. Trends Mach. Learn. 2021, 14, 1–210. [Google Scholar] [CrossRef]
- Gupta, O.; Raskar, R. Distributed learning of deep neural network over multiple agents. J. Netw. Comput. Appl. 2018, 116, 1–8. [Google Scholar] [CrossRef]
- Vepakomma, P.; Gupta, O.; Swedish, T.; Raskar, R. Split Learning for Health: Distributed Deep Learning without Sharing Raw Patient Data. ICLR AI for Social Good Workshop 2019. Available online: https://aiforsocialgood.github.io/iclr2019/accepted/track1/pdfs/31_aisg_iclr2019.pdf (accessed on 1 October 2021).
- He, C.; Annavaram, M.; Avestimehr, S. Group knowledge transfer: Federated learning of large cnns at the edge. In Proceedings of the 34th Annual Conference on Neural Information Processing Systems (NeurIPS 2020), Online, 6–12 December 2020; pp. 14068–14080. [Google Scholar]
- Buciluǎ, C.; Caruana, R.; Niculescu-Mizil, A. Model compression. In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Philadelphia, PA, USA, 20–23 August 2016; pp. 535–541. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531v1. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training data-efficient image transformers & distillation through attention. In Proceedings of the 38th International Conference on Machine Learning, Virtual Event, 18–24 July 2021; pp. 10347–10357. [Google Scholar]
- Sun, S.; Cheng, Y.; Gan, Z.; Liu, J. Patient knowledge distillation for bert model compression. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, Hong Kong, China, 3–7 November 2019; pp. 4323–4332. [Google Scholar]
- Xiao, T.; Singh, M.; Mintun, E.; Darrell, T.; Dollár, P.; Girshick, R. Early convolutions help transformers see better. In Proceedings of the 35th Conference on Neural Information Processing Systems (NeurIPS 2021), Virtual Event, 6–14 December 2021; pp. 30392–30400. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local Neural Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7794–7803. [Google Scholar] [CrossRef]
- He, C.; Li, S.; So, J.; Zeng, X.; Zhang, M.; Wang, H.; Wang, X.; Vepakomma, P.; Singh, A.; Qiu, H. Fedml: A research library and benchmark for federated machine learning. In Proceedings of the 34th Conference on Neural Information Processing Systems (NeurIPS 2020 SpicyFL Workshop), Online, 6–12 December 2020. [Google Scholar]
- Fang, M.; Cao, X.; Jia, J.; Gong, N. Local Model Poisoning Attacks to Byzantine-Robust Federated Learning. In Proceedings of the 29th USENIX Security Symposium (USENIX Security 20), Boston, MA, USA, 12–14 August 2020; pp. 1605–1622. [Google Scholar]
- Konečný, J.; McMahan, H.B.; Felix, X.Y.; Richtárik, P.; Suresh, A.T.; Bacon, D. Federated learning: Strategies for improving communication efficiency. In Proceedings of the 6th International Conference on Learning Representations (ICLR 2018), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Sattler, F.; Korjakow, T.; Rischke, R.; Samek, W. FedAUX: Leveraging Unlabeled Auxiliary Data in Federated Learning. IEEE Trans. Neural Netw. Learn. Syst. 2021. [Google Scholar] [CrossRef] [PubMed]
- Hsieh, K.; Phanishayee, A.; Mutlu, O.; Gibbons, P. The non-iid data quagmire of decentralized machine learning. In Proceedings of the 37th International Conference on Machine Learning, Virtual Event, 13–18 July 2020; pp. 4387–4398. [Google Scholar]
- Reddi, S.; Charles, Z.; Zaheer, M.; Garrett, Z.; Rush, K.; Konečný, J.; Kumar, S.; McMahan, H.B. Adaptive federated optimization. In Proceedings of the 9th International Conference on Learning Representations (ICLR 2021), Virtual Event, 3–7 May 2021. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
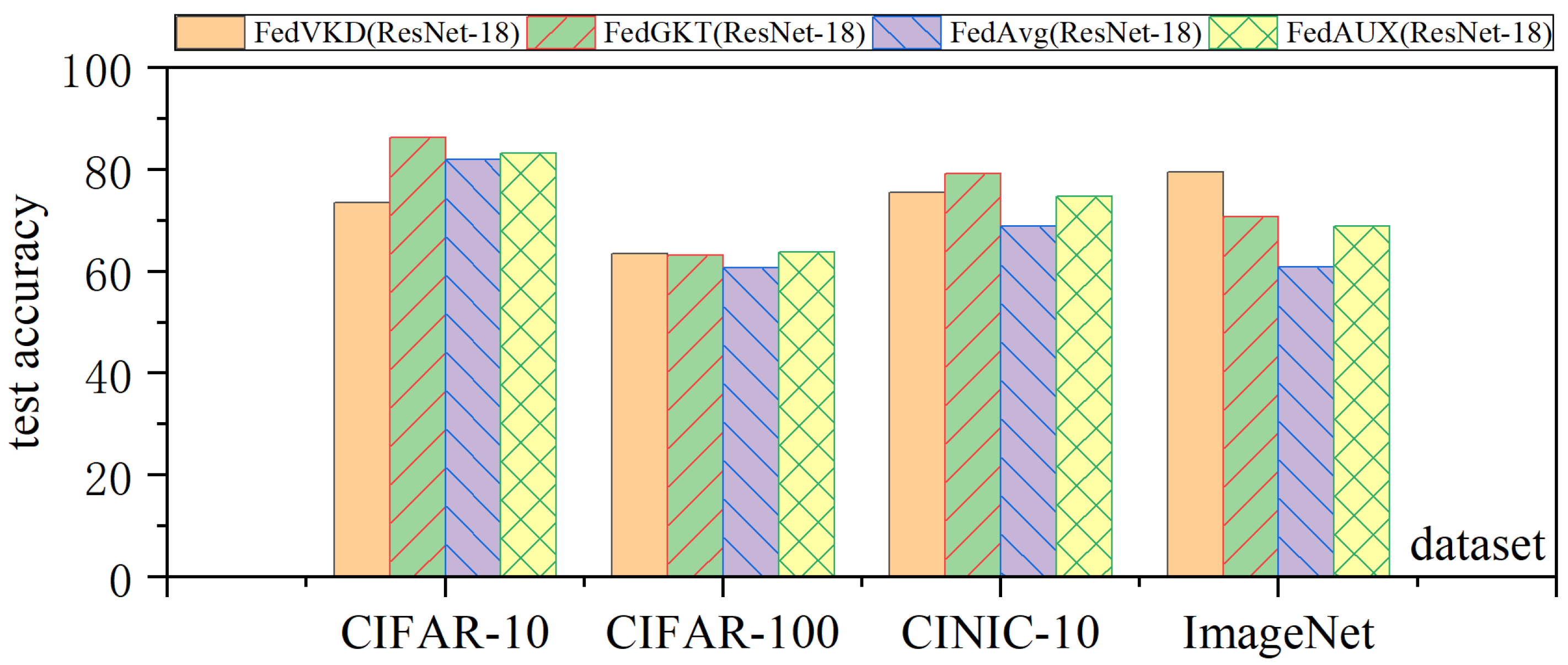{kind=link}
| Method | CIFAR-10 | CIFAR-100 | CINIC-10 | ImageNet | ||||
|---|---|---|---|---|---|---|---|---|
| IID | Non-IID | IID | Non-IID | IID | Non-IID | IID | Non-IID | |
| FedVKD (ViT) | 75.88 | 69.93 | 65.86 | 60.79 | 79.74 | 76.18 | 82.72 | 80.41 |
| FedAUX (ViT) | 77.99 | 74.17 | 68.04 | 62.44 | 80.04 | 77.46 | 78.6 | 75.09 |
| FedAvg (ViT) | 73.91 | 68.10 | 61.87 | 57.84 | 77.77 | 74.24 | 73.79 | 70.99 |
| FedGKT (CNN) | 91.96 | 85.17 | 71.86 | 65.31 | 83.62 | 77.27 | 75.78 | 70.24 |
| FedAUX (CNN) | 93.6 | 90.05 | 74.98 | 70.56 | 83.5 | 78.81 | 77.01 | 74.31 |
| FedAvg (CNN) | 92.74 | 84.36 | 72.71 | 66.44 | 82.75 | 75.18 | 75.86 | 69.83 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tao, J.; Gao, Z.; Guo, Z. Training Vision Transformers in Federated Learning with Limited Edge-Device Resources. Electronics 2022, 11, 2638. https://doi.org/10.3390/electronics11172638
Tao J, Gao Z, Guo Z. Training Vision Transformers in Federated Learning with Limited Edge-Device Resources. Electronics. 2022; 11(17):2638. https://doi.org/10.3390/electronics11172638
Chicago/Turabian StyleTao, Jiang, Zhen Gao, and Zhaohui Guo. 2022. "Training Vision Transformers in Federated Learning with Limited Edge-Device Resources" Electronics 11, no. 17: 2638. https://doi.org/10.3390/electronics11172638