
A Multiscale Fusion Lightweight Image-Splicing Tamper-Detection Model


Abstract
:1. Introduction
2. Related Work
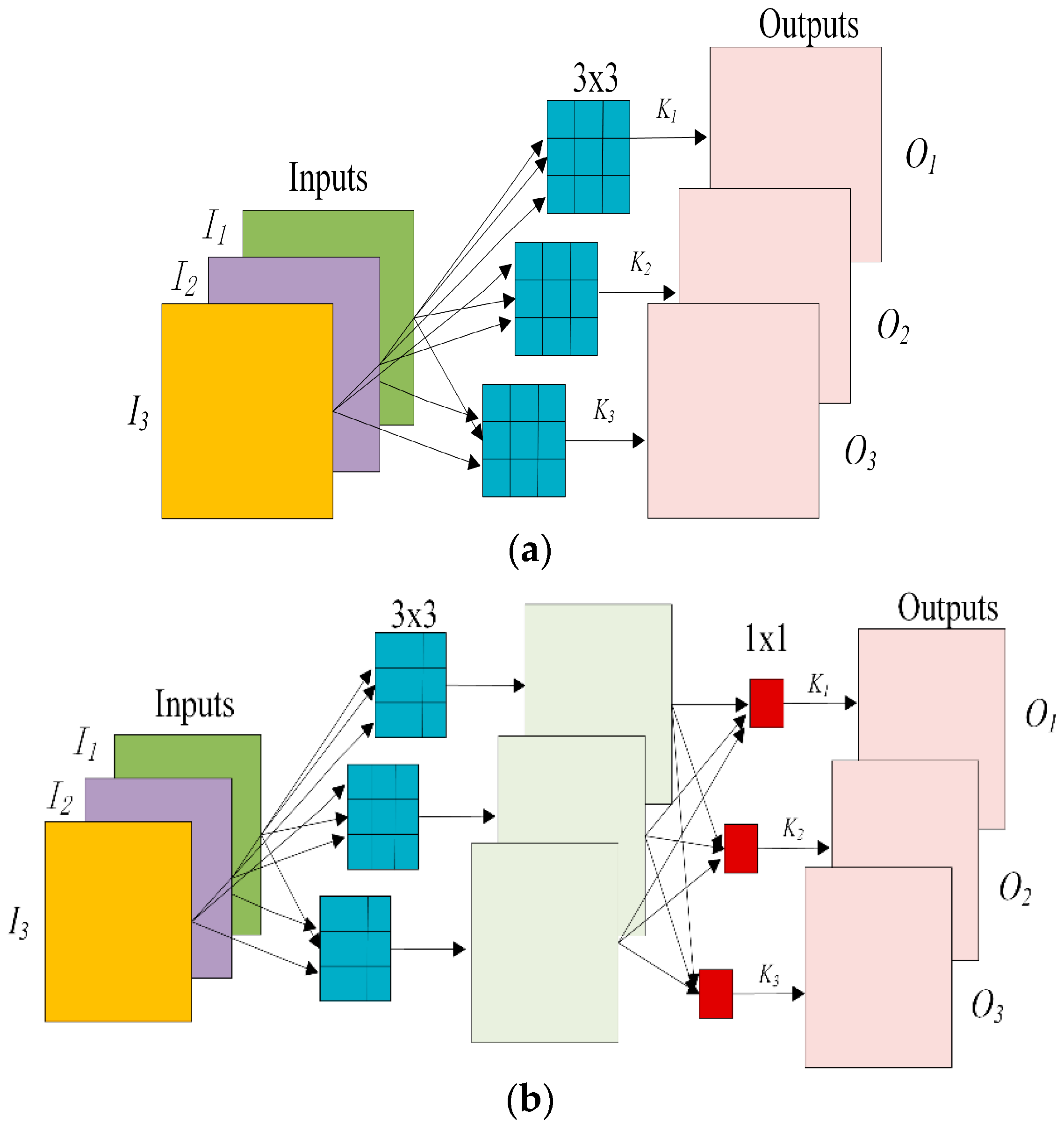
2.1. Depthwise Separable Convolution
2.2. Lightweight MobileNetV2
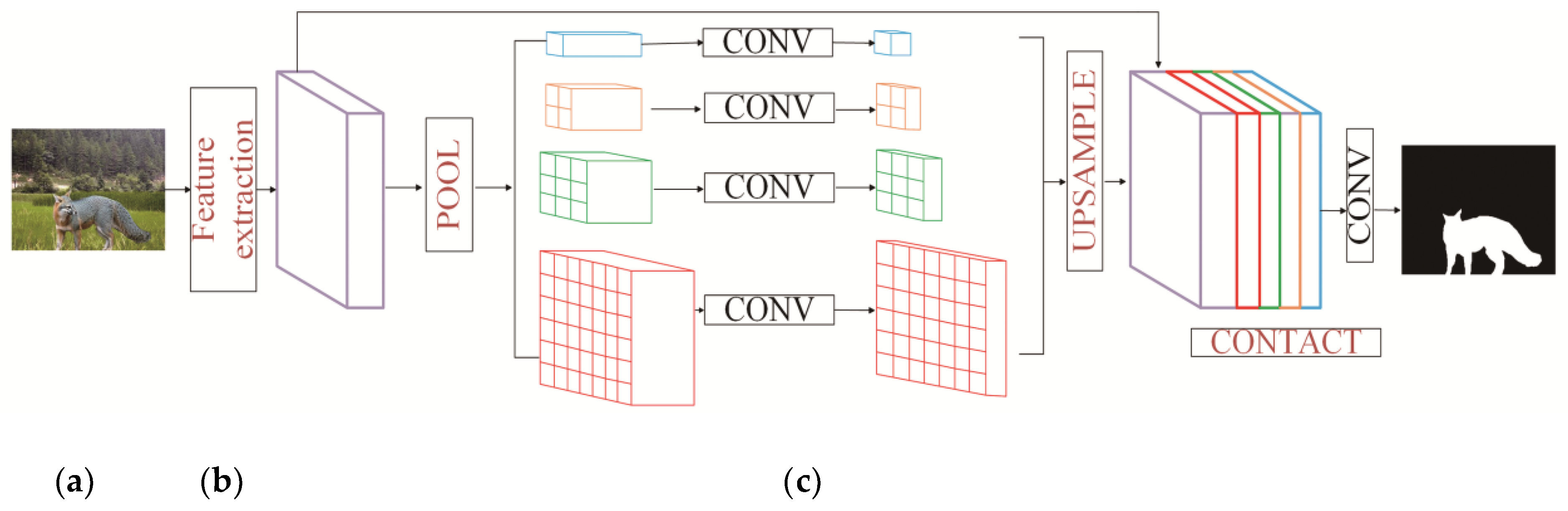
2.3. Pyramid Pooling Module
3. Proposed Method
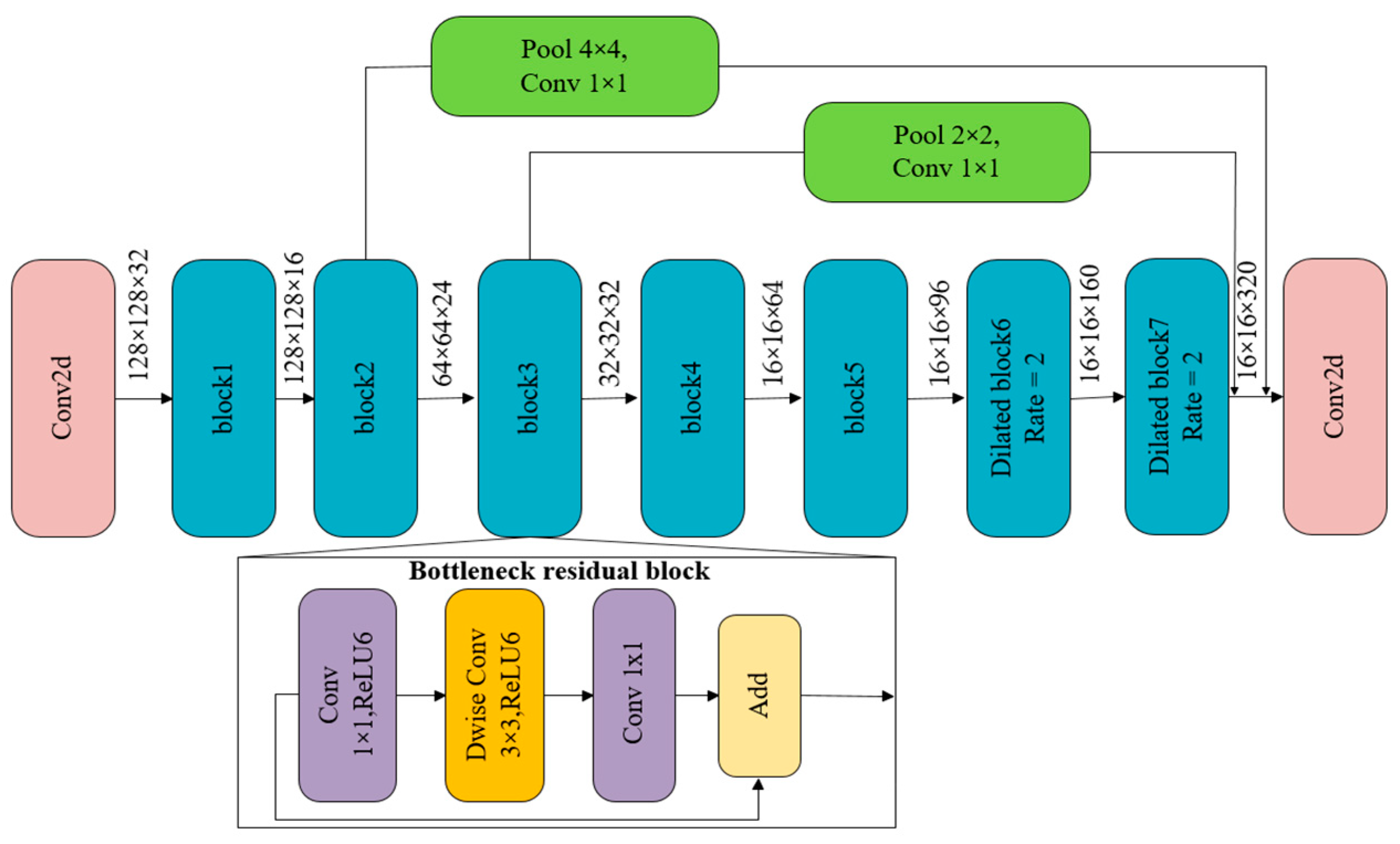
3.1. Improving MobileNetV2
3.2. Feature Extraction Module
4. Experimental Results and Discussion
4.1. Dataset Introduction
4.2. Evaluation Index
4.3. Comparative Approach
4.4. Experimental Results
4.4.1. Ablation Experiment
4.4.2. Common Splicing-Detection Result
- Mobile-Pspnet generally outperformed the traditional image splicing detection methods.
- Compared with the detection methods based on deep-learning comparison methods, the algorithm in this paper had higher accuracy and lower model complexity.
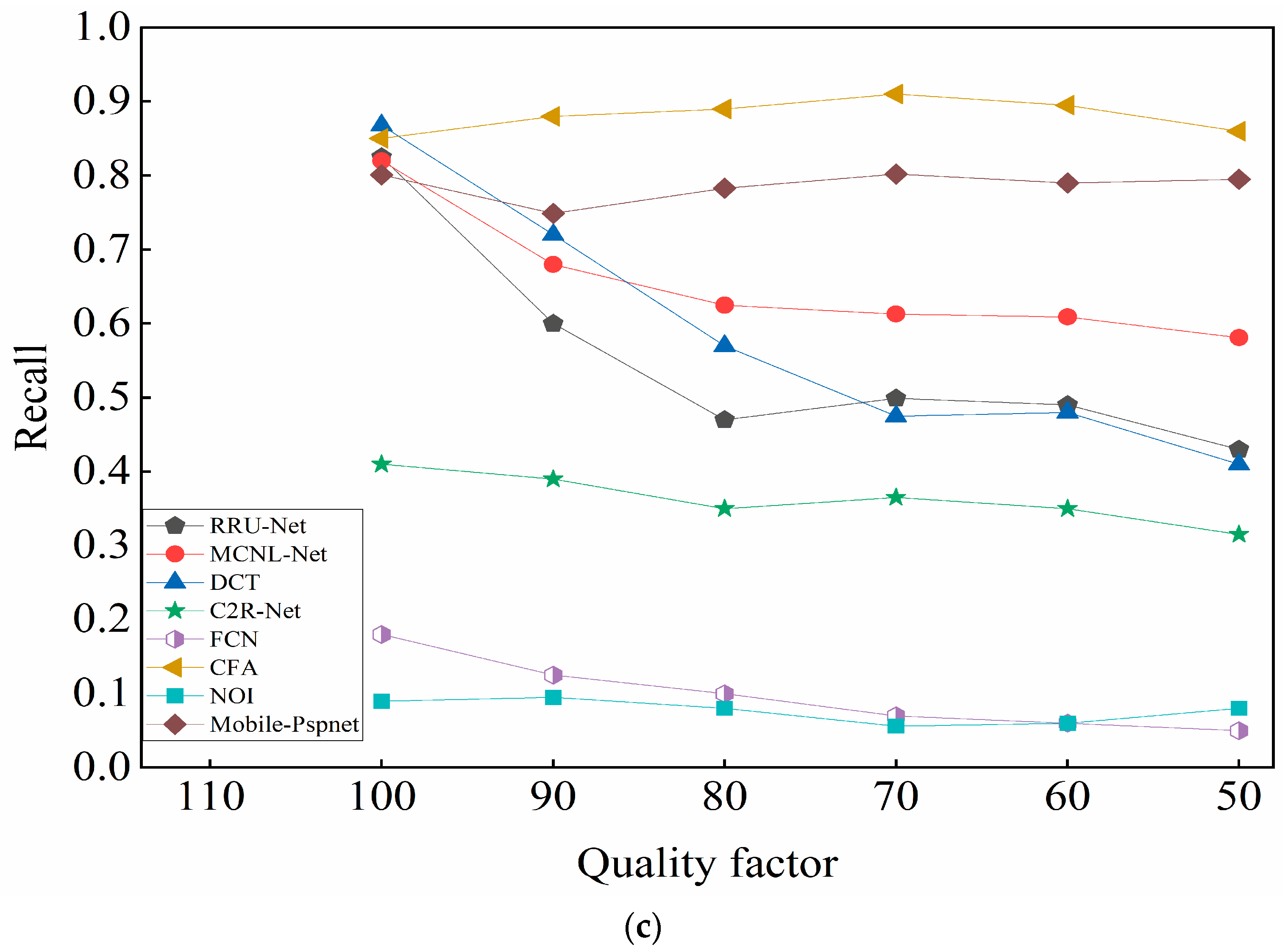
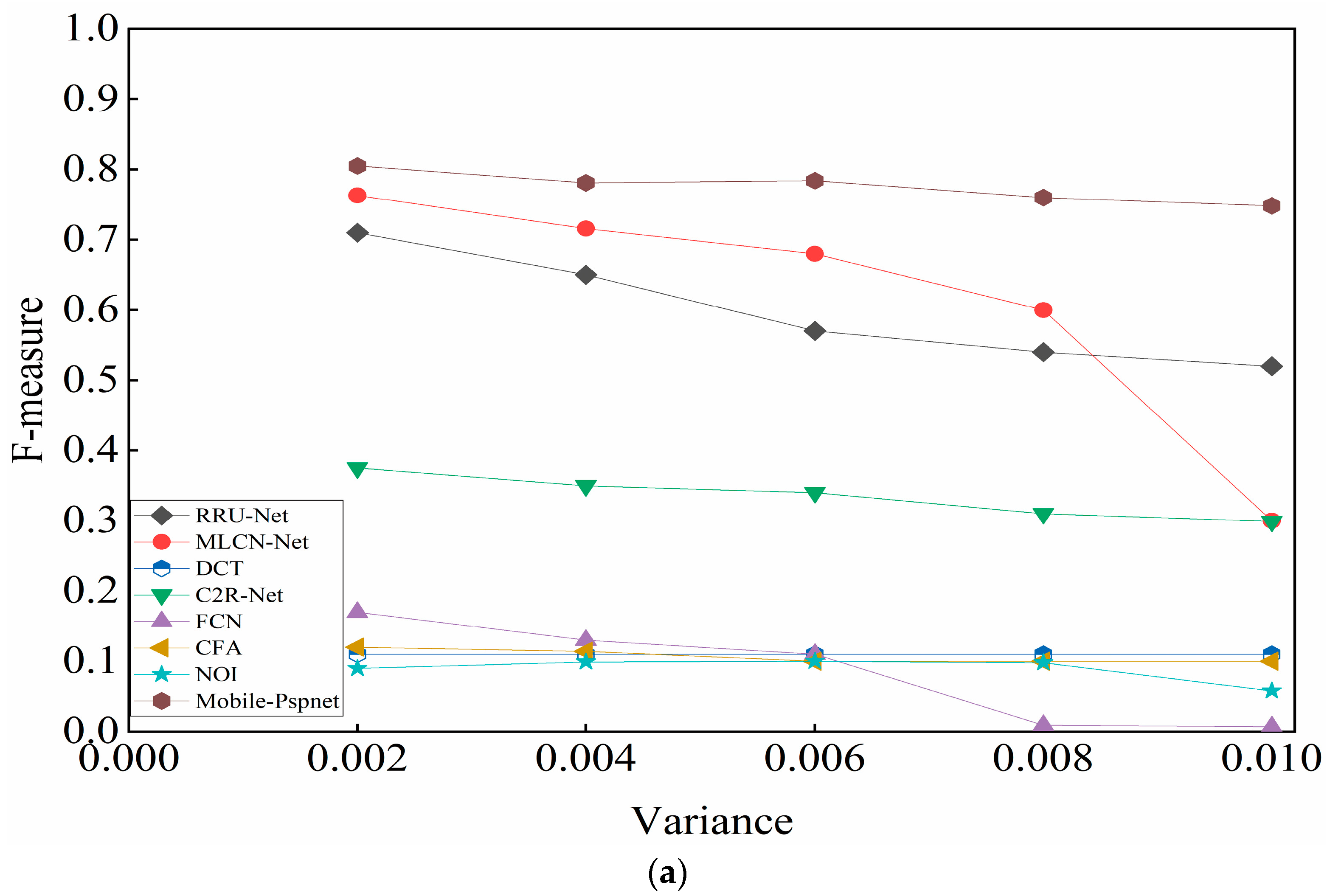
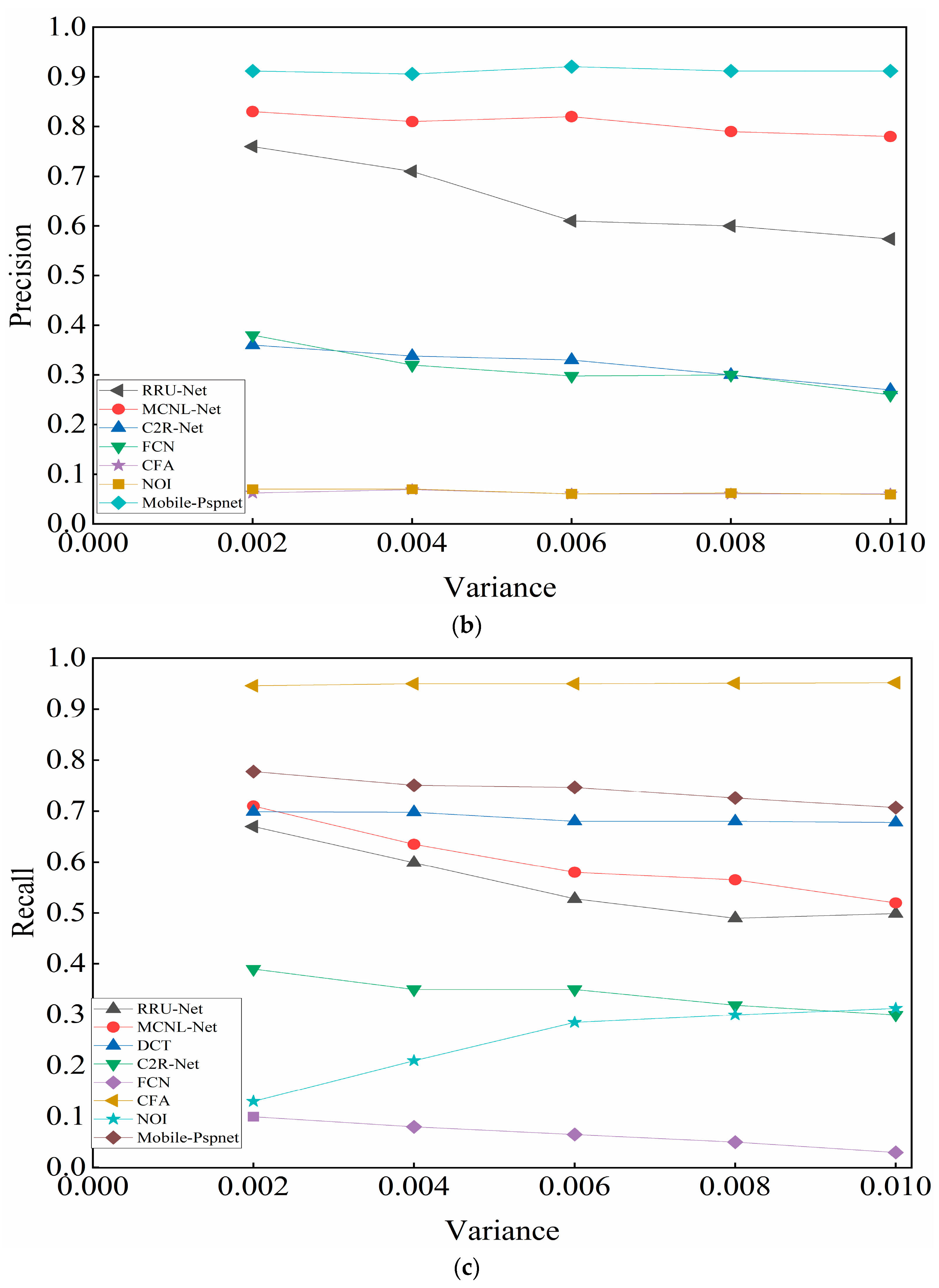
4.4.3. Comparative Experiment of Anti-Interference Detection
- (1)
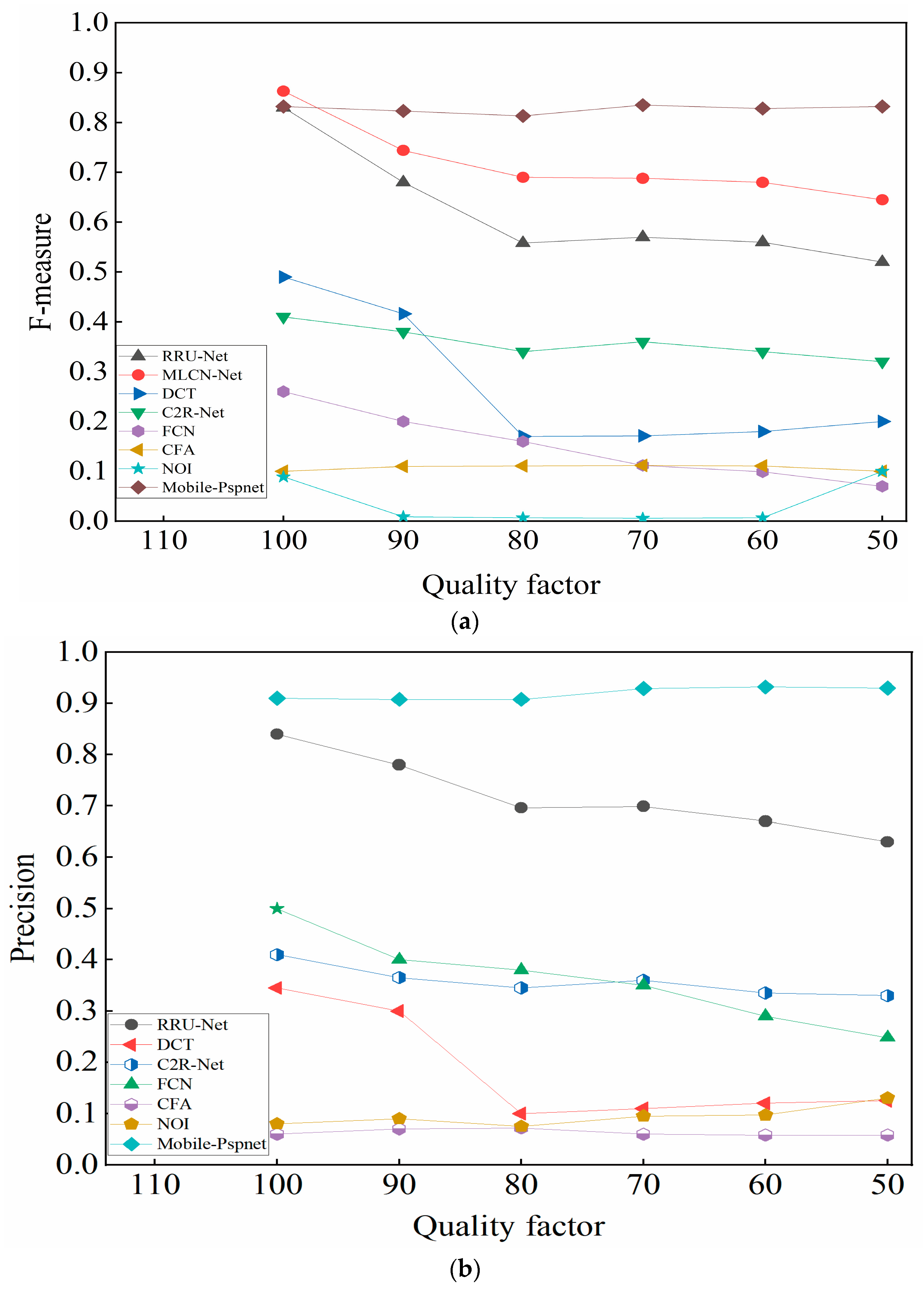
- The CASIA test set was compressed with different JPEG quality factors of 50, 60, 70, 80, and 90 for splicing detection. The results of F-measure, precision, and recall are shown in Figure 5a–c, respectively.
- (2)
- After adding different degrees of noise to the CASIA test set (variances were 0.02, 0.04, 0.06, 0.08, and 0.1), splicing detection was performed. Figure 6a–c show the F-measure, precision, and recall in the experimental results, respectively.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Tsai, Y.H.; Shen, X.; Lin, Z.; Sunkavalli, K.; Lu, X.; Yang, M.H. Deep image harmonization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3789–3797. [Google Scholar]
- Verdoliva, L. Media forensics and deepfakes: An overview. IEEE J. Sel. Top. Signal Process. 2020, 14, 910–932. [Google Scholar] [CrossRef]
- Mahdian, B.; Saic, S. Using noise inconsistencies for blind image forensics. Image Vis. Comput. 2009, 27, 1497–1503. [Google Scholar] [CrossRef]
- Ferrara, P.; Bianchi, T.; De Rosa, A.; Piva, A. Image forgery localization via fine-grained analysis of CFA artifacts. IEEE Trans. Inf. Forensics Secur. 2012, 7, 1566–1577. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.; Wang, Y.; Lei, J.; Li, B.; Wang, Q.; Xue, J. Coarse-to-fine-grained method for image splicing region detection. Pattern Recognit. 2022, 122, 108347. [Google Scholar] [CrossRef]
- Singh, G.; Singh, K. Digital image forensic approach based on the second-order statistical analysis of CFA artifacts. Forensic Sci. Int. Digit. Investig. 2022, 05, 7. [Google Scholar] [CrossRef]
- Ye, S.; Sun, Q.; Chang, E.C. Detecting digital image forgeries by measuring inconsistencies of blocking artifact. In Proceedings of the 2007 IEEE International Conference on Multimedia and Expo, Beijing, China, 2–5 July 2007; pp. 12–15. [Google Scholar]
- Bianchi, T.; Piva, A. Image forgery localization via block-grained analysis of JPEG artifacts. IEEE Trans. Inf. Forensics Secur. 2012, 7, 1003–1017. [Google Scholar] [CrossRef] [Green Version]
- Abecidan, R.; Itier, V.; Boulanger, J.; Bas, P. Unsupervised JPEG Domain Adaptation for Practical Digital Image Forensics. In Proceedings of the 2021 IEEE International Workshop on Information Forensics and Security (WIFS), Montpellier, France, 7–10 December 2021; pp. 1–6. [Google Scholar]
- Chierchia, G.; Poggi, G.; Sansone, C.; Verdoliva, L. A Bayesian-MRF approach for PRNU-based image forgery detection. IEEE Trans. Inf. Forensics Secur. 2014, 9, 554–567. [Google Scholar] [CrossRef]
- Flor, E.; Aygun, R.; Mercan, S.; Akkaya, K. PRNU-based Source Camera Identification for Multimedia Forensics. In Proceedings of the 2021 IEEE 22nd International Conference on Information Reuse and Integration for Data Science (IRI), Las Vegas, NV, USA, 10–12 August 2021; pp. 168–175. [Google Scholar]
- De Carvalho, T.J.; Riess, C.; Angelopoulou, E.; Pedrini, H.; de Rezende Rocha, A. Exposing digital image forgeries by illumination color classification. IEEE Trans. Inf. Forensics Secur. 2013, 8, 1182–1194. [Google Scholar] [CrossRef] [Green Version]
- Wu, X.; Fang, Z. Image splicing detection using illuminant color inconsistency. In Proceedings of the 2011 Third International Conference on Multimedia Information Networking and Security, Shanghai, China, 4–6 November 2011; pp. 600–603. [Google Scholar]
- Zhang, Y.; Goh, J.; Win, L.L.; Thing, V.L. Image Region Forgery Detection: A Deep Learning Approach. SG-CRC 2016, 2016, 1–11. [Google Scholar]
- Liu, B.; Pun, C.M. Deep fusion network for splicing forgery localization. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Wei, Y.; Bi, X.; Xiao, B. C2r net: The coarse to refined network for image forgery detection. In Proceedings of the 2018 17th IEEE International Conference on Trust, Security and Privacy in Computing and Communications/12th IEEE International Conference on Big Data Science and Engineering (TrustCom/BigDataSE), New York, NY, USA, 1–3 August 2018; pp. 1656–1659. [Google Scholar]
- Huh, M.; Liu, A.; Owens, A.; Efros, A.A. Fighting fake news: Image splice detection via learned self-consistency. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 101–117. [Google Scholar]
- Zhou, P.; Han, X.; Morariu, V.I.; Davis, L.S. Learning rich features for image manipulation detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1053–1061. [Google Scholar]
- Wu, Y.; AbdAlmageed, W.; Natarajan, P. Mantra-net: Manipulation tracing network for detection and localization of image forgeries with anomalous features. In Proceedings of the IEEE/ CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 9543–9552. [Google Scholar]
- Remya Revi, K.; Wilscy, M. Image forgery detection using deep textural features from local binary pattern map. J. Intell. Fuzzy Syst. 2020, 38, 6391–6401. [Google Scholar] [CrossRef]
- El-Latif, E.; Taha, A.; Zayed, H.H. A passive approach for detecting image splicing based on deep learning and wavelet transform. Arab. J. Sci. Eng. 2020, 45, 3379–3386. [Google Scholar] [CrossRef]
- Nath, S.; Naskar, R. Automated image splicing detection using deep CNN-learned features and ANN-based classifier. Signal Image Video Process. 2021, 15, 1601–1608. [Google Scholar] [CrossRef]
- Horváth, J.; Baireddy, S.; Hao, H.; Montserrat, D.M.; Delp, E.J. Manipulation Detection in Satellite Images Using Vision Transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Online, 19–25 June 2021; pp. 1032–1041. [Google Scholar]
- Jaiswal, A.K.; Srivastava, R. Forensic image analysis using inconsistent noise pattern. Pattern Anal. Appl. 2021, 24, 655–667. [Google Scholar] [CrossRef]
- Kwon, M.J.; Yu, I.J.; Nam, S.H.; Lee, H.K. CAT-net: Compression artifact tracing network for detection and localization of image splicing. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Online, 19–25 June 2021; pp. 375–384. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE conference on computer vision and pattern recognition, Salt Lake City, UT, USA, 19–21 June 2018; pp. 4510–4520. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2022, arXiv:1704.04861v1. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (VOC) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Shore, J.; Johnson, R. Axiomatic derivation of the principle of maximum entropy and the principle of minimum crossentropy. IEEE Trans. Inf. Theory 1980, 26, 26–37. [Google Scholar] [CrossRef] [Green Version]
- Dong, J.; Wang, W.; Tan, T. Casia image tampering detection evaluation database. In Proceedings of the 2013 IEEE China Summit and International Conference on Signal and Information Processing, Beijing, China, 6–10 July 2013; pp. 422–426. [Google Scholar]
- Hsu, Y.F.; Chang, S.F. Detecting image splicing using geometry invariants and camera characteristics consistency. In Proceedings of the 2006 IEEE International Conference on Multimedia and Expo, Toronto, ON, Canada, 9–12 July 2006; pp. 549–552. [Google Scholar]
- Pham, N.T.; Lee, J.W.; Kwon, G.R.; Park, C.S. Hybrid image-retrieval method for image splicing validation. Symmetry Hybrid image-retrieval method for image splicing validation. Symmetry 2019, 11, 83. [Google Scholar] [CrossRef] [Green Version]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Bi, X.; Wei, Y.; Xiao, B.; Li, W.S. RRU-Net: The ringed residual U-Net for image splicing forgery detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Wei, Y.; Wang, Z.; Xiao, B.; Liu, X.; Yan, Z.; Ma, J. Controlling neural learning network with multiple scales for image splicing forgery detection. ACM Trans. Multimed. Comput. Commun. Appl. 2020, 16, 1–22. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Operation (Before) | Operation | Stride (Before) | Stride |
|---|---|---|---|---|
| 1 | Block | Block | 1 | 1 |
| 2 | Block | Block | 2 | 2 |
| 3 | Block | Block | 2 | 2 |
| 4 | Block | Block | 2 | 2 |
| 5 | Block | Block | 1 | 1 |
| 6 | Block | dilated block | 2 | Stride = 1, dilate rate = 2 |
| 7 | Block | dilated block | 1 | Stride = 1, dilate rate = 2 |
| Sets | Cases | Parameters | Range | Step | CASIA | COLUMB |
|---|---|---|---|---|---|---|
| Training Set | Augmented splicing | — | — | — | 20,000 | 625 |
| Source image | — | — | — | 4000 | 125 | |
| Validation Set | Plain splicing | — | — | — | 1500 | 110 |
| Source image | — | — | — | 300 | 11 | |
| Testing Set | Plain splicing | — | — | — | 100 | 44 |
| Source image | — | — | — | 100 | 44 | |
| JPEG compression | Quality factor | 50–90 | 10 | 500 | 220 | |
| Noise corruption | Variance | 0.002~0.01 | 0.002 | 500 | 220 |
| Methods | Para (MB) | GFLOPs | IoU (%) |
|---|---|---|---|
| MobileNetV2 | 2.41 | 1.68 | 70.12 |
| Ours | 2.53 | 1.72 | 76.75 |
| Methods | CASIA | COLUMB | ||||
|---|---|---|---|---|---|---|
| Precision | Recall | F-Measure | Precision | Recall | F-Measure | |
| CFA [4] | 0.057 | 0.846 | 0.108 | 0.574 | 0.469 | 0.517 |
| DCT [7] | 0.349 | 0.871 | 0.498 | 0.365 | 0.633 | 0.463 |
| NOI [3] | 0.079 | 0.088 | 0.083 | 0.321 | 0.015 | 0.028 |
| DF-Net [16] | - | - | - | 0.528 | 0.468 | 0.496 |
| C2R-Net [17] | 0.417 | 0.424 | 0.42 | 0.576 | 0.097 | 0.166 |
| FCN [34] | 0.509 | 0.173 | 0.259 | 0.859 | 0.443 | 0.584 |
| MCNL-Net [36] | 0.909 | 0.828 | 0.866 | 0.839 | 0.715 | 0.772 |
| RRU-Net [35] | 0.848 | 0.834 | 0.841 | 0.961 | 0.873 | 0.915 |
| Ours | 0.910 | 0.801 | 0.832 | 0.964 | 0.852 | 0.881 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, D.; Tian, X. A Multiscale Fusion Lightweight Image-Splicing Tamper-Detection Model. Electronics 2022, 11, 2621. https://doi.org/10.3390/electronics11162621
Zhao D, Tian X. A Multiscale Fusion Lightweight Image-Splicing Tamper-Detection Model. Electronics. 2022; 11(16):2621. https://doi.org/10.3390/electronics11162621
Chicago/Turabian StyleZhao, Dan, and Xuedong Tian. 2022. "A Multiscale Fusion Lightweight Image-Splicing Tamper-Detection Model" Electronics 11, no. 16: 2621. https://doi.org/10.3390/electronics11162621