
A Spatio-Temporal Feature Trajectory Clustering Algorithm Based on Deep Learning


Abstract
:1. Introduction
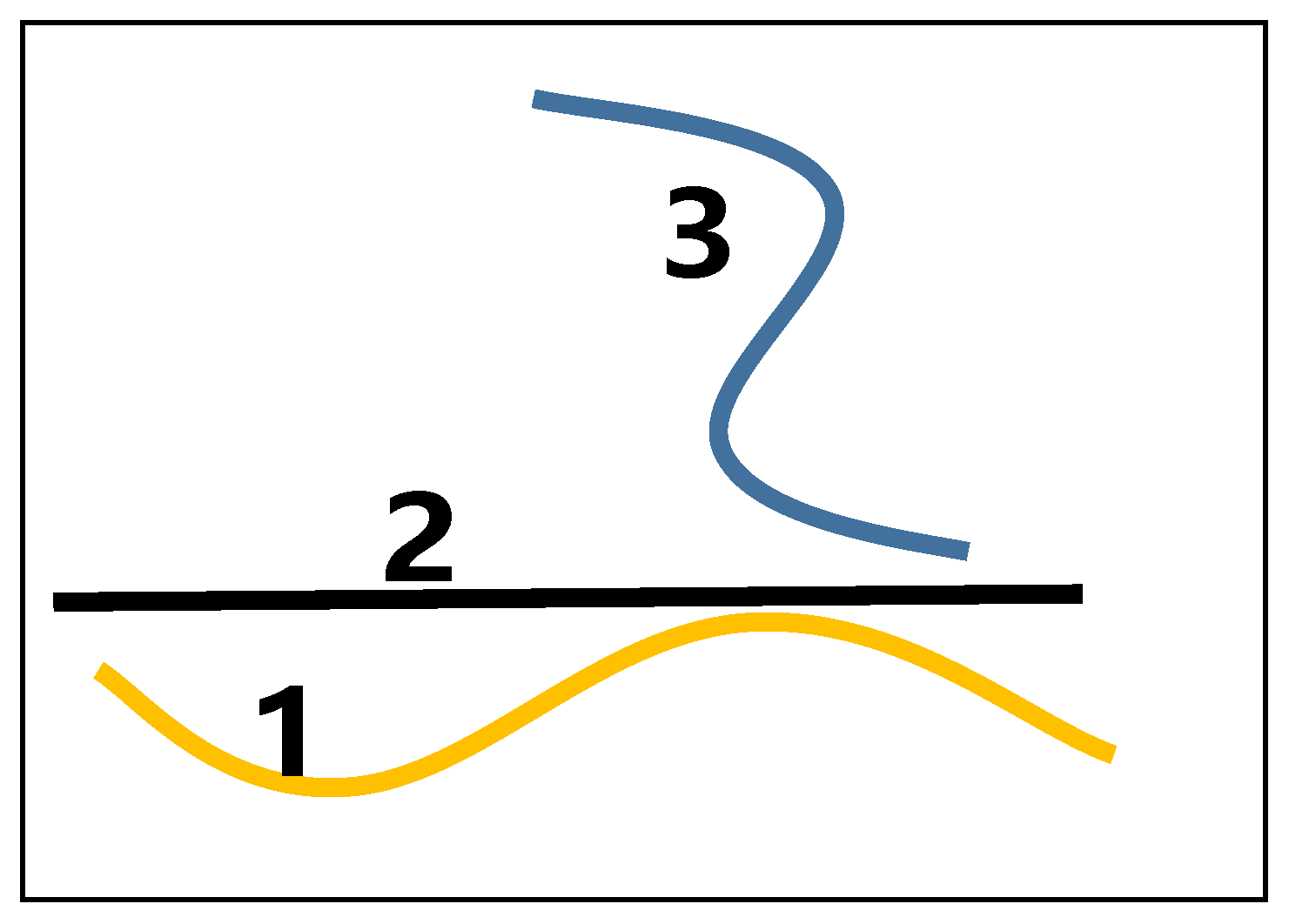
2. Problem Analysis
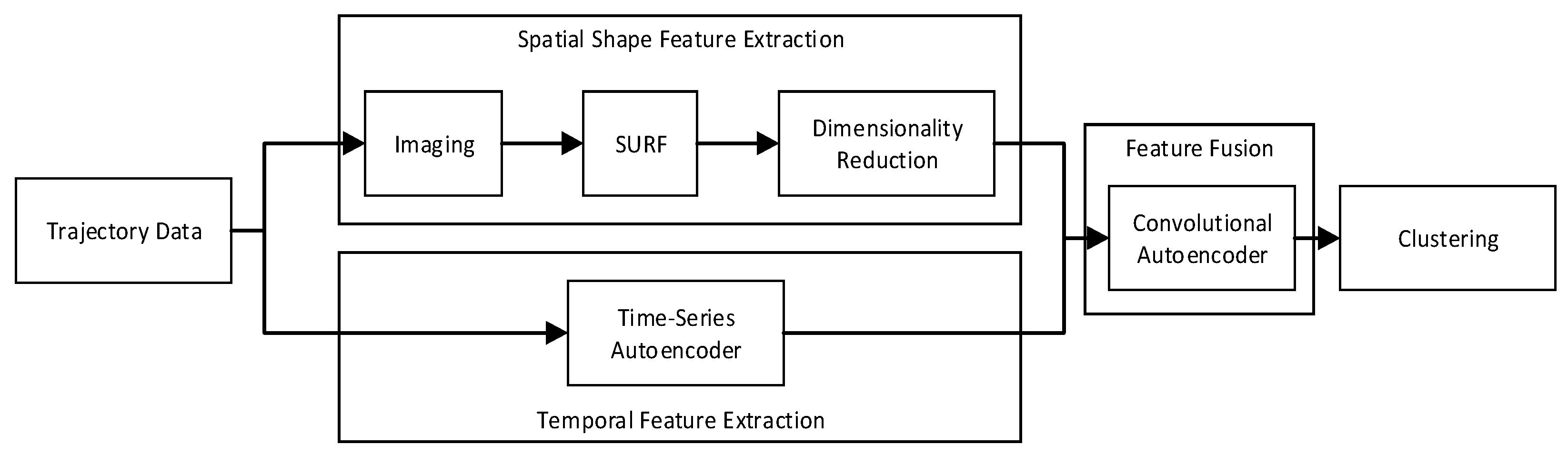
3. A Spatio-Temporal Feature Trajectory Clustering Algorithm
3.1. Image-Based Trajectory Spatial Shape Feature Extraction Algorithm
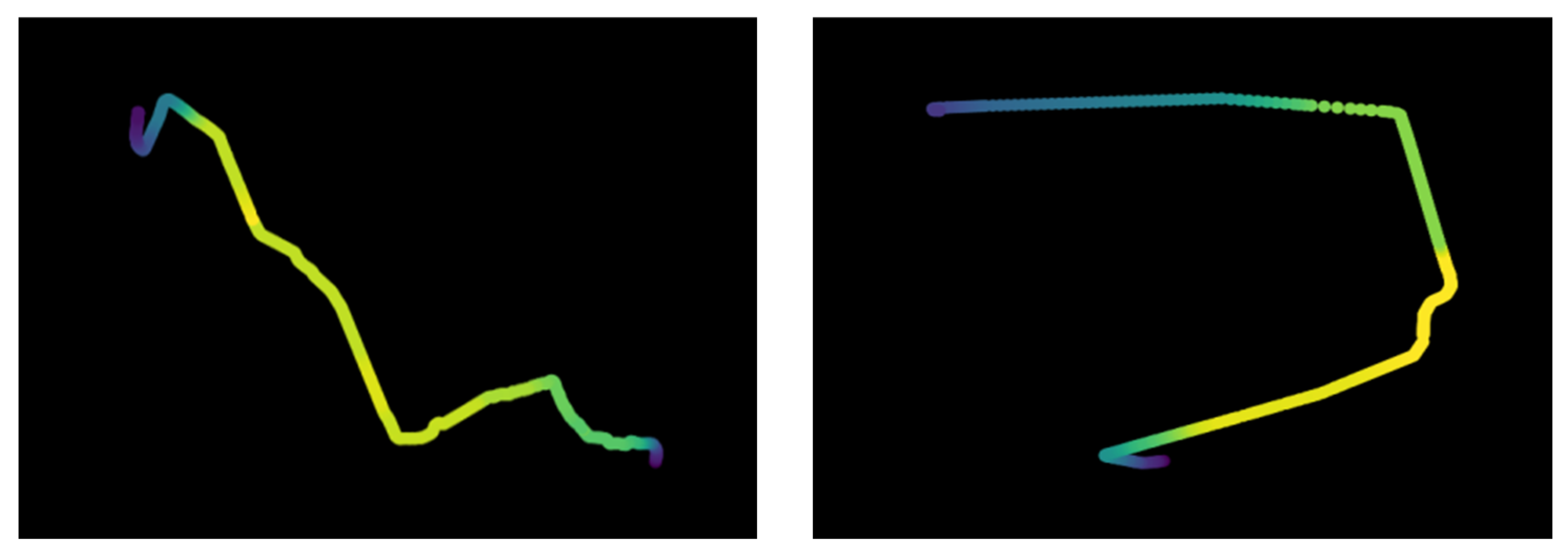
3.1.1. Trajectory Imaging
3.1.2. SURF Similarity Matching
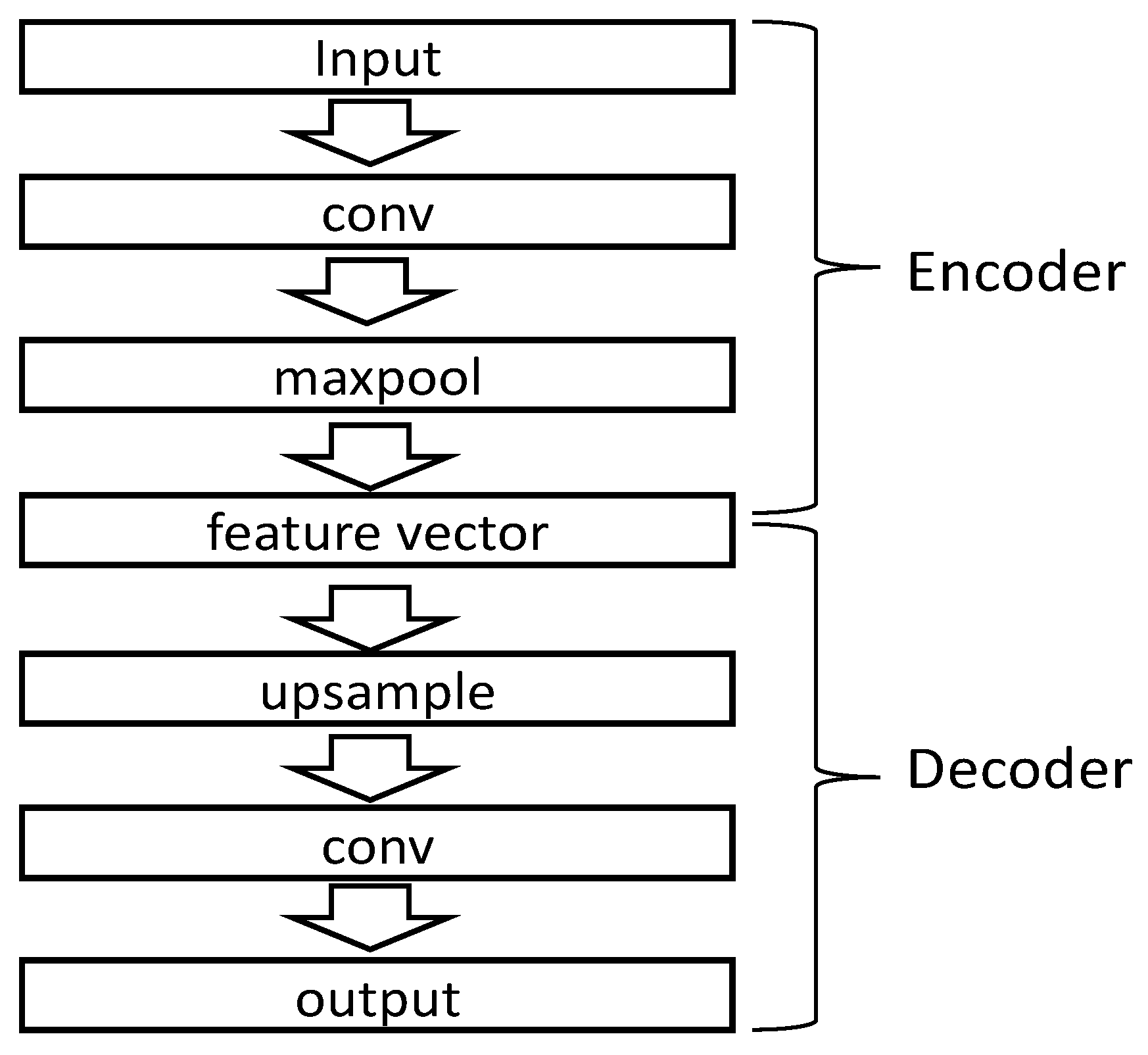
3.1.3. Feature Dimensionality Reduction
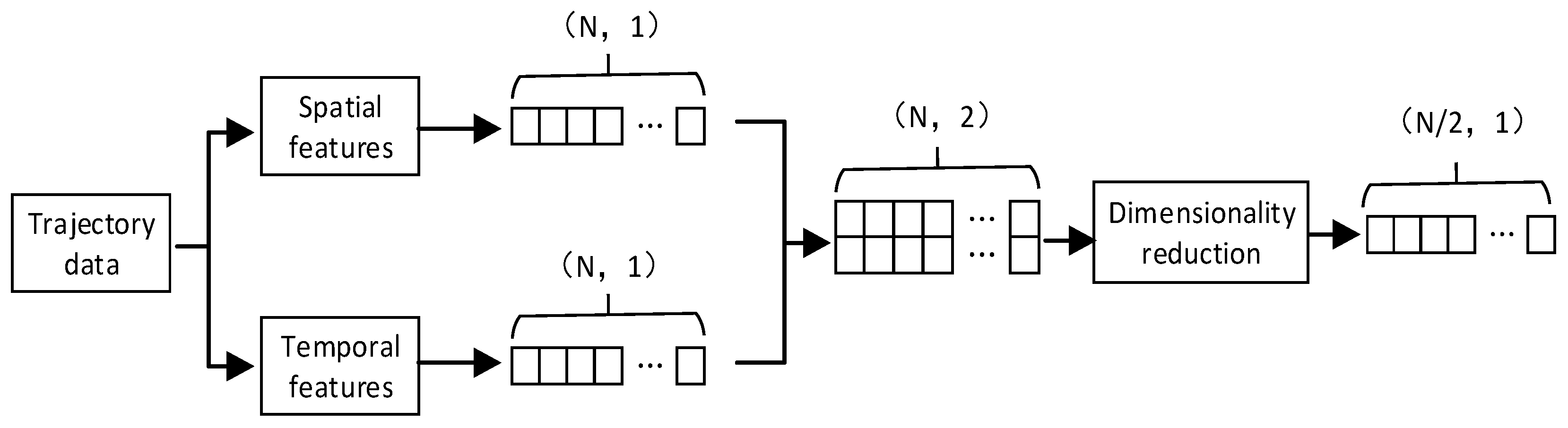
3.2. Spatio-Temporal Feature Trajectory Clustering Algorithm
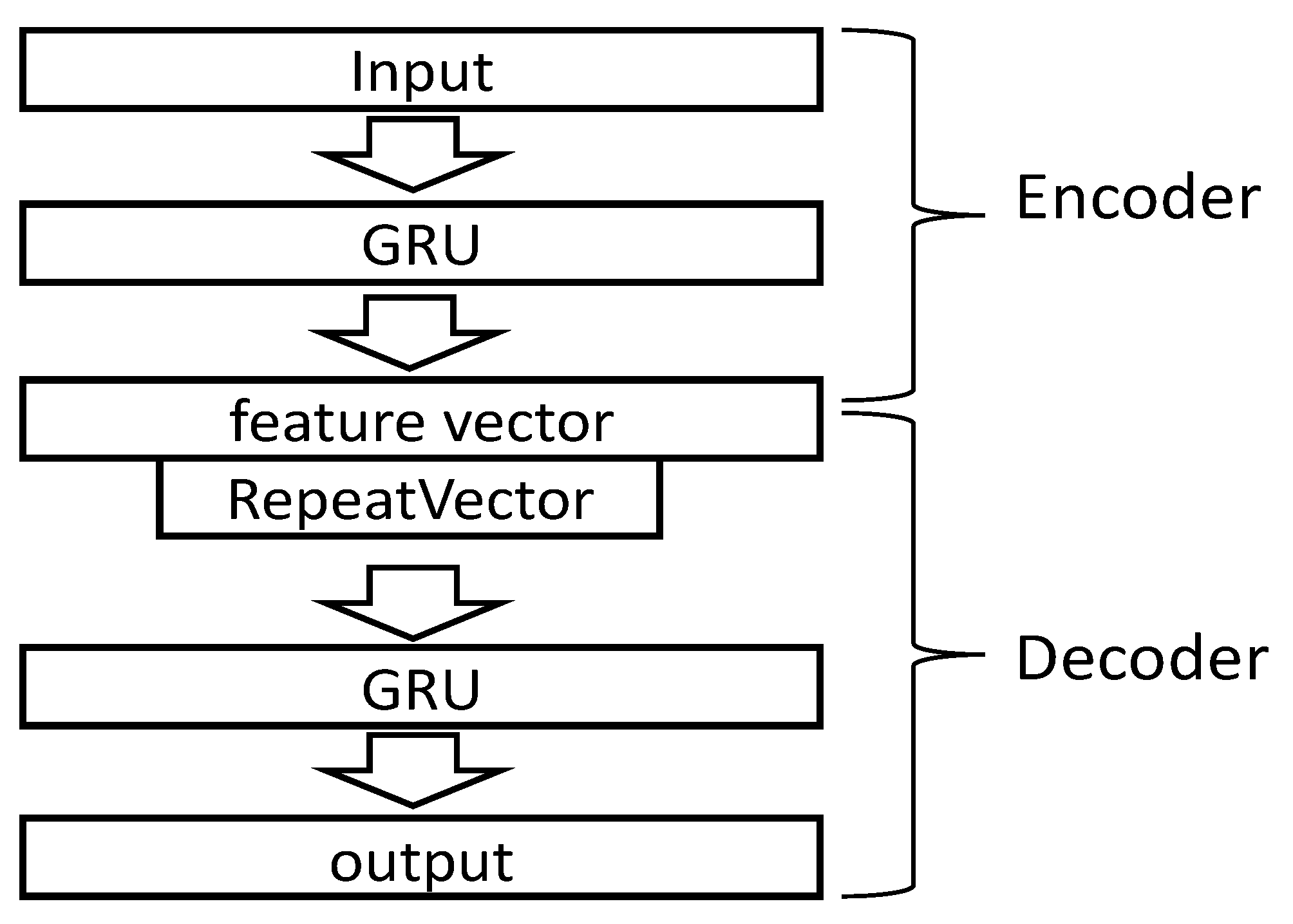
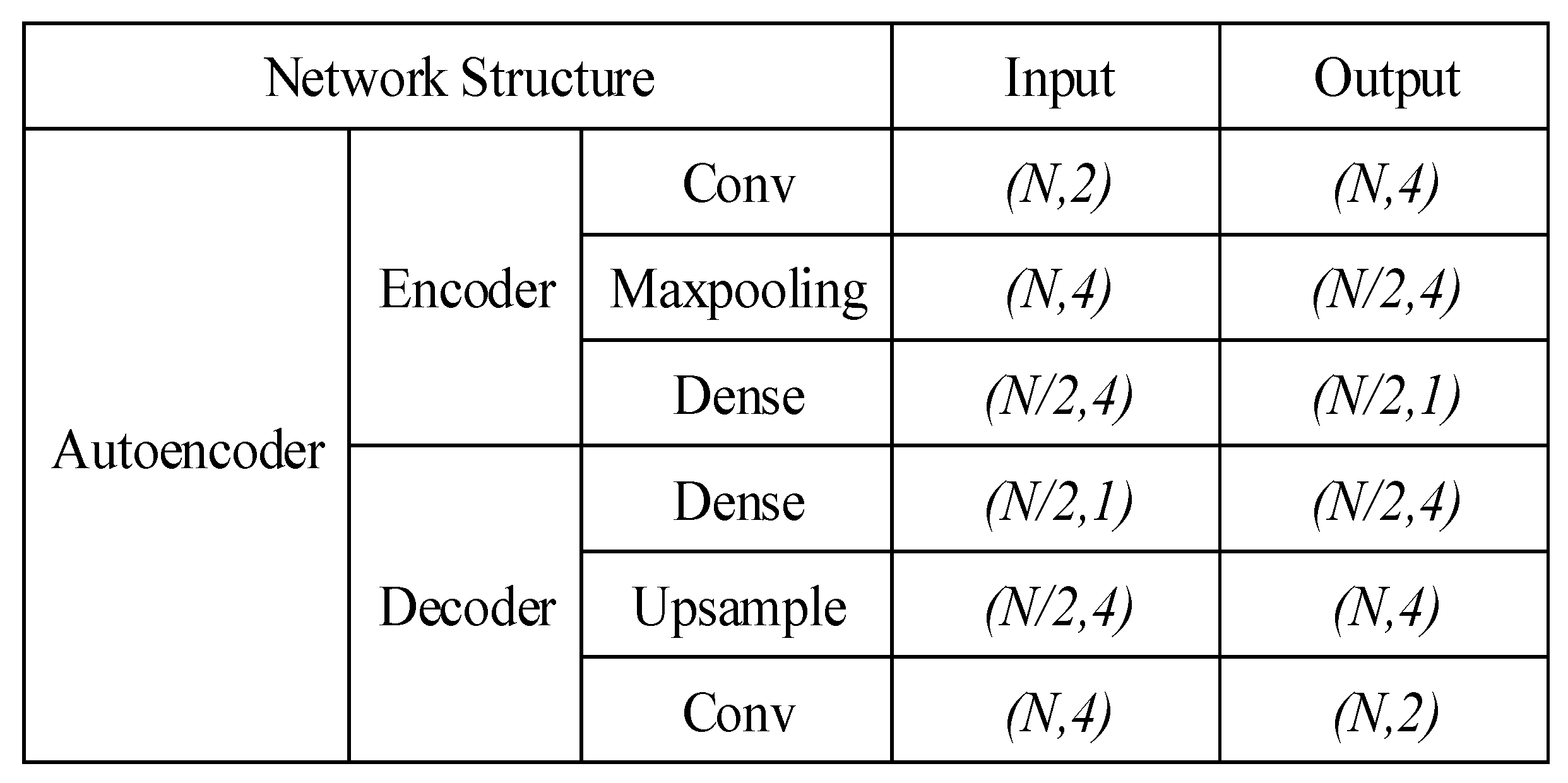
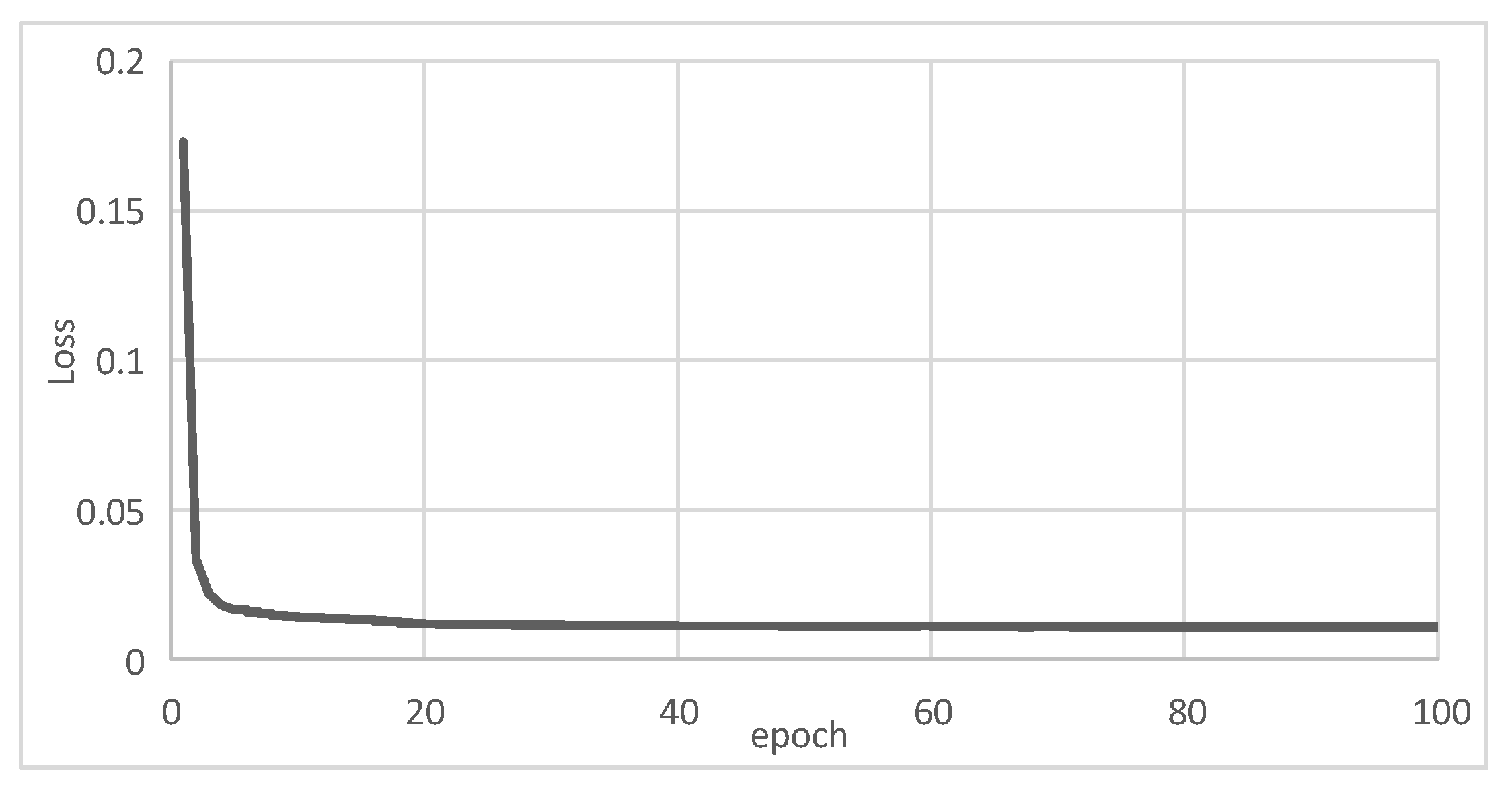
3.2.1. Temporal Feature Extraction
3.2.2. Feature Fusion
3.2.3. Clustering
4. Experiment and Analysis
4.1. Experimental Design
4.1.1. Performance Index
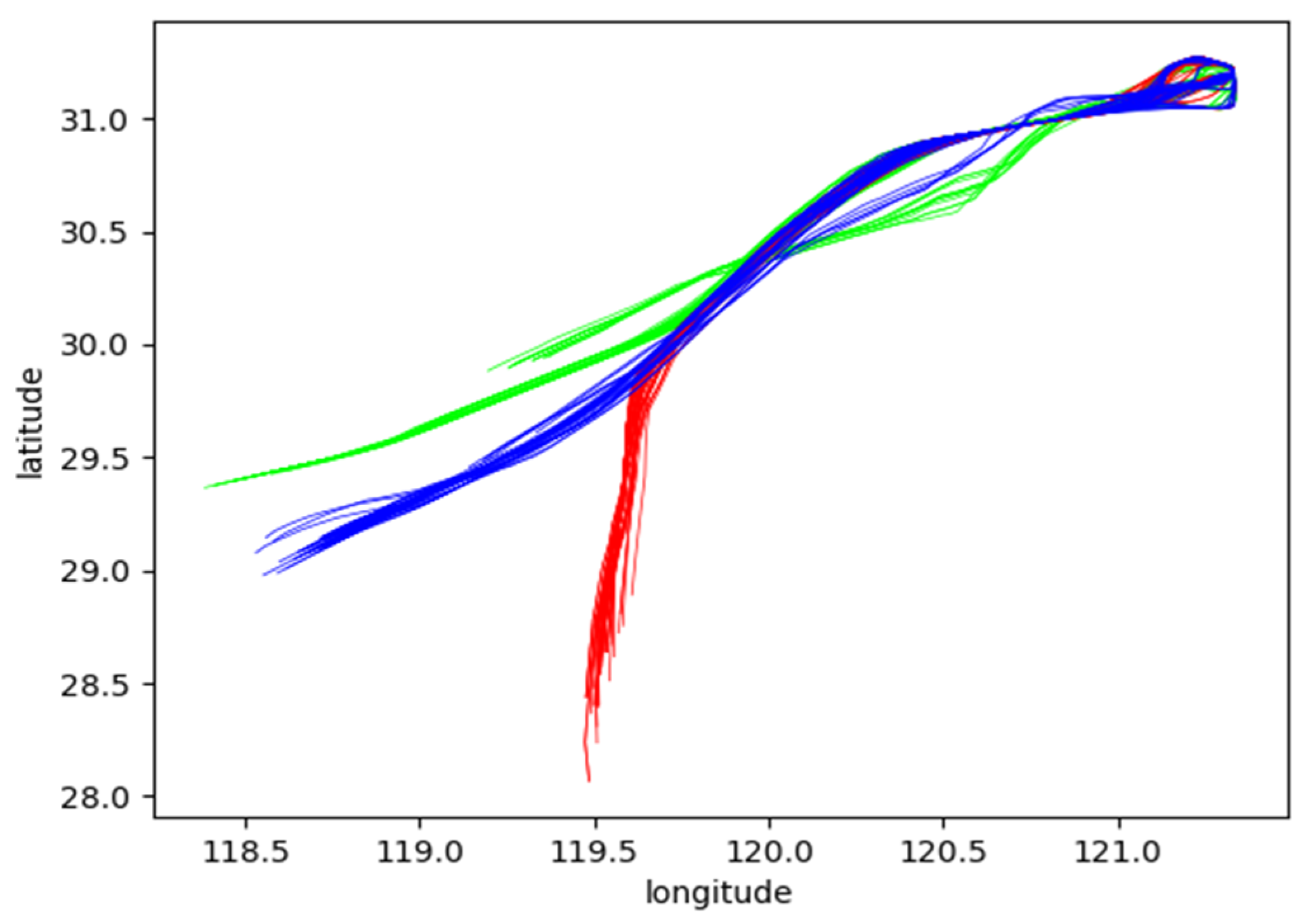
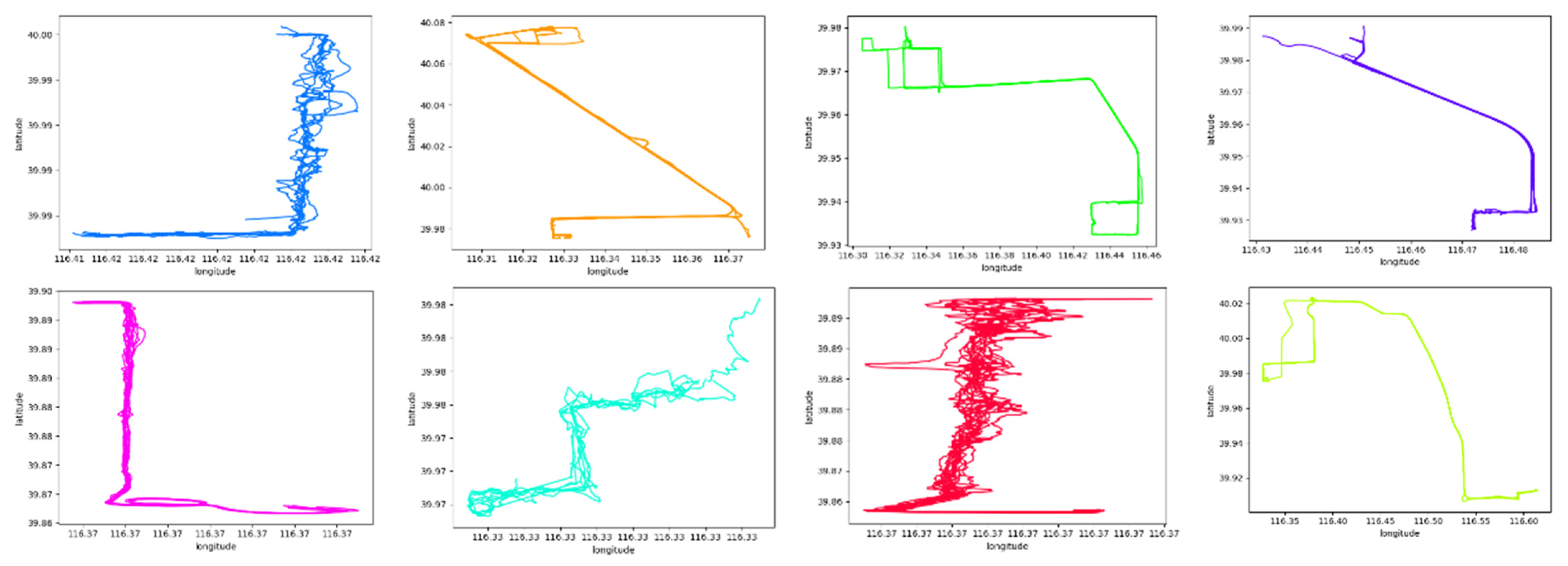
4.1.2. Data Sources
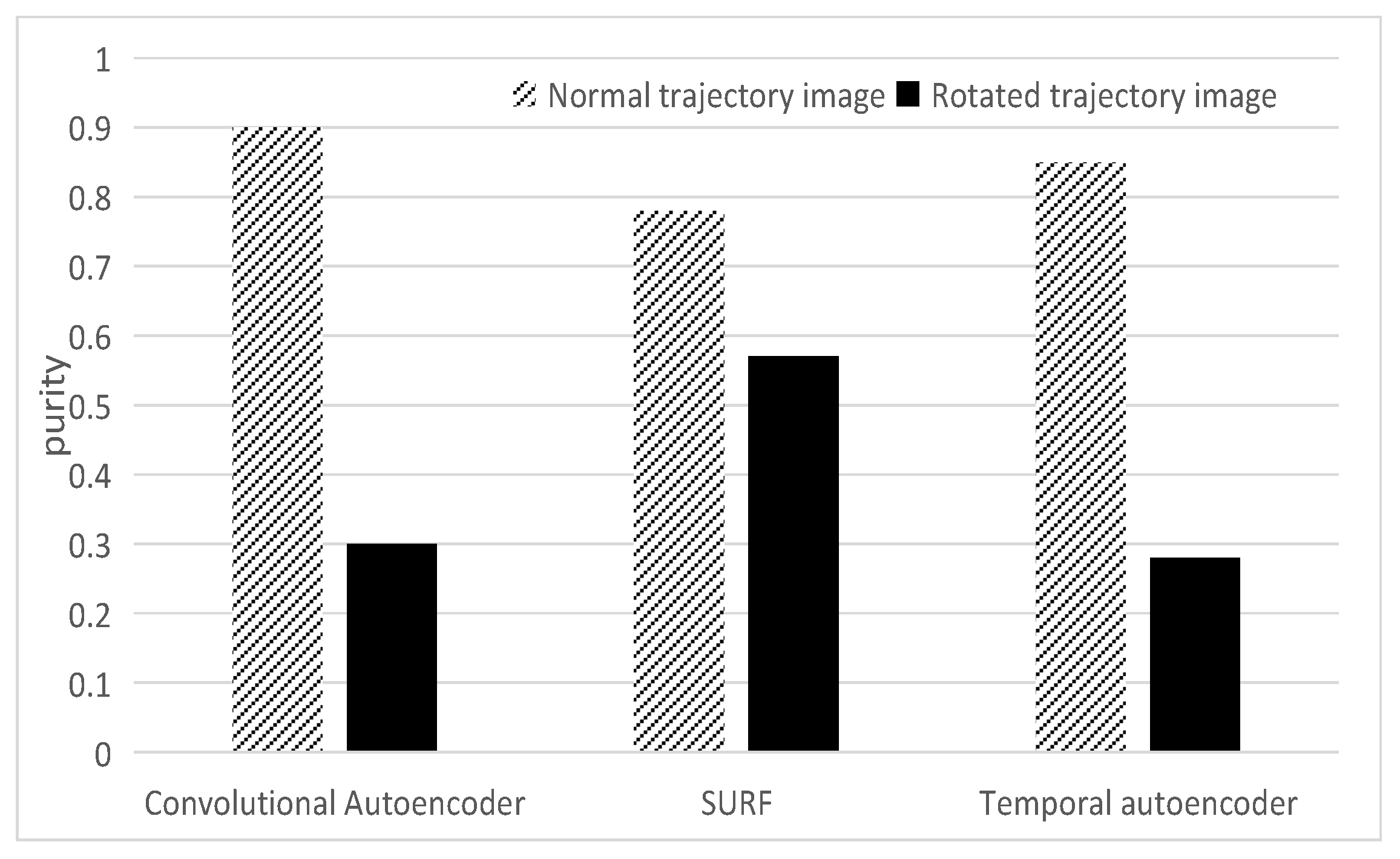
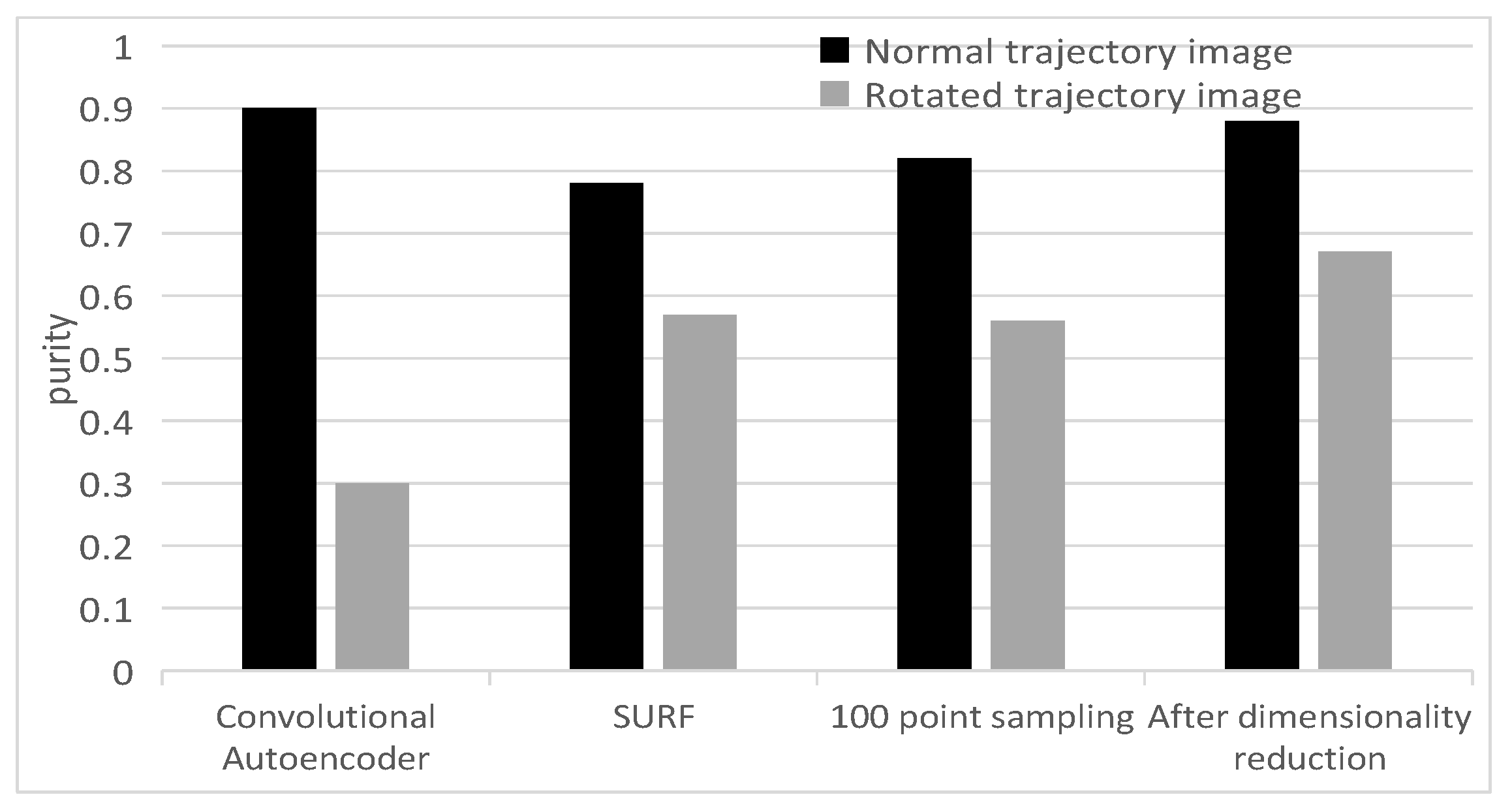
4.2. Verification of Trajectory Spatial Shape Feature Extraction
4.2.1. Simulation Datasets
4.2.2. SURF Algorithm Effect Verification
4.2.3. Verification of Spatial Shape Feature Extraction Process
4.2.4. Verification of Feature Fusion Effect
4.3. Algorithm Comparison
4.3.1. Datasets
4.3.2. Experimental Results
5. Conclusions
- (1)
- An image-based trajectory spatial shape feature extraction algorithm is proposed. It is used to extract the overall shape features of the trajectory and is robust to changes such as rotation and scaling of the trajectory.
- (2)
- The extracted spatial shape features and temporal features are fused, and a trajectory clustering method based on the fusion of temporal and spatial features is proposed to get better clustering performance.
- (3)
- The performance of the algorithm is verified by experiments on simulated datasets and actual ADS-B and GPS datasets. The experimental results show that the algorithm in this paper can effectively extract the trajectory spatial shape features and obtain better clustering performance.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, J.; Liu, W.; Zhu, Y. Study of ADS-B data evaluation. Chin. J. Aeronaut. 2011, 24, 461–466. [Google Scholar] [CrossRef] [Green Version]
- Svanberg, M.; Santén, V.; Hörteborn, A.; Holm, H.; Finnsgård, C. AIS in maritime research. Mar. Policy. 2019, 106, 103520. [Google Scholar] [CrossRef]
- Gong, L.; Liu, X.; Wu, L.; Liu, Y. Inferring trip purposes and uncovering travel patterns from taxi trajectory data. Cartogr. Geogr. Inf. Sci. 2016, 43, 103–114. [Google Scholar] [CrossRef]
- Zhao, L.; Shi, G. A Novel Similarity Measure for Clustering Vessel Trajectories Based on Dynamic Time Warping. J. Navig. 2019, 72, 290–306. [Google Scholar] [CrossRef]
- Xiao, X. Research on Vehicle Sparse Trajectory Similarity in City Traffic. Master’s Thesis, Fudan University, Shanghai, China, 2014. [Google Scholar]
- Hu, Z. Research on Ship Anomaly Behavior Identification Based on Trajectory Clustering. Master’s Thesis, Jimei University, Xiamen, China, 2017. [Google Scholar]
- Wang, J.; Wang, C.; Song, X.; Raghavan, V. Automatic intersection and traffic rule detection by mining motor-vehicle GPS trajectories. Comput. Environ. Urban Syst. 2017, 64, 19–29. [Google Scholar] [CrossRef]
- Zhang, J.; Chou, P.; Du, M. Mining method of travel characteristics based on Spatio-Temporal trajectory data. J. Transp. Syst. Eng. Inf. 2014, 14, 72–78. [Google Scholar]
- Yuan, G.; Sun, P.; Zhao, J.; Li, D.; Wang, C. A review of moving object trajectory clustering algorithms. Artif. Intell. Rev. 2017, 47, 123–144. [Google Scholar] [CrossRef]
- Elman, J.L. Finding structure in time. Cogn. Sci. 1990, 14, 179–211. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y. Research on Target Track Recognition and Prediction Based on Deep Learning. Master’s Thesis, Hefei University of Technology, Hefei, China, 2020. [Google Scholar]
- Cui, T.; Wang, G.; Gao, J. Ship trajectory classification method based on 1DCNN-LSTM. Comput. Sci. 2020, 47, 176–184. [Google Scholar]
- Kapadais, K.; Varlamis, I.; Sardianos, C.; Tserpes, K. A Framework for the Detection of Search and Rescue Patterns Using Shapelet Classification. Future Internet. 2019, 11, 192. [Google Scholar] [CrossRef] [Green Version]
- Wen, P. Research on Target Track Recognition and Clustering Based on Radar Data. Master’s Thesis, Hefei University of Technology, Hefei, China, 2020. [Google Scholar]
- Herbert, B.; Andreas, E. Tinne Tuytelaars and Luc Van Gool, Speeded-Up robust features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar]
- Lowe, D.G. Object Recognition from Local Scale-Invariant Features, In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999.
- Shlens, J. A Tutorial on Principal Component Analysis. arXiv 2014, arXiv:1404.1100. [Google Scholar]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, Y. Ship track prediction base on CNN and LSTM. Master’s Thesis, Dalian Maritime University, Dalian, China, 2020. [Google Scholar]
- Bengio, Y.; Courville, A.; Vincent, P. Representation learning: A review and new perspectives. IEEE Trans Pattern Anal Mach Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Liu, A.; Liu, G.; Li, Z.; Li, Q. Deep Representation Learning of Activity Trajectory Similarity Computation. In Proceedings of the 34th IEEE International Conference on Data Engineering, Paris, France, 16–19 April 2018. [Google Scholar]
- Wang, T.; Ye, C.; Zhou, H.; Ou, M.; Cheng, B. AIS ship trajectory clustering based on convolutional auto-encoder. In Proceedings of the SAI Intelligent Systems Conference, London, UK, 3–4 September 2020. [Google Scholar]
- Wu, H.; Huang, R.; You, L.; Xiang, L. Recent progress in taxi trajectory data mining. Acta Geod. Et Cartogr.Sin. 2019, 48, 1341–1356. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Liu, H.; Sharmat, A. An efficient CAD based design system for spatial CAM reducer. Comput.-Aided Des. Appl. 2022, 19, 134–143. [Google Scholar] [CrossRef]
- Faloutsos, C.; Ranganathan, M.; Manolopoulos, Y. Fast subsequence matching in time-series databases. Acm Sigmod Rec. 1994, 23, 419–429. [Google Scholar] [CrossRef] [Green Version]
- MacQueen, J. Some methods for classification and analysis of multivariate observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability 1967, Oakland, CA, USA, 7 January 1967; pp. 281–297. [Google Scholar]
- Zeng, W.; Xu, Z.; Cai, Z.; Chu, X.; Lu, X. Aircraft Trajectory Clustering in Terminal Airspace Based on Deep Autoencoder and Gaussian Mixture Model. Aerospace 2021, 8, 266. [Google Scholar] [CrossRef]
- Berndt, D.J.; Clifford, J. Using dynamic time warping to find patterns in time-series. In Proceedings of the 3rd International Conference on Knowledge Discovery and Data Mining, Seattle, WA, USA, 31 July–1 August 1994. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Description |
|---|---|
| the i-th trajectory in the trajectory dataset | |
| the k-th point in the i-th trajectory | |
| the number of trajectory feature points | |
| the number of match feature points | |
| the similarity of trajectories calculated by SURF method | |
| the distance between the i-th and the j-th trajectory | |
| the number of track categories | |
| the number of matching samples trajectories | |
| the trajectory shape feature vector | |
| the final generated feature vector |
| Clustering Features | Purity | KL Divergence |
|---|---|---|
| Temporal Features | 0.73 | 0.22 |
| Spatial Shape Features | 0.87 | 0.05 |
| Feature Stitching | 0.89 | 0.06 |
| Feature Fusion | 0.93 | 0.06 |
| Data | Clustering Algorithm | Purity | KL Divergence |
|---|---|---|---|
| ADS-B | SURF | 0.729 | 0.160 |
| Temporal Autoencoder | 0.718 | 0.168 | |
| Our Algorithm | 0.882 | 0.044 | |
| DTW | 0.702 | 0.219 | |
| MFA Autoencoder | 0.790 | 0.154 | |
| GeoLife | SURF | 0.719 | 0.129 |
| Temporal Autoencoder | 0.744 | 0.149 | |
| Our Algorithm | 0.884 | 0.052 | |
| DTW | 0.791 | 0.158 | |
| MFA Autoencoder | 0.836 | 0.068 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, X.; Li, Q.; Wang, R.; Chen, K. A Spatio-Temporal Feature Trajectory Clustering Algorithm Based on Deep Learning. Electronics 2022, 11, 2283. https://doi.org/10.3390/electronics11152283
He X, Li Q, Wang R, Chen K. A Spatio-Temporal Feature Trajectory Clustering Algorithm Based on Deep Learning. Electronics. 2022; 11(15):2283. https://doi.org/10.3390/electronics11152283
Chicago/Turabian StyleHe, Xintai, Qing Li, Runze Wang, and Kun Chen. 2022. "A Spatio-Temporal Feature Trajectory Clustering Algorithm Based on Deep Learning" Electronics 11, no. 15: 2283. https://doi.org/10.3390/electronics11152283