
Defending Adversarial Attacks against DNN Image Classification Models by a Noise-Fusion Method

Abstract
:1. Introduction
2. Method
2.1. Adversarial Attack Methods
| Algorithm 1 Adding Noise |
| Input Output Training phase: 1: Repeat 2: (1) 3: (2) Calculate losses and noise gradients. 4: (3) Update network parameters. 5: until training finishes Defensive phase: 1: Fusion of adversarial sample data with noise. 2: Added it and the image data to the neural network. 3: 4: 5: Update p 6: Predict |
2.2. Defense Algorithms
2.3. Datasets and Related Models
3. Results
3.1. Results on the MINST
- (1)
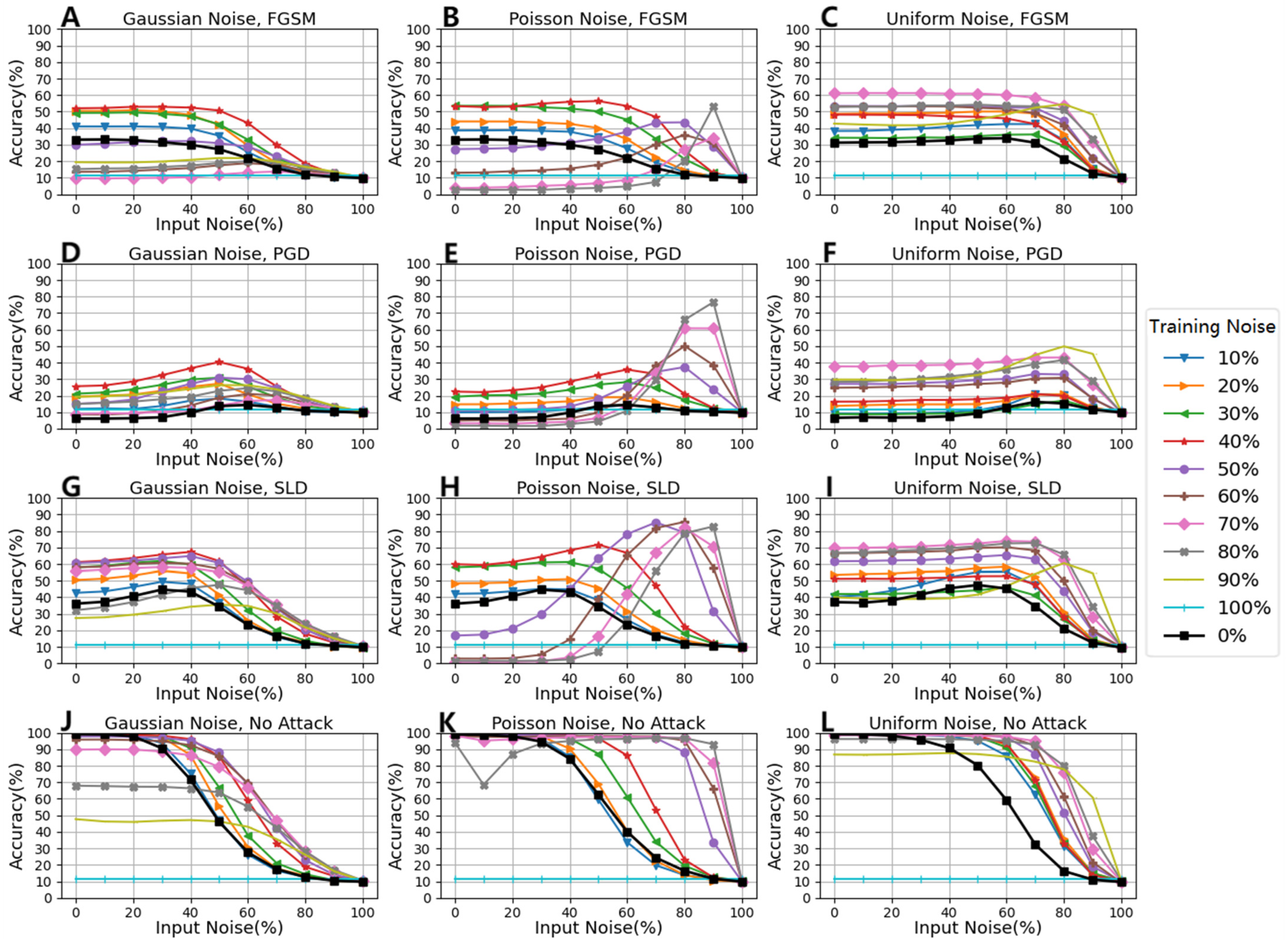
- The accuracy values dropped from over 95% to about 30% under the condition of the FGSM attack without defense, while the accuracy of the model improved to 60% with the NFM defense. Among them, the defense effect of the NFM under the condition of Uniform noise was the best (see Figure 2A–C,J);
- (2)
- The accuracy values dropped from over 95% to below 10% under the condition of the PCD attack without defense, while the accuracy of the model improved to 80% with the NFM defense. Among them, the defense effect of the NFM under the condition of Poisson noise was the best (see Figure 2D–F,K);
- (3)
- The accuracy values dropped from over 95% to below 40% under the condition of the SLD attack without defense, while the accuracy of the model improved to over 80% with the NFM defense. Among them, the defense effect of the NFM under the condition of Poisson noise was the best (see Figure 2G–I,L).
- (1)
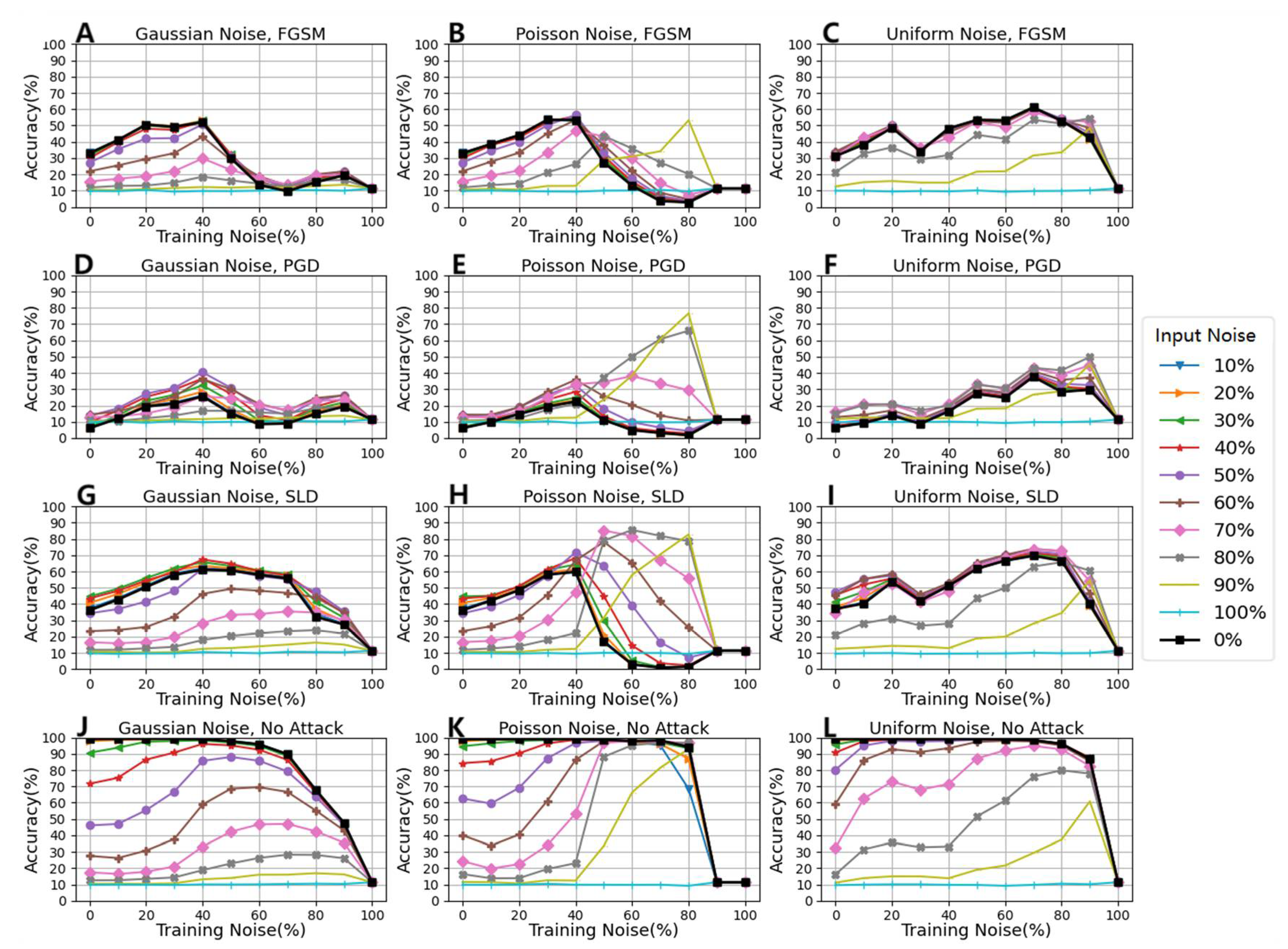
- In the NFM under Gaussian noise conditions, when the input noise amplitude varied from 0% to 40%, the model accuracy was improved in all attack conditions. The NFM under Poisson noise conditions improved model accuracy in all attack conditions with input noise amplitudes from 0% to 80%. In the NFM under Uniform noise conditions, when the input noise amplitude was 60% to 80%, the model accuracy was improved in all attack conditions (see Figure 3);
- (2)
- Under the FGSM attack condition, the model accuracy was improved when adding training noise ranging from 0% to 80% amplitude. Under the PGD attack condition, adding training noise in almost all amplitude intervals improved the model accuracy. Under the SLD attack condition, except adding 100% amplitude training noise, the model accuracy was improved in all cases (see Figure 4);
- (3)
- The NFM under Poisson noise conditions had the best defense effect against all attacks which was obtained at an 80% amplitude Poisson noise condition.
3.2. Results on the CIFAR-10
- (1)
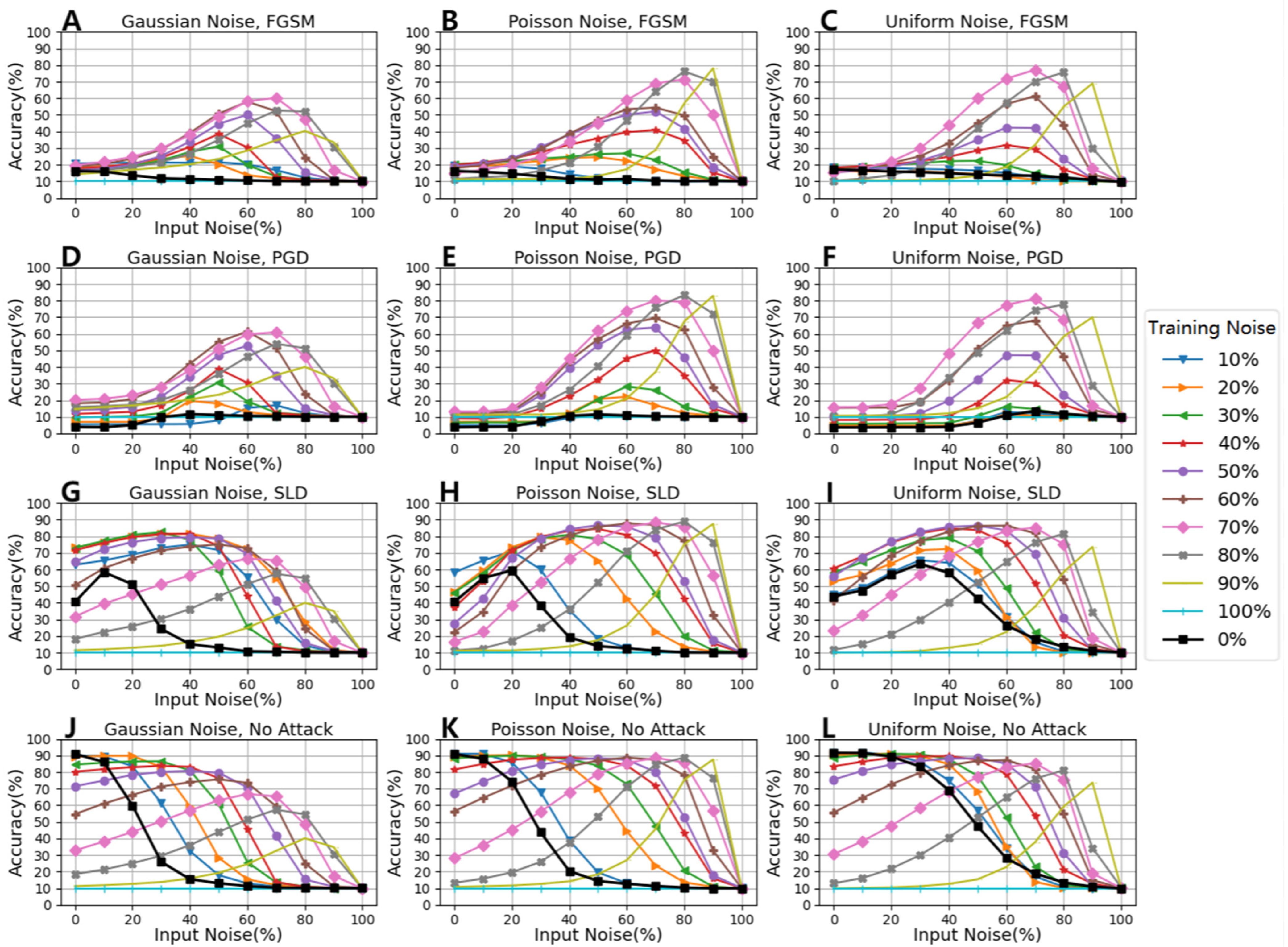
- The accuracy values dropped from over 90% to below 20% under the condition of the FGSM attack, while the accuracy of the model improved with the NFM to 80%. Among them, the defense effect of the NFM under a condition of Poisson noise and Uniform noise was the best (see Figure 5A–C,J);
- (2)
- The accuracy values dropped from over 90% to below 10% under the condition of the PGD attack, while the accuracy of the model improved to over 80% with the NFM. Among them, the defense effect of the NFM under a condition of Poisson noise and Uniform noise was the best (see Figure 5D–F,K);
- (3)
- The accuracy values dropped from over 90% to about 40% under the condition of the SLD attack, while the accuracy of the model improved to 85% with the NFM. Among them, the defense effect of the NFM under a condition of Poisson noise and Uniform noise was the best (see Figure 5G–I,L).
- (1)
- On the CIFAR-10 dataset, under the conditions of the FGSM, PGD and SLD attacks, the model accuracy tended to be the highest at a small amplitude noise;
- (2)
- Whether adding input noise or training noise, the model accuracy was significantly improved compared to without adding noise.
3.3. Comparison Adversarial Training and the NFM
4. Discussion
4.1. Adversarial Defense Effects
4.2. Accuracy
4.3. Robustness
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Biggio, B.; Corona, I.; Maiorca, D.; Nelson, B.; Šrndić, N.; Laskov, P.; Roli, F. Evasion attacks against machine learning at test time. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases; Springer: Berlin/Heidelberg, Germany, 2013; pp. 387–402. [Google Scholar]
- Dalvi, N.; Domingos, P.; Sanghai, S.; Verma, D. Adversarial classification. In Proceedings of the 10th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 22–25 August 2004; pp. 99–108. [Google Scholar]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv 2013, arXiv:1312.6199. [Google Scholar]
- Papernot, N.; McDaniel, P.; Jha, S.; Fredrikson, M.; Celik, Z.B.; Swami, A. The limitations of deep learning in adversarial settings. In Proceedings of the 2016 IEEE European Symposium on Security and Privacy (EuroS&P), Saarbrücken, Germany, 21–24 March 2016; pp. 372–387. [Google Scholar]
- Schönherr, L.; Kohls, K.; Zeiler, S.; Holz, T.; Kolossa, D. Adversarial attacks against automatic speech recognition systems via psychoacoustic hiding. arXiv 2018, arXiv:1808.05665. [Google Scholar]
- Carlini, N.; Mishra, P.; Vaidya, T.; Zhang, Y.; Sherr, M.; Shields, C.; Zhou, W. Hidden voice commands. In Proceedings of the 25th USENIX security symposium (USENIX security 16), Vancouver, BC, Canada, 16–18 August 2017; pp. 513–530. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards deep learning models resistant to adversarial attacks. arXiv 2017, arXiv:1706.06083. [Google Scholar]
- Tramer, F.; Boneh, D. Adversarial training and robustness for multiple perturbations. In Proceedings of the Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; p. 32. [Google Scholar]
- Carlini, N.; Wagner, D. Towards evaluating the robustness of neural networks. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (sp), San Jose, CA, USA, 25 May 2017; pp. 39–57. [Google Scholar]
- Moosavi-Dezfooli, S.M.; Fawzi, A.; Frossard, P. Deepfool: A simple and accurate method to fool deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2574–2582. [Google Scholar]
- Xiao, C.; Li, B.; Zhu, J.Y.; He, W.; Liu, M.; Song, D. Generating adversarial examples with adversarial networks. arXiv 2018, arXiv:1801.02610. [Google Scholar]
- Papernot, N.; McDaniel, P.; Goodfellow, I.; Jha, S.; Celik, Z.B.; Swami, A. Practical black-box attacks against deep learning systems used adversarial examples. arXiv 2016, arXiv:1602.02697. [Google Scholar]
- Su, J.; Vargas, D.V.; Sakurai, K. One pixel attack for fooling deep neural networks. IEEE Trans. Evol. Comput. 2017, 23, 828–841. [Google Scholar] [CrossRef] [Green Version]
- Papernot, N.; McDaniel, P.; Wu, X.; Jha, S.; Swami, A. Distillation as a defense to adversarial perturbations against deep neural networks. In Proceedings of the 2016 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2016; pp. 582–597. [Google Scholar]
- Zheng, S.; Song, Y.; Leung, T.; Goodfellow, I. Improving the robustness of deep neural networks via stability training. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 4480–4488. [Google Scholar]
- Buckman, J.; Roy, A.; Raffel, C.; Goodfellow, I. Thermometer encoding: One hot way to resist adversarial examples. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Das, N.; Shanbhogue, M.; Chen, S.T.; Hohman, F.; Li, S.; Chen, L.; Chau, D.H. Shield: Fast, practical defense and vaccination for deep learning used jpeg compression. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 196–204. [Google Scholar]
- Prakash, A.; Moran, N.; Garber, S.; DiLillo, A.; Storer, J. Deflecting adversarial attacks with pixel deflection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8571–8580. [Google Scholar]
- Gupta, P.; Rahtu, E. Ciidefence: Defeating adversarial attacks by fusing class-specific image inpainting and image denoising. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6708–6717. [Google Scholar]
- Chen, K.C.; Chen, P.Y.; Yu, C.M. Poster: REMIX: Mitigating Adversarial Perturbation by Reforming, Masking and Inpainting. In Proceedings of the IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 20–24 May 2018. [Google Scholar]
- Bhagoji, A.N.; Cullina, D.; Sitawarin, C.; Mittal, P. Enhancing robustness of machine learning systems via data transformations. In Proceedings of the 52nd Annual Conference on Information Sciences and Systems (CISS), Princeton, NJ, USA, 21–23 March 2018; pp. 1–5. [Google Scholar]
- Osadchy, M.; Hernandez-Castro, J.; Gibson, S.; Dunkelman, O.; Pérez-Cabo, D. No bot expects the DeepCAPTCHA! Introducing immutable adversarial examples, with applications to CAPTCHA generation. IEEE Trans. Inf. Forensics Secur. 2017, 12, 2640–2653. [Google Scholar] [CrossRef] [Green Version]
- Zuo, F.; Zeng, Q. Exploiting the sensitivity of L2 adversarial examples to erase-and-restore. In Proceedings of the 2021 ACM Asia Conference on Computer and Communications Security, Nagasaki, Japan, 30 May–2 June 2021; pp. 40–51. [Google Scholar]
- Tian, S.; Yang, G.; Cai, Y. Detecting adversarial examples through image transformation. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Li, X.; Li, F. Adversarial examples detection in deep networks with convolutional filter statistics. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5764–5772. [Google Scholar]
- He, Z.; Rakin, A.S.; Fan, D. Parametric noise injection: Trainable randomness to improve deep neural network robustness against adversarial attack. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 588–597. [Google Scholar]
- You, Z.; Ye, J.; Li, K.; Xu, Z.; Wang, P. Adversarial noise layer: Regularize neural network by adding noise. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 909–913. [Google Scholar]
- Liu, A.; Liu, X.; Yu, H.; Zhang, C.; Liu, Q.; Tao, D. Training robust deep neural networks via adversarial noise propagation. IEEE Trans. Image Processing 2021, 30, 5769–5781. [Google Scholar] [CrossRef]
- Meng, D.; Chen, H. Magnet: A two-pronged defense against adversarial examples. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October 2017; pp. 135–147. [Google Scholar]
- Xu, W.; Evans, D.; Qi, Y. Feature squeezing: Detecting adversarial examples in deep neural networks. arXiv 2017, arXiv:1704.01155. [Google Scholar]
- Carlini, N.; Wagner, D. Magnet and “efficient defenses against adversarial attacks” were not robust to adversarial examples. arXiv 2017, arXiv:1711.08478. [Google Scholar]
- He, W.; Wei, J.; Chen, X.; Carlini, N.; Song, D. Adversarial example defense: Ensembles of weak defenses were not strong. In Proceedings of the 11th USENIX Workshop on Offensive Technologies, Santa Clara, CA, USA, 12–13 August 2019. [Google Scholar]
- Huang, R.; Xu, B.; Schuurmans, D.; Szepesvári, C. Learning with a strong adversary. arXiv 2015, arXiv:1511.03034. [Google Scholar]
- Zantedeschi, V.; Nicolae, M.I.; Rawat, A. Efficient defenses against adversarial attacks. In Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security, Dallas, TX, USA, 3 November 2017; pp. 39–49. [Google Scholar]
- Kurakin, A.; Goodfellow, I.; Bengio, S. Adversarial machine learning at scale. arXiv 2016, arXiv:1611.01236. [Google Scholar]
- Carlini, N.; Wagner, D. Adversarial examples were not easily detected: Bypassing ten detection methods. In Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security, Dallas, TX, USA, 3 November 2017; pp. 3–14. [Google Scholar]
- Papernot, N.; Faghri, F.; Carlini, N.; Goodfellow, I.; Feinman, R.; Kurakin, A.; Xie, C.; Sharma, Y.; Brown, T.; Roy, A.; et al. Technical report on the CleverHans v4.0.0 adversarial examples library. arXiv 2016, arXiv:1610.00768. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Method | FGSM | PGD | SLD |
|---|---|---|---|---|
| MNIST | Adversarial Training | 95% | 94% | 83% |
| NFM | 61% | 77% | 86% | |
| CIFAR-10 | Adversarial Training | 47% | 46% | 74% |
| NFM | 78% | 83% | 89% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, L.; Liao, T.; He, J. Defending Adversarial Attacks against DNN Image Classification Models by a Noise-Fusion Method. Electronics 2022, 11, 1814. https://doi.org/10.3390/electronics11121814
Shi L, Liao T, He J. Defending Adversarial Attacks against DNN Image Classification Models by a Noise-Fusion Method. Electronics. 2022; 11(12):1814. https://doi.org/10.3390/electronics11121814
Chicago/Turabian StyleShi, Lin, Teyi Liao, and Jianfeng He. 2022. "Defending Adversarial Attacks against DNN Image Classification Models by a Noise-Fusion Method" Electronics 11, no. 12: 1814. https://doi.org/10.3390/electronics11121814