
Introducing the ReaLISED Dataset for Sound Event Classification

 ,
,  , , and
, , and 
Abstract
:1. Introduction
2. Description of the Database
- “abc”: the first three letters indicate the source that produces the sound. This segment can take 18 different values: ‘bea’ (beater), ‘coo’ (cooking), ‘cup’ (cupboard/wardrobe), ‘dis’ (dishwasher), ‘doo’ (door), ‘dra’ (drawer), ‘fur’ (furniture movement), ‘mic’ (microwave), ‘obj’ (object falling), ‘smo’ (smoke extractor), ‘spe’ (speech), ‘swi’ (switch), ‘tel’ (television), ‘vac’ (vacuum cleaner), ‘wal’ (walking), ‘was’ (washing machine), ‘wat’ (water tap), ‘win’ (window).
- “123”: this set of digits identifies the event among the number of events produced by the source identified with “abc”. This segment can take all the values between ‘001’ and ‘190’, which is the maximum number of events of a particular class we can find in the dataset (speech).
- “45”: this set of digits identifies the action that produces the sound. This segment can take 11 different values: ‘01’ (close), ‘02’ (open), ‘03’ (throw), ‘04’ (turn on), ‘05’ (turn off), ‘06’ (move), ‘07’ (plug), ‘08’ (unplug), ‘09’ (raise), ‘10’ (lower), and ‘00’ (there is no information about the action).
- “67”: this set of digits identifies the material the sound source is made of. This segment can take 14 different values: ’01’ (wood), ’02’ (glass), ’03’ (metal), ’04’ (plastic), ’05’ (ceramic), ’06’ (synthetic), ’07’ (cardboard), ’08’ (marble), ’09’ (floating platform), ’10’ (platelet), ’11’ (wicker), ’12’ (carpet), ’13’ (medium-density fibreboard MDF), and ’00’ (there is no information about the material).
- “8”: the last digit gives approximate information about the intensity of the recorded sound. It can take 4 different values: ’1’ (low intensity), ’2’ (medium intensity), ’3’ (high intensity), ’0’ (there is no information about the intensity).
- “doo_040_02_00_3.flac” is the name of the 40th file in the “door” class, described as “opening a door of unknown material with high intensity”.
- “fur_058_06_01_2.flac” is the name of the 58th file in the “furniture movement” class, described as “moving a wooden furniture with medium intensity”.
- “vac_001_00_00_0.flac” is the name of the 1st audio file in the “vacuum cleaner” class, described as “using the vacuum cleaner, without information about the action, neither the material or the intensity”.
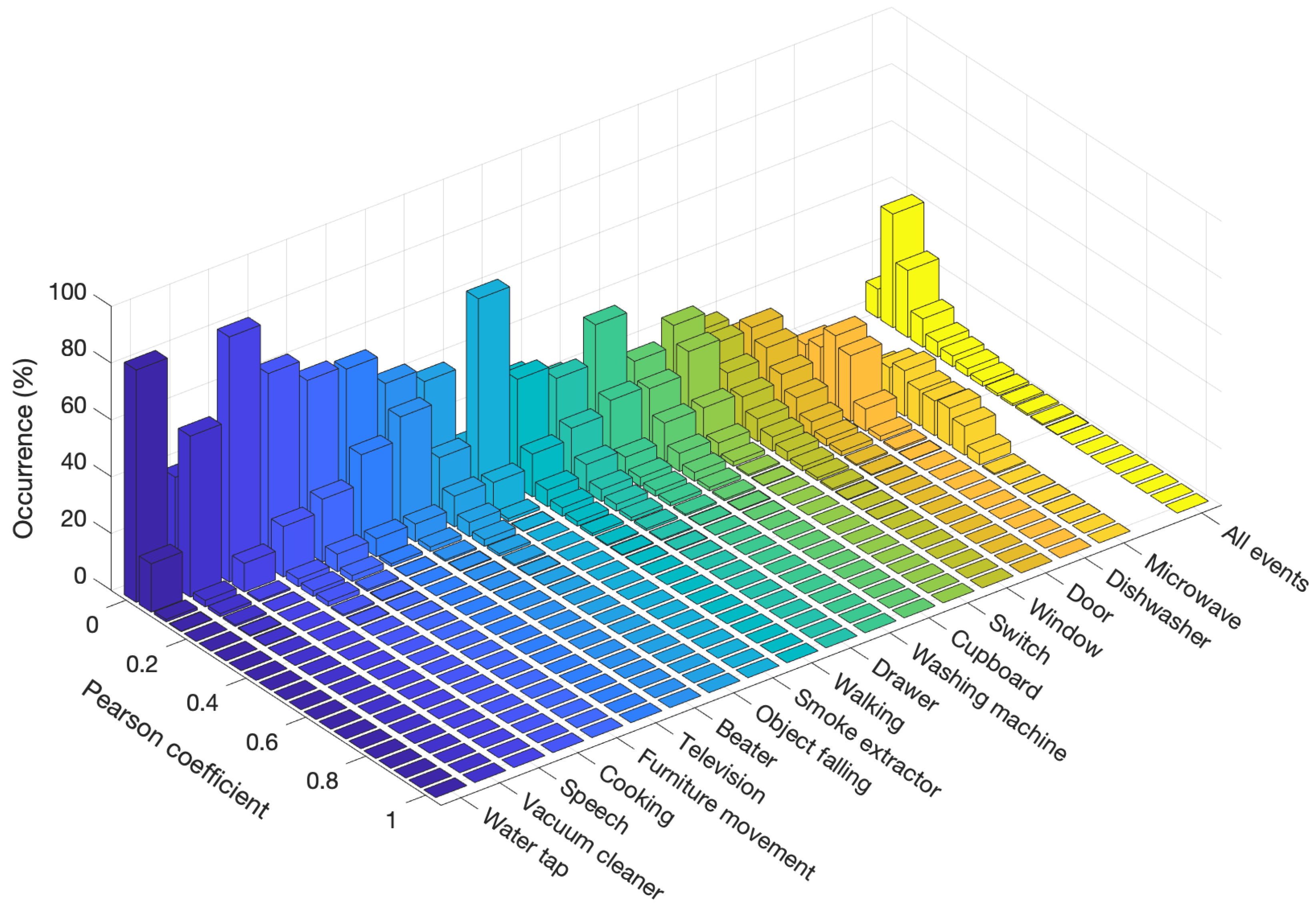
3. Intraclass Similarity
4. Interclass Similarity
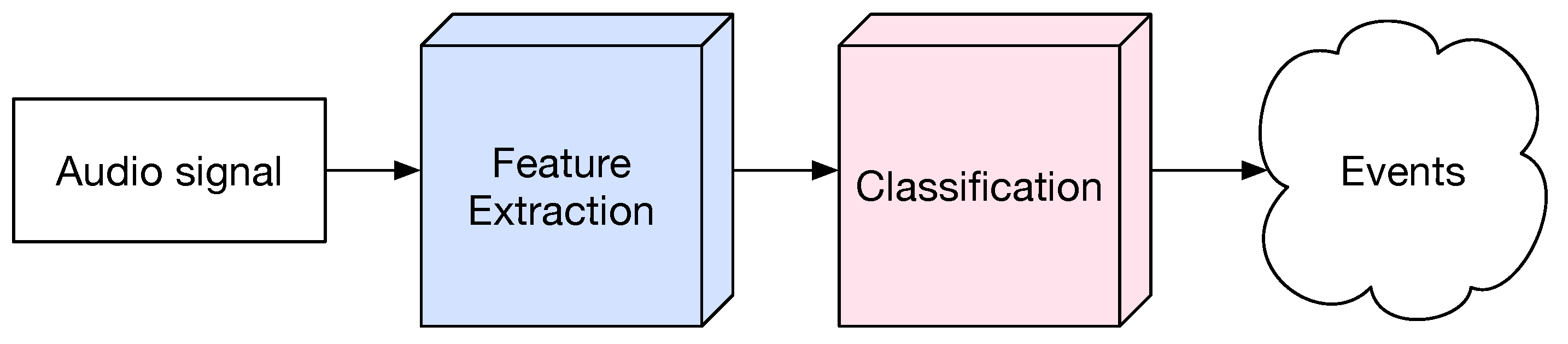
4.1. Feature Extraction
4.2. Classification Stage
- Least Squares Linear Classifier (LSLC), where the values of the weights of the linear combinations are those that minimize the Mean Squared Error (MSE) obtaining the Wiener-Hopf equations [37].
- Least Squares Quadratic Classifier (LSQC). This classifier linearly combines first and second degree combinations of the input data, generally obtaining better results than the LSLC without greatly increasing the computational complexity [38].
- k-Nearest Neighbors (kNN). This classifier measures the distance of the input vector x to k vectors representing the class in question and choosing the class with the smallest average distance [39].
- Support Vector Machine (SVM) with linear kernel [40]. SVMs project the observation vector to a higher dimensional space, using a set of kernel functions. The centers of the kernel functions are chosen from the design set and are denominated “support vectors”. Once the observation vector is projected, a linear discriminant is used to determine the SVM’s output and take the decision.
- Multilayer Perceptron (MLP). It consists of three layers of nodes (one input layer, one hidden layer and one output layer). Except for the input nodes, each node is a neuron that uses a nonlinear activation function. The most common type of neuron is McCulloch–Pitts neuron [41], which consists of a weighted sum of the inputs, followed by the application of a non-linear function (sigmoidal function or hyperbolic tangent, commonly). In this work, MLPs were trained with the Scaled Conjugate Gradient training function, a fast supervised learning algorithm [42].
- Deep Neural Networks (DNN). It consists of at least four layers of nodes (one input layer, two or more hidden layers and one output layer). This type of classifier is an extension of the MLP included within deep learning techniques.
4.3. Validation Stage
4.4. Evaluation Metrics
- ACC is calculated using the number of True Positives (TP), True Negatives (TN), False Positives (FP) and False Negatives (FN):
- P and R are defined as follows:
5. Experiments and Results
5.1. Results of Intraclass Similarity Analysis
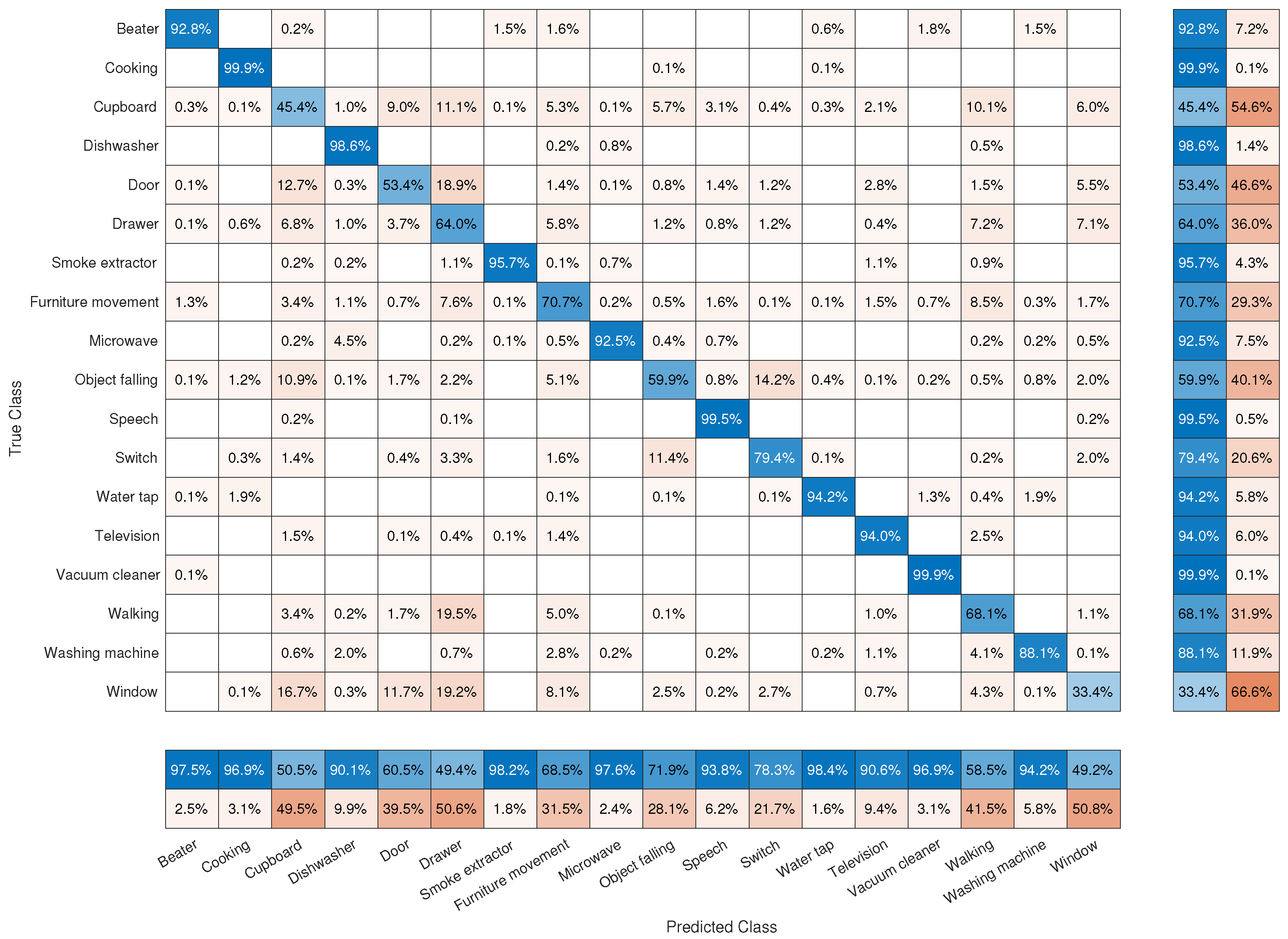
5.2. Results of Interclass Similarity Analysis
5.2.1. Interclass Analysis with the Whole Set of Classes
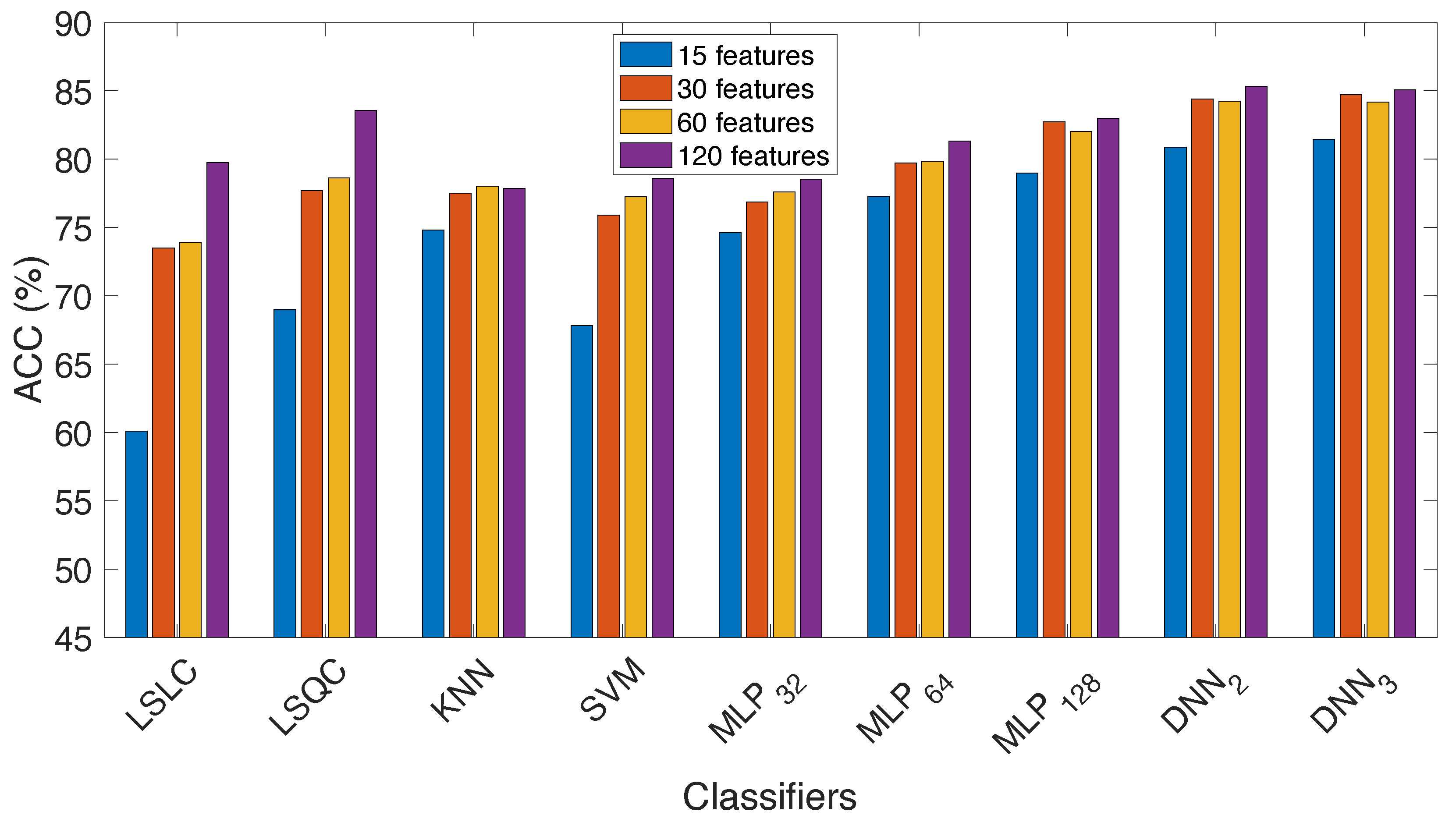
- In Figure 4, the ACC is represented according to the classifiers used and the number of features selected. It is observed that the more features used, the better results are obtained for all classifiers. The best results are obtained when combining the three sets of MFCCs (120 features). When the sets are tested separately, the number of MFCCs that gets the best results is 20 in most cases (60 features), followed closely by 15 MFCCs (45 features). The classifiers most sensitive to the number of features are LSLC, LSQC and SVM, while the performance of the rest of them is not as dependent on the number of features. Regarding the classifiers applied, the best results are obtained when using the DNN with two hidden layers (DNN2) and the LSQC.

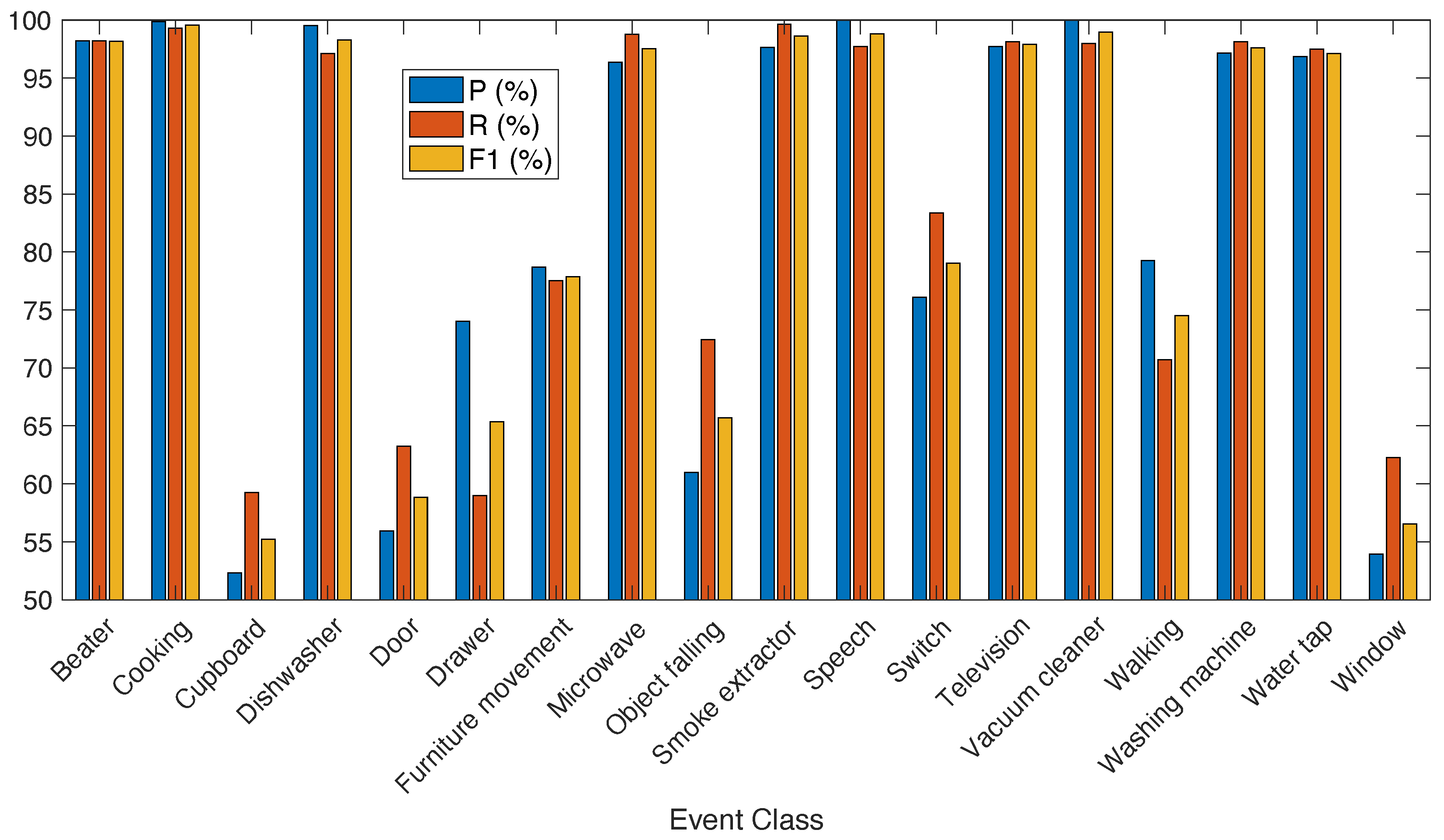
- The results of ACC, P, R and F1, obtained with the whole set of event classes using the complete set of features (120) are presented in Table 2. The best results are obtained using the DNN2, getting 85.33% of ACC and 84.44% of F1. If we focus on machine learning based classifiers, the best results are provided by the LSQC, which gets 83.58% of ACC and 82.12% of F1. These results also indicate that the problem of SEC with this database can only be solved satisfactorily if the number of free parameters in the classifier is high. Therefore, the performance with simpler classifiers such as LSLC, kNN or SVM are worse.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classifier | ACC (%) | P (%) | R (%) | F1 (%) |
|---|---|---|---|---|
| LSLC | 79.75 | 78.25 | 78.59 | 77.69 |
| LSQC | 83.58 | 82.24 | 82.82 | 82.12 |
| kNN | 77.86 | 76.45 | 77.40 | 76.53 |
| SVM | 78.62 | 77.54 | 76.72 | 76.55 |
| MLP32 | 78.55 | 76.67 | 77.96 | 76.55 |
| MLP64 | 81.34 | 79.65 | 80.88 | 79.79 |
| MLP128 | 83.01 | 81.53 | 82.86 | 81.74 |
| DNN2 | 85.33 | 84.15 | 85.02 | 84.44 |
| DNN3 | 85.09 | 83.86 | 84.73 | 84.17 |
5.2.2. Interclass Analysis by Grouping the Classes
- Group 1: Impulsive sound events, is composed of six different classes: cupboard/wardrobe, door, drawer, object falling, switch, and window. In Table 3, the event class, the number of files and their lengths are shown.
- Group 2: Non-impulsive sound events encompasses six different events: furniture movement, speech, television, vacuum cleaner, walking, and water tap. Table 4 shows the classes, the number of files in each class, and their lengths.
- Group 3: Appliances includes six classes of sound events produced typically in the kitchen by different household appliances and by a person which is cooking (e.g., frying, roasting): beater, cooking, dishwasher, microwave, smoker extractor, and washing machine. Table 5 shows the classes, the number of files in each class, and their lengths.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| ACC | Accuracy |
| dBSPL | Decibels of Sound Pressure Level |
| DCT | Discrete Cosine Transform |
| DFT | Discrete Fourier Transform |
| DNN | Deep Neural Networks |
| FN | False Negatives |
| FP | False Positives |
| kNN | k-Nearest Neighbors |
| LSLC | Least Squares Linear Classifier |
| LSQC | Least Squares Quadratic Classifier |
| MFCCs | Mel-Frequency Cepstral Coefficients |
| ΔMFCCs | Delta Mel-Frequency Cepstral Coefficients |
| MLP | Multilayer Perceptron |
| MSE | Mean Squared Error |
| P | Precision |
| PCM | Pulse-Code Modulation |
| R | Recall |
| ReaLISED | Real-Life Indoor Sound Event Dataset |
| SEC | Sound Event Classification |
| SED | Sound Event Detection |
| SVM | Support Vector Machines |
| TN | True Negatives |
| TP | True Positives |
References
- Ambika, N. Secure and Reliable Knowledge-Based Intrusion Detection Using Mobile Base Stations in Smart Environments. In Encyclopedia of Information Science and Technology, 4th ed.; IGI Global: Hershey, PA, USA, 2021; pp. 500–513. [Google Scholar]
- Dong, L.J.; Tang, Z.; Li, X.B.; Chen, Y.C.; Xue, J.C. Discrimination of mining microseismic events and blasts using convolutional neural networks and original waveform. J. Cent. South Univ. 2020, 27, 3078–3089. [Google Scholar] [CrossRef]
- Peng, K.; Tang, Z.; Dong, L.; Sun, D. Machine Learning Based Identification of Microseismic Signals Using Characteristic Parameters. Sensors 2021, 21, 6967. [Google Scholar] [CrossRef]
- Hou, Y.; Li, Q.; Zhang, C.; Lu, G.; Ye, Z.; Chen, Y.; Wang, L.; Cao, D. The state-of-the-art review on applications of intrusive sensing, image processing techniques, and machine learning methods in pavement monitoring and analysis. Engineering 2021, 7, 845–856. [Google Scholar] [CrossRef]
- Kwon, S. Att-Net: Enhanced emotion recognition system using lightweight self-attention module. Appl. Soft Comput. 2021, 102, 107101. [Google Scholar]
- Kwon, S. MLT-DNet: Speech emotion recognition using 1D dilated CNN based on multi-learning trick approach. Expert Syst. Appl. 2021, 167, 114177. [Google Scholar]
- Zhu-Zhou, F.; Gil-Pita, R.; García-Gómez, J.; Rosa-Zurera, M. Robust Multi-Scenario Speech-Based Emotion Recognition System. Sensors 2022, 22, 2343. [Google Scholar] [CrossRef]
- Adavanne, S.; Fayek, H.; Tourbabin, V. Sound event classification and detection with weakly labeled data. In Proceedings of the Detection and Classification of Acoustic Scenes and Events 2019 Workshop (DCASE2019), New York, NY, USA, 25–26 October 2019. [Google Scholar]
- Vacher, M.; Portet, F.; Fleury, A.; Noury, N. Development of audio sensing technology for ambient assisted living: Applications and challenges. Int. J. E-Health Med. Commun. 2011, 2, 35–54. [Google Scholar] [CrossRef]
- Rouas, J.L.; Louradour, J.; Ambellouis, S. Audio events detection in public transport vehicle. In Proceedings of the 2006 IEEE Intelligent Transportation Systems Conference, Toronto, ON, Canada, 17–20 September 2006; pp. 733–738. [Google Scholar]
- Clavel, C.; Ehrette, T.; Richard, G. Events detection for an audio-based surveillance system. In Proceedings of the 2005 IEEE International Conference on Multimedia and Expo, Amsterdam, The Netherlands, 6 July 2005; pp. 1306–1309. [Google Scholar]
- DCASE2022 Challenge. Challenge on Detection and Classification of Acoustic Scenes and Events. Available online: https://dcase.community/challenge2022/ (accessed on 27 May 2022).
- Diment, A. Sound event detection for office live and office synthetic AASP challenge. In Proceedings of the IEEE AASP Challenge on Detection and Classification of Acoustic Scenes and Events, New Paltz, NY, USA, 20–23 October 2013. [Google Scholar]
- Mesaros, A.; Heittola, T.; Virtanen, T. TUT database for acoustic scene classification and sound event detection. In Proceedings of the 2016 24th European Signal Processing Conference (EUSIPCO), Budapest, Hungary, 29 August–2 September 2016; pp. 1128–1132. [Google Scholar] [CrossRef]
- Adavanne, S.; Pertilä, P.; Virtanen, T. Sound event detection using spatial features and convolutional recurrent neural network. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 771–775. [Google Scholar]
- Adavanne, S.; Politis, A.; Virtanen, T. A multi-room reverberant dataset for sound event localization and detection. arXiv 2019, arXiv:1905.08546. [Google Scholar]
- Foggia, P.; Petkov, N.; Saggese, A.; Strisciuglio, N.; Vento, M. Reliable detection of audio events in highly noisy environments. Pattern Recognit. Lett. 2015, 65, 22–28. [Google Scholar] [CrossRef]
- Ciaburro, G.; Iannace, G. Improving Smart Cities Safety Using Sound Events Detection Based on Deep Neural Network Algorithm. Informatics 2020, 7, 23. [Google Scholar] [CrossRef]
- Gemmeke, J.F.; Ellis, D.P.W.; Freedman, D.; Jansen, A.; Lawrence, W.; Moore, R.C.; Plakal, M.; Ritter, M. Audio Set: An ontology and human-labeled dataset for audio events. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 776–780. [Google Scholar] [CrossRef]
- Yiu, C. The big data opportunity. Policy Exch. 2012, 1, 36. [Google Scholar]
- Fonseca, E.; Favory, X.; Pons, J.; Font, F.; Serra, X. FSD50K: An Open Dataset of Human-Labeled Sound Events. arXiv 2020, arXiv:2010.00475. [Google Scholar] [CrossRef]
- Yadav, S.; Foster, M.E. GISE-51: A scalable isolated sound events dataset. arXiv 2021, arXiv:2103.12306. [Google Scholar]
- Cartwright, M.; Mendez, A.E.M.; Cramer, J.; Lostanlen, V.; Dove, G.; Wu, H.H.; Salamon, J.; Nov, O.; Bello, J. SONYC Urban Sound Tagging (SONYC-UST): A multilabel dataset from an urban acoustic sensor network. In Proceedings of the Detection and Classification of Acoustic Scenes and Events 2019 Workshop (DCASE2019), New York, NY, USA, 25–26 October 2019. [Google Scholar]
- Purohit, H.; Tanabe, R.; Ichige, K.; Endo, T.; Nikaido, Y.; Suefusa, K.; Kawaguchi, Y. MIMII Dataset: Sound Dataset for Malfunctioning Industrial Machine Investigation and Inspection. arXiv 2019, arXiv:1909.09347. [Google Scholar]
- Koizumi, Y.; Saito, S.; Uematsu, H.; Harada, N.; Imoto, K. ToyADMOS: A Dataset of Miniature-Machine Operating Sounds for Anomalous Sound Detection. In Proceedings of the 2019 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), New Paltz, NY, USA, 20–23 October 2019; pp. 313–317. [Google Scholar] [CrossRef] [Green Version]
- Nakamura, S.; Hiyane, K.; Asano, F.; Nishiura, T.; Yamada, T. Acoustical sound database in real environments for sound scene understanding and hands-free speech recognition. In Proceedings of the 2nd International Conference on Language Resources and Evaluation, Athens, Greece, 31 May–2 June 2000. [Google Scholar]
- Turpault, N.; Wisdom, S.; Erdogan, H.; Hershey, J.; Serizel, R.; Fonseca, E.; Seetharaman, P.; Salamon, J. Improving Sound Event Detection In Domestic Environments Using Sound Separation. arXiv 2020, arXiv:2007.03932. [Google Scholar]
- Foster, P.; Sigtia, S.; Krstulovic, S.; Barker, J.; Plumbley, M.D. Chime-home: A dataset for sound source recognition in a domestic environment. In Proceedings of the 2015 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), New Paltz, NY, USA, 18–21 October 2015; pp. 1–5. [Google Scholar]
- Brousmiche, M.; Rouat, J.; Dupont, S. SECL-UMons Database for Sound Event Classification and Localization. In Proceedings of the ICASSP 2020–2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 756–760. [Google Scholar]
- Olympus. Multi-Track Linear PCM Recorder LS-100 User’s Manual; Olympus: Tokyo, Japan, 2012. [Google Scholar]
- Pedersen, T. Audibility of impulsive sounds in environmental noise. In Proceedings of the 29th International Congress on Noise Control Engineering, Nice, France, 27–28 August 2000; pp. 4158–4164. [Google Scholar]
- Mohino-Herranz, I.; Garcia-Gomez, J.; Aguilar-Ortega, M.; Utrilla-Manso, M.; Gil-Pita, R.; Rosa-Zurera, M. Real-Life Indoor Sound Event Dataset (ReaLISED) for Sound Event Classification (SEC). Available online: https://zenodo.org/record/6488321 (accessed on 5 June 2022).
- Rosli, M.M.; Tempero, E.; Luxton-Reilly, A. Evaluating the quality of datasets in software engineering. Adv. Sci. Lett. 2018, 24, 7232–7239. [Google Scholar] [CrossRef]
- Lee Rodgers, J.; Nicewander, W.A. Thirteen ways to look at the correlation coefficient. Am. Stat. 1988, 42, 59–66. [Google Scholar] [CrossRef]
- Davis, S.; Mermelstein, P. Comparison of parametric representations for monosyllabic word recognition in continuously spoken sentences. IEEE Trans. Acoust. Speech Signal Process. 1980, 28, 357–366. [Google Scholar] [CrossRef] [Green Version]
- Mohino-Herranz, I.; Gil-Pita, R.; Alonso-Diaz, S.; Rosa-Zurera, M. Synthetical enlargement of mfcc based training sets for emotion recognition. Int. J. Comput. Sci. Inf. Technol. 2014, 6, 249–259. [Google Scholar]
- Van Trees, H.L. Detection, Estimation and Modulation, Part I; Wiley Press: New York, NY, USA, 1968. [Google Scholar]
- Gil-Pita, R.; Alvarez-Perez, L.; Mohino, I. Evolutionary diagonal quadratic discriminant for speech separation in binaural hearing aids. Adv. Comput. Sci. 2012, 20, 227–232. [Google Scholar]
- Kataria, A.; Singh, M.D. A review of data classification using k-nearest neighbour algorithm. Int. J. Emerg. Technol. Adv. Eng. 2013, 3, 354–360. [Google Scholar]
- Vapnik, V.N.; Vapnik, V. Statistical Learning Theory; Wiley: New York, NY, USA, 1998; Volume 1. [Google Scholar]
- McCulloch, W.S.; Pitts, W. A logical calculus of the ideas immanent in nervous activity. Bull. Math. Biophys. 1943, 5, 115–133. [Google Scholar] [CrossRef]
- Møller, M.F. A scaled conjugate gradient algorithm for fast supervised learning. Neural Netw. 1993, 6, 525–533. [Google Scholar] [CrossRef]





| Event Class | Number of Audios | Average Duration (s) | Impulsive Sound (Yes/No) |
|---|---|---|---|
| Beater | 126 | 1.02 | No |
| Cooking | 176 | 1.01 | No |
| Cupboard/Wardrobe | 156 | 0.96 | Yes |
| Dishwasher | 130 | 1.01 | No |
| Door | 109 | 1.75 | Yes |
| Drawer | 158 | 1.34 | Yes |
| Furniture movement | 152 | 1.18 | No |
| Microwave | 124 | 1.03 | No |
| Object falling | 119 | 0.49 | Yes |
| Smoke extractor | 142 | 1.01 | No |
| Speech | 190 | 4.03 | No |
| Switch | 108 | 0.24 | Yes |
| Television | 143 | 2.18 | No |
| Vacuum cleaner | 166 | 1.26 | No |
| Walking | 119 | 2.67 | No |
| Washing machine | 117 | 1.01 | No |
| Water tap | 140 | 1.40 | No |
| Window | 104 | 1.74 | Yes |
| Event Class | Number of Files | Length (s) |
|---|---|---|
| Cupboard/Wardrobe | 156 | 149.52 |
| Door | 109 | 119.89 |
| Drawer | 158 | 121.47 |
| Object falling | 119 | 38.43 |
| Switch | 108 | 26.03 |
| Window | 104 | 181.21 |
| Event Class | Number of Files | Length (s) |
|---|---|---|
| Furniture movement | 152 | 178.78 |
| Speech | 190 | 764.86 |
| Television | 143 | 311.87 |
| Vacuum cleaner | 166 | 208.58 |
| Walking | 119 | 317.52 |
| Water tap | 140 | 196.25 |
| Event Class | Number of Files | Length (s) |
|---|---|---|
| Beater | 126 | 128.67 |
| Cooking | 176 | 177.85 |
| Dishwasher | 130 | 131.72 |
| Microwave | 124 | 125.64 |
| Smoke extractor | 142 | 144.10 |
| Washing Machine | 117 | 117.88 |
| Classifier | ACC (%) | P (%) | R (%) | F1 (%) |
|---|---|---|---|---|
| LSLC | 76.48 | 75.38 | 75.41 | 75.26 |
| LSQC | 75.94 | 75.22 | 75.02 | 75.03 |
| kNN | 73.44 | 72.43 | 72.50 | 72.32 |
| SVM | 73.22 | 70.96 | 71.36 | 70.51 |
| MLP32 | 76.54 | 75.12 | 75.49 | 75.17 |
| MLP64 | 76.25 | 74.96 | 74.88 | 74.78 |
| MLP128 | 76.74 | 75.59 | 75.77 | 75.56 |
| DNN2 | 76.26 | 75.02 | 75.32 | 74.97 |
| DNN3 | 77.21 | 76.07 | 76.30 | 76.09 |
| Classifier | ACC(%) | P (%) | R (%) | F1 (%) |
|---|---|---|---|---|
| LSLC | 75.08 | 74.66 | 75.61 | 75.04 |
| LSQC | 77.48 | 76.93 | 77.39 | 77.11 |
| kNN | 76.63 | 76.15 | 76.79 | 76.35 |
| SVM | 73.20 | 72.98 | 74.34 | 73.47 |
| MLP32 | 76.91 | 76.40 | 78.11 | 77.08 |
| MLP64 | 76.64 | 76.19 | 77.86 | 76.82 |
| MLP128 | 76.78 | 76.28 | 77.43 | 76.76 |
| DNN2 | 77.67 | 77.19 | 78.83 | 77.82 |
| DNN3 | 77.75 | 77.38 | 79.11 | 78.03 |
| Classifier | ACC (%) | P (%) | R (%) | F1 (%) |
|---|---|---|---|---|
| LSLC | 83.29 | 82.17 | 82.40 | 82.21 |
| LSQC | 83.66 | 82.65 | 82.92 | 82.60 |
| kNN | 79.44 | 78.02 | 78.58 | 77.93 |
| SVM | 80.83 | 79.31 | 79.56 | 79.36 |
| MLP32 | 83.55 | 82.52 | 82.86 | 82.53 |
| MLP64 | 83.64 | 82.53 | 82.78 | 82.58 |
| MLP128 | 83.80 | 82.77 | 83.17 | 82.74 |
| DNN2 | 83.64 | 82.57 | 83.00 | 82.63 |
| DNN3 | 84.34 | 83.36 | 83.67 | 83.36 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mohino-Herranz, I.; García-Gómez, J.; Aguilar-Ortega, M.; Utrilla-Manso, M.; Gil-Pita, R.; Rosa-Zurera, M. Introducing the ReaLISED Dataset for Sound Event Classification. Electronics 2022, 11, 1811. https://doi.org/10.3390/electronics11121811
Mohino-Herranz I, García-Gómez J, Aguilar-Ortega M, Utrilla-Manso M, Gil-Pita R, Rosa-Zurera M. Introducing the ReaLISED Dataset for Sound Event Classification. Electronics. 2022; 11(12):1811. https://doi.org/10.3390/electronics11121811
Chicago/Turabian StyleMohino-Herranz, Inma, Joaquín García-Gómez, Miguel Aguilar-Ortega, Manuel Utrilla-Manso, Roberto Gil-Pita, and Manuel Rosa-Zurera. 2022. "Introducing the ReaLISED Dataset for Sound Event Classification" Electronics 11, no. 12: 1811. https://doi.org/10.3390/electronics11121811