
J-CO: A Platform-Independent Framework for Managing Geo-Referenced JSON Data Sets


Abstract
:1. Introduction
2. Background and Related Work
2.1. Background of the Proposal
2.2. Related Work (on NoSQL Databases and on Query Languages for JSON Documents)
- Adaptability to heterogeneity. This feature refers to the ability of the language to manipulate heterogeneous documents with one single instruction. In fact, usually query operators have sets of documents as operands; sets of documents may contain heterogeneous documents, i.e., documents having (possibly many) different structures from each other; if the operators are able to work on documents with totally different structure with one single instruction, i.e., processing them all together, the feature called Adaptability to heterogeneity is met. In contrast, if operators deal with one single structure at a time, this feature is not met.
- Spatial operations. This feature refers to the capability of performing spatial operations on geo-tagged documents.
- Platform independence. This feature refers to the fact that the query language is independent of a specific platform, typically JSON document stores.
- Re-use of intermediate results. When complex transformations are performed, intermediate results could be precious for next processing steps. With this feature, we refer to the capability of the query language to explicitly handle and re-use intermediate results, to avoid re computations as well as to avoid storing intermediate results temporarily within JSON databases.
- Orientation to Analysts. This feature refers to the fact that operators of the query language are oriented to analysts, without specific procedural programming skills.
- Orientation to Programmers. This feature refers to the fact that operators of the query language are oriented to computer programmers, having strong computer programming skills.
3. A Framework for Manipulating Geo-Referenced Data
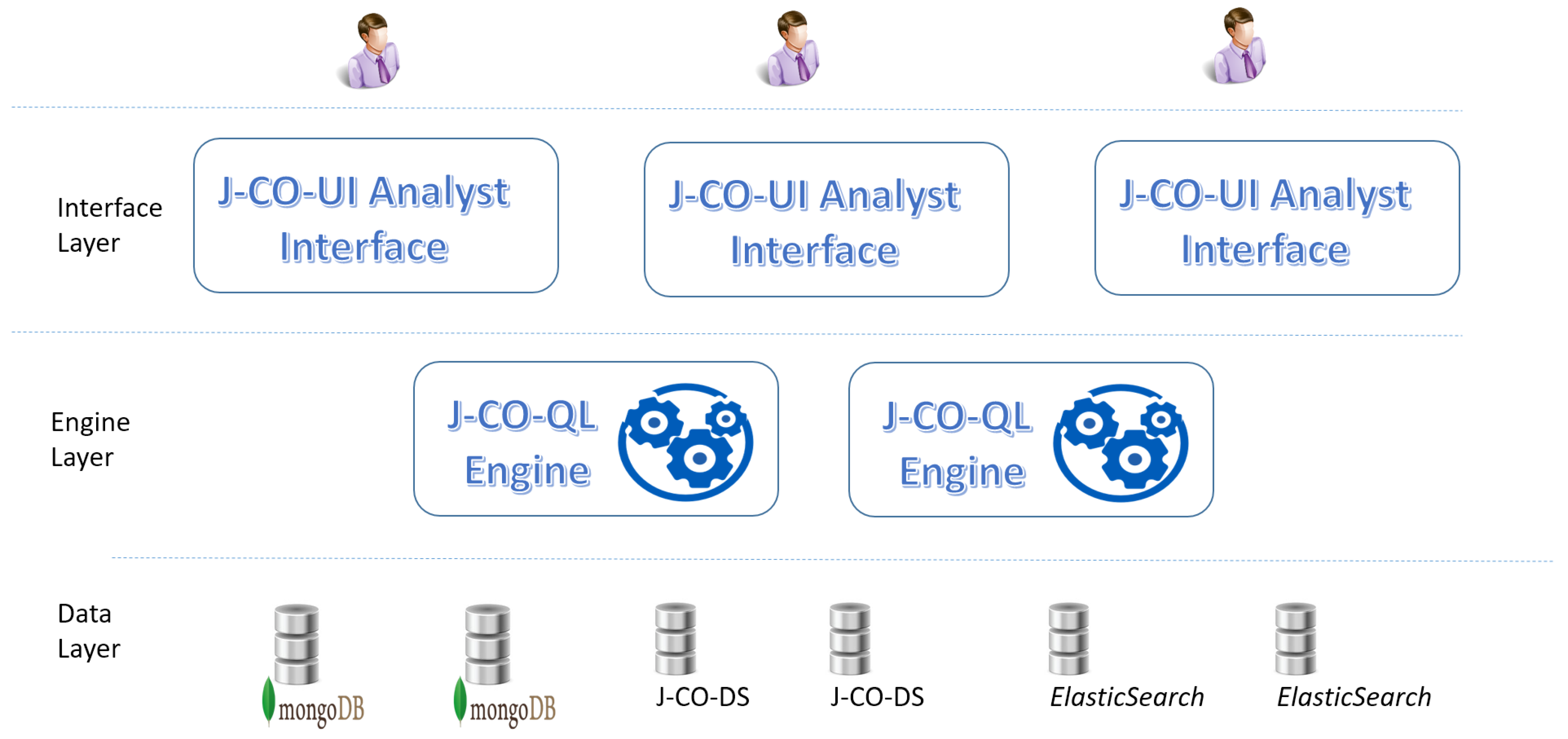
3.1. Organization of the Framework
- One or more NoSQL storage systems, powered by MongoDB, ElasticSearch [45] and, in the future, other similar systems (for example, AWS Amazon DB, https://aws.amazon.com/documentdb/, accessed on 3 March 2021).
- J-CO-DS is a simplified storage system for sets of JSON documents; since it is based on the file-system, it is able to store very large JSON documents that would not be managed by other systems, like MongoDB. It is not a DBMS, since it neither provides a query language nor supports OLTP operations.
- J-CO-QL is the query language around which the entire framework is built. The language allows for specifying complex transformations, possibly based on spatial operations.
- The J-CO-QL Engine executes J-CO-QL queries by retrieving data stored in one or many JSON storage systems.
- A User Interface, named J-CO-UI, provides users with a powerful tool to write complex queries step-by-step, by possibly inspecting temporary results of the process.
- The Data Layer includes all data stores, managed by any kind of NoSQL storage system (currently, MongoDB, ElasticSearch and J-CO-DS). Since each single data store can contain a relevant piece of information to integrate, they must be viewed in a seamless way by users: they do not have to take care of the specific storage technology.
- The Engine Layer encompasses one or many instances of the J-CO-QL Engine. Why more than one instance? Because it could be installed on several servers, in order to provide many different users, possibly located in different areas of the Earth globe, with the necessary computational power.
- The Interface Layer encompasses one or more installations of J-CO-UI: in fact, users (typically, analysts) write queries and develop transformation processes through this tool. Since J-CO-UI is a desktop application (see Section 5), its instances are installed on analysts’ PCs.
- Some JSON storage systems provide query languages, in a way similar to traditional DBMSs; however, these languages do not provide operations that are familiar to SQL users, like “joins”. An example is MongoDB, in which to perform queries equivalent to “joins” it is often necessary to write procedural JavaScript code, to overcome the limitations of its query language.
- Other JSON storage systems do not provide any query language or capability to transform stored data. ElasticSearch falls into this category: it is an engine for information retrieval, which receives and provides data in JSON format through its API. However, it is not a DBMS: when a document is received, it is indexed by means of an inverted index, that allows keyword-based searches to retrieve indexed documents. Clearly, it has not to provide a query language as intended for DBMSs, because it is not a DBMS.
- In principle, any Open Data portal could be a read-only JSON store: if we had a tool able to provide a database-like abstraction of Open Data portals, we could consider it as a valid JSON store from which data can be read for further processing. Obviously, we cannot expect any processing functionality (in terms of query language) by such sources.
- A strong concurrency model is one of the key success factors of relational DBMSs. Some JSON store systems provide strong concurrency models, like CouchDB [25,46], that, for this reason, has been chosen as the DBMS for HyperLedger Fabric [47], the well-known block-chain platform developed by Linux Foundation.
- Originally, MongoDB provided very limited concurrency control and transaction management. Now, as long as it becomes more and more adopted, new versions enrich support to transactions; consequently, it is becoming a true DBMS for JSON documents.
- Other JSON storage systems do not provide any concurrency control or support to transactions. This is the case, for instance, of ElasticSearch.
3.2. J-CO-DS
- MongoDB [6] is a true DBMS for JSON data. Its data model is the same we introduced in Definition 1: a “database” is a set of collections, where a “collection” is a set of JSON documents. Neither predefined structures nor schemas must be defined: a collection can store heterogeneous JSON documents, with no limitations. However, MongoDB is designed to manage very large collections of small documents: it does not accept JSON documents whose internal binary representation (the BSON format) is larger than 16MB. This limitation makes impossible to store large GeoJSON documents within MongoDB databases: in fact, a GeoJSON document is a single document that can be giant; in case of complex geometries, the BSON representation can easily exceed 16 MB. Consequently, MongoDB is actually unable to manage very large documents.
- On the other side, ElasticSearch [45] is a very popular tool for performing information retrieval operations. It is not designed to be a pure DBMS, but since it receives and provides JSON data sets through its API, it can be assimilated to the database view. However, it is not good to store very large GeoJSON documents into ElasticSearch, because it has to index the whole document, including geometries; this would cause a significant waste of time (during indexing) and would negatively affect results provided by ElasticSearch at retrieval time, because coordinates would be considered for text-based retrieval as text fragments, not as numbers denoting geo-tagging. ElasticSearch does not provide any query language, in the sense of database query languages: stored data cannot be manipulated as it is possible to do, e.g., within MongoDB. Obviously, its API allows for uploading, getting and deleting data sets.
- J-CO-DS Service is the true storage service that can be contacted through a TCP port, either by J-CO-QL Engine instances or by any other application wishing to exploit its services.
- J-CO-DS Manager is a user interface that allows for interactively managing the data store; it is an application that can be installed on administrator’s PC and provides two execution modes:
- –
- Stand-alone mode: in this execution mode, the application uses a text-based interface, that can be accessed through a classical text-based shell;
- –
- Web-based mode: when launched in this mode, the application provides a web-based interface, by means of an internal web server packaged in the executable file.
Through the user interface, usual basic management operations can be performed, such as database creation and deletion, collection creation and deletion and upload of JSON documents into collections. J-CO-DS does not support transactions and does not provide explicit locking mechanisms, because they are not necessary; only an implicit locking mechanism on collections, when either a read or a write operation is performed, is provided to serialize access to single collections.
3.3. J-CO-QL Engine
- Batch Mode: this mode can be used to execute complex and long queries, previously written by analysts.
- Interactive Mode: this mode can be used to write queries step-by-step, so as to build complex transformation processes, in an interactive manner.
- Long-Term Query Process: the query process lives for a long time, the process state is not lost while waiting for new instructions;
- Step-by-step Issuing: instructions are provided one at a time; if the instruction generates an error (lexical, syntactic or semantic error) simply the process state does not change;
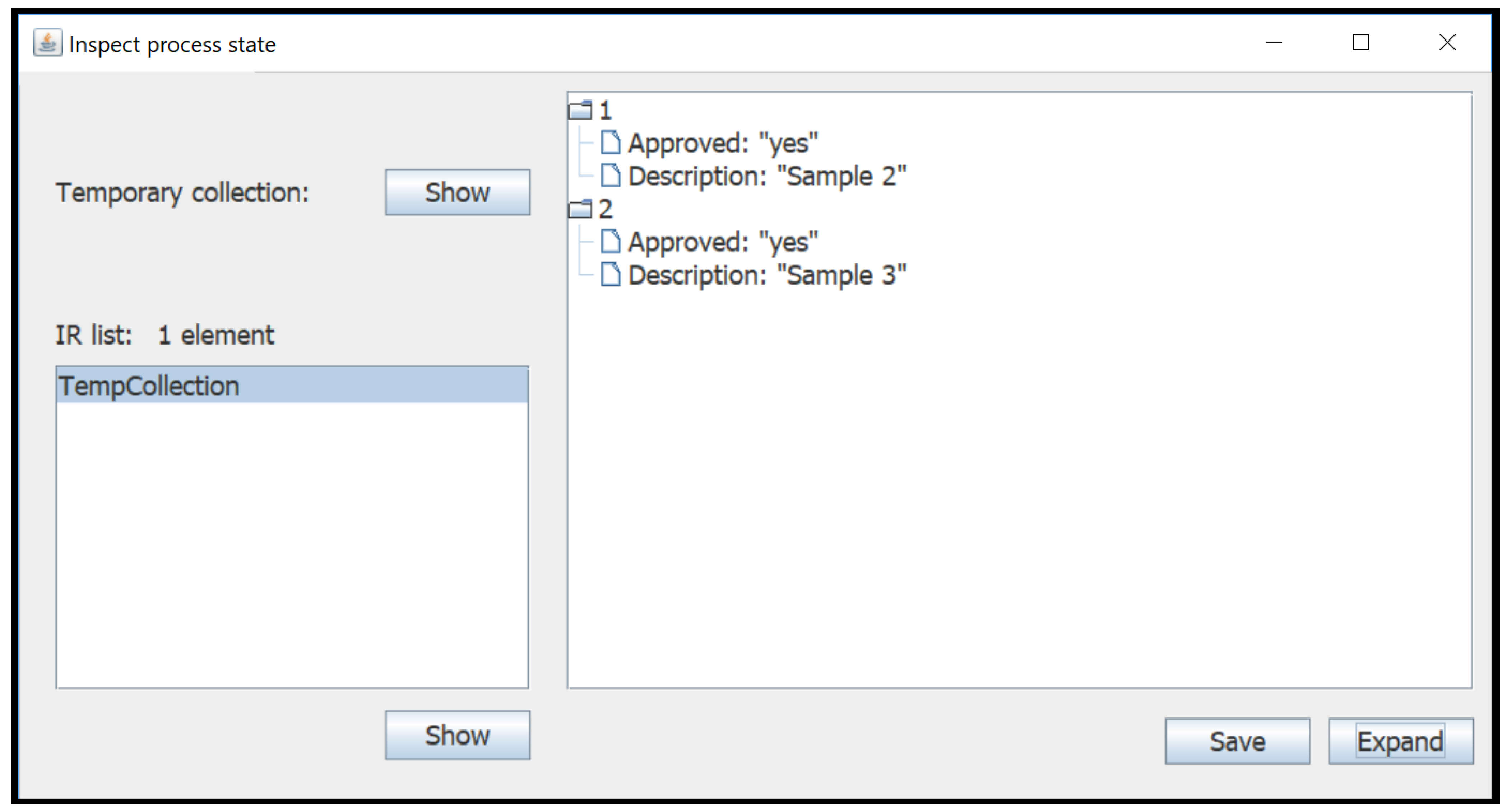
- State Inspection: the current process state can be inspected;
- Roll-back: the user can roll-back the execution of the process to a previous execution state.
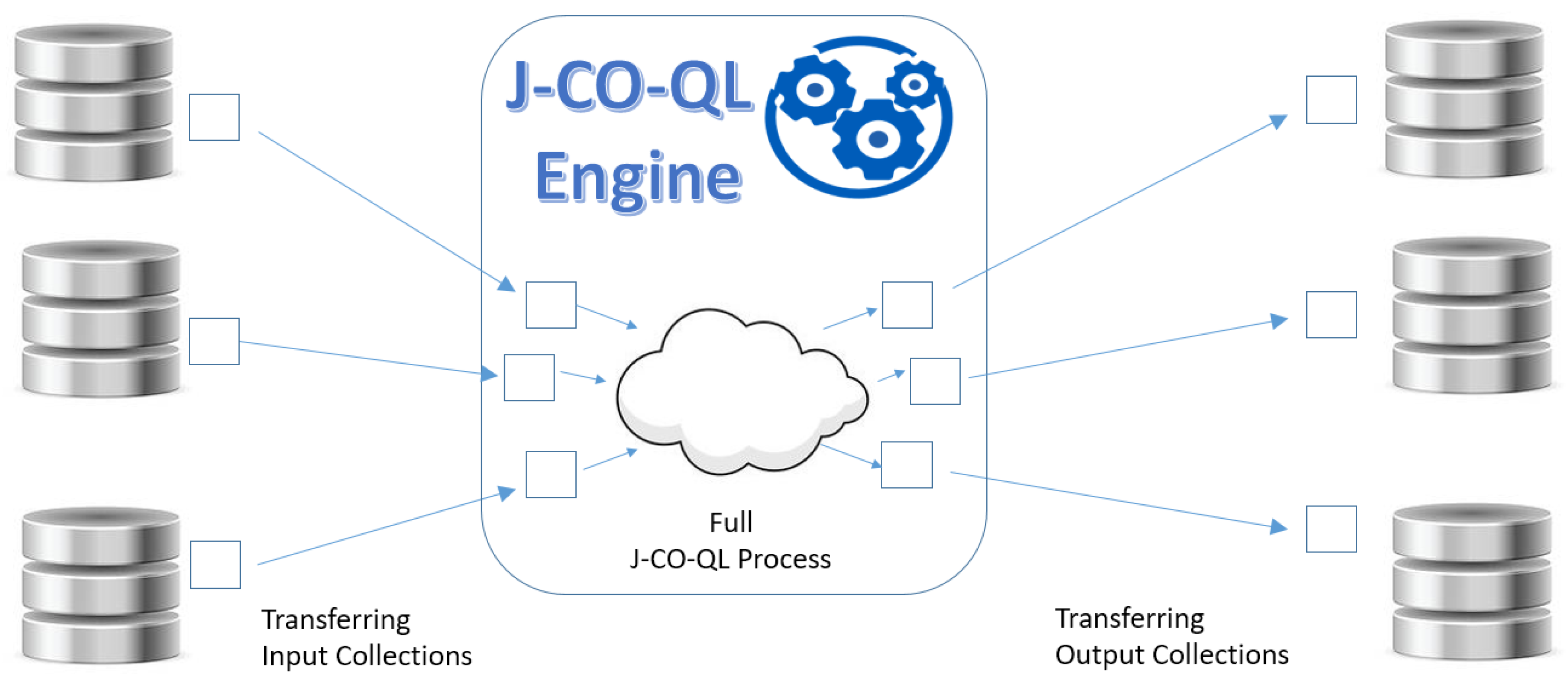
- Multiple Connectors. The J-CO-QL Engine is equipped with a specific connector for each single data storage system we have considered so far, i.e., MongoDB, ElasticSearch and J-CO-DS. These connectors provide a uniform interface to the code of the J-CO-QL Engine towards different data storage systems.
- Retrieving/storing Collections. The J-CO-QL Engine interacts with data storage systems only to retrieve the content of collections and to store new collections. No data processing is asked to data storage systems because input collections are transferred to the J-CO-QL Engine and output collections are transferred to the data storage systems.
- Loosely Coupling. As a result, the J-CO-QL Engine is loosely coupled to data storage systems: all processing activities (i.e., execution of J-CO-QL transformation processes) are performed within the J-CO-QL Engine on the local copy of collections, not on the source databases.
4. J-CO-QL: The Query Language of the J-CO Framework
4.1. J-CO-QL Main Features


- J-CO-QLinstructions are able to deal with documents with different structure with one single instruction. This is the feature named Adaptability to heterogeneity in Table 1.
- J-CO-QL instructions allow for specifying complex transformations oriented to analyze data. This is the feature named Orientation to Analysts in Table 1.
- J-CO-QL instructions directly deal with geo-references (through the ~geometry field) and spatial operations. This is the feature named Spatial operations in Table 1.
4.2. Language by Example


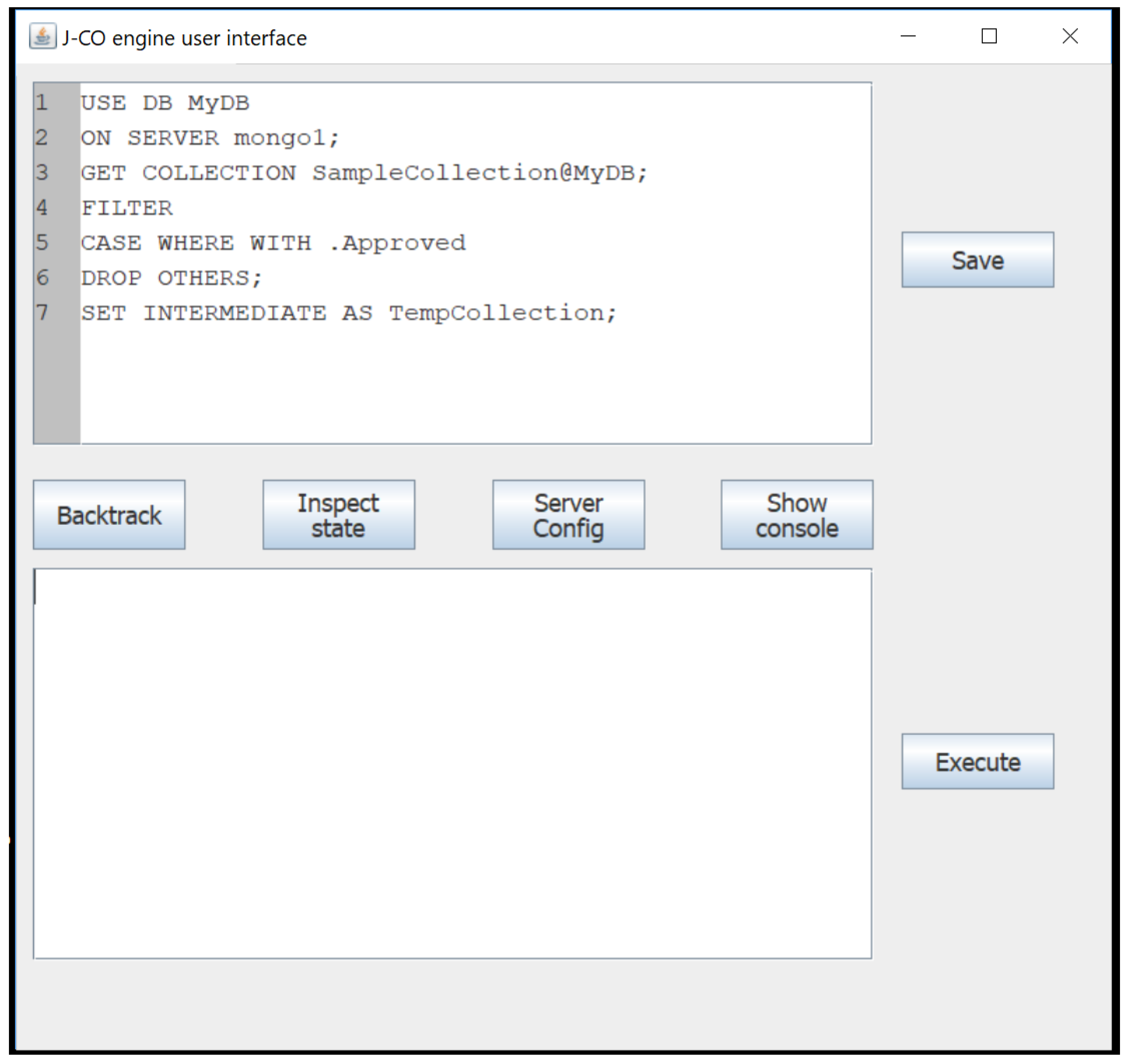
- First of all, it is necessary to specify which databases to connect to. The three USE DB instructions at lines 1–3 do this work. Notice that the ON clauses specify the connection strings necessary to connect to the desired servers. These instructions do not change the query-process state; consequently, both temporary collection and Intermediate Results database remain empty; this is why in Figure 3 we start depicting the query process form line 4.
- The GET COLLECTION instruction at line 4 gets the Districts collection from the Boundaries database: the collection becomes the new temporary collection of the query process (as depicted in Figure 3).
- The FILTER instruction at line 5 actually filters documents that describe districts of Milan. It takes the current temporary collection and applies the CASE WHERE clause, which is a document selection condition. In the instruction, the condition relies on the WITH predicate: this predicate is true if the document under selection contains the specified field (or fields, if a list of field names is specified). In the specific case, the condition is true if the document under selection contains the City field within the root-level Properties field and if its value is “Milan”.For each document that meets the condition, the GENERATE action inserts a restructured version of the document into the output temporary collection , such that the ID field is reported as it is, while a new root-level Name field is derived from the previously nested one (specified by the expression .Name: .Properties.Name). The ~geometry field is kept as it is, as specified by the KEEPING GEOMETRY directive.The final DROP OTHERS option specifies that documents that do not meet the selection condition must be discarded and will not appear in the output collection (the language admits an alternative KEEP OTHERS option, which would keep not-selected documents into the output collection). We introduced this option to make J-CO-QL adaptive to heterogeneity (feature 1 of Table 1).The output collection becomes the new temporary collection . An excerpt is reported in the upper part of Listing 5, where the restructured version of documents shown in Listing 1 is reported.In the CASE WHERE clause and in the GENERATE action, fields are referred to by means of a dot notation like .A.B.C, in order to deal with nested documents (the sample dot notation would access the C field nested within a B field, in turn nested within the A field at the root level of the document).
- The temporary collection produced by line 5 contains only districts of Milan. Line 6 saves this temporary collection into the Intermediate Results database with name Milan_Districts, for further processing during the same query process; this is the feature Re-use of intermediate results reported in Table 1. In Figure 3, notice how the database is no longer empty in the query-process state produced by line 6.
- Lines 7 to 9 basically perform, on bike lanes, the same task performed by lines 4 to 6. Specifically, line 7 gets the BikeLanes collection from the RegionInfo database; this collection becomes the new temporary collection .
- The FILTER instruction at line 8 selects bike lanes of Milan. However, recall from Listing 2 that documents describing bike lanes are heterogeneous: for this reason, the CASE clause contains two WHERE selection conditions, each one followed by a corresponding GENERATE action. When a document is evaluated, if the first selection condition is not true, the second one is evaluated and, if true, the document is restructured according to the corresponding GENERATE action. If none of the selection conditions is true, the document is discarded from the output collection, according to the DROP OTHERS option.Notice that line 8 is an example of one of the innovative features introduced by J-CO-QL, i.e., the capability of dealing with heterogeneous collections (feature Adaptability to heterogeneity in Table 1). In fact, the collection can contain documents with several structures (as in the example); by means of multiple WHERE conditions and the contribution of the KEEP OTHERS/DROP OTHERS options, the same instruction is able to filter documents with different structures, focusing on some of them, possibly unifying the structure of output documents as well as possibly generating documents with different structures, with one single instruction.Notice that the two GENERATE actions restructure the selected documents in order to have the same structure. The two documents shown in Listing 2 are restructured as reported in the lower part of Listing 5.Furthermore, the two GENERATE actions have to adapt geo-tagging to the J-CO-QL data model: the SETTING GEOMETRY .geometry option specifies that the new ~geometry special field must be derived from the geometry field formerly present in the source selected document (in the lower part of Listing 5, which reports the output collection, it is possible to see that, now, documents have the ~geometry field). This field is internally managed by means of the representation provided by the JTS—Java Topology Suite library; consequently, the SETTING GEOMETRY option asks the J-CO-QL Engine to convert a pure JSON field (the former geometry field) into the internal representation adopted to represent the~geometry field.The SETTING GEOMETRY option was introduced to explicitly deal with geometries; it is accompanied by the alternative KEEPING GEOMETRY and DROPPING GEOMETRY options that, respectively, actually keep and drop the ~geometry field coming from the source document. In fact, this field has a special meaning for documents; consequently, we thought that the language had to force users to always consider this field in a special way, without confusing it with other fields.
- Line 9 saves the resulting temporary collection (containing only bike lanes of Milan) into the Intermediate Results database , with name Milan_BikeLanes: this can be clearly seen in Figure 3, where the database in the output query-process state of line 9 now contains two collections.

- The query carries on at line 10 with the SPATIAL JOIN instruction. This is the key instruction provided by J-CO-QL in order to perform complex transformations concerned with geo-referenced data. Recall that the Milan_Districts collection describes districts in Milan: each document in the collection contains a field named ~geometry, which, in this case, describes the boundary of the district as a polygon. This collection is aliased as D in the instruction. The second collection is Milan_BikeLanes: it is aliased as B and the ~geometry field of each document, in this case, represents the full path of a single bike lane. These two collections are taken from the Intermediate Results database, in that they are intermediate results obtained by previous instructions in the query (when no database is specified after a collection name, it is retrieved from the database). This is how J-CO-QL completes the support to the feature Re-usability of intermediate results reported in Table 1.The SPATIAL JOIN instruction computes pairs of documents in the two collections, such that the spatial-join condition specified in the ON clause is satisfied. Specifically, a new document is built if the geometries of the two paired documents intersect. The SET GEOMETRY clause specifies the geometry to assign to the document obtained by pairing the two original ones: we specify that we want the intersection of the two geometries, i.e., the fragment of polyline that describes the portion of bike lane crossing the given district. The upper part of Listing 6 reports an excerpt of the documents resulting from the generation of pairs that satisfy the spatial-join condition. Notice the D field, which contains the original document coming from the collection aliased as D, the B field, which contains the original document coming from the collection aliased as B, and the ~geometry field resulting from the intersection of the two original geometries.The subsequent CASE WHERE clause is necessary to restructure the documents, removing nesting; it behaves as the CASE WHERE clause already seen in the FILTER instruction. The specific WHERE selection condition in the instruction uses the WITH predicate, so as to select documents having the desired fields; then, the GENERATE action specifies how to restructure each document that satisfies the condition; the KEEPING GEOMETRY option specifies that we maintain the geometry obtained by the spatial join (i.e., the intersection of the two original geometries). The lower part of Listing 6 reports an excerpt of the temporary collection (as reported in Figure 3) resulting from the SPATIAL JOIN; notice how the documents in the upper part of the listing are restructured by the GENERATE action.The final REMOVE DUPLICATES option asks for removing duplicates from the output temporary collection. This option is available in many instructions (in particular FILTER): when it is not specified, removal of duplicates is not performed.The SPATIAL JOIN could be done on the temporary collection as well, by using the collection name TEMPORARY. This is not usually possible in JSON DBMSs, which enable spatial queries only on materialized documents, because they have to build spatial indexes. In contrast, J-CO-QL is able to spatially join collections obtained from two different databases, possibly managed by two different storage services, without forcing analysts to transfer them from one storage to another.Furthermore, if we explicitly consider MongoDB, currently its query language is not at all able to perform something similar to the SPATIAL JOIN without writing JavaScript code, i.e., procedural and imperative code. This is why, in Table 1, we said that MongoDB is not Oriented to Analysts but is Oriented to Programmers; in contrast, J-CO-QL is fully oriented to analysts, because its instructions are declarative and no procedural integration is allowed.
- At this point (line 11), it is necessary to group documents resulting from the SPATIAL JOIN, in order to count the number of districts that are crossed by each bike lane. In fact, if a bike lane crosses several districts, several documents having the same value for the BikeLaneName field are in the output of the SPATIAL JOIN instruction (line 10).In the GROUP instruction, the goal of the PARTITION clause is to select documents (from the temporary collection produced by the previous instruction) that have some common fields or characteristics. In line 11 of Listing 4, we select documents having the BikeLaneName field. In practice, we specify a partition of the full set of documents in the temporary collection; the DROP OTHERS option at the end of line 11 specifies that documents not selected for the specified partition are discarded from the output temporary collection. This is again to meet the feature Adaptability to heterogeneity reported in Table 1; in particular, since many PARTITION clauses are allowed, many different grouping tasks on many different document structures could be specified within the same instruction.At this point, documents in the partition are then grouped based on the BikeLaneName field, as specified by the BY clause. For each identified group of documents (i.e., documents having the same value for the BikeLaneName field), a new document is put into the output collection, such that all common fields are reported and a new field, an array of grouped documents named DistrictSegs (as specified by the INTO clause) is added. The DROP GROUPING FIELDS option specifies that grouping fields (in this case, only the BikeLaneName field) are removed from grouped documents.An excerpt of the temporary collection , as numbered in Figure 3, is reported in the upper part of Listing 7.
- Once documents are grouped, it is necessary (line 12) to add a field to be assigned with the number of elements that are present in the DistrictSegs array, so as to know how many districts are crossed by each bike lane.The FILTER instruction at line 12 selects all the documents and restructures them by adding the field named NumOfDistricts. The lower part of Listing 7 reports the temporary collection , as numbered in Figure 3, resulting from the FILTER instruction.It is worth noticing the SETTING GEOMETRY option: it derives the ~geometry field of each output document by aggregating single geometries of documents within the DistrictSegs array (remember that these geometries represent the fragment of bike lane that intersect the specific district); specifically, the Aggregate function unites single geometries, obtaining either a GeometryCollection or a MultiPoint, or a MultiLineString, or a MultiPolygon (see the specification of GeoJSON [3]) as value of the ~geometry field.
- The FILTER instruction at line 13 is necessary to actually select documents whose value of the NumOfDistricts field is no less than 2. This is done by the CASE WHERE clause.Then, the GENERATE action further restructures selected documents, in order to get the final structure: in particular, only the BikeLaneName field is kept, as well as the geometry obtained by the FILTER instruction at line 12. The lower part of Listing 7 reports an excerpt of the resulting temporary collection .
- The query terminates (line 14) by saving the final temporary collection into a persistent database. In particular, the SAVE AS instruction saves the temporary collection into the toShare database with name BikeLanesCrossingDistricts.


5. J-CO-UI: The User Interface of the J-CO Framework
6. Performance Evaluation
6.1. Scalability of the J-CO-QL Engine
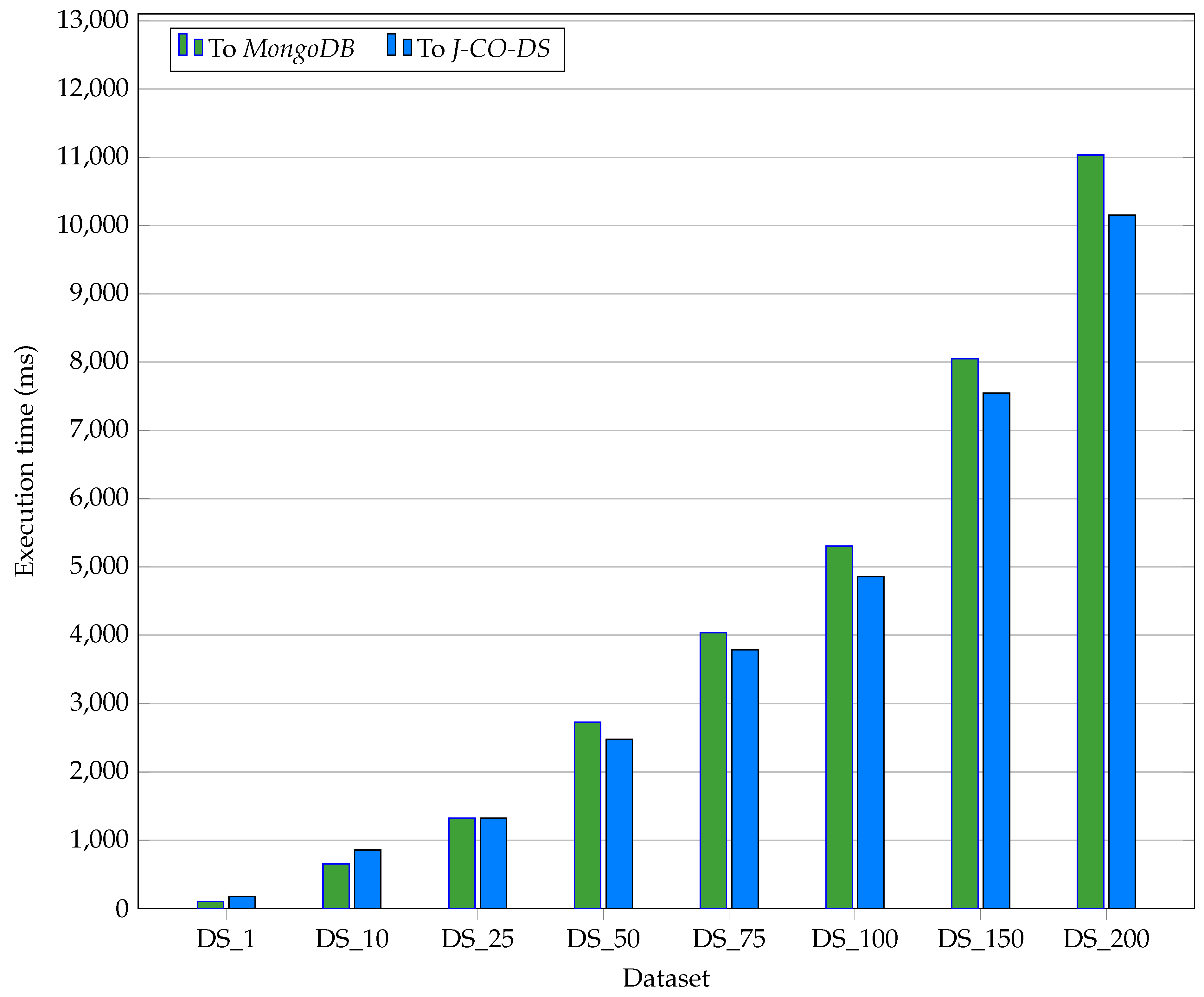
6.2. J-CO-DS vs. MongoDB
7. Conclusions
7.1. Summary
7.2. Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Bray, T. The Javascript Object Notation (JSON) Data Interchange Format. 2014. Available online: https://www.rfc-editor.org/rfc/rfc7159.txt (accessed on 3 March 2021).
- Bray, T.; Paoli, J.; Sperberg-McQueen, C.M.; Maler, E.; Yergeau, F. Extensible markup language (XML) 1.0; W3C Recommendation. 2000. Available online: https://www.w3.org/TR/xml/ (accessed on 25 February 2021).
- Butler, H.; Daly, M.; Doyle, A.; Gillies, S.; Hagen, S.; Schaub, T. The geojson format. In Internet Engineering Task Force (IETF); 2016; Available online: https://tools.ietf.org/html/rfc7946 (accessed on 25 February 2021).
- Chow, T.E. Geography 2.0: A mashup perspective. In Advances in Web-based GIS, Mapping Services Furthermore, Applications; CRC Press: Boca Rato, FL, USA, 2011; pp. 15–36. [Google Scholar]
- Cattell, R. Scalable SQL and NoSQL data stores. ACM Sigmod Rec. 2011, 39, 12–27. [Google Scholar] [CrossRef] [Green Version]
- Chodorow, K. MongoDB: The Definitive Guide; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2013. [Google Scholar]
- Burini, F.; Cortesi, N.; Gotti, K.; Psaila, G. The Urban Nexus Approach for Analyzing Mobility in the Smart City: Towards the Identification of City Users Networking. Mob. Inf. Syst. 2018, 2018, 6294872. [Google Scholar] [CrossRef] [Green Version]
- Bordogna, G.; Capelli, S.; Psaila, G. A big geo data query framework to correlate open data with social network geotagged posts. In Proceedings of the Annual International Conference on Geographic Information Science, Wageningen, The Netherlands, 9–12 May 2017; pp. 185–203. [Google Scholar]
- Bordogna, G.; Ciriello, D.E.; Psaila, G. A flexible framework to cross-analyze heterogeneous multi-source geo-referenced information: The J-CO-QL proposal and its implementation. In Proceedings of the International Conference on Web Intelligence, Leipzig, Germany, 23–26 August 2017; pp. 499–508. [Google Scholar]
- Bordogna, G.; Capelli, S.; Ciriello, D.E.; Psaila, G. A cross-analysis framework for multi-source volunteered, crowdsourced, and authoritative geographic information: The case study of volunteered personal traces analysis against transport network data. Geo-Spat. Inf. Sci. 2018, 21, 257–271. [Google Scholar] [CrossRef]
- Cuzzocrea, A.; Psaila, G.; Toccu, M. Knowledge discovery from geo-located tweets for supporting advanced big data analytics: A real-life experience. In Model and Data Engineering, Rhodes, Greece; Springer: Berlin, Germany, 2015; pp. 285–294. [Google Scholar]
- Cuzzocrea, A.; Psaila, G.; Toccu, M. An innovative framework for effectively and efficiently supporting big data analytics over geo-located mobile social media. In Proceedings of the 20th International Database Engineering & Applications Symposium, Montreal, QC, Cananda, 11–13 July 2016. [Google Scholar]
- Bordogna, G.; Cuzzocrea, A.; Frigerio, L.; Psaila, G.; Toccu, M. An interoperable open data framework for discovering popular tours based on geo-tagged tweets. Int. J. Intell. Inf. Database Syst. 2017, 10, 246–268. [Google Scholar] [CrossRef]
- Bordogna, G.; Frigerio, L.; Cuzzocrea, A.; Psaila, G. Clustering geo-tagged tweets for advanced big data analytics. In Proceedings of the 2016 IEEE International Congress on Big Data (BigData Congress), San Francisco, CA, USA, 27 June–2 July 2016; pp. 42–51. [Google Scholar]
- Uddin, M.F.; Gupta, N. Seven V’s of Big Data understanding Big Data to extract value. In Proceedings of the 2014 Zone 1 Conference of the American Society for Engineering Education, Bridgeport, CT, USA, 3–5 April 2014; pp. 1–5. [Google Scholar]
- Feng, J.H.; Qian, Q.; Liao, Y.G.; Li, G.L.; Ta, N.; Zhou, L.Z. Survey of research on native xml databases. Appl. Res. Comput. 2006, 6, 1–7. [Google Scholar]
- Gou, G.; Chirkova, R. Efficiently querying large XML data repositories: A survey. IEEE Trans. Knowl. Data Eng. 2007, 19, 1381–1403. [Google Scholar] [CrossRef] [Green Version]
- Haw, S.C.; Lee, C.S. Data storage practices and query processing in XML databases: A survey. Knowl. Based Syst. 2011, 24, 1317–1340. [Google Scholar] [CrossRef]
- Kurgan, L.A.; Musilek, P. A survey of Knowledge Discovery and Data Mining process models. Knowl. Eng. Rev. 2006, 21, 1–24. [Google Scholar] [CrossRef]
- Meo, R.; Psaila, G. An XML-based database for knowledge discovery. In Proceedings of the International Conference on Extending Database Technology, Munich, Germany, 26–31 March 2006; pp. 814–828. [Google Scholar]
- Nayak, A.; Poriya, A.; Poojary, D. Type of NOSQL databases and its comparison with relational databases. Int. J. Appl. Inf. Syst. 2013, 5, 16–19. [Google Scholar]
- Hecht, R.; Jablonski, S. Nosql evaluation: A us case oriented survey. In Proceedings of the CSC-2011 International Conference on Cloud and Service Computing, Hong Kong, China, 12–14 December 2011; pp. 336–341. [Google Scholar]
- Han, J.; Haihong, E.; Le, G.; Du, J. Survey on NoSQL database. In Proceedings of the 2011 6th International Conference on Pervasive Computing and Applications, Chengdu, China, 11–13 May 2011; pp. 363–366. [Google Scholar]
- Beyer, K.S.; Ercegovac, V.; Gemulla, R.; Balmin, A.; Eltabakh, M.; Kanne, C.C.; Ozcan, F.; Shekita, E.J. Jaql: A scripting language for large scale semistructured data analysis. Proc. VLDB Endow. 2011, 4, 1272–1283. [Google Scholar] [CrossRef]
- Anderson, J.C.; Lehnardt, J.; Slater, N. CouchDB: The Definitive Guide: Time to Relax; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2010. [Google Scholar]
- Ong, K.W.; Papakonstantinou, Y.; Vernoux, R. The SQL++ unifying semi-structured query language, and an expressiveness benchmark of SQL-on-Hadoop, NoSQL and NewSQL databases. arXiv 2014, arXiv:1405.3631. [Google Scholar]
- Chamberlin, D. SQL++ For SQL Users: A Tutorial. 2018. Available online: Amazon.com (accessed on 3 March 2021).
- Florescu, D.; Fourny, G. JSONiq: The history of a query language. IEEE Internet Comput. 2013, 17, 86–90. [Google Scholar] [CrossRef]
- Chamberlin, D. XQuery: An XML query language. IBM Syst. J. 2002, 41, 597–615. [Google Scholar] [CrossRef] [Green Version]
- Arora, R.; Aggarwal, R.R. Modeling and querying data in mongodb. Int. J. Sci. Eng. Res. 2013, 4, 141–144. [Google Scholar]
- Doulkeridis, C.; N∅rvåg, K. A survey of large-scale analytical query processing in MapReduce. VLDB J. The Int. J. Very Large Data Bases 2014, 23, 355–380. [Google Scholar] [CrossRef] [Green Version]
- Goyal, V.; Soni, D. Survey paper on Big Data Analytics using Hadoop Technologies. Int. J. Curr. Eng. Sci. Res. (IJCESR) 2006, 3, 2394–2697. [Google Scholar]
- Armbrust, M.; Xin, R.S.; Lian, C.; Huai, Y.; Liu, D.; Bradley, J.K.; Meng, X.; Kaftan, T.; Franklin, M.J.; Ghodsi, A.; et al. Spark sql: Relational data processing in spark. In Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data, Melbourne, VIC, Australia, 31 May–4 June 2015; pp. 1383–1394. [Google Scholar]
- Battle, R.; Kolas, D. Geosparql: Enabling a geospatial semantic web. Semant. Web J. 2011, 3, 355–370. [Google Scholar] [CrossRef]
- Bordogna, G.; Pagani, M.; Psaila, G. Database model and algebra for complex and heterogeneous spatial entities. In Progress in Spatial Data Handling; Springer: Berlin, Germany, 2006; pp. 79–97. [Google Scholar]
- Psaila, G. A database model for heterogeneous spatial collections: Definition and algebra. In Proceedings of the 2011 International Conference on Data and Knowledge Engineering (ICDKE); IEEE: New York, NY, USA, 2011; pp. 30–35. [Google Scholar]
- Bordogna, G.; Campi, A.; Psaila, G.; Ronchi, S. An interaction framework for mobile web search. In Proceedings of the 6th International Conference on Advances in Mobile Computing and Multimedia, Linz, Austria, 24–26 November 2008; pp. 183–191. [Google Scholar]
- Duggan, J.; Elmore, A.J.; Stonebraker, M.; Balazinska, M.; Howe, B.; Kepner, J.; Madden, S.; Maier, D.; Mattson, T.; Zdonik, S. The BIGDAWG polystore system. ACM Sigmod Rec. 2015, 44, 11–16. [Google Scholar] [CrossRef]
- Singhal, R.; Zhang, N.; Nardi, L.; Shahbaz, M.; Olukotun, K. Polystore++: Accelerated Polystore System for Heterogeneous Workloads. In Proceedings of the 2019 IEEE 39th International Conference on Distributed Computing Systems (ICDCS), Dallas, TX, USA, 7–10 July 2019; pp. 1641–1651. [Google Scholar]
- Hamadou, H.B.; Gallinucci, E.; Golfarelli, M. Answering GPSJ queries in a polystore: A dataspace-based approach. In Proceedings of the International Conference on Conceptual Modeling, Salvador, Brazil, 4–7 November 2019; pp. 189–203. [Google Scholar]
- Jananthan, H.; Zhou, Z.; Gadepally, V.; Hutchison, D.; Kim, S.; Kepner, J. Polystore mathematics of relational algebra. In Proceedings of the 2017 IEEE International Conference on Big Data (Big Data), Boston, MA, USA, 11–14 December 2017; pp. 3180–3189. [Google Scholar]
- Rantung, V.P.; Kembuan, O.; Rompas, P.T.D.; Mewengkang, A.; Liando, O.E.S.; Sumayku, J. In-memory business intelligence: Concepts and performance. In IOP Conference Series: Materials Science and Engineering; IOP Publishing: Sebastopol, CA, USA, 2018; Volume 306, p. 012129. [Google Scholar]
- Shukla, A.; Dhir, S. Tools for data visualization in business intelligence: Case study using the tool Qlikview. In Information Systems Design and Intelligent Applications; Springer: Berlin, Germany, 2016; pp. 319–326. [Google Scholar]
- Mora, J.M.L. Qlik Sense Implementation: Dashboard Creation and Implementation of the Test Performance Methodology. Master’s Thesis, Universidade Nova de Lisboa, Lisbon, Portugal, 2020. [Google Scholar]
- Gormley, C.; Tong, Z. Elasticsearch: The Definitive Guide: A Distributed Real-Time Search and Analytics Engine; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2015. [Google Scholar]
- Manyam, G.; Payton, M.A.; Roth, J.A.; Abruzzo, L.V.; Coombes, K.R. Relax with CouchDB—Into the non-relational DBMS era of bioinformatics. Genomics 2012, 100, 1–7. [Google Scholar] [CrossRef] [Green Version]
- Bortnikov, E.A.A.B.V.; Konstantinos, C.C.; Enyeart, C.A.D.C.D.; Laventman, C.F.G.; Manevich, Y.; Muralidharan, S.; Murthy, C.; Nguyen, B.; Sethi, M.; Singh, G.; et al. Hyperledger Fabric: A Distributed Operating System for Permissioned Blockchains. In Proceedings of the 13th EuroSys Conference, Porto, Portugal, 23–26 April 2018. [Google Scholar]
- Hubert, G.; Cabanac, G.; Sallaberry, C.; Palacio, D. Query operators shown beneficial for improving search results. In International Conference on Theory and Practice of Digital Libraries; Springer: Berlin, Germany, 2011; pp. 118–129. [Google Scholar]
- Pelucchi, M.; Psaila, G.; Toccu, M. Hadoop vs. Spark: Impact on Performance of the Hammer Query Engine for Open Data Corpora. Algorithms 2018, 11, 209. [Google Scholar] [CrossRef] [Green Version]
- Marrara, S.; Pelucchi, M.; Psaila, G. Blind Queries Applied to JSON Document Stores. Information 2019, 10, 291. [Google Scholar] [CrossRef] [Green Version]
- Bordogna, G.; Pagani, M.; Pasi, G.; Psaila, G. Evaluating uncertain location-based spatial queries. In Proceedings of the 2008 ACM Symposium on Applied Computing, Ceara, Brazil, 16–20 March 2008; pp. 1095–1100. [Google Scholar]
- Bordogna, G.; Pagani, M.; Pasi, G.; Psaila, G. Managing uncertainty in location-based queries. Fuzzy Sets Syst. 2009, 160, 2241–2252. [Google Scholar] [CrossRef]
- Wiederhold, G. Mediators in the architecture of future information systems. Computer 1992, 25, 38–49. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Query Language | J-CO-QL | Jaql | SQL++ | JSONiq | MongoDB |
|---|---|---|---|---|---|
| 1. Adaptability to heterogeneity | YES | NO | NO | NO | NO |
| 2. Spatial operations | YES | NO | NO | NO | YES |
| 3. Platform independence | YES | NO | YES | YES | NO |
| 4. Re-use of intermediate results | YES | NO | NO | NO | NO |
| 5. Orientation to Analysts | YES | NO | YES | NO | NO |
| 6. Orientation to Programmers | NO | YES | NO | YES | YES |
| Data Set Id | Factor f | N. of Districts | N. of Bike Lanes |
|---|---|---|---|
| DS_1 | 1 | 88 | 422 |
| DS_10 | 10 | 880 | 4220 |
| DS_25 | 25 | 2200 | 10,550 |
| DS_50 | 50 | 4400 | 21,100 |
| DS_75 | 75 | 6600 | 31,650 |
| DS_100 | 100 | 8800 | 42,200 |
| DS_150 | 150 | 13,200 | 63,300 |
| DS_200 | 200 | 17,600 | 84,400 |
| Instruction | Avg. | Exec. 1 | Exec. 2 | Exec. 3 | Exec. 4 | Exec. 5 |
|---|---|---|---|---|---|---|
| 1. USE DB | 0.31 | 0.99 | 0.31 | 0.16 | 0.04 | 0.03 |
| 2. USE DB | 0.03 | 0.05 | 0.02 | 0.03 | 0.03 | 0.03 |
| 3. USE DB | 0.02 | 0.03 | 0.02 | 0.03 | 0.02 | 0.02 |
| 4. GET COLLECTION | 306.55 | 1,088.70 | 138.00 | 122.97 | 99.64 | 83.46 |
| 5. FILTER | 2.43 | 9.99 | 0.86 | 0.30 | 0.50 | 0.51 |
| 6. SET INTERMEDIATE | 164.39 | 247.16 | 172.25 | 126.64 | 162.62 | 113.25 |
| 7. GET COLLECTION | 59.27 | 100.33 | 64.47 | 63.80 | 31.84 | 35.90 |
| 8. FILTER | 220.29 | 409.07 | 241.38 | 150.78 | 143.52 | 156.72 |
| 9. SET INTERMEDIATE | 99.56 | 157.43 | 103.85 | 94.21 | 74.21 | 68.09 |
| 10. SPATIAL JOIN | 706.82 | 1,417.74 | 677.38 | 489.00 | 507.97 | 442.00 |
| 11. GROUP | 5.82 | 18.64 | 3.20 | 2.34 | 2.31 | 2.62 |
| 12. FILTER | 133.85 | 302.74 | 111.68 | 99.64 | 89.16 | 66.03 |
| 13. FILTER | 1.58 | 2.72 | 1.70 | 1.46 | 0.93 | 1.06 |
| 14. SAVE AS | 98.17 | 172.54 | 84.16 | 91.87 | 81.15 | 61.12 |
| Total (ms) | 1,799.08 | 3,928.10 | 1,599.28 | 1,243.23 | 1,193.96 | 1,030.84 |
| Instruction | Avg. | Exec. 1 | Exec. 2 | Exec. 3 | Exec. 4 | Exec. 5 |
|---|---|---|---|---|---|---|
| 1. USE DB | 0.04 | 0.08 | 0.04 | 0.03 | 0.03 | 0.02 |
| 2. USE DB | 0.03 | 0.02 | 0.02 | 0.02 | 0.03 | 0.03 |
| 3. USE DB | 0.02 | 0.02 | 0.02 | 0.01 | 0.02 | 0.01 |
| 4. GET COLLECTION | 0.01 | 0.02 | 0.01 | 0.01 | 0.02 | 0.01 |
| 5. FILTER | 5.47 | 20.14 | 3.01 | 1.34 | 1.49 | 1.36 |
| 6. SET INTERMEDIATE | 800.51 | 1075.87 | 874.02 | 671.30 | 670.68 | 710.68 |
| 7. GET COLLECTION | 214.74 | 437.30 | 167.66 | 151.11 | 147.97 | 169.66 |
| 8. FILTER | 1196.96 | 2173.38 | 989.40 | 904.84 | 927.73 | 989.45 |
| 9. SET INTERMEDIATE | 486.41 | 713.83 | 417.10 | 403.20 | 416.89 | 481.03 |
| 10. SPATIAL JOIN | 11,475.88 | 16,998.58 | 10,088.89 | 10,032.71 | 10,074.85 | 10,184.37 |
| 11. GROUP | 4.12 | 12.07 | 2.96 | 2.10 | 1.45 | 2.03 |
| 12. FILTER | 70.84 | 128.41 | 56.46 | 56.87 | 56.32 | 56.11 |
| 13. FILTER | 0.65 | 1.02 | 0.56 | 0.53 | 0.55 | 0.57 |
| 14. SAVE AS | 82.80 | 144.41 | 87.49 | 58.31 | 57.59 | 66.22 |
| Total (ms) | 14,338.48 | 21,705.16 | 12,687.65 | 12,282.40 | 12,355.62 | 12,661.57 |
| Instruction | DS_1 | DS_10 | DS_25 | DS_50 | DS_75 | DS_100 | DS_150 | DS_200 |
|---|---|---|---|---|---|---|---|---|
| 1. USE DB | 2 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 2. USE DB | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3. USE DB | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4. GET COLLECTION | 951 | 1,598 | 2,368 | 3,726 | 5,177 | 5,733 | 7,966 | 9,831 |
| 5. FILTER | 8 | 22 | 36 | 52 | 55 | 57 | 59 | 66 |
| 6. SET INTERMEDIATE | 214 | 952 | 1,885 | 3,362 | 4,338 | 5,201 | 8,180 | 10,505 |
| 7. GET COLLECTION | 83 | 374 | 893 | 1,020 | 1,368 | 1,747 | 2,566 | 3,911 |
| 8. FILTER | 324 | 1,841 | 2,938 | 5,340 | 8,344 | 9,872 | 15,747 | 20,460 |
| 9. SET INTERMEDIATE | 136 | 654 | 1,230 | 2,340 | 3,669 | 3,958 | 6,349 | 8,657 |
| 10. SPATIAL JOIN | 857 | 13,095 | 56,513 | 207,209 | 445,508 | 737,696 | 1,652,120 | 3,021,693 |
| 11. GROUP | 9 | 8 | 11 | 12 | 14 | 13 | 14 | 11 |
| 12. FILTER | 228 | 92 | 125 | 130 | 121 | 134 | 103 | 121 |
| 13. FILTER | 3 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 14. SAVE AS | 153 | 126 | 130 | 126 | 127 | 174 | 118 | 124 |
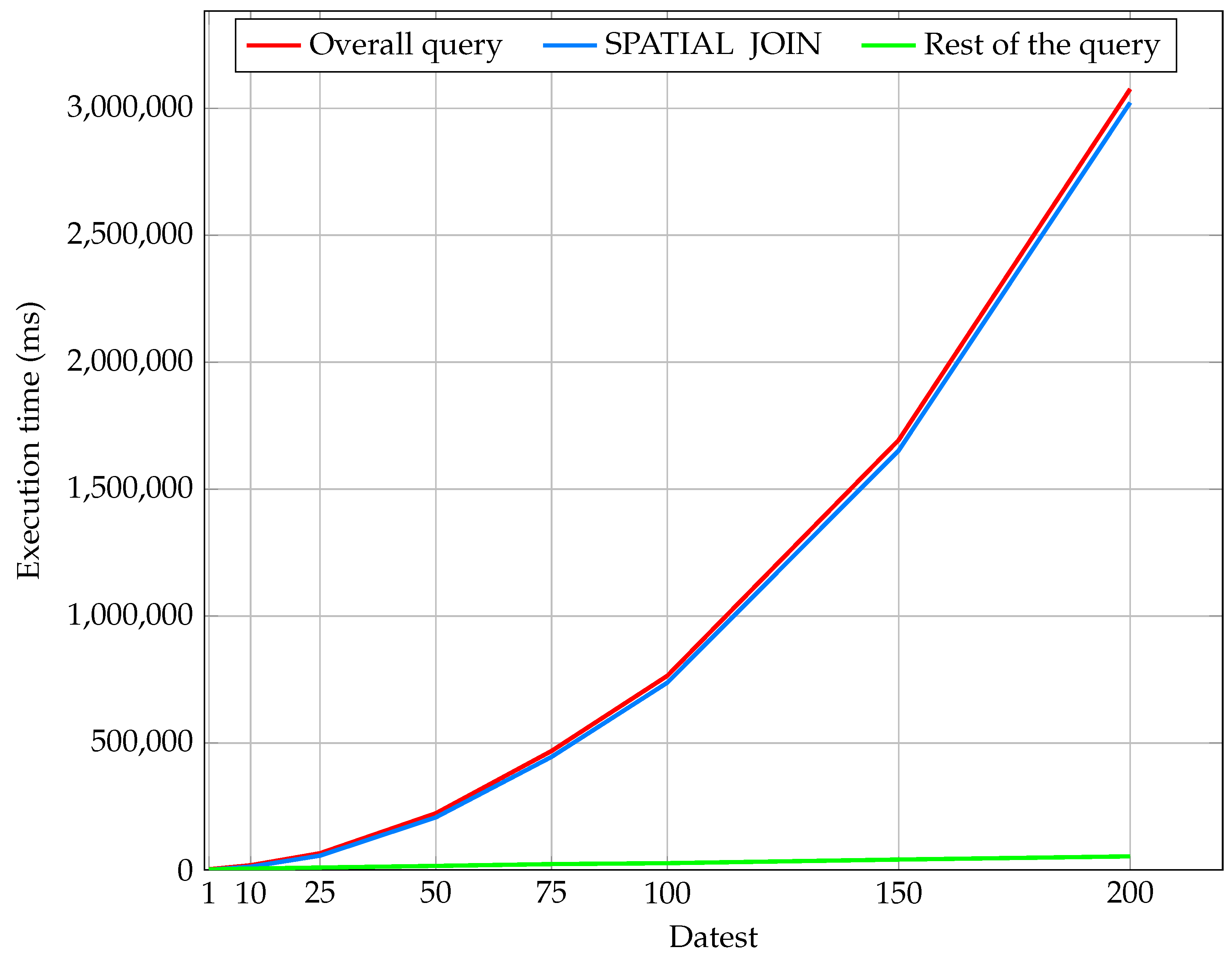
| Total (ms) | 2,966 | 18,764 | 66,132 | 223,319 | 468,722 | 764,587 | 1,693,224 | 3,075,381 |
| Total (min) | 0.05 | 0.31 | 1.10 | 3.72 | 7.81 | 12.74 | 28.22 | 51.26 |
| Total (min′s″) | 003 | 019 | 106 | 343 | 749 | 1245 | 2813″ | 5115 |
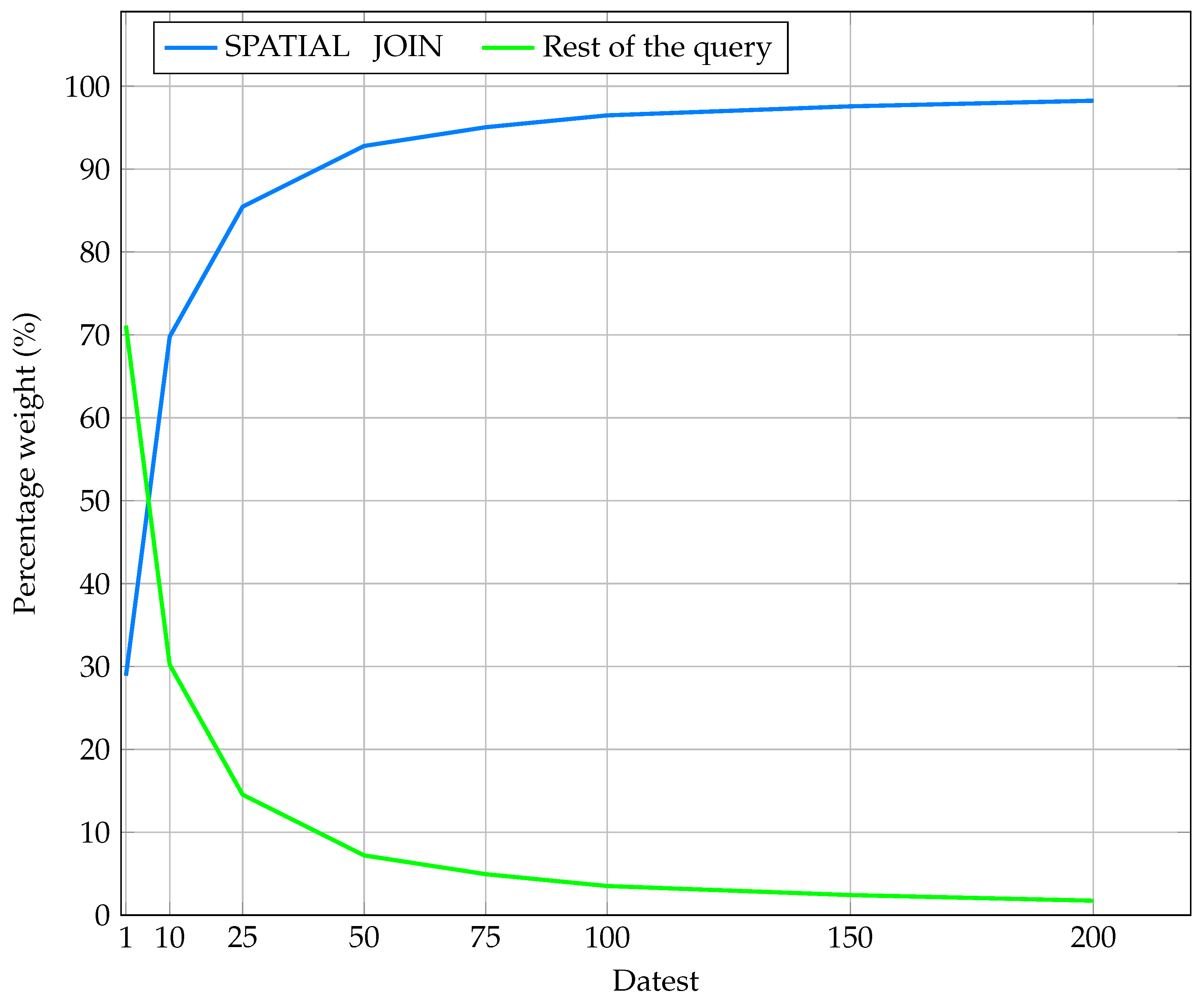
| SPATIAL JOIN % | 28.90% | 69.79% | 85.45% | 92.79% | 95.05% | 96.48% | 97.57% | 98.25% |
| Rest of the query % | 71.10% | 30.21% | 14.55% | 7.21% | 4.95% | 3.52% | 2.43% | 1.75% |
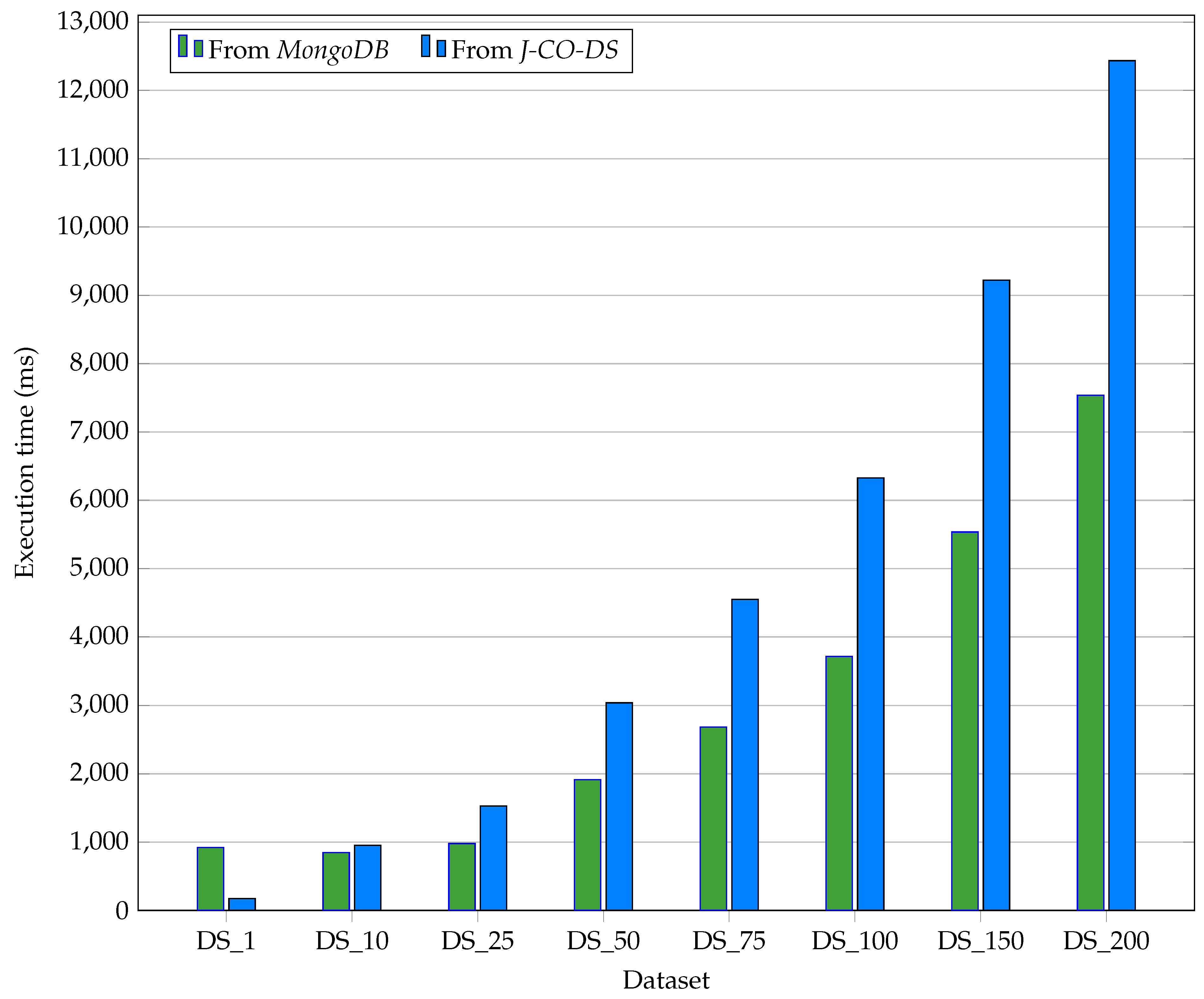
| Dataset | DS_1 | DS_10 | DS_25 | DS_50 | DS_75 | DS_100 | DS_150 | DS_200 |
|---|---|---|---|---|---|---|---|---|
| FromMongoDB | 922 | 847 | 979 | 1,915 | 2,686 | 3,713 | 5,535 | 7,537 |
| FromJ-CO-DS | 173 | 954 | 1,529 | 3,039 | 4,550 | 6,327 | 9,222 | 12,435 |
| ToMongoDB | 100 | 655 | 1,324 | 2,728 | 4,033 | 5,303 | 8,050 | 11,034 |
| ToJ-CO-DS | 180 | 858 | 1,325 | 2,480 | 3,784 | 4,856 | 7,547 | 10,154 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Psaila, G.; Fosci, P. J-CO: A Platform-Independent Framework for Managing Geo-Referenced JSON Data Sets. Electronics 2021, 10, 621. https://doi.org/10.3390/electronics10050621
Psaila G, Fosci P. J-CO: A Platform-Independent Framework for Managing Geo-Referenced JSON Data Sets. Electronics. 2021; 10(5):621. https://doi.org/10.3390/electronics10050621
Chicago/Turabian StylePsaila, Giuseppe, and Paolo Fosci. 2021. "J-CO: A Platform-Independent Framework for Managing Geo-Referenced JSON Data Sets" Electronics 10, no. 5: 621. https://doi.org/10.3390/electronics10050621