1. Introduction
At present, there are many studies on component-based software architecture, integration and selection; architecture mismatch analysis; and off-the-shell (OTS) based development in the literature. Initially, software component composition is introduced in [
1] as “an assembly of parts (components) into a whole (a composite) without modifying the parts.” It means the components should be composed in a way to satisfy functional requirements, where each component contains a clearly defined interface and functional description. The architecture-centric manner is utilized in traditional component selection (CS) approaches in which the most suitable available alternative component in the market is selected by considering the description of the desired component.
Various commercial OTS (COTS) approaches have been proposed in the literature, including [
2,
3,
4,
5]. In [
2,
3], the authors focused on COST selection and implementation by considering the business and functional criteria. However, architectural constraints without considering interoperability issue proposed in [
4] as COST selection. A time-consuming and manual approach for COST component interoperability evaluation was proposed in [
6], which is not suitable for evaluating a large number of COST combinations.
The second type of CS methods are designed by considering the relationship between requirements and available components for use. The main goal of these methods is to identify the mutual affection between requirements and available components to acquire a set of requirements, which is consistent with the desired market goal. The requirements for engineering and CS methods are incorporated to achieve this goal. PORE and CRE are the two most notable examples of the second type of CS methods [
5]. It is not realistic to anticipate a completed match between desired components and available components in any CS approach. A set of components that creates a system may overlap and have gaps in required functionality. A gap represents a lack of functionality, while an overlap can lead to responsibility confusion and declines in non-functional attributes, including performance and size.
A report given in [
7] by Gartner shows that 59% of organizations are going to build their own intelligent systems (ISs). This report also reveals that leading organizations are going to increase their numbers of projects, which involve IS features and components. ISs have been widely used in different domains, such as healthcare [
8], financial management [
9], tourism [
10], information systems [
11], transportation [
12], autonomous vehicles [
13], and marketing [
14]. Although artificial intelligence (AI) methods have various dark sides, including high energy consumption and a high pollution rate, many studies have focused on their utilization to improve the resource management, efficiency, and accuracy of decision making processes [
15] in different contexts. Despite the existence of a few studies, such as [
16], on the dark sides of AI in designing ISs, this problem has not been considered in designing component-based software. It is obvious that inappropriate composition of components may lead to developing an unsafe, power-consuming, and vulnerable IS. As a result, it is essential to use CS to engineer the dark sides of AI in ISs.
CS methods have evolved considering the substantial challenges associated with intelligent systems, including dark sides of artificial intelligence. A list of potential AI dark sides is as follows:
The complexity issue [
30].
Monopoly.
Responsibility challenges [
31].
Section 4.2.1 explains such issues in more detail. Some of the above challenges were used in the literature to define new versions of CS in different contexts, such as electric vehicles (EVs) [
32], smart buildings [
33], and renewable energy systems [
34]. These studies only focused on challenges without considering information about AI-based components. Therefore, information about AI-based components does not affect the component selection process. On the other hand, some studies, such as [
35,
36,
37], present mechanisms that consider some dark sides of AI such as privacy and data corruption, but they propose ad hoc solutions. In other words, they do not develop a general solution for developing software considering the dark sides of AI. Therefore, the existing solutions are not general enough to be used in different domains. In the next paragraph, the context of EVs is studied in more detail.
CS has also been considered in EVs, wherein there are different components, such as electric motors, power converters, and energy storage systems, which play a critical role in EVs’ architectures. A comparative study on various components of EVs is presented in [
32]. Finding the best coordination among the existing components can lead to the incrementing of traveled distance and fuel consumption reduction by EVs. Moreover, the use of dynamic programming in the CS process was proposed in [
38] to reduce EVs’ fuel consumption. On the other hand, control theory and learning algorithms are widely used in designing EVs. As some recent works, we can refer to [
39,
40,
41]. However, all of the available algorithms suffer from a critical problem, which is the lack of a general framework to develop AI-based systems considering dark sides of AI.
In this paper, we developed a new framework to overcome the component selection problem of ISs considering the dark sides of AI. The proposed framework consists of four phases, namely, component analyzing, extracting criteria and weighting, formulating the problem as multiple knapsacks, and finding components. After describing and analyzing components’ attributes via experts in the first phase, dark sides of AI techniques are extracted in second phase through a comprehensive study. Moreover, the AHP method is utilized to compute appropriate weights for components in this phase. In the third phase, the CS problem by considering obtained weights is formulating as a multiple knapsack problem, which is solved by using the learning automata algorithm in the last phase. The main contributions of this paper are as follows:
Discussion of the general concepts of CS problem and its variations;
An extensive and comprehensive study on the dark sides of AI techniques to extract the main technical dark sides;
Proposing a novel framework for the CS problem of ISs that considers the dark sides of AI.
The organization of the paper is as follows: Related works are discussed in
Section 2.
Section 3 discusses the learning automata theory as a solution for the knapsack problem.
Section 4 is dedicated to the proposed framework’s explanation, including its phases. The applicability of the proposed framework was investigated through a case study, i.e., an autonomous vehicle, in
Section 5.
Section 6 is dedicated to managerial implications of the proposed framework. Finally,
Section 7 concludes the paper and suggests the direction for future research.
2. Related Works
Several researchers have been focused on the complexity of CS approaches. For example, CS is defined as the problem of selecting the minimum number of components from a group of components so that their combination meets a set of goals [
42]. It is an NP-complete optimization problem formally showed to be embedded within compensability [
43]. This problem is similar to the cardinality set cover problem where all components have equal costs. Various genetic and heuristic algorithms have been used to solve this problem. However, a different definition is presented in [
44] for the CS problem as the process of modeling an engineering system from OTS components by merging them to form a functional system. For this purpose, there are some generic components and each component can be implemented via a set of components. This problem is defined as the process of choosing particular components from producer’s catalog by considering components’ mutual effects on each other. The genetic algorithm is utilized to solve this problem in [
44]. Two algorithms are proposed in [
45] for the component section problem and the next release problem. The next release problem deals with the selection of a subset of requirements based on their desirability. In this problem, each component is determined via a set of values including anticipated development duration, revenue, and cost.
Although one of the well-known NP-hard problems is the knapsack problem, it can be solved by a pseudo-polynomial algorithm using dynamic programming. Another definition of CS is presented in [
46], where they proved it as an NP-complete problem.
Recently, a fuzzy-based approach is proposed in [
47] for CS by considering both functional and non-functional requirements. The fuzzy clustering groups similar components at each selection step based on the desired requirements. Finally, the authors developed a reservation system on the basis of different requirements to effectively evaluate the proposed model. In [
48] a scorecard-based CS method is proposed based on high-level quality attribute indicators, project health measures, and a context-specific aggregation function to provide an explicit decision (yes or no) for integrators. Kaur et al. [
49] developed a software CS architecture on the basis of the clustering concept. The proposed architecture includes four tiers: component requirements and selection, query and decision, application with clustering, and component clustering. In this architecture, components are clustered based on user defined requirements and their similarities. As a result, the search space, time, and cost of the CS procedure are reduced. According to the exploratory analysis, cost, support for the component, longevity prediction, and level of off-the-shelf fit to a product are the four main attributes of components for industry practitioners in CS [
50].
In addition to software engineering, CS has been used in different domains. For example, in [
33] smart buildings that are equipped with sensors, devices, and automation systems of the smart building have been considered as a very complex component selection task due to the variety of available vendors and technologies. Hence, to decrease the exponential complexity of the CS problem and minimize the search space, the authors developed a multi-step method for analyzing the prioritized criteria.
In the power industry, the CS plays an important role in the performance of the off-grid system. In [
34], the CS for renewable energy systems has been developed based on the total cost and power reliability of the system. The authors leveraged the selection of renewable energy system components to electrify the rural area used for evaluation purposes. Moreover, a multi-variable linear regression in a company with the gradient descent algorithm was used for impact assessment. This approach outperforms the existing methods in terms of optimum selection of components for an off-grid systems.
3. Learning Automata Theory
A field of AI called reinforcement learning focuses on designing ISs that are able to learn optimal policy for decision making in an unknown environments. Among reinforcement learning algorithms, Q-learning and learning automata are well-known. The main difference between these models is that Q-learning invests in the changes of the states in the environment of the learning system, but learning automata theory does not invest in the information of changes related to the environment. Therefore, in some problems reported in engineering and mathematics claiming that formalizing information about the environment is either expensive or impossible, the theory of learning automata can be suitable. In the rest of this section, the theory of learning automata and its applications are explained. In the theory of learning automaton (LA), an intelligent agent is able to make a decision with a self-adaptive manner decision making model [
51]. The learning process of this model is made through repeated interactions with a random environment (
Figure 1). In the theory of learning automata, the learning automata can be classified into two classes: fixed and variable structure [
52]. A variable structure LA can be represented by a triple
where
is the set of feedbacks of the environment,
is the set of actions, and
L is the learning algorithm. Let
and
denote the action selected by LA and the probability vector defined over the action set at instant k, respectively.
The
a and
b indicate the reward and the penalty parameters, and
r indicates the number of actions that can be selected by LA. At step
n, the action is selected based on the action probability vector. Then, the action probability vector
is updated by the linear learning algorithm given in Equation (
1), if the selected action
is rewarded by the environment, and it is updated as given in Equation (
2) if the taken action is penalized. If
, the recurrence Equations (1) and (2) are called the linear reward penalty (LRP) algorithm. More information can be found in [
52]:
In recent years, LA has been used in different applications, such as cognitive networks [
53], computer networks [
54], and the shortest-path problem [
55] to mention a few.
4. Proposed Framework
We designed a new framework in which a process to select components for ISs considering the dark sides of AI is given. ISs that are considered in this section can be self-driving cars, intelligent drones, and industrial robots, but they are not limited to a specific domain. In this framework, a set of components are provided to design a software package based on the component-oriented design.
Table 1 introduces the symbols that are used to formally explain the phases of the proposed framework.
This framework consists of four phases as described below and illustrated in
Figure 2.
Component analyzing: according to the information about the component set (CO) and attributes of the components, F set and appropriate components for each function are determined by the expert.
Extracting criteria and Weighting: in this phase, we extract the required criteria on the basis of the dark sides of AI to organize the AHP procedure and compute the weight for each component.
Formulating the problem as multiple knapsacks: in this phase, the problem of CS is mapped to multiple knapsack problems based on the generated weights in the previous phase.
Finding components: In this phase, learning automata theory is used to solve the knapsack problem, and the results are utilized to determine the S set. It is worth noting that there is a possibility to apply different solver algorithms in this phase of the proposed framework.
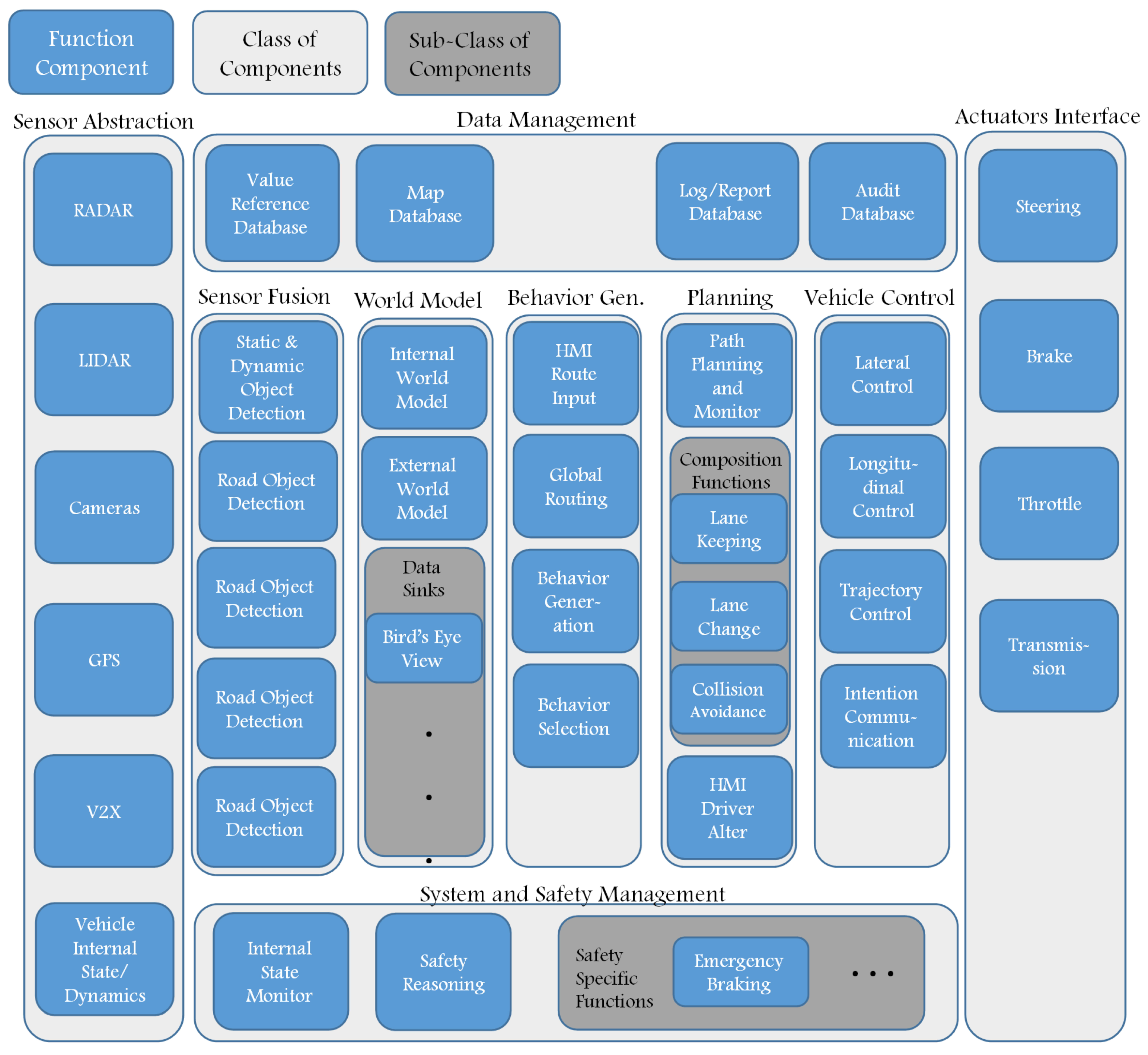
Figure 3 shows an example of the essential components in autonomous vehicles [
12]. This example illustrates how component-based software is able to manage different parts of autonomous vehicles. In this example, finding appropriate components considering safety, privacy, and energy consumption that are relevant criteria to the dark sides of AI is a challenging problem. This example will be simplified and used as a case study to show the applicability of the proposed framework in
Section 4.
Detailed explanations about phases are given in the rest of this section.
4.1. Component Analyzing
In the component analyzing phase, we generate the F set, which contains appropriate components for each function along with the corresponding attributes for each component.
4.2. Extracting Criteria and Weighting
In this phase, some criteria considering the dark sides of AI are extracted and then the AHP mechanism is used to calculate the weights of components. This phase is organized into two sub-phases as follows.
Extracting criteria: wherein about 20 papers focusing on the dark sides of AI are reviewed and then 12 criteria are extracted (refer to
Section 4.2.1 for more details).
Weighting: during this sub-phase, the AHP mechanism is organized to find the weights of components considering criteria extracted in the previous sub-phase (refer to
Section 4.2.2 for more details).
In the next two sub-sections, the above sub-phases are explained in more detail.
4.2.1. Extracting Criteria
Although AI provides significant changes and improvements for networked digital business and facilitates smart services and digital transformation, there are plentiful dark sides of AI that present tremendous risks for individuals, organizations, and society. To address these dark sides, the first and most important step is to identify and classify such criteria. Therefore, a list of potential AI dark sides is as follows:
The above terms are explained in more detail in the rest of this section.
- 1.
Energy Consumption. One of the dark sides of most machine learning algorithms is high energy consumption. Nowadays, the majority of machine learning algorithms rely on iterative policies instead of fixed policies, which leads to high energy consumption and energy wastage. Moreover, this problem is accelerated by a growing number of learning models that require more iterations for learning purposes. For example, deep learning methods require the high computational power of GPUs more than other methods. Environmental pollution and global warming are reported as other side effects of high computational power usage [
17].
- 2.
Data Issues. A category of AI invests in data-driven algorithms to construct machine learning models. It should be noted that in many situations, there are many problems in data that lead to many difficulties in data-driven machine learning. Some of these problems are as follows.
Big Data: The size of data sets gathered in a wide range of systems such as IoT and AR is increasing. With a huge amount of data, defining machine learning algorithms that are able to operate in an online fashion leads to a challenging problem [
18]. We can use wide range of methods, such as sampling, distributed processing, and parameter estimation to obtain required information from data.
Data incompleteness: Incomplete data refers to a challenging problem in the machine learning algorithms. Incomplete data in every data set may mislead the algorithm to learn inappropriate models. This challenge creates uncertainties during data analysis if we do not consider incomplete data during the data analysis step. Many imputation methods exist for this purpose. An initial approach is to fill a training set with the most frequently observed values or to build learning models to predict possible values for each data field, based on the observed values of a given instance [
18].
Other issues in this domain are data heterogeneity, data insufficiency, data uncertainty, data originality, data inaccurateness, imbalanced data, data dynamicity, and high dimensional data [
18,
19,
56,
57].
- 3.
Security and trust. Security and trust are two important issues that have received much attention in recent years. In ISs, these issues have two dimensions as follows. Most of the papers [
58,
59] only focused on utilizing ISs to design secure systems. It is worth noting that every piece of software, including ISs, may be hacked or cracked. These issues are not considered by AI experts because the development of ISs in critical systems is in the early stages. For example, in data-driven machine learning, we trust data and a model will be constructed based on it. When data are untrusted, the machine learning model is also untrusted. During the software lifecycle, a malicious person may swap trusted data with untrusted data, and this phenomenon may occur in every data-driven approach. An emerging field called adversarial machine learning was the first attempt to solve some security problems in data-driven machine learning [
20]. For other AI-based methods such as genetic algorithms, we may consider attack mechanisms to manipulate the evolutionary processes.
- 4.
Privacy. The privacy issue in AI has different dimensions. In recent years, many ISs have been constructed based on big data analyses, data sciences, and data-driven methods. All of these methods are fed by the data of a huge number of users. During the execution of these methods, three different roles are possible, as explained below.
A role for data imputation and data owners (or contributors).
A role for data analyzers and model manipulators.
A role for result visualizers.
Usually, a programmer has all those roles during designing ISs. However, in industrial projects, the mentioned roles may be played by different entities and these entities may not be trusted considering privacy issues. In order to solve this problem, many efforts have been made by researchers. Federated learning is one of these efforts [
21]. Federated learning is a machine learning technique that trains an algorithm across multiple decentralized computers, without exchanging data among them, thereby allowing one to address critical issues such as data privacy, data security, and data access rights.
- 5.
Fairness. In AI, a given algorithm is said to be fair if its results are independent of some variables, such as gender, ethnicity, and sexual orientation. The rationale behind this issue is that many people have disabilities and gender must not add rights to users. This issue is recently reported as a hot topic in machine learning, and papers such as [
22,
23] are reported in the literature depicting modified machine learning algorithms (removing bios considering special fields) while considering this issue. This issue becomes more challenging when some features such as gender and race are sensitive in the culture of humans. Therefore, well-known companies such as IBM, Facebook, and Google are going to introduce a machine learning library considering this issue.
- 6.
Safety. AI has shown to be successful algorithms at smart managing systems. In mission-critical, real-world environments, there is little tolerance for failure that can cause damaging effects on humans and devices. In these environments, current approaches are not sufficient to support the safety of humans. Considering this issue, two main approaches are reported in the literature. In the first approach proposed in [
24,
25], a system is defined to control the output of an IS while considering the safety of humans. In the second approach proposed in [
60], computation in the internal parts of an intelligent agent will be manipulated using some weights considering the safety of humans.
- 7.
Beneficial. In the near future, ISs will make better decisions than humans in many domains, including computer vision. An IS can diagnose many diseases using image processing techniques that are more efficient than human vision. For more than one decade, humans have trained to extend the works of their ancestors in simple domains such as piping and constructing a city. These jobs can be easily done by ISs and these systems will control many things in the near future. In some situations, an IS may decide to do an action that is harmful for humans. Most of the existing systems with deterministic decision-making mechanisms may easily execute harmful decisions without considering human preferences. In these situations, beneficial AI computation can be applied. With this theory, a system is designated to behave in such a way that humans are satisfied with the results. In these systems, the agent is initially uncertain about what the preferences of humans are, and human behavior will be used to extract information about human preferences [
26].
- 8.
Predictability. One of the most important issues in designing ISs is predictability. This issue becomes more challenging when many management algorithms in different fields utilize ISs. In designing ISs, many factors exist which destroy the predictability capability. Some of these factors are explained as follows. Paradox and ambiguity are two factors that exist in image, voice, and text, and therefore a system with these types of inputs cannot present a predictable output. Some theorems in computer sciences, such as Turing undecidability, the Gödel theorem, and the strange loop theorem are used to prove unpredictable behavior in most of the systems [
27,
28,
61].
- 9.
Explainable AI. Explainable AI refers to AI methods such that the results of the solution obtained by them can be understood by human experts [
29]. Many of the AI-based systems that are known as best problem solvers, such as deep learning, only focus on a mathematically-specified goal system determined by the designers [
62]. Therefore, the output of the system may not be understood by a human agent. This problem can be very challenging in military services and healthcare because the rationale behind a decision should be evaluated by a human agent. In the literature, there are some efforts to solve this problem [
63].
- 10.
Complexity. The complexity of ISs is increasing day by day. The primary versions of ISs invest in a limited set of solutions to do their jobs and therefore their complexity is limited to simple algorithms. Nowadays, the existing ISs utilize numerous learning algorithms. The complexity related to the size and format of data is discussed in
Section 4.2. In addition to the mentioned issues, many challenges related to the complexity of input, computation, memory, and output in the ISs are reported in the literature [
30]. Novel approaches to solve complex problems in complex systems rely on digital twin technologies [
64].
- 11.
Monopoly. Many AI-based solutions require huge computational power. There are a few companies (IBM, Amazon, and Microsoft) and countries which invest in AI and high computational power devices. For example, a few countries are pioneers in quantum computation, which is one of the enablers of artificial general intelligence and super-intelligence. This capability may lead to the appearance of a monopoly in the scope of AI. Those companies which can execute many AI-based algorithms are able to do many valuable activities such as developing new drugs and treatments for diseases.
- 12.
Responsibility Challenges. AI-based systems, such as self-driving cars, will act autonomously in our world. In many fields, ISs will make better decisions than humans eventually. A challenging question in these systems such as self-driving cars is: who is liable if a self-driving car is involved in an accident? This problem has many dimensions. It seems that many laws must be defined considering those ISs that are involved in decision making processes. From an algorithmic perspective, frameworks will be needed to extract the responsibility of all entities that are involved in decision making processes. In [
31], some interesting points related to responsibility issues are covered for a specific case study.
4.2.2. Weighting
In this phase, for each set of components that are suitable for a function, weights are computed. Decision-making in CS can be defined as a problem of multi-criteria decision analysis by considering the dark sides of AI. In this section, the analytic hierarchy process (AHP) is utilized to compute each component’s weight for the desired function. Since AHP considers decision maker’s subjectivity in determining the preferences for evaluation objectives and also there is a correlation between the criteria, the AHP method is utilized as weighting method for the proposed case study. The AHP can be used when the decision-making process is faced with several options and decision criteria. The desired criteria can be quantitative and qualitative. A similar approach is utilized in [
65] for mobile robot path planning. AHP uses a hierarchy structure in which the desired problem is located at the top; the criteria and the solution alternatives are located at the intermediate and bottom levels, respectively. The AHP procedure can be summarized as the following steps:
Step 1—Problem hierarchy: A hierarchy by considering the desired goal (at the top layer), criteria (at the intermediate level), and solution alternatives (at the bottom level) is created. Each criterion can be divided into sub-criteria based on the requirements. The criteria are used by decision makers to set priorities.
Step 2—Set priorities for each criterion: The decision maker assigns a numerical value to each criterion based on preferences. These numerical values can be assigned based on a scale that is presented in
Table 2. This scale is proposed in [
66] and its effectiveness has been validated by multiple researchers. Paired comparison is performed by the decision maker to set priority by assigning desired weights. For this purpose, a paired comparison matrix should be created in which
determines the comparison result between
and
. It is worth noting that consistency ratio should be computed for each paired comparison matrix in order to prove its consistency and its value should be less than 0.1. The procedure for computing the consistency ratio (CR) is as follows. Equation (
3) is used to calculate the consistency index (CI) in which
n and
denote the number of criteria and eigenvalue of the pairwise comparison matrix, respectively.
After calculating the CI value, Equation (
4) is utilized to compute the CR in which the random consistency (RC) index is determined by
Table 3.
Detailed information regarding consistency ratio computation can be found in [
67].
Step 3—Define priorities for solution alternatives: this step is the same as step 2, but the paired comparison should be performed between solution alternatives to create preferences based on predefined criteria.
Step 4—Calculate the final priority of solution alternatives: the total weight for the criteria and solution alternatives is calculated from the multiplication of the local weight by the total weight of the immediately superior criterion. The totality of the final weights of the solution alternatives is computed with respect to each criterion.
4.3. Formulating Component Selection as a Multiple Knapsack Problem
In this phase, the CS problem is considered as a
multiple knapsack problem (MKP). MKP is a strongly NP-hard combinatorial optimization problem that has many applications, such as resource allocation, financial planning, stock allocation, and shipment loading. MKP includes
m knapsacks with capacities of
and
n items (components) (
).
item has an associated profit,
and occupies
value (total weight) of
knapsack. The goal is to fill knapsacks with a subset of items so that the maximum profit is achieved, and the total weight of a backpack’s items does not exceed its capacity. The MKP can be defined as follows:
4.4. Finding Components: A Learning Automata-Based Solution for the Component Selection
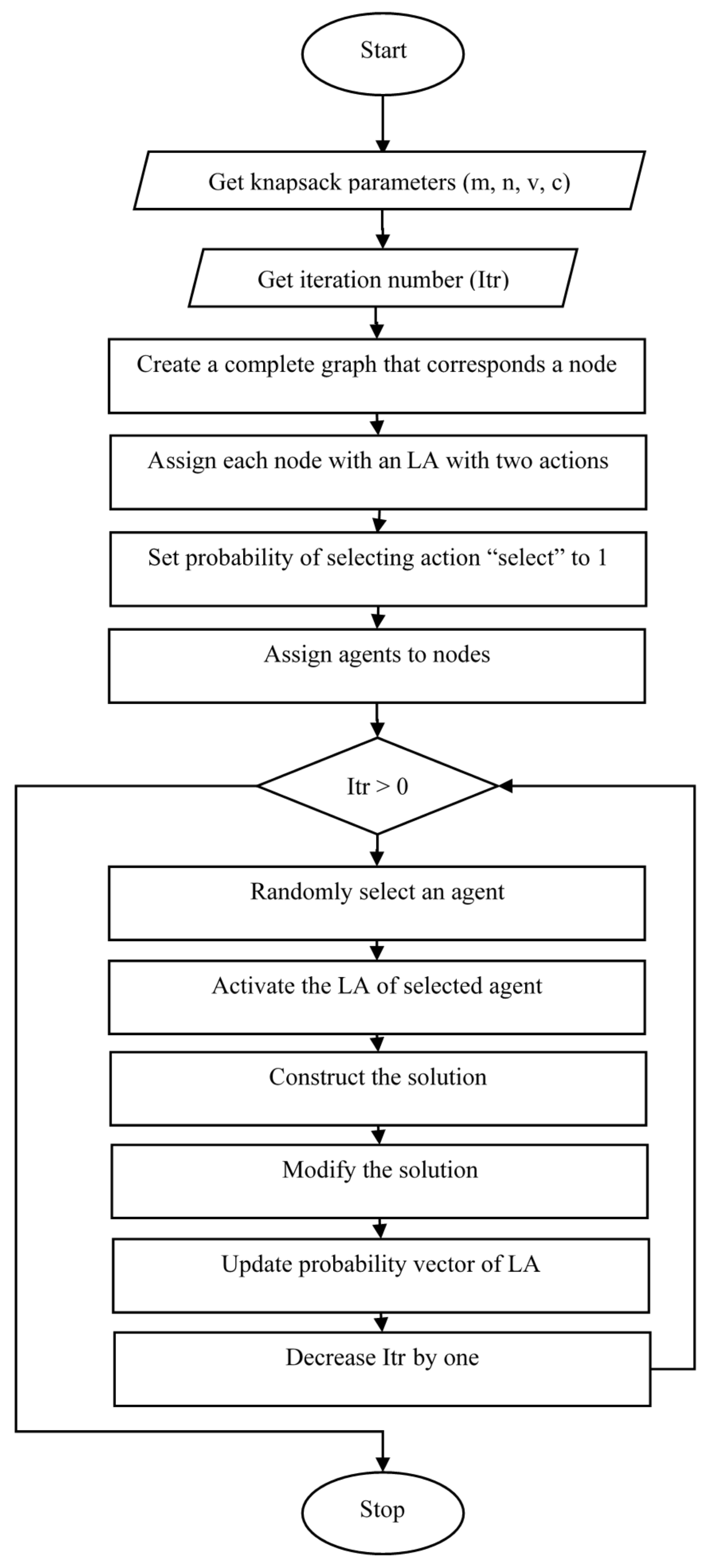
In this phase, in order to find the solution to the knapsack problem which formulated in the previous phase, a learning automata-based algorithm is utilized. This algorithm is reported in [
68]. This algorithm gets iteration number (
), reward (
a), and penalty (
b) parameters and then searches with a solution space-based probabilistic search mechanism to find an appropriate solution. In this algorithm, the problem is modeled as a complete graph where each node of the graph corresponds to a component in the knapsack problem. Each node of the graph is equipped with a learning automaton with two actions of selecting either item to be placed in a knapsack or not. In this mechanism, agents are defined to activate learning automata. In each iteration of the algorithm, there are a few agents, each of which creates a solution. Initially, an agent is randomly placed on one of the graph nodes and activates the learning automaton of that node. Whenever a learning automaton is activated, it selects one of its two actions according to the probability vector of its actions. Afterward, the solution set is constructed based on the action chosen by the learning automaton. Finally, the solution set is modified considering some criteria. This process is repeated based on the predefined iteration number. The flowchart of this algorithm is represented in
Figure 4.
Remark 1. Although in this phase, we have used the learning automata approach to solve the knapsack problem, every other mechanism that is able to solve this problem can be used in this framework as an alternative mechanism.
Remark 2. The proposed method has four phases. Phases 1 and 3 will be done by a designer. In these phases, some simple decisions are made by designers, and therefore computational complexity is not a critical matter in them. Computational complexities of other parts are studied as below.
Therefore, the time complexity of the proposed method is .
Remark 3. The proposed method presents a systematic approach for constructing AI-based software considering the dark sides of AI. The proposed method is based on a well-known software engineering perspective that is component based systems. This method is more generalized than ad-hoc solutions such as those reported in [70] that only invest in solving a specific problem. 5. Case Study
In this case study, autonomous vehicles are considered as well-known ISs. Autonomous vehicles are designated based on a fusion of an IS into a car with sufficient sensors and actuators. As reported in [
12], the design of autonomous vehicles can be done using component oriented design, and therefore the problem of CS in this domain is a well-defined problem for the proposed framework in this paper.
Figure 5 is an abstraction of
Figure 3 that shows the functional components of an autonomous vehicle in which our selected components for this case study are shown in gray. It is desired to select appropriate components for road object detection, dynamic object detection, global routing, and path planning and trajectory control.
In this case study, we considered six components,
, which are described in
Table 4. In the rest of this part, the phases of the proposed framework for this case study are applied.
5.1. Component Analysis Phase
In this phase, functions and component attribute sets are extracted.
Table 4 represents some information about all components. Moreover, it is assumed that two functions (
) should be operated by the components as described below.
Object detection (
): This function is explicitly mentioned in [
12] that should be covered by road object detection and dynamic object detection components. It is assumed that the
.
Function approximation (
): This function is implicitly mentioned in [
12] that should be covered by some components such as global routing, path planning, and trajectory control components. It is assumed that the
.
5.2. Criteria Extraction and Weighting
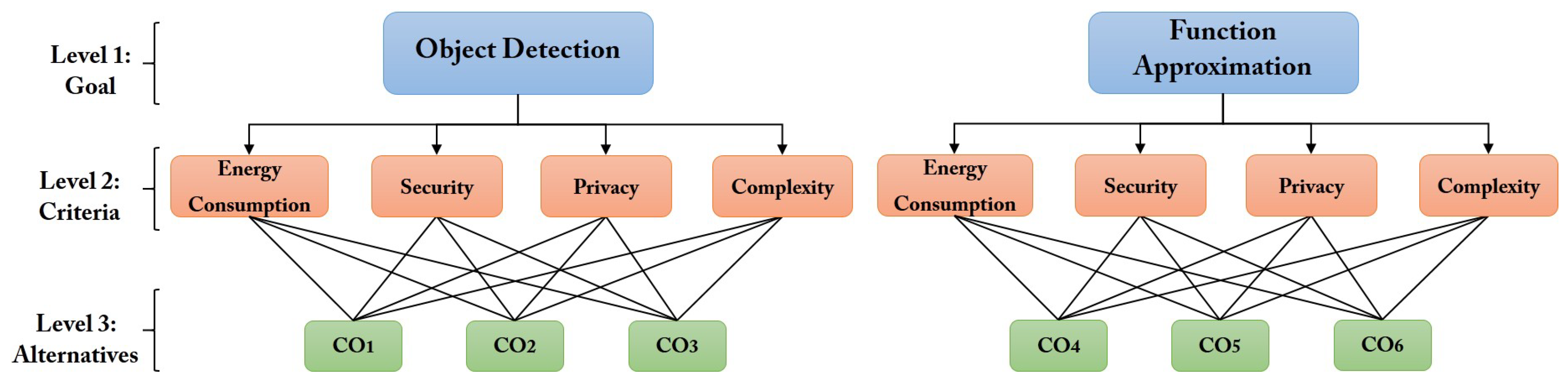
In this phase, four criteria,
{Energy Consumption, Security, Privacy, Complexity}, are extracted from dark sides of AI which are discussed in
Section 4.2.1. The weighting procedure based on AHP for determining the weights of components is explained in the rest of this phase. As mentioned before, creating a hierarchy for the decision is the first step of AHP analysis. The hierarchy proposed for our use case is depicted in
Figure 6. Object detection and function approximation are considered as two main goals (functions); and energy consumption, security, privacy, and complexity are considered as decision criteria. Alternatives (components) are described in
Table 4. Components 1, 2, and 3 are alternative ways to reach object detection goal, and three other components are utilized as alternatives for the second goal (function approximation).
In order to drive weights for the criteria, a pairwise comparison was created for each goal via comparison matrix as shown in
Table 5 and
Table 6. These matrices were designed in the form of a questionnaire that was answered by 28 AI and software engineering experts. An example of a completed questionnaire for object detection goal is illustrated in
Table 7 in which the selected preferences by one of the experts are highlighted. The numerical rating description is considered the same as
Table 2. Experts were asked to keep in mind the following proposition while answering the questionnaire: In pairwise comparisons, when comparing two criteria, if the preference is with the item on the left (criterion
i), one of the left-hand side numerical cells of the table should be marked, and if the preference is with an item on the right (criterion
j), one of the right-hand side numerical cells of the table should be marked according to the scale mentioned in
Table 2. As can be seen in the pairwise comparison matrices (
Table 5 and
Table 6), the numerical values at the bottom of the matrices are inversely proportional to the numerical values at the top of the matrix. The geometric mean of responses was used to combine pairwise comparisons. Weights were then normalized to give a better perspective from criteria.
The third step is driving relative preferences regarding alternatives by considering each criterion. A questionnaire, which is identical to the criteria questionnaire, was designed and completed by AI and software engineering experts to drive alternatives preferences with respect to each criterion. There were three alternatives and four criteria for each goal in our case study. Hence, four comparison matrices corresponding to the following comparisons were required for each goal. For example, the following comparisons were required for the object detection function:
By considering the energy consumption criterion: compare
,
, and
(the results are represented in
Table 8).
By considering the security criterion: Compare
,
, and
(the results are represented in
Table 9).
By considering the privacy criterion: Compare
,
, and
(the results are represented in
Table 10).
By considering the complexity criterion: Compare
,
, and
(the results are represented in
Table 11).
The same process took place for the second goal and the results are represented through
Table 12,
Table 13,
Table 14 and
Table 15. The geometric mean of responses and normalization were used for weight computation. The obtained results are summarized in
Table 16.
The final step is to calculate the final weight of the alternatives. For this purpose, the relative weight matrix of the alternatives (
Table 16) must be multiplied by the criteria weight matrix (
Table 5 and
Table 6), which is given below for each function:
Function 1: Object Detection
.
.
.
Function 2: Function Approximation
.
.
.
The value (total weight) of each component is represented in
Table 17.
It is worth noting that the CR was under 0.1 for our experimental case study.
5.3. Problem Formulation
In this phase, according to the weights of components, the knapsack problem is customized as follows. We assumed the profit values of all components equal to one. Equation (
7) is modified as follows since one of the components should be selected to perform the desired function.
In addition, parameters m and n are set to 5 and 6, respectively. This means that there are 5 knapsacks.
5.4. Finding Components
In this phase, in order to find the solution to the knapsack problem which formulated in the previous phase, a learning automata-based algorithm is utilized. The reward and penalty parameters of the learning automata are set according to [
68]. The final solution set,
S, is
in which
is selected for functions 1, and
is selected for function 2. In order to more clarification regarding the findings, some other scenarios are considered in
Appendix A.
7. Conclusions
In this paper, IS design is represented as a CS problem. ISs utilize various AI-based functions to perform the desired functions. A new framework that considers the dark sides of AI techniques in its proposed solution for ISs’ CS problem is proposed in this paper. This framework consists of four phases, namely, component analyzing, extracting criteria and weighting, formulating the problem as multiple knapsacks, and finding components. In the first phase, components’ attributes are described and analyzed via experts by considering corresponding functions. In order to extract the criteria, an extensive and comprehensive study on the dark sides of AI techniques is conducted. Dark sides may have intersections among themselves, but each side refers to some unique challenges. Since there is a correlation between the criteria, the AHP method is utilized as a weighting mechanism. After obtaining components’ weights, the CS problem is formulated as a multiple knapsack problem, which is solved by using the learning automata algorithm in the last phase, called finding components. The applicability of the proposed framework was investigated through a case study. The autonomous vehicle was considered as an example case study by taking into account its various functional components, including object detection, path planning, and trajectory control. Six components along with four criteria (energy consumption, security, privacy, and complexity) were analyzed and weighted by 28 AI and software engineering experts via the AHP method. The related multiple knapsack problem was solved by the learning automata algorithm assigning an appropriate component to the desired function. It should be noted that a wide range of problems related to technical aspects of dark sides was covered in this paper; and the dark sides of AI may affect other non-technical issues, such as political, social, and financial fields that can be considered as future work.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





