
Modeling the Conditional Distribution of Co-Speech Upper Body Gesture Jointly Using Conditional-GAN and Unrolled-GAN


Abstract
:1. Introduction
2. Related Work
2.1. Generative Adversarial Nets (GAN)
2.2. Gesture Generation
3. Materials and Methods
3.1. Problem Formulation
3.2. Feature Extraction
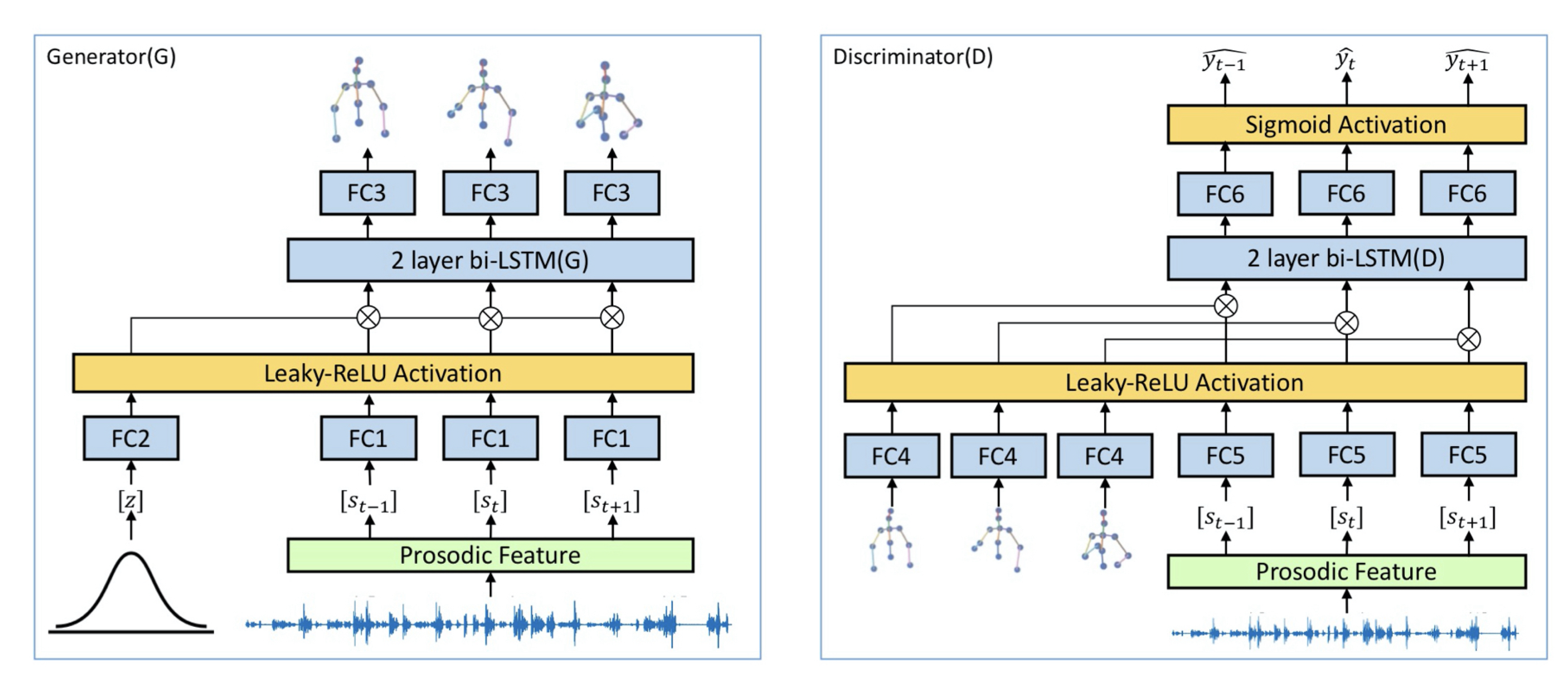
3.3. Methodology
| Algorithm 1. Algorithm for variating noise vectors. |
|
| Algorithm 2. Algorithm for training the proposed model. |
|
3.4. Corpus
3.5. Implementation
4. Results
4.1. Baseline
4.2. Quantitative Evaluation
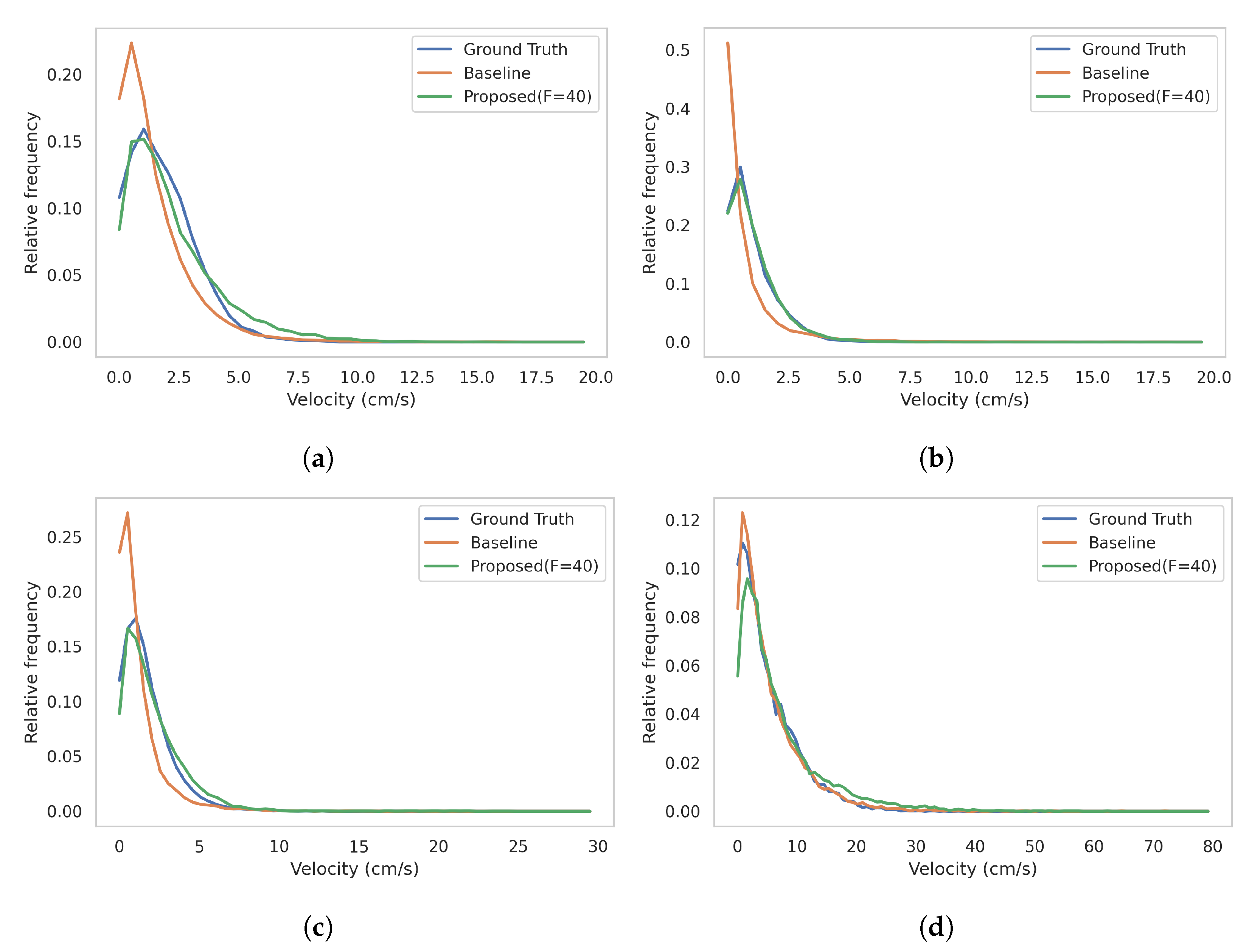
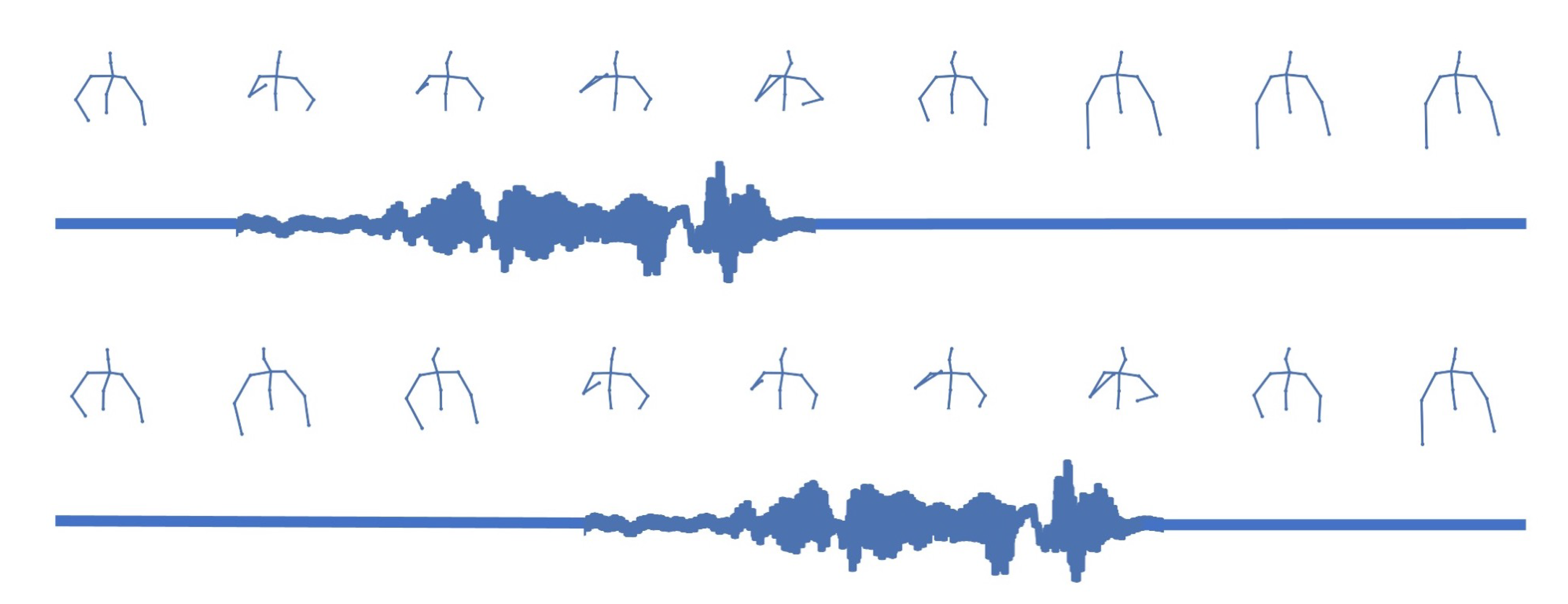
4.3. Motion Dynamics Distribution
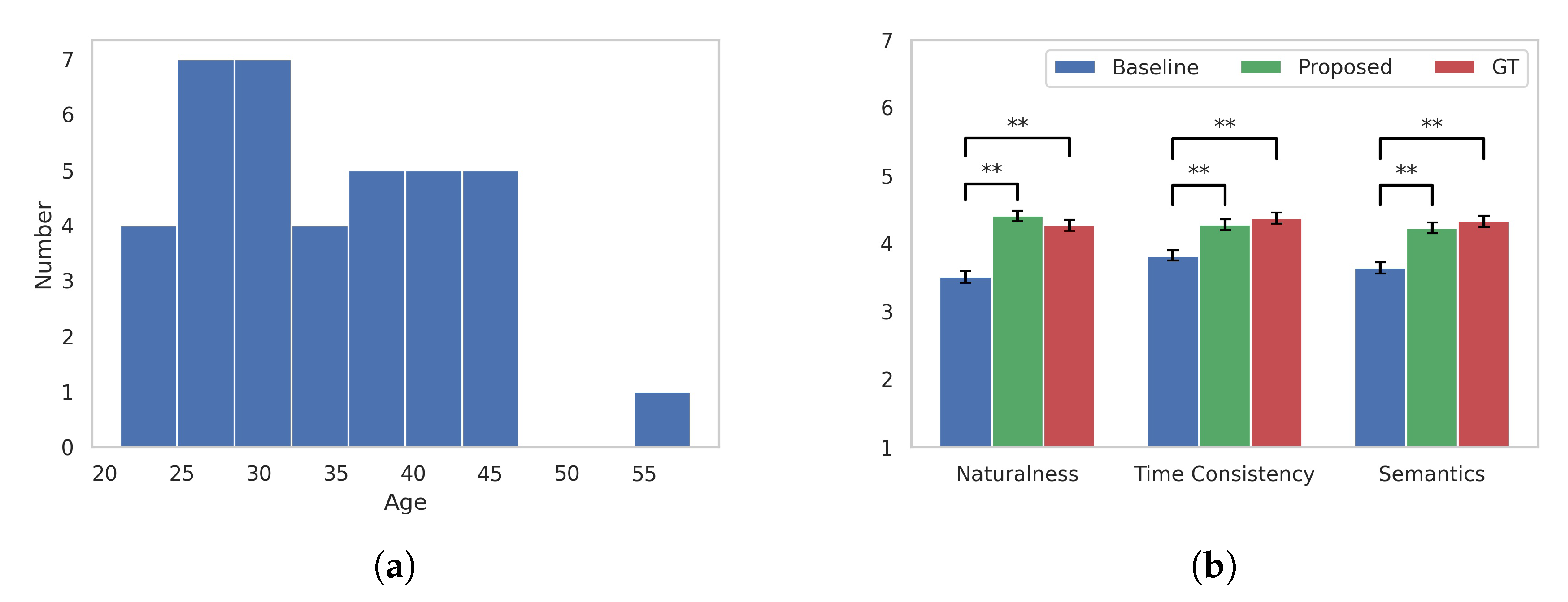
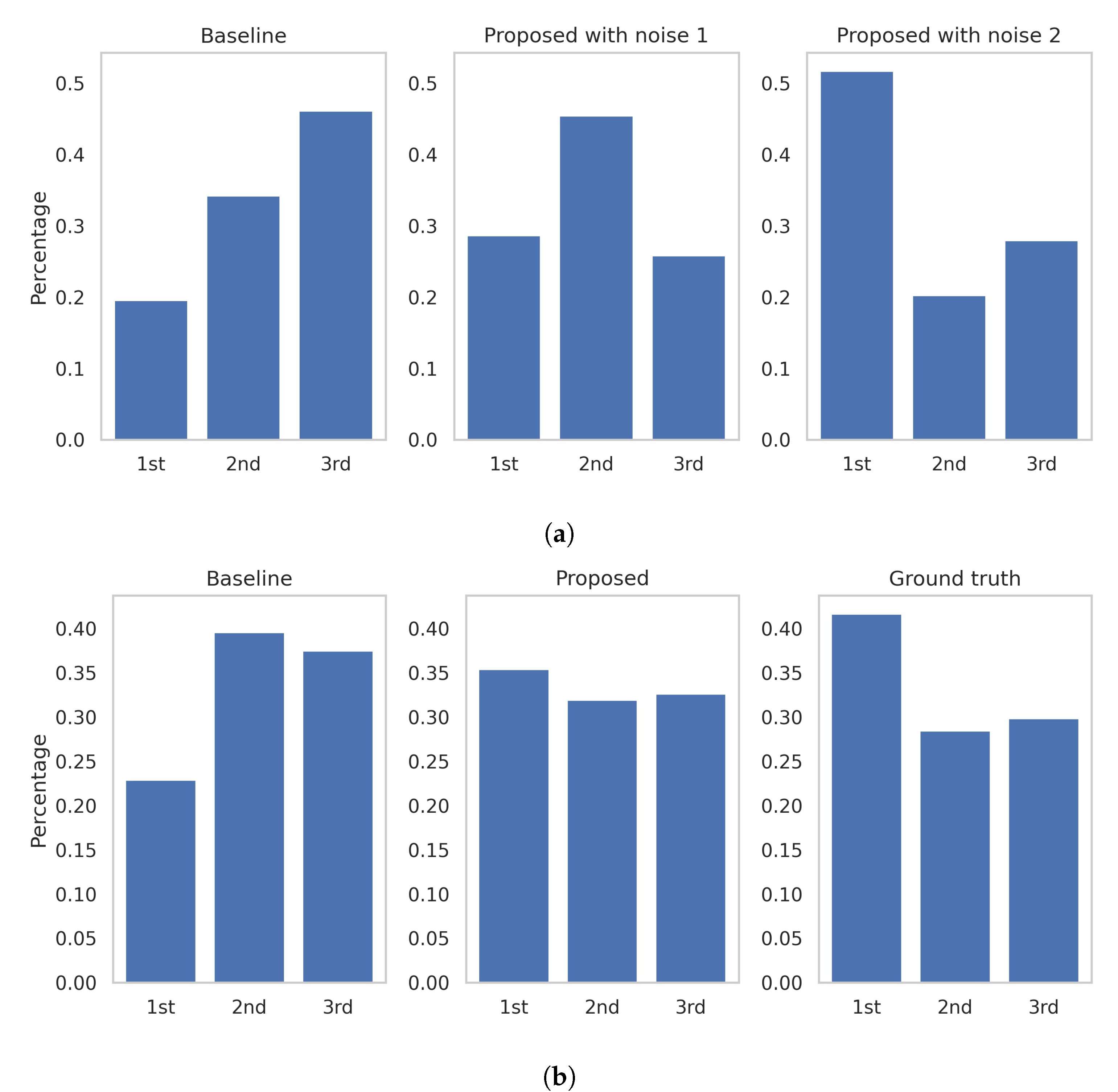
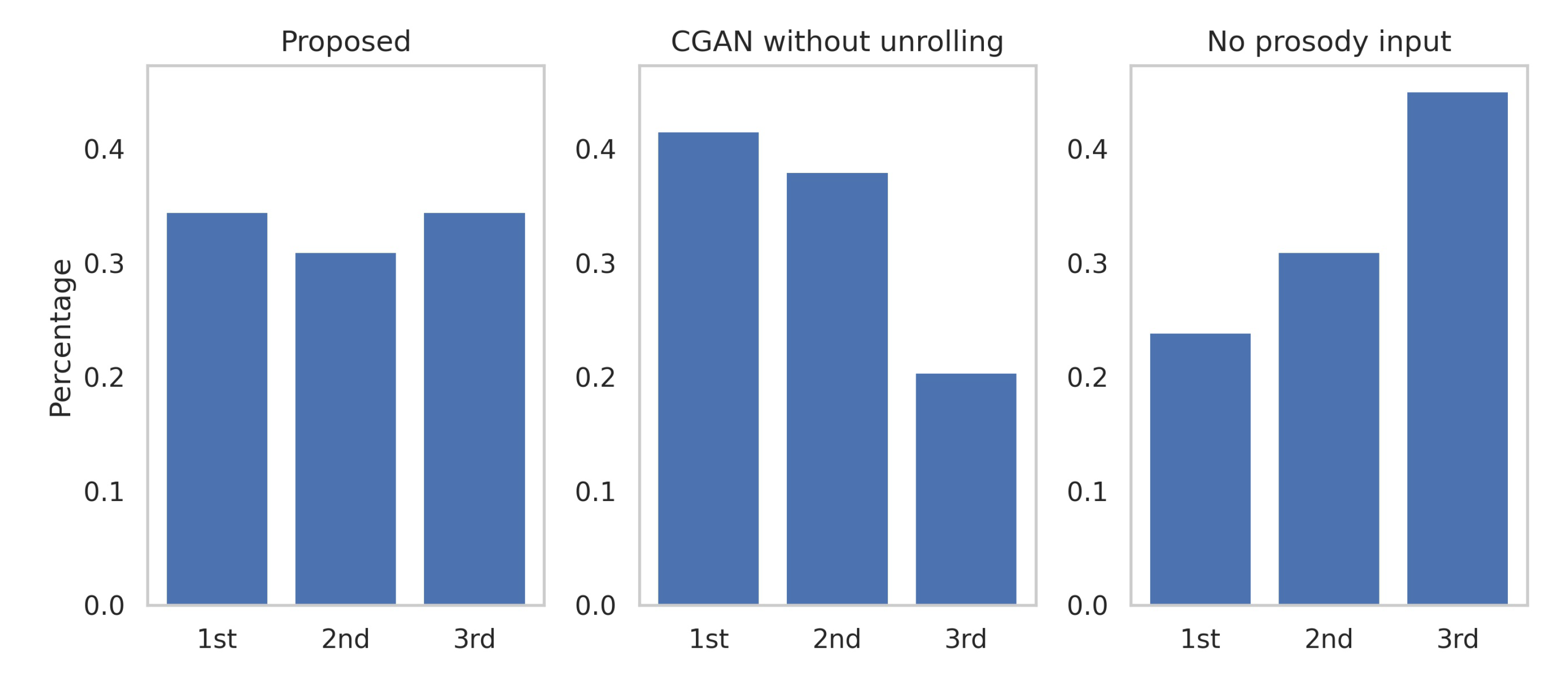
4.4. User Study
5. Discussion
5.1. Inappropriateness of Using Euclidean Distance as a Loss Function
5.2. Unrolling for More Variation
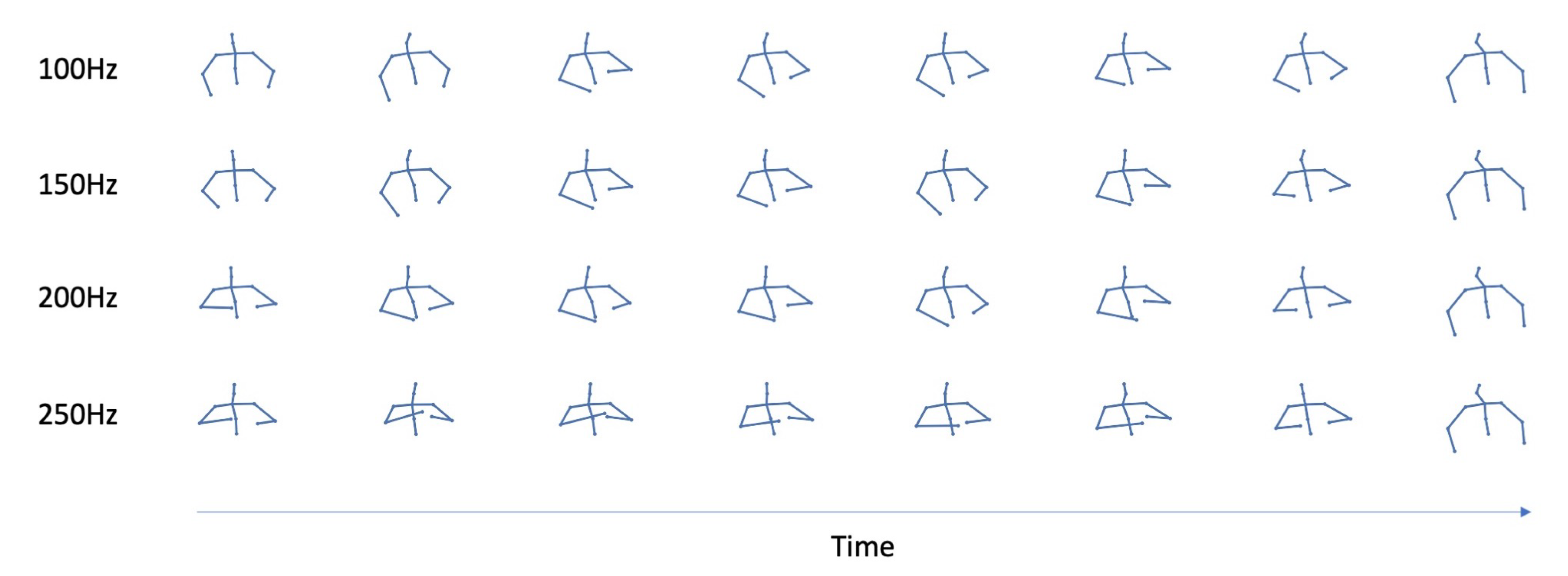
5.3. The Role of the Noise Vector
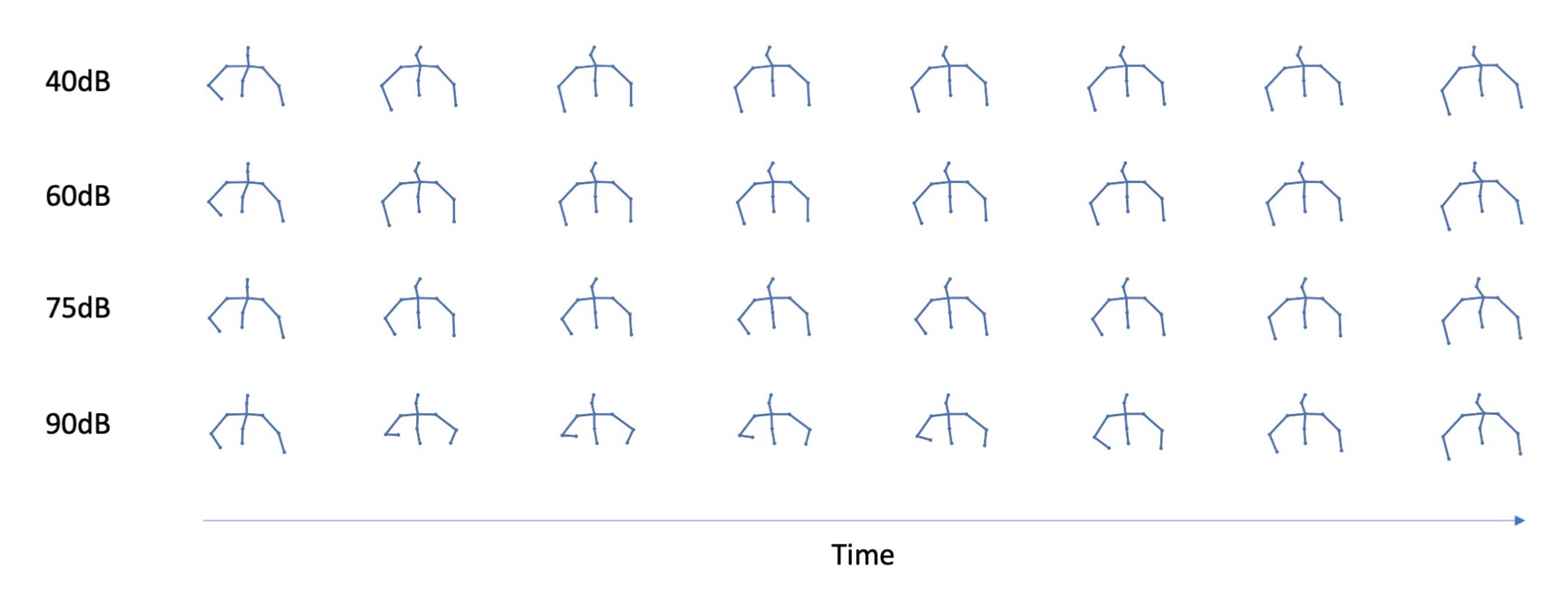
5.4. The Role of Prosody as a Condition
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kendon, A. Gesture: Visible Action as Utterance; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- McNeill, D. Gesture and thought; University of Chicago Press: Chicago, IL, USA, 2008. [Google Scholar]
- Iverson, J.M.; Goldin-Meadow, S. Why people gesture when they speak. Nature 1998, 396, 228. [Google Scholar] [CrossRef] [PubMed]
- Hasegawa, D.; Kaneko, N.; Shirakawa, S.; Sakuta, H.; Sumi, K. Evaluation of speech-to-gesture generation using bi-directional LSTM network. In Proceedings of the 18th International Conference on Intelligent Virtual Agents, Sydney, Australia, 5–8 November 2018; pp. 79–86. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Sadoughi, N.; Busso, C. Novel realizations of speech-driven head movements with generative adversarial networks. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 6169–6173. [Google Scholar]
- Metz, L.; Poole, B.; Pfau, D.; Sohl-Dickstein, J. Unrolled generative adversarial networks. arXiv 2016, arXiv:1611.02163. [Google Scholar]
- Cassell, J. A framework for gesture generation and interpretation. In Computer Vision for Human-Machine Interaction; Cambridge University Press (CUP): Cambridge, UK, 1998; pp. 191–215. [Google Scholar]
- Hartmann, B.; Mancini, M.; Pelachaud, C. Implementing expressive gesture synthesis for embodied conversational agents. In International Gesture Workshop; Springer: Berlin/Heidelberg, Germany, 2005; pp. 188–199. [Google Scholar]
- Baumert, D.; Kudoh, S.; Takizawa, M. Design of conversational humanoid robot based on hardware independent gesture generation. arXiv 2019, arXiv:1905.08702. [Google Scholar]
- Ishi, C.T.; Machiyashiki, D.; Mikata, R.; Ishiguro, H. A speech-driven hand gesture generation method and evaluation in android robots. IEEE Robot. Autom. Lett. 2018, 3, 3757–3764. [Google Scholar] [CrossRef]
- Bergmann, K.; Kopp, S. GNetIc–Using bayesian decision networks for iconic gesture generation. In Proceedings of the International Workshop on Intelligent Virtual Agents, Amsterdam, The Netherlands, 14–16 September 2009; Springer: Berlin/Heidelberg, Germany, 2009; pp. 76–89. [Google Scholar]
- Sadoughi, N.; Busso, C. Speech-driven animation with meaningful behaviors. Speech Commun. 2019, 110, 90–100. [Google Scholar] [CrossRef] [Green Version]
- Chiu, C.C.; Marsella, S. How to train your avatar: A data driven approach to gesture generation. In Proceedings of the International Workshop on Intelligent Virtual Agents, Reykjavik, Iceland, 15–17 September 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 127–140. [Google Scholar]
- Ishii, R.; Katayama, T.; Higashinaka, R.; Tomita, J. Generating Body Motions Using Spoken Language in Dialogue. In Proceedings of the 18th International Conference on Intelligent Virtual Agents (IVA ’18), Sydney, Australia, 5–8 November 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 87–92. [Google Scholar] [CrossRef]
- Sargin, M.E.; Aran, O.; Karpov, A.; Ofli, F.; Yasinnik, Y.; Wilson, S.; Erzin, E.; Yemez, Y.; Tekalp, A.M. Combined gesture-speech analysis and speech driven gesture synthesis. In Proceedings of the 2006 IEEE International Conference on Multimedia and Expo, Toronto, ON, Canada, 9–12 July 2006; pp. 893–896. [Google Scholar]
- Ferstl, Y.; McDonnell, R. Investigating the use of recurrent motion modelling for speech gesture generation. In Proceedings of the 18th International Conference on Intelligent Virtual Agents, Sydney, Australia, 5–8 November 2018; pp. 93–98. [Google Scholar]
- Yoon, Y.; Ko, W.R.; Jang, M.; Lee, J.; Kim, J.; Lee, G. Robots learn social skills: End-to-end learning of co-speech gesture generation for humanoid robots. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 4303–4309. [Google Scholar]
- Kucherenko, T.; Jonell, P.; van Waveren, S.; Henter, G.E.; Alexanderson, S.; Leite, I.; Kjellström, H. Gesticulator: A framework for semantically-aware speech-driven gesture generation. arXiv 2020, arXiv:2001.09326. [Google Scholar]
- Kucherenko, T.; Hasegawa, D.; Henter, G.E.; Kaneko, N.; Kjellström, H. Analyzing input and output representations for speech-driven gesture generation. In Proceedings of the 19th ACM International Conference on Intelligent Virtual Agents, Paris, France, 2–5 July 2019; pp. 97–104. [Google Scholar]
- Ferstl, Y.; Neff, M.; McDonnell, R. Multi-objective adversarial gesture generation. Motion Interact. Games 2019, 1–10. [Google Scholar] [CrossRef]
- Ginosar, S.; Bar, A.; Kohavi, G.; Chan, C.; Owens, A.; Malik, J. Learning individual styles of conversational gesture. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3497–3506. [Google Scholar]
- Ahuja, C.; Lee, D.W.; Nakano, Y.I.; Morency, L.P. Style Transfer for Co-Speech Gesture Animation: A Multi-Speaker Conditional-Mixture Approach. arXiv 2020, arXiv:2007.12553. [Google Scholar]
- Alexanderson, S.; Henter, G.E.; Kucherenko, T.; Beskow, J. Style-Controllable Speech-Driven Gesture Synthesis Using Normalising Flows. In Computer Graphics Forum; Wiley Online Library: Hoboken, NJ, USA, 2020; Volume 39, pp. 487–496. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Takeuchi, K.; Kubota, S.; Suzuki, K.; Hasegawa, D.; Sakuta, H. Creating a gesture-speech dataset for speech-based automatic gesture generation. In Proceedings of the International Conference on Human-Computer Interaction, Vancouver, BC, Canada, 9–14 July 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 198–202. [Google Scholar]
- Laukka, P.; Juslin, P.; Bresin, R. A dimensional approach to vocal expression of emotion. Cogn. Emot. 2005, 19, 633–653. [Google Scholar] [CrossRef]
- Dael, N.; Goudbeek, M.; Scherer, K.R. Perceived gesture dynamics in nonverbal expression of emotion. Perception 2013, 42, 642–657. [Google Scholar] [CrossRef] [Green Version]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyper-Praram | Value |
|---|---|
| Iterations | 2000 |
| Batch size | 32 |
| Learning rate for G | |
| Learning rate for D | |
| Unrolling steps | 10 |
| Beta for optimizer | (0.9, 0.999) |
| Layer | Number of Nodes |
|---|---|
| FC1 | 64 |
| FC2 | 64 |
| 2 layer bi-LSTM(G) | 128 |
| FC3 | 33 |
| FC4 | 64 |
| FC5 | 64 |
| 2 layer bi-LSTM(D) | 128 |
| FC6 | 1 |
| Model | Log-Likelihood | Standard Error |
|---|---|---|
| Ground Truth | −29.98 | 1.03 |
| Baseline [21] | −508.82 | 87.61 |
| CGAN * | −245.67 | 44.72 |
| Unrolled-CGAN * | −118.91 | 17.03 |
| Proposed (F = 20) ** | −177.86 | 29.36 |
| Proposed (F = 30) ** | −161.30 | 26.78 |
| Proposed (F = 40) ** | −107.58 | 15.21 |
| Proposed (F = 50) ** | −107.98 | 15.77 |
| Proposed (F = 60) ** | −126.20 | 19.01 |
| Scale | Statements (Translated from Japanese) |
|---|---|
| Gesture was natural | |
| Naturalness | Gesture was smooth |
| Gesture was comfortable | |
| Time | Gesture timing was matched to speech |
| Consistency | Gesture speed was matched to speech |
| Gesture pace was matched to speech | |
| Gesture was matched to speech content | |
| Semantics | Gesture well described speech content |
| Gesture helped me understand the content |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, B.; Liu, C.; Ishi, C.T.; Ishiguro, H. Modeling the Conditional Distribution of Co-Speech Upper Body Gesture Jointly Using Conditional-GAN and Unrolled-GAN. Electronics 2021, 10, 228. https://doi.org/10.3390/electronics10030228
Wu B, Liu C, Ishi CT, Ishiguro H. Modeling the Conditional Distribution of Co-Speech Upper Body Gesture Jointly Using Conditional-GAN and Unrolled-GAN. Electronics. 2021; 10(3):228. https://doi.org/10.3390/electronics10030228
Chicago/Turabian StyleWu, Bowen, Chaoran Liu, Carlos Toshinori Ishi, and Hiroshi Ishiguro. 2021. "Modeling the Conditional Distribution of Co-Speech Upper Body Gesture Jointly Using Conditional-GAN and Unrolled-GAN" Electronics 10, no. 3: 228. https://doi.org/10.3390/electronics10030228