
Privacy-Preserving Tampering Detection in Automotive Systems


Abstract
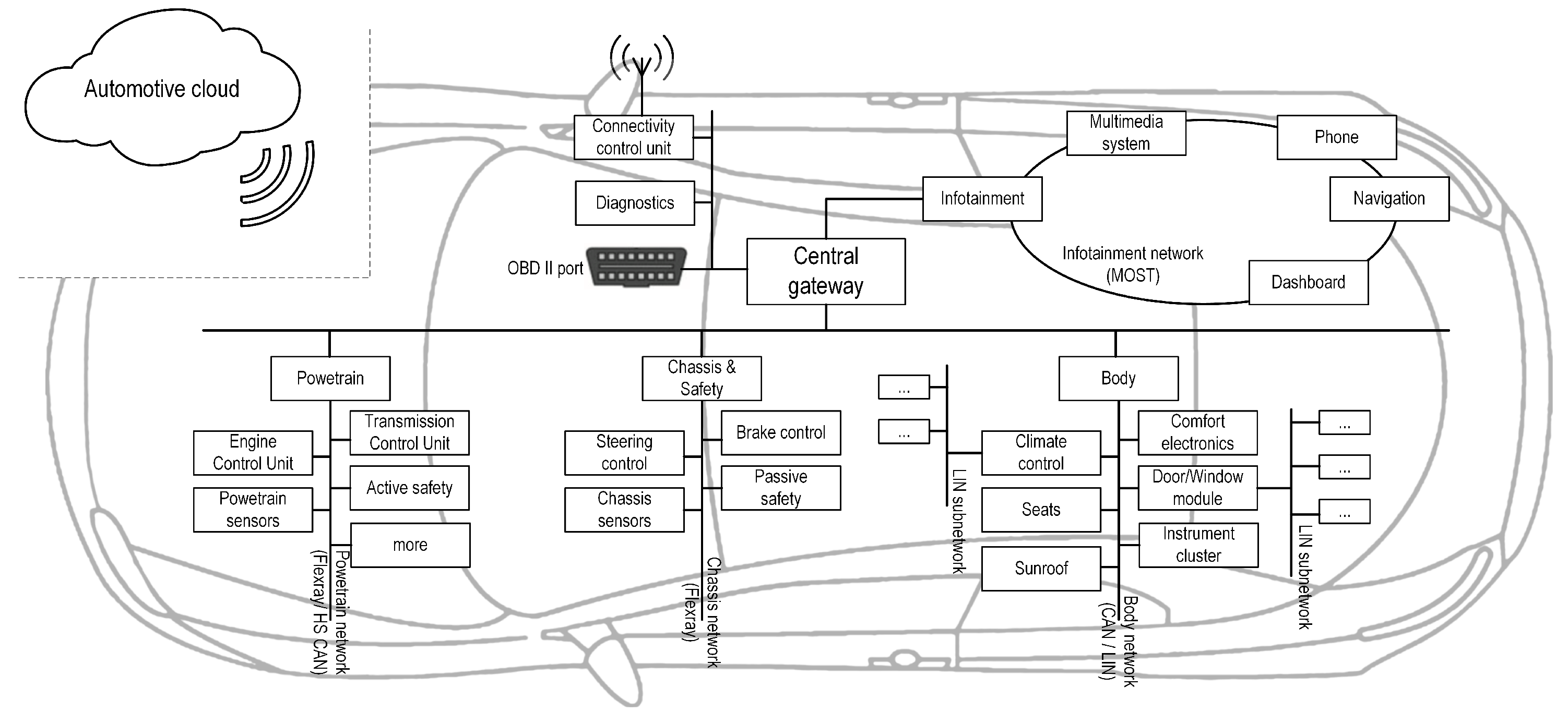
:1. Introduction
2. Related Work
2.1. Background and Overview of Traditional Techniques
2.2. Privacy-Preserving Detection Techniques
3. Privacy-Preserving Tampering Detection
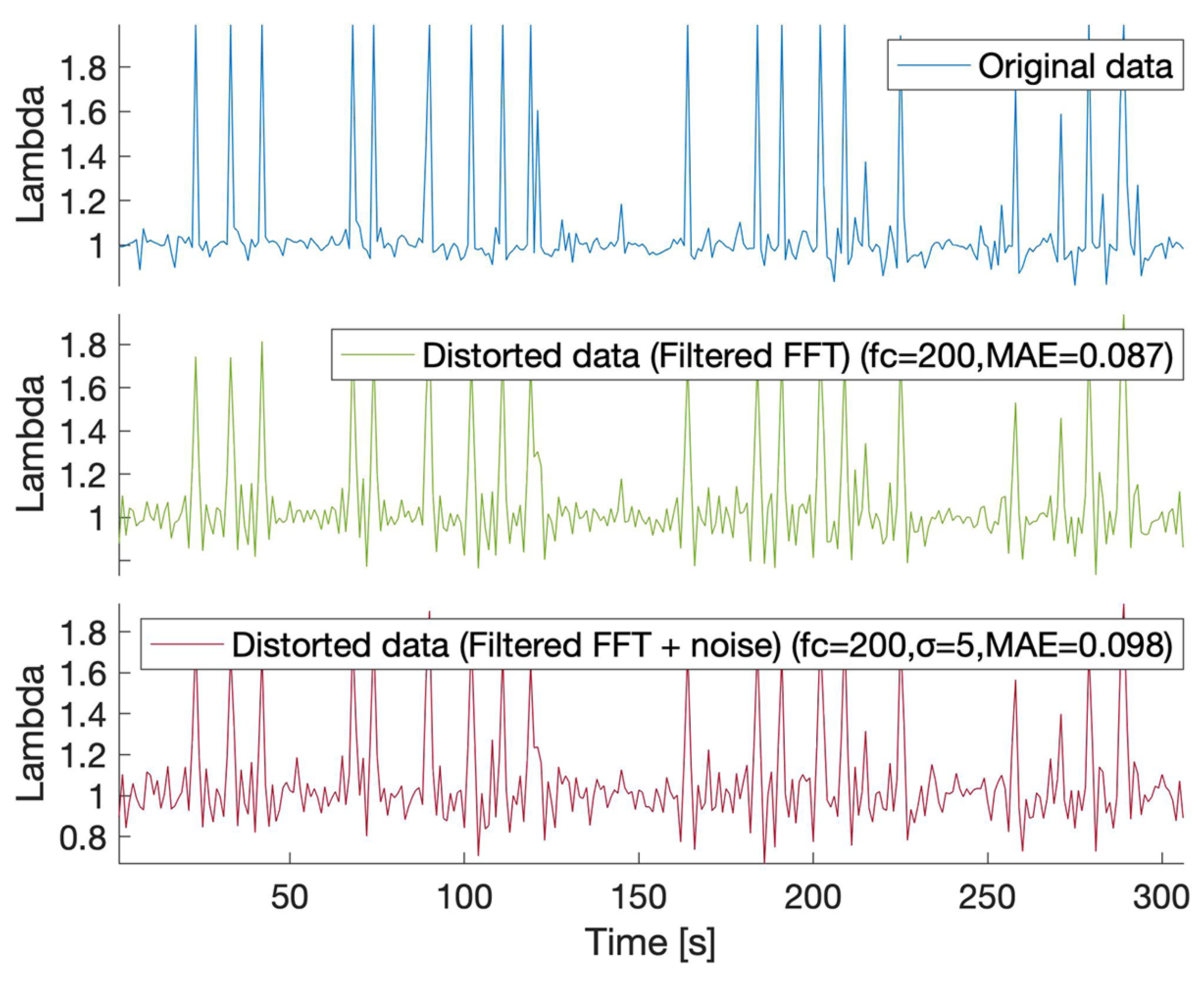
3.1. FFT-Based Data Distortion
3.2. Data Distortion by Filtering Fourier Frequencies and Adding Gaussian Noise
| Algorithm 1: FFT-based data distortion. |
| Input: A (Sensor data); (Cut-off frequency); (Noise variance) Output: D (The distorted data) |
 |
| Algorithm 2: Add Gaussian white noise to the frequency matrix. |
| Input: (The filtered frequency matrix); (Noise variance) Output: (The distorted frequency matrix) |
 |
3.3. Data Distortion Measurements
3.4. Tampering Detection with Anonymized Data
3.4.1. Random Forest
3.4.2. The Univariate Cumulative Sum
| Algorithm 3: UCUSUM computation over a sliding window. |
| Input: X (Column vector); W (Sliding window size); Output: CS (The cumulative sum as a column vector) |
 |
3.4.3. Tampering Detection
3.5. Computational Complexity
4. Experimental Results
4.1. 1D Sensor Data FFT-Based Distortion
4.2. 2D Sensor Data FFT-Based Distortion
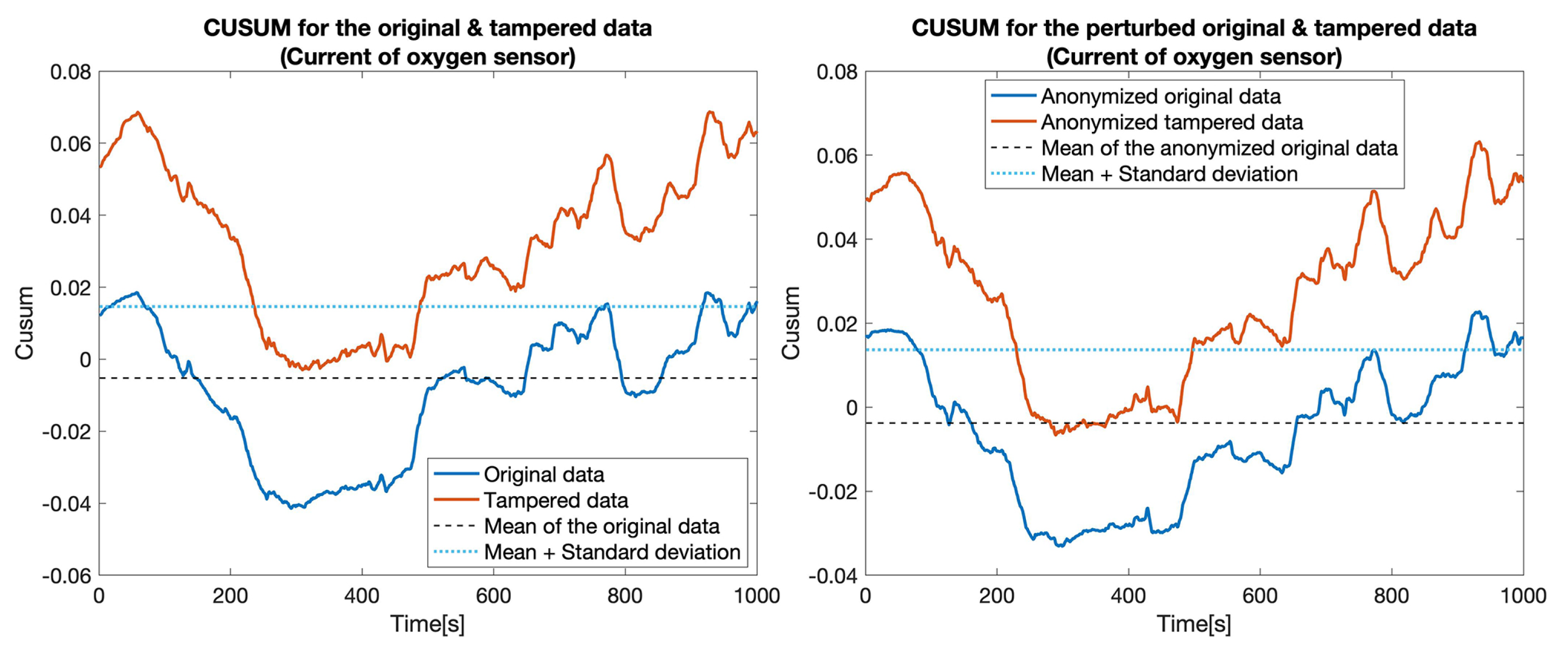
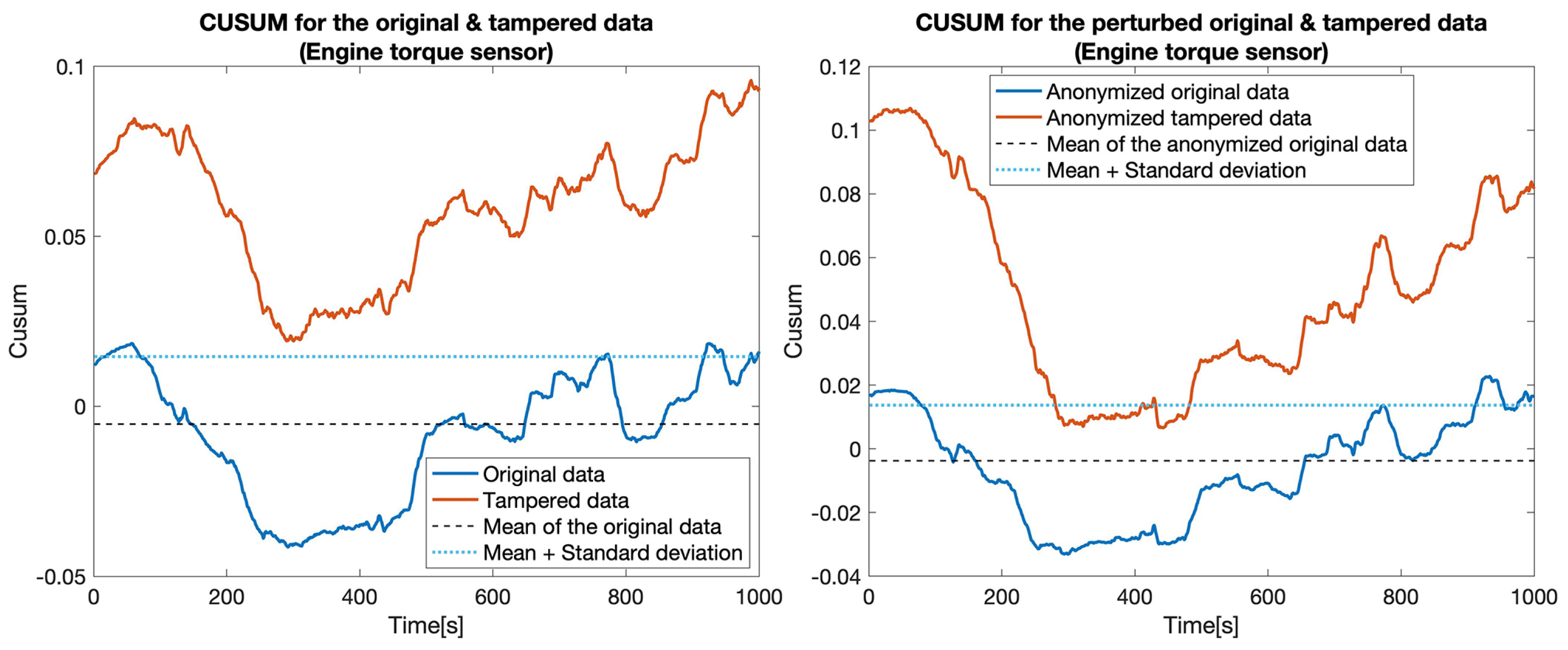
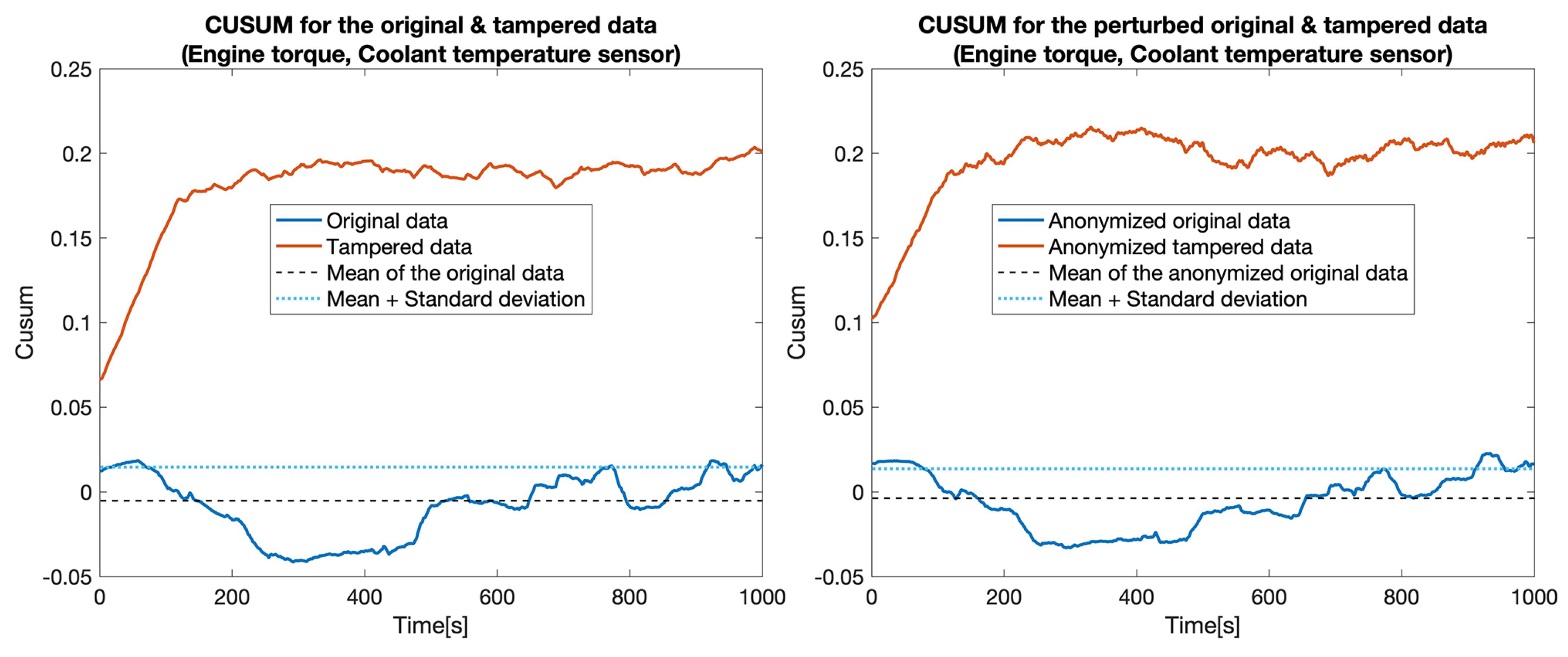
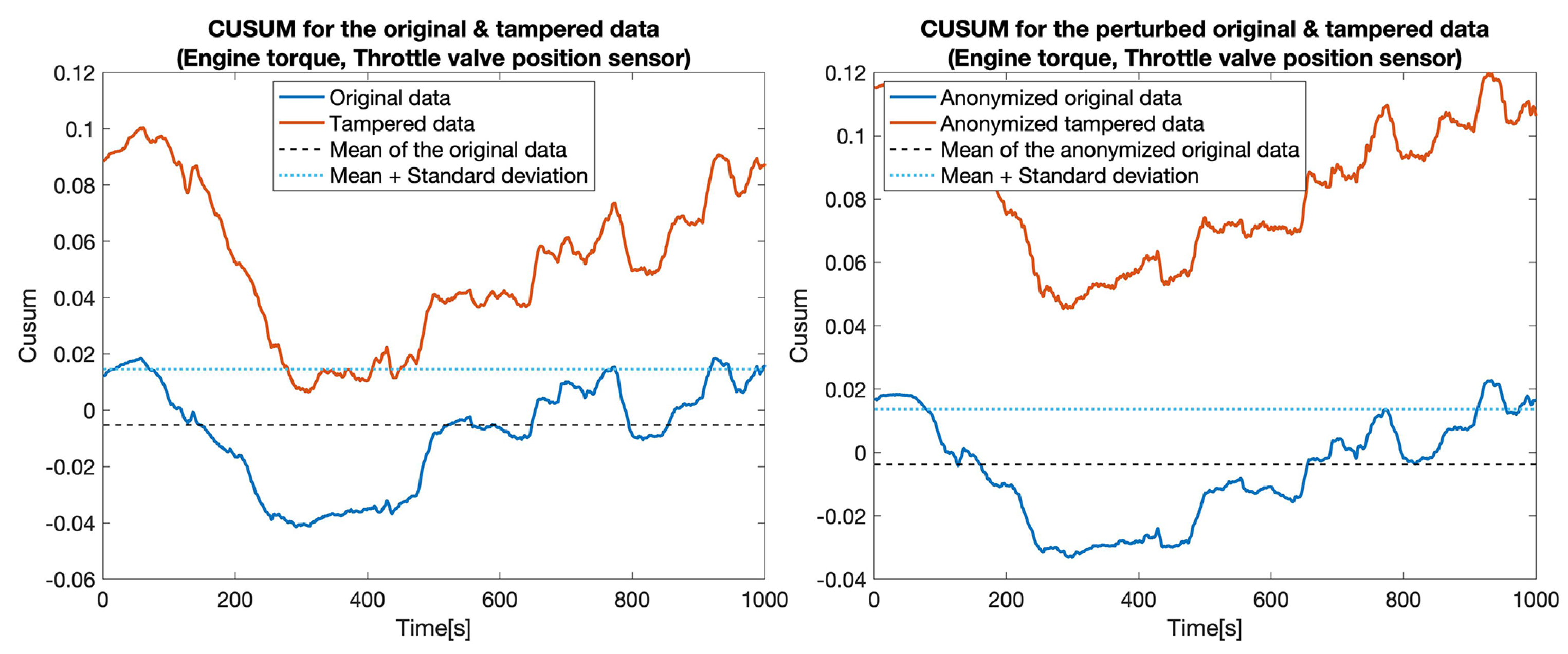
4.3. Privacy-Preserving Tampering Detection
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Coppola, R.; Morisio, M. Connected Car: Technologies, Issues, Future Trends. ACM Comput. Surv. 2016, 49, 1–36. [Google Scholar] [CrossRef]
- Rahim, M.A.; Rahman, M.A.; Rahman, M.; Asyhari, A.T.; Bhuiyan, M.Z.A.; Ramasamy, D. Evolution of IoT-enabled connectivity and applications in automotive industry: A review. Veh. Commun. 2021, 27, 100285. [Google Scholar] [CrossRef]
- Khan, S.K.; Shiwakoti, N.; Stasinopoulos, P.; Chen, Y. Cyber-attacks in the next-generation cars, mitigation techniques, anticipated readiness and future directions. Accid. Anal. Prev. 2020, 148, 105837. [Google Scholar] [CrossRef]
- Tian, J.; Wang, B.; Guo, R.; Wang, Z.; Cao, K.; Wang, X. Adversarial Attacks and Defenses for Deep Learning-based Unmanned Aerial Vehicles. IEEE Internet Things J. 2021, 1. [Google Scholar] [CrossRef]
- Baldini, G.; Giuliani, R.; Gemo, M. Mitigation of Odometer Fraud for In-Vehicle Security Using the Discrete Hartley Transform. In Proceedings of the 2020 11th IEEE Annual Ubiquitous Computing, Electronics Mobile Communication Conference (UEMCON), New York, NY, USA, 28–31 October 2020; pp. 479–485. [Google Scholar] [CrossRef]
- Thirumalini, S.; Malemutt, P. Investigations on anti-Tampering of diesel particulate filter. Mater. Today Proc. 2021, 46, 4988–4992. [Google Scholar] [CrossRef]
- Ertug, I. Motion for a European Parliament Solution with Recommendations to the Commission on Odometer Manipulation in Motor Vehicles: Revision of the EU Legal Framework. Report of the European Parliament. 2018. Available online: https://www.europarl.europa.eu/doceo/document/A-8-2018-0155_EN.html (accessed on 15 November 2021).
- Grelier, F. CO2 Emissions from Cars: The Facts. European Federation for Transport and Environment AISBL. 2018. Available online: https://www.transportenvironment.org/wp-content/uploads/2021/07/2018_04_CO2_emissions_cars_The_facts_report_final_0_0.pdf (accessed on 15 November 2021).
- European Data Protection Board. Guidelines 1/2020 on Processing Personal Data in the Context of Connected Vehicles and Mobility Related Applications. 2020. Available online: https://edpb.europa.eu/our-work-tools/documents/public-consultations/2020/guidelines-12020-processing-personal-data_en (accessed on 15 November 2021).
- Agrawal, D.; Aggarwal, C.C. On the Design and Quantification of Privacy Preserving Data Mining Algorithms. In Proceedings of the 20th ACM SIGACT-SIGMOD-SIGART Symposium on Principles of Database Systems, New York, NY, USA, 21–23 May 2001; pp. 247–255. [Google Scholar]
- Johnson, S.; Frigo, M. Implementing FFTs in Practice, ch. 11; Rice University: Houston, TX, USA, 2008. [Google Scholar]
- Keshk, M.; Sitnikova, E.; Moustafa, N.; Hu, J.; Khalil, I. An Integrated Framework for Privacy-Preserving Based Anomaly Detection for Cyber-Physical Systems. IEEE Trans. Sustain. Comput. 2021, 6, 66–79. [Google Scholar] [CrossRef]
- Alabdulatif, A.; Kumarage, H.; Khalil, I.; Yi, X. Privacy-preserving anomaly detection in cloud with lightweight homomorphic encryption. J. Comput. Syst. Sci. 2017, 90, 28–45. [Google Scholar] [CrossRef]
- Spathoulas, G.; Theodoridis, G.; Damiris, G.P. Using homomorphic encryption for privacy-preserving clustering of intrusion detection alerts. Int. J. Inf. Secur. 2021, 20, 347–370. [Google Scholar] [CrossRef]
- Wang, Z.; Liu, W.; Pang, X.; Ren, J.; Liu, Z.; Chen, Y. Towards Pattern-aware Privacy-preserving Real-time Data Collection. In Proceedings of the IEEE INFOCOM 2020-IEEE Conference on Computer Communications, Toronto, ON, Canada, 6–9 July 2020; pp. 109–118. [Google Scholar]
- Liu, K.; Giannella, C.; Kargupta, H. A Survey of Attack Techniques on Privacy-Preserving Data Perturbation Methods; Springer: Boston, MA, USA, 2008; pp. 359–381. [Google Scholar] [CrossRef] [Green Version]
- Hallac, D.; Sharang, A.; Stahlmann, R.; Lamprecht, A.; Huber, M.; Roehder, M.; Sosic, R.; Leskovec, J. Driver identification using automobile sensor data from a single turn. In Proceedings of the 2016 IEEE 19th International Conference on Intelligent Transportation Systems (ITSC), Rio de Janeiro, Brazil, 1–4 November 2016; pp. 953–958. [Google Scholar] [CrossRef] [Green Version]
- Zhu, Y.; Fu, Y.; Fu, H. On Privacy in Time Series Data Mining; Springer: Berlin/Heidelberg, Germany, 2008; pp. 479–493. [Google Scholar] [CrossRef]
- Hassan, M.U.; Rehmani, M.H.; Chen, J. Differential Privacy Techniques for Cyber Physical Systems: A Survey. IEEE Commun. Surv. Tutorials 2020, 22, 746–789. [Google Scholar] [CrossRef] [Green Version]
- Wang, T.; Zheng, Z.; Rehmani, M.H.; Yao, S.; Huo, Z. Privacy Preservation in Big Data From the Communication Perspective—A Survey. IEEE Commun. Surv. Tutor. 2019, 21, 753–778. [Google Scholar] [CrossRef]
- Sweeney, L. k-Anonymity: A Model for Protecting Privacy. IEEE Secur. Priv. 2002, 10, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Machanavajjhala, A.; Gehrke, J.; Kifer, D.; Venkitasubramaniam, M. l-Diversity: Privacy Beyond k-Anonymity. ACM Trans. Knowl. Discov. Data 2006, 1, 24. [Google Scholar]
- Li, N.; Li, T.; Venkatasubramanian, S. t-Closeness: Privacy Beyond k-Anonymity and l-Diversity. In Proceedings of the 2007 IEEE 23rd International Conference on Data Engineering, Istanbul, Turkey, 17–20 April 2007; Volume 2, pp. 106–115. [Google Scholar]
- Kreso, I.; Kapo, A.; Turulja, L. Data mining privacy preserving: Research agenda. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2021, 11, e1392. [Google Scholar] [CrossRef]
- Agrawal, R.; Srikant, R. Privacy-Preserving Data Mining. In Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data, SIGMOD ’00, New York, NY, USA, 15–18 May 2000; pp. 439–450. [Google Scholar] [CrossRef]
- Chen, K.; Liu, L. Privacy preserving data classification with rotation perturbation. In Proceedings of the Fifth IEEE International Conference on Data Mining (ICDM’05), Houston, TX, USA, 27–30 November 2005; p. 4. [Google Scholar] [CrossRef]
- Bingham, E.; Mannila, H. Random Projection in Dimensionality Reduction: Applications to Image and Text Data. In Proceedings of the Seventh ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’01, New York, NY, USA, 26–29 August 2001; pp. 245–250. [Google Scholar] [CrossRef]
- Bhaduri, K.; Stefanski, M.D.; Srivastava, A.N. Privacy-Preserving Outlier Detection through Random Nonlinear Data Distortion. IEEE Trans. Syst. Man, Cybern. Part B (Cybern.) 2011, 41, 260–272. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dwork, C. Differential privacy: A survey of results. In Proceedings of the International Conference on Theory and Applications of Models of Computation, Xi’an, China, 25–29 April 2008; Springer: Berlin/Heidelberg, Germany, 2008; pp. 1–19. [Google Scholar]
- Mukherjee, S.; Chen, Z.; Gangopadhyay, A. A privacy-preserving technique for Euclidean distance-based mining algorithms using Fourier-related transforms. VLDB J. 2006, 15, 293–315. [Google Scholar] [CrossRef]
- Papadimitriou, S.; Li, F.; Kollios, G.; Yu, P.S. Time Series Compressibility and Privacy. In Proceedings of the 33rd International Conference on Very Large Data Bases, VLDB Endowment, VLDB ’07, Vienna, Austria, 23–27 September 2007; pp. 459–470. [Google Scholar]
- Rastogi, V.; Nath, S. Differentially Private Aggregation of Distributed Time-Series with Transformation and Encryption. In Proceedings of the 2010 ACM SIGMOD International Conference on Management of Data, Indianapolis, IN, USA, 6–10 June 2010; pp. 735–746. [Google Scholar]
- Lyu, L.; Law, Y.W.; Jin, J.; Palaniswami, M. Privacy-Preserving Aggregation of Smart Metering via Transformation and Encryption. In Proceedings of the 2017 IEEE Trustcom/BigDataSE/ICESS, Sydney, NSW, Australia, 1–4 August 2017; pp. 472–479. [Google Scholar]
- Lako, F.L.; Lajoie-Mazenc, P.; Laurent, M. Privacy-Preserving Publication of Time-Series Data in Smart Grid. Secur. Commun. Net. 2021, 2021, 6643566. [Google Scholar] [CrossRef]
- Huang, Z.; Du, W.; Chen, B. Deriving Private Information from Randomized Data. In Proceedings of the 2005 ACM SIGMOD International Conference on Management of Data, SIGMOD ’05, New York, NY, USA, 14–16 June 2005; pp. 37–48. [Google Scholar] [CrossRef] [Green Version]
- Giannella, C.; Liu, K.; Kargupta, H. Breaching Euclidean Distance-Preserving Data Perturbation Using Few Known Inputs. Data Knowl. Eng. 2013, 83, 93–110. [Google Scholar] [CrossRef] [Green Version]
- Jiang, L.; Lou, X.; Tan, R.; Zhao, J. Differentially Private Collaborative Learning for the IoT Edge. In Proceedings of the International Conference on Embedded Wireless Systems and Networks (EWSN) 2019, Beijing, China, 25–27 February 2019. [Google Scholar]
- Grigorescu, S.; Cocias, T.; Trasnea, B.; Margheri, A.; Lombardi, F.; Aniello, L. Cloud2Edge Elastic AI Framework for Prototyping and Deployment of AI Inference Engines in Autonomous Vehicles. Sensors 2020, 20, 5450. [Google Scholar] [CrossRef]
- Hong, S.K.; Gurjar, K.; Kim, H.S.; Moon, Y.S. A Survey on Privacy Preserving Time-Series Data Mining. In Proceedings of the 3rd International Conference on Intelligent Computational Systems ICICS, Singapore, 29–30 April 2013. [Google Scholar]
- Genge, B.; Haller, P.; Enăchescu, C. Anomaly Detection in Aging Industrial Internet of Things. IEEE Access 2019, 7, 74217–74230. [Google Scholar] [CrossRef]
- Kiss, I.; Genge, B.; Haller, P.; Sebestyén, G. Data clustering-based anomaly detection in industrial control systems. In Proceedings of the 2014 IEEE 10th International Conference on Intelligent Computer Communication and Processing (ICCP), Cluj-Napoca, Romania, 4–6 September 2014; pp. 275–281. [Google Scholar] [CrossRef]
- Wang, B.; Mao, Z. One-class classifiers ensemble based anomaly detection scheme for process control systems. Trans. Inst. Meas. Control. 2018, 40, 0142331217724508. [Google Scholar] [CrossRef]
- Ha, D.; Ahmed, U.; Pyun, H.; Lee, C.J.; Baek, K.H.; Han, C. Multi-mode operation of principal component analysis with k-nearest neighbor algorithm to monitor compressors for liquefied natural gas mixed refrigerant processes. Comput. Chem. Eng. 2017, 106, 96–105. [Google Scholar] [CrossRef]
- Portnoy, I.; Melendez, K.; Pinzon, H.; Sanjuan, M. An improved weighted recursive PCA algorithm for adaptive fault detection. Control. Eng. Pract. 2016, 50, 69–83. [Google Scholar] [CrossRef]
- Chen, B.; Ho, D.W.C.; Zhang, W.A.; Yu, L. Distributed Dimensionality Reduction Fusion Estimation for Cyber-Physical Systems Under DoS Attacks. IEEE Trans. Syst. Man Cybern. Syst. 2019, 49, 455–468. [Google Scholar] [CrossRef]
- Thaseen, I.S.; Mohanraj, V.; Ramachandran, S.; Sanapala, K.; Yeo, S.S. A Hadoop Based Framework Integrating Machine Learning Classifiers for Anomaly Detection in the Internet of Things. Electronics 2021, 10, 1995. [Google Scholar] [CrossRef]
- Longari, S.; Nova Valcarcel, D.H.; Zago, M.; Carminati, M.; Zanero, S. CANnolo: An Anomaly Detection System Based on LSTM Autoencoders for Controller Area Network. IEEE Trans. Netw. Serv. Manag. 2021, 18, 1913–1924. [Google Scholar] [CrossRef]
- Domingo-Ferrer, J. A Provably Secure Additive and Multiplicative Privacy Homomorphism. In Proceedings of the 5th International Conference on Information Security, ISC ’02, Sao Paulo, Brazil, 30 September–2 October 2002; Springer: Berlin/Heidelberg, Germany, 2002; pp. 471–483. [Google Scholar]
- Alabdulatif, A.; Khalil, I.; Yi, X. Towards secure big data analytic for cloud-enabled applications with fully homomorphic encryption. J. Parallel Distrib. Comput. 2020, 137, 192–204. [Google Scholar] [CrossRef]
- Gyawali, S.; Qian, Y.; Hu, R.Q. A Privacy-Preserving Misbehavior Detection System in Vehicular Communication Networks. IEEE Trans. Veh. Technol. 2021, 70, 6147–6158. [Google Scholar] [CrossRef]
- Tsiropoulou, E.E.; Baras, J.; Papavassiliou, S.; Sinha, S. RFID-based smart parking management system. Cyber-Phys. Syst. 2017, 3, 1–20. [Google Scholar] [CrossRef]
- Abbasi, I.A.; Shahid Khan, A. A review of vehicle to vehicle communication protocols for VANETs in the urban environment. Future Internet 2018, 10, 14. [Google Scholar] [CrossRef] [Green Version]
- Shon, T. In-Vehicle Networking/Autonomous Vehicle Security for Internet of Things/Vehicles. Electronics 2021, 10, 637. [Google Scholar] [CrossRef]
- Brigham, E.O. The Fast Fourier Transform and its Applications; Prentice-Hall, Inc.: Hoboken, NJ, USA, 1988; pp. 131–166. [Google Scholar]
- Xu, S.; Lai, S. Fast Fourier Transform Based Data Perturbation Method for Privacy Protection. In Proceedings of the 2007 IEEE Intelligence and Security Informatics, New Brunswick, NJ, USA, 23–24 May 2007; pp. 221–224. [Google Scholar]
- Dewangan, S.; Sharma, A. Image Smoothening and Sharpening using Frequency Domain Filtering Technique. Int. J. Emerg. Technol. Eng. Res. 2017, 5, 169–174. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Page, E.S. Continuous inspection schemes. Biometrika 1954, 41, 100–115. [Google Scholar] [CrossRef]
- Franklin, G.F.; Powell, J.D.; Emami-Naeini, A. Feedback Control of Dynamic Systems, 8th ed.; Pearson: New York, NY, USA, 2019. [Google Scholar]
- AliExpress. Automotive Sensor Simulators. 2021. Available online: https://www.aliexpress.com/popular/automotive-sensor-simulator.html (accessed on 15 November 2021).
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Privacy Preservation Technique | Computation Operations | Privacy Preservation Location | Applicable on Multiple Sensors Simultaneously | Adjustable Level of Privacy | Computation Complexity |
|---|---|---|---|---|---|
| Lightweight homomorphic encryption [13] | additive and multiplicative homomorphic encryption | on an external trusted server | no | no | high |
| PPMDS [50] | additive homomorphic encryption and signing | locally | no | no | medium |
| FFT-based data perturbation | data transformation, frequency filtering, noise addition | locally | yes | yes | low |
| No. of | Overall Exec. | Exec. Time/Sensor | Data |
|---|---|---|---|
| Sensors | Time (ms) | (ms) | Reduction (%) |
| 1 | 9.5 | 9.5 | 34.3 |
| 2 | 9.7 | 4.9 | 34.6 |
| 3 | 9.9 | 3.3 | 13.0 |
| 5 | 10.2 | 2.0 | −4.18 |
| 10 | 11.1 | 1.1 | −4.11 |
| 12 | 12.6 | 1.0 | 13.23 |
| # of Tampered Sensors | Tampered Sensor(s) | Clear Data | Anonymized Data | ||
|---|---|---|---|---|---|
| TPR | FPR | TPR | FPR | ||
| 1 | Current of oxygen sensor | 77.4% | 18.5% | 76% | 21.5% |
| 1 | Oxygen jump sensor voltage | 100% | 18.5% | 100% | 21.5% |
| 1 | Coolant temperature | 100% | 18.5% | 100% | 21.5% |
| 1 | Throttle valve position | 100% | 18.5% | 100% | 21.5% |
| 1 | Engine torque | 100% | 18.5% | 82.7% | 21.5% |
| 2 | Current of oxygen sensor, Oxygen jump sensor voltage | 100% | 18.5% | 100% | 21.5% |
| 2 | Current of oxygen sensor, Engine torque | 100% | 18.5% | 99.4% | 21.5% |
| 2 | Engine torque, Coolant temperature | 100% | 18.5% | 100% | 21.5% |
| 2 | Engine torque, Throttle valve position | 87.4% | 18.5% | 100% | 21.5% |
| 4 | Current of oxygen sensor, Coolant temperature, Engine torque, Throttle valve position | 100% | 18.5% | 100% | 21.5% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Roman, A.-S.; Genge, B.; Duka, A.-V.; Haller, P. Privacy-Preserving Tampering Detection in Automotive Systems. Electronics 2021, 10, 3161. https://doi.org/10.3390/electronics10243161
Roman A-S, Genge B, Duka A-V, Haller P. Privacy-Preserving Tampering Detection in Automotive Systems. Electronics. 2021; 10(24):3161. https://doi.org/10.3390/electronics10243161
Chicago/Turabian StyleRoman, Adrian-Silviu, Béla Genge, Adrian-Vasile Duka, and Piroska Haller. 2021. "Privacy-Preserving Tampering Detection in Automotive Systems" Electronics 10, no. 24: 3161. https://doi.org/10.3390/electronics10243161