
The Constraints between Edge Depth and Uncertainty for Monocular Depth Estimation


Abstract
:1. Introduction
- We study the impact of multi-scale uncertainty on self-supervised monocular depth estimation and find that it yields more edge-depth uncertainty.
- We analyze the effect of different teacher–student combination strategies on the uncertainty of self-supervised monocular depth estimation.
- We propose a paradigm for self-supervised monocular depth estimation based on a teacher–student framework and combined with multi-scale uncertainty. Our method effectively improves the overall performance of depth estimation.
2. Related Work
2.1. Self-Supervised Methods
2.2. Uncertainty Estimation
3. Method
3.1. Self-Supervised Depth Estimation
3.2. Uncertainty Estimation
3.2.1. Uncertainty in Depth Models
3.2.2. Uncertainty from Depth Distribution
3.2.3. Multi-Scale Depth Uncertainty
3.3. Teacher-Student Frameworks
4. Experiments
4.1. Training Details and Metrics
4.1.1. Details on the Learning Procedure
4.1.2. Depth Metrics
4.1.3. Uncertainty Metrics
4.1.4. Dataset
4.2. Monocular Depth Estimation with Uncertainty
4.2.1. KITTI Eigen Split
4.2.2. Ablation Study
4.2.3. KITTI New Benchmark
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Hao, Y.; Li, J.; Meng, F.; Zhang, P.; Ciuti, G.; Dario, P.; Huang, Q. Photometric Stereo-Based Depth Map Reconstruction for Monocular Capsule Endoscopy. Sensors 2020, 20, 5403. [Google Scholar] [CrossRef] [PubMed]
- Urban, D.; Caplier, A. Time- and Resource-Efficient Time-to-Collision Forecasting for Indoor Pedestrian Obstacles Avoidance. J. Imaging 2021, 7, 61. [Google Scholar] [CrossRef] [PubMed]
- Hwang, S.J.; Park, S.J.; Kim, G.M.; Baek, J.H. Unsupervised Monocular Depth Estimation for Colonoscope System Using Feedback Network. Sensors 2021, 21, 2691. [Google Scholar] [CrossRef] [PubMed]
- Jia, Q.; Chang, L.; Qiang, B.; Zhang, S.; Xie, W.; Yang, X.; Sun, Y.; Yang, M. Real-Time 3D Reconstruction Method Based on Monocular Vision. Sensors 2021, 21, 5909. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Chang, Y.; Li, Z.; Yuan, H. A depth estimation method for edge precision improvement of depth map. In Proceedings of the 2010 International Conference on Computer and Communication Technologies in Agriculture Engineering, Chengdu, China, 12–13 June 2010; Volume 3, pp. 422–425. [Google Scholar]
- Chou, H.Y.; Shih, K.T.; Chen, H. Occlusion-and-edge-aware depth estimation from stereo images for synthetic refocusing. In Proceedings of the 2018 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), San Diego, CA, USA, 23–27 July 2018; pp. 1–6. [Google Scholar]
- Yang, Z.; Wang, P.; Xu, W.; Zhao, L.; Nevatia, R. Unsupervised learning of geometry from videos with edge-aware depth-normal consistency. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Khan, N.; Kim, M.H.; Tompkin, J. Edge-aware Bidirectional Diffusion for Dense Depth Estimation from Light Fields. arXiv 2021, arXiv:2107.02967. [Google Scholar]
- Li, Z.; Zhu, X.; Yu, H.; Zhang, Q.; Jiang, Y. Edge-Aware Monocular Dense Depth Estimation with Morphology. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milano, Italy, 10–15 January 2021; pp. 2935–2942. [Google Scholar]
- Palafox, P.R.; Betz, J.; Nobis, F.; Riedl, K.; Lienkamp, M. SemanticDepth: Fusing Semantic Segmentation and Monocular Depth Estimation for Enabling Autonomous Driving in Roads without Lane Lines. Sensors 2019, 19, 3224. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kwak, D.; Lee, S. A Novel Method for Estimating Monocular Depth Using Cycle GAN and Segmentation. Sensors 2020, 20, 2567. [Google Scholar] [CrossRef]
- Wang, R.; Zou, J.; Wen, J.Z. SFA-MDEN: Semantic-Feature-Aided Monocular Depth Estimation Network Using Dual Branches. Sensors 2021, 21, 5476. [Google Scholar] [CrossRef] [PubMed]
- Song, X.; Zhao, X.; Hu, H.; Fang, L. Edgestereo: A context integrated residual pyramid network for stereo matching. In Proceedings of the Asian Conference on Computer Vision, Singapore, 20–23 May 2018; pp. 20–35. [Google Scholar]
- Xiong, L.; Wen, Y.; Huang, Y.; Zhao, J.; Tian, W. Joint Unsupervised Learning of Depth, Pose, Ground Normal Vector and Ground Segmentation by a Monocular Camera Sensor. Sensors 2020, 20, 3737. [Google Scholar] [CrossRef] [PubMed]
- Richter, S.; Wang, Y.; Beck, J.; Wirges, S.; Stiller, C. Semantic Evidential Grid Mapping Using Monocular and Stereo Cameras. Sensors 2021, 21, 3380. [Google Scholar] [CrossRef] [PubMed]
- Han, L.; Huang, X.; Shi, Z.; Zheng, S. Depth Estimation from Light Field Geometry Using Convolutional Neural Networks. Sensors 2021, 21, 6061. [Google Scholar] [CrossRef] [PubMed]
- Kendall, A.; Gal, Y. What uncertainties do we need in bayesian deep learning for computer vision? arXiv 2017, arXiv:1703.04977. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The kitti dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef] [Green Version]
- Karsch, K.; Liu, C.; Kang, S.B. Depth extraction from video using non-parametric sampling. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; pp. 775–788. [Google Scholar]
- Saxena, A.; Sun, M.; Ng, A.Y. Make3d: Learning 3d scene structure from a single still image. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 31, 824–840. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Laina, I.; Rupprecht, C.; Belagiannis, V.; Tombari, F.; Navab, N. Deeper depth prediction with fully convolutional residual networks. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 239–248. [Google Scholar]
- Fu, H.; Gong, M.; Wang, C.; Batmanghelich, K.; Tao, D. Deep ordinal regression network for monocular depth estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2002–2011. [Google Scholar]
- Godard, C.; Mac Aodha, O.; Brostow, G.J. Unsupervised monocular depth estimation with left-right consistency. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–27 July 2017; pp. 270–279. [Google Scholar]
- Zhou, T.; Brown, M.; Snavely, N.; Lowe, D.G. Unsupervised learning of depth and ego-motion from video. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–27 July 2017; pp. 1851–1858. [Google Scholar]
- Garg, R.; Bg, V.K.; Carneiro, G.; Reid, I. Unsupervised cnn for single view depth estimation: Geometry to the rescue. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 740–756. [Google Scholar]
- Godard, C.; Mac Aodha, O.; Firman, M.; Brostow, G.J. Digging into self-supervised monocular depth estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 3828–3838. [Google Scholar]
- Gao, H.; Liu, X.; Qu, M.; Huang, S. PDANet: Self-Supervised Monocular Depth Estimation Using Perceptual and Data Augmentation Consistency. Appl. Sci. 2021, 11, 5383. [Google Scholar] [CrossRef]
- Zhu, Z.; Ma, Y.; Zhao, R.; Liu, E.; Zeng, S.; Yi, J.; Ding, J. Improve the Estimation of Monocular Vision 6-DOF Pose Based on the Fusion of Camera and Laser Rangefinder. Remote Sens. 2021, 13, 3709. [Google Scholar] [CrossRef]
- Fan, C.; Yin, Z.; Xu, F.; Chai, A.; Zhang, F. Joint Soft–Hard Attention for Self-Supervised Monocular Depth Estimation. Sensors 2021, 21, 6956. [Google Scholar] [CrossRef]
- Jung, G.; Won, Y.Y.; Yoon, S.M. Computational Large Field-of-View RGB-D Integral Imaging System. Sensors 2021, 21, 7407. [Google Scholar] [CrossRef] [PubMed]
- Mahjourian, R.; Wicke, M.; Angelova, A. Unsupervised learning of depth and ego-motion from monocular video using 3d geometric constraints. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5667–5675. [Google Scholar]
- Zhan, H.; Garg, R.; Weerasekera, C.S.; Li, K.; Agarwal, H.; Reid, I. Unsupervised learning of monocular depth estimation and visual odometry with deep feature reconstruction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 340–349. [Google Scholar]
- Chen, Z.; Ye, X.; Yang, W.; Xu, Z.; Tan, X.; Zou, Z.; Ding, E.; Zhang, X.; Huang, L. Revealing the Reciprocal Relations Between Self-Supervised Stereo and Monocular Depth Estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 15529–15538. [Google Scholar]
- Cheng, J.; Wang, Z.; Zhou, H.; Li, L.; Yao, J. DM-SLAM: A Feature-Based SLAM System for Rigid Dynamic Scenes. ISPRS Int. J. Geo-Inf. 2020, 9, 202. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Zhang, L.; Lewis, F.L.; Pei, H. Non-Uniform Discretization-based Ordinal Regression for Monocular Depth Estimation of an Indoor Drone. Electronics 2020, 9, 1767. [Google Scholar] [CrossRef]
- Liu, P.; Zhang, Z.; Meng, Z.; Gao, N. Monocular Depth Estimation with Joint Attention Feature Distillation and Wavelet-Based Loss Function. Sensors 2021, 21, 54. [Google Scholar] [CrossRef]
- Guizilini, V.; Ambrus, R.; Pillai, S.; Raventos, A.; Gaidon, A. 3d packing for self-supervised monocular depth estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2485–2494. [Google Scholar]
- Kim, S.; Kim, S.; Min, D.; Sohn, K. Laf-net: Locally adaptive fusion networks for stereo confidence estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 205–214. [Google Scholar]
- Mac Aodha, O.; Humayun, A.; Pollefeys, M.; Brostow, G.J. Learning a confidence measure for optical flow. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 1107–1120. [Google Scholar] [CrossRef] [PubMed]
- Wannenwetsch, A.S.; Keuper, M.; Roth, S. Probflow: Joint optical flow and uncertainty estimation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1173–1182. [Google Scholar]
- Pu, C.; Song, R.; Tylecek, R.; Li, N.; Fisher, R.B. SDF-MAN: Semi-Supervised Disparity Fusion with Multi-Scale Adversarial Networks. Remote Sens. 2019, 11, 487. [Google Scholar] [CrossRef] [Green Version]
- Song, C.; Qi, C.; Song, S.; Xiao, F. Unsupervised Monocular Depth Estimation Method Based on Uncertainty Analysis and Retinex Algorithm. Sensors 2020, 20, 5389. [Google Scholar] [CrossRef]
- Walz, S.; Gruber, T.; Ritter, W.; Dietmayer, K. Uncertainty depth estimation with gated images for 3D reconstruction. In Proceedings of the 2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC), Virtual, 20–23 September 2020; pp. 1–8. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Lakshminarayanan, B.; Pritzel, A.; Blundell, C. Simple and scalable predictive uncertainty estimation using deep ensembles. arXiv 2016, arXiv:1612.01474. [Google Scholar]
- Ilg, E.; Cicek, O.; Galesso, S.; Klein, A.; Makansi, O.; Hutter, F.; Brox, T. Uncertainty estimates and multi-hypotheses networks for optical flow. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 August 2018; pp. 652–667. [Google Scholar]
- Klodt, M.; Vedaldi, A. Supervising the new with the old: Learning sfm from sfm. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 August 2018; pp. 698–713. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern recognition, Honolulu, HI, USA, 21–27 July 2017; pp. 2117–2125. [Google Scholar]
- Poggi, M.; Aleotti, F.; Tosi, F.; Mattoccia, S. On the uncertainty of self-supervised monocular depth estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–18 June 2020; pp. 3227–3237. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Eigen, D.; Puhrsch, C.; Fergus, R. Depth map prediction from a single image using a multi-scale deep network. arXiv 2014, arXiv:1406.2283. [Google Scholar]
- Eigen, D.; Fergus, R. Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2650–2658. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Yang, Z.; Wang, P.; Xu, W.; Zhao, L.; Nevatia, R. Unsupervised learning of geometry with edge-aware depth-normal consistency. arXiv 2017, arXiv:1711.03665. [Google Scholar]
- Zou, Y.; Luo, Z.; Huang, J.B. Df-net: Unsupervised joint learning of depth and flow using cross-task consistency. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 August 2018; pp. 36–53. [Google Scholar]
- Bian, J.; Li, Z.; Wang, N.; Zhan, H.; Shen, C.; Cheng, M.M.; Reid, I. Unsupervised scale-consistent depth and ego-motion learning from monocular video. Adv. Neural Inf. Process. Syst. 2019, 32, 35–45. [Google Scholar]
- Chen, P.Y.; Liu, A.H.; Liu, Y.C.; Wang, Y.C.F. Towards scene understanding: Unsupervised monocular depth estimation with semantic-aware representation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–19 June 2019; pp. 2624–2632. [Google Scholar]
- Tosi, F.; Aleotti, F.; Poggi, M.; Mattoccia, S. Learning monocular depth estimation infusing traditional stereo knowledge. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–19 June 2019; pp. 9799–9809. [Google Scholar]
- Klingner, M.; Termöhlen, J.A.; Mikolajczyk, J.; Fingscheidt, T. Self-supervised monocular depth estimation: Solving the dynamic object problem by semantic guidance. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 582–600. [Google Scholar]
- Uhrig, J.; Schneider, N.; Schneider, L.; Franke, U.; Brox, T.; Geiger, A. Sparsity invariant cnns. In Proceedings of the 2017 International Conference on 3D Vision (3DV), Qingdao, China, 10–12 October 2017; pp. 11–20. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
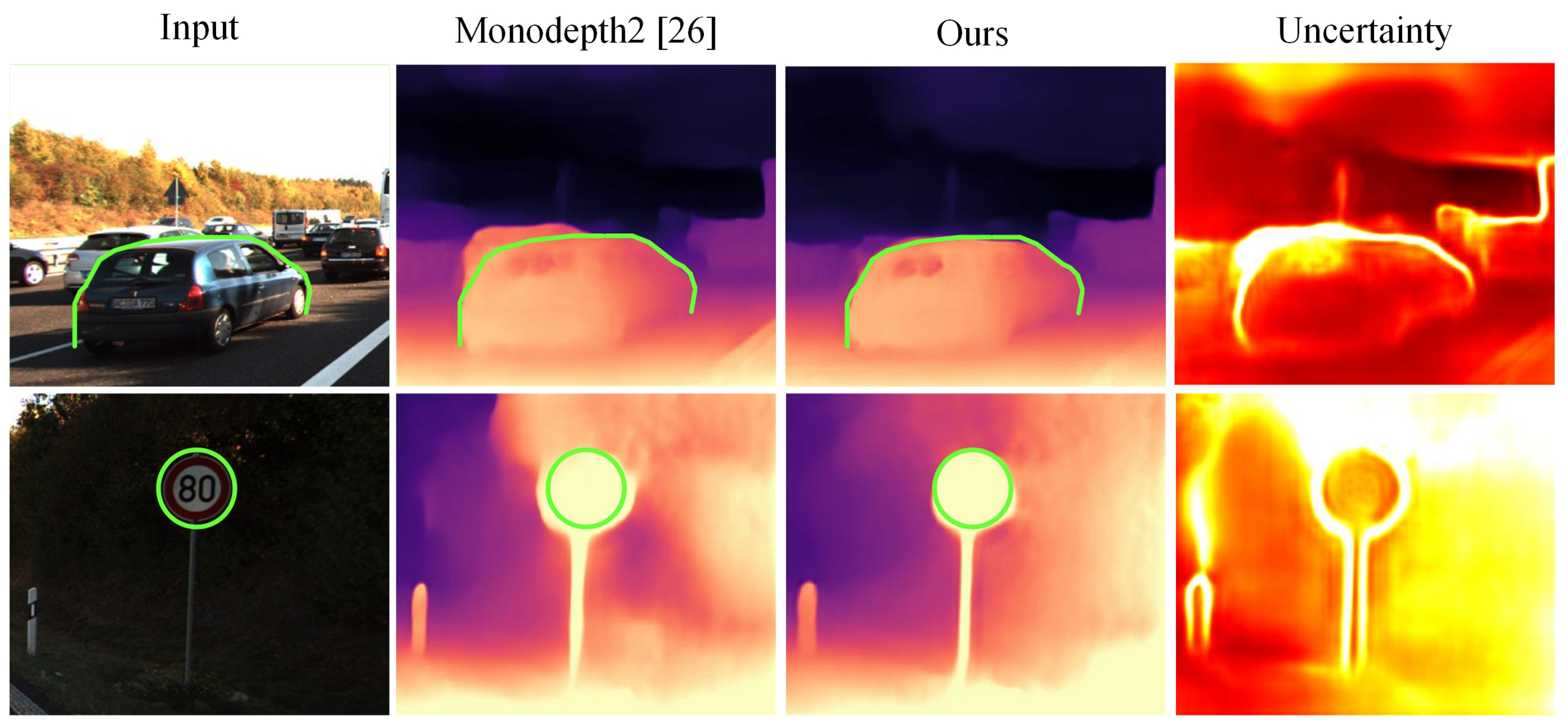{kind=link}
{kind=link}
| Method | Abs Rel ↓ | Sq Rel ↓ | RMSE ↓ | RMSE log ↓ | |||
|---|---|---|---|---|---|---|---|
| Zhou [24] | 0.183 | 1.595 | 6.709 | 0.27 | 0.734 | 0.902 | 0.959 |
| Yang [55] | 0.182 | 1.481 | 6.501 | 0.267 | 0.725 | 0.906 | 0.963 |
| Mahjourian [31] | 0.163 | 1.24 | 6.22 | 0.25 | 0.762 | 0.916 | 0.968 |
| DF-Net [56] | 0.15 | 1.124 | 5.507 | 0.223 | 0.806 | 0.933 | 0.973 |
| Bian [57] | 0.137 | 1.089 | 5.439 | 0.217 | 0.83 | 0.942 | 0.975 |
| Chen [58] | 0.118 | 0.905 | 5.096 | 0.211 | 0.839 | 0.945 | 0.977 |
| Tosi [59] | 0.111 | 0.867 | 4.714 | 0.199 | 0.864 | 0.954 | 0.979 |
| Godard [26] | 0.115 | 0.903 | 4.863 | 0.193 | 0.877 | 0.959 | 0.981 |
| Klingner [60] | 0.113 | 0.835 | 4.693 | 0.191 | 0.879 | 0.961 | 0.981 |
| Poggi [50] | 0.112 | 0.861 | 4.762 | 0.189 | 0.88 | 0.961 | 0.982 |
| Ours | 0.11 | 0.822 | 4.686 | 0.187 | 0.882 | 0.961 | 0.982 |
| Method | T+S | Alea | Epis | Multi-Scale | Abs Rel ↓ | Sq Rel ↓ | RMSE ↓ | RMSE log ↓ | |||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Baseline | 0.113 | 0.87 | 4.756 | 0.19 | 0.879 | 0.96 | 0.981 | ||||
| Baseline+A | √ | √ | 0.113 | 0.865 | 4.76 | 0.189 | 0.88 | 0.961 | 0.982 | ||
| Bagging | √ | √ | 0.113 | 0.79 | 4.607 | 0.189 | 0.876 | 0.961 | 0.983 | ||
| Dropout | √ | √ | 0.124 | 0.835 | 4.74 | 0.194 | 0.852 | 0.955 | 0.983 | ||
| BaseT+A+S | √ | √ | 0.111 | 0.823 | 4.676 | 0.188 | 0.882 | 0.961 | 0.982 | ||
| BaseT+A | √ | √ | √ | 0.11 | 0.822 | 4.686 | 0.187 | 0.882 | 0.961 | 0.982 | |
| BaseT+AE | √ | √ | √ | √ | 0.111 | 0.844 | 4.706 | 0.188 | 0.881 | 0.961 | 0.982 |
| BagT+AE | √ | √ | √ | √ | 0.113 | 0.786 | 4.628 | 0.189 | 0.875 | 0.961 | 0.983 |
| DropT+AE | √ | √ | √ | √ | 0.119 | 0.787 | 4.627 | 0.189 | 0.861 | 0.957 | 0.983 |
| Method | Abs Rel | RMSE | ||||
|---|---|---|---|---|---|---|
| AUSE ↓ | AURG ↑ | AUSE ↓ | AURG ↑ | AUSE ↓ | AURG ↑ | |
| Baseline+A | 0.063 | 0.01 | 3.676 | 0.383 | 0.09 | 0.02 |
| Bagging | 0.063 | 0.01 | 3.631 | 0.275 | 0.094 | 0.019 |
| Dropout | 0.075 | 0.005 | 3.582 | 0.395 | 0.122 | 0.01 |
| BaseT+A+S | 0.034 | 0.039 | 2.175 | 1.833 | 0.034 | 0.075 |
| BaseT+A | 0.034 | 0.039 | 2.168 | 1.871 | 0.035 | 0.075 |
| BaseT+AE | 0.036 | 0.038 | 2.274 | 1.79 | 0.037 | 0.074 |
| BagT+AE | 0.037 | 0.036 | 2.507 | 1.428 | 0.041 | 0.073 |
| DropT+AE | 0.064 | 0.014 | 2.488 | 1.406 | 0.095 | 0.03 |
| Method | Abs Rel ↓ | Sq Rel ↓ | RMSE ↓ | RMSE log ↓ | |||
|---|---|---|---|---|---|---|---|
| Baseline | 0.089 | 0.525 | 3.867 | 0.135 | 0.916 | 0.983 | 0.995 |
| Baseline+A | 0.088 | 0.508 | 3.835 | 0.133 | 0.918 | 0.983 | 0.995 |
| Bagging | 0.091 | 0.5 | 3.806 | 0.136 | 0.912 | 0.983 | 0.995 |
| Dropout | 0.099 | 0.553 | 4.064 | 0.147 | 0.895 | 0.978 | 0.995 |
| BaseT+A+S | 0.087 | 0.497 | 3.79 | 0.132 | 0.919 | 0.984 | 0.996 |
| BaseT+A | 0.086 | 0.488 | 3.792 | 0.131 | 0.92 | 0.984 | 0.995 |
| BaseT+AE | 0.087 | 0.508 | 3.813 | 0.132 | 0.919 | 0.984 | 0.995 |
| BagT+AE | 0.091 | 0.501 | 3.838 | 0.136 | 0.912 | 0.982 | 0.995 |
| DropT+AE | 0.094 | 0.497 | 3.862 | 0.14 | 0.905 | 0.981 | 0.995 |
| Method | Abs Rel | RMSE | ||||
|---|---|---|---|---|---|---|
| AUSE ↓ | AURG ↑ | AUSE ↓ | AURG ↑ | AUSE ↓ | AURG ↑ | |
| Baseline+A | 0.049 | 0.007 | 3.016 | 0.259 | 0.067 | 0.01 |
| Bagging | 0.051 | 0.007 | 3.047 | 0.184 | 0.071 | 0.011 |
| Dropout | 0.06 | 0.004 | 3.177 | 0.262 | 0.09 | 0.006 |
| BaseT+A+S | 0.029 | 0.027 | 1.926 | 1.333 | 0.028 | 0.047 |
| BaseT+A | 0.029 | 0.027 | 1.916 | 1.362 | 0.029 | 0.047 |
| BaseT+AE | 0.03 | 0.027 | 2.019 | 1.287 | 0.03 | 0.047 |
| BagT+AE | 0.033 | 0.026 | 2.35 | 0.921 | 0.037 | 0.045 |
| DropT+AE | 0.05 | 0.01 | 2.316 | 0.955 | 0.069 | 0.019 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, S.; Li, W.; Liang, B.; Huang, G. The Constraints between Edge Depth and Uncertainty for Monocular Depth Estimation. Electronics 2021, 10, 3153. https://doi.org/10.3390/electronics10243153
Wu S, Li W, Liang B, Huang G. The Constraints between Edge Depth and Uncertainty for Monocular Depth Estimation. Electronics. 2021; 10(24):3153. https://doi.org/10.3390/electronics10243153
Chicago/Turabian StyleWu, Shouying, Wei Li, Binbin Liang, and Guoxin Huang. 2021. "The Constraints between Edge Depth and Uncertainty for Monocular Depth Estimation" Electronics 10, no. 24: 3153. https://doi.org/10.3390/electronics10243153