
FMECA and MFCC-Based Early Wear Detection in Gear Pumps in Cost-Aware Monitoring Systems




Abstract
:1. Introduction
- An MFCC-based early wear detection model is proposed with validations from a case study on an AP3.5/100 external gear pump manufactured by BESCO. The proposed model exploits the sensitivity of MFCC features for discriminant feature selection and AI-based models for wear detection performance evaluation.
- The early wear effect of fluid contamination of gear pump housing is investigated and presented using surface profiles.
- An exploratory comparison is presented between the employed ML-based classifiers and their performances assessed from different empirical standpoints.
2. Background of Study
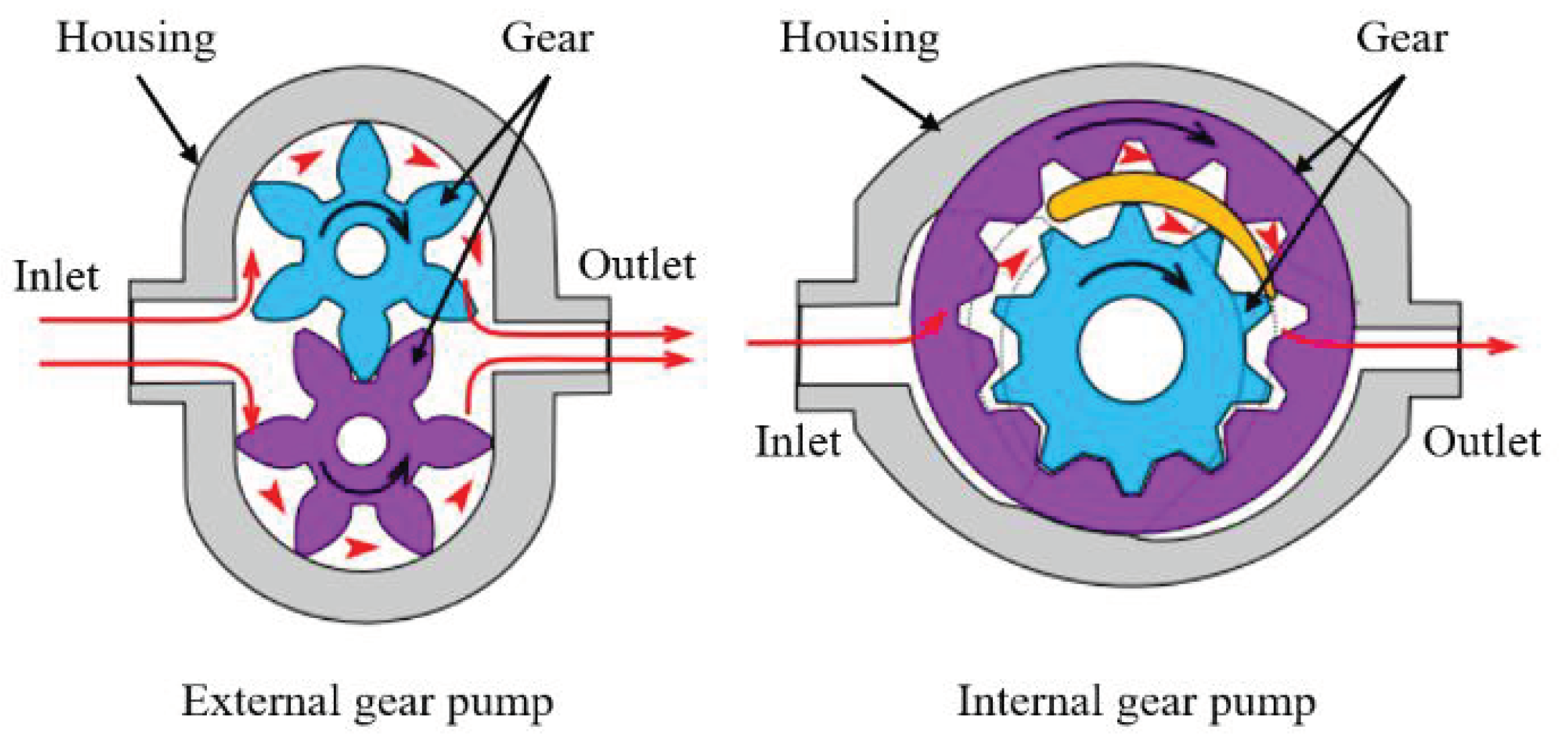
2.1. Mode of Operation of Gear Pumps
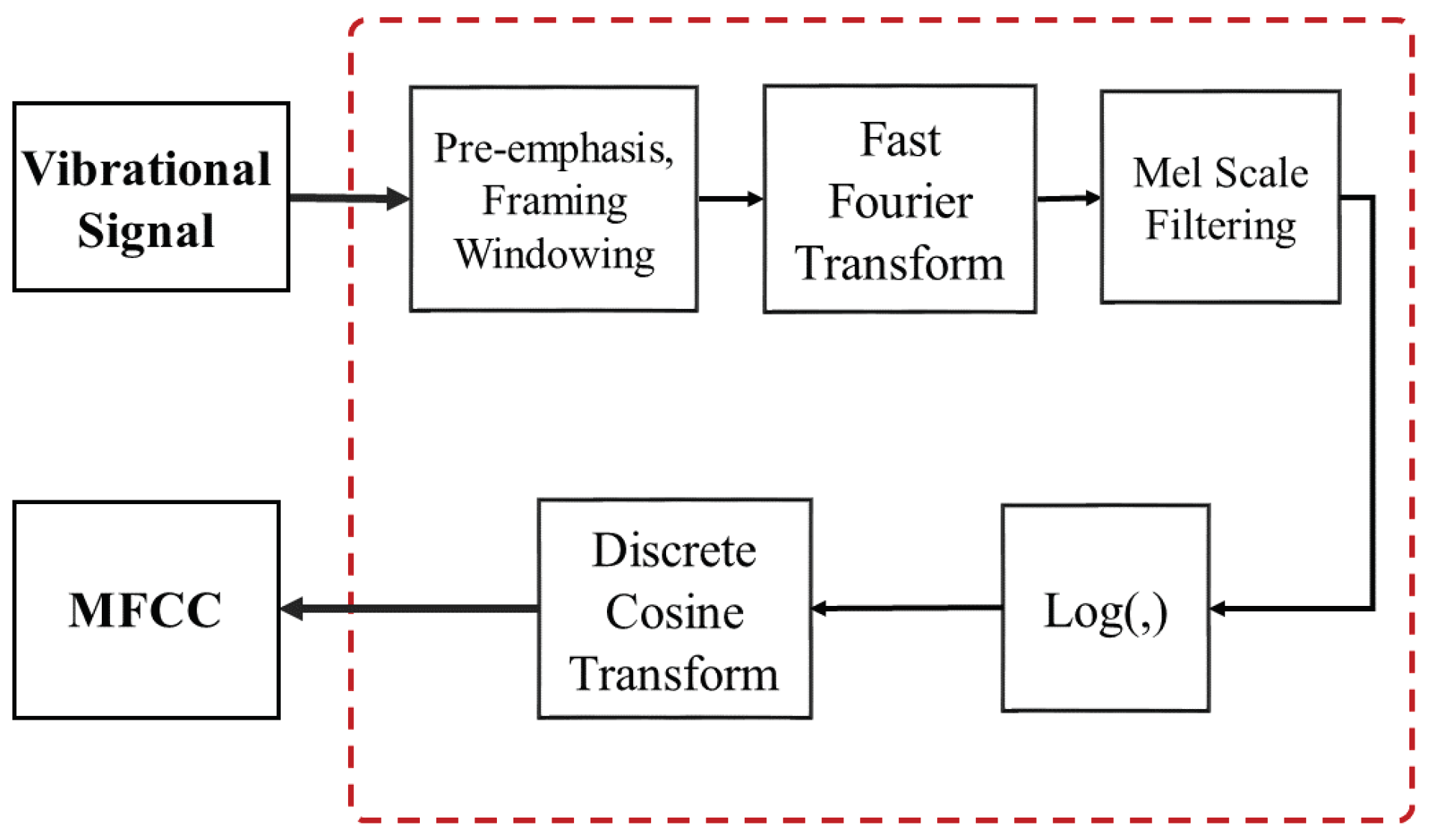
2.2. MFCC Feature Extraction
2.3. Review of ML Algorithms for FDI
2.3.1. Decision Tree
2.3.2. Random Forest
2.3.3. k-Nearest Neighbor
2.3.4. Naïve Bayes Classifier
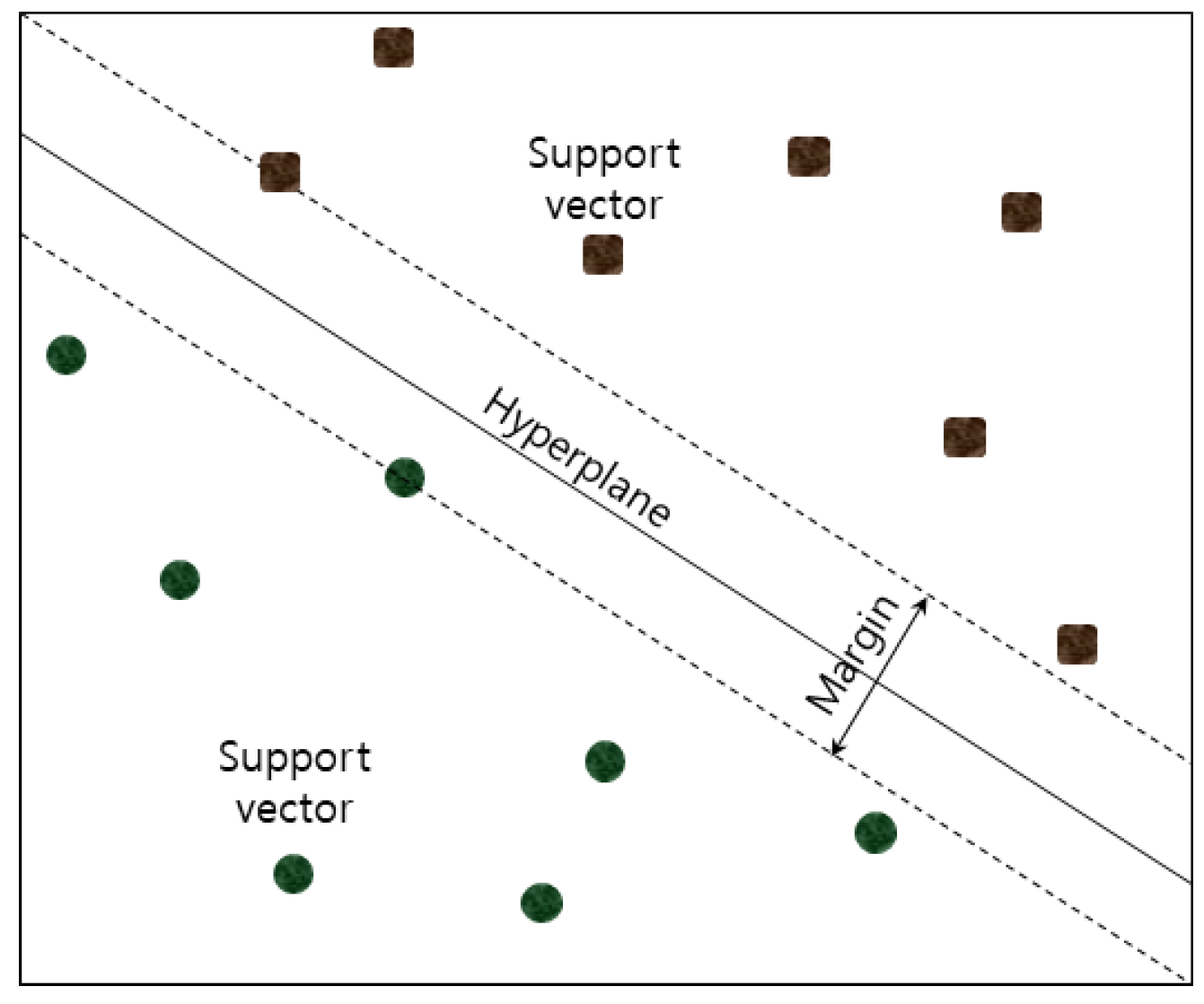
2.3.5. Support Vector Machines
2.3.6. Multi-Layer Perceptron
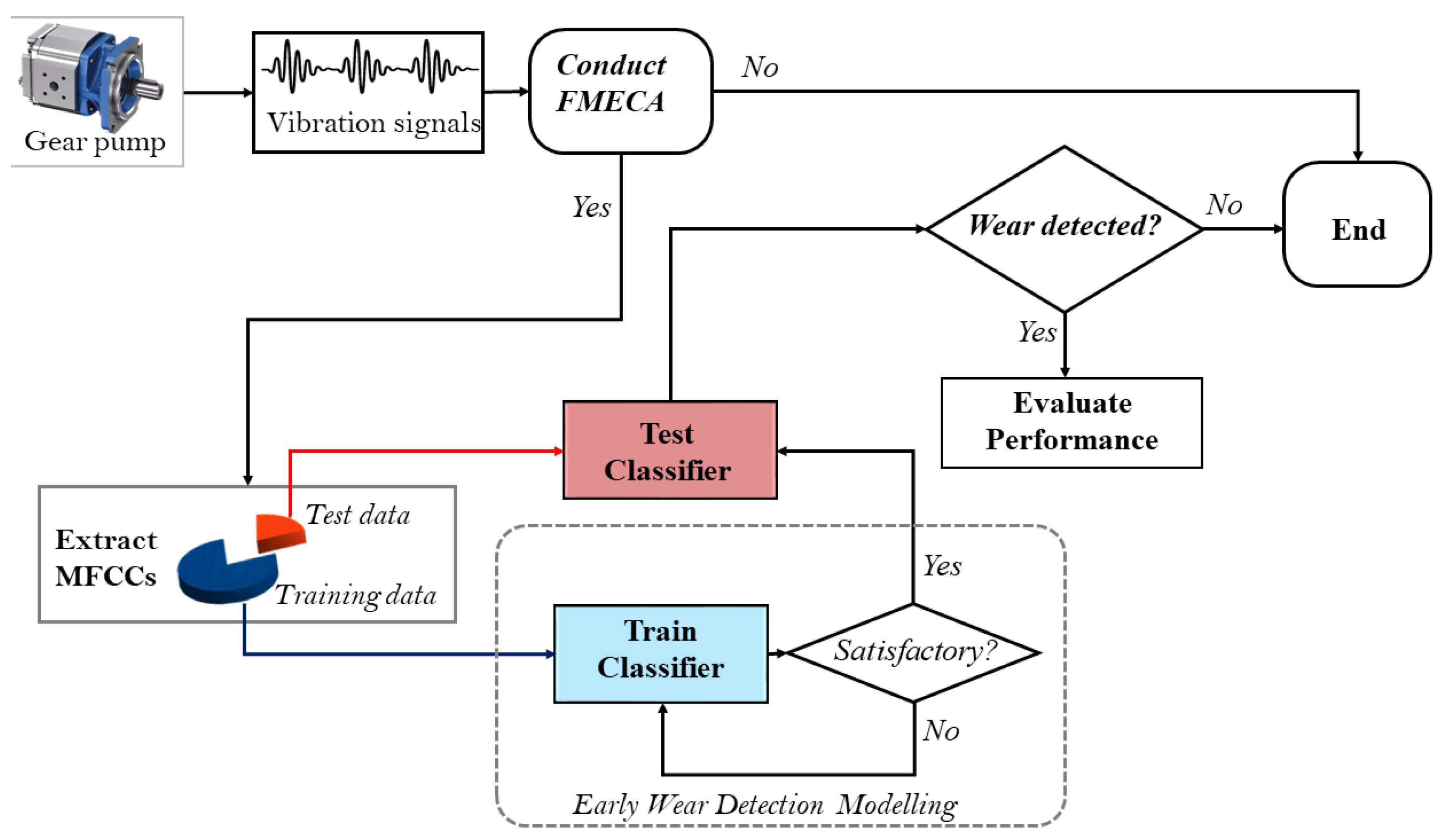
3. Proposed Wear Detection Model
3.1. FMECA
3.2. MFCC Feature Extraction
3.3. ML-Based Modelling and Wear Detection
3.4. Performance Evaluation
4. Experimental Study and Analysis
4.1. FMECA of Gear Pump
4.2. Gear Pump Abrasion Test
4.3. Abrasion Test Results
4.4. Feature Engineering
4.5. ML-Based Wear Detection
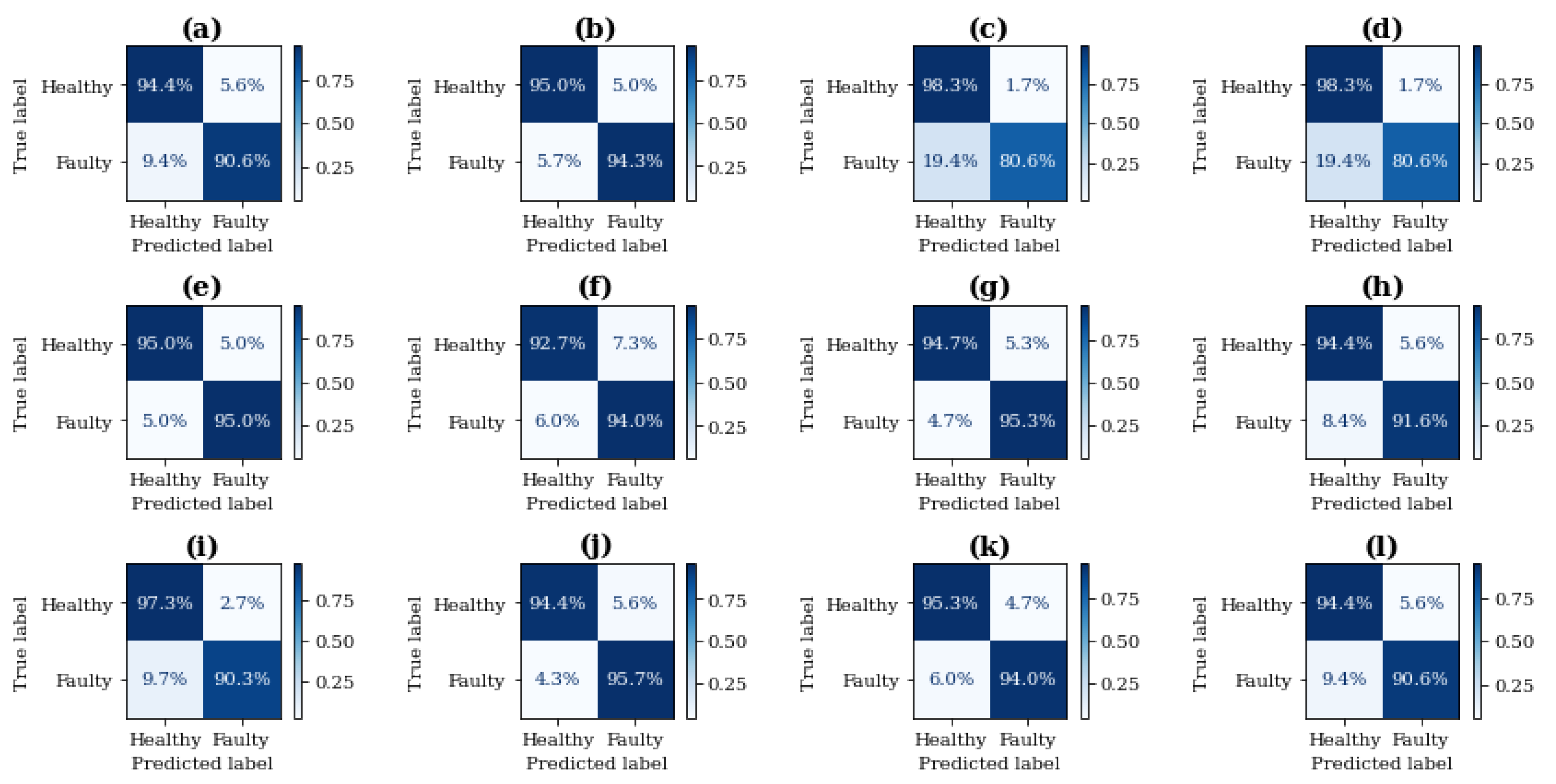
4.6. Performance Evaluations
4.7. Fault Visualization
5. Conclusions and Drawn Insights
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ciani, L.; Guidi, G.; Patrizi, G.; Galar, D. Condition-Based Maintenance of HVAC on a High-Speed Train for Fault Detection. Electronics 2021, 10, 1418. [Google Scholar] [CrossRef]
- Casoli, P.; Pastori, M.; Scolari, F.; Rundo, M. A Vibration Signal-Based Method for Fault Identification and Classification in Hydraulic Axial Piston Pumps. Energies 2019, 12, 953. [Google Scholar] [CrossRef] [Green Version]
- Stamatis, D.H. Failure Mode and Effect Analysis FMEA from Theory to Execution, 2nd ed.; ASQ Quality Press: Milwaukee, WI, USA, 2003. [Google Scholar]
- MIL-STD-1629A, Military Standard: Procedures for Performing a Failure mode, Effects, and Criticality Analysis (24 NOV 1980). Available online: https://extapps.ksc.nasa.gov/Reliability/Documents/milstd1629_FMEA.pdf (accessed on 13 January 2021).
- Gu, Y.; Li, W.; Zhang, J.; Qiu, G. Effects of Wear, Backlash, and Bearing Clearance on Dynamic Characteristics of a Spur Gear System. IEEE Access 2019, 7, 117639–117651. [Google Scholar] [CrossRef]
- Natili, F.; Daga, A.P.; Castellani, F.; Garibaldi, L. Multi-Scale Wind Turbine Bearings Supervision Techniques Using Industrial SCADA and Vibration Data. Appl. Sci. 2021, 11, 6785. [Google Scholar] [CrossRef]
- Dineva, A.; Mosavi, A.; Gyimesi, M.; Vajda, I.; Nabipour, N.; Rabczuk, T. Fault Diagnosis of Rotating Electrical Machines Using Multi-Label Classification. Appl. Sci. 2019, 9, 5086. [Google Scholar] [CrossRef] [Green Version]
- Esakimuthu Pandarakone, S.; Mizuno, Y.; Nakamura, H. A Comparative Study between Machine Learning Algorithm and Artificial Intelligence Neural Network in Detecting Minor Bearing Fault of Induction Motors. Energies 2019, 12, 2105. [Google Scholar] [CrossRef] [Green Version]
- Ju, Y.J.; Kim, M.S.; Kim, K.S.; Lee, J.H. Comparison of Machine Learning Algorithms Applied to Classification of Operating Condition of Rotating Machinery. J. Comput. Des. Eng. 2020, 5, 77–87. [Google Scholar] [CrossRef]
- Ding, C.; Zhao, M.; Lin, J. Sparse feature extraction based on periodical convolutional sparse representation for fault detection of rotating machinery. Meas. Sci. Technol. 2021, 32, 1. [Google Scholar] [CrossRef]
- Qiao, Z.; Elhattab, A.; Shu, X.; He, C. A second-order stochastic resonance method enhanced by fractional-order derivative for mechanical fault detection. Nonlinear Dyn. 2021, 106, 707–723. [Google Scholar] [CrossRef]
- Qiao, Z.; Shu, X. Coupled neurons with multi-objective optimization benefit incipient fault identification of machinery. Chaos Solitons Fractals 2021, 145, 110813. [Google Scholar] [CrossRef]
- Akpudo, U.E.; Hur, J.-W. D-dCNN: A Novel Hybrid Deep Learning-Based Tool for Vibration-Based Diagnostics. Energies 2021, 14, 5286. [Google Scholar] [CrossRef]
- Kim, S.; Akpudo, U.E.; Hur, J.-W. A Cost-Aware DNN-Based FDI Technology for Solenoid Pumps. Electronics 2021, 10, 2323. [Google Scholar] [CrossRef]
- Akpudo, U.E.; Hur, J.-W. A CEEMDAN-Assisted Deep Learning Model for the RUL Estimation of Solenoid Pumps. Electronics 2021, 10, 2054. [Google Scholar] [CrossRef]
- Akpudo, U.E.; Hur, J.W. Towards bearing failure prognostics: A practical comparison between data-driven methods for industrial applications. J. Mech. Sci. Technol. 2020, 34, 4161–4172. [Google Scholar] [CrossRef]
- Han, T.; Jiang, D.; Zhao, Q.; Wang, L.; Yin, K. Comparison of random forest, artificial neural networks and support vector machine for intelligent diagnosis of rotating machinery. Trans. Inst. Meas. Control 2017, 40, 2681–2693. [Google Scholar] [CrossRef]
- Akpudo, U.E.; Hur, J. A Cost-Efficient MFCC-Based Fault Detection and Isolation Technology for Electromagnetic Pumps. Electronics 2021, 10, 439. [Google Scholar] [CrossRef]
- Caesarendra, W.; Tjahjowidodo, T. A Review of Feature Extraction Methods in Vibration-Based Condition Monitoring and Its Application for Degradation Trend Estimation of Low-Speed Slew Bearing. Machines 2017, 5, 21. [Google Scholar] [CrossRef]
- Akpudo, U.E.; Hur, J.W. A Multi-Domain Diagnostics Approach for Solenoid Pumps Based on Discriminative Features. IEEE Access 2020, 8, 175020–175034. [Google Scholar] [CrossRef]
- Tang, S.; Zhu, Y.; Yuan, S.; Li, G. Intelligent Diagnosis towards Hydraulic Axial Piston Pump Using a Novel Integrated CNN Model. Sensors 2020, 20, 7152. [Google Scholar] [CrossRef]
- Akpudo, U.E.; Hur, J.W. Intelligent Solenoid Pump Fault Detection based on MFCC Features, LLE and SVM. In Proceedings of the International Conference on AI in Information and Communication (ICAIIC 2020), Fukuoka, Japan, 19–21 February 2020; pp. 404–408. [Google Scholar]
- Lee, G.H.; Shin, B.C.; Hur, J.W. Fault Classification of Gear Pumps Using SVM. J. Appl. Reliab. 2020, 20, 187–196. [Google Scholar] [CrossRef]
- Tjoa, E.; Guan, C. A Survey on Explainable Artificial Intelligence (XAI): Toward Medical XAI. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 4793–4813. [Google Scholar] [CrossRef] [PubMed]
- Asman, S.H.; Ab Aziz, N.F.; Ungku Amirulddin, U.A.; Ab Kadir, M.Z.A. Decision Tree Method for Fault Causes Classification Based on RMS-DWT Analysis in 275 kV Transmission Lines Network. Appl. Sci. 2021, 11, 4031. [Google Scholar] [CrossRef]
- Li, Z.; Zhang, Y.; Abu-Siada, A.; Chen, X.; Li, Z.; Xu, Y.; Zhang, L.; Tong, Y. Fault Diagnosis of Transformer Windings Based on Decision Tree and Fully Connected Neural Network. Energies 2021, 14, 1531. [Google Scholar] [CrossRef]
- Xu, G.; Liu, M.; Jiang, Z.; Söffker, D.; Shen, W. Bearing Fault Diagnosis Method Based on Deep Convolutional Neural Network and Random Forest Ensemble Learning. Sensors 2019, 19, 1088. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yang, J.; Sun, Z.; Chen, Y. Fault Detection Using the Clustering-kNN Rule for Gas Sensor Arrays. Sensors 2016, 16, 2069. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pietrzak, P.; Wolkiewicz, M. On-line Detection and Classification of PMSM Stator Winding Faults Based on Stator Current Symmetrical Components Analysis and the KNN Algorithm. Electronics 2021, 10, 1786. [Google Scholar] [CrossRef]
- Zhang, N.; Wu, L.; Yang, J.; Guan, Y. Naive Bayes Bearing Fault Diagnosis Based on Enhanced Independence of Data. Sensors 2018, 18, 463. [Google Scholar] [CrossRef] [Green Version]
- Oh, S.H. Improving the Water Level Prediction of Multi-Layer Perceptron with a Modified Error Function. Int. J. Contents 2018, 13, 23–28. [Google Scholar] [CrossRef]
- KS A 0006:2001. Standard Atmospheric Conditions for Testing. Korean Agency for Technology and Standard, Eumseong-gun, Korea. 2014, pp. 1–2. Available online: https://infostore.saiglobal.com/en-us/standards/ks-a-0006-2001-639645_saig_ksa_ksa_1524462/ (accessed on 13 January 2021).
- Pumps, Hydraulic, Variable Flow. In General Specification for MIL-P-19692 E; Department of Defense: Washington, DC, USA, 1994; pp. 20–21, 24–25. Available online: http://everyspec.com/MIL-SPECS/MIL-SPECS-MIL-P/MIL-P-19692E_38833/ (accessed on 13 October 2020).
- Test Powders and Test Particles; KS A 0090, Korean Agency for Technology and Standards: Eumseong-gun, Korea, 2017. Available online: https://shop.standards.ie/Store/Details.aspx?ProductID=2036387 (accessed on 13 October 2020).
- Nasir, I.M.; Khan, M.A.; Yasmin, M.; Shah, J.H.; Gabryel, M.; Scherer, R.; Damaševičius, R. Pearson Correlation-Based Feature Selection for Document Classification Using Balanced Training. Sensors 2020, 20, 6793. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Component | Function | Failure Mode | Cause | Effect | Criticality | |||
|---|---|---|---|---|---|---|---|---|
| Sr | Dr | Fr | RPN | |||||
| Gear Case | Structure flow distribution | wear | Contaminants, fatigue | Outside leakage, efficiency reduction | 5 | 2 | 2 | 20 |
| Transient Resistance | fluid passage Narrow | Noise | 3 | 2 | 1 | 6 | ||
| Cover | Structure | wear | Uneven load | Outside leakage, efficiency reduction | 9 | 3 | 3 | 81 |
| Corrosion | Moisture, surface contamination | Outside leakage | 5 | 3 | 1 | 15 | ||
| Drive shaft gear | Power transmission | Gear hit damage | Foreign substance, fatigue | Vibration and noise | 7 | 2 | 3 | 42 |
| Gear end wear | Contaminants, fatigue | Outside leakage, efficiency reduction | 7 | 3 | 2 | 42 | ||
| Damage | Increased fatigue, stress concentration | Inoperable | 5 | 3 | 1 | 15 | ||
| Follower shaft gear | fluid suction, discharge | Gear hit damage | Foreign substance, fatigue | Vibration and noise | 7 | 2 | 3 | 42 |
| Gear end wear | Contaminants, fatigue | outside leakage, efficiency reduction | 7 | 3 | 2 | 42 | ||
| Damage | Increased fatigue, stress concentration | Inoperable | 5 | 3 | 1 | 15 | ||
| Shroud | Vibration damping | wear | Uneven load | Leakage, efficiency reduction | 7 | 3 | 2 | 42 |
| Vibration | Design failure | Vibration and noise | 5 | 3 | 1 | 15 | ||
| Seal | fluid leak prevention | Damage | Aging, cracking | Internal/external leakage | 7 | 3 | 2 | 42 |
| Bearing | Rotation and support | wear | Foreign substance | Vibration, efficiency reduction | 7 | 3 | 2 | 42 |
| Crack | Fatigue | Friction and vibration | 5 | 3 | 1 | 15 | ||
| Fastening bolt | Housing fastening | Loosening | Poor assembly | Internal/external leakage | 7 | 3 | 2 | 42 |
| Damage | Increased fatigue, stress concentration | Outside leakage | 5 | 3 | 1 | 15 | ||
| Algorithm | Parameter | Value |
|---|---|---|
| Logistic regression (LR) | regularisation | L1 |
| KNN | k | 5 |
| Linear SVM (SVM-Lin) | kernel | Linear |
| Gaussian-kernel SVM (SVM–RBF) | C, gamma | 10, 1 |
| Gradient boosting Classifier (GBC) | n estimators | 1000 |
| DT | Pruning | 12 |
| RF | n estimators | 120 |
| Multi-layer perceptron (MLP) classifier | n layers, learning rate | 3, 0.001 |
| NBC | Gaussian | – |
| Adaboost classifier (ABC) | n estimators, learning rate | 50, 0.1 |
| Quadratic discriminant analysis (QDA) | regularization | 0.001 |
| Gaussian process classifier (GPC) | kernel | RBF |
| Algorithm | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) | Cost (Secs) |
|---|---|---|---|---|---|
| LR | 92.50 | 92.56 | 92.49 | 92.50 | 0.03697 |
| k-NN | 94.67 | 94.67 | 94.67 | 94.67 | 0.01035 |
| SVM-Lin | 89.50 | 90.79 | 89.47 | 89.41 | 0.14247 |
| SVM–RBF | 89.50 | 90.79 | 89.47 | 89.41 | 9.35574 |
| GBC | 94.83 | 94.83 | 94.83 | 94.83 | 12.84497 |
| DT | 93.00 | 93.00 | 93.00 | 93.00 | 0.01374 |
| RF | 95.17 | 95.17 | 95.17 | 95.17 | 17.61929 |
| MLP | 93.33 | 93.34 | 93.33 | 93.33 | 15.47579 |
| NBC | 93.83 | 94.06 | 93.82 | 93.82 | 0.0800 |
| ABC | 95.00 | 95.01 | 95.00 | 95.00 | 0.94587 |
| QDA | 94.67 | 94.68 | 94.66 | 94.67 | 0.0740 |
| GPC | 92.50 | 92.56 | 92.49 | 92.50 | 6.52012 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, G.-H.; Akpudo, U.E.; Hur, J.-W. FMECA and MFCC-Based Early Wear Detection in Gear Pumps in Cost-Aware Monitoring Systems. Electronics 2021, 10, 2939. https://doi.org/10.3390/electronics10232939
Lee G-H, Akpudo UE, Hur J-W. FMECA and MFCC-Based Early Wear Detection in Gear Pumps in Cost-Aware Monitoring Systems. Electronics. 2021; 10(23):2939. https://doi.org/10.3390/electronics10232939
Chicago/Turabian StyleLee, Geon-Hui, Ugochukwu Ejike Akpudo, and Jang-Wook Hur. 2021. "FMECA and MFCC-Based Early Wear Detection in Gear Pumps in Cost-Aware Monitoring Systems" Electronics 10, no. 23: 2939. https://doi.org/10.3390/electronics10232939