
Word Sense Disambiguation Using Prior Probability Estimation Based on the Korean WordNet


Abstract
:1. Introduction
2. Related Study
3. Lexical Disambiguation Using the Korean Lexical Semantic Network
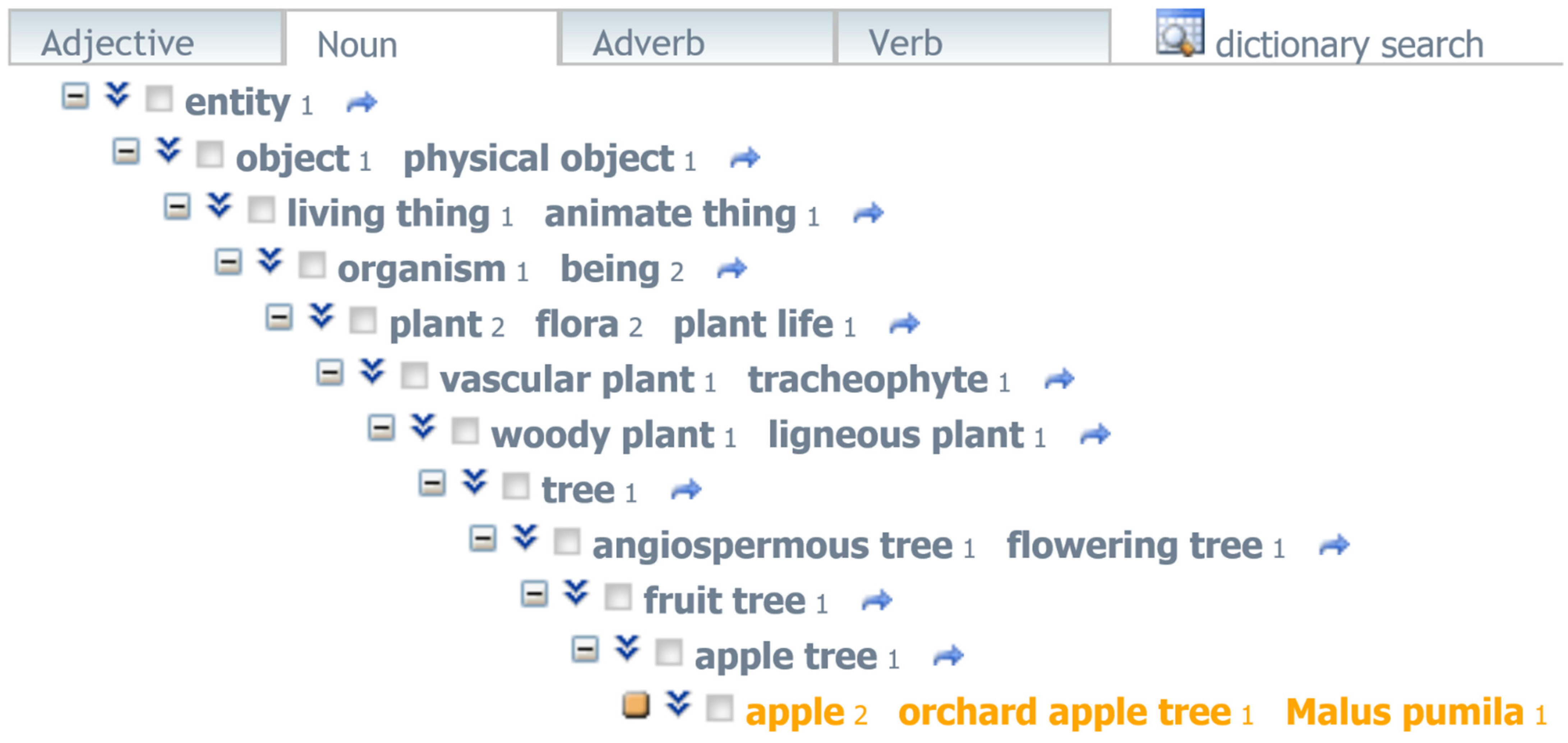
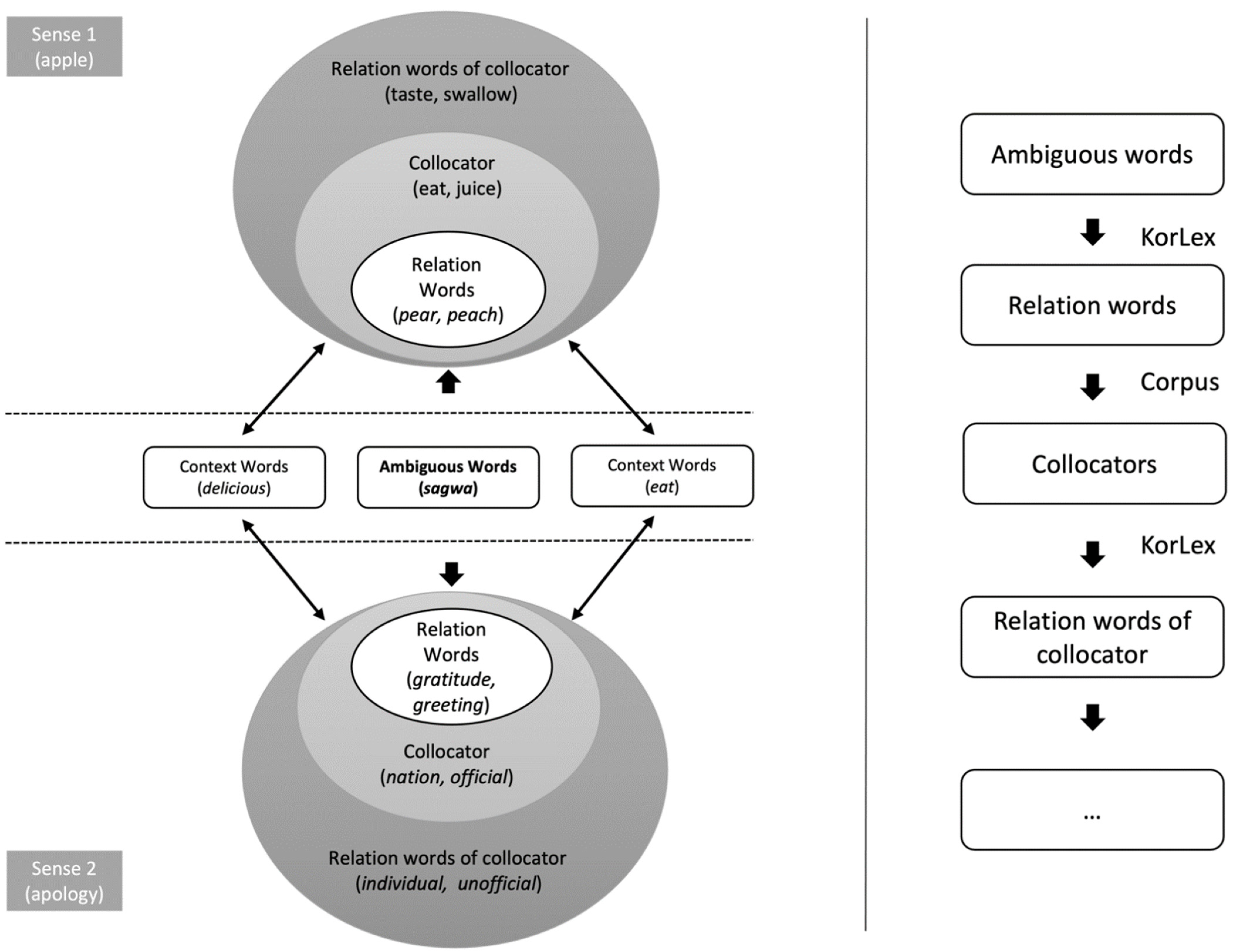
3.1. Analysis of Relationship between Words Using the Korean Lexical Semantic Network (KorLex)
- Null hypothesis: Two words (, ) are not related to each other (independent),
- Alternative hypothesis: Two words (, ) are related to each other (dependent),
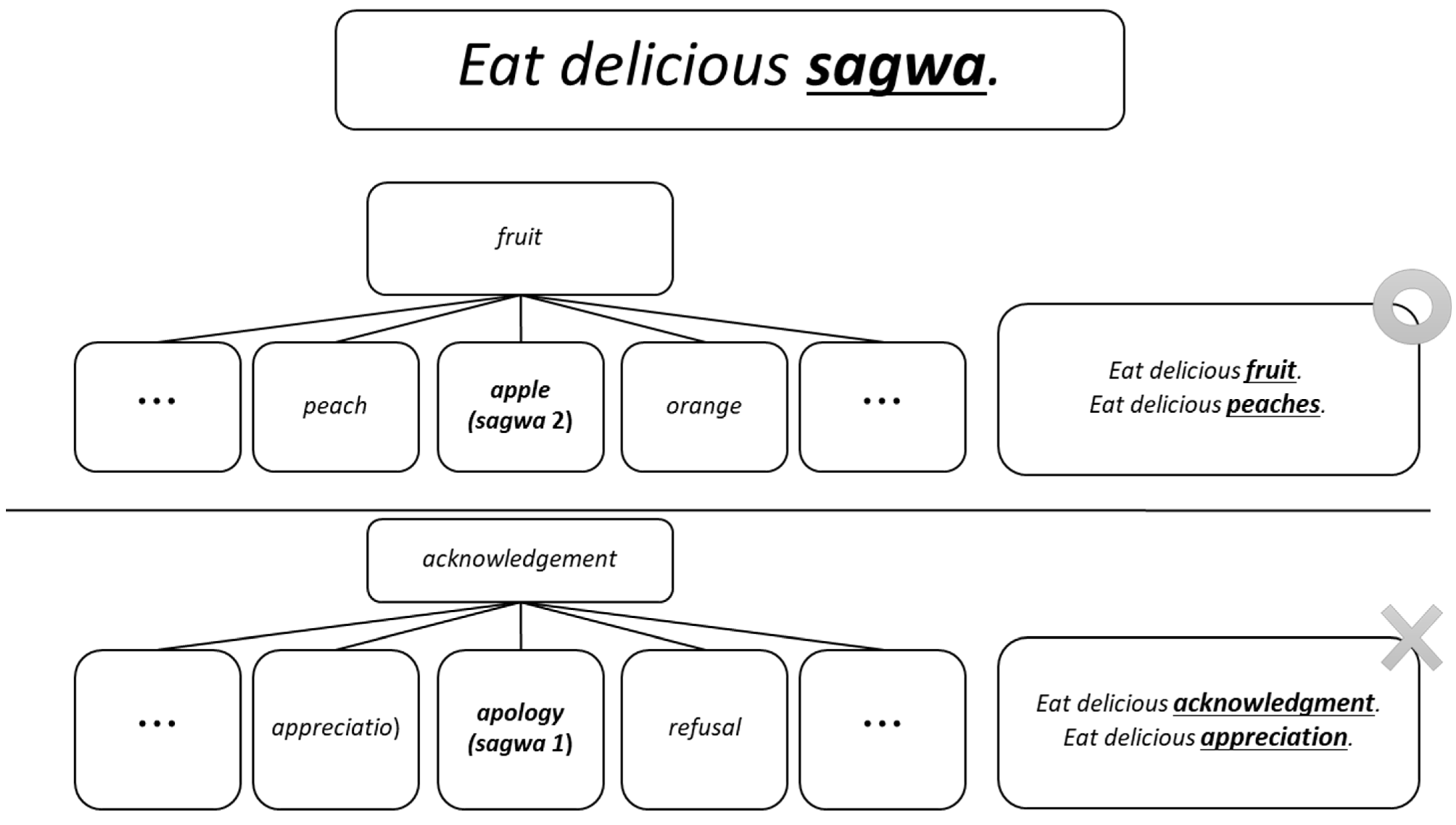
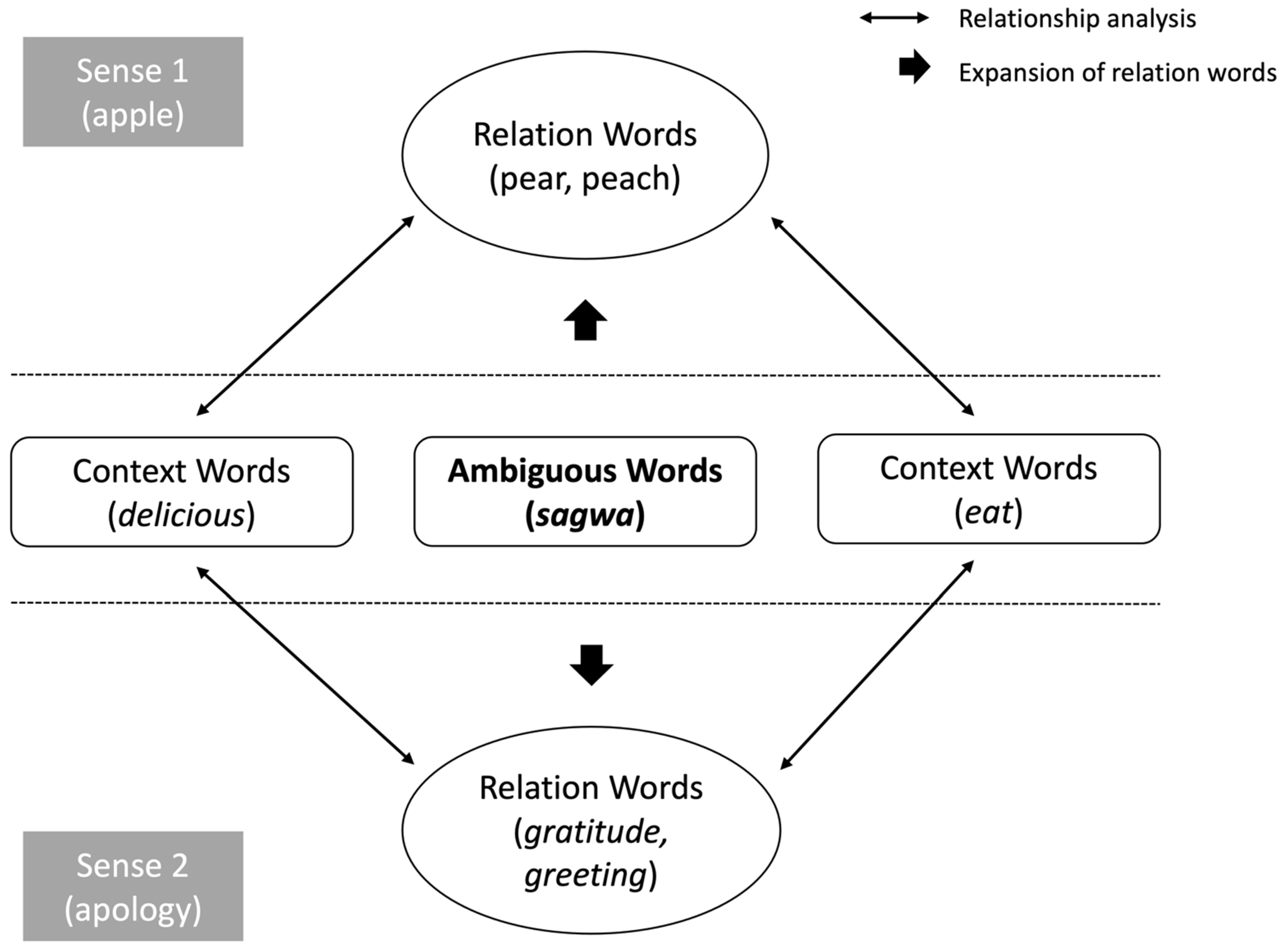
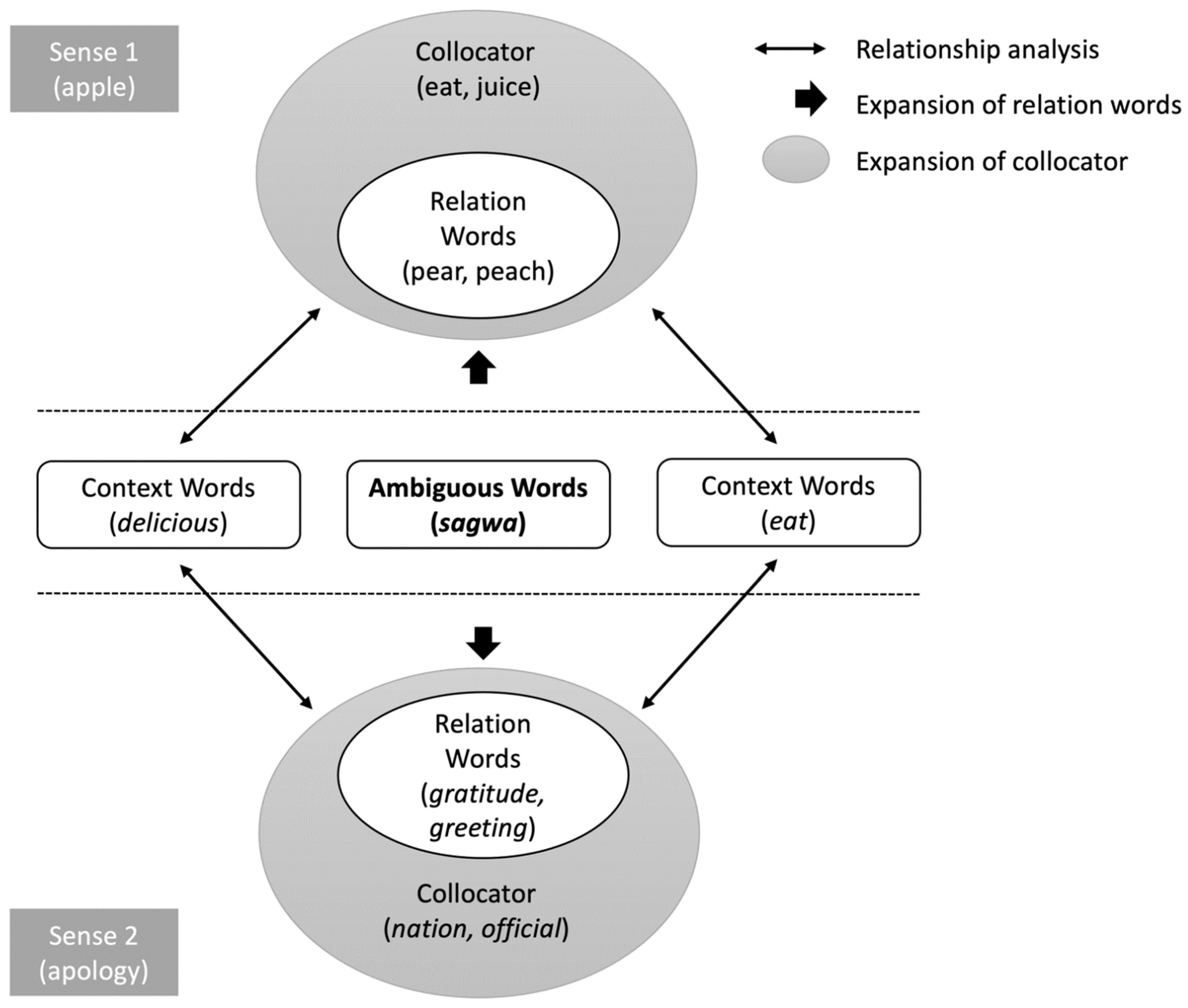
3.2. Expansion of Semantically Related Words to the Ambiguous Word
3.3. Estimation of Prior Information Using Semantically Related Words of an Ambiguous Word
4. Experiment and Evaluation
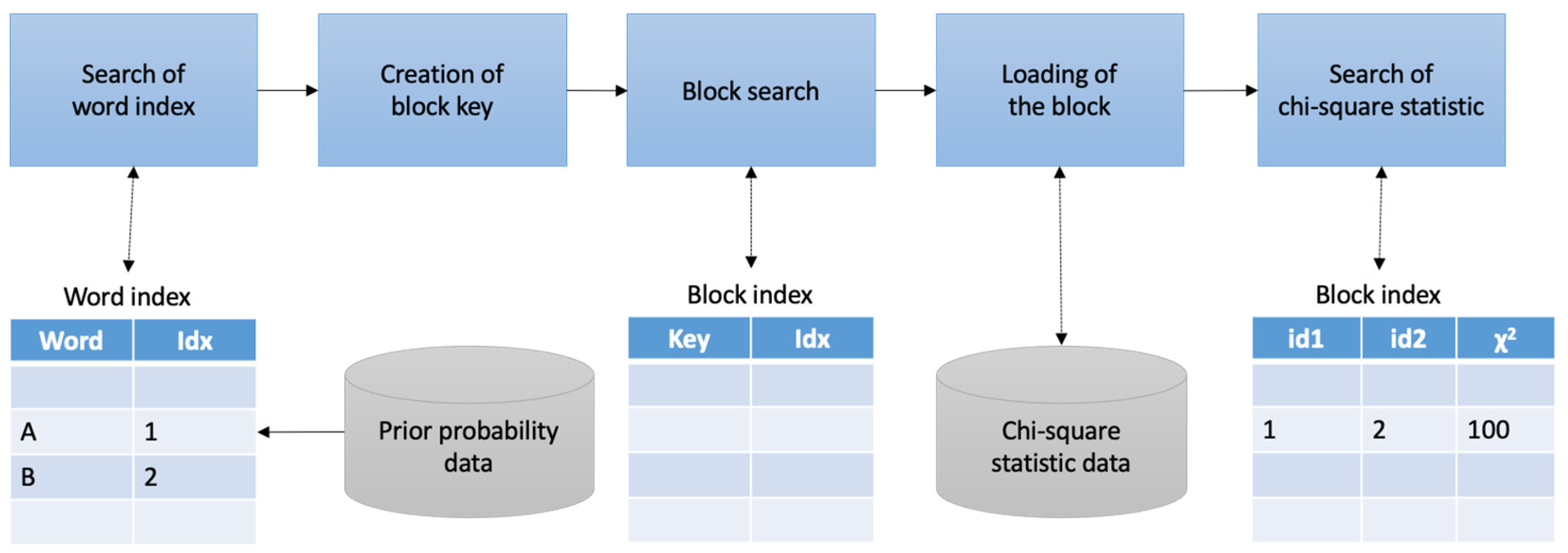
4.1. Experiment Environment
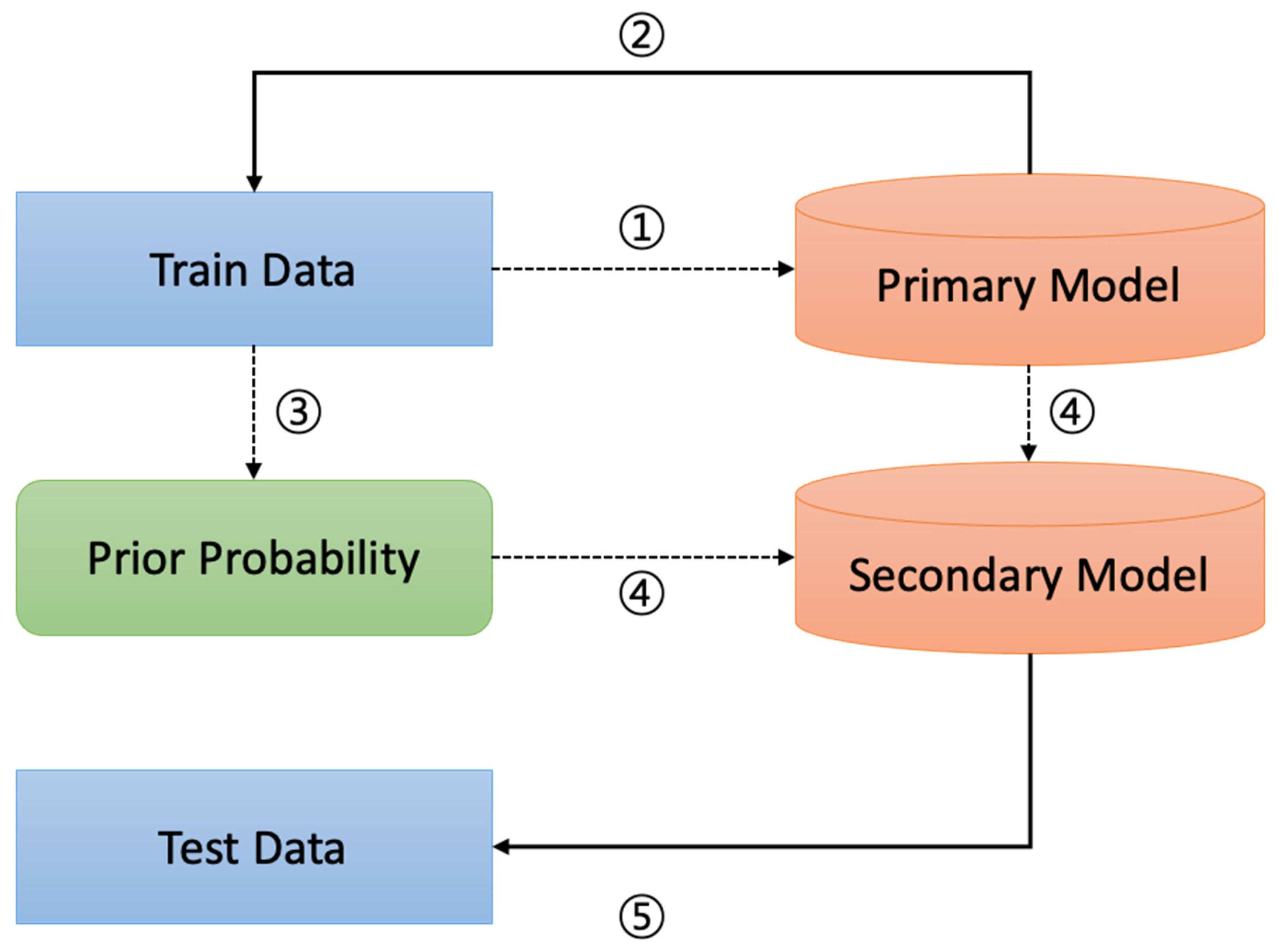
4.2. Experiment Method
- ①
- A weight is adjusted according to the types of semantically related words of an ambiguous word so that more information regarding the relation words can be used than in existing methods.
- ②
- Semantically related words of an ambiguous word and the coordinate terms of the related words are expanded so that more information can be used than in existing methods.
- ③
- Using the part-of-speech information of words, normalization is done for words such as numerals and proper nouns.
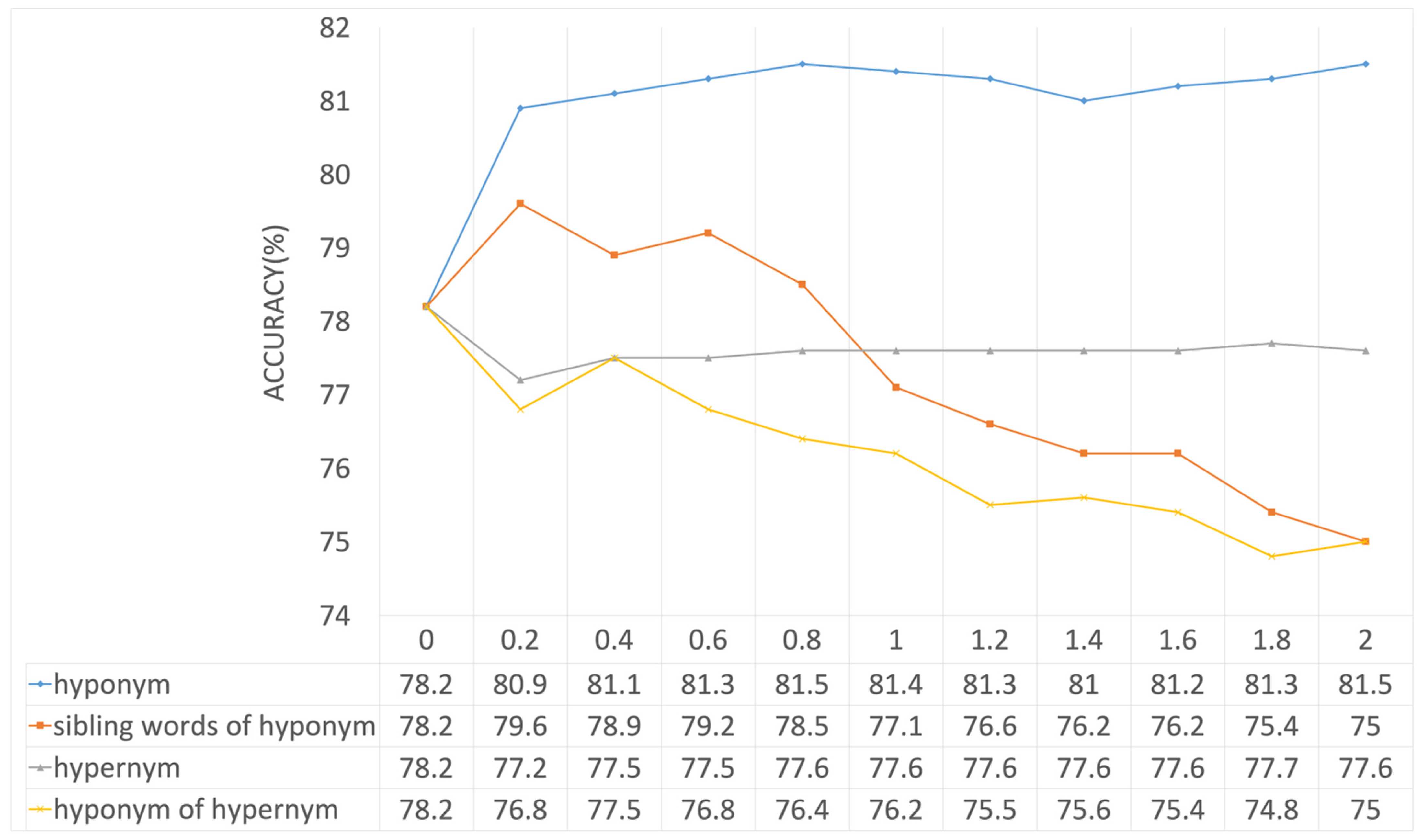
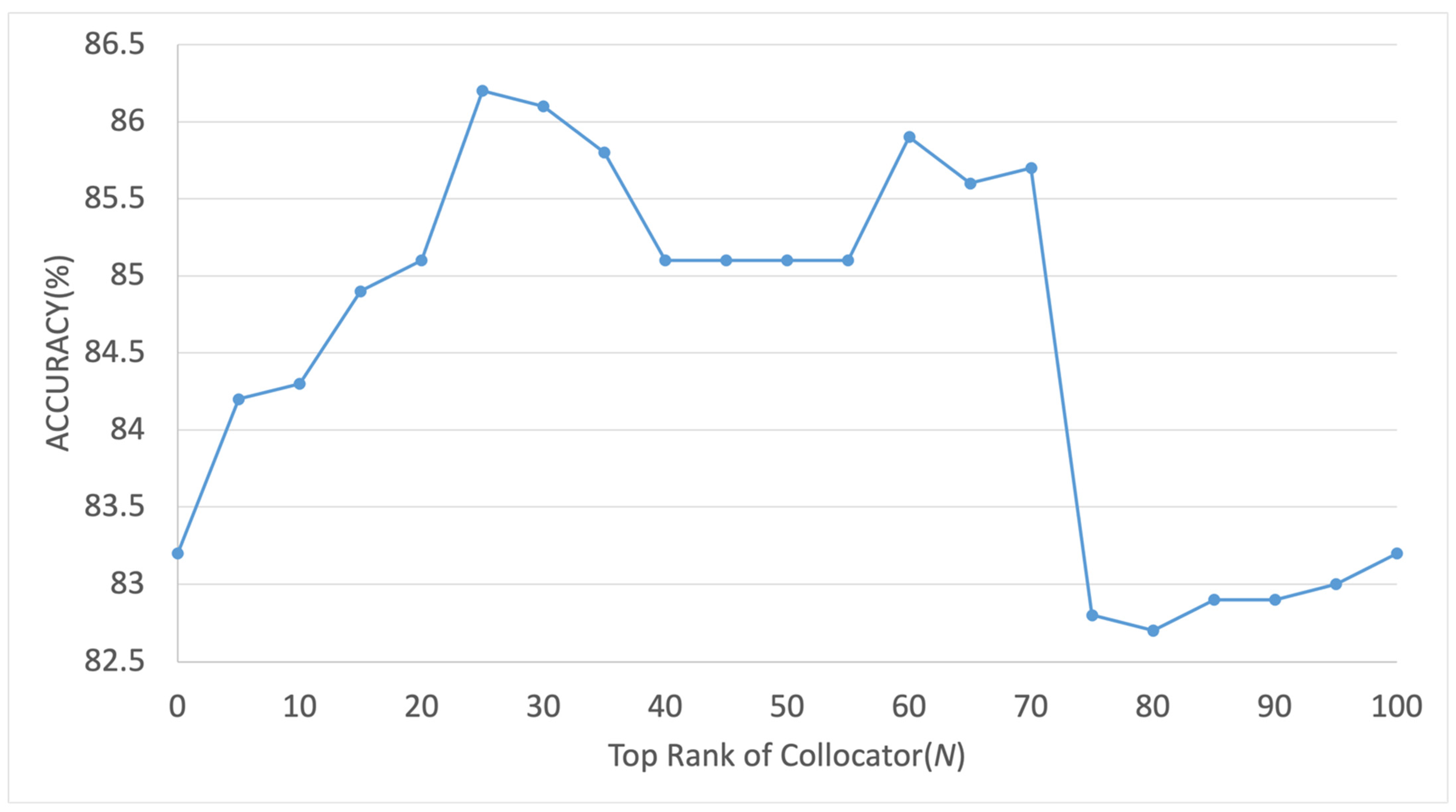
4.3. Analysis of Effect of the Prior Probability Estimation
4.4. Practical Experiment with the Proposed System
5. Conclusions and Future Research
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Chi-Square (x2) Distribution | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Area to the Right of Critical Value | ||||||||||
| Degrees of Freedom | 0.995 | 0.99 | 0.975 | 0.95 | 0.90 | 0.10 | 0.05 | 0.025 | 0.01 | 0.005 |
| 1 | --- | --- | 0.001 | 0.004 | 0.016 | 2.706 | 3.841 | 5.024 | 6.635 | 7.879 |
| 2 | 0.010 | 0.020 | 0.051 | 0.103 | 0.211 | 4.605 | 5.991 | 7.378 | 9.210 | 10.597 |
| 3 | 0.072 | 0.115 | 0.216 | 0.352 | 0.584 | 6.251 | 7.815 | 9.348 | 11.345 | 12.838 |
| 4 | 0.207 | 0.297 | 0.484 | 0.711 | 1.064 | 7.779 | 9.488 | 11.143 | 13.277 | 14.860 |
| 5 | 0.412 | 0.554 | 0.831 | 1.145 | 1.610 | 9.236 | 11.070 | 12.833 | 15.086 | 16.750 |
| 6 | 0.676 | 0.872 | 1.237 | 1.635 | 2.204 | 10.645 | 12.592 | 14.449 | 16.812 | 18.548 |
| 7 | 0.989 | 1.239 | 1.690 | 2.167 | 2.833 | 12.017 | 14.067 | 16.013 | 18.475 | 20.278 |
| 8 | 1.344 | 1.646 | 2.180 | 2.733 | 3.490 | 13.362 | 15.507 | 17.535 | 20.090 | 21.955 |
| 9 | 1.735 | 2.088 | 2.700 | 3.325 | 4.168 | 14.684 | 16.919 | 19.023 | 21.666 | 23.589 |
| 10 | 2.156 | 2.558 | 3.247 | 3.940 | 4.865 | 15.987 | 18.307 | 20.483 | 23.209 | 25.188 |
| 11 | 2.603 | 3.053 | 3.816 | 4.575 | 5.578 | 17.275 | 19.675 | 21.920 | 24.725 | 26.757 |
| 12 | 3.074 | 3.571 | 4.404 | 5.226 | 6.304 | 18.549 | 21.026 | 23.337 | 26.217 | 28.300 |
| 13 | 3.565 | 4.107 | 5.009 | 5.892 | 7.042 | 19.812 | 22.362 | 24.736 | 27.688 | 29.819 |
| 14 | 4.075 | 4.660 | 5.629 | 6.571 | 7.790 | 21.064 | 23.685 | 26.119 | 29.141 | 31.319 |
| 15 | 4.601 | 5.229 | 6.262 | 7.261 | 8.547 | 22.307 | 24.996 | 27.488 | 30.578 | 32.801 |
| 16 | 5.142 | 5.812 | 6.908 | 7.962 | 9.312 | 23.542 | 26.296 | 28.845 | 32.000 | 34.267 |
| 17 | 5.697 | 6.408 | 7.564 | 8.672 | 10.085 | 24.769 | 27.587 | 30.191 | 33.409 | 35.718 |
| 18 | 6.265 | 7.015 | 8.231 | 9.390 | 10.865 | 25.989 | 28.869 | 31.526 | 34.805 | 37.156 |
| 19 | 6.844 | 7.633 | 8.907 | 10.117 | 11.651 | 27.204 | 30.144 | 32.852 | 36.191 | 38.582 |
| 20 | 7.434 | 8.260 | 9.591 | 10.851 | 12.443 | 28.412 | 31.410 | 34.170 | 37.566 | 39.997 |
| 21 | 8.034 | 8.897 | 10.283 | 11.591 | 13.240 | 29.615 | 32.671 | 35.479 | 38.932 | 41.401 |
| 22 | 8.643 | 9.542 | 10.982 | 12.338 | 14.041 | 30.813 | 33.924 | 36.781 | 40.289 | 42.796 |
| 23 | 9.260 | 10.196 | 11.689 | 13.091 | 14.848 | 32.007 | 35.172 | 38.076 | 41.638 | 44.181 |
| 24 | 9.886 | 10.856 | 12.401 | 13.848 | 15.659 | 33.196 | 36.415 | 39.364 | 42.980 | 45.559 |
| 25 | 10.520 | 11.524 | 13.120 | 14.611 | 16.473 | 34.382 | 37.652 | 40.646 | 44.314 | 46.928 |
| 26 | 11.160 | 12.198 | 13.844 | 15.379 | 17.292 | 35.563 | 38.885 | 41.923 | 45.642 | 48.290 |
| 27 | 11.808 | 12.879 | 14.573 | 16.151 | 18.114 | 36.741 | 40.113 | 43.195 | 46.963 | 49.645 |
| 28 | 12.461 | 13.565 | 15.308 | 16.928 | 18.939 | 37.916 | 41.337 | 44.461 | 48.278 | 50.993 |
| 29 | 13.121 | 14.256 | 16.047 | 17.708 | 19.768 | 39.087 | 42.557 | 45.722 | 49.588 | 52.336 |
| 30 | 13.787 | 14.953 | 16.791 | 18.493 | 20.599 | 40.256 | 43.773 | 46.979 | 50.892 | 53.672 |
| 40 | 20.707 | 22.164 | 24.433 | 26.509 | 29.051 | 51.805 | 55.758 | 59.342 | 63.691 | 66.766 |
| 50 | 27.991 | 29.707 | 32.357 | 34.764 | 37.689 | 63.167 | 67.505 | 71.420 | 76.154 | 79.490 |
| 60 | 35.534 | 37.485 | 40.482 | 43.188 | 46.459 | 74.397 | 79.082 | 83.298 | 88.379 | 91.952 |
| 70 | 43.275 | 45.442 | 48.758 | 51.739 | 55.329 | 85.527 | 90.531 | 95.023 | 100.425 | 104.215 |
| 80 | 51.172 | 53.540 | 57.153 | 60.391 | 64.278 | 96.578 | 101.879 | 106.629 | 112.329 | 116.321 |
| 90 | 59.196 | 61.754 | 65.647 | 69.126 | 73.291 | 107.565 | 113.145 | 118.136 | 124.116 | 128.299 |
| 100 | 67.328 | 70.065 | 74.222 | 77.929 | 82.358 | 118.498 | 124.342 | 129.561 | 135.807 | 140.169 |
References
- Ide, N.; Véronis, J. Introduction to the special issue on word sense disambiguation: The state of the art. Comput. Linguist. 1998, 24, 1–40. [Google Scholar]
- Kim, S.-K.; Huh, J.-H. Artificial intelligence based electronic healthcare solution. In Advances in Computer Science and Ubiquitous Computing; Springer: Berlin/Heidelberg, Germany, 2021; pp. 575–581. [Google Scholar]
- Kim, S.-K.; Huh, J.-H. Consistency of medical data using intelligent neuron faster R-CNN algorithm for smart health care application. Healthcare 2020, 8, 185. [Google Scholar] [CrossRef] [PubMed]
- Navigli, R. Word sense disambiguation: A survey. ACM Comput. Surv. (CSUR) 2009, 41, 1–69. [Google Scholar] [CrossRef]
- Le, N.-B.-V.; Huh, J.-H. Applying sentiment product reviews and visualization for BI systems in vietnamese E-commerce website: Focusing on vietnamese context. Electronics 2021, 10, 2481. [Google Scholar] [CrossRef]
- Yoon, A.-S.; Hwang, S.-H.; Lee, E.-R.; Kwon, H.-C. Construction of Korean WordNet. J. KIISE Softw. Appl. 2009, 36, 92–108. [Google Scholar]
- Lesk, M. Automatic sense disambiguation using machine readable dictionaries: How to tell a pine cone from an ice cream cone. In Proceedings of the 5th Annual International Conference on Systems Documentation, New York, NY, USA, 1 June 1986; pp. 24–26. [Google Scholar]
- Luk, A.K. Statistical sense disambiguation with relatively small corpora using dictionary definitions. In Proceedings of the 33rd annual meeting on Association for Computational Linguistics, Cambridge, MA, USA, 26–30 June 1995; pp. 181–188. [Google Scholar]
- Miller, G.A.; Beckwith, R.; Fellbaum, C.; Gross, D.; Miller, K.J. Introduction to WordNet: An on-line lexical database. Int. J. Lexicogr. 1990, 3, 235–244. [Google Scholar] [CrossRef] [Green Version]
- Resnik, P. Disambiguating noun groupings with respect to WordNet senses. In Natural Language Processing Using Very Large Corpora; Springer: Berlin/Heidelberg, Germany, 1999; pp. 77–98. [Google Scholar]
- Agirre, E.; Rigau, G. Word sense disambiguation using conceptual density. arXiv 1996, arXiv:preprint cmp-lg/9606007. [Google Scholar] [CrossRef] [Green Version]
- Mihalcea, R.; Moldovan, D. A method for word sense disambiguation of unrestricted text. In Proceedings of the 37th annual meeting of the Association for Computational Linguistics, College Park, MD, USA, 20–26 June 1999; pp. 152–158. [Google Scholar]
- Mihalcea, R. Unsupervised large-vocabulary word sense disambiguation with graph-based algorithms for sequence data labeling. In Proceedings of the Human Language Technology Conference and Conference on Empirical Methods in Natural Language Processing, Vancouver, BC, Canada, 6–8 October 2005; pp. 411–418. [Google Scholar]
- Pedersen, T. A simple approach to building ensembles of naive bayesian classifiers for word sense disambiguation. arXiv 2000, arXiv:preprint cs/0005006. [Google Scholar]
- Ramakrishnan, G.; Prithviraj, B.; Bhattacharyya, P. A gloss-centered algorithm for disambiguation. In Proceedings of the SENSEVAL-3, the Third International Workshop on the Evaluation of Systems for the Semantic Analysis of Text, Barcelona, Spain, 25–26 July 2004; pp. 217–221. [Google Scholar]
- Sinha, R.; Mihalcea, R. Unsupervised graph-basedword sense disambiguation using measures of word semantic similarity. In Proceedings of the International conference on semantic computing (ICSC 2007), Irvine, CA, USA, 17–19 September 2007; pp. 363–369. [Google Scholar]
- Navigli, R.; Lapata, M. Graph connectivity measures for unsupervised word sense disambiguation. In Proceedings of the IJCAI, Hyderabad, India, 6–12 January 2007; pp. 1683–1688. [Google Scholar]
- Agirre, E.; Soroa, A. Personalizing pagerank for word sense disambiguation. In Proceedings of the 12th Conference of the European Chapter of the ACL (EACL 2009), Athens, Greece, 30 March–3 April 2009; pp. 33–41. [Google Scholar]
- Heo, J.; Seo, H.-C.; Jang, M.-G. Homonym disambiguation based on mutual information and sense-tagged compound noun dictionary. J. KIISE: Softw. Appl. 2006, 33, 1073–1089. [Google Scholar]
- Scarlini, B.; Pasini, T.; Navigli, R. Sensembert: Context-enhanced sense embeddings for multilingual word sense disambiguation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 8758–8765. [Google Scholar]
- Bevilacqua, M.; Pasini, T.; Raganato, A.; Navigli, R. Recent trends in word sense disambiguation: A survey. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, IJCAI-21, Montreal, QC, Canada, 21–26 August 2021. [Google Scholar]
- Kohli, H. Transfer learning and augmentation for word sense disambiguation. arXiv 2021, arXiv:2101.03617. [Google Scholar]
- Chen, H.; Xia, M.; Chen, D. Non-parametric few-shot learning for word sense disambiguation. arXiv 2021, arXiv:2104.12677. [Google Scholar]
- Pasini, T. The knowledge acquisition bottleneck problem in multilingual word sense disambiguation. In Proceedings of the IJCAI, Yokohama, Japan, 11–17 July 2020; pp. 4936–4942. [Google Scholar]
- Zhimao, L.; Ting, L.; Sheng, L. Unsupervised Chinese Word Sense Disambiguation Based on Equivalent Pseudowords; Information Retrieval Laboratory of Computer Science & Technology School, Harbin Institute of Technology: Harbin, China, 2014. [Google Scholar]
- Rouhizadeh, H.; Shamsfard, M.; Rouhizadeh, M. Knowledge based word sense disambiguation with distributional semantic expansion for the persian language. In Proceedings of the 2020 10th International Conference on Computer and Knowledge Engineering (ICCKE), Mashhad, Iran, 29–30 October 2020; pp. 329–335. [Google Scholar]
- Bordag, S. A comparison of co-occurrence and similarity measures as simulations of context. In Proceedings of the International Conference on Intelligent Text Processing and Computational Linguistics, Haifa, Israel, 17–23 February 2008; pp. 52–63. [Google Scholar]
- Kolesnikova, O. Survey of word co-occurrence measures for collocation detection. Comput. Y Sist. 2016, 20, 327–344. [Google Scholar] [CrossRef]
- Párraga-Valle, J.; García-Bermúdez, R.; Rojas, F.; Torres-Morán, C.; Simón-Cuevas, A. Evaluating mutual information and chi-square metrics in text features selection process: A study case applied to the text classification in PubMed. In Proceedings of the International Work-Conference on Bioinformatics and Biomedical Engineering, Granada, Spain, 6–8 May 2020; pp. 636–646. [Google Scholar]
- Raganato, A.; Camacho-Collados, J.; Navigli, R. Word sense disambiguation: A unified evaluation framework and empirical comparison. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics, Volume 1, Long Papers, Valencia, Spain, 3–7 April 2017; pp. 99–110. [Google Scholar]
- Du, J.; Qi, F.; Sun, M. Using bert for word sense disambiguation. arXiv 2019, arXiv:1909.08358. [Google Scholar]
- Blevins, T.; Zettlemoyer, L. Moving down the long tail of word sense disambiguation with gloss-informed biencoders. arXiv 2020, arXiv:2005.02590. [Google Scholar]
- Duarte, J.M.; Sousa, S.; Milios, E.; Berton, L. Deep analysis of word sense disambiguation via semi-supervised learning and neural word representations. Inf. Sci. 2021, 570, 278–297. [Google Scholar] [CrossRef]










| Co-Occurrence Word | x2 Value with Sagwa 1 (Apology) | x2 Value with Sagwa 2 (Apple) |
|---|---|---|
| Han (one) | 20.43 | 50.89 |
| Gai (piece) | 20.24 | 0.69 |
| Meokda (eat) | 145.25 | 0.07 |
| Co-Occurrence Word | x2 Value with Sagwa 1 (Apology) | x2 Value with Sagwa 2 (Apple) |
|---|---|---|
| Han (one) | 20.43 | 50.89 |
| Gai (piece) | 20.24 | 0.69 |
| Meokda (eat) | 145.25 | 0.07 |
| Number of related words | 3 words | 1 word |
| Co-Occurrence Word | x2 Value with Sagwa 1 (Apology) | x2 Value with Sagwa 2 (Apple) |
|---|---|---|
| Na (I) | 5.47 | 8.95 |
| Batda (receive) | 145.25 | 0.07 |
| Number of related words | 1 word | 1 word |
| Co-Occurrence Word | x2 Value with Sagwa 1 (Apology) | x2 Value with Sagwa 2 (Apple) |
|---|---|---|
| Na (I) | 5.47 | 8.95 |
| Batda (receive) | 145.25 | 0.07 |
| Sum | 150.72 | 9.02 |
| Multiplication | 794.5175 | 0.6265 |
| Average | 75.36 | 4.51 |
| Multiplication of weight | 0.3672 | 0.0228 |
| Normalization | Word |
| Counting Unit | Han(1), Doo(2), Sip(10), Bak(100) |
| Dependent noun on unit | Segi, wol, boon |
| Numeral | 1, 2, 10, 100 |
| Proper noun | Catholic University of Pusan, Minho Kim |
| General pre-noun | Geu, Yi, Enu |
| Rank | Noon (eye) | Noon (Snow) | ||
|---|---|---|---|---|
| Related Word | Related Word | |||
| 1 | Glasses | 4416.99 | Weather service | 15,187.17 |
| 2 | Organ | 1681.90 | Previous year | 2438.09 |
| 3 | Feel | 733.49 | Continue | 141.42 |
| 4 | Nose | 251.31 | Rain | 118.95 |
| 5 | Method | 200.78 | Fall | 78.87 |
| 6 | cannot | 147.87 | Rear | 43.53 |
| 7 | Ear | 145.29 | Appear | 30.58 |
| 8 | Keep an eye | 130.47 | Start | 23.44 |
| 9 | Touch | 97.48 | Out of | 19.42 |
| 10 | Mouth | 96.83 | Day | 9.69 |
| Ambiguous Word | Accuracy (%) | ||||
|---|---|---|---|---|---|
| MFC | Basic Algorithm | Improvement ① | Improvement ① + ② | Improvement ① + ② + ③ | |
| noon | 93.98 | 93.98 | 93.98 | 94.74 | 94.74 |
| son | 97.73 | 93.18 | 97.73 | 97.73 | 98.48 |
| mal | 34.65 | 46.53 | 54.46 | 54.46 | 65.35 |
| baram | 98.98 | 98.98 | 96.94 | 96.94 | 94.90 |
| geori | 53.44 | 47.33 | 47.33 | 68.70 | 74.05 |
| jari | 89.11 | 95.05 | 96.04 | 96.04 | 96.04 |
| euisa | 62.42 | 56.36 | 87.27 | 89.70 | 88.48 |
| mok | 99.00 | 97.00 | 94.00 | 94.00 | 96.00 |
| jeom | 89.90 | 90.91 | 88.89 | 89.90 | 94.95 |
| bam | 71.29 | 77.23 | 77.23 | 77.23 | 77.23 |
| Word | Meaning No. | Meaning | Number of Data |
|---|---|---|---|
| mal | mal_1 | Domestic livestock | 11 |
| mal_2 | Marker in the game board such as Yut game or Gonu | 0 | |
| mal_3 | Means to express people’s thought and feeling | 33 | |
| mal_6 | End | 22 | |
| mal_9 | Unit of quantity for grain or liquid | 35 |
| Ambiguous Word | Accuracy (%) | |||
|---|---|---|---|---|
| Learning Corpus | Evaluation Corpus | |||
| Primary Model (Related Word, Relation Word) | Primary Model (Related Word, Relation Word) | Secondary Model (Use of Prior Knowledge Extracted from the Learning Corpus Tagging Result) | Existing Model (Prior Knowledge Estimation) | |
| noon | 89.87 | 87.02 | 92.45 | 94.54 |
| dari | 82.34 | 81.34 | 83.84 | 85.78 |
| bam | 82.49 | 91.09 | 93.34 | 98.57 |
| bae | 84.47 | 83.47 | 86.39 | 89.21 |
| sagwa | 86.25 | 85.99 | 83.68 | 90.41 |
| shinjang | 81.64 | 75.24 | 83.98 | 83.46 |
| yeongi | 85.56 | 77.46 | 88.69 | 89.65 |
| indo | 75.64 | 73.99 | 83.97 | 87.24 |
| insa | 80.24 | 79.68 | 84.47 | 89.45 |
| janggi | 86.43 | 87.87 | 90.96 | 92.47 |
| Average | 83.49 | 82.32 | 87.18 | 90.14 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, M.; Kwon, H.-C. Word Sense Disambiguation Using Prior Probability Estimation Based on the Korean WordNet. Electronics 2021, 10, 2938. https://doi.org/10.3390/electronics10232938
Kim M, Kwon H-C. Word Sense Disambiguation Using Prior Probability Estimation Based on the Korean WordNet. Electronics. 2021; 10(23):2938. https://doi.org/10.3390/electronics10232938
Chicago/Turabian StyleKim, Minho, and Hyuk-Chul Kwon. 2021. "Word Sense Disambiguation Using Prior Probability Estimation Based on the Korean WordNet" Electronics 10, no. 23: 2938. https://doi.org/10.3390/electronics10232938