
Privacy Preservation in Online Social Networks Using Multiple-Graph-Properties-Based Clustering to Ensure k-Anonymity, l-Diversity, and t-Closeness


Abstract
:1. Introduction
2. Related Works
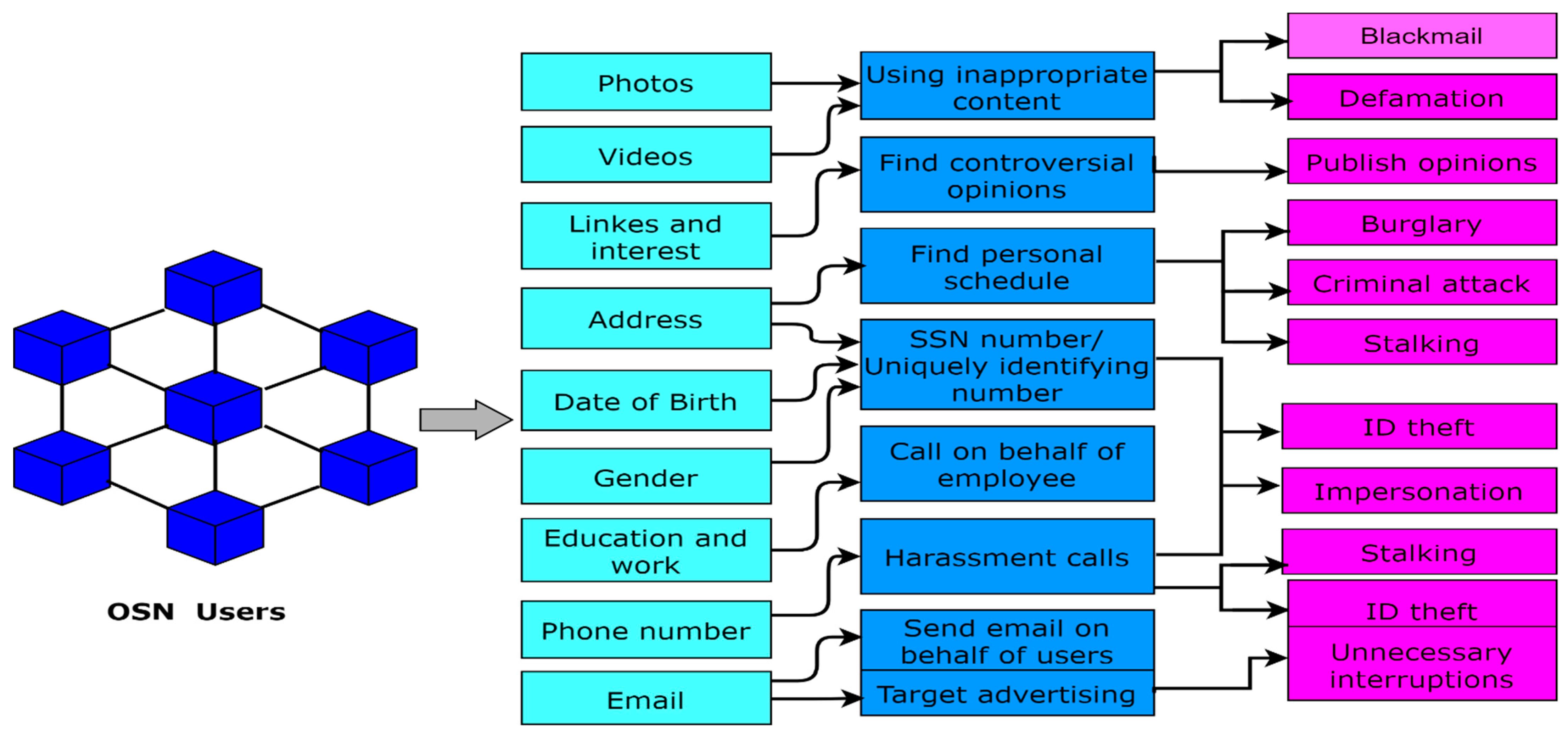
2.1. Privacy Methods in OSNs
2.2. Motivation
2.3. Contributions
- After data normalization and K-means clustering, we propose the novel cluster optimization algorithm to achieve k-anonymity using two graph properties: distance, and eccentricity. Multiple graph properties ensure reliability in cluster optimization, with minimal sensitive information leakage and a higher degree of anonymization. The cluster optimization phase produces clusters with at least k-anonymized users;
- To enhance the privacy preservation of k-anonymized clusters, we propose the novel one-pass algorithm to ensure that the clusters have l-diversity and t-closeness, and to protect data from similarity threats and attribute disclosure threats;
- The notion of equal-distance-based t-closeness privacy ensures the prevention of disclosure of users’ attributes, and of similarity threats. The notion of l-diversity privacy ensures the prevention of the disclosure of sensitive attributes at the cluster head (CH);
- The analysis of our results presents performance comparison of the proposed method with similar methods, using a real-world dataset, and varying the number of users and the number of clusters.
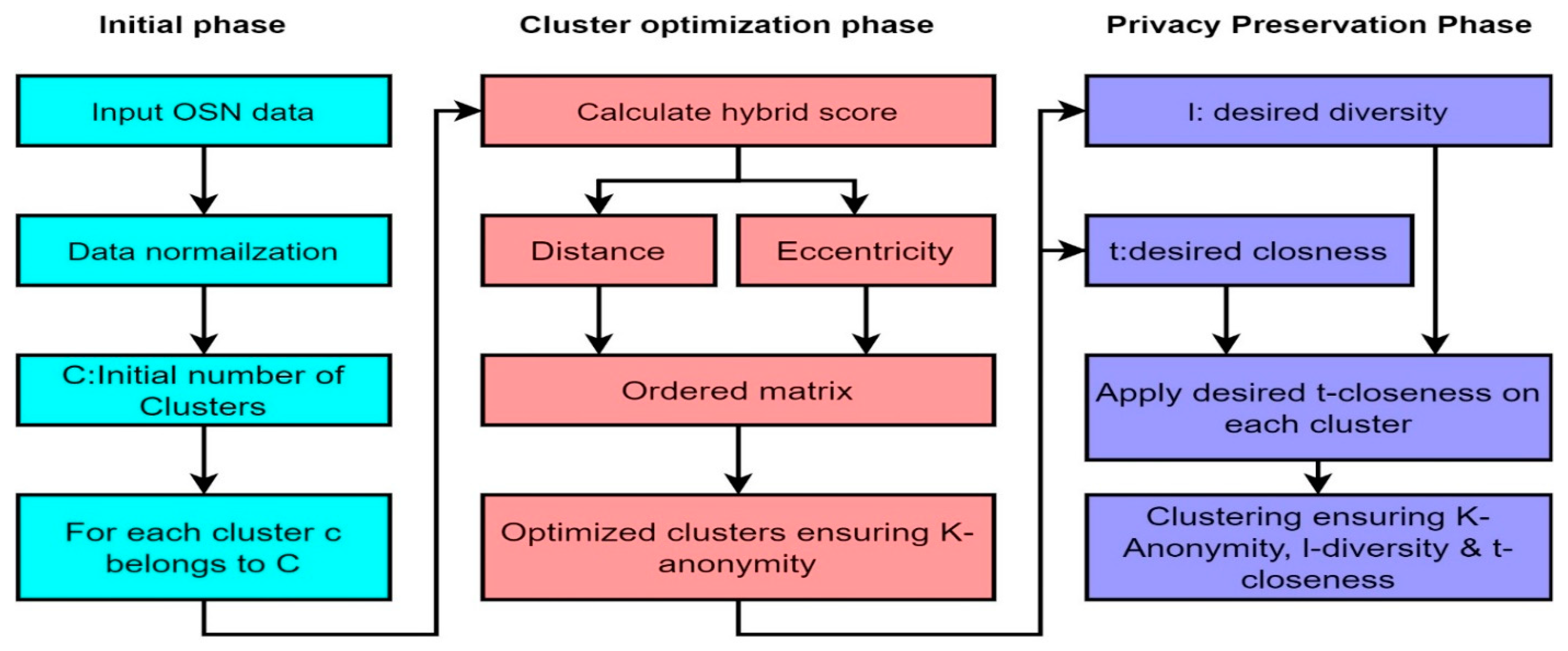
3. Proposed Method
3.1. System Model
- To achieve complete privacy notions—k-anonymity, l-diversity, and t-closeness—for giving the constant value k;
- To minimize the sensitive information leakage and reduce processing time, with minimal IL, and achieve high-level privacy preservation;
- To improve the reliability of anonymization considering the multiple graph properties and data normalization.
3.2. Initial Phase
- Preprocessing Algorithm
| Algorithm 1 Preprocessing |
| Input f: raw OSN data Output V: Set of vertices A: Set of attributes
|
- 2.
- Initial Clustering (K-means Clustering Algorithm)
3.3. Cluster Optimization Phase
- Hybrid Score Matrix Computation
| Algorithm 2 Cluster Optimization |
| Inputs Output Hybrid Score Matrix Computation:
|
- 2.
- Cluster Optimization
3.4. Privacy Preservation Phase
“An equivalence class is said to have l-diversity if there are at least l well-represented values for the sensitive attribute. A table is said to have l-diversity if every equivalence class of the table has l-diversity”.Definition of l-diversity [19]
“An equivalence class is said to have t-closeness if the distance between the distribution of a sensitive attribute in this class and the distribution of the attribute in the whole table is no more than a threshold t. A table is said to have t-closeness if all equivalence classes have t-closeness”.Definition of t-closeness [19]
| Algorithm 3 One-pass privacy preservation |
| Inputs Output
|
4. Experimental Results
4.1. Dataset and Performance Metrics
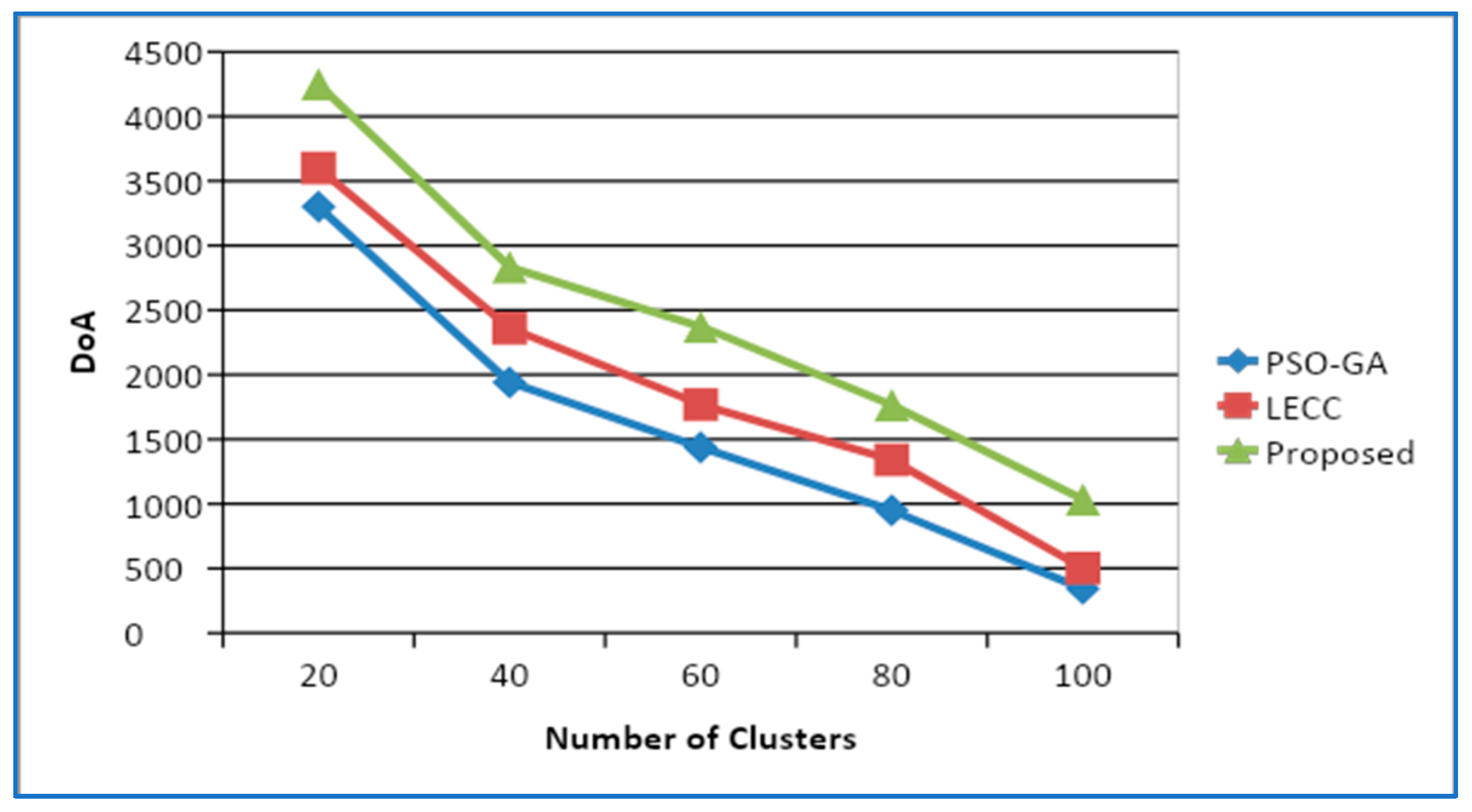
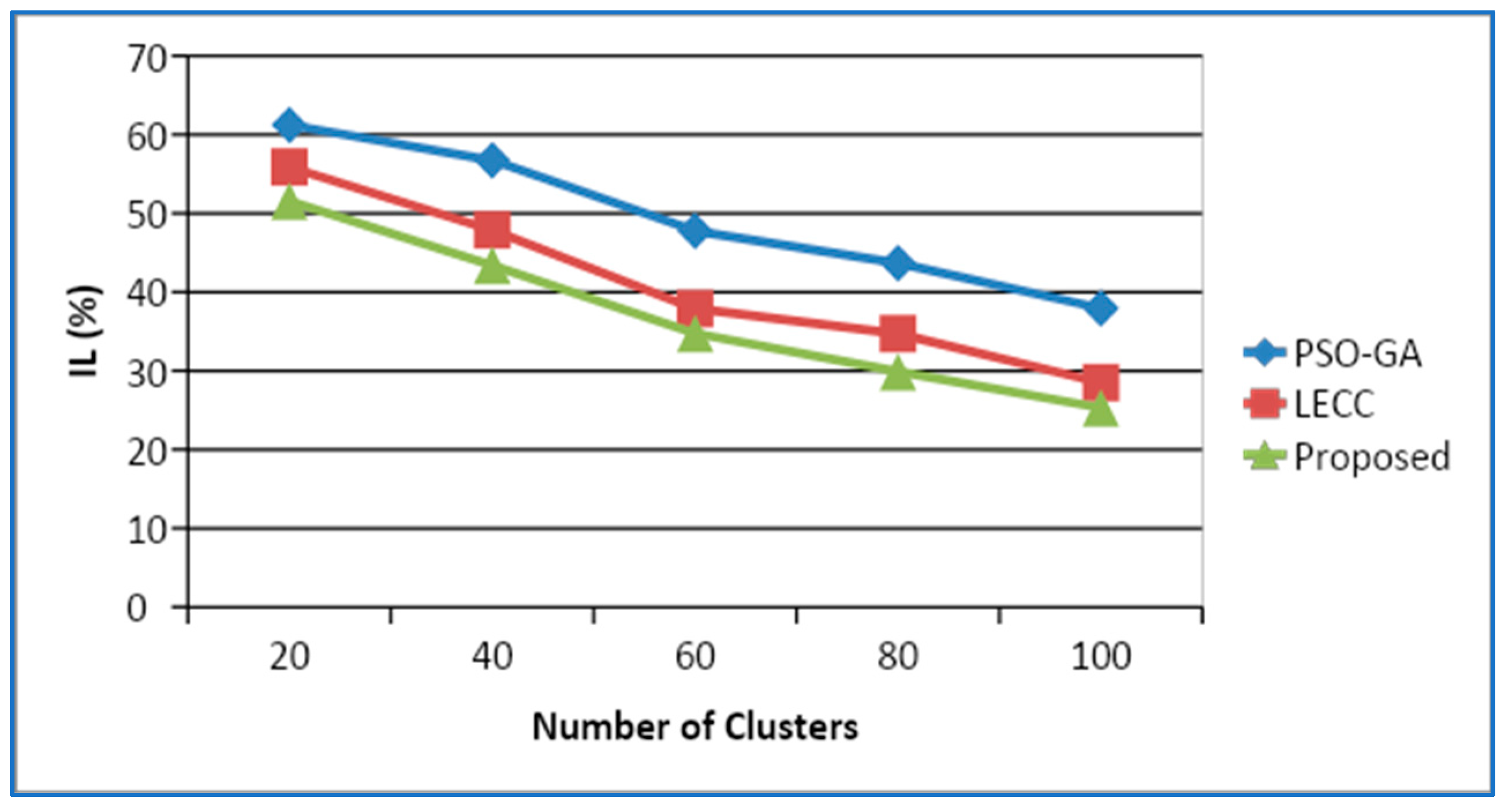
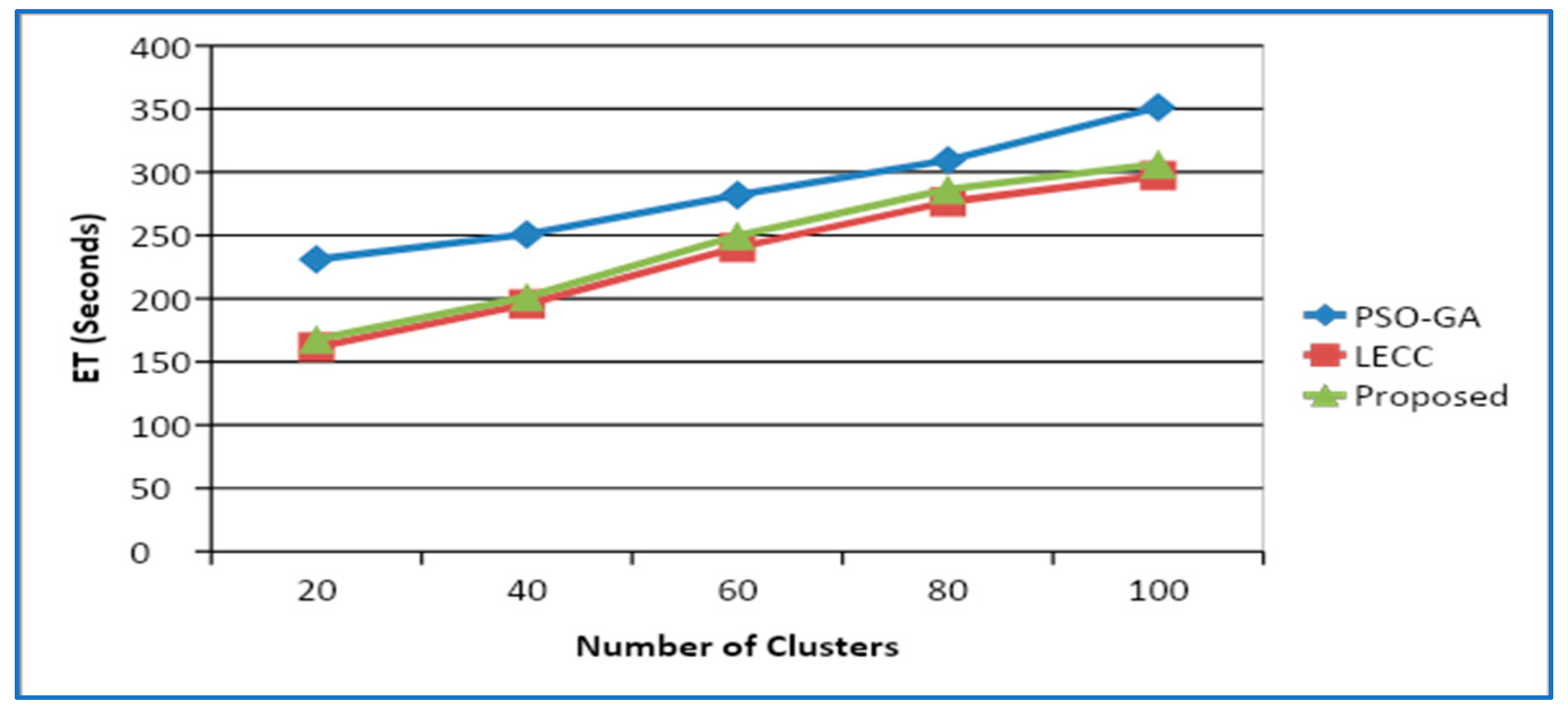
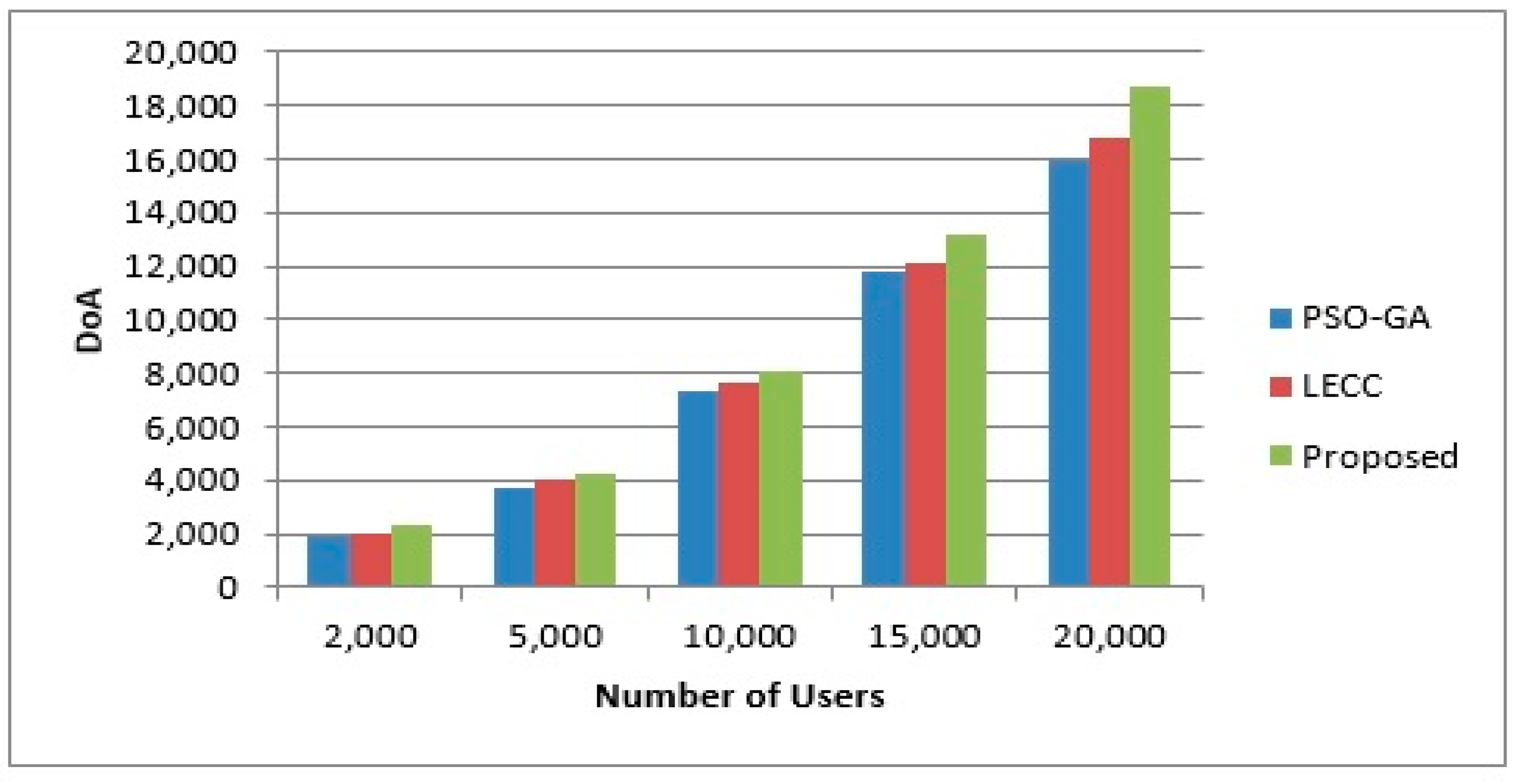
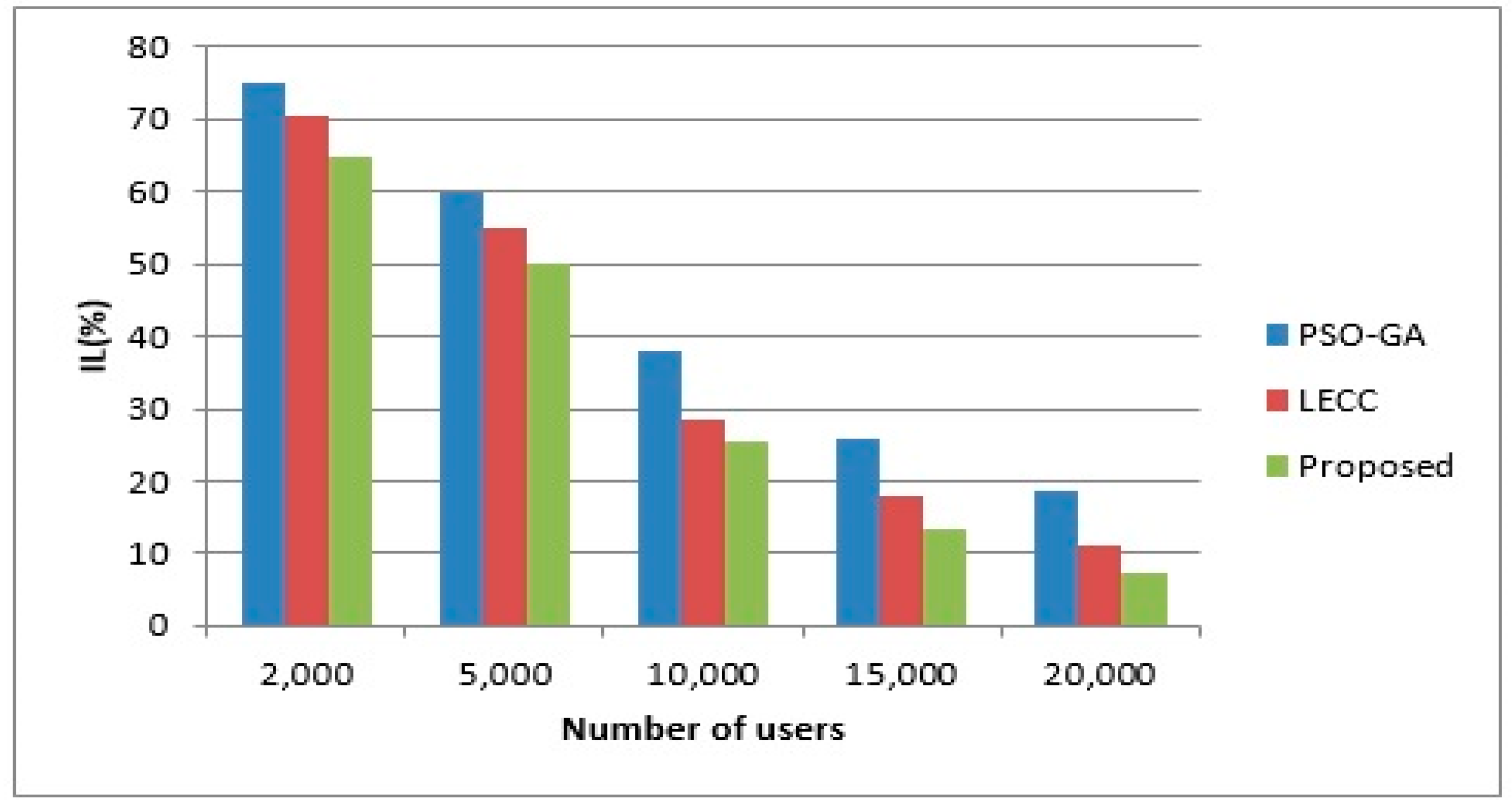
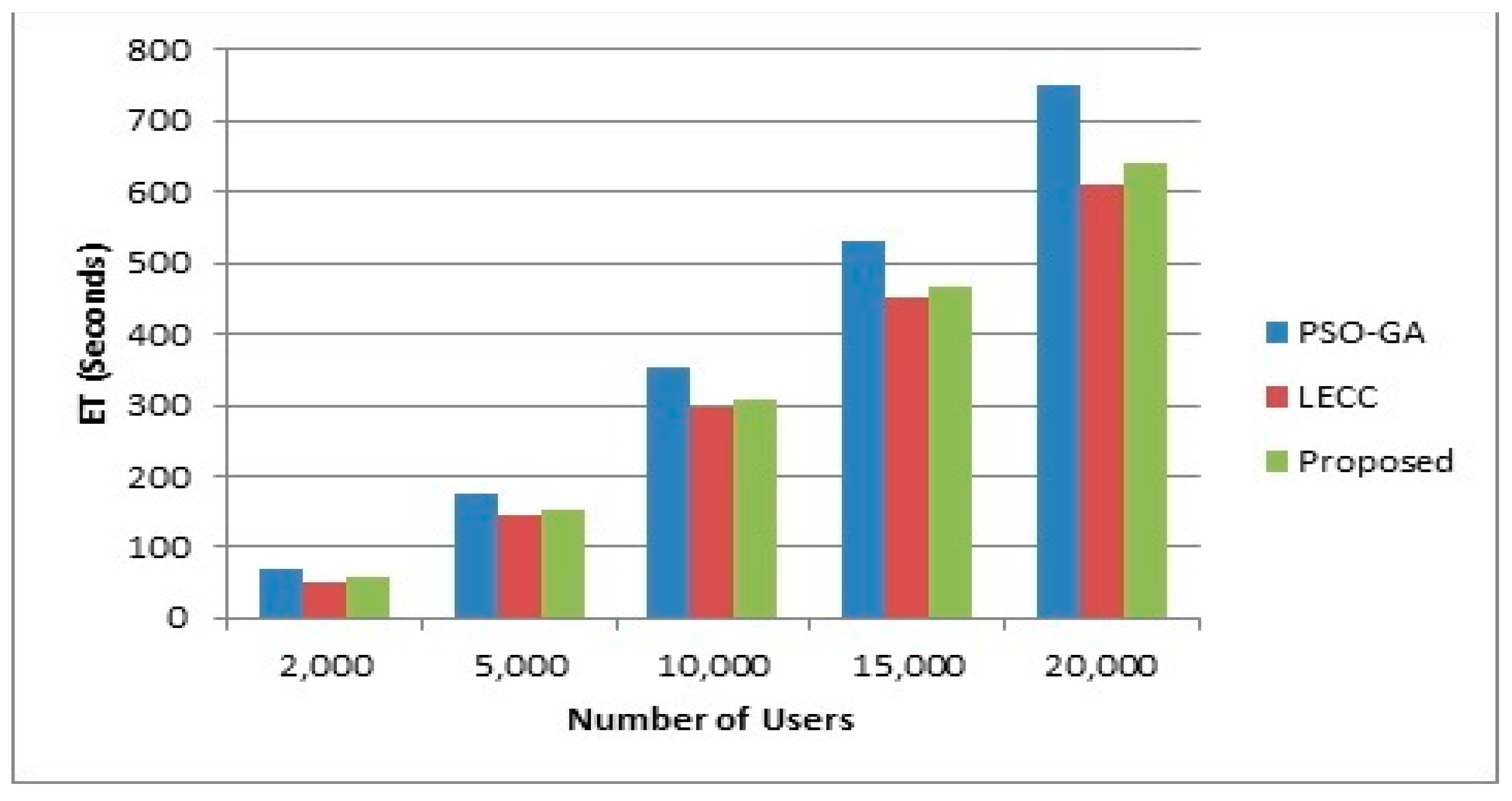
4.2. Variations in Cluster Size
4.3. Variations in Density
4.4. Limitations
5. Conclusions and Future Directions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Novak, E.; Li, Q. A survey of security and privacy in online social networks. Coll. William Mary Comput. Sci. Tech. Rep. 2012, 1–32. [Google Scholar]
- Gangarde, R.; Sharma, A.P.A. DigitalCommons @ University of Nebraska-Lincoln Bibliometric Survey of Privacy of Social Media Network Data Publishing. Libr. Philos. Pract. 2019, 3617, 1–21. [Google Scholar]
- Mishra, N.; Pandya, S. Internet of Things Applications, Security Challenges, Attacks, Intrusion Detection, and Future Visions: A Systematic Review. IEEE Access 2021, 9, 59353–59377. [Google Scholar] [CrossRef]
- Poovarasan, G.; Susikumar, S.; Naveen, S. International Journal of Engineering Technology Research & Management. Academia. Edu. 2020, 4, 131–134. [Google Scholar]
- Maple, C. Security and privacy in the internet of things. J. Cyber Policy 2017, 2, 155–184. [Google Scholar] [CrossRef]
- Li, C.; Palanisamy, B. Privacy in Internet of Things: From Principles to Technologies. IEEE Internet Things J. 2019, 6, 488–505. [Google Scholar] [CrossRef]
- Yang, Y.; Wu, L.; Yin, G.; Li, L.; Zhao, H. A Survey on Security and Privacy Issues in Internet-of-Things. IEEE Internet Things J. 2017, 4, 1250–1258. [Google Scholar] [CrossRef]
- Sadeghian, A.; Zamani, M.; Shanmugam, B. Security threats in online social networks. In Proceedings of the 2013 International Conference on Informatics and Creative Multimedia, ICICM 2013, IEEE Computer Society, Kuala Lumpur, Malaysia, 4–6 September 2013; pp. 254–258. [Google Scholar]
- Jaber, K.M.; Institute of Electrical and Electronics Engineers. Jordan Section; Institute of Electrical and Electronics Engineers. Region 8; Institute of Electrical and Electronics Engineers. 2019 IEEE Jordan International Joint Conference on Electrical Engineering and Information Technology (JEEIT); IEEE: Piscataway, NJ, USA, 2019; ISBN 9781538679425. [Google Scholar]
- Prasad, M.R.; Kumar, S. Advance Identification of Cloning Attacks in Online Social Networks. Int. J. Eng. Technol. 2018, 7, 83. [Google Scholar] [CrossRef] [Green Version]
- Devmane, M.A.; Rana, I.N.K. Privacy Issues in Online Social Networks. Int. J. Comput. Appl. 2012, 41. [Google Scholar]
- Ali, S.; Islam, N.; Rauf, A.; Din, I.U.; Guizani, M.; Rodrigues, J.J.P.C. Privacy and security issues in online social networks. Futur. Internet 2018, 10, 114. [Google Scholar] [CrossRef] [Green Version]
- Jamshidi, M.B.; Lalbakhsh, A.; Alibeigi, N.; Soheyli, M.R.; Oryani, B.; Rabbani, N. Socialization of Industrial Robots: An Innovative Solution to improve Productivity. In Proceedings of the 2018 IEEE 9th Annual Information Technology, Electronics and Mobile Communication Conference (IEMCON), Vancouver, BC, Canada, 1–3 November 2018; pp. 832–837. [Google Scholar] [CrossRef]
- Jamshidi, M.B.; Alibeigi, N.; Rabbani, N.; Oryani, B.; Lalbakhsh, A. Artificial Neural Networks: A Powerful Tool for Cognitive Science. In Proceedings of the 2018 IEEE 9th Annual Information Technology, Electronics and Mobile Communication Conference (IEMCON), Vancouver, BC, Canada, 1–3 November 2018; pp. 674–679. [Google Scholar] [CrossRef]
- Jamshidi, M.; Lalbakhsh, A.; Talla, J.; Peroutka, Z.; Hadjilooei, F.; Lalbakhsh, P.; Jamshidi, M.; Spada, L.; La Mirmozafari, M.; Dehghani, M.; et al. Artificial Intelligence and COVID-19: Deep Learning Approaches for Diagnosis and Treatment. IEEE Access 2020, 8, 109581–109595. [Google Scholar] [CrossRef]
- Revathi, S.; Suriakala, M. An intelligent and novel algorithm for securing vulnerable users of online social network. In Proceedings of the 2018 Second International Conference on Computing Methodologies and Communication (ICCMC), Erode, India, 15–16 February 2018; pp. 214–219. [Google Scholar] [CrossRef]
- Garcia, D. Leaking Privacy and Shadow Profiles in Online Social Networks. Sci. Adv. 2017, 3, e1701172. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Friedland, G.; Choi, J. Semantic computing and privacy: A case study using inferred geo-location. Int. J. Semant. Comput. 2011, 5, 79–93. [Google Scholar] [CrossRef]
- Ninghui, L.; Tiancheng, L.; Venkatasubramanian, S. t-Closeness: Privacy beyond k-anonymity and ℓ-diversity. In Proceedings of the International Conference on Data Engineering, Istanbul, Turkey, 15 April 2007; pp. 106–115. [Google Scholar] [CrossRef] [Green Version]
- Majeed, A.; Lee, S. Anonymization Techniques for Privacy Preserving Data Publishing: A Comprehensive Survey. IEEE Access 2021, 9, 8512–8545. [Google Scholar] [CrossRef]
- Hay, M.; Miklau, G.; Jensen, D.; Towsley, D.; Li, C. Resisting structural re-identification in anonymized social networks. VLDB J. 2010, 19, 797–823. [Google Scholar] [CrossRef] [Green Version]
- Zheng, X.; Cai, Z.; Li, Y. Data Linkage in Smart Internet of Things Systems: A Consideration from a Privacy Perspective. IEEE Commun. Mag. 2018, 56, 55–61. [Google Scholar] [CrossRef]
- Zheleva, E.; Getoor, L. Preserving the Privacy of Sensitive Relationships in Graph Data. Lect. Notes Comput. Sci. Incl. Subser. Lect. Notes Artif. Intell. Lect. Notes Bioinform. 2008, 4890 LNCS, 153–171. [Google Scholar] [CrossRef]
- Sun, C.; Yu, P.S.; Kong, X.; Fu, Y. Privacy preserving social network publication against mutual friend attacks. In Proceedings of the IEEE 13th International Conference on Data Mining Workshops, ICDMW 2013, IEEE Computer Society, Dallas, TX, USA, 7–10 December 2013; pp. 883–890. [Google Scholar] [CrossRef] [Green Version]
- Cheng, J.; Fu, A.W.C.; Liu, J.; Association for Computing Machinary. K-isomorphism: Privacy preserving network publication against structural attacks. In Proceedings of the ACM SIGMOD International Conference on Management of Data (SIGMOD’ 10), New York, NY, USA, 6–10 June 2010; pp. 459–470. [Google Scholar]
- Zhang, Y.; O’Neill, A.; Sherr, M.; Zhou, W. Privacy-preserving network provenance. Proc. VLDB Endow. 2017, 10, 1550–1561. [Google Scholar]
- Gangarde, R.; Sharma, A.; Pawar, A. Research opportunities in privacy of online social network data publishing. Int. J. Adv. Sci. Technol. 2020, 29, 5095–5101. [Google Scholar]
- Cai, Z.; He, Z. Trading private range counting over big IoT data. In Proceedings of the International Conference on Distributed Computing Systems(ICDCS), Dallas, Texas, USA, 7–9 July 2019; pp. 144–153. [Google Scholar] [CrossRef]
- Cai, Z.; Zheng, X. A Private and Efficient Mechanism for Data Uploading in Smart Cyber-Physical Systems. IEEE Trans. Netw. Sci. Eng. 2020, 7, 766–775. [Google Scholar] [CrossRef]
- Casas-Roma, J.; Herrera-Joancomartí, J.; Torra, V. A survey of graph-modification techniques for privacy-preserving on networks. Artif. Intell. Rev. 2017, 47, 341–366. [Google Scholar] [CrossRef]
- Yan, Z.; Feng, W.; Wang, P. Anonymous Authentication for Trustworthy Pervasive Social Networking. IEEE Trans. Comput. Soc. Syst. 2015, 2, 88–98. [Google Scholar] [CrossRef]
- Feng, W.; Yan, Z.; Xie, H. Anonymous Authentication on Trust in Pervasive Social Networking Based on Group Signature. IEEE Access 2017, 5, 6236–6246. [Google Scholar] [CrossRef]
- Ghayvat, H.; Pandya, S.N.; Bhattacharya, P.; Zuhair, M.; Rashid, M.; Hakak, S.; Dev, K. CP-BDHCA: Blockchain-based Confidentiality-Privacy preserving Big Data scheme for healthcare clouds and applications. IEEE J. Biomed. Health Inform. 2021, 2194, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Liu, Q.; Wang, G.; Li, F.; Yang, S.; Wu, J. Preserving Privacy with Probabilistic Indistinguishability in Weighted Social Networks. IEEE Trans. Parallel Distrib. Syst. 2017, 28, 1417–1429. [Google Scholar] [CrossRef]
- Siddula, M.; Li, L.; Li, Y. An Empirical Study on the Privacy Preservation of Online Social Networks. IEEE Access 2018, 6, 19912–19922. [Google Scholar] [CrossRef]
- Qu, Y.; Yu, S.; Gao, L.; Zhou, W.; Peng, S. A hybrid privacy protection scheme in cyber-physical social networks. IEEE Trans. Comput. Soc. Syst. 2018, 5, 773–784. [Google Scholar] [CrossRef]
- Liu, P.; Xu, Y.X.; Jiang, Q.; Tang, Y.; Guo, Y.; Wang, L.E.; Li, X. Local differential privacy for social network publishing. Neurocomputing 2020, 391, 273–279. [Google Scholar] [CrossRef]
- Shao, Y.; Liu, J.; Shi, S.; Zhang, Y.; Cui, B. Fast De-anonymization of Social Networks with Structural Information. Data Sci. Eng. 2019, 4, 76–92. [Google Scholar] [CrossRef] [Green Version]
- Yazdanjue, N.; Fathian, M.; Amiri, B. Evolutionary algorithms for k-anonymity in social networks based on clustering approach. Comput. J. 2021, 63, 1039–1062. [Google Scholar] [CrossRef]
- Qian, J.; Li, X.Y.; Zhang, C.; Chen, L.; Jung, T.; Han, J. Social Network De-Anonymization and Privacy Inference with Knowledge Graph Model. IEEE Trans. Dependable Secur. Comput. 2019, 16, 679–692. [Google Scholar] [CrossRef]
- Siddula, M.; Li, Y.; Cheng, X.; Tian, Z.; Cai, Z. Anonymization in online social networks based on enhanced equi-cardinal clustering. IEEE Trans. Comput. Soc. Syst. 2019, 6, 809–820. [Google Scholar] [CrossRef]
- Zhao, P.; Huang, H.; Zhao, X.; Huang, D. P3: Privacy-Preserving Scheme Against Poisoning Attacks in Mobile-Edge Computing. IEEE Trans. Comput. Soc. Syst. 2020, 7, 818–826. [Google Scholar] [CrossRef]
- De Montjoye, Y.A.; Hidalgo, C.A.; Verleysen, M.; Blondel, V.D. Unique in the Crowd: The privacy bounds of human mobility. Sci. Rep. 2013, 3, 1–5. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cai, Y.; Zhang, S.; Xia, H.; Fan, Y.; Zhang, H. A Privacy-Preserving Scheme for Interactive Messaging over Online Social Networks. IEEE Internet Things J. 2020, 7, 6817–6827. [Google Scholar] [CrossRef]
- Gao, T.; Li, F. Protecting Social Network with Differential Privacy under Novel Graph Model. IEEE Access 2020, 8, 185276–185289. [Google Scholar] [CrossRef]
- Qu, Y.; Yu, S.; Zhou, W.; Chen, S.; Wu, J. Customizable Reliable Privacy-Preserving Data Sharing in Cyber-Physical Social Networks. IEEE Trans. Netw. Sci. Eng. 2021, 8, 269–281. [Google Scholar] [CrossRef]
- Machanavajjhala, A.; Kifer, D.; Gehrke, J.; Venkitasubramaniam, M. ℓ-diversity: Privacy beyond k-anonymity. ACM Trans. Knowl. Discov. Data 2007, 1, 3. [Google Scholar] [CrossRef]
- Stanford Large Network Dataset Collection. Available online: http://snap.stanford.edu/data/ (accessed on 13 January 2020).
- Domingo-Ferrer, J.; Mateo-Sanz, J.M. Practical data-oriented microaggregation for statistical disclosure control. IEEE Trans. Knowl. Data Eng. 2002, 14, 189–201. [Google Scholar] [CrossRef] [Green Version]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Phases | Processing |
|---|---|
| Initial Phase |
|
| Cluster Optimization Phase |
|
| Privacy Preservation Phase |
|
| Symbol | Quantity |
|---|---|
| OSN graph | |
| RD | Raw OSN data |
| Set of edges (relationship between two users) in the graph | |
| Set of vertices (users) in graph G | |
| Set of attributes of each user/vertex | |
| attribute of user/vertex | |
| Represents the user ID in raw OSN data | |
| Number of reviews posted by | |
| Active years of | |
| Number of friends of | |
| Number of fans of | |
| Average vote score of | |
| An elite score of | |
| Compliment scores of | |
| Attribute set of | |
| Number of clusters | |
| C | Set of clusters |
| Attribute set of the centroid of cluster | |
| The hybrid score value of user/vertex of cluster | |
| Set of users/cluster members of cluster | |
| Total number of attributes in set | |
| The distance between the vertex and a centroid | |
| The eccentricity of vertex |
| Cluster Number | Number of Users |
|---|---|
| Cluster Number | Number of Users |
|---|---|
| PSO-GA | LECC | Proposed | |
|---|---|---|---|
| DoA | 4861 | 5211 | 5880 |
| IL | 46.46 | 38.78 | 34.55 |
| ET | 330.29 | 272.31 | 283.85 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gangarde, R.; Sharma, A.; Pawar, A.; Joshi, R.; Gonge, S. Privacy Preservation in Online Social Networks Using Multiple-Graph-Properties-Based Clustering to Ensure k-Anonymity, l-Diversity, and t-Closeness. Electronics 2021, 10, 2877. https://doi.org/10.3390/electronics10222877
Gangarde R, Sharma A, Pawar A, Joshi R, Gonge S. Privacy Preservation in Online Social Networks Using Multiple-Graph-Properties-Based Clustering to Ensure k-Anonymity, l-Diversity, and t-Closeness. Electronics. 2021; 10(22):2877. https://doi.org/10.3390/electronics10222877
Chicago/Turabian StyleGangarde, Rupali, Amit Sharma, Ambika Pawar, Rahul Joshi, and Sudhanshu Gonge. 2021. "Privacy Preservation in Online Social Networks Using Multiple-Graph-Properties-Based Clustering to Ensure k-Anonymity, l-Diversity, and t-Closeness" Electronics 10, no. 22: 2877. https://doi.org/10.3390/electronics10222877