
Explainable Sentiment Analysis: A Hierarchical Transformer-Based Extractive Summarization Approach †


Abstract
:1. Introduction
- A new approach to explain document classification tasks as sentiment analysis, by providing extractive summaries as the explanation of the model decision;
- Exploring use of attention weights of a hierarchical transformer architecture as a base to achieve extractive summaries as an explanation of the document classification task;
- A new annotated dataset for the evaluation of extractive summaries as an explanation of a sentiment analysis task. We shared the annotated dataset together with the algorithm code on our Github page (www.github.com/lbacco/ExS4ExSA, accessed on 28 June 2021);
- Two different proposed models, both based on transformer architectures, analyzed in terms of the performance in both the classification and explanation tasks.
2. Related Works
2.1. Explainability in Sentiment Analysis
2.2. Automatic Text Summarization
2.3. Transformers vs. RNNs
2.4. Hierarchy in Transformer Models
2.5. Attention as Explanation
3. Materials and Methods
3.1. Data
3.2. Models
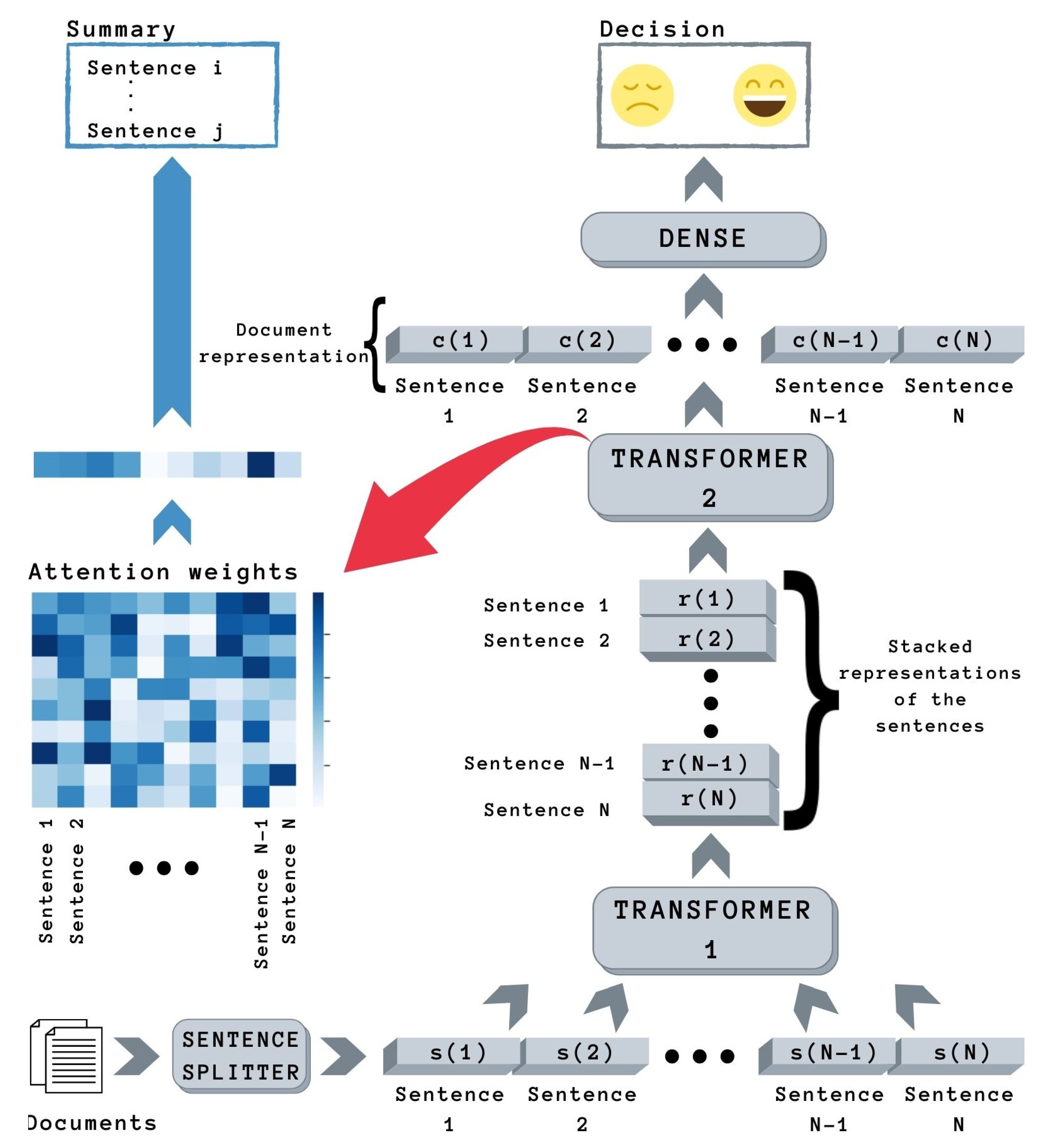
3.2.1. Explainable Hierarchical Transformer (ExHiT)
- By concatenation: ;
- By averaging: ;
- By masked averaging: with , for which is the set of the added empty sentences;
- By the application of a Bidirectional LSTM: .
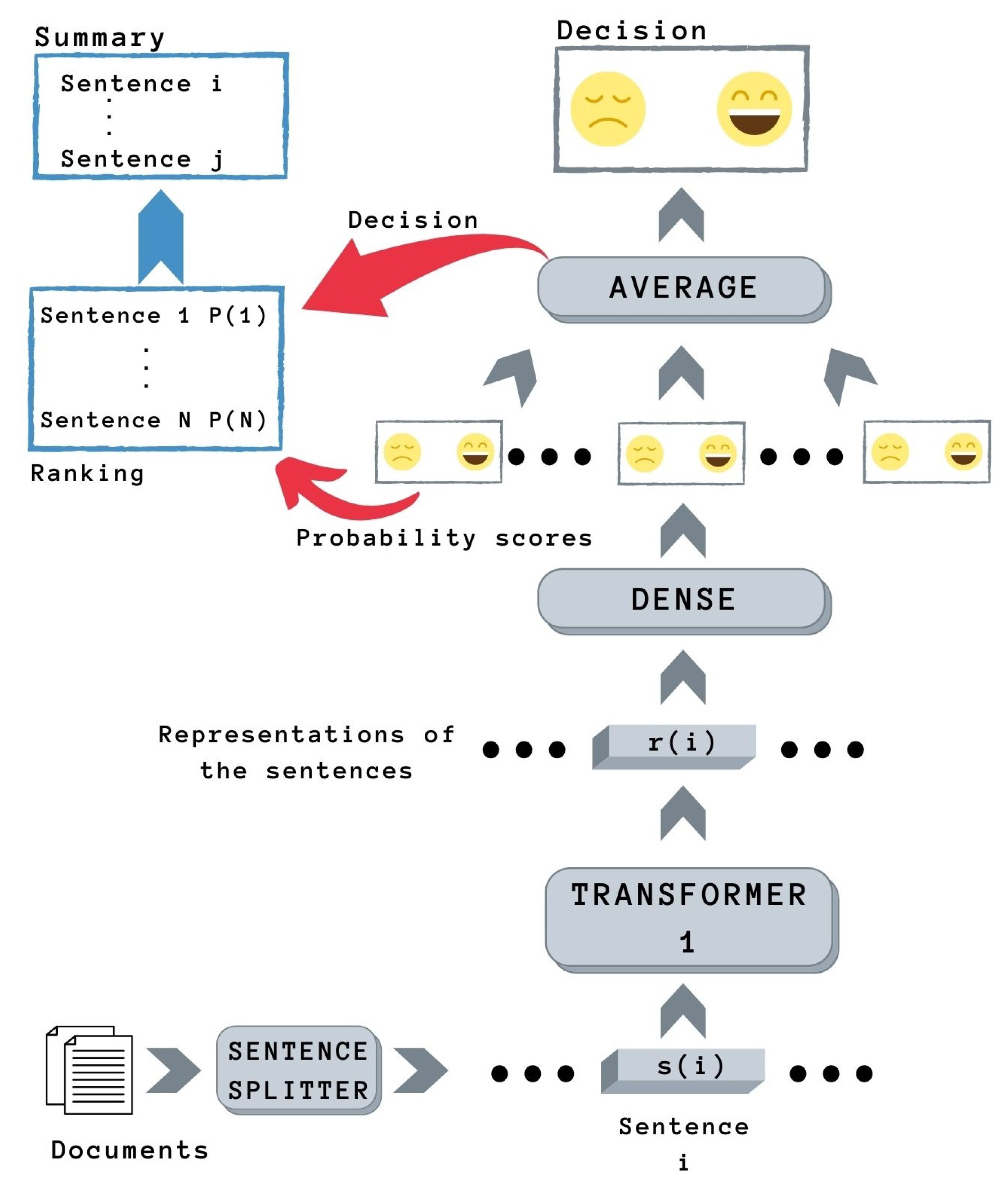
3.2.2. Sentence Classification Combiner Model (SCC)
3.2.3. Parameters
- T1: For a fair comparison, the first transformer model was the same for both the architectures; we opted to use the pre-trained version of RoBERTa [36];
- T2: We used a transformer with two layers, one head per layer; this choice was motivated to facilitate the explainability phase;
- N: The maximum number of sentences per document was set to 15; by this way, we ensured that the 75% of the training documents were elaborated in their entirety;
- t: The maximum number of tokens per sentence was set to 32, comprehensive of the two special delimiter tokens; by this way, we ensured that the 75% of the training sentences were elaborated without being truncated.
4. Experiments
4.1. Joint Training
4.2. Ablation Study
- Sinusoidal sentence positional embedding for T2 (SPE): following the original works on the transformers architectures, we added the positional embedding to the sentence embedding in input to the second transformer;
- Sentence masking for T2 (SM): following the principle of the attention mask for the padded token of the sequences in input to the first transformer, we applied an attention mask on the empty sentences added at the bottom of the document.
5. Results
- If the model performance is worst than if it chose all neutral sentences;
- If the model is going better than if it chose all neutral sentences.
6. Discussion
is simply a description of a plot passage in the movie Macbeth—The tragedy of ambition and contains no information about the sentiment of the review provided by the user and, therefore, would be impossible for an annotator to classify as black or white. Another kind of sentence extracted by the models is sentences that may gain a sentiment sense only if seen together with the previous or next parts of the document. For example, the sentenceBut success has it’s downside, as Macbeth soon finds out, when he has to go to hideous lengths to protect his murderous secret.
has no particular sentiment when picked alone and gives no clue about the polarity of the document. In fact, it is licit for an annotator to wonder: I’ll be glad I did what?. Thus, this sentence alone does not give good hints to guess the sentiment nature of the document. However, if you look at this sentence inside its contextYou’ll be glad you did.
it can be easily noticed that it enforces the negative sense of the previous part of the discourse. The annotators reported this kind of behavior for the ExHiT model, in particular, and this seems to be confirmed by the last two columns of Table 4, where a greater percentage of neutral annotations is reported for both training and test set with respect to the SCC model. This seems to suggest that the ExHiT model it is less suited to perform single sentence-extractive summaries, because of a more contextual understanding of the document classification task. However, the ExHiT version implementing both the sentence masking and positional embeddings has been reported to less show this behavior. In fact, its neutral percentage is way lower than the simpler version. In the case of the training set, it is even lower than the SCC system. Furthermore, also the proposed score presents a significant improvement. These outcomes suggest, once again, how these components are of great importance to the interpretability of the hierarchical model.Do yourself a favor and avoid this movie at all costs. You’ll be glad you did.
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| ExHiT | Explainable hierarchical transformer |
| MAE | Mean absolute error |
| SCC | Sentence classification combiner |
| SM | Sentence mask(ing) |
| SPE | (sinusoidal) Sentence positional embeddings |
References
- Dashtipour, K.; Gogate, M.; Cambria, E.; Hussain, A. A novel context-aware multimodal framework for persian sentiment analysis. arXiv 2021, arXiv:2103.02636. [Google Scholar]
- Gunning, D. Explainable Artificial Intelligence (XAI); Defense Advanced Research Projects Agency (DARPA): Arlington County, VA, USA, 2017. [Google Scholar]
- Gunning, D.; Aha, D. DARPA’s explainable artificial intelligence (XAI) program. AI Mag. 2019, 40, 44–58. [Google Scholar]
- Arrieta, A.B.; Díaz-Rodríguez, N.; Del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; García, S.; Gil-López, S.; Molina, D.; Benjamins, R.; et al. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Inf. Fusion 2020, 58, 82–115. [Google Scholar] [CrossRef] [Green Version]
- Loyola-Gonzalez, O. Black-box vs. white-box: Understanding their advantages and weaknesses from a practical point of view. IEEE Access 2019, 7, 154096–154113. [Google Scholar] [CrossRef]
- Danilevsky, M.; Qian, K.; Aharonov, R.; Katsis, Y.; Kawas, B.; Sen, P. A survey of the state of explainable AI for natural language processing. arXiv 2020, arXiv:2010.00711. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Maas, A.; Daly, R.E.; Pham, P.T.; Huang, D.; Ng, A.Y.; Potts, C. Learning word vectors for sentiment analysis. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, Oregon, 19–24 June 2011; pp. 142–150. [Google Scholar]
- Liu, B. Sentiment analysis and opinion mining. Synth. Lect. Hum. Lang. Technol. 2012, 5, 1–167. [Google Scholar] [CrossRef] [Green Version]
- McGlohon, M.; Glance, N.; Reiter, Z. Star quality: Aggregating reviews to rank products and merchants. In Proceedings of the Fourth International AAAI Conference on Weblogs and Social Media, Washington, DC, USA, 23–26 May 2010. [Google Scholar]
- Zarzour, H.; Al shboul, B.; Al-Ayyoub, M.; Jararweh, Y. Sentiment Analysis Based on Deep Learning Methods for Explainable Recommendations with Reviews. In Proceedings of the 2021 12th International Conference on Information and Communication Systems (ICICS), Valencia, Spain, 24–26 May 2021; pp. 452–456. [Google Scholar]
- Gite, S.; Khatavkar, H.; Kotecha, K.; Srivastava, S.; Maheshwari, P.; Pandey, N. Explainable stock prices prediction from financial news articles using sentiment analysis. PeerJ Comput. Sci. 2021, 7, e340. [Google Scholar] [CrossRef]
- Joshi, M.; Das, D.; Gimpel, K.; Smith, N.A. Movie reviews and revenues: An experiment in text regression. In Proceedings of the Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics, Los Angeles, CA, USA, 2–4 June 2010; pp. 293–296. [Google Scholar]
- Hu, M.; Liu, B. Mining opinion features in customer reviews. AAAI 2004, 4, 755–760. [Google Scholar]
- Silveira, T.D.S.; Uszkoreit, H.; Ai, R. Using Aspect-Based Analysis for Explainable Sentiment Predictions. In Proceedings of the CCF International Conference on Natural Language Processing and Chinese Computing, Zhengzhou, China, 14–18 October 2019. [Google Scholar]
- Baccianella, S.; Esuli, A.; Sebastiani, F. Sentiwordnet 3.0: An enhanced lexical resource for sentiment analysis and opinion mining. In Proceedings of the International Conference on Language Resources and Evaluation, LREC 2010, Valletta, Malta, 17–23 May 2010. [Google Scholar]
- Cambria, E.; Speer, R.; Havasi, C.; Hussain, A. Senticnet: A publicly available semantic resource for opinion mining. In Proceedings of the AAAI Fall Symposium: Commonsense Knowledge, Arlington, VA, USA, 11–13 November 2010. [Google Scholar]
- Zhang, Y.; Lai, G.; Zhang, M.; Zhang, Y.; Liu, Y.; Ma, S. Explicit factor models for explainable recommendation based on phrase-level sentiment analysis. In Proceedings of the 37th International Acm Sigir Conference on Research & Development in Information Retrieval, Gold Coast, Australia, 6–11 July 2014. [Google Scholar]
- Zhao, A.; Yu, Y. Knowledge-enabled BERT for aspect-based sentiment analysis. Knowl. Based Syst. 2021, 227, 107220. [Google Scholar] [CrossRef]
- Bacco, L.; Cimino, A.; Dell’Orletta, F.; Merone, M. Extractive Summarization for Explainable Sentiment Analysis Using Transformers. 2021. Available online: https://openreview.net/pdf?id=xB1deFXLaF9 (accessed on 7 July 2021).
- El-Kassas, W.S.; Salama, C.R.; Rafea, A.A.; Mohamed, H.K. Automatic text summarization: A comprehensive survey. Expert Syst. Appl. 2020, 165, 113679. [Google Scholar] [CrossRef]
- Elman, J.L. Finding structure in time. Cogn. Sci. 1990, 14, 179–211. [Google Scholar] [CrossRef]
- Schuster, M.; Paliwal, K.K. Bidirectional recurrent neural networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef] [Green Version]
- Bengio, Y.; Simard, P.; Frasconi, P. Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Netw. 1994, 5, 157–166. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Sundermeyer, M.; Schlüter, R.; Ney, H. LSTM neural networks for language modeling. In Proceedings of the Thirteenth Annual Conference of the International Speech Communication Association, Portland, Oregon, 9–13 September 2012. [Google Scholar]
- Sundermeyer, M.; Ney, H.; Schlüter, R. From feedforward to recurrent LSTM neural networks for language modeling. IEEE/ACM Trans. Audio Speech Lang. Process. 2015, 23, 517–529. [Google Scholar] [CrossRef]
- Larochelle, H.; Hinton, G.E. Learning to combine foveal glimpses with a third-order boltzmann machine. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 6–9 December 2010. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. 2018. Available online: https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf (accessed on 8 February 2021).
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language Models are Unsupervised Multitask Learners. 2019. Available online: https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf (accessed on 8 February 2021).
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. arXiv 2020, arXiv:2005.14165. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.R.; Le, Q.V. Xlnet: Generalized autoregressive pretraining for language understanding. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter. arXiv 2019, arXiv:1910.01108. [Google Scholar]
- Wolf, T.; Chaumond, J.; Debut, L.; Sanh, V.; Delangue, C.; Moi, A.; Rush, A.M. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Stroudsburg, PA, USA, 16–20 November 2020. [Google Scholar]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2009, 22, 1345–1359. [Google Scholar] [CrossRef]
- Wang, A.; Singh, A.; Michael, J.; Hill, F.; Levy, O.; Bowman, S.R. Glue: A multi-task benchmark and analysis platform for natural language understanding. arXiv 2018, arXiv:1804.07461. [Google Scholar]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep contextualized word representations. arXiv 2018, arXiv:1802.05365. [Google Scholar]
- Howard, J.; Ruder, S. Universal language model fine-tuning for text classification. arXiv 2018, arXiv:1801.06146. [Google Scholar]
- Pappagari, R.; Zelasko, P.; Villalba, J.; Carmiel, Y.; Dehak, N. Hierarchical transformers for long document classification. In Proceedings of the 2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Singapore, 14–18 December 2019. [Google Scholar]
- Pelicon, A.; Pranjić, M.; Miljković, D.; Škrlj, B.; Pollak, S. Zero-shot learning for cross-lingual news sentiment classification. Appl. Sci. 2020, 10, 5993. [Google Scholar] [CrossRef]
- Zhang, X.; Wei, F.; Zhou, M. HIBERT: Document level pre-training of hierarchical bidirectional transformers for document summarization. arXiv 2019, arXiv:1905.06566. [Google Scholar]
- Xu, S.; Zhang, X.; Wu, Y.; Wei, F.; Zhou, M. Unsupervised Extractive Summarization by Pre-training Hierarchical Transformers. arXiv 2020, arXiv:2010.08242. [Google Scholar]
- Vig, J. A multiscale visualization of attention in the transformer model. arXiv 2019, arXiv:1906.05714. [Google Scholar]
- Kovaleva, O.; Romanov, A.; Rogers, A.; Rumshisky, A. Revealing the dark secrets of BERT. arXiv 2019, arXiv:1908.08593. [Google Scholar]
- Voita, E.; Serdyukov, P.; Sennrich, R.; Titov, I. Context-aware neural machine translation learns anaphora resolution. arXiv 2018, arXiv:1805.10163. [Google Scholar]
- Goldberg, Y. Assessing BERT’s syntactic abilities. arXiv 2019, arXiv:1901.05287. [Google Scholar]
- Wolf, T. Some Additional Experiments Extending the Tech Report “Assessing BERTs Syntactic Abilities” by Yoav Goldberg. 2019. Available online: https://huggingface.co/bert-syntax/extending-bert-syntax.pdf (accessed on 5 February 2021).
- Hewitt, J.; Manning, C.D. A structural probe for finding syntax in word representations. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, pp. 4129–4138. [Google Scholar]
- Raganato, A.; Tiedemann, J. An analysis of encoder representations in transformer-based machine translation. In Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, Brussels, Belgium, 1 November 2018. [Google Scholar]
- Vig, J.; Belinkov, Y. Analyzing the structure of attention in a transformer language model. arXiv 2019, arXiv:1906.04284. [Google Scholar]
- Voita, E.; Talbot, D.; Moiseev, F.; Sennrich, R.; Titov, I. Analyzing multi-head self-attention: Specialized heads do the heavy lifting, the rest can be pruned. arXiv 2019, arXiv:1905.09418. [Google Scholar]
- Franz, L.; Shrestha, Y.R.; Paudel, B. A deep learning pipeline for patient diagnosis prediction using electronic health records. arXiv 2020, arXiv:2006.16926. [Google Scholar]
- Letarte, G.; Paradis, F.; Giguère, P.; Laviolette, F. Importance of self-attention for sentiment analysis. In Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, Brussels, Belgium, 1 November 2018. [Google Scholar]
- Bodria, F.; Panisson, A.; Perotti, A.; Piaggesi, S. Explainability Methods for Natural Language Processing: Applications to Sentiment Analysis (Discussion Paper). 2020. Available online: http://ceur-ws.org/Vol-2646/18-paper.pdf (accessed on 17 January 2021).
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should i trust you?” Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar]
- Zhang, Y.; Song, K.; Sun, Y.; Tan, S.; Udell, M. “Why Should You Trust My Explanation?” Understanding Uncertainty in LIME Explanations. arXiv 2019, arXiv:1904.12991. [Google Scholar]
- Sundararajan, M.; Taly, A.; Yan, Q. Axiomatic attribution for deep networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 3319–3328. [Google Scholar]
- Krippendorff, K. Estimating the reliability, systematic error and random error of interval data. Educ. Psychol. Meas. 1970, 30, 61–70. [Google Scholar] [CrossRef]
- Krippendorff, K. Content Analysis: An Introduction to Its Methodology, 2nd ed.; SAGE Publications, Inc.: Thousand Oaks, CA, USA, 2004. [Google Scholar]
- Krippendorff, K. Reliability in content analysis: Some common misconceptions and recommendations. Hum. Commun. Res. 2004, 30, 411–433. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Merging Strategy | Accuracy (%) | Precision (%) | Recall (%) | F1 (%) | |||
|---|---|---|---|---|---|---|---|---|
| Neg | Pos | Neg | Pos | Neg | Pos | |||
| ExHiT | Concatenation | 92.59 | 90.97 | 94.34 | 94.56 | 90.62 | 92.73 | 92.44 |
| Average | 92.35 | 92.18 | 92.51 | 92.54 | 92.15 | 92.36 | 92.33 | |
| Masked Average | 92.77 | 92.07 | 93.49 | 93.60 | 91.94 | 92.83 | 92.71 | |
| BiLSTM | 92.34 | 90.97 | 93.80 | 94.01 | 90.67 | 92.47 | 93.06 | |
| SCC | - | 93.51 | 95.42 | 91.75 | 91.40 | 95.62 | 93.37 | 93.65 |
| Model | Merging Strategy | Agreement at Least 1 | Agreement at Least 2 | Agreement at Least 3 | |||
|---|---|---|---|---|---|---|---|
| Precision (%) | Precision (%) | Precision (%) | |||||
| Test | Train | Test | Train | Test | Train | ||
| ExHiT | Concatenation | 53.82% | 55.88% a | 49.15% | 45.00% | 46.63% | 46.45% |
| Average | 58.04% | 57.82% | 50.42% | 45.92% 1 | 45.29% | 41.84% | |
| Masked Average | 53.15% a | 55.79% | 45.97% a | 44.92% | 40.66% | 39.80% | |
| BiLSTM | 55.51% a | 55.85% | 49.05% a | 45.24% a | 43.38% a | 39.95% | |
| SCC | - | 70.74% | 65.61% | 65.22% | 57.83% | 55.22% | 47.52% |
| Model | Accuracy (%) | Agreement at Least 1 | Agreement at Least 2 | Agreement at Least 3 | |||
|---|---|---|---|---|---|---|---|
| Precision (%) | Precision (%) | Precision (%) | |||||
| Test | Train | Test | Train | Test | Train | ||
| ExHiT | 92.59% | 53.82% | 55.88% a | 49.15% | 45.00% | 46.63% | 46.45% |
| + SM | 92.51% | 67.24% | 68.27% | 59.82% | 56.17% | 54.88% | 57.09% a |
| + SPE | 92.37% | 64.34% | 65.35% | 58.13% | 56.33% | 52.19% | 56.38% |
| + SM + SPE | 92.67% | 70.27% a | 69.11% 1 | 63.65% | 63.50% | 55.56% | 55.67% a |
| Frozen T1 | 89.50% | 63.43% | 68.16% a | 52.78% a | 56.00% | 44.11% a | 48.23% a |
| SCC | 93.51% | 70.74% | 65.61% | 65.22% | 57.83% | 55.22% | 47.52% |
| Model | (%) | Neutral Rate (%) | ||
|---|---|---|---|---|
| Test | Train | Test | Train | |
| ExHiT | 78.33% | 74.67% | 26.00% | 35.37% |
| + SM + SPE | 86.50% | 82.67% | 13.00% | 17.69% |
| SCC | 92.67% | 88.67% | 11.56% | 19.05% |
| Index | ExHiT | Index | ExHiT + SM |
|---|---|---|---|
| 0 | This film was a surprise. | 0 | This film was a surprise. |
| 6 | Jealousy, sexual tension, incest, intrigue, […] | 6 | Jealousy, sexual tension, incest, intrigue, […] |
| 11 | Even though her strength and lack of illusion […] | 1 | The plot synopsis sounds kinky […] |
| 13 | 8 | However, I wanted to clarify a point […] | |
| 14 | 10 | The attractive female slave successfully resists […] | |
| 4 | The child takes him to the girls […] | 9 | I find that there is one. |
| 10 | The attractive female slave successfully resists […] | 3 | There is that opening scene where […] |
| 3 | There is that opening scene where […] | 11 | Even though her strength and lack of illusion […] |
| 5 | He takes advantage of the situation […] | 2 | I didn’t know what to expect. |
| 7 | I’ve read the other comments here and find little to disagree with. | 5 | He takes advantage of the situation […] |
| 2 | I didn’t know what to expect. | 7 | I’ve read the other comments here and find little to disagree with. |
| 12 | She, more than any of the other women […] | 4 | The child takes him to the girls […] |
| 9 | I find that there is one. | 12 | She, more than any of the other women […] |
| 8 | However, I wanted to clarify a point […] | 13 | |
| 1 | The plot synopsis sounds kinky […] | 14 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bacco, L.; Cimino, A.; Dell’Orletta, F.; Merone, M. Explainable Sentiment Analysis: A Hierarchical Transformer-Based Extractive Summarization Approach. Electronics 2021, 10, 2195. https://doi.org/10.3390/electronics10182195
Bacco L, Cimino A, Dell’Orletta F, Merone M. Explainable Sentiment Analysis: A Hierarchical Transformer-Based Extractive Summarization Approach. Electronics. 2021; 10(18):2195. https://doi.org/10.3390/electronics10182195
Chicago/Turabian StyleBacco, Luca, Andrea Cimino, Felice Dell’Orletta, and Mario Merone. 2021. "Explainable Sentiment Analysis: A Hierarchical Transformer-Based Extractive Summarization Approach" Electronics 10, no. 18: 2195. https://doi.org/10.3390/electronics10182195