
Super-Resolution Model Quantized in Multi-Precision


Abstract
:1. Introduction
- (1)
- The concept of “quantization sensitivity” is proposed, which describes the sensitivity of quantization results of all stages to a quantization approach, from three aspects: model size, test time and result accuracy.
- (2)
- For different stages of the same network with different quantization sensitivities, a hybrid quantization method is proposed to obtain a good quantization results in model size, testing time and accuracy.
2. Background and Related Works
2.1. Super-Resolution
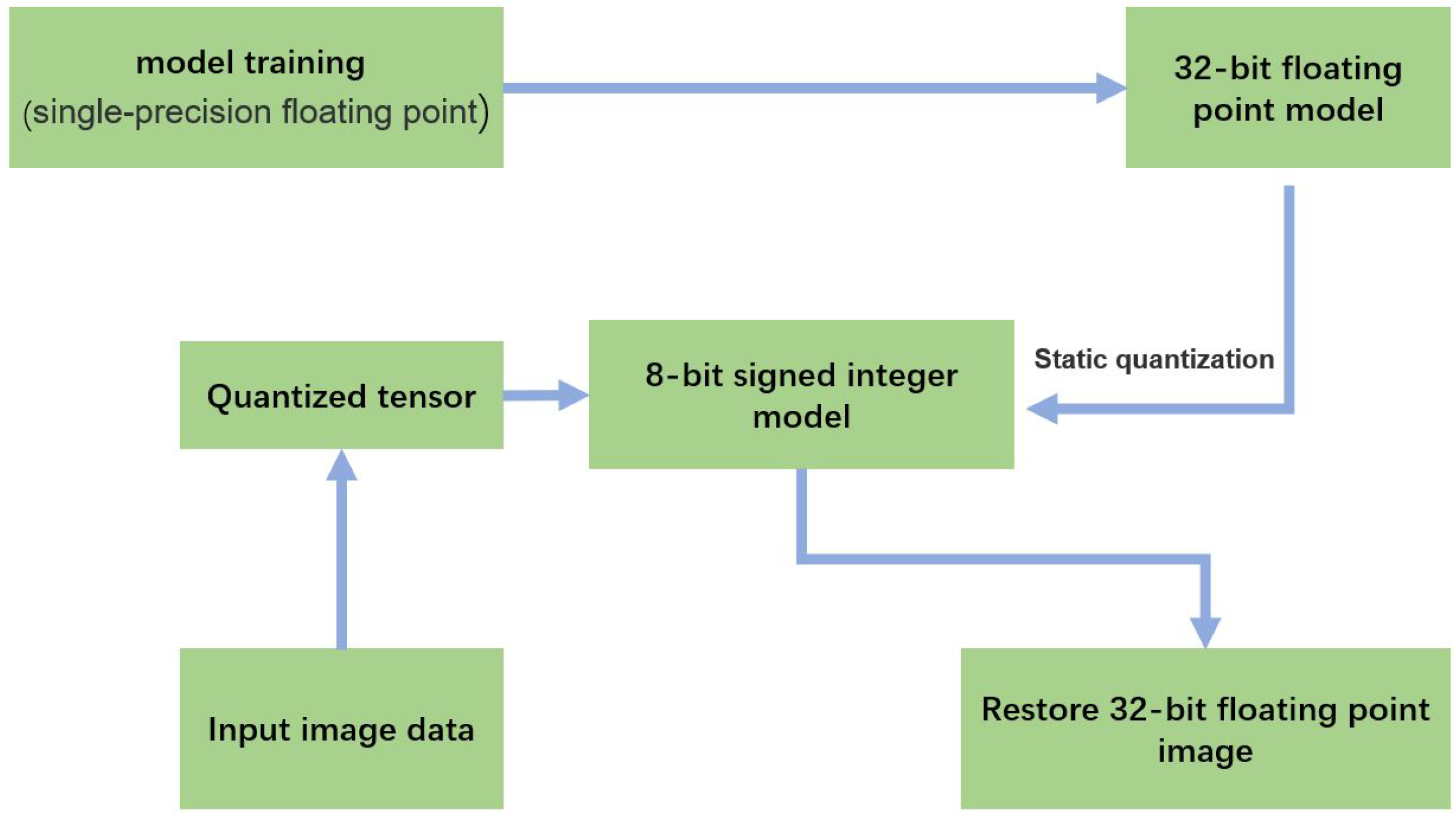
2.2. Model Quantization
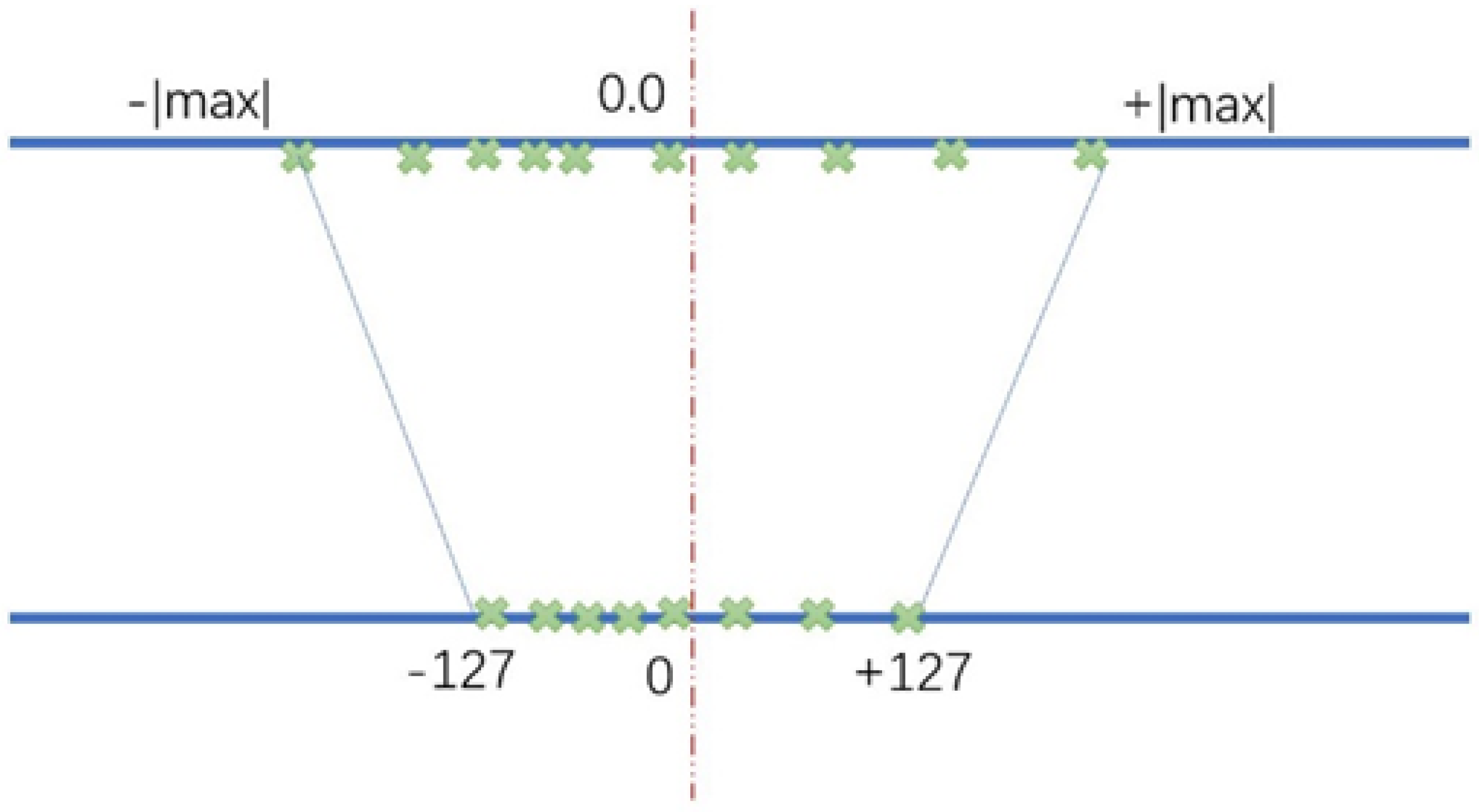
Quantization Method
2.3. Super-Resolution Model in Quantization
3. Quantizton Method Selection of Typical SR Model
4. Mixed Quantization Method
4.1. The Basic Concept of Sensitivity
4.2. Mixed Quantization
5. Experiment and Discussion
5.1. Experiment
5.2. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| CUDA | Compute Unified Device Architecture |
| SR | Super-Resolution |
| GPU | Graphics Processing Unit |
| SRCNN | Image super-resolution using deep convolutional networks |
| SRGAN | Super-resolution using a generative adversarial network |
| ESRGAN | Enhanced SRGAN |
| EDSR | Enhanced Deep Residual Networks for Single Image Super-Resolution |
| OS | Operation System |
| CPU | Central Processing Unit |
| PI | Perceptual Index |
| TWN | Ternary Weight Networks |
| INQ | Incremental Network Quantization |
| QNN | Quantized Neural Network |
| CNN | Convolutional Neural Network |
| DNN | Deep Neural Network |
References
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Loy, C.C.; Qiao, Y.; Tang, X. ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual Losses for Real-Time Style Transfer and Super-Resolution. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016. [Google Scholar]
- Ying, T.; Jian, Y.; Liu, X. Image Super-Resolution via Deep Recursive Residual Network. In Proceedings of the IEEE Conference on Computer Vision & Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Lee, K.M. Enhanced Deep Residual Networks for Single Image Super-Resolution. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Jolicoeur-Martineau, A. The relativistic discriminator: A key element missing from standard GAN. arXiv 2018, arXiv:1807.00734. [Google Scholar]
- Choi, J.; Zhuo, W.; Venkataramani, S.; Chuang, I.J.; Gopalakrishnan, K. PACT: Parameterized Clipping Activation for Quantized Neural Networks. arXiv 2018, arXiv:1805.06085. [Google Scholar]
- Courbariaux, M.; Bengio, Y.; David, J.P. BinaryConnect: Training Deep Neural Networks with Binary Weights during Propagations; MIT Press: Cambridge, MA, USA, 2015. [Google Scholar]
- Courbariaux, M.; Hubara, I.; Soudry, D.; El-Yaniv, R.; Bengio, Y. Binarized Neural Networks: Training Deep Neural Networks with Weights and Activations Constrained to +1 or -1. arXiv 2016, arXiv:1602.02830. [Google Scholar]
- Wu, J.; Cong, L.; Wang, Y.; Hu, Q.; Jian, C. Quantized Convolutional Neural Networks for Mobile Devices. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Rastegari, M.; Ordonez, V.; Redmon, J.; Farhadi, A. XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sa, C.D.; Leszczynski, M.; Jian, Z.; Marzoev, A.; Ré, C. High-Accuracy Low-Precision Training. arXiv 2018, arXiv:1803.03383. [Google Scholar]
- Chu, T.; Luo, Q.; Yang, J.; Huang, X. Mixed-precision quantized neural networks with progressively decreasing bitwidth. Pattern Recognit. 2021, 111, 107647. [Google Scholar] [CrossRef]
- Mishra, A.; Nurvita DHi, E.; Cook, J.J.; Marr, D. WRPN: Wide Reduced-Precision Networks. arXiv 2017, arXiv:1709.01134. [Google Scholar]
- Zhuang, B.; Liu, L.; Tan, M.; Shen, C.; Reid, I. Training Quantized Neural Networks with a Full-precision Auxiliary Module. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Li, F.; Liu, B. Ternary Weight Networks. arXiv 2016, arXiv:1605.04711. [Google Scholar]
- Zhou, A.; Yao, A.; Guo, Y.; Xu, L.; Chen, Y. Incremental Network Quantization: Towards Lossless CNNs with Low-Precision Weights. arXiv 2017, arXiv:1702.03044. [Google Scholar]
- Hubara, I.; Courbariaux, M.; Soudry, D.; El-Yaniv, R.; Bengio, Y. Quantized Neural Networks: Training Neural Networks with Low Precision Weights and Activations. J. Mach. Learn. Res. 2016, 18, 6869–6898. [Google Scholar]
- Kim, N.; Shin, D.; Choi, W.; Kim, G.; Park, J. Exploiting Retraining-Based Mixed-Precision Quantization for Low-Cost DNN Accelerator Design. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 2925–2938. [Google Scholar] [CrossRef] [PubMed]
- Li, M.; Lin, J.; Ding, Y.; Liu, Z.; Zhu, J.Y.; Han, S. GAN Compression: Efficient Architectures for Interactive Conditional GANs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Zhuang, B.; Tan, M.; Liu, J.; Liu, L.; Shen, C. Effective Training of Convolutional Neural Networks with Low-bitwidth Weights and Activations. IEEE Trans. Pattern Anal. Mach. Intell. 2021. [Google Scholar] [CrossRef]
- Cai, H.; Gan, C.; Wang, T.; Zhang, Z.; Han, S. Once-for-All: Train One Network and Specialize it for Efficient Deployment. arXiv 2019, arXiv:1908.09791. [Google Scholar]
- Chang, S.E.; Li, Y.; Sun, M.; Jiang, W.; Shi, R.; Lin, X.; Wang, Y. MSP: An FPGA-Specific Mixed-Scheme, Multi-Precision Deep Neural Network Quantization Framework. arXiv 2020, arXiv:2009.07460. [Google Scholar]
- Vasquez, K.; Venkatesha, Y.; Bhattacharjee, A.; Moitra, A.; Panda, P. Activation Density based Mixed-Precision Quantization for Energy Efficient Neural Networks. arXiv 2021, arXiv:2101.04354. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Bing, X.; Bengio, Y. Generative Adversarial Nets; MIT Press: Cambridge, MA, USA, 2014. [Google Scholar]
- Lee, R.; Dudziak, U.; Abdelfattah, M.; Venieris, S.I.; Lane, N.D. Journey Towards Tiny Perceptual Super-Resolution. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2020. [Google Scholar]
- Ma, Y.; Xiong, H.; Hu, Z.; Ma, L. Efficient Super Resolution Using Binarized Neural Network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Xin, J.; Wang, N.; Jiang, X.; Li, J.; Huang, H.; Gao, X. Binarized neural network for single image super resolution. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2020; pp. 91–107. [Google Scholar]
- Li, H.; Yan, C.; Lin, S.; Zheng, X.; Zhang, B.; Yang, F.; Ji, R. PAMS: Quantized Super-Resolution via Parameterized Max Scale; Springer: Cham, Switzerland, 2020. [Google Scholar]
- Jacob, B.; Kligys, S.; Chen, B.; Zhu, M.; Tang, M.; Howard, A.; Adam, H.; Kalenichenko, D. Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Soudry, D.; Hubara, I.; Meir, R. Expectation Backpropagation: Parameter-Free Training of Multilayer Neural Networks with Continuous or Discrete Weights. In Proceedings of the Neural Information Processing Systems (NIPS), Montreal, QC, USA, 8–13 December 2014. [Google Scholar]
- Yuan, N.; Zhu, Z.; Wu, X.; Shen, L. MMSR: A Multi-model Super Resolution Framework. In Network and Parallel Computing; Springer: Cham, Switzerland, 2019. [Google Scholar]
- Yuan, N.; Liu, J.; Wang, Q.; Shen, L. Customizing Super-Resolution Framework According to Image Features. In Proceedings of the 2020 IEEE Intl Conf on Parallel & Distributed Processing with Applications, Big Data & Cloud Computing, Sustainable Computing & Communications, Social Computing & Networking (ISPA/BDCloud/SocialCom/SustainCom), Exeter, UK, 17–19 December 2020. [Google Scholar]
- Yuan, N.; Zhang, D.; Wang, Q.; Shen, L. A Multi-Model Super-Resolution Training and Reconstruction Framework; Network and Parallel Computing; Springer: Cham, Switzerland, 2021. [Google Scholar]
- Imambi, S.; Prakash, K.B.; Kanagachidambaresan, G.R. PyTorch; Programming with TensorFlow; EAI/Springer Innovations in Communication and Computing; Springer: Cham, Switzerland, 2021. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| HW/SW Module | Description |
|---|---|
| CPU | Intel® Xeon® E5-2660 v3 @2.6 GHz × 2 |
| GPU | NVIDIA Tesla K80 × 4 |
| Memory | 64 GB |
| OS | Linux CentOS 7.4 |
| Development Environment | Anaconda 3, CUDA 9.2, Pytorch 1.7.1 |
| Model | SRGAN | ESRGAN |
|---|---|---|
| Size-B(MB) | 5.941 | 65.361 |
| Size-A(MB) | 1.163 | 17.4 |
| PI-O | 2.0817 | 2.2061 |
| PI-S | 4.6278 | 4.562 |
| PI-Q | 2.4731 | 2.688 |
| Inf time-B | 82 s | 138 s |
| Inf time-A | 53 s | 77 s |
| Model | SRGAN | ESRGAN |
|---|---|---|
| Size-B(MB) | 5.941 | 65.361 |
| Size-A(MB) | 1.163 | 17.4 |
| Size-A-M(MB) | 1.952 | 20.6 |
| PI-O | 2.0817 | 2.2061 |
| PI-Q-M | 2.1049 | 2.2075 |
| Inf time-B | 82 s | 138 s |
| Inf time-A | 57 s | 83 s |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, J.; Wang, Q.; Zhang, D.; Shen, L. Super-Resolution Model Quantized in Multi-Precision. Electronics 2021, 10, 2176. https://doi.org/10.3390/electronics10172176
Liu J, Wang Q, Zhang D, Shen L. Super-Resolution Model Quantized in Multi-Precision. Electronics. 2021; 10(17):2176. https://doi.org/10.3390/electronics10172176
Chicago/Turabian StyleLiu, Jingyu, Qiong Wang, Dunbo Zhang, and Li Shen. 2021. "Super-Resolution Model Quantized in Multi-Precision" Electronics 10, no. 17: 2176. https://doi.org/10.3390/electronics10172176