1. Introduction
Neural machine translation (NMT) has shown impressive results on translation quality, due to the availability of vast parallel corpus [
1], and the introduction of novel deep neural network (DNN) architectures such as encoder-decoder model [
2,
3], and self-attention based networks [
4]. The performance of NMT systems has reached on par with human translators in some domains, and hence many commercial MT services, such as Google Translation, have adopted NMT as their backbone of translation systems [
5].
Despite the significant improvement over the previous machine translation (MT) systems, NMT still suffers from language-specific problems such as Russian pronoun resolution [
6] and honorifics. Addressing such language-specific problems is crucial in both personal and business communications [
7] not only because the preservation of meaning is necessary but also many of these language-specific problems are also closely related to their culture.
Honorifics are good example of these language-specific problems that conveys respect to the audience. In some languages including Korean, Japanese, and Hindi that use honorifics frequently, speaking the right honorifics is considered imperative in those languages.
In Korean, one of the most frequent usages of honorifics occurs in the conversation with people who are in superior positions, or elders [
8]. As is shown in
Figure 1, the
source English sentence “Wait a minute, please.”, which is the second utterance by the son, is translated into the
target sentence “잠시만 기다려요.” (jam-si-man gi-da-lyeo-yo) that is represented as
haeyo-che (해요체) as the sentence ends with -요 (-yo). Haeyo-che is a type of Korean honorific reflecting the relationship between the two speakers.
Addressing such honorifics in MT is challenging since the definition of honorifics differs across different languages. For example, Korean has 3 major types of honorifics [
8] and corresponding honorific expressions. In contrast, it is known that English has fewer types of honorifics compared to many other languages [
9]; only titles, such as Mr. and Mrs., are frequently used in modern English. It is known that managing honorifics in translation is comparatively more complicated in English-Korean translation; the source language has a simpler honorific system compared to the target language. The source language with fewer honorifics provides fewer honorific features that are used to generate correct honorifics in the target side, as shown in
Figure 1. Since the English verb “wait” can be translated into both the honorific style (기다려요, gi-da-lyeo-yo) and the non-honorific style (기다려, gi-da-lyeo), the model cannot determine the adequate honorific solely depending on the source sentence, and additional information is necessary such as the relationship between speakers.
In this paper, we propose a novel method to remedy limitations from solely depending on source sentence by using
context, which is represented by the surrounding sentences of the source sentence. In
Figure 1, we can infer that this is a dialogue between a son and his father from the content of
context_1, and the source sentence. Therefore, the model can determine that the source sentence should be translated into a polite sentence using honorifics, such as
haeyo-che (해요체), if such context is taken into account.
To this end, we introduce a
context-aware NMT to incorporate the context for improving Korean honorific translation. It is known that the context-aware NMT can improve the translation of words or phrases that need contextual information, such as pronouns that are sensitive to the plural and/or gender [
10]. Considering above example that how the adequate honorific style can be determined using the context, we suggest that the context-aware NMT can also be used to aid the honorific-aware translation. To the best of our knowledge, this work is the first attempt to utilize context-aware NMT for honorific-aware translation.
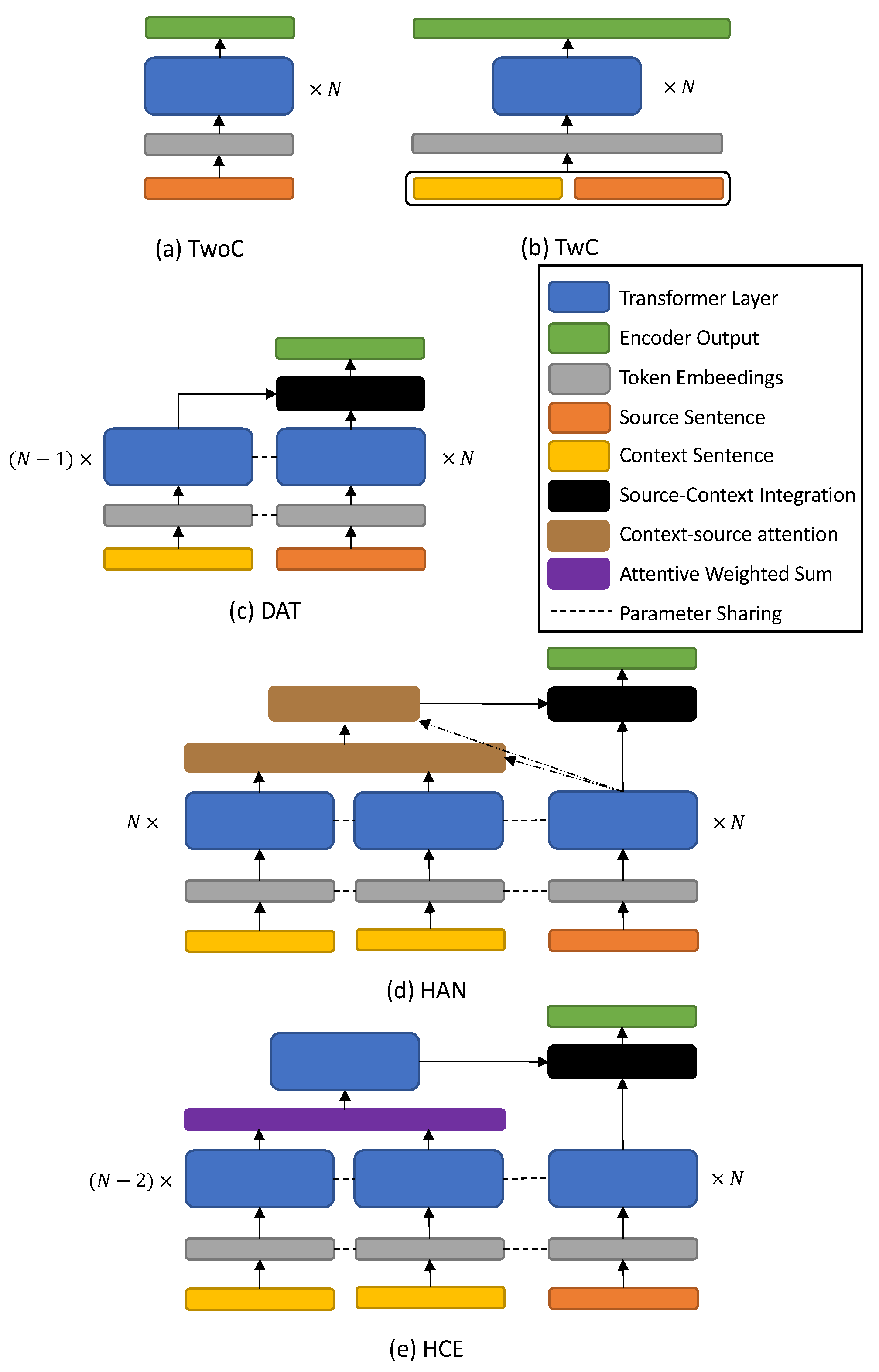
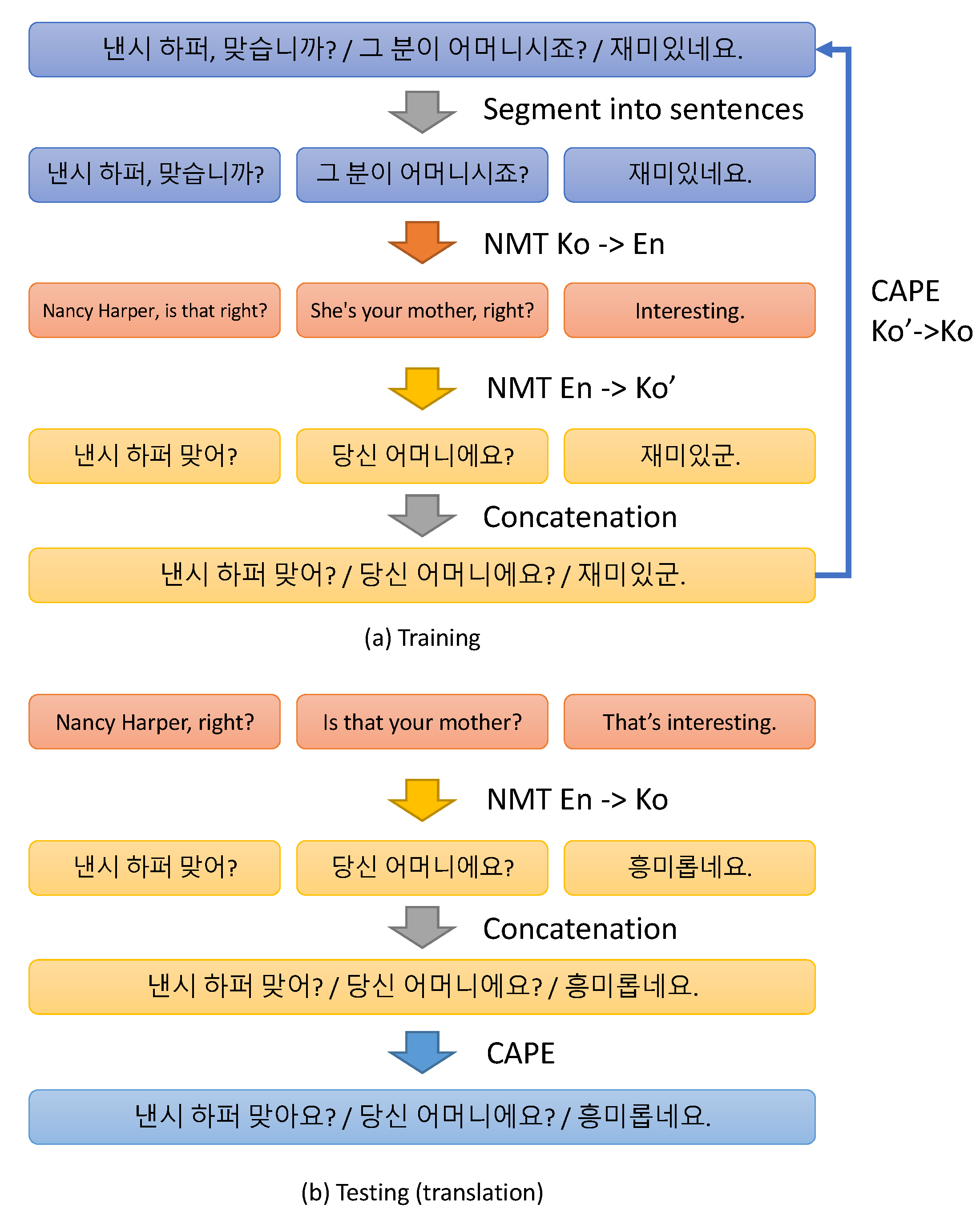
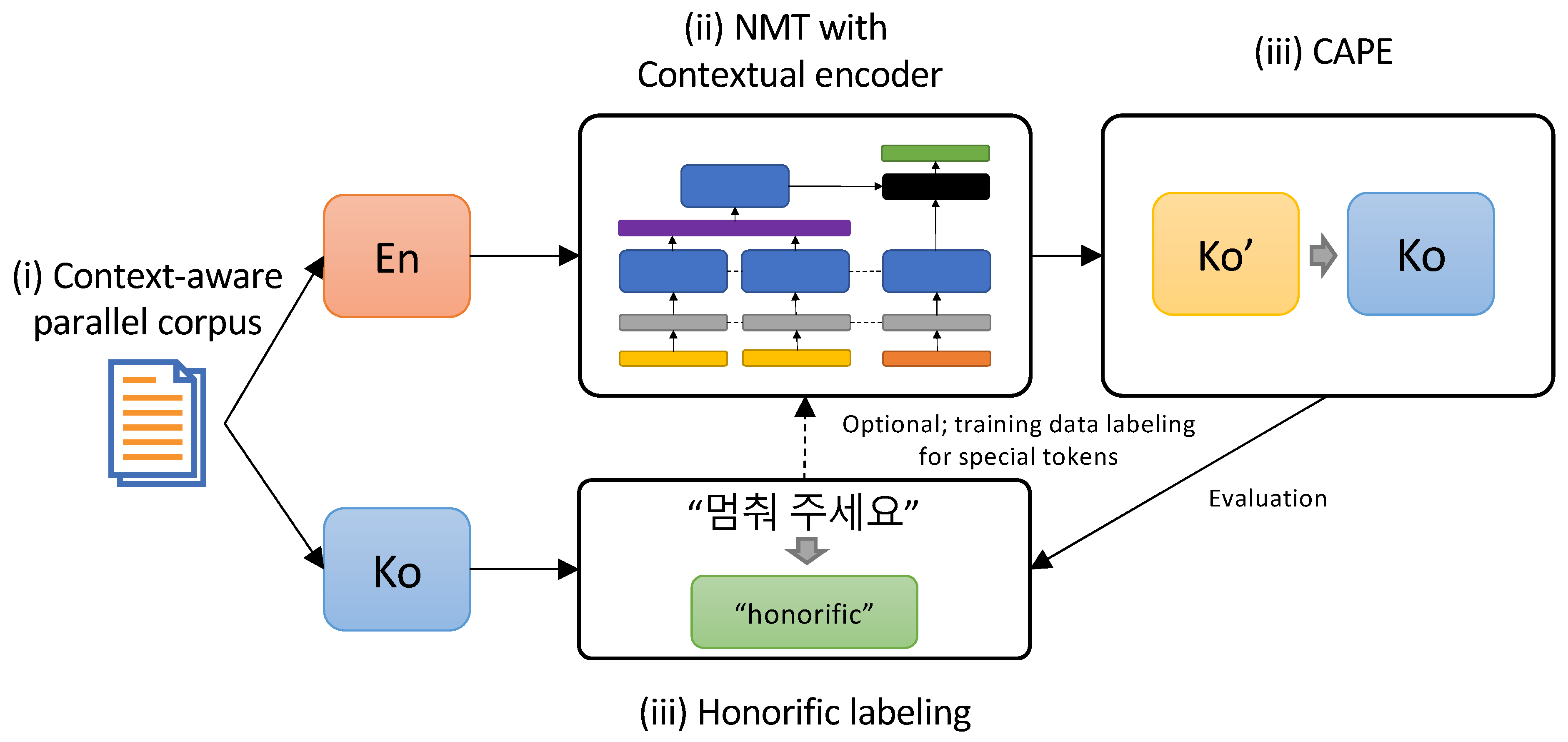
We consider two types of context-aware NMT framework in our proposed method. First, we use a contextual encoder that takes context in addition to the source sentence as input. The encoder captures contextual information from the source language that is needed to determine target honorifics. Second, a context-aware post-editing (CAPE) system is adopted to take the context of translated target sentences for refining the sentence-level translations accordingly.
To demonstrate the performance of our method, an honorific-labeled parallel corpus is needed so we also developed simple and fast rule-based honorific annotation for labeling the test data. In the experiments, we compared our context-aware systems with context-agnostic models and we show that our method outperformed the context-agnostic baselines significantly in both the overall translation quality and translation of honorifics.
We hope that our proposed method improves the overall quality of Korean NMT and thus expanding the real-world use of NMT in communicating with Korean. Adequate use of honorifics can greatly improve the overall quality of Korean translations, especially in spoken language translation (SLT) systems. We suggest that MT systems for applications like movie/TV captioning, chatting can be benefited from our method.
Our contributions can be summarized in threefolds:
We show that the NMT model with a contextual encoder improves the quality of the honorific translation regardless of the model structure. In our experiments, even the simplest model that concatenates all the contextual sentences with the source sentence can improve honorific accuracy. We also show that the NMT model with contextual encoder also outperforms the sentence-level model even when the model is explicitly controlled to translate to a specific honorific style.
In addition to the contextual encoder, we demonstrate that the CAPE can improve honorifics of both the sentence-level NMT and contextual NMT by exploiting contextual sentences of the target language. Our qualitative analysis also reveals the ability of CAPE to improve the inconsistent use of honorifics of the NMT model with a contextual encoder.
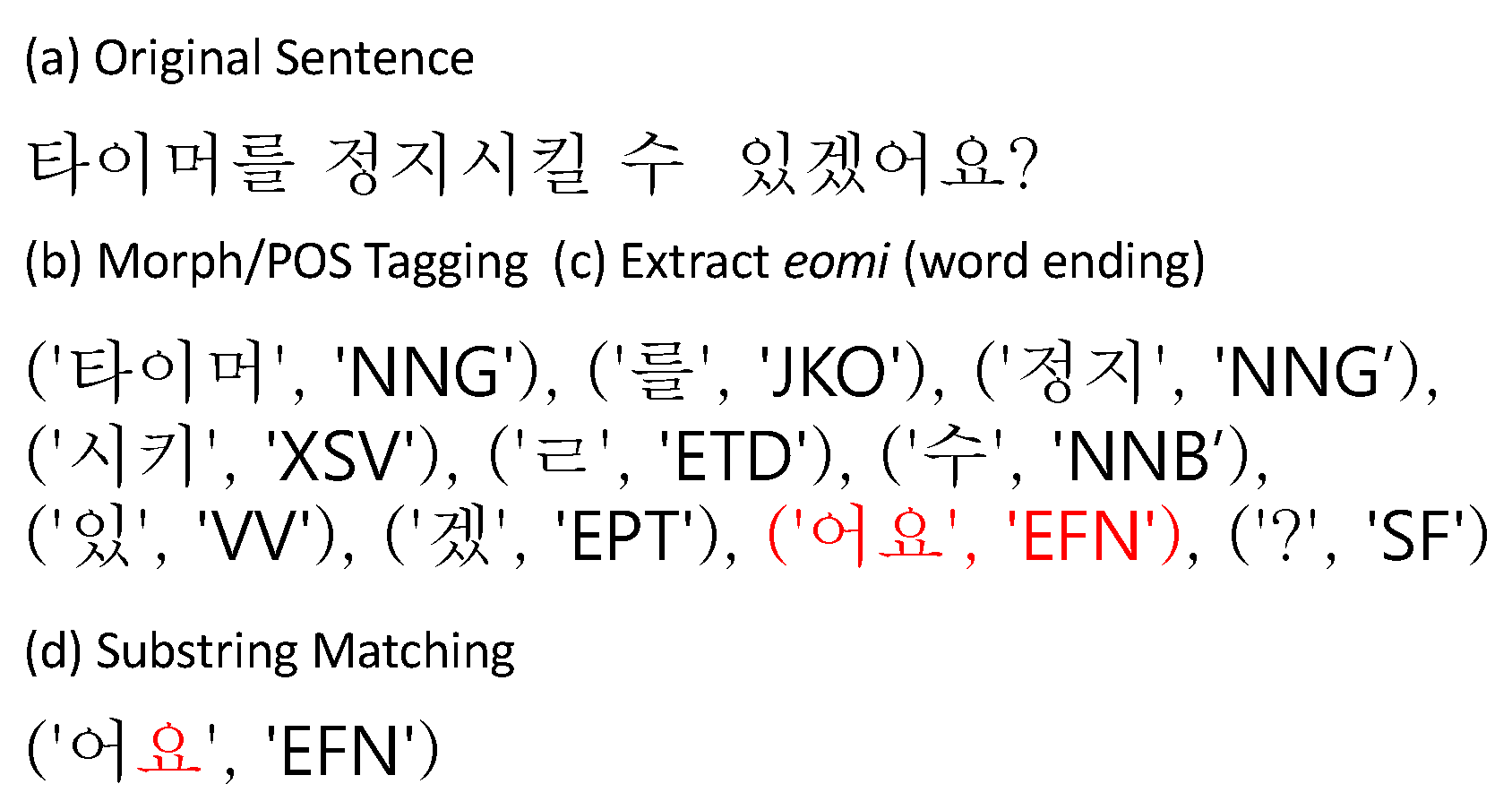
We also develop an automatic data annotation heuristics for labeling Korean sentences as honorific and non-honorific style. Our heuristics utilize Korean morphology to precisely determine the honorific style of a given sentence. We labeled our test set by using the heuristics and used it to validate the improvements of our proposed method.
The remaining part of this paper consists as follows: We briefly review the related works in
Section 2 and introduce Korean honorifics in
Section 3. Context-aware NMT methods are presented in
Section 4. We introduce our methods in
Section 5 then show the experimental results in
Section 6. Finally we present our conclusion in
Section 7.
3. Addressing Korean Honorifics in Context
In this section, we present an overview of the Korean honorifics system and how the contextual sentence can be used to infer appropriate honorifics for translation.
3.1. Overview of Korean Honorifics System
Asian languages such as Korean, Japanese, and Hindi are well-known as having rich honorific systems to express formality distinctions. Among those languages, the use of honorifics is extensive and also crucial in Korean culture. In practice, Korean speakers are forced to choose appropriate honorifics in every utterance, and failing to do that can induce serious social sanctions including school expulsion [
8]. Moreover, it is known that Korean honorific systems are very sophisticated among the well-known languages thus teaching how to use Korean honorifics appropriately is also considered challenging in Korean as a Second Language (KSL) education [
8,
33]
There are three types of Korean honorifics; subject honorification, object honorification, and addressee honorification. First, in the subject honorification, the speaker honors the referent by using honorific suffixes such as ‘-시-’(-si-), case particles such as ‘-께서’(-kke-seo), and so on:
In contrast to (1), the speaker’s 어머니 (eo-meo-ni, mother) in (2) is honored by the following case particle `께서’ (-kke-seo) and the honorific suffix ‘-신-’ (-sin-) at the verb 가다 (ga-da; go). Second, object honorification is used when the referent of the object is of higher status (e.g., elder) to both the speaker and referent of the subject:
- (a)
철수는 잘 모르는 것이 있으면 항상 아버지께 여쭌다. (cheol-su-neun jal mo-leu-neun geos-i iss-eu-myeon hang-sang a-beo-ji-kke yeo-jjun-da; Cheolsoo always ask his father about something that he doesn’t know well.)
- (b)
아버지는 휴대폰에 대해 잘 모르는 게 있으면 항상 철수에게 묻는다. (a-beo-ji-neun hyu-dae-pon-e dae-hae jal mo-leu-neun ge iss-eu-myeon hang-sang cheol-su-e-ge mud-neun-da; Cheolsoo’s father always ask him about mobile phones that he doesn’t know well.)
In the example (a), Cheolsoo’s 아버지 (a-beo-ji, father) is in the superior position both to 철수 (Cheolsoo) and the speaker. Therefore, ’여쭌다’ (yeo-jjun-da), which is an honorific from of the verb 묻는다 (mud-neun-da, ask), is used.
Finally, addressee honorifics are expressions of varying speech levels that are used to show politeness or closeness and are usually expressed as sentence endings in
Table 1.
Despite that all 6 examples are translated as the same English sentence, each example has its own levels of formality and politeness and different usages. For example, `반말체’ (
banmal-che) and `해라체’ (
haela-che) are used between people with close relationships or used by the elderly when speaking to younger people. Conversely, `해요체’ (
haeyo-che) and `합쇼체’ (
hapsio-che) are used to honor the addressees and express politeness [
8].
3.2. The Role of Context on Choosing Honorifics
As stated earlier, the relationship between speaker and audiences affects the use of Korean honorifics. For example, the student should use haeyo-che and hapsio-che as addressee honorifics when asking a teacher some questions. Since such social context is often reflected in utterances, readers may infer the relationship from text without knowing who are speakers and/or audiences.
In the
Figure 1, we can infer that the source and the contextual sentence is consist of a dialogue between a dad and a son and the
context_1 and the source sentence is utterances of the son, so the source English sentence should be translated into a polite Korean sentence as shown.
Figure 2 shows two another examples in our dataset. In (a), a dialogue between a person (
context_0) and his/her superior (
context_1). So their Korean translations are in polite (
haeyo-che) and impolite (
banmal-che) respectively. In addition, we can infer that the source sentence is also an utterance by the same person who told (
context_0) as we can find the same pronoun
we to refer themselves. So the sentence endings of translation should be as “중독 됐어
요” (jung-dog dwaess-eo-
yo) which has the same honorifics as
context_0, instead of using
banmal-che, such as “중독 됐
어” (jung-dog dwaess-
eo).
On the other hand, (b) shows the usage of hapsio-che which is frequently used for formal expressions in context_0 and the source sentence, as both of the sentences are ending with ‘-ㅂ니다’ (-b-nida). The word suspect (용의자, yong-ui-ja) in context_0 give us a hint that the context_0 is told by police officers, prosecutors etc since the word is frequently used by those occupations. We can also infer that this dialogue is not held between those officers from the pronoun you, rather the utterances are told to a witness, etc. So the context_0 and the source sentence would be translated into formal Korean utterances, rather than informal sentences like “우린 빨리 제시카를 찾아야 해” (u-lin ppal-li je-si-ka-leul chaj-a-ya hae).
As shown in the examples, contextual sentences often have important clues for choosing appropriate honorifics in Korean translation. However prior approaches for honorific-aware NMT including [
26] for Japanese, and [
22] for Korean have ignored those contexts. Instead, they explicitly controlled the model to translate the source sentence into a specific honorific style, using special tokens for indicating the target honorific as [
20].
6. Experiments
To verify how the context-aware models improve Korean honorifics in English-Korean translation, we conduct comprehensive experiments and analyses on how context-aware MT models translate Korean honorifics. First, we constructed an English-Korean parallel corpus with contextual sentences. Then, we train and compare the models described in
Section 4. Finally, a qualitative analysis is conducted on some examples from our proposed method.
6.1. Dataset and Preprocessing
To the best of our knowledge, there are no English-Korean discourse-level or context-aware parallel corpora that are publicly available. Thus, we constructed an English-Korean parallel corpus with contextual sentences. We took an approach similar to [
34] by choosing to use bilingual English-Korean subtitles of movies and TV shows because these subtitles contain many scripts with honorific expressions.
We first crawled approximately 6100 subtitle files from websites such as GomLab.com. Then, we split these files into training, development, and test sets, which consist of 5.3
k, 500, and 50 files, respectively. We applied a file-based split to make sure that contextual sentences are only extracted from the same movie/episode. Unlike other datasets such as OpenSubtitles2018 [
38], our subtitle files contain both English and Korean sentences, so extracting bilingual sentence pairs is straightforward; we used timestamp-based heuristics to obtain those pairs. The resulting sentence pairs are 3.0
M, 28.8
k, and 31.1
k pairs for training, development, and test sets, respectively. Some of the raw samples from our test sets are shown in
Figure 7.
The contextual sentences are selected by using the timestamp of each subtitle, which contains the start time and end time in milliseconds. We assume that the sentences contain contextual information if they appear within a short period of time before the source sentence. Specifically, the start time of a contextual sentence is within
K milliseconds from the start time of the source sentence. We set
K as 3000 heuristically, and the maximum number of preceding contextual sentences is 2 for all experiments except those of
Section 6.4.2. The final data contains 1.6
M, 155.6
k, and 18.1
k examples of consecutive sentences in the training, development, and test sets, respectively.
For monolingual data to train the CAPE, we added 2.1M Korean sentences using an additional 4029 crawled monolingual subtitles. The resulting monolingual data consist of 5.1M sentences.
We finally tokenized the dataset using the wordpiece model [
5], and the size of the vocabulary is approximately 16.5
k. We also put a special token
<BOC> at the beginning of contextual sentences to differentiate them from the source sentences.
6.2. Model Training Details
For NMT models, we use model hyperparameters, such as the size of hidden dimensions and the number of hidden layers as the
transformer-base [
4], since all of the models in our experiment share the same Transformer structure. Specifically, we set 512 as the hidden dimension, the number of layers is 6, the number of attention heads is 8, and the dropout rate is set to 0.1. These hyperparameters are also applied to the CAPE model. For NMT models with additional encoders (DAT, HCE), we share the weights of encoders.
All models are trained with ADAM [
39] with a learning rate of 1e-3, and we employ early stopping of the training when loss on the development set does not improve. We trained all of the models from scratch with random initialization, and we do not pretrain the model on a sentence-level task as in [
22,
28]. All the evaluated models are implemented by using the
tensor2tensor framework [
40].
6.3. Metrics
We measure the translation quality by BLEU scores [
41]. For scoring BLEU, we use the
t2t-bleu script (
https://github.com/tensorflow/tensor2tensor/blob/master/tensor2tensor/bin/t2t-bleu accessed on 1 May 2021) which yields the same scores as Moses [
42]. We first measure BLEU scores with original translations and we refer to these scores as
normal BLEU scores. In addition, we also measure
tokenized BLEU scores by tokenizing translations prior to scoring BLEU, as a common practice in the evaluation of Korean NMT [
43].
For honorifics, we set the accuracy of honorifics as the ratio of translations with the same type of honorific style with respect to the reference translations. For example, if the reference translation of an English sentence “Yeonghee is cleaning.” is “영희가 청소해요.” (yeong-hui-ga cheong-so-hae-yo; haeyo-che - honorific) and the model translation is “영희가 청소한다.” (yeong-hui-ga cheong-so-han-da; banmal-che - non-honorific), the translation is considered inaccurate.
6.4. Results
First, overall BLEU scores and honorific accuracy are compared among MT models with various types of contextual encoders. We also examine the varying performance of these models with respect to the number of contextual sentences and effects of CAPE for improving honorific translations.
6.4.1. Effect of Contextual Encoders
To evaluate the effect of contextual information on the translation of Korean honorifics, we first measure the performances of context-agnostic and context-aware models. The results are summarized on
Table 2. As shown in the results, all the context-aware models (TwC, DAT, HAN, and HCE) outperform the context-agnostic model (TwoC) in terms of BLEU. The HCE shows a significant English-Korean BLEU improvement over TwoC of approximately 1.07/2.03 and the TwC, DAT, and HAN also show slight improvements. We later use Korean-English TwoC and HCE trained in this experiment for generating round-trip translations on CAPE experiment since the HCE performed best among the context-aware models in terms of BLEU. We also experimented with the models on Korean-English BLEU using the same dataset for comparison. All the context-aware models again outperformed the context-agnostic model in this experiment. Note that BLEU scores are lower in all English-Korean experiments compared to Korean-English BLEU in the same dataset. This is mainly due to the morphological-rich nature of Korean and the domain of the dataset, which consists of spoken languages.
In addition to the BLEU scores, the context-aware models are also better in translation with correct Korean honorifics in English-Korean translation. In particular, the HCE has improved the honorific accuracy by 3.6%. Since showing politeness is considered important in Korean culture as discussed in
Section 3.1, we also focus on the accuracy of the test sets which are polite target sentences. The TwC outperformed all other models in this set up to 4.81% compared to TwoC. The HAN and HCE also showed significant improvement over TwoC, while the DAT’s accuracy is slightly lower than that of TwoC. We believe that such differences derive from how the model utilizes contextual information. Since we only use the sequence-level cross-entropy (CE) as a training objective, the more compact representations of contextual encoders in DAT, HAN, and HCE can improve the main objective (translation quality), but considering the raw information of contextual sentences as in TwC could be more beneficial to honorific translation.
On the other hand, all of the results in
Table 2 are from models that do not have any explicit control of honorifics and do not employ the honorific-annotated dataset. For comparison with prior works that forced the model to translate with specific honorifics as [
22], we also include the results of NMT models with special tokens for controlling output honorifics in
Table 3. In particular, the TwoC with special tokens is the same as the data labeling (DL) method in [
22]. The training set was labeled the same as the test set, with the method described in
Section 5.3. As shown in the results, both models are able to translate almost all the test examples with the same honorifics as their references, which is a similar result to that in [
22]. Interestingly, both controlled models also improve the translation quality over their counterparts without control, and the HCE with special tokens again outperformed TwoC with special tokens on BLEU.
In summary, the context-aware NMT models can improve not only the translation quality but also the accuracy of honorifics. While their improvements are less significant compared to the honorific-controlled models, they can nevertheless exploit the contextual information to aid in the correct translation of honorifics.
6.4.2. Effect of the Number of Contextual Sentences
The number of contextual sentences has a significant effect on the model performance since not all the contextual sentences are important in obtaining an adequate translation [
44]. Such redundant information can hurt the performance. Since this number is dependent on the model and the data, we carry out experiments to examine the effect of the number of contextual sentences. As shown in
Table 4, both the BLEU and accuracy of honorifics are the best on 2 contextual sentences, and then they decay as the number increases. Similar effects are also shown by the other context-aware NMT models, as displayed in
Table 5.
6.4.3. Effect of CAPE
Finally, scores with or without context-aware postediting (CAPE) are provided in
Table 6. The CAPE improved TwoC by 0.87/1.93 on BLEU and outperformed TwC and DAT on honorific accuracies by approximately 3 to 4%. The improvement in honorific accuracy suggests that CAPE can also repair the inconsistency of honorifics. We additionally applied CAPE to HCE. The result shows that HCE with CAPE also outperformed the vanilla HCE, supporting our hypothesis.
6.5. Translation Examples and Analysis
We show some translation examples in
Figure 8 and
Figure 9. As discussed in
Section 5, the honorific sentences are mostly used when a subordinate such as a child is talking to superiors such as his/her parents.
Figure 8 shows two examples of these situations. In (a), context and source sentences are a conversation between a mother and her child. This can be speculated from the contextual sentences; the child is talking but the mom urges him/her to continue eating. The TwoC completely ignores the contextual sentences, so such a situation is not considered. Thus, TwoC translates the source sentence as a non-honorific style using the non-honorific sentence ending
때 (ttae), which is
banmal-che. In contrast, the translation of HCE is an honorific sentence since its sentence ending is
요 (yo), which is
haeyo-che, the same as the reference. This is an example that shows HCE’s context-awareness that helps translation of honorific-styled sentences.
On the other hand, Daddy! in context_1 of (b) and the content of context_1 directly indicate that the source sentence is spoken by a dad’s child. Despite such direct hints, HCE failed to correctly identify the proper honorific style, resulting in banmal-che (해 (hae) and 어 (eo)). However, the TwC correctly translated the source sentence as an honorific sentence using haeyo-che (해요 (haeyo) and 데요 (daeyo)). Note that there are two sentence segments in the source and translations, and the honorific style of the two segments agrees in all the model translations and the reference. One interesting observation is that TwC has translated verb sorry as 죄송-하다 (joesong-hada) instead of 미안-하다 (mian-hada) and the 2nd person pronoun you as 아빠(appa; daddy) instead of 네 (ne; you) like HCE. As the former is resulting as a more polite translation and the latter is closer to the reference so this example can be viewed as a clue that TwC’s context-awareness is better than that of HCE. We suggest that TwC’s simple and direct use of contextual sentences can perform better than the abstract representation of contextual sentences in HCE when the contextual sentences are simple and short.
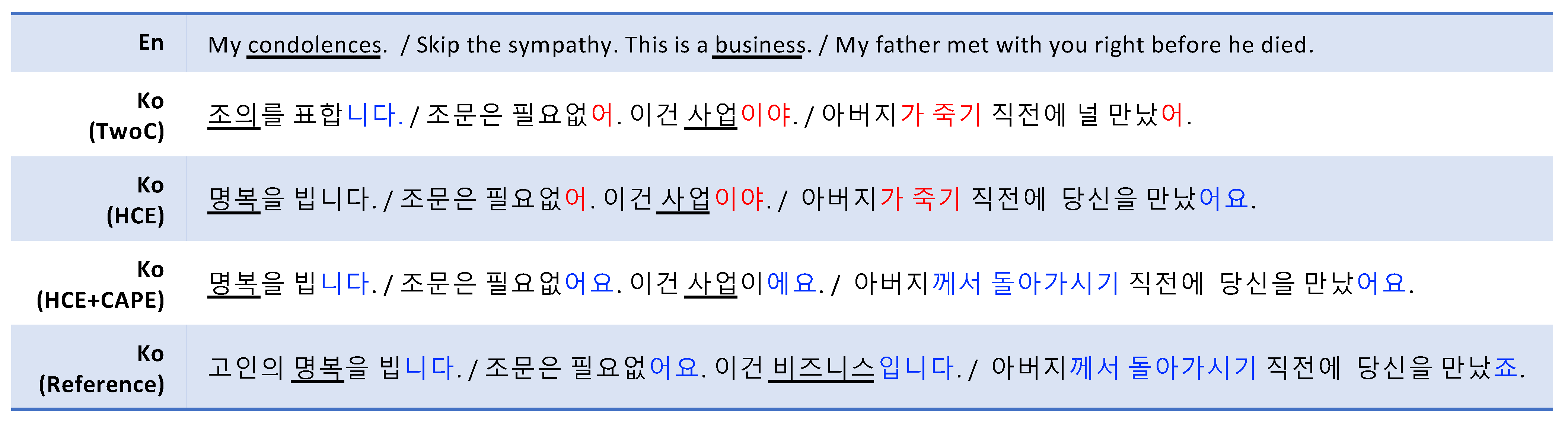
Finally,
Figure 9 shows how the CAPE corrects the inconsistent use of honorifics. These 3 sentence segments are obtained from a scene held in a funeral home. Considering the content of the sentences, we can assume that the 2nd and 3rd segments are the utterances of the same speaker. However the honorific styles of HCE translations do not agree on
banmal-che for the 2nd segment and
haeyo-che for the 3rd. CAPE corrected this inconsistency by looking at the translated Korean sentences. In addition, CAPE also amended the 3rd sentence segment by modifying the subject honorification, replacing both the case particle for the subject (his father) from
-가 (-ga) to
께서 (-kkeseo) and the verb
죽기 (jukgi) to
돌아가시기 (doragasigi); both are translated as
died. Considering that a deceased person is generally highly honored in Korean culture, the CAPE’s correction results in a more polite and thus adequate honorific-styled sentence. Although the subject honorification is out of scope in this paper, this shows the CAPE’s ability to capture various honorific patterns observed in the training corpus and correct translations.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}