
Reinforcement Learning-Based Multi-Objective Optimization for Generation Scheduling in Power Systems

Abstract
:1. Introduction

{kind=link}
{kind=link}
{kind=link}
{kind=link}
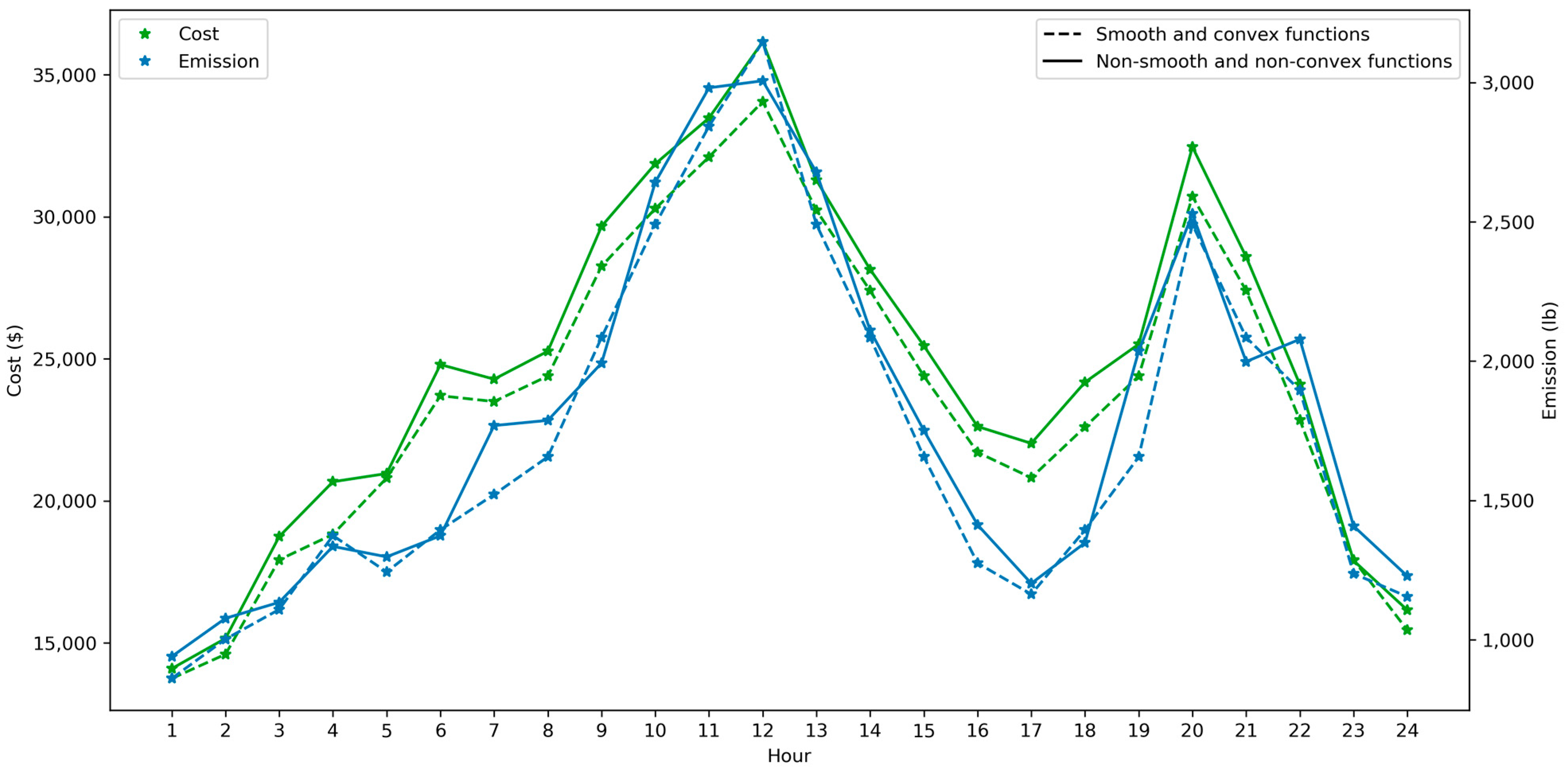{kind=link}
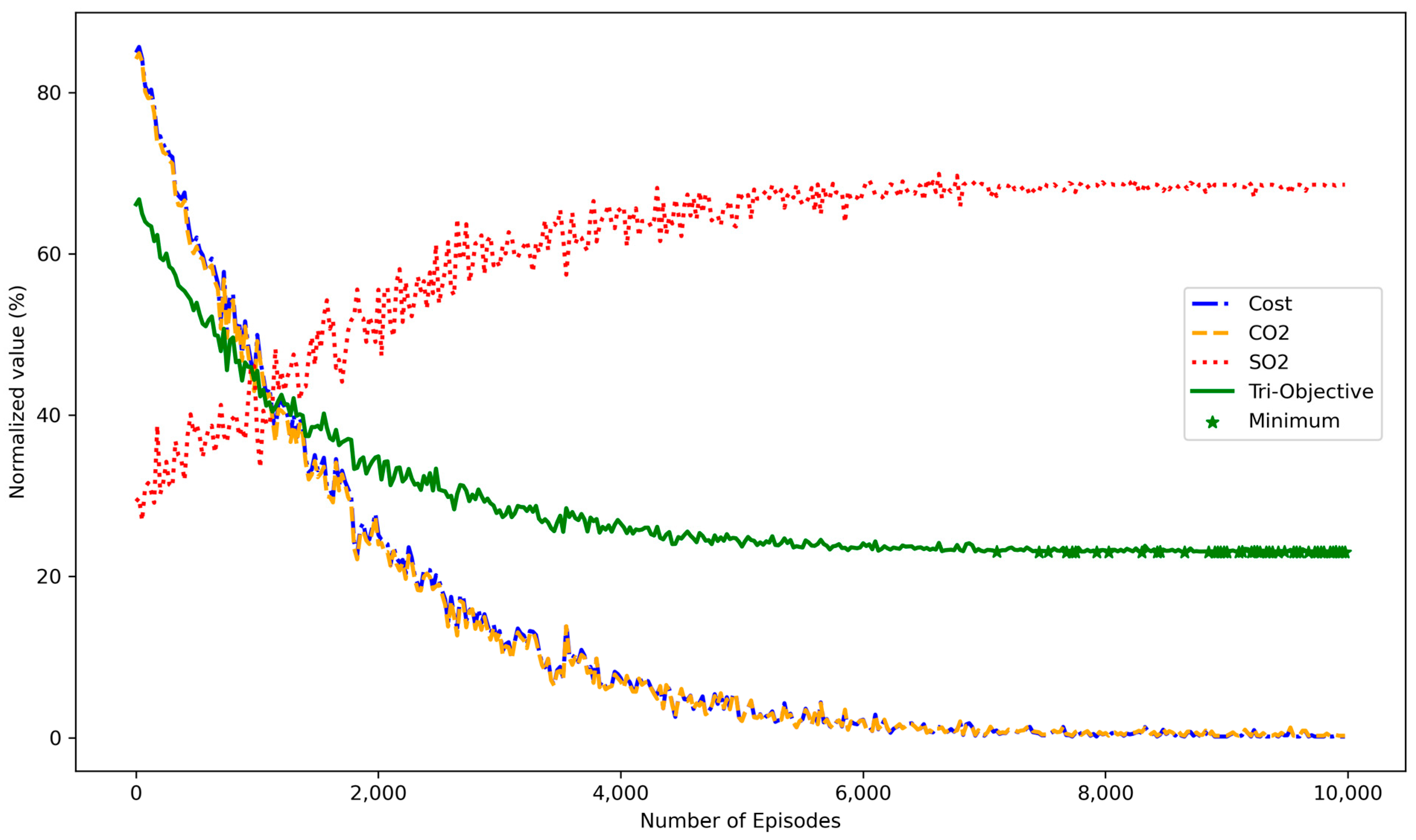{kind=link}
| Reference | Objective | Units | Constraints | VPEs | |||
|---|---|---|---|---|---|---|---|
| Production Capacity | Operating Duration | Ramp Rates | Reserve | ||||
| [43] | Single | 4 | Yes | No | No | No | No |
| [44] | Single | 3 | Yes | No | No | No | No |
| [47] | Single | 8 | Yes | Yes | No | No | No |
| [12] | Single | 10 | Yes | Yes | No | No | No |
| [45] | Single | 10 | Yes | Yes | Yes | Yes | No |
| [29] | Single | 10 | Yes | No | No | No | Yes |
| [5] | Single | 5 | Yes | Yes | Yes | No | No |
| [40] | Single | 30 | Yes | Yes | No | No | No |
| [46] | Single | 30 | Yes | Yes | No | No | No |
| [42] | Single | 100 | Yes | Yes | No | Yes | No |
- The primary contribution is the introduction of a pioneering MADRL-based optimization algorithm that can solve single- to tri-objective power scheduling problems. The algorithm harnesses the power of MADRL to decisively confront the intricate challenges of MOPS.
- Unlike existing methods, the proposed algorithm does not confine itself to a limited planning horizon and a fixed number of generating units. It also encompasses a comprehensive set of unit-specific (including ramp rates and VPEs) and system-level constraints such as reserve availability.
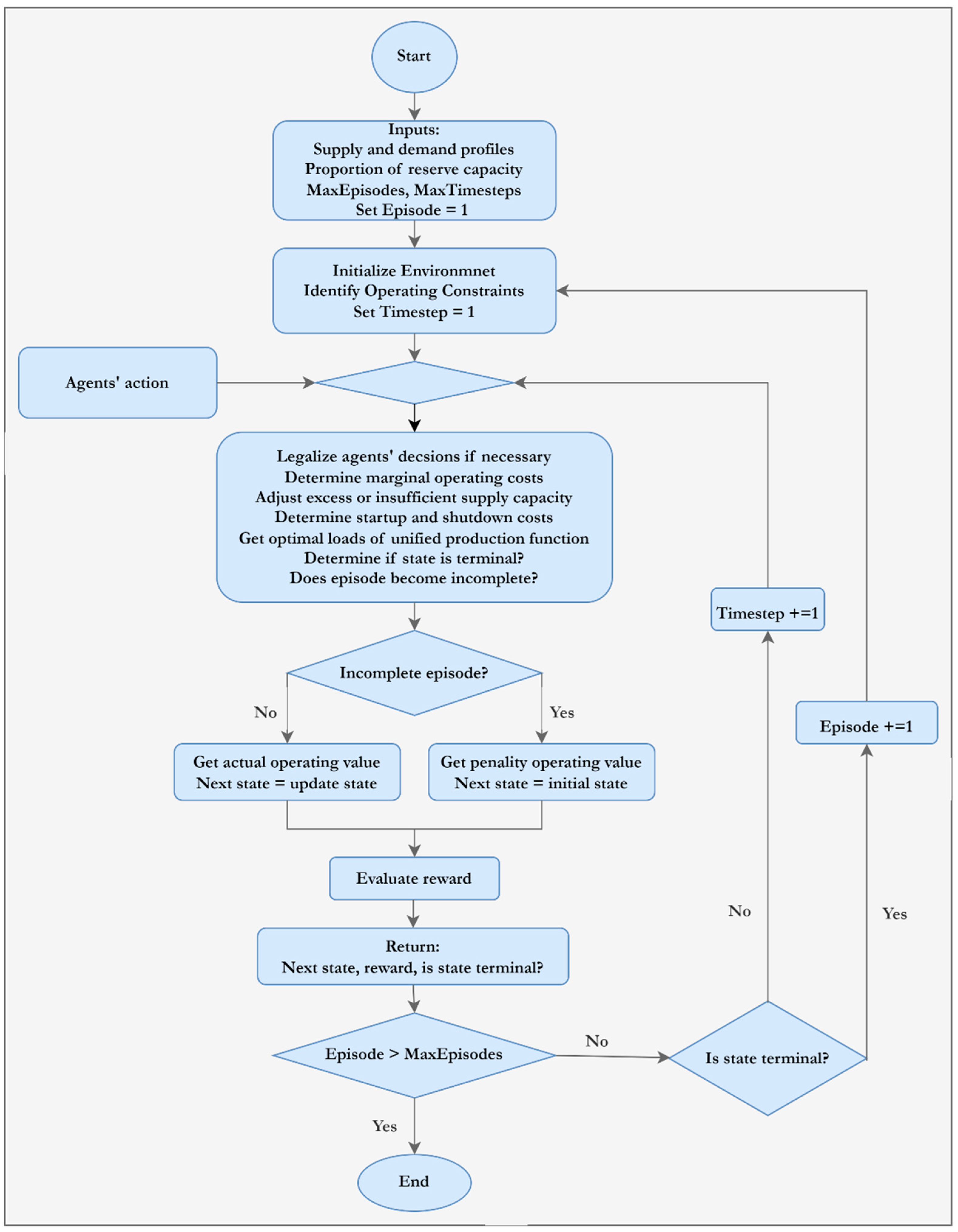
- Another distinctive contribution to our approach is developing a contextually adaptive multi-agent simulation environment. The environment is used to decompose the MOPS problem into sequential MDPs. It can contextually correct agents’ illegal decisions and adjust excess and shortages of supply capacities. By accelerating agents’ learning and reducing model training time, the simulation environment may significantly enhance the efficiency of the entire optimization process.
- The simulation environment is not specifically tailored to train a specific RL model but is model agnostic. This adaptability allows researchers and practitioners to train and explore diverse types of RL models for solving power scheduling.
- Unlike traditional models with exponential dimensionality (i.e., for generating units), the proposed algorithm has linear dimensionality (i.e., ). This characteristic underscores its scalability and better performance to handle large-scale problems compared to existing methods.
- The algorithm’s programming code has been verified by Code Ocean for quality and computational reproducibility (https://doi.org/10.24433/CO.9235622.v1) and published as an open-source software package [48]. This initiative may facilitate results replication and foster a spirit of experimentation and further extensions within the research community.
2. MOPS Problem Formulation
2.1. Cost Objective Function
2.2. Emission Objective Function
2.3. MOPS Objective Function
2.3.1. Constraints
| Power production capacities: | |
| Maximum ramp rates: | |
| Minimum operating durations: | |
| Supply and demand balance: | |
| Minimum reserve constraint: |
2.3.2. Cost-to-Emission Conversion Factors
2.3.3. Sensitivity Analyses for Weights
3. Proposed Methodology
3.1. Multi-Agent Simulation Environment
- If there is a shortage of capacity (i.e., ), unconstrained OFF units are turned ON () in the increasing order of until the demand, including reserve, is met (i.e., ) or no unconstrained OFF unit remains.
- If there is excess capacity (i.e., ), unconstrained ON units are turned OFF () in the decreasing order of until supply matches demand, including reserve (i.e., ) or no unconstrained ON units are left.
| Algorithm 1. Pseudocode for simulating power scheduling as MDPs |
 |
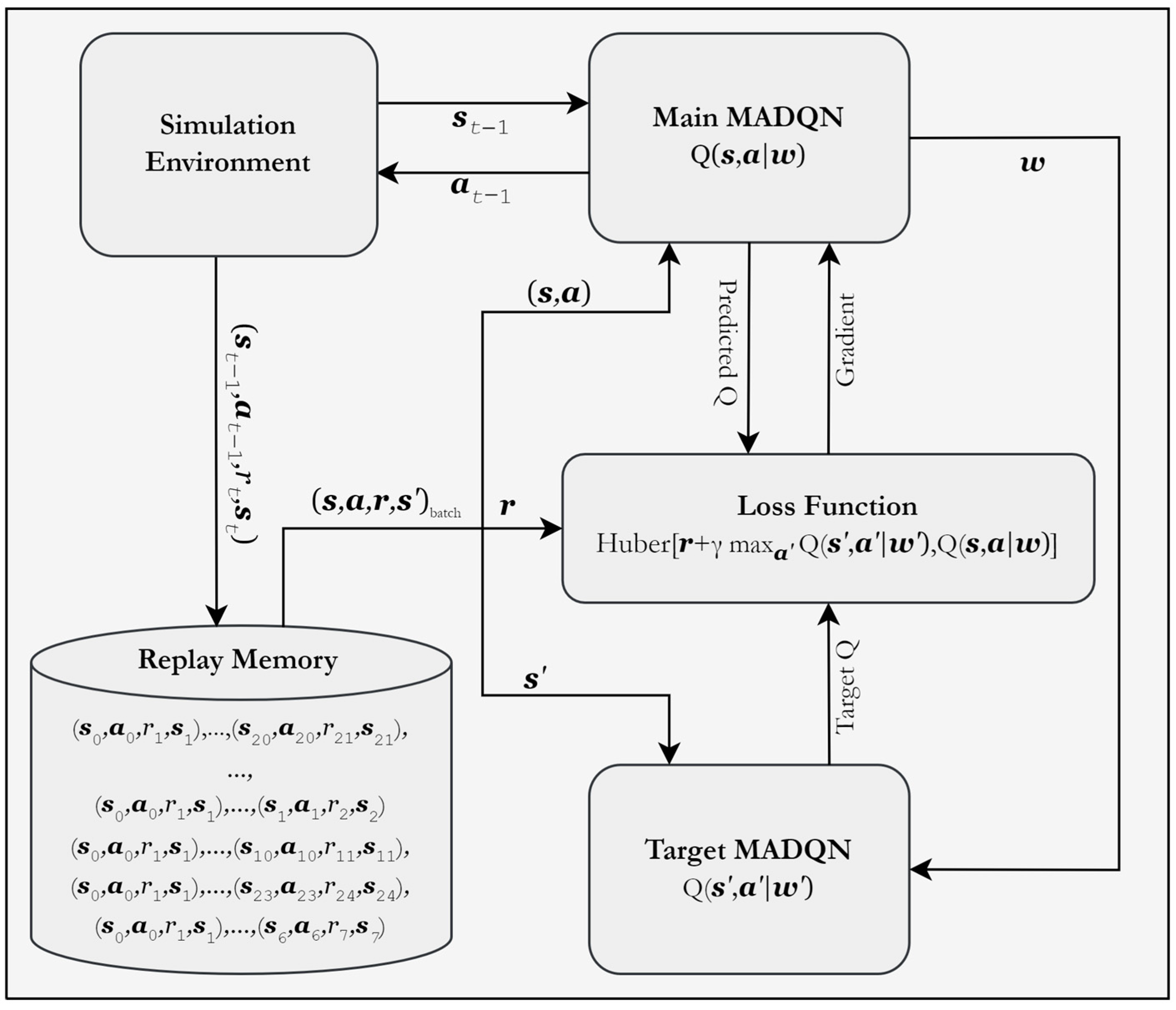
3.2. Multi-Agent Deep Q-Network (MADQN)
3.2.1. Model Architecture
3.2.2. Experience Relay
3.2.3. Loss Function and Parameter Updates
4. Practical Applications
4.1. Experimental Settings
4.1.1. Specifications of Generating Units
4.1.2. Parameters and Hyperparameters
4.1.3. MADQN Model Configurations
4.2. Comparative Results
4.2.1. Test System I: Bi-Objective Problem without Ramp Rate Constraints and No VPEs
4.2.2. Test System II: Ramp Rates Constrained Bi-Objective Problem without VPEs
4.2.3. Test System III: Bi-Objective Problem with VPEs and No Ramp Rates
4.2.4. Test System IV: Bi-Objective Problem with VPEs and Ramp Rate Constraints
4.2.5. Test System V: Tri-Objective Problem without VPEs and No Ramp Rates
4.2.6. Test System VI: Ramp Rates Constrained Tri-Objective Problem
4.2.7. Large Scale Test Systems: Test Systems VII–XXVI
4.3. Training Convergence
5. Concluding Remarks
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Nomenclature
| Indices | |
| : | Number of periods in a scheduling horizon. |
| : | Number of power-generating units. |
| : | Number of types of emissions |
| : | Indices of all periods, . |
| : | Indices of all units, . |
| : | Indices of all objectives, |
| Supply and Demand Profiles | |
| : | Maximum, minimum capacity of unit (MW). |
| : | Maximum ramp up, ramp down unit (MW). |
| : | Minimum up-, down-time duration of the unit (hour). |
| : | Number of cold start periods (hour) |
| : | Hot, cold start cost ($) |
| : | Power output of unit at period (MW). |
| : | Online, offline duration of unit at period (hour). |
| : | Operating (online/offline) duration of unit at period (hour). |
| : | Demand at period (MW). |
| : | Proportion of demand for reserve capacity. |
| Cost Functions | |
| : | Total operating cost ($) in the entire planning horizon. |
| : | Total operating cost ($) at period . |
| ,,: | Startup, production, shutdown cost ($) of unit at period . |
| Quadratic, linear, constant cost parameters of unit . | |
| Valve point cost parameters of the unit . | |
| Emission Functions | |
| : | Total operating emissions (lbs) in the entire planning horizon. |
| : | Total operating emissions (lbs) at period . |
| ,,: | Startup, production, shutdown emission (lbs) of unit at period . |
| Quadratic, linear, constant emission parameters of unit . | |
| Valve point emission parameters of unit . | |
| Quadratic, linear, constant CO2 parameters of unit . | |
| Quadratic, linear, constant SO2 parameters of unit . | |
| Other Notations | |
| : | Expected value. |
| : | Set of real numbers. |
| : | Indicator function. |
References
- Huang, Y.; Pardalos, P.; Zheng, Q. Electrical power unit commitment: Deterministic and two-stage stochastic programming models and algorithms. In Springer Briefs in Energy; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Goyal, S.; Singh, J.; Saraswat, A.; Kanwar, N.; Shrivastava, M.; Mahela, O. Economic Load Dispatch with Emission and Line Constraints using Biogeography Based Optimization Technique. In Proceedings of the 2020 International Conference on Intelligent Engineering and Management (ICIEM), London, UK, 17–19 June 2020. [Google Scholar]
- Rex, C.R.E.S.; Marsaline, B.M. State of art in combined economic and emission dispatch. Middle-East J. Sci. Res. 2017, 25, 56–64. [Google Scholar]
- Montero, L.; Bello, A.; Reneses, J. Review on the Unit Commitment Problem: Approaches, Techniques, and Resolution Methods. Energies 2022, 15, 1296. [Google Scholar] [CrossRef]
- Qin, J.; Yu, N.; Gao, Y. Solving Unit Commitment Problems with Multi-step Deep Reinforcement Learning. In Proceedings of the 2021 IEEE International Conference on Communications, Control, and Computing Technologies for Smart Grids (SmartGridComm), Virtually, 25–28 October 2021. [Google Scholar]
- de Oliveira, L.; da Silva Junior, I.; Abritta, R. Search Space Reduction for the Thermal Unit Commitment Problem through a Relevance Matrix. Energies 2022, 15, 7153. [Google Scholar] [CrossRef]
- Bendotti, P.; Fouilhoux, P.; Rottner, C. On the complexity of the unit commitment problem. Ann. Oper. Res. 2019, 274, 119–130. [Google Scholar] [CrossRef]
- Roy, P.; Roy, P.; Chakrabarti, A. Modified shuffled frog leaping algorithm with genetic algorithm crossover for solving economic load dispatch problem with valve-point effect. Appl. Soft Comput. 2013, 13, 4244–4252. [Google Scholar] [CrossRef]
- Wang, T.; He, X.; Huang, T.; Li, C.; Zhang, W. Collective neurodynamic optimization for economic emission dispatch problem considering valve point effect in microgrid. Neural Netw. 2017, 93, 126–136. [Google Scholar] [CrossRef]
- Wang, C.; Shahidehpour, S. Effects of ramp rate Limits on unit commitment and Economic Dispatch. IEEE Trans. Power Syst. 1993, 8, 1341–1350. [Google Scholar] [CrossRef]
- Zaoui, S.; Belmadani, A. Solution of combined economic and emission dispatch problems of power systems without penalty. Appl. Artif. Intell. 2022, 36, 1976092. [Google Scholar] [CrossRef]
- Jasmin, E.; Ahamed, T.; Remani, T. A function approximation approach to reinforcement learning for solving unit commitment problem with photo voltaic sources. In Proceedings of the 2016 IEEE International Conference on Power Electronics, Drives and Energy Systems, Kerala, India, 14–17 December 2016. [Google Scholar]
- Park, H. A Unit Commitment Model Considering Feasibility of Operating Reserves under Stochastic Optimization Framework. Energies 2022, 15, 6221. [Google Scholar] [CrossRef]
- Feng, Z.K.; Niu, W.J.; Wang, W.C.; Zhou, J.Z.; Cheng, C.T. A mixed integer linear programming model for unit commitment of thermal plants with peak shaving operation aspect in regional power grid lack of flexible hydropower energy. Energy 2019, 175, 618–629. [Google Scholar] [CrossRef]
- Lin, S.; Wu, H.; Liu, J.; Liu, W.; Liu, Y.L.M. A Solution Method for Many-Objective Security-Constrained Unit Commitment Considering Flexibility. Front. Energy Res. 2022, 10, 857520. [Google Scholar] [CrossRef]
- Srikanth, K.; Panwar, L.; Panigrahi, B.; Herrera-Viedma, E.; Sangaiah, A.; Wang, G. Meta-heuristic framework: Quantum inspired binary grey wolf optimizer for unit commitment problem. Comput. Electr. Eng. 2018, 70, 243–260. [Google Scholar] [CrossRef]
- Yang, Z.; Li, K.; Niu, Q.; Xue, Y. A novel parallel-series hybrid meta-heuristic method for solving a hybrid unit commitment problem. Knowl. Based Syst. 2017, 134, 13–30. [Google Scholar] [CrossRef]
- Kigsirisin, S.; Miyauchi, H. Short-Term Operational Scheduling of Unit Commitment Using Binary Alternative Moth-Flame Optimization. IEEE Access 2021, 9, 12267–12281. [Google Scholar] [CrossRef]
- Trivedi, A.; Srinivasan, D.; Biswas, S.; Reindl, T. Hybridizing genetic algorithm with differential evolution for solving the unit commitment scheduling problem. Swarm Evol. Comput. 2015, 23, 50–64. [Google Scholar] [CrossRef]
- Zhu, X.; Zhao, S.; Yang, Z.; Zhang, N.; Xu, X. A parallel meta-heuristic method for solving large scale unit commitment considering the integration of new energy sectors. Energy 2022, 238, 121829. [Google Scholar] [CrossRef]
- Basu, M. Economic environmental dispatch using multi-objective differential evolution. Appl. Soft Comput. 2011, 11, 2845–2853. [Google Scholar] [CrossRef]
- Ponciroli, R.; Stauff, N.; Ramsey, J.; Ganda, F.; Vilim, R. An improved genetic algorithm approach to the unit commitment/economic dispatch problem. IEEE Trans. Power Syst. 2020, 35, 4005–4013. [Google Scholar] [CrossRef]
- Balasubramanian, K.; Santhi, R. Best Compromised Schedule for Multi-Objective Unit Commitment Problems. Indian J. Sci. Technol. 2016, 9, 2. [Google Scholar] [CrossRef]
- Roy, P.; Sarkar, R. Solution of unit commitment problem using quasi-oppositional teaching learning based algorithm. Electr. Power Energy Syst. 2014, 60, 96–106. [Google Scholar] [CrossRef]
- Datta, D. Unit commitment problem with ramp rate constraint using a binary-real-coded genetic algorithm. Appl. Soft Comput. 2013, 13, 3873–3883. [Google Scholar] [CrossRef]
- Reddy, S.; Kumar, R.; Panigrahi, B. Binary Bat Search Algorithm for Unit Commitment Problem in Power system. In Proceedings of the IEEE International WIE Conference on Electrical and Computer Engineering (WIECON-ECE), Dehradun, India, 14–16 December 2017. [Google Scholar]
- Khunkitti, S.; Watson, N.; Chatthaworn, R.; Premrudeepreechacharn, S.; Siritaratiwat, A. An Improved DA-PSO Optimization Approach for Unit Commitment Problem. Energies 2019, 12, 2335. [Google Scholar] [CrossRef]
- Panwar, L.; Reddy, S.; Verma, A.; Panigrahi, B.; Kumar, R. Binary grey wolf optimizer for large scale unit commitment problem. Swarm Evol. Comput. 2018, 38, 251–266. [Google Scholar] [CrossRef]
- Li, F.; Qin, J.; Zheng, W. Distributed Q-learning-based online optimization algorithm for unit commitment and dispatch in smart grid. IEEE Trans. Cybern. 2020, 50, 4146–4156. [Google Scholar] [CrossRef]
- Reddy, S.P.L.; Panigrahi, B.; Kumar, R. Solution to unit commitment in power system operation planning using binary coded modified moth flame optimization algorithm (BMMFOA): A flame selection based computational technique. J. Comput. Sci. 2018, 25, 298–317. [Google Scholar]
- Nassef, A.A.M.; Maghrabie, H.; Baroutaji, A. Review of Metaheuristic Optimization Algorithms for Power. Sustainability 2023, 15, 9434. [Google Scholar] [CrossRef]
- Kumar, V.; Kumar, D. Binary whale optimization algorithm and its application to unit commitment problem. Neural Comput. Appl. 2020, 32, 2095–2123. [Google Scholar] [CrossRef]
- Zhai, Y.; Liao, X.; Mu, N.; Le, J. A two-layer algorithm based on PSO for solving unit commitment problem. Soft Comput. 2020, 24, 9161–9178. [Google Scholar] [CrossRef]
- Rameshkumar, J.; Ganesan, S.; Abirami, M.; Subramanian, S. Cost, emission and reserve pondered predispatch of thermal power generating units coordinated with real coded grey wolf optimization. IET Gener. Transm. Distrib. 2016, 10, 972–985. [Google Scholar] [CrossRef]
- Bora, T.C.; Mariani, V.C.; dos Santos Coelho, L. Multiobjective optimization of the environmental-economic dispatch with reinforcement learning based on non-dominated sorting genetic algorithm. Appl. Therm. Eng. 2019, 146, 688–700. [Google Scholar] [CrossRef]
- Yang, D.; Zhou, X.; Yang, Z.; Guo, Y.; Niu, Q. Low Carbon Multi-Objective Unit Commitment Integrating Renewable Generations. IEEE Access 2020, 8, 207768–207778. [Google Scholar] [CrossRef]
- Trivedi, A.; Srinivasan, D.; Pal, K.; Saha, C.; Reindl, T. Enhanced Multiobjective Evolutionary Algorithm based on Decomposition for Solving the Unit Commitment Problem. IEEE Trans. Ind. Inform. 2009, 11, 1346–1357. [Google Scholar] [CrossRef]
- Wang, B.; Wang, S.; Zhou, X.; Watada, J. Two-Stage Multi-Objective Unit Commitment Optimization Under Hybrid Uncertainties. IEEE Trans. Power Syst. 2015, 31, 2266–2277. [Google Scholar] [CrossRef]
- Wang, B.; Wang, S.; Zhou, X.; Watada, J. Multi-objective unit commitment with wind penetration and emission concerns under stochastic and fuzzy uncertainties. Energy 2016, 111, 18–31. [Google Scholar] [CrossRef]
- de Mars, P.; O’Sullivan, A. Applying reinforcement learning and tree search to the unit commitment problem. Appl. Energy 2021, 302, 117519. [Google Scholar] [CrossRef]
- Rajasomashekar, S.; Aravindhababu, P. Biogeography based optimization technique for best compromise solution of economic emission dispatch. Swarm Evol. Comput. 2012, 7, 47–57. [Google Scholar] [CrossRef]
- Ebrie, A.; Paik, C.; Chung, Y.; Kim, Y. Environment-Friendly Power Scheduling Based on Deep Contextual Reinforcement Learning. Energies 2023, 16, 5920. [Google Scholar] [CrossRef]
- Jasmin, E.; Ahamed, T.; Jagathy, R. Reinforcement learning solution for unit commitment problem through pursuit method. In Proceedings of the 2009 International Conference on Advances in Computing, Control, and Telecommunication Technologies, Kerala, India, 28–29 December 2009. [Google Scholar]
- Rajua, L.; Milton, R.; Suresha, S.; Sankara, S. Reinforcement Learning in Adaptive Control of Power System Generation. Procedia Comput. Sci. 2015, 46, 202–209. [Google Scholar] [CrossRef]
- Navin, N.; Sharma, R. A fuzzy reinforcement learning approach to thermal unit commitment problem. Neural Comput. Appl. 2019, 31, 737–750. [Google Scholar] [CrossRef]
- de Mars, P.; O’Sullivan, A. Reinforcement learning and A* search for the unit commitment problem. Energy AI 2022, 9, 100179. [Google Scholar] [CrossRef]
- Dalal, G.; Mannor, S. Reinforcement learning for the unit commitment problem. In Proceedings of the 2015 IEEE Eindhoven PowerTech, Eindhoven, The Netherlands, 29 June–2 July 2015. [Google Scholar]
- Ebrie, A.; Kim, Y. pymops: A multi-agent simulation-based optimization package for power scheduling. Softw. Impacts 2024, 19, 1006160. [Google Scholar] [CrossRef]
- Ongsakul, W.; Petcharaks, N. Unit commitment by enhanced adaptive Lagrangian relaxation. IEEE Trans. Power Syst. 2004, 19, 620–628. [Google Scholar] [CrossRef]
- Walters, D.; Sheble, G. Genetic algorithm solution of economic dispatch with valve point loading. IEEE Trans. Power Syst. 1993, PAS 97, 1325–1332. [Google Scholar] [CrossRef]
- Guesmi, T.; Farah, A.; Marouani, I.; Alshammari, B.; Abdallah, H. Chaotic sine–cosine algorithm for chance-constrained economic emission dispatch problem including wind energy. IET Renew. Power Gener. 2020, 14, 1801–1808. [Google Scholar] [CrossRef]
- Li, L.-L.; Lou, J.-L.; Tseng, M.-L.; Lim, M.; Tan, R. A hybrid dynamic economic environmental dispatch model for balancing operating costs and pollutant emissions in renewable energy: A novel improved mayfly algorithm. Expert Syst. Appl. 2022, 203, 117411. [Google Scholar] [CrossRef]
- Dey, S.; Dash, D.; Basu, M. Application of NSGA-II for environmental constraint economic dispatch of thermal-wind-solar power system. Renew. Energy Focus 2022, 43, 239–245. [Google Scholar]
- Li, Y.; Pedroni, N.; Zio, E. A memetic evolutionary multiobjective optimization method for environmental power unit commitment. IEEE Trans. Power Syst. 2013, 28, 2660–2669. [Google Scholar] [CrossRef]
- Sutton, R.; Barto, A. Reinforcement Learning, An Introduction; The MIT Press: London, UK, 2018. [Google Scholar]
- Virtanen, P.; Gommers, R.; Oliphant, T.S. SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python. Nat. Methods 2020, 17, 261–272. [Google Scholar] [CrossRef] [PubMed]
- Adam, S.; Busoniu, L.; Babuska, R. Experience Replay for Real-Time Reinforcement Learning Control. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2012, 42, 201–212. [Google Scholar] [CrossRef]
- Attaviriyanupap, P.; Kita, H.; Tanaka, E.; Hasegawa, J. A Hybrid EP and SQP for Dynamic Economic Dispatch with Nonsmooth Fuel Cost Function. IEEE Trans. Power Syst. 2002, 17, 2. [Google Scholar] [CrossRef]
- Truby, J. Thermal Power Plant Economics and Variable Renewable Energies: A Model-Based Case Study for Germany; International Energy Agency: Paris, France, 2014. [Google Scholar]






| U1 | U2 | U3 | U4 | U5 | U6 | U7 | U8 | U9 | U10 | ||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Without VPEs | 1.12 | 1.12 | 1.18 | 1.72 | 1.32 | 1.60 | 1.42 | 0.63 | 0.64 | 0.63 | |
| 1.26 | 1.31 | 1.97 | 1.47 | 1.36 | 1.80 | 2.00 | 2.58 | 2.35 | 3.42 | ||
| 4.64 | 4.98 | 4.00 | 3.74 | 5.23 | 3.51 | 7.16 | 2.64 | 2.63 | 2.67 | ||
| With VPEs | 1.09 | 1.11 | 1.15 | 1.64 | 1.29 | 1.53 | 1.42 | 0.63 | 0.62 | 0.60 |
| Test System | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| I | 0.35 | 0.36 | 0.37 | 0.38 | 0.39 | 0.40 | 0.41 | 0.42 | 0.43 | 0.44 | |
| 0.878007 | 0.890443 | 0.901638 | 0.912586 | 0.921031 | 0.928662 | 0.935648 | 0.942570 | 0.949212 | 0.955643 | ||
| 0.207331 | 0.273058 | 0.252767 | 0.232082 | 0.215422 | 0.199729 | 0.184779 | 0.169305 | 0.153849 | 0.138279 | ||
| 0.009882 | 0.010593 | 0.010510 | 0.010422 | 0.010347 | 0.010274 | 0.010201 | 0.010123 | 0.010043 | 0.009960 | ||
| II | 0.37 | 0.38 | 0.39 | 0.40 | 0.41 | 0.42 | 0.43 | 0.44 | 0.45 | 0.46 | |
| 0.898268 | 0.909701 | 0.917872 | 0.925332 | 0.932428 | 0.939034 | 0.945612 | 0.951902 | 0.957516 | 0.953013 | ||
| 0.161389 | 0.236437 | 0.220693 | 0.205621 | 0.190679 | 0.176148 | 0.161154 | 0.146186 | 0.132335 | 0.135774 | ||
| 0.009876 | 0.010682 | 0.010611 | 0.01054 | 0.010467 | 0.010393 | 0.010315 | 0.010234 | 0.010157 | 0.010147 | ||
| III | 0.30 | 0.36 | 0.37 | 0.40 | 0.45 | 0.48 | 0.62 | 0.91 | 0.92 | 0.95 | |
| 0.000001 | 0.000001 | 0.040960 | 0.075624 | 0.083236 | 0.098914 | 0.252296 | 0.207296 | 0.306373 | 0.260789 | ||
| 0.311485 | 0.301039 | 0.273215 | 0.237354 | 0.220239 | 0.218529 | 0.058457 | 0.109696 | 0.011730 | 0.043777 | ||
| 0.009821 | 0.009492 | 0.009906 | 0.009868 | 0.009569 | 0.010009 | 0.009798 | 0.009995 | 0.010030 | 0.009603 | ||
| IV | 0.42 | 0.54 | 0.68 | 0.69 | 0.70 | 0.73 | 0.87 | 0.96 | 0.97 | 0.98 | |
| 0.144462 | 0.110142 | 0.213309 | 0.216820 | 0.186339 | 0.208077 | 0.196714 | 0.222655 | 0.225096 | 0.164261 | ||
| 0.087651 | 0.115980 | 0.013510 | 0.015474 | 0.000001 | 0.000001 | 0.000001 | 0.006746 | 0.000001 | 0.000001 | ||
| 0.006831 | 0.006655 | 0.006676 | 0.006837 | 0.005484 | 0.006124 | 0.005790 | 0.006752 | 0.006625 | 0.004834 |
| Test System | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| V | 0.07 | 0.13 | 0.15 | 0.17 | 0.31 | 0.43 | 0.46 | 0.47 | 0.56 | 0.61 | |
| 0.67 | 0.60 | 0.57 | 0.52 | 0.38 | 0.21 | 0.22 | 0.17 | 0.06 | 0.06 | ||
| 0.26 | 0.27 | 0.28 | 0.31 | 0.31 | 0.36 | 0.32 | 0.36 | 0.38 | 0.33 | ||
| 0.877544 | 0.874737 | 0.876852 | 0.867023 | 0.876270 | 0.866799 | 0.882510 | 0.869905 | 0.863371 | 0.884918 | ||
| 0.515861 | 0.518307 | 0.525821 | 0.513806 | 0.549959 | 0.560309 | 0.583100 | 0.572289 | 0.579697 | 0.612661 | ||
| 0.617123 | 0.625220 | 0.620835 | 0.643178 | 0.624359 | 0.644600 | 0.610428 | 0.637967 | 0.650002 | 0.603679 | ||
| 0.005176 | 0.005175 | 0.005211 | 0.005130 | 0.005298 | 0.005302 | 0.005445 | 0.005358 | 0.005361 | 0.005563 | ||
| VI | 0.03 | 0.21 | 0.24 | 0.41 | 0.43 | 0.44 | 0.45 | 0.49 | 0.52 | 0.52 | |
| 0.76 | 0.52 | 0.47 | 0.28 | 0.21 | 0.23 | 0.19 | 0.15 | 0.12 | 0.12 | ||
| 0.21 | 0.26 | 0.29 | 0.31 | 0.36 | 0.33 | 0.35 | 0.36 | 0.36 | 0.36 | ||
| 0.890529 | 0.885126 | 0.878897 | 0.882360 | 0.866862 | 0.878171 | 0.871210 | 0.870520 | 0.872000 | 0.871944 | ||
| 0.530925 | 0.548683 | 0.542729 | 0.575160 | 0.561762 | 0.573672 | 0.569808 | 0.576117 | 0.582108 | 0.583029 | ||
| 0.580650 | 0.601661 | 0.617481 | 0.610705 | 0.644421 | 0.620414 | 0.635385 | 0.636538 | 0.633200 | 0.633290 | ||
| 0.005296 | 0.005342 | 0.005297 | 0.005431 | 0.005323 | 0.005410 | 0.005369 | 0.005390 | 0.005418 | 0.005421 |
| Test System | Objectives | Units | Nodes | -Decay Rate | Replay Memory | Training Episodes | ||
|---|---|---|---|---|---|---|---|---|
| Input | Hidden | Output | ||||||
| I | Bi-objective | 10 | 12 | 64 | 20 | 0.999 | 64 | 8000 |
| II | Bi-objective | 10 | 12 | 64 | 20 | 0.999 | 64 | 8000 |
| III | Bi-objective | 10 | 12 | 64 | 20 | 0.999 | 64 | 8000 |
| IV | Bi-objective | 10 | 12 | 64 | 20 | 0.999 | 64 | 8000 |
| V | Tri-objective | 10 | 12 | 64 | 20 | 0.9991 | 64 | 10,000 |
| VI | Tri-objective | 10 | 12 | 64 | 20 | 0.9991 | 64 | 10,000 |
| VII–X | Bi-objective | 20 | 22 | 64 | 40 | 0.999 | 64 | 8000 |
| XI–XIV | Bi-objective | 40 | 42 | 128 | 80 | 0.9993 | 128 | 12,000 |
| XV–XVIII | Bi-objective | 60 | 62 | 128 | 120 | 0.9993 | 128 | 12,000 |
| XIX–XXII | Bi-objective | 80 | 82 | 256 | 160 | 0.9994 | 256 | 15,000 |
| XXIII–XXVI | Bi-objective | 100 | 102 | 256 | 200 | 0.9994 | 256 | 15,000 |
(Hour) | Commitments | Optimal Loads (MW) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1100000000 | 375.8 | 324.2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 30.0 |
| 2 | 1100000000 | 400.6 | 349.4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 21.3 |
| 3 | 1100100000 | 405.5 | 354.3 | 0 | 0 | 90.2 | 0 | 0 | 0 | 0 | 0 | 26.1 |
| 4 | 1100100000 | 442.5 | 391.7 | 0 | 0 | 115.9 | 0 | 0 | 0 | 0 | 0 | 12.8 |
| 5 | 1101100000 | 412.9 | 361.8 | 0 | 130.0 | 95.4 | 0 | 0 | 0 | 0 | 0 | 20.2 |
| 6 | 1111100000 | 401.8 | 350.5 | 130.0 | 130.0 | 87.7 | 0 | 0 | 0 | 0 | 0 | 21.1 |
| 7 | 1111100000 | 420.3 | 369.2 | 130.0 | 130.0 | 100.5 | 0 | 0 | 0 | 0 | 0 | 15.8 |
| 8 | 1111100000 | 438.8 | 387.9 | 130.0 | 130.0 | 113.3 | 0 | 0 | 0 | 0 | 0 | 11.0 |
| 9 | 1111111000 | 455.0 | 409.4 | 130.0 | 130.0 | 128.0 | 21.7 | 25.9 | 0 | 0 | 0 | 15.2 |
| 10 | 1111111100 | 455.0 | 441.4 | 130.0 | 130.0 | 149.9 | 37.7 | 28.5 | 27.5 | 0 | 0 | 10.9 |
| 11 | 1111111110 | 455.0 | 454.1 | 130.0 | 130.0 | 158.7 | 44.1 | 29.5 | 29.6 | 18.9 | 0 | 10.8 |
| 12 | 1111111111 | 455.0 | 455.0 | 130.0 | 130.0 | 162.0 | 58.4 | 31.8 | 34.5 | 23.9 | 19.3 | 10.8 |
| 13 | 1111111100 | 455.0 | 441.4 | 130.0 | 130.0 | 149.9 | 37.7 | 28.5 | 27.5 | 0 | 0 | 10.9 |
| 14 | 1111111000 | 455.0 | 409.4 | 130.0 | 130.0 | 128.0 | 21.7 | 25.9 | 0 | 0 | 0 | 15.2 |
| 15 | 1111100000 | 438.8 | 387.9 | 130.0 | 130.0 | 113.3 | 0 | 0 | 0 | 0 | 0 | 11.0 |
| 16 | 1111100000 | 383.3 | 331.8 | 130.0 | 130.0 | 74.8 | 0 | 0 | 0 | 0 | 0 | 26.9 |
| 17 | 1111100000 | 364.8 | 313.1 | 130.0 | 130.0 | 62.0 | 0 | 0 | 0 | 0 | 0 | 33.2 |
| 18 | 1111100000 | 401.8 | 350.5 | 130.0 | 130.0 | 87.7 | 0 | 0 | 0 | 0 | 0 | 21.1 |
| 19 | 1111100000 | 438.8 | 387.9 | 130.0 | 130.0 | 113.3 | 0 | 0 | 0 | 0 | 0 | 11.0 |
| 20 | 1111111100 | 455.0 | 441.4 | 130.0 | 130.0 | 149.9 | 37.7 | 28.5 | 27.5 | 0 | 0 | 10.9 |
| 21 | 1111111000 | 455.0 | 409.3 | 130.0 | 130.0 | 128.0 | 21.7 | 25.9 | 0 | 0 | 0 | 15.2 |
| 22 | 1100111000 | 455.0 | 435.8 | 0 | 0 | 146.1 | 35.0 | 28.1 | 0 | 0 | 0 | 12.5 |
| 23 | 1100100000 | 424.0 | 373.0 | 0 | 0 | 103.1 | 0 | 0 | 0 | 0 | 0 | 19.1 |
| 24 | 1100000000 | 425.5 | 374.5 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 13.7 |
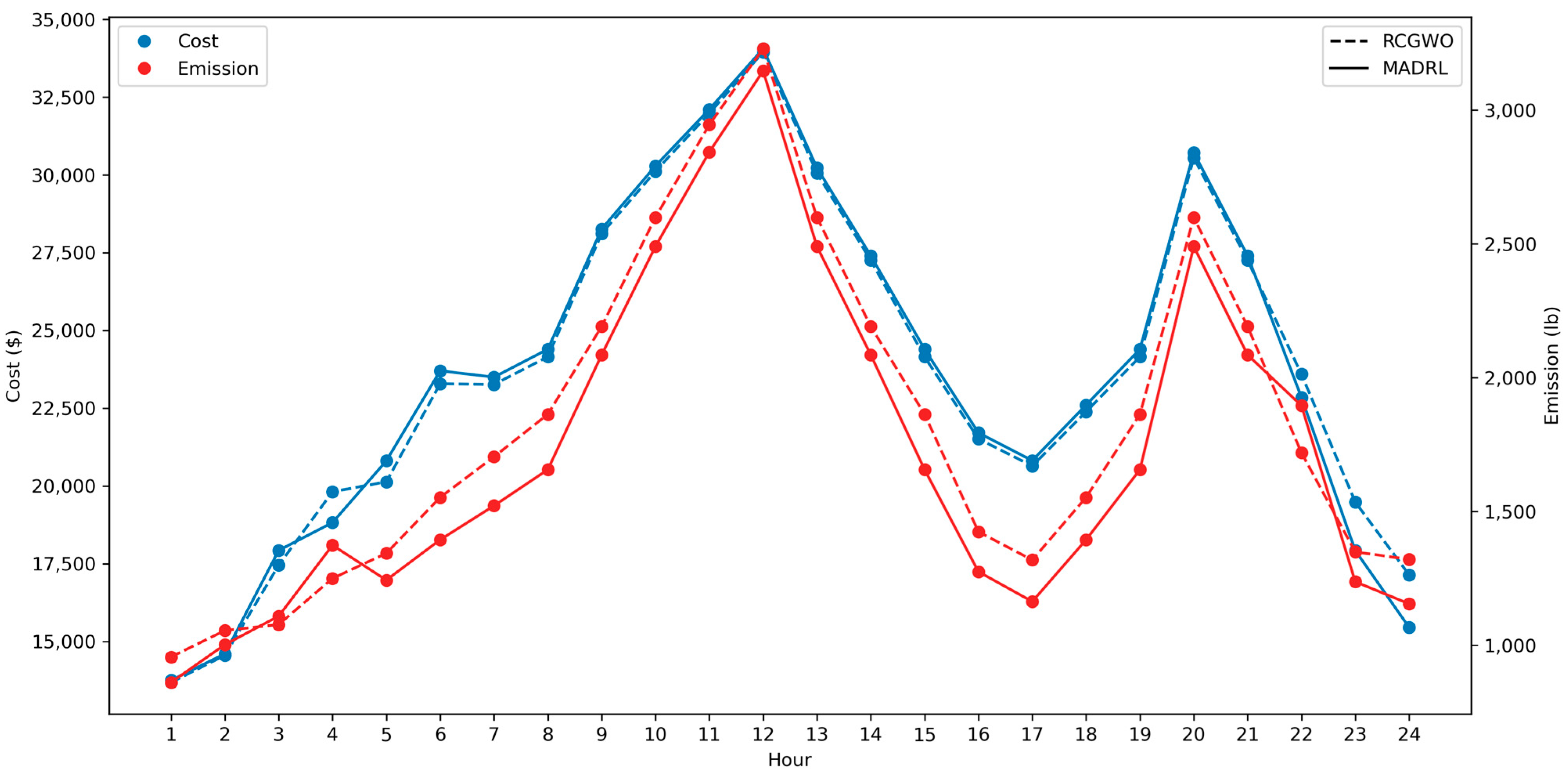
(Hour) | RCGWO [34] | MADRL | ||||||
|---|---|---|---|---|---|---|---|---|
| ($) | ($) | ($) | (lbs) | ($) | ($) | ($) | (lbs) | |
| 1 | 0 | 13,683.1 | 13,683.1 | 956.4 | 0 | 13,750.3 | 13,750.3 | 861.1 |
| 2 | 0 | 14,554.5 | 14,554.5 | 1055.0 | 0 | 14,601.2 | 14,601.2 | 1002.2 |
| 3 | 560 | 16,892.1 | 17,452.1 | 1077.4 | 900 | 17,027.5 | 17,927.5 | 1108.7 |
| 4 | 550 | 19,261.5 | 19,811.5 | 1249.8 | 0 | 18,821.2 | 18,821.2 | 1373.8 |
| 5 | 0 | 20,132.5 | 20,132.5 | 1343.8 | 560 | 20,246.3 | 20,806.3 | 1243.5 |
| 6 | 900 | 22,387.1 | 23,287.1 | 15,52.7 | 1100 | 22,601.0 | 23,701.0 | 1394.3 |
| 7 | 0 | 23,262.0 | 23,262.0 | 1704.2 | 0 | 23,496.6 | 23,496.6 | 1521.4 |
| 8 | 0 | 24,150.3 | 24,150.3 | 1863.1 | 0 | 24,394.0 | 24,394.0 | 1656.3 |
| 9 | 860 | 27,251.1 | 28,111.1 | 2191.3 | 860 | 27,399.1 | 28,259.1 | 2085.1 |
| 10 | 60 | 30,057.6 | 30,117.6 | 2599.2 | 60 | 30,226.2 | 30,286.2 | 2490.5 |
| 11 | 60 | 31,916.1 | 31,976.1 | 2945.2 | 60 | 32,045.6 | 32,105.6 | 2843.0 |
| 12 | 60 | 33,890.2 | 33,950.2 | 3229.4 | 60 | 33,995.6 | 34,055.6 | 3146.4 |
| 13 | 0 | 30,057.6 | 30,057.6 | 2599.2 | 0 | 30,226.2 | 30,226.2 | 2490.5 |
| 14 | 0 | 27,251.1 | 27,251.1 | 2191.3 | 0 | 27,399.1 | 27,399.1 | 2085.1 |
| 15 | 0 | 24,150.3 | 24,150.3 | 1863.1 | 0 | 24,394.0 | 24,394.0 | 1656.3 |
| 16 | 0 | 21,513.7 | 21,513.7 | 1424.2 | 0 | 21,707.3 | 21,707.3 | 1274.9 |
| 17 | 0 | 20,641.8 | 20,641.8 | 1318.6 | 0 | 20,815.4 | 20,815.4 | 1163.3 |
| 18 | 0 | 22,387.1 | 22,387.1 | 1552.7 | 0 | 22,601.0 | 22,601.0 | 1394.3 |
| 19 | 0 | 24,150.3 | 24,150.3 | 1863.1 | 0 | 24,394.0 | 24,394.0 | 1656.3 |
| 20 | 490 | 30,057.6 | 30,547.6 | 2599.2 | 490 | 30,226.2 | 30,716.2 | 2490.5 |
| 21 | 0 | 27,251.1 | 27,251.1 | 2191.3 | 0 | 27,399.1 | 27,399.1 | 2085.1 |
| 22 | 0 | 23,593.0 | 23,593.0 | 1719.6 | 0 | 22,847.1 | 22,847.1 | 1895.6 |
| 23 | 0 | 19,480.8 | 19,480.8 | 1348.9 | 0 | 17,923.5 | 17,923.5 | 1237.4 |
| 24 | 0 | 17,142.8 | 17,142.8 | 1321.1 | 0 | 15,453.1 | 15,453.1 | 1154.8 |
| Total | 3540 | 565,115.3 | 568,655.3 | 43,759.7 | 4090.0 | 563,990.6 | 568,080.6 | 41,310.4 |
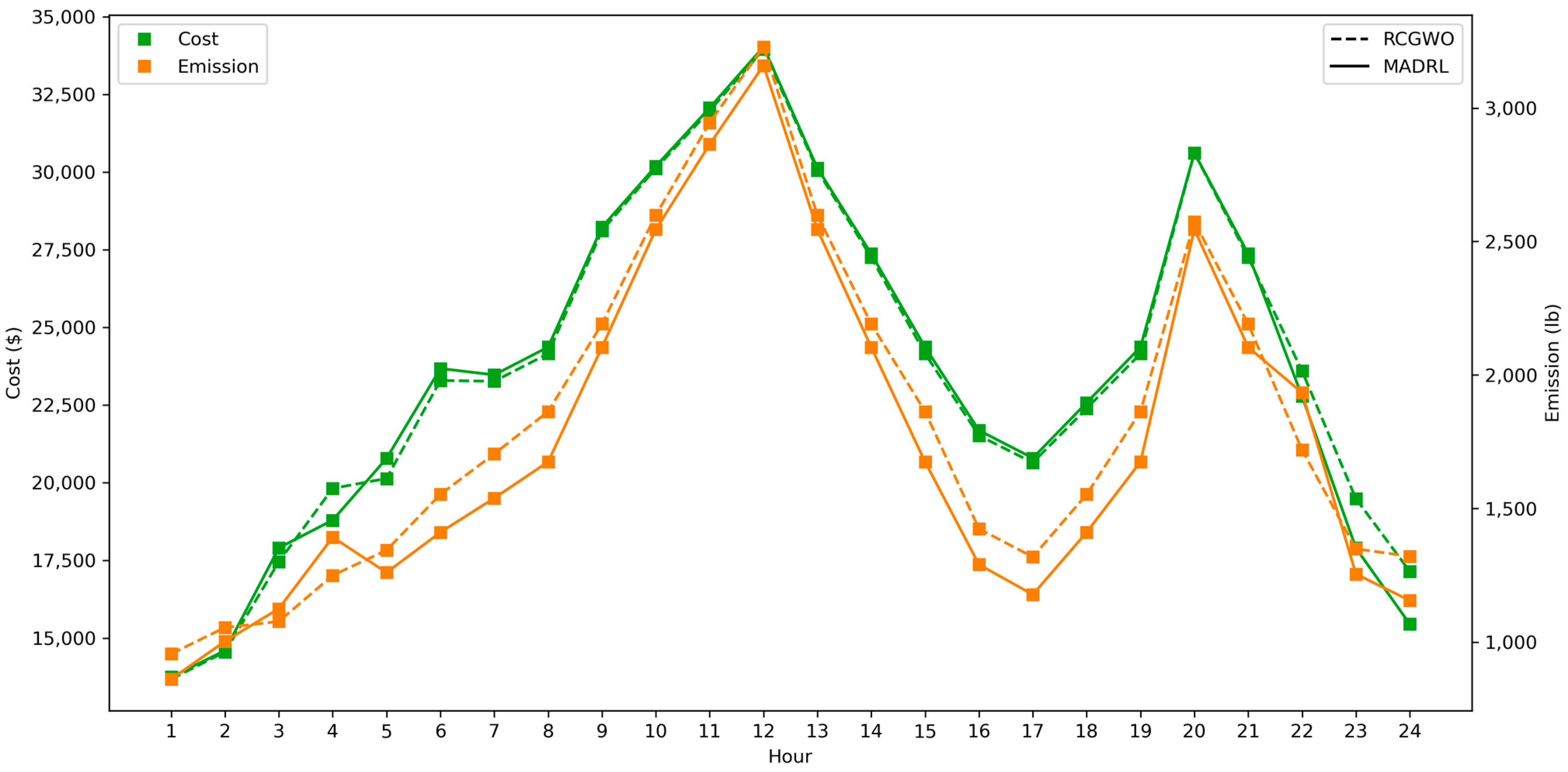
(Hour) | RCGWO [34] | MADRL | ||||||
|---|---|---|---|---|---|---|---|---|
| ($) | ($) | ($) | (lbs) | ($) | ($) | ($) | (lbs) | |
| 1 | 0 | 13,683.0 | 13,683.0 | 956.4 | 0 | 13,748.3 | 13,748.3 | 862.1 |
| 2 | 0 | 14,554.4 | 14,554.4 | 1055.0 | 0 | 14,599.3 | 14,599.3 | 1003.2 |
| 3 | 560 | 16,892.0 | 17,452.0 | 1077.3 | 900 | 16,998.9 | 17,898.9 | 1125.3 |
| 4 | 550 | 19,261.4 | 19,811.4 | 1249.8 | 0 | 18,789.8 | 18,789.8 | 1392.3 |
| 5 | 0 | 20,132.4 | 20,132.4 | 1343.8 | 560 | 20,217.1 | 20,777.1 | 1260.5 |
| 6 | 900 | 22,387.2 | 23,287.2 | 1552.7 | 1100 | 22,572.7 | 23,672.7 | 1410.7 |
| 7 | 0 | 23,262.1 | 23,262.1 | 1704.3 | 0 | 23,466.8 | 23,466.8 | 1538.7 |
| 8 | 0 | 24,150.1 | 24,150.1 | 1863.1 | 0 | 24,362.9 | 24,362.9 | 1674.5 |
| 9 | 860 | 27,251.3 | 28,111.3 | 2191.3 | 860 | 27,365.0 | 28,225.0 | 2103.9 |
| 10 | 60 | 30,057.8 | 30,117.8 | 2599.2 | 60 | 30,128.4 | 30,188.4 | 2545.2 |
| 11 | 60 | 31,916.3 | 31,976.3 | 2945.2 | 60 | 32,008.3 | 32,068.3 | 2864.0 |
| 12 | 60 | 33,890.4 | 33,950.4 | 3229.4 | 60 | 33,972.9 | 34,032.9 | 3159.7 |
| 13 | 0 | 30,057.8 | 30,057.8 | 2599.2 | 0 | 30,128.5 | 30,128.5 | 2545.2 |
| 14 | 0 | 27,251.3 | 27,251.3 | 2191.3 | 0 | 27,365.0 | 27,365.0 | 2103.9 |
| 15 | 0 | 24,150.1 | 24,150.1 | 1863.1 | 0 | 24,362.9 | 24,362.9 | 1674.5 |
| 16 | 0 | 21,513.8 | 21,513.8 | 1424.2 | 0 | 21,680.3 | 21,680.3 | 1290.4 |
| 17 | 0 | 20,642.0 | 20,642.0 | 1318.6 | 0 | 20,789.7 | 20,789.7 | 1177.9 |
| 18 | 0 | 22,387.2 | 22,387.2 | 1552.7 | 0 | 22,572.7 | 22,572.7 | 1410.7 |
| 19 | 0 | 24,150.1 | 24,150.1 | 1863.1 | 0 | 24,362.9 | 24,362.9 | 1674.5 |
| 20 | 490 | 30,124.9 | 30,614.9 | 2573.1 | 490 | 30,128.5 | 30,618.5 | 2545.2 |
| 21 | 0 | 27,251.3 | 27,251.3 | 2191.3 | 0 | 27,365.0 | 27,365.0 | 2103.9 |
| 22 | 0 | 23,593.1 | 23,593.1 | 1719.6 | 0 | 22,776.2 | 22,776.2 | 1933.8 |
| 23 | 0 | 19,481.0 | 19,481.0 | 1349.0 | 0 | 17,893.5 | 17,893.5 | 1254.9 |
| 24 | 0 | 17,142.9 | 17,142.9 | 1321.1 | 0 | 15,451.2 | 15,451.2 | 1155.8 |
| Total | 3540 | 565,183.9 | 568,723.9 | 43,733.6 | 4090 | 563,106.8 | 567,196.8 | 41,810.8 |
(Hour) | Optimal Loads (MW) | ($) | (lbs) | (lbs) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 357.9 | 342.1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 30.0 | 13,766.8 | 1891.3 | 3466.5 |
| 2 | 382.1 | 367.9 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 21.3 | 14,618.2 | 2001.8 | 4087.5 |
| 3 | 391.8 | 378.3 | 0 | 0 | 79.9 | 0 | 0 | 0 | 0 | 0 | 26.1 | 17,910.0 | 2380.6 | 4703.5 |
| 4 | 434.2 | 423.4 | 0 | 0 | 92.4 | 0 | 0 | 0 | 0 | 0 | 12.8 | 18,757.8 | 2606.3 | 6063.5 |
| 5 | 400.3 | 387.3 | 130.0 | 0 | 82.4 | 0 | 0 | 0 | 0 | 0 | 20.2 | 20,801.1 | 2896.1 | 5460.1 |
| 6 | 391.3 | 377.8 | 130.0 | 121.2 | 79.7 | 0 | 0 | 0 | 0 | 0 | 21.1 | 23,711.7 | 3305.7 | 5884.6 |
| 7 | 410.0 | 397.7 | 130.0 | 127.1 | 85.2 | 0 | 0 | 0 | 0 | 0 | 15.8 | 23,462.3 | 3421.5 | 6532.2 |
| 8 | 430.0 | 418.9 | 130.0 | 130.0 | 91.1 | 0 | 0 | 0 | 0 | 0 | 11.0 | 24,335.3 | 3536.1 | 7223.2 |
| 9 | 442.3 | 432.1 | 130.0 | 130.0 | 94.8 | 45.9 | 25.0 | 0 | 0 | 0 | 15.2 | 28,285.2 | 4045.8 | 7944.8 |
| 10 | 455.0 | 455.0 | 130.0 | 130.0 | 117.2 | 59.7 | 27.7 | 25.4 | 0 | 0 | 10.9 | 30,273.5 | 4502.8 | 9026.7 |
| 11 | 455.0 | 455.0 | 130.0 | 130.0 | 127.3 | 65.8 | 34.0 | 29.9 | 23.1 | 0 | 10.8 | 32,210.0 | 4854.7 | 9420.4 |
| 12 | 455.0 | 455.0 | 130.0 | 130.0 | 134.9 | 70.5 | 38.9 | 33.2 | 26.5 | 25.9 | 10.8 | 34,188.2 | 5230.3 | 9752.3 |
| 13 | 455.0 | 455.0 | 130.0 | 130.0 | 117.2 | 59.7 | 27.7 | 25.4 | 0 | 0 | 10.9 | 30,213.5 | 4502.8 | 9026.7 |
| 14 | 442.3 | 432.1 | 130.0 | 130.0 | 94.8 | 45.9 | 25.0 | 0 | 0 | 0 | 15.2 | 27,425.2 | 4045.8 | 7944.8 |
| 15 | 430.0 | 418.9 | 130.0 | 130.0 | 91.1 | 0 | 0 | 0 | 0 | 0 | 11.0 | 24,335.3 | 3536.1 | 7223.2 |
| 16 | 374.1 | 359.4 | 126.1 | 115.7 | 74.6 | 0 | 0 | 0 | 0 | 0 | 26.9 | 21,723.1 | 3188.9 | 5289.7 |
| 17 | 357.4 | 341.6 | 120.9 | 110.4 | 69.7 | 0 | 0 | 0 | 0 | 0 | 33.2 | 20,855.7 | 3072.2 | 4734.0 |
| 18 | 391.3 | 377.8 | 130.0 | 121.2 | 79.7 | 0 | 0 | 0 | 0 | 0 | 21.1 | 22,591.7 | 3305.7 | 5884.6 |
| 19 | 430.0 | 418.9 | 130.0 | 130.0 | 91.1 | 0 | 0 | 0 | 0 | 0 | 11.0 | 24,335.3 | 3536.1 | 7223.2 |
| 20 | 455.0 | 455.0 | 130.0 | 130.0 | 117.2 | 59.7 | 27.7 | 25.4 | 0 | 0 | 10.9 | 30,703.5 | 4502.8 | 9026.7 |
| 21 | 442.3 | 432.1 | 130.0 | 130.0 | 94.8 | 45.9 | 25.0 | 0 | 0 | 0 | 15.2 | 27,425.2 | 4045.8 | 7944.8 |
| 22 | 455.0 | 455.0 | 0 | 0 | 109.9 | 55.1 | 25.0 | 0 | 0 | 0 | 12.5 | 22,808.6 | 3245.9 | 7418.8 |
| 23 | 413.0 | 400.9 | 0 | 0 | 86.1 | 0 | 0 | 0 | 0 | 0 | 19.1 | 17,883.4 | 2493.2 | 5360.9 |
| 24 | 406.3 | 393.7 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 13.7 | 15,470.6 | 2112.7 | 4760.9 |
| Total | 568,091.2 | 82,261.0 | 161,403.6 | |||||||||||
| Test Systems | Units | Objective | Total Cost and Emissions | |||
|---|---|---|---|---|---|---|
| No Ramp Rates, No VPEs | Ramp Rates, No VPEs | No Ramp Rates, VPEs | Ramp Rates, VPEs | |||
| VII–X | 20 | Cost ($) | 1,136,746.4 | 1,135,081.0 | 1,179,295.2 | 1,184,760.6 |
| Emission (lbs) | 84,786.0 | 85,731.0 | 93,047.3 | 89,305.9 | ||
| XI–XIV | 40 | Cost ($) | 2,283,893.8 | 2,280,510.1 | 2,371,344.6 | 2,372,688.8 |
| Emission (lbs) | 173,154.7 | 175,069.2 | 189,596.4 | 182,460.3 | ||
| XV–XVIII | 60 | Cost ($) | 3,411,158.6 | 3,406,502.8 | 3,527,471.5 | 3,554,833.5 |
| Emission (lbs) | 257,715.8 | 260,352.8 | 288,407.1 | 276,125.6 | ||
| XIX–XXII | 80 | Cost ($) | 4,558,451.2 | 4,551,960.6 | 4,710,657.6 | 4,734,809.3 |
| Emission (lbs) | 346,550.7 | 350,220.1 | 385,657.1 | 366,742.4 | ||
| XXIII–XXVI | 100 | Cost ($) | 5,704,920.7 | 5,696,950.6 | 5,901,065.7 | 5,901,065.7 |
| Emission (lbs) | 434,073.9 | 438,576.0 | 481,106.2 | 481,106.2 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ebrie, A.S.; Kim, Y.J. Reinforcement Learning-Based Multi-Objective Optimization for Generation Scheduling in Power Systems. Systems 2024, 12, 106. https://doi.org/10.3390/systems12030106
Ebrie AS, Kim YJ. Reinforcement Learning-Based Multi-Objective Optimization for Generation Scheduling in Power Systems. Systems. 2024; 12(3):106. https://doi.org/10.3390/systems12030106
Chicago/Turabian StyleEbrie, Awol Seid, and Young Jin Kim. 2024. "Reinforcement Learning-Based Multi-Objective Optimization for Generation Scheduling in Power Systems" Systems 12, no. 3: 106. https://doi.org/10.3390/systems12030106