1. Introduction
With the advancement of science and technology, the continuous improvement of urban spatial structure has promoted the rapid growth of the economy. But at the same time, rapid urbanization has also caused serious air quality problems [
1,
2]. In addition, studies have also shown that people’s long-term exposure to particulate pollutants and other air pollutants mainly includes SO
2, NO
2, O
3, and CO [
3], which will cause harm to the human respiratory system, nervous system, cardiovascular system, and reproductive system [
4,
5,
6,
7]. Therefore, it is necessary to establish an air quality forecasting system to grasp the development trend of air quality and air pollution, provide technical support for regional air pollution prevention and control, and provide early warning information for daily travel or production activities.
The individual methods commonly used to forecast air quality are summarized into three types: data simulation method, mathematical statistics method, and machine learning method. The data simulation method uses professional knowledge such as atmospheric physical diffusion formulas and chemical reaction equations to simulate and forecast the formation and diffusion of pollutants [
8]. This method is simple to calculate, but it needs to follow strict theoretical assumptions. Because the complexity that occurs in the atmosphere cannot be considered, forecasting accuracy is low [
9]. Compared with simulation-based methods, statistical methods based on probability theory show better forecasting results. The most common are classical time series models, such as the auto-regressive (AR) models, moving average (MA) models, and auto-regressive moving average (ARMA) models [
10]. However, statistical methods cannot perform nonlinear fitting during the formation and diffusion of pollutants, which leads to deviations. To address the nonlinear relationship between input and output outcomes, scholars were beginning to leverage machine learning. Support vector machine (SVM) [
11,
12], random foresting (RF) [
13,
14], and artificial neural network (ANN) [
15] are widely applied in air quality forecasting. Saeid et al. used artificial neural networks to forecast PM
10 concentration and applied it to health risk assessment, and the correlation coefficient reached 0.87 [
16]. In addition, as the historical data collected by monitoring sites increases, deep learning methods for big data show superior predictive performance. Given that the recurrent neural network (RNN) can take into account the time-dependent effects of air quality [
17], it can be applied to forecast air quality by processing series well. However, in highly complex and large-scale monitoring site networks, it is difficult to capture spatiotemporal correlations between sites.
Fuzzy cognitive maps (FCM) were developed in combination with the above advantages. FCM not only has the ability to handle fuzzy logic uncertainty problems but also has the machine learning algorithms used by neural networks. The model has a good predictive effect while explaining causality [
18]. For example, Liu et al. established an EMD-HFCM model combining recurrent neural networks and fuzzy logic, which greatly improved the performance of processing large-scale and non-stationary time series [
19]. Yang et al. established the Wavelet-FCM model, which decomposed the original nonstationary time series into multiple time series through the wavelet transform, which improved the forecasting performance and could be applied to a variety of forecasting tasks [
20]. Therefore, an in-depth study of FCM can effectively improve the performance of the model, which has the potential and advantages for dealing with dynamic, noisy air quality [
21].
However, the forecasting effect of individual models is limited. So, people started building hybrid models. The multi-scale decomposition step is introduced in the forecasting system to decompose the complex system into multiple subsystems that are easy to analyze, such as decomposition and recombination methods [
22], data reconstruction [
23], feature extraction [
24], optimization algorithms [
25], etc. For example, Wang et al. applied data preprocessing based on different strategies to improve the performance of wind speed prediction systems [
26]. Yang et al. added the variational mode decomposition technique based on adaptive parameters to the machine learning model, and the average absolute error of the last four data sets reached 0.5121 [
27]. Hybrid models can reduce the difficulty of modeling complex systems and improve the forecasting performance of the model. Therefore, it makes sense to construct a hybrid model based on FCM.
Based on the combing and summarizing of the literature, the research motivation of this paper can be summarized as follows:
- (1)
Although the hybrid model can serve the purpose of the problem well by combining specific methods, there are still some disadvantages. Most of the current hybrid models only focus on extracting data features through the decomposition of time series, which greatly improves the fitting effect of data but ignores the potential risk of information leakage in the decomposition process [
28]. Therefore, the data preprocessing method needs to be further improved.
- (2)
In the past, the study of air pollution was based on the division of administrative regions, and the effects of meteorology and time were analyzed separately. However, air pollution is a cross-regional environmental pollution problem, and the spatial spillover effect between urban agglomerations cannot be ignored [
29].
- (3)
Traditional single models cannot achieve high accuracy requirements, while hybrid models can improve forecasting accuracy.
- (4)
The study of time series data only focuses on the order of time and ignores the particularities of the air quality data itself, such as the ambiguity and uncertainty of the data.
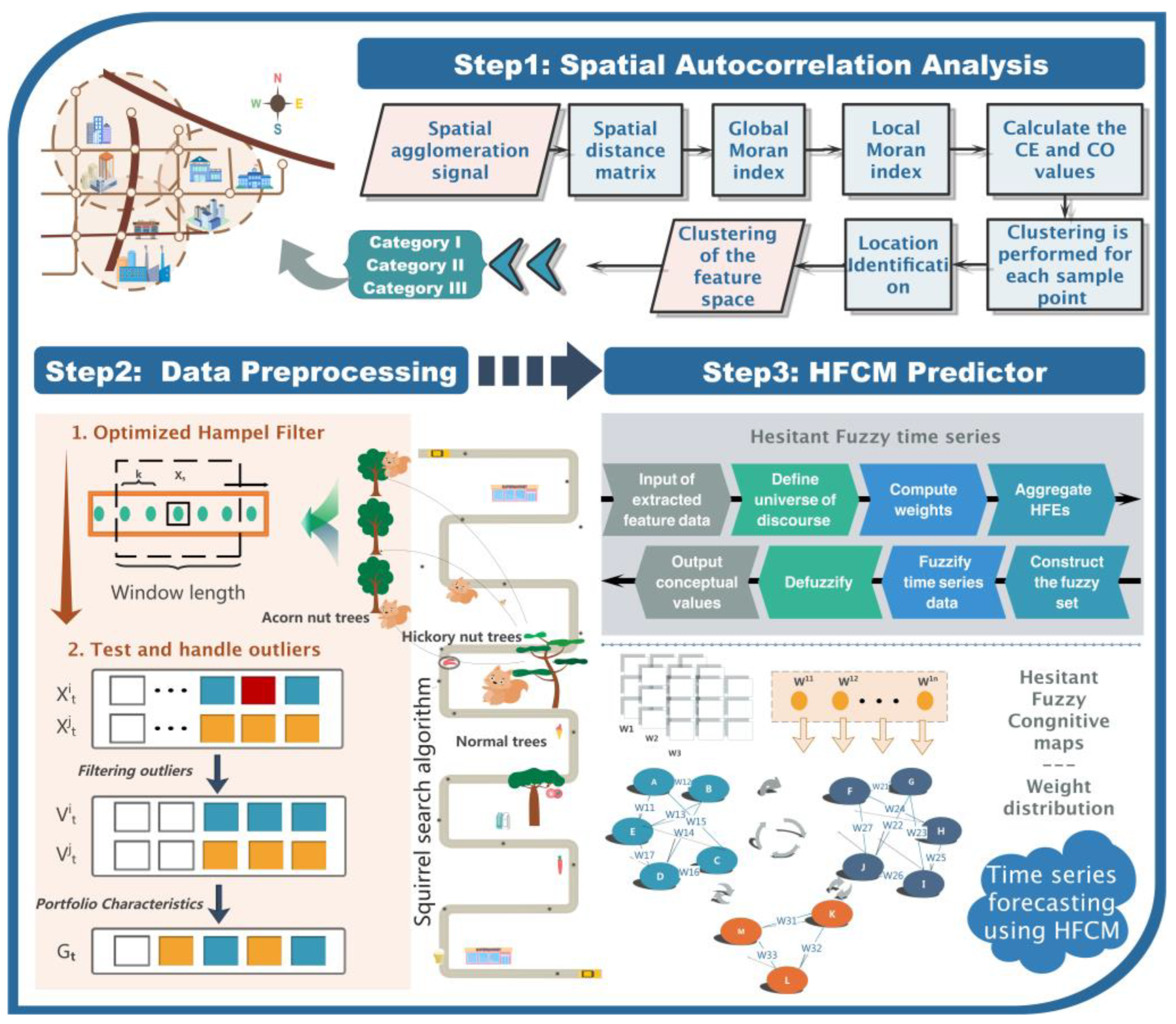
In order to solve the above problems, an innovative spatiotemporal hybrid forecasting model based on adaptive feature extraction and improved fuzzy cognitive maps is proposed. It consists of three modules: a spatial correlation analysis module, data preprocessing module, and fuzzy information forecasting module. For the spatial correlation analysis module, a spatial feature extraction model based on the Moran index and local gravitational clustering (LGC) is designed that can combine spatiotemporal features and extract key influencers from complex data to represent a variety of complex issues in a visual way. For the data preprocessing module, a novel adaptive feature extraction model optimized by the squirrel search algorithm (SSA) is proposed to process and correct the outliers of the original series. Finally, novel hesitant fuzzy cognitive maps (HFCM) are proposed for the fuzzy information forecasting module. The fuzzy logic in the original model is optimized by hesitate fuzzy information, and the forecasting at the numerical level is transformed into the forecasting of probability at the interval level.
In summary, the main contributions of this paper are:
Spatial spillover effects are considered the main factors affecting the air quality index (AQI) of different cities. It verifies that the spatiotemporal correlation of the extracted data is necessary to improve the accuracy of air pollution forecasting.
The Hampel filter algorithm optimized by the squirrel search algorithm is innovatively introduced into the air quality forecasting model to process and correct the data outliers to improve the forecasting accuracy of the hybrid model.
Hesitant fuzzy cognitive maps are first proposed to forecast air pollution. It can effectively solve the gray information of air quality or fuzzy relationships and uncertainties, thus further improving the accuracy of forecasting.
The proposed model was comprehensively evaluated with the actual AQI dataset, five model evaluation criteria, and thirteen comparative models collected from the Beijing-Tianjin-Hebei region. The empirical results show that the proposed hybrid method has superior forecasting performance compared with the comparison models and can provide a theoretical basis for air pollution forecasting and early warning.
2. Design of Spatiotemporal Hybrid Air Pollution Early Warning System
Air pollution not only has a temporal complexity but also has a spatial spillover effect. Therefore, in order to forecast air pollution scientifically and rationally, this paper proposes a spatiotemporal hybrid air pollution early warning system of urban agglomeration.
Figure 1 depicts the framework of the system.
2.1. Spatial Correlation Analysis Module
In this section, the Moran I-Local gravitational clustering (ILGC) model is proposed to verify the spatial correlation and capture the diffusion and concentration characteristics of air pollution between regions.
2.1.1. Moran Index
The Moran index is applied to analyze the spatial correlation between different cities. The Moran index is divided into the global Moran index and the local Moran index [
30,
31]. The global Moran index is used to determine whether there is aggregation or anomaly in space, and if it is judged to be global autocorrelation, the local Moran index is further used to explore the specific manifestations of aggregation or outliers.
Local Moran index
where
is each region
,
c represents a different group of cities. The spatial weights between features
i and
j are denoted as
and the total number of features is
, so that the aggregation of all spatial weights can be found.
Most of Moran’s
I belong to (−1, 1), but there are also extreme cases, that is, Moran’s value appears outside this range [
32]. When Moran’s
I is closer to 1, the more pronounced the positive spatial correlation and the closer the relationship between cities. When Moran’s
I is closer to −1, the more pronounced the negative spatial correlation and the greater the spatial difference between cities. When Moran’s
I is 0, the space is random, indicating that cities are not correlated.
2.1.2. Local Gravitational Clustering
The data are grouped using LGC based on a spatial neighborhood matrix. LGC is a clustering algorithm based on local center metrics. It describes the connectivity of the adjacent regions of each sample point through local gravitational resultant force and centrality. By comparing clustering algorithms such as k-means clustering [
33] and fuzzy c-means clustering [
34], LGC has the advantage of being able to train singular values to obtain possible impact information [
35].
Step 1: The local resultant force is calculated for each sample point.
The local resultant force (LRF) is the sum of the forces acting at point
with mass
, denoted as
.
where the reciprocal of all distance points acting on the
k nearest neighbors of the data point
is obtained by summing up
.
is a unit vector connecting two mass directions and k is the number of nearest neighbors around . The closer to the center, the greater the mass of the sample points and the less susceptible they are to other forces.
Step 2: Calculate the centrality (CE) and coordination (CO) values.
The relationship between LRF is measured by two metrics: centrality and coordination. Where the centrality of data point
is calculated as follows:
where
is the displacement vector from
’s neighbor to
,
belongs to (−1, 1), and when
is greater than zero, it is pointed out that most of the neighbors point to it, indicating that it has better centrality.
The CO of data point
is calculated as follows:
Among them, and are the local resultant forces of points and , and their neighbors, and a smaller local gravitational resultant force and a larger CE value are selected as local proxy points in their own domain, and the local proxy point should preferably appear above the direction pointed by the local gravitational resultant force of the sample point.
Step 3: Clustering is performed for each sample point .
The current local proxy point selected in the previous step connects to communicate with other local proxy points. The current local proxy point looks for the target local proxy point in the neighborhood for connection communication, and if it cannot be found, the best sample is found in the neighborhood sample, and the intermediate communication point continues to complete the work. The intermediate communication point must have a value greater than 0 and be closer to the target proxy point than the origin. The local proxy point itself forms a small cluster, which forms a large cluster by communicating with the target proxy point.
2.2. Data Preprocessing Module
This stage introduces a new type of feature extraction model based on an improved Hampel filtering method called SHP. Since the default parameters of the adaptive Hampel filter cannot adapt to the characteristics of all data, we use the squirrel algorithm to optimize the DX (the scalar of the half-width of the filter window), T (the threshold used in the equation), and Threshold (adaptive threshold. The final minimum MAPE value is the optimization goal, and the data preprocessing algorithm for different urban agglomerations finds the best parameters and then obtains the optimal forecasting effect. The basic theoretical composition of the model is as follows.
2.2.1. Squirrel Search Algorithm
The SSA is a naturally inspired optimization paradigm that simulates the dynamic process of finding pinecones in southern flying squirrel gliding. Compared with other optimizations, SSA considers the seasonal factors of the data to be random factors, which disrupts the search space and improves the randomness of the optimization algorithm.
First, the position of the squirrel in the dimensional search space is represented using the following matrix:
where
is the initial position. Next, random initialization is performed using the fol-lowing formula:
where
is the updated position.
denotes the randomness of the flying squirrel population contained in the range 0 to 1.
and
are the upper and lower limits, respectively.
Eventually, the squirrel colony locations are updated to the following matrix:
The difference between the advantages and disadvantages of searching for food sources will depend on the different fitness levels of each flying squirrel’s location. Therefore, based on the initial position of the squirrel, the position fitness is calculated by determining the variables, namely the best food source (hickory tree ), normal food source (acorn tree ), and no food source (flying squirrel on normal tree ). Its position updating for three different foraging scenarios is mathematically modeled as follows.
Case 1: Best food source (hickory tree)
Case 2: Normal food source (acorn tree)
Case 3: No food source (flying squirrel on normal tree)
where
is the random glide distance,
is a random number in the range of [0, 1],
is the position of the squirrel reaching the hickory tree, and
t is the current iteration. The sliding constant
is used in the mathematical model to seek a balance between exploration and development. Its value has a non-negligible role in the performance of the proposed algorithm. In the current work, the value of
is 1.9, which is derived from rigorous analysis. The predator presence probability
is 0.1 in all cases.
At the same time, in winter, due to low-temperature environmental conditions, squirrels tend to exercise on a small scale compared to other seasons and are mostly used to store pecans to maintain energy for the winter, so the influence of seasonal factors is considered. It can effectively solve the problem that the algorithm is trapped in the local optimal solution. Seasonal variables are expressed as:
where
k is the current iteration value and
is a direct influence on the algorithm’s search and development capability. The larger the
, the stronger the exploration capability, and the smaller the
, the stronger the development capability.
After winter, flying squirrel foraging will be active again, considering that those squirrels that have not been able to find the best food source in winter but still survive will be able to forage again, and there is randomness, which will move in different directions.
The repositioning of the flying squirrel can be expressed by the equation as:
where
and
are the upper and lower bounds of variables,
is used to generate random solutions.
where
and
are random number matrices belonging to (0, 1),
= 1.5. And
is defined as follows:
where
.
2.2.2. Hampel Filter
The Hampel filter is a decision filter used to detect and remove outliers [
36]. Like the
rule, which distinguishes between the mean and standard deviation, it determines whether the data in the data set are a singular value by the median and the median that deviates from the absolute value of the median, and then replaces the outlier with the median of the short series in the filter movement window.
where
t is a predefined threshold for determining the absolute difference from the median, and
denotes the median of the data sequence of length
N, and
S is the median absolute difference (MAD) scale estimator. The constant 1.4286 guarantees that the expected value of
S is equal to the standard deviation of the normal distribution data [
37].
2.3. Fuzzy Information Forecasting Module
In this section, the basic theory of hesitant fuzzy time series is first described, followed by the details of the innovative hesitant fuzzy cognitive maps. This paper innovatively proposes hesitant fuzzy cognitive maps (HFCM) and introduces the hesitant fuzzy logic relationship to modify the output results of the fuzzy cognitive maps.
2.3.1. The Basic Definition of Hesitant Fuzzy Theory
Before constructing hesitant fuzzy cognitive maps for forecasting, let us review the definitions of fuzzy set, hesitant fuzzy set, and fuzzy time series (FTS). The basic theory is as follows [
38].
Definition 1. Define the universe of discourse. A fuzzy set in U can be defined by its membership function.where represents the membership function of the fuzzy set and represents the member degree of µ to .
Definition 2. over the reference set is represented by a mathematical expression as follows:where is the set of possible subsets in [0, 1] by membership function that computes the possible membership degrees of the elements in U to the set H. is the set of multiple subsets of [0, 1].
For the element , is called the hesitant fuzzy element (HFE). Definition 3. Let , R (a subset of real number) be a universe of discourse. Different fuzzy sets are defined on . If is a collection of , then it is known that is called an FTS on .
Definition 4. Let be the FTS and be a first order model of . If for any time
, then is designated as time-invariant FTS, otherwise is named as time-variant FTS.
Definition 5. The fuzzy logic relation (FLR) can be expressed as , Their relationship can be expressed by the formula:where “” is a max-min composition operator, is fuzzy relationship. Definition 6. The relationship between and can be denoted as , where and are called the left-hand side and the right-hand side of the FLR, respectively. FLRs with the same left-hand side can be categorized into an ordered fuzzy logic group (FLG).
2.3.2. The FCM Framework
FCM consists of a set of nodes and weighted edges, which can be regarded as a weighted directed graph. The nodes represent the variables in the AQI time series, that is, each city in the urban agglomeration, and the edges represent the causal relationship between these nodes. The set of these concept nodes is represented as vector
C, that is, the set of urban agglomerations. Each FCM containing
N concepts can be defined by four elements,
, where
is the collection of concepts that represent all detected air quality indices. These concepts define the state value of
t at any moment as a vector
, that is, the AQI time series data of each city:
where
is an
connection matrix representing the relationship from
to
.
The circular relationship between
and
on
is expressed as follows:
denotes the state value of node at time , denotes the value of node at time . The state value of the node at the (t + 1)-th iteration is determined by the weight matrix and state value of all connected nodes at the t-th iteration.
The
f is the transfer function which simulates the forecasting process of the conceptual state of the
c-
th FCM model. It is the activation function that updates the activation state of the node at each iteration to perform a simulation of conceptual state forecasting.
where
acts as a regulator that determines the appropriate shape of the function and the speed at which the curve converges to the boundary.
is commonly chosen.
2.3.3. Hesitant Fuzzy Processing Time Series
The universe of discourse is defined as . Among them, and are the maximum and minimum values of AQI data, respectively, and are the standard deviation of the training sample.
Then, the cumulative distribution function (CDF) is used to divide the equal frequency interval.
To determine the optimal number of intervals, adaptive interval division is performed based on fuzzy c-means clustering. The cluster generated by clustering is regarded as a fuzzy set; the cluster center is the midpoint of the interval, and the size of the clustered category is the interval size.
where
is the membership degree between the sample point
and the cluster enter
,
i is the sample,
c is the city category,
is the fuzzy index (
),
is the distance between the sample point
and cluster center
. The most common method for calculating the distance is Euclidean distance.
For the calculation of the weights
,
, this article uses the trigonometric membership function with the following formula:
where
and
are the equal and unequal spacing lengths calculated above, respectively.
The triangle membership function is used to calculate the membership degree on the interval divided by different methods, and the
,
is obtained. The triangle membership function formula is as follows:
The formula for aggregating hesitant fuzzy elements and constructing fuzzy sets, where the aggregation operator is used to calculate the member rank of the elements, is defined as follows:
Based on Definition 3, the fuzzy set is determined according to the maximum membership principle. Because the air quality index lags one-stage correlation, the first-order fuzzy logic relationship is determined according to Definition 5. After that, the fuzzy relationship group is established based on Definition 6 by counting the frequency of fuzzy relationships in the training set.
The weight matrix is established by the elements in the fuzzy relationship matrix with the frequency of “
” in the training set.
where
. It is the result of weighting the frequency of each fuzzy relationship.
Fuzzy output is obtained on the basis of hesitant fuzzy relations. Before that, the combined midpoints of the equal and unequally spaced trigonometric membership functions are calculated as follows:
where
;
and
;
are the midpoints and weights of the membership functions in the interval of equality and inequality, respectively. Use the following formula to defuzzify them for numerical forecasting.
where
is the fuzzified output obtained by applying the max–min combination operation on fuzzy logic relationships (FLR).
The pseudo-code of the data hesitant fuzzification process of Algorithm 1 is as follows:
| Algorithm 1: HFCM |
| Objective function: min (MAPE) = |
Input: —a sequence of sample data.
—a sequence of FCM output
Output: |
Parameters:
ip: number of the intervals
i: i-th sample
j:
: the left endpoint of the adaptive division interval
: the right endpoint of the adaptive division interval
: the left endpoint of the equal frequency division interval
: the right endpoint of the equal frequency division interval
: the membership degree of the adaptive division interval
: the membership degree of the equal frequency division interval
nn: min number of the intervals
mm: max number of the intervals |
| 1: | /* Initialize the data and convert it into growth rate */ |
| 2: | /* Define the universe of discourse */ |
| 3: | FOR ip = nn: mm (number of the intervals); N = ip; |
| 4: | | /* Calculate by cumulative distribution function. (Equation (26)) */ |
| 5: | | /* Calculate by fuzzy c-means clustering (Equation (27)) */ |
| 6: | | /* Calculate the weights of different intervals */ |
| 7: | |
; |
| 8: | |
|
| 9: | | /* Calculate */ |
| 10: | | Calculate: Membership grades ; |
| 11: | | /* Judgment fuzzy sets */ |
| 12: | | | IF is fuzzy set corresponding to |
| 13: | | | | Assign fuzzy set to |
| 14: | | | END |
| 15: | | | IF is fuzzy production of day n, and is fuzzy production of day n + 1 |
| 16: | | | | |
| 17: | | | END |
| 18: | | /* Determine the fuzzy logic relation group */ |
| 19: | | /* Count the frequency of each logical relationship */ |
| 20: | | /* Calculate the percentage rate of each occurrence logic */ |
| 21: | | /* Calculate the weight matrix and normalize the weight. */ |
| 22: | | Calculate: ; |
| 23: | | /* The maximum membership principle determines the fuzzy set to which it belongs. */ |
| 24: | | Calculate: ; |
| 25: | | /* Defuzzification to obtain the predicted value */ |
| 26: | | /* Turning growth rates into data */ |
| 27: | END |
| 28: | |
| 29: | Returned: r (The location of the optimal concept)
|
2.4. Error Evaluation Module
To evaluate the superiority of the proposed system, the error evaluation module was constructed, which contained three statistical indicators and two test models.
2.4.1. Error Test
The following three statistical indicators were employed to evaluate the effectiveness of the predictive model: mean absolute percentage error (
MAPE), root mean square error (
RMSE), and mean absolute error (
MAE). They are defined as:
where
is the forecasting data,
is the original data, and
i is the number of samples.
2.4.2. Hypothesis Testing
This section uses the Diebold–Mariano (DM) test [
39] and the modified Diebold–Mariano (MDM) test [
40] to evaluate hypothesis testing methods for the predictive performance of different models. Its theory is described below.
The raw data is
, and for the two forecasting sequences
and
, their error can be calculated by the following formula:
At this point, the difference between the two error sequences
can be defined as follow:
The null and alternative hypotheses are set as follows:
The DM statistic follows a standard normal distribution and can be calculated as:
Specifically,
T is the number of advance multi-step forecasting. Where
,
can be defined as:
However, efficient T-period forecasting has forecasting errors after the process, so MDM is proposed to solve this problem with the assumption that “no observed” lag has zero covariance. The DM statistic is compared with the cut-off value . If , accept the null hypothesis, indicating that there is no difference in the forecasting effect of the two models; If or , the null hypothesis was rejected, indicating that the difference in forecasting performance between the two models was not caused by accidental factors.
3. Results
This section includes three parts: data description, spatial feature capture, and model comparison experiments. What is more, three sets of comparison experiments are established to verify the validity of the forecasting of the proposed spatiotemporal mixture model.
3.1. Study Area and Data Description
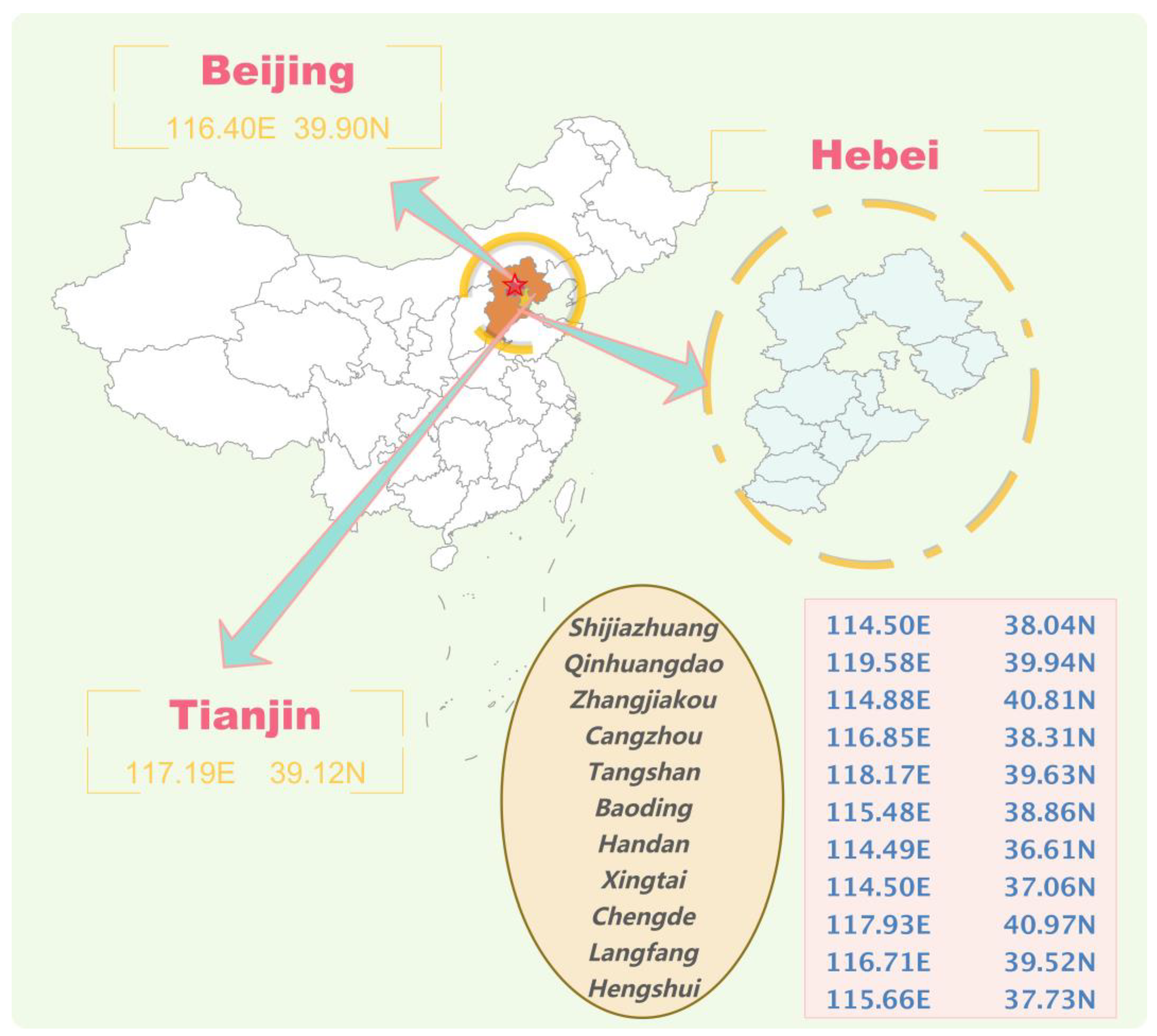
To verify the accuracy and effectiveness of the proposed model, the Beijing-Tianjin-Hebei region was selected as the research object. The site of the study is shown in
Figure 2.
China’s major urban agglomerations with high levels of economic development are Beijing-Tianjin-Hebei, Yangtze River Delta, and Pearl River Delta. Among them, the Beijing-Tianjin-Hebei region is not only a representative area of China’s economic development but also a typical area with serious air pollution [
41]. Due to the high population density in the region, the proportion of heavy industry [
42], industrial transfer [
43], and other factors, the air environment problem has become increasingly prominent. While the Beijing-Tianjin-Hebei region has coordinated economic development [
44], air quality between different cities also has a certain mutual influence [
45]. The air pollution problem of the Beijing-Tianjin-Hebei urban agglomeration has become a topic of general concern for the Chinese government, the media, and the public. So, it is typical to select the Beijing-Tianjin-Hebei region as the research object.
This study uses daily AQI data from 1 January 2017 to 31 August 2022, for 13 cities with a total of 2069 observations. Daily AQI data were collected from
http://www.tianqihoubao.com (accessed on 10 September 2022). AQI is a comprehensive indicator of air quality [
46], and the higher the value, the more serious the pollution. It was calculated according to the National Ambient Air Quality Standard of China (GB3095-2012) [
47], including sulfur dioxide (SO
2), nitrogen dioxide (NO
2), PM
2.5, PM
10 (particulate matter with particle size less than or equal to 10 μm), ozone (O
3), carbon monoxide (CO), and other six pollutants [
18] to comprehensively reflect the regional air quality and pollution degree. Comprehensive AQI can emphasize the possible chronic health effects of air pollution and long-term damage to the environment. Compared with the air pollution index (API) [
48], the detection of pollutants is more comprehensive, the grading restriction standards are stricter, and the evaluation results are more objective. Specifically, the air pollution level is divided into seven attribute categories according to the air quality index (AQI), as shown in
Table 1.
When the air pollution index is less than 100, people can engage in normal activities. When the air quality index reaches mild pollution (100~200), patients with heart disease and respiratory diseases should reduce physical consumption and outdoor activities; when the air quality index reaches 200~300, healthy people ought to reduce outdoor ac-tivities. Additionally, the elderly and patients with heart disease and lung disease should stay indoors and reduce physical activity; when heavy pollution (air quality index above 300) is reached, healthy people should also avoid outdoor activities.
Statistical analysis of daily data is shown in
Table 2.
From
Table 2, in the Beijing-Tianjin-Hebei region, Shijiazhuang and Chengde have the best air quality situation, with mean values of 59.69 and 59.34, respectively, and less fluctuation, with variances of 31.2 and 36.17. In comparison, Handan has the worst air quality and a larger variation, indicating that the air pollution level fluctuates more seri-ously in the process of economic and social development.
3.2. Spatial Feature Extraction Results
For each city, the annual average of daily AQI data is taken as the data for Moran’s index, and the geographical distance matrix is used to describe the static spatial correlation between cities, so as to further use the model to summarize the neighborhood characteristics of the target city for spatiotemporal forecasting.
3.2.1. Spatial Autocorrelation
Table 3 shows the calculation results of the global Moran index to verify whether it is spatially correlated. The average daily data for one year was taken as the calculation data for Moran’s index.
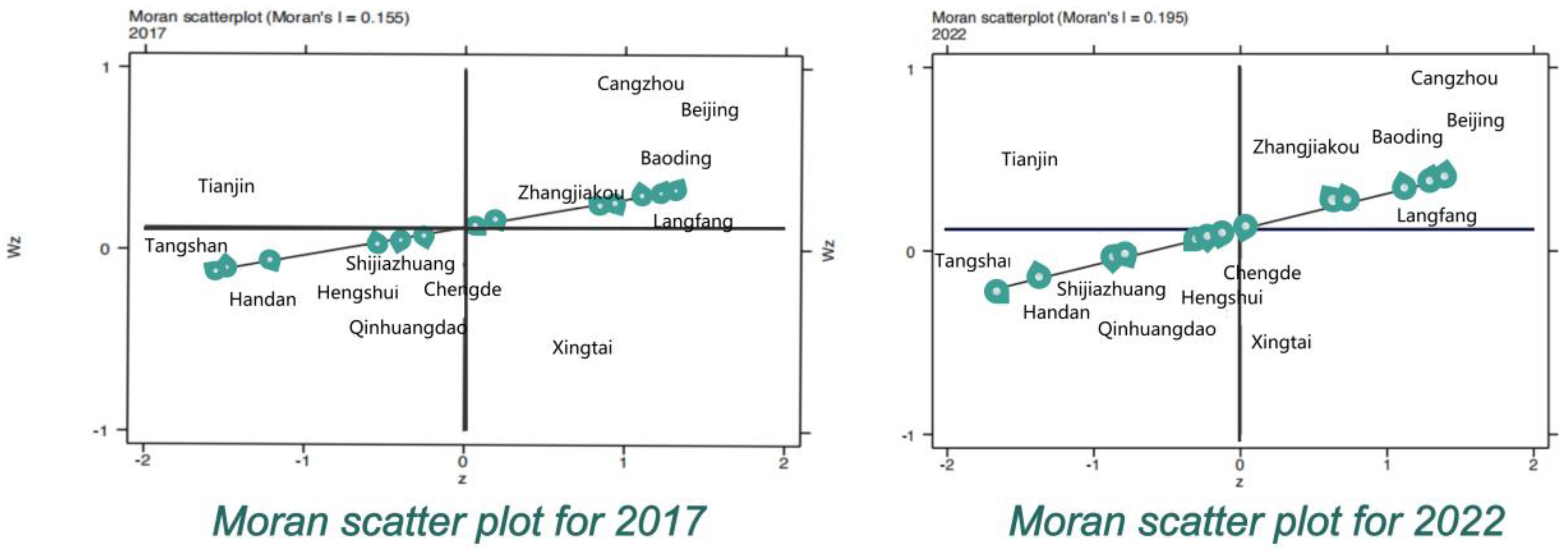
Figure 3 is the Moran scatter plot, which visually shows the distribu-tion of AQI clusters in various cities and further explores the degree of spatial correlation in a specific area.
Table 4 shows the distribution trend of the Moran index, from which there is a temporal and spatial transfer process for the AQI.
Table 3 shows the AQI of thirteen cities in the Beijing-Tianjin-Hebei region from 2017 to 2022. It can be seen from the table that the Moran index has passed the 5% confidence test and is positive. The results showed that there was a positive spatial correlation, the AQI tended to be agglomerated in space, and the distribution of the air quality index was concentrated and encircled.
As shown in
Figure 3, the Moran scatter plot set for each city’s AQI is distributed in the first and third quadrants, indicating a significant positive contribution of each city’s air quality in the local space. The total number of cities located in the 1,3-quadrant re-mained unchanged at 0.77 in the total sample. Most cities maintain similar cluster charac-teristics to their neighbors.
In addition, only three cities have experienced location migration of the Moran scat-tering point, namely, Chengde, Langfang, and Hengshui. Among them, Hengshui and Langfang return to their original spatial states after being influenced by the surrounding environment, while Cangzhou, which was at low air pollution, completely changes its original state and enters the HL region under the influence of high surrounding air pollu-tion. This indicates that the air quality of Chinese urban agglomerations is highly spatially correlated, that air pollution between urban agglomerations is interacting, and that the magnitude of the effect is not the same.
3.2.2. Local Gravitational Clustering
As described in
Section 3.2.1, the AQI is spatially dependent. Non-independent air quality may affect clustered data with interdependent observations. Because the AQI is a comprehensive index, it can reflect the air quality of the city. Therefore, the daily AQI data of different cities are used as clustering variables to cluster cities.
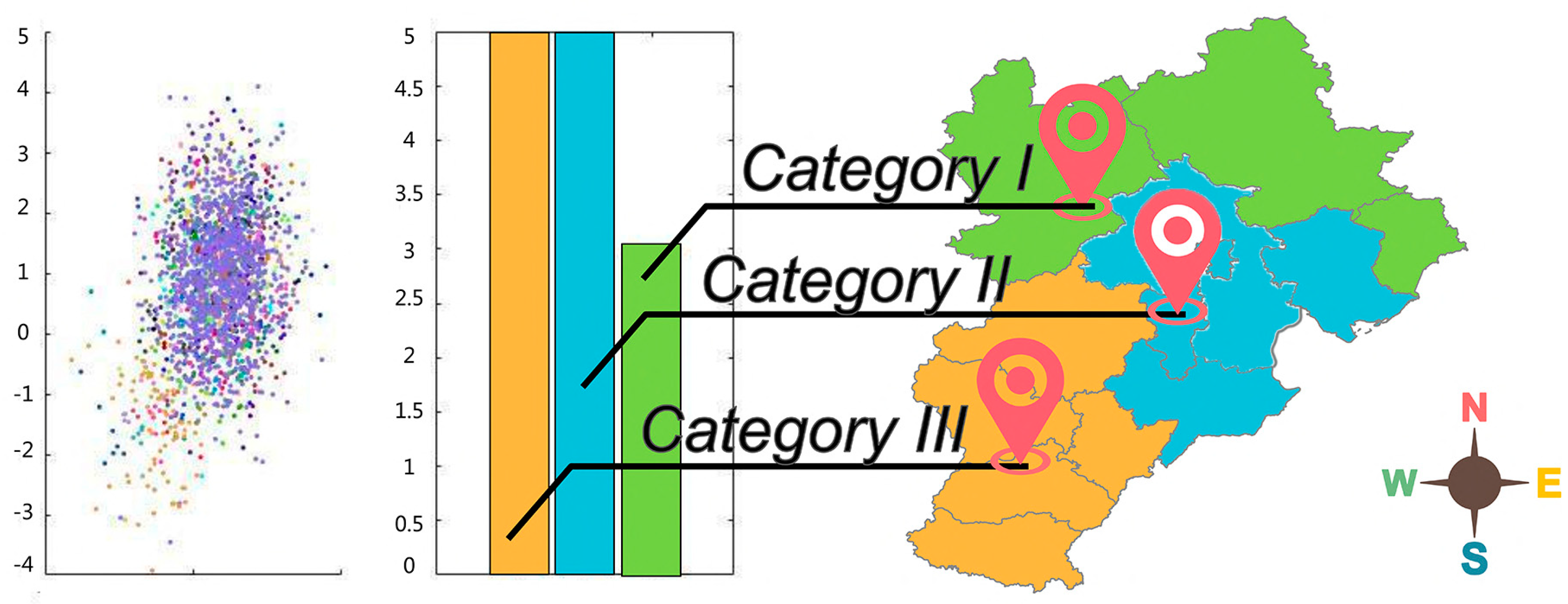
It can be seen from
Figure 4 that the cities are divided into three different classes of air quality categories, showing good zonal differences and regional similarities.
Category I includes five cities: Shijiazhuang, Hengshui, Baoding, Xingtai, and Han-dan. This type of urban agglomeration is in the plains and has poor air pollution dispel-sion conditions. It is a heavy industrial city close to the inland, with many polluting industries superimposed on the transmission of air pollution from western Lu and north-ern Yu, where air pollution is most serious.
Category II includes five cities: Beijing, Cangzhou, Langfang, Tianjin, and Tangshan. Due to the large population and rapid economic development, in which the steel industry in Tangshan, coal in Cangzhou, and cement in Langfang were coupled, pollution is serious and air quality is deteriorating.
Category III includes three cities: Chengde, Qinhuangdao, and Zhangjiakou. Tour-ism-driven economic development, a few polluting industries, and mountainous terrain limit the flow and interaction of the atmosphere between the three cities and other cities, thus keeping air quality low.
Therefore, in order to continuously improve the environmental benefits and air qual-ity of the Beijing-Tianjin-Hebei region, the interaction between its cities cannot be ignored, and it is necessary to establish an improvement mechanism according to its geographical location, industrial structure, and economic development level to achieve the coordinated development of the Beijing-Tianjin-Hebei region.
3.3. Model Comparison Results
Based on the above experimental purposes, this section establishes three comparative experiments and uses the same evaluation index system to verify the forecasting performance.
3.3.1. Feature Extraction Strategy
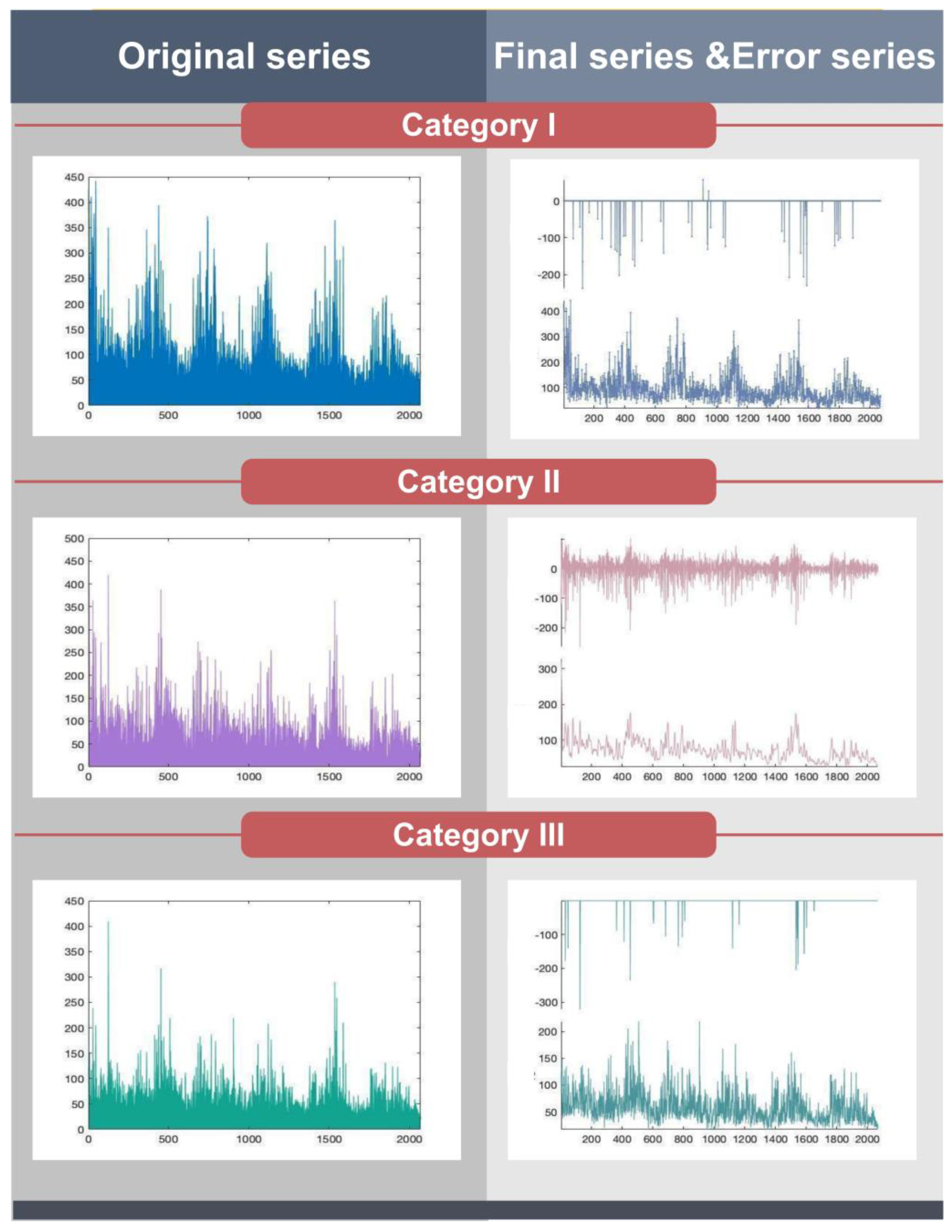
Due to the variability and nonlinearity of AQI in time series changes, it is difficult to accurately predict. In addition, there are many factors affecting air quality, including pol-icy factors, natural factors, etc., which are prone to fluctuations and singular values. Out-liers are data with significant deviations from most observations, which interfere with the training efficiency of the model. Removing outliers can improve forecasting accuracy. Therefore, before the experimental forecasting, it is necessary to test and correct the outli-ers of the data.
To illustrate the excellence of the optimized Hempel filtering in detecting and cor-recting outliers, comparative models based on different optimization algorithms were de-veloped, including the dragonfly algorithm (DA), SSA, and the honey badger algorithm (HBA). The comparison experiments were FCM and DHP-FCM, FCM and SHP-FCM, and FCM and HHP-FCM. The specific results are shown in
Table 5 and
Figure 5.
From
Table 5, it can be seen that the SHP-FCM model has the best performance on MAPE, RMSE, and MAE compared to other optimization models for Category I, Category II, and Category III. In addition, the SSA algorithm has an outstanding advantage in find-ing the best model parameters to build a better hybrid model. In the three urban clusters, the MAPE metrics were reduced by 1.6%, 10.5%, and 5.8% compared to those optimized using the SSA algorithm. This finding has been confirmed in several application scenarios.
Remark 1. SHP not only removes significantly deviated data and reduces interference with the model training rate, but also reduces data variability and preserves original features. Furthermore, from the residual sequence of the right diagram, it can be seen that the processed data and the original data only change slightly, and only the median substitution in the data pane is performed on the extreme data. Therefore, the data preprocessing in this paper will not cause information loss to the data.
3.3.2. Probabilistic Hesitation Fuzzy Set Strategy
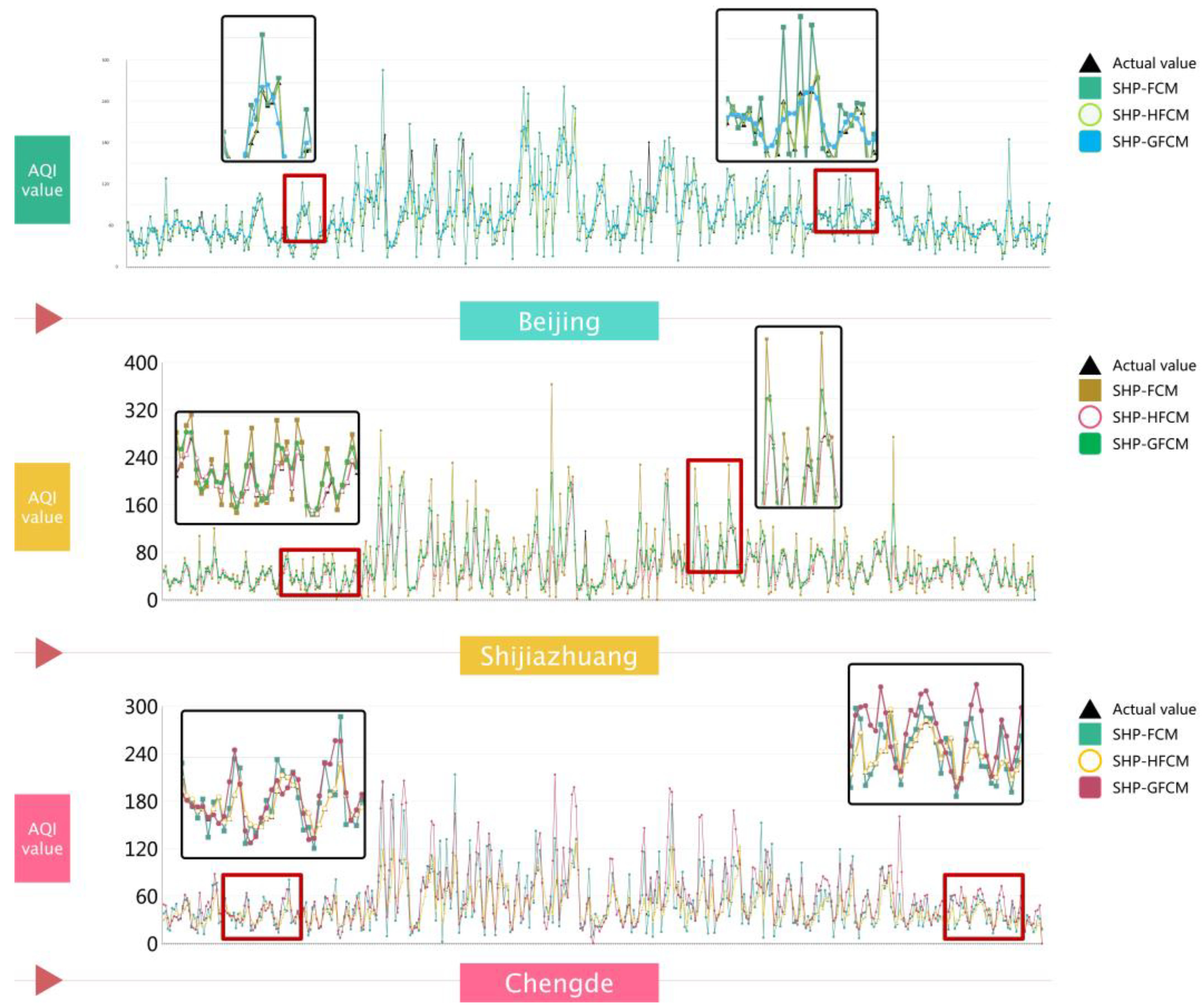
In the previous section, it was known that SHP is superior to DHP and HHP through comparative experiments. In the setting of SHP to extract data features, in order to verify the effectiveness of the HFCM prediction system constructed by combining the hesitant fuzzy information set strategy, FCM and Gaussian smooth fuzzy cognitive maps (GFCM) are also constructed for comparative experiments. The experimental results are shown in
Table 6,
Figure 6 and
Figure 7.
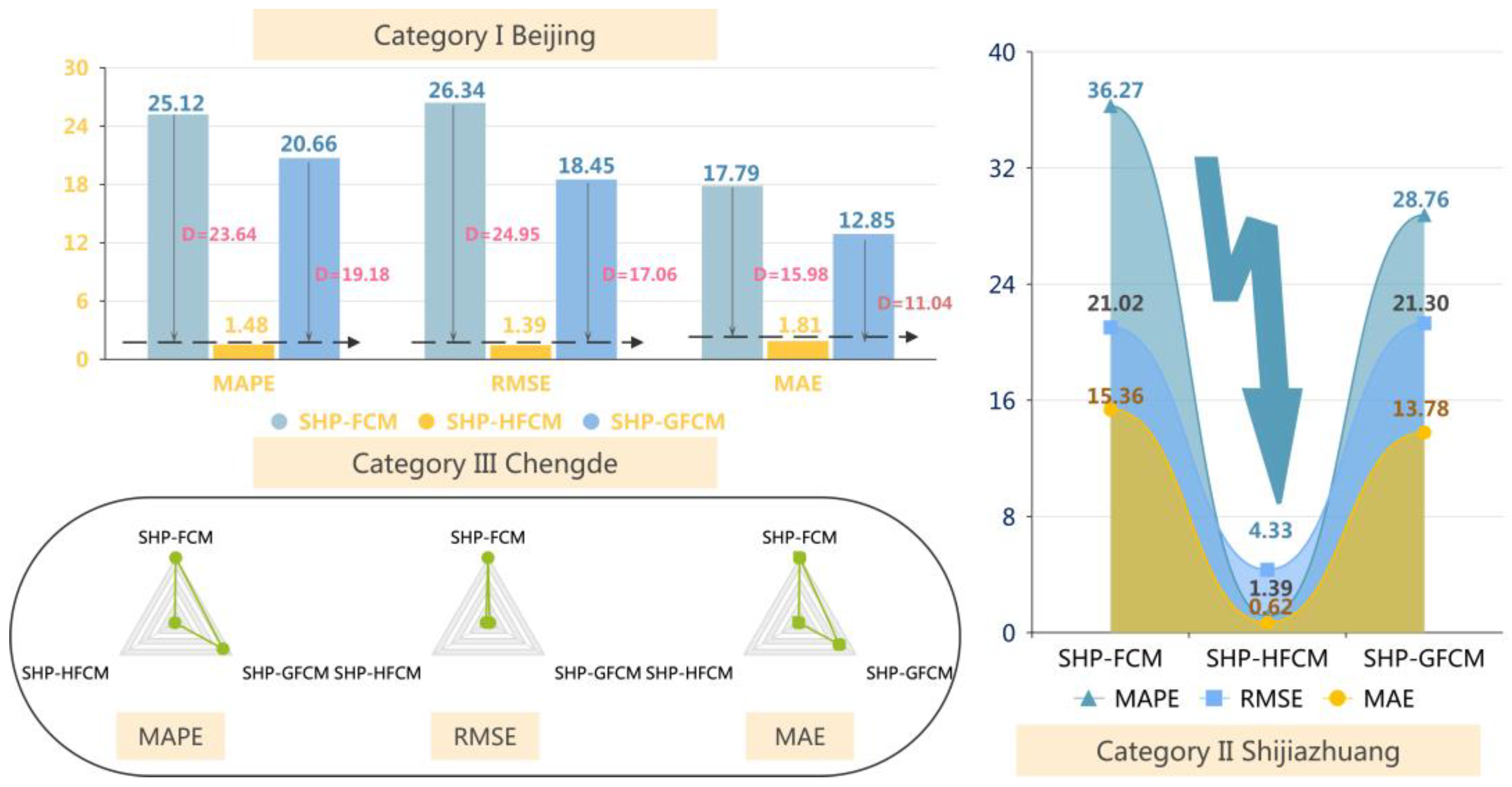
The results in
Table 6 showed that adaptive feature extraction using the Hampel fil-tering algorithm on the original data significantly improved forecasting accuracy com-pared to the direct use of fuzzy cognitive maps. In the comparison of the first type of model to improve the forecasting effect of the original single model, in the case of MAPE, the proposed model decreased by 94.1083% compared with FCM. And GFCM decreased by 17.7548% compared with FCM. In addition, MAE and RMSE also showed different degrees of improvement in each type of urban cluster. Taking Beijing as an example, SHP-FCM and SHP-GFCM are 24.95 and 17.06 higher than the RMSE of SHP-HFCM, respect-tively. The proposed model SHP-HFCM in Shijiazhuang has MAPE, RMSE, and MAE of 1.12%, 4.33, and 0.69, respectively, which are significantly less than the other two compar-ison models.
In particular, the third type of urban agglomeration has the best forecasting accuracy. In all evaluation indicators, the feature extraction strategy based on SHP is significantly better than the hybrid forecasting system based on ordinary fuzziness and Gaussian smoothing.
Remark 2. HFCM has non-negligible advantages over FCM and GFCM in data forecasting. The proposed novel hesitant fuzzy cognitive maps can not only effectively eliminate uncertain infor-mation and unstable elements in time series but also be a promising method for processing the characteristics of time series forecast data itself.
3.3.3. Comparison of Mixed Models in Different Data Preprocessing Environments
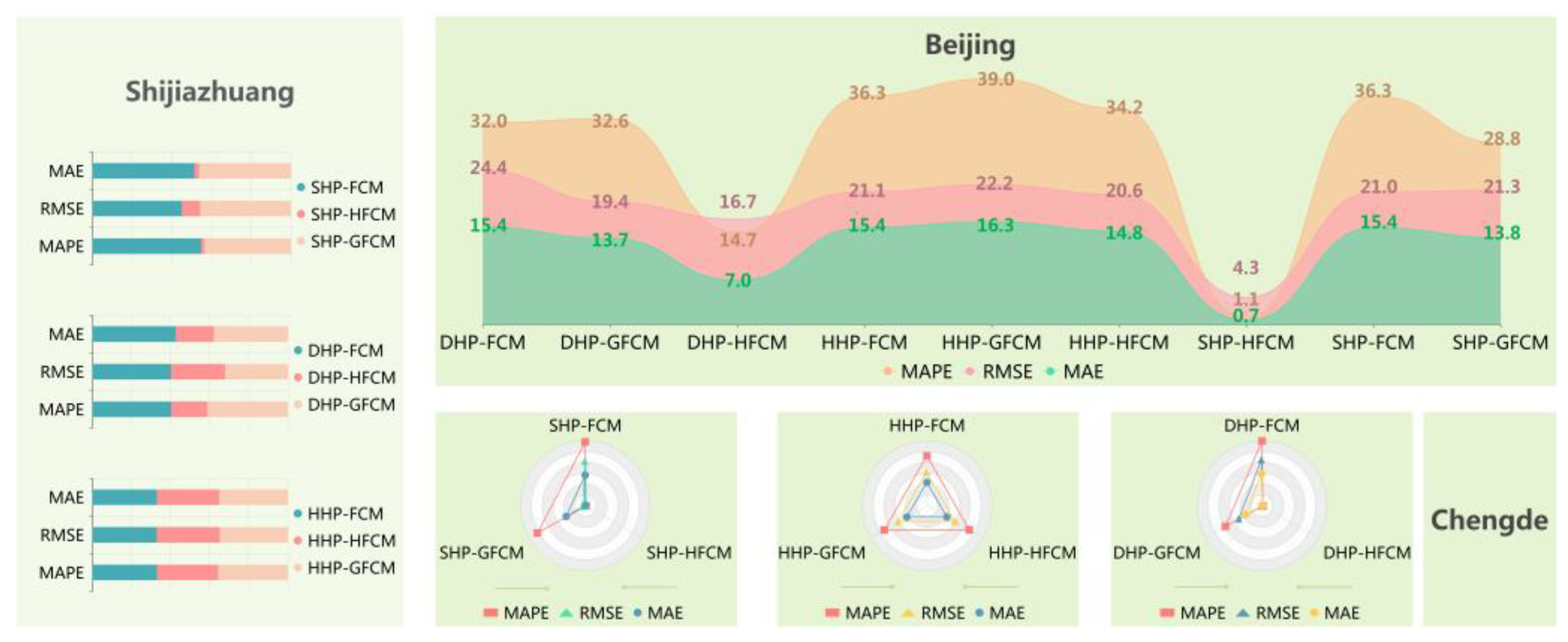
In addition, to show the scalability of hesitant, ambiguous information, the third comparison model is established. The FCM, HFCM, and GFCM data processing methods in the SHP, DHP, and HHP cases were compared. The results are shown in
Table 7 and
Figure 8.
Table 7 shows the performance indicator values for all submodules launched for the three considered environments. Especially taking the third type of urban agglomeration as an example,
,
,
, so for the same data preprocessing environment, the model using the HFCM method is better than the model using the FCM and the GFCM. In addition, the MAPE values for various hybrid forecasting systems are
,
,
, thus it is concluded that SSA plays an important role in HFCM forecasting. After comprehensive comparison, the proposed model has a good effect in the forecasting of pollutant concentration series.
Remark 3. In different data preprocessing scenarios, the submodule with the best predictive per-formance is uniquely identified. The hybrid forecasting system based on HFCM constructed in this paper achieves the best results of all evaluation indicators under different data processing environ-ments. This property has been demonstrated in three different scenarios.
4. Discussion
4.1. Robustness of the Proposed Model
The purpose of the robustness test is to investigate whether the daily data are non-stationary when the air quality receives the impact of high pollution. At this time, whether the model can still work normally and whether the forecasting accuracy fluctuates greatly are evaluated in this test. In this experiment, the data of the training set increases the ran-dom number in the range of (−2, 2), which is considered to be from random interference; then, observe the changes of each performance index; the comparison results are shown in
Table 8.
Before and after adding random disturbance, the MAPE values of Beijing were 1.39% and 1.48%, respectively; only 0.09% changed, and the same was true for other cities. After adding random disturbances, the forecasting accuracy of the proposed model changed slightly: Shijiazhuang changed by 0.29%, and Chengde changed by 0.18%. It can also be seen from
Table 7 that the average RMSE of the three observation cities of the original data model is 17.63, 21.03, and 13.50, respectively. Compared with the model with increased disturbance, the values of MAPE change by 2.49, 0.82, and 0.3, respectively, which clarifies that the random disturbance will not affect the forecasting performance. In addition, for the original data model, taking the predicted value of Beijing as an example, the average MAE is 12.45, and the standard deviation is 9.22. From the model, after increasing the disturbance, the average MAE increases slightly, the standard deviation increases to 13.97, the change range is 1.52, and the standard deviation change range is 1.36, which indicates that the random disturbance is not significant.
In summary, by observing the fluctuation of the forecasting results of each city, the forecasting performance of the model proposed in this paper has not changed significantly and still maintains an outstanding forecasting effect. Therefore, there is enough evidence to prove that although the air quality will be affected by other factors, such as high pollu-tion or other abnormal conditions, the proposed model can still have stability.
4.2. Differences of the Proposed Model
The discrepancy test of the forecasting system proposed in this paper will be further discussed in this section. To test whether the forecasting performance of the proposed hybrid forecasting model is significantly different from other forecasting models, the DM test and the MDM test are used to perform statistical tests.
From the experimental results in
Table 9, the loss series of the proposed hybrid fore-casting system passed the significance test at the 5% confidence level. It denotes that the proposed hybrid forecasting system has higher forecasting efficiency than other hybrid strategies, and it is not a coincidence that the forecasting is significantly different.
Compared with other models, the model proposed in this paper has the best results in any possible data environment. On the one hand, it performs spatial effect analysis and data feature extraction before data forecasting, which can better utilize the spatial and data features of the data for subsequent forecasting, and this is the excellence of the model. On the other hand, the system continuously updates the output conceptual values after k iterations by combining the geographic location of each data and does not directly output the forecasting results, but it eliminates the uniqueness of the data itself through fuzzy time series, and the forecasting results are more superior.
4.3. Application of the Proposed Model
The proposed model not only has outstanding forecasting performance but also has potential functions in practical applications. The early warning system consists of three modules: spatial feature analysis module, data preprocessing module, and fuzzy infor-mation prediction module. The following analyzes its practical significance from these three modules.
Air pollution has spatial spillover effects, so the spatial feature analysis module can comprehensively consider the interaction of urban agglomerations. In addition, it also provides theoretical support for the formulation of pollution control policies among urban agglomerations and facilitates coordinated governance among urban agglomerations.
In fact, air quality is affected by many factors, including information ambiguity and uncertainty. Through the data preprocessing module, it can remove the outliers and noise from the data, making the data features more obvious and achieving better forecasting performance.
Accurate AQI forecasting results can provide early warning information for actual life and production activities. From the perspective of the public, the forecasting of air quality can let the public understand the air quality, the scope of air quality dete-rioration, the degree of deterioration, and the development trend; secondly, it guides the daily activities and behaviors of residents, protects the physical and mental health of the people, and reduces the incidence of diseases. From the perspective of social economy, it can not only provide the theoretical basis for pollution control measures, such as strict control of motor vehicle pollution, reduction of coal consumption, shut-down of polluting enterprises, control of construction sites and road dust, and super-vision of factories with large pollutant emissions.
5. Conclusions
In terms of application, it is profoundly important to make accurate forecasts of air quality. The air environment is an important guarantee for people’s health and production safety, and understanding real-time AQI can provide a theoretical basis for establishing an early warning system on the one hand, and a tool for implementing pollution control policies on the other. However, because AQI has the complexity and nonlinearity of time series changes, and has spatial correlation among urban clusters, it is difficult to make accurate forecasting. Coupled with the fact that it is influenced by many factors and prone to fluctuations and singular values, it is even more challenging for the forecasting effect of the model. Therefore, this paper proposes a novel spatiotemporal hybrid forecasting system to realize the time series forecasting of AQI. Three comparative experiments were established using the air quality indices of thirteen cities in the Beijing-Tianjin-Hebei re-gion of China to analyze and demonstrate, and the results are as follows:
First, the spatial feature extraction module is built. The module successfully extracted the spatial overflow features, captured the dynamic transition of air quality, and per-formed cluster analysis with different sizes and weights for irregular data.
The adaptive Hampel filtering model improved by SSA is the best data processing sub-module for comparison with FCM, DHP-FCM, and HHP-FCM.
The first proposed HFCM forecasting model plays an irreplaceable role in time series forecasting in the same data preprocessing environment. The model reduced MAPE by 94.1083%, 96.9120%, and 98.2361% for three different urban clusters.
In the environment of different data preprocessing methods, the model proposed in this paper can still make accurate forecasts for data with large fluctuations and mu-tations. MAPE, RMSE, and MAE reach the minimum values in the three urban ag-glomerations.
In summary, the proposed air quality forecasting system has outstanding forecasting performance in handling low-quality and large-noise data. Although the model makes an accurate prediction by analyzing the spatial correlation between the target city and the adjacent city and excavating its internal relationship, this study also has shortcomings, and the stability needs to be improved when optimizing the Hampel parameter values for single objectives. In future research, we can consider a multi-objective optimization algorithm and select other urban agglomerations for research to further verify the superiority of the forecasting model proposed in this paper for air quality index forecasting.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}