

Parallel Learning of Dynamics in Complex Systems

Abstract
:1. Introduction
- (1)
- A novel algorithm: We propose a novel algorithm for graph partition, namely, Dynamics-METIS (D-METIS). D-METIS can partition a large graph into multiple subgraphs, and it innovatively considers two balances of the subgraphs, i.e., the balance of vertexes and the balance of cumulative dynamic changes.
- (2)
- A novel model: This novel model is called the Partitioned Graph Neural Dynamics Learner (PGNDL). The PGNDL is a parallel model that combines ordinary differential equation systems and GNN. Thus, it can quickly learn the dynamics of large graphs. It can also learn unequal interval (continuous-time) dynamics on any graph.
- (3)
- More efficient parallel general framework: The experimental results show that our framework completed the tasks on various graphs faster than the most well-known framework, NDCN [17], with at least twice the efficiency.
- (4)
- More accurate in regression tasks: The PGNDL (D-METIS) performs accurately on various dynamics and networks.
2. Related Work
2.1. Graph Partition
2.2. GNNs with ODE
3. Methodology
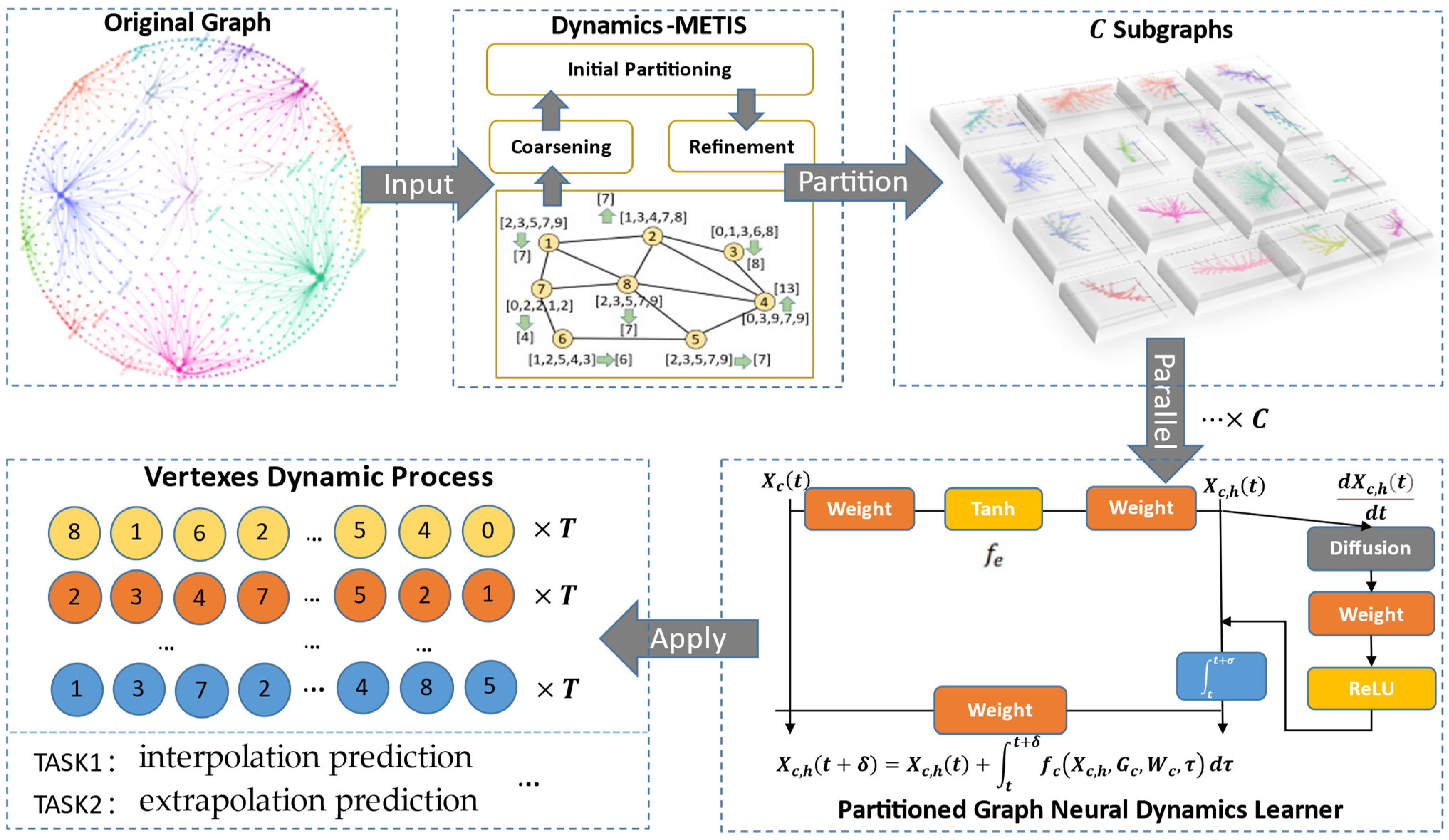
3.1. Dynamics METIS
- The graph structure damage caused by partitioning should be minimized;
- The structure of each subgraph should be evenly distributed to facilitate the synchronization and parallel assessment of downstream tasks;
- The distribution of the dynamics state change degree of each subgraph should be even and convenient for downstream application and analysis.
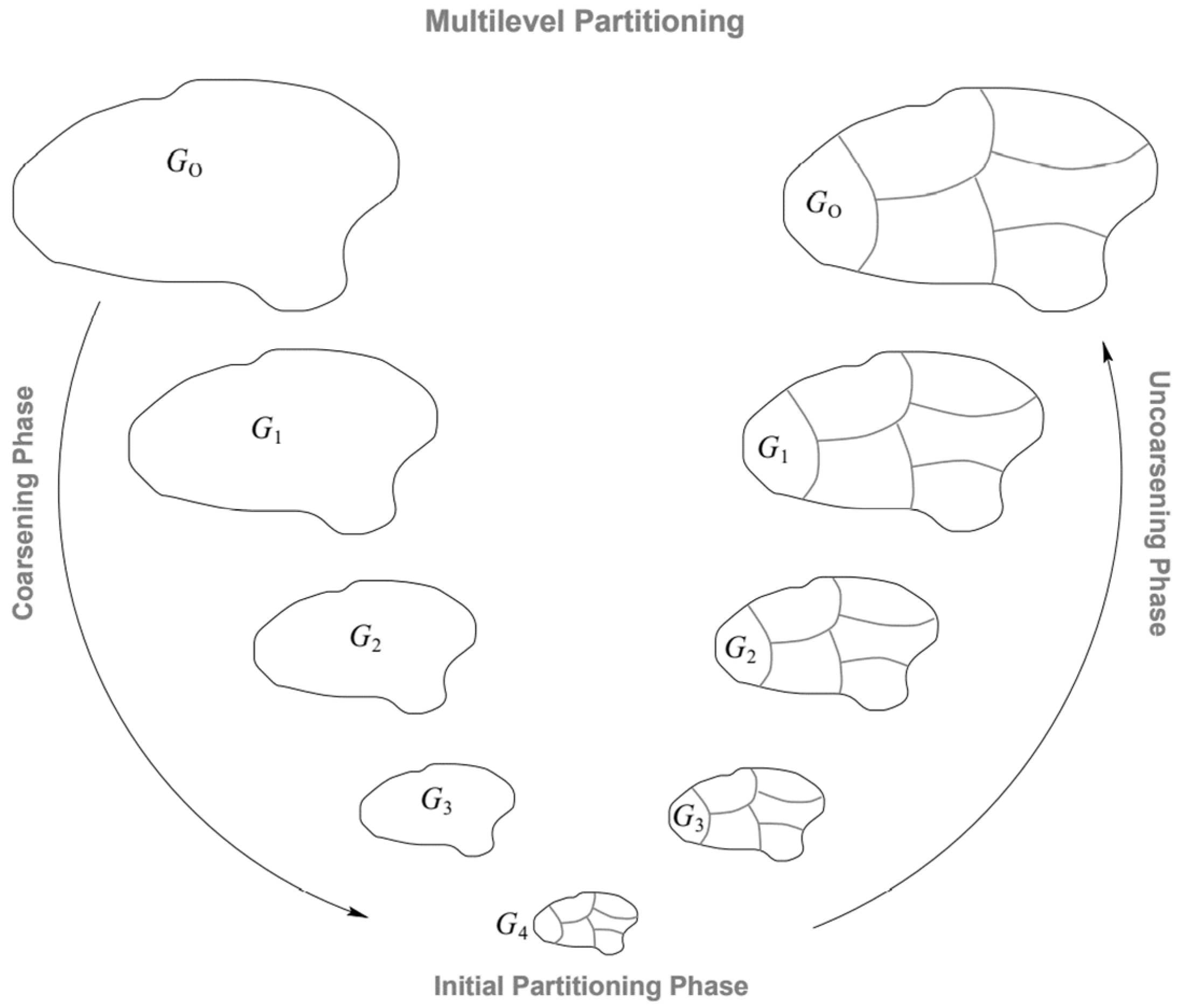
3.1.1. METIS Algorithm
3.1.2. METIS for a Graph with Dynamics
- Obtaining graph data;
- Compressing dynamics process information;
- Converting the adjacency matrix to Compressed Sparse Row (CSR) format;
- Coarsening;
- Initial partitioning;
- Refinement.
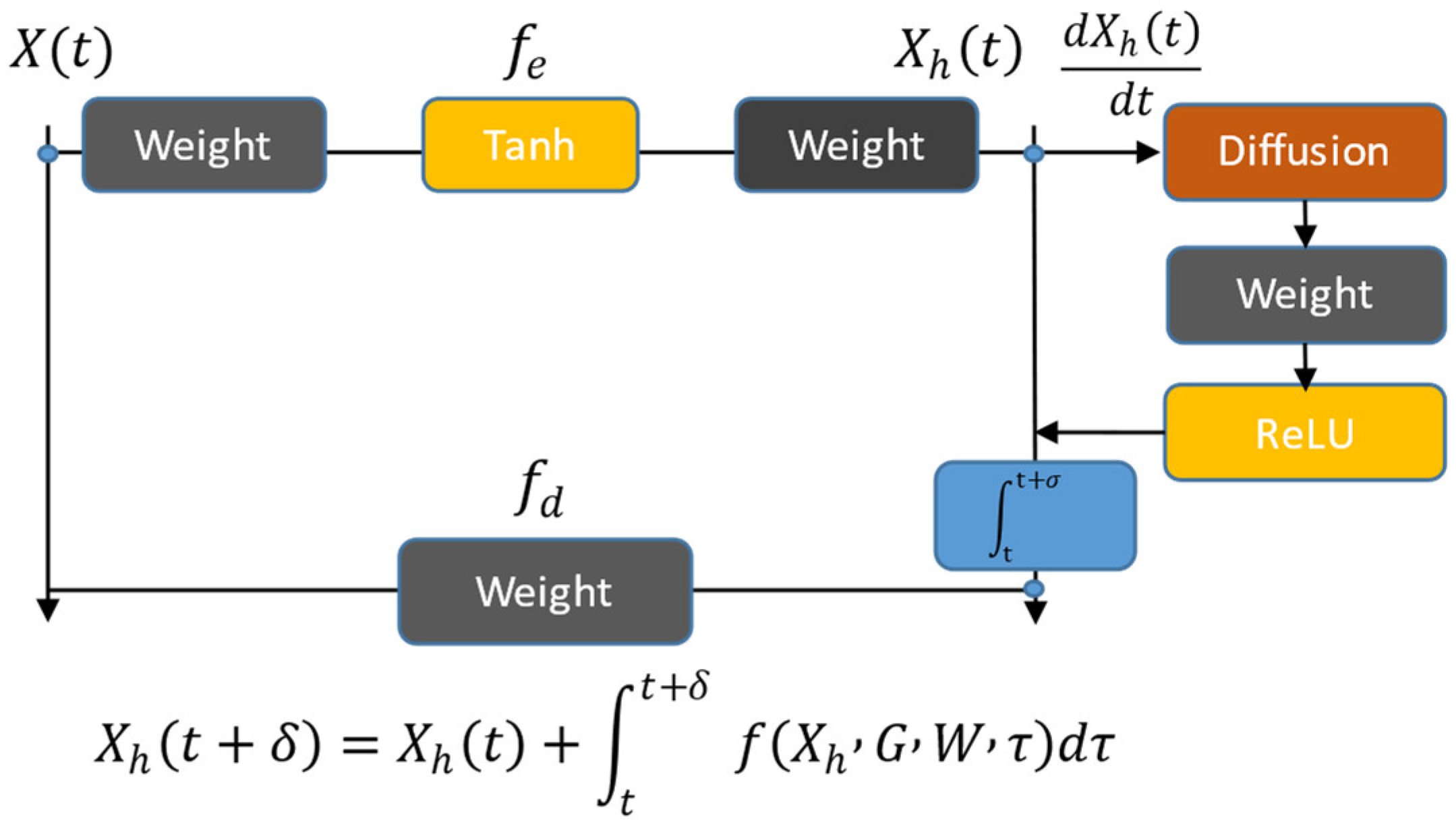
3.2. Partitioned Graph Neural Dynamics Learner
3.3. General Framework
4. Experiments
4.1. Setup
4.1.1. Datasets
4.1.2. Dynamics Simulation on the Graph
- Mutualistic interaction dynamics [35].
- This is a dynamic among species in ecology, and its equation is
- The operations there between vectors are element-wise. The mutualistic differential equation systems capture the abundance of species , consisting of incoming migration term , logistic growth with population capacity and Allee effect with cold-start threshold , and the mutualistic interaction term with interaction network .
- Gene-regulatory dynamics [36].
- This can be described by an equation as follows:
- where the first term models degradation when or dimerization when , and the second term captures genetic activation tuned by the Hill coefficient
- S (Susceptible), a susceptible person, refers to a healthy person who lacks immunity and is vulnerable to infection after contact with an infected person. I (Infectious), the patient, refers to the infectious patient, and the infection can be transmitted to S and changed into I; R (Recovered) refers to a person with immunity after recovery. If the disease is a lifelong immune infectious disease, a person cannot be changed into S or I again. If the immune period is limited, a person can be changed into S again and then be reinfected. The mathematical expression is
- The total number of people is . At time , the ratio of various groups to the total number of people is, respectively, recorded as and , and the number of various groups is and . When at the initial time, the initial ratio of the number of different types of people is . The average number of susceptible persons effectively contacted by each patient at each time point is λ, and the ratio of the number of cured patients to the total number of patients at each time point is μ.
4.2. Balance Analysis of D-METIS
4.2.1. Dynamic Cumulative Change of Subgraphs
4.2.2. Vertex Distribution of Subgraphs
4.3. Learning Graph Dynamics with Unequal Interval Sampling
4.3.1. Interpolation-Prediction Task

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Dynamics | Random | Power Law | Community | Small World |
|---|---|---|---|---|---|
| NDCN | SIS Dynamics | 0.023 | 0.287 | 0.025 | 0.037 |
| Mutualistic interaction | 0.472 | 0.341 | 0.831 | 0.436 | |
| Gene Regulation | 1.951 | 0.719 | 2.529 | 1.053 | |
| PGNDL (METIS) | SIS Dynamics | 0.005 | 0.291 | 0.012 | 0.033 |
| Mutualistic interaction | 0.503 | 0.437 | 0.523 | 0.393 | |
| Gene Regulation | 3.451 | 1.534 | 2.671 | 0.891 | |
| PGNDL (D-METIS) | SIS Dynamics | 0.004 ↑↑ | 0.273 ↑↑ | 0.011 ↑↑ | 0.033 ↑- |
| Mutualistic interaction | 0.460 ↑↑ | 0.486 ↓↓ | 0.457 ↑↑ | 0.407 ↑↓ | |
| Gene Regulation | 2.780 ↓↑ | 1.568 ↓↓ | 2.456 ↑↑ | 0.849 ↑↑ |
| Model | Dynamics | Random | Power Law | Community | Small World |
|---|---|---|---|---|---|
| NDCN | SIS Dynamics | 0.028 | 0.137 | 0.024 | 0.111 |
| Mutualistic interaction | 0.538 | 0.368 | 1.098 | 0.482 | |
| Gene Regulation | 11.150 | 1.248 | 24.090 | 1.110 | |
| PGNDL (METIS) | SIS Dynamics | 0.024 | 0.024 | 0.014 | 0.043 |
| Mutualistic interaction | 0.644 | 0.538 | 0.697 | 0.446 | |
| Gene Regulation | 11.582 | 2.085 | 47.890 | 2.892 | |
| PGNDL (D-METIS) | SIS Dynamics | 0.008 ↑↑ | 0.022 ↑↑ | 0.005 ↑↑ | 0.037 ↑↑ |
| Mutualistic interaction | 0.664 ↓↓ | 0.635 ↓↓ | 0.735 ↑↓ | 0.431 ↑↑ | |
| Gene Regulation | 10.141 ↓↑ | 1.548 ↓↑ | 35.250 ↓↑ | 2.030 ↓↑ |
| Model | Dynamics | Random | Power Law | Community | Small World |
|---|---|---|---|---|---|
| NDCN | SIS Dynamics | 0.017 | 0.021 | 0.008 | 0.021 |
| Mutualistic interaction | 0.223 | 0.245 | 0.434 | 0.227 | |
| Gene Regulation | 2.287 | 0.371 | 3.070 | 0.870 | |
| PGNDL (METIS) | SIS Dynamics | 0.009 | 0.019 | 0.014 | 0.024 |
| Mutualistic interaction | 0.516 | 0.390 | 0.512 | 0.300 | |
| Gene Regulation | 3.592 | 1.312 | 2.501 | 0.994 | |
| PGNDL (D-METIS) | SIS Dynamics | 0.005 ↑↑ | 0.020 ↑↓ | 0.006 ↑↑ | 0.019 ↑↑ |
| Mutualistic interaction | 0.420 ↓↑ | 0.360 ↓↑ | 0.220 ↑↑ | 0.210 ↑↑ | |
| Gene Regulation | 2.860 ↓↑ | 1.907 ↓↓ | 2.597 ↑↓ | 2.490 ↓↓ |
| Model | Dynamics | Random | Power Law | Community | Small World |
|---|---|---|---|---|---|
| NDCN | SIS Dynamics | 0.004 | 0.021 | 0.004 | 0.019 |
| Mutualistic interaction | 0.103 | 0.299 | 0.493 | 0.194 | |
| Gene Regulation | 15.710 | 0.548 | 25.940 | 1.258 | |
| PGNDL(METIS) | SIS Dynamics | 0.004 | 0.024 | 0.004 | 0.023 |
| Mutualistic interaction | 0.644 | 0.538 | 0.686 | 0.346 | |
| Gene Regulation | 11.582 | 2.025 | 54.130 | 3.271 | |
| PGNDL(D-METIS) | SIS Dynamics | 0.004 -- | 0.020 ↑↑ | 0.003 ↑↑ | 0.019 -↑ |
| Mutualistic interaction | 0.634 ↓↑ | 0.530 ↓↑ | 0.487 ↑↑ | 0.337 ↓↑ | |
| Gene Regulation | 10.611 ↑↓ | 2.034 ↓↓ | 32.640 ↓↑ | 2.625 ↓↑ |
4.3.2. Extrapolation-Prediction Task
4.3.3. Complexity and Time-Consumption Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
References
- Christensen, K.K.; Liebetrau, T. A new role for ‘the public’? Exploring cyber security controversies in the case of WannaCry. Intell. Natl. Secur. 2019, 34, 395–408. [Google Scholar] [CrossRef]
- Akaev, A.; Zvyagintsev, A.I.; Sarygulov, A.; Devezas, T.; Tick, A.; Ichkitidze, Y. Growth Recovery and COVID-19 Pandemic Model: Comparative Analysis for Selected Emerging Economies. Mathematics 2022, 10, 3654. [Google Scholar] [CrossRef]
- Abdelhamid, A.A.; El-Kenawy, E.-S.M.; Khodadadi, N.; Mirjalili, S.; Khafaga, D.S.; Alharbi, A.H.; Ibrahim, A.; Eid, M.M.; Saber, M. Classification of Monkeypox Images Based on Transfer Learning and the Al-Biruni Earth Radius Optimization Algorithm. Mathematics 2022, 10, 3614. [Google Scholar] [CrossRef]
- Doerr, B.; Fouz, M.; Friedrich, T. Why rumors spread so quickly in social networks. Commun. ACM 2012, 55, 70–75. [Google Scholar] [CrossRef]
- Fan, C.; Zeng, L.; Sun, Y.; Liu, Y.-Y. Finding key players in complex networks through deep reinforcement learning. Nat. Mach. Intell. 2020, 2, 317–324. [Google Scholar] [CrossRef]
- Tanaka, G.; Morino, K.; Aihara, K. Dynamical robustness in complex networks: The crucial role of low-degree nodes. Sci. Rep. 2012, 2, 232. [Google Scholar] [CrossRef] [Green Version]
- Acharya, A. An action for nonlinear dislocation dynamics. J. Mech. Phys. Solids 2022, 161, 104811. [Google Scholar] [CrossRef]
- Lyu, J.; Liu, F.; Ren, Y. Fuzzy identification of nonlinear dynamic system based on selection of important input variables. J. Syst. Eng. Electron. 2022, 33, 737–747. [Google Scholar] [CrossRef]
- Newman, M.E.; Barabási, A.L.E.; Watts, D.J. The Structure and Dynamics of Networks; Princeton University Press: Princeton, NJ, USA, 2011; Volume 12. [Google Scholar]
- Lü, J.; Wen, G.; Lu, R.; Wang, Y.; Zhang, S. Networked Knowledge and Complex Networks: An Engineering View. IEEE/CAA J. Autom. Sin. 2022, 9, 1366–1383. [Google Scholar] [CrossRef]
- Wood, R.K. Deterministic network interdiction. Math. Comput. Model. 1993, 17, 1–18. [Google Scholar] [CrossRef]
- Phillips, C.A. The network inhibition problem. In Proceedings of the Twenty-fifth Annual ACM Symposium on Theory of Computing, San Diego, CA, USA, 16–18 May 1993; pp. 776–785. [Google Scholar]
- Brockschmidt, M. GNN-FiLM: Graph Neural Networks with Feature-wise Linear Modulation. In Proceedings of the 37th International Conference on Machine Learning, PMLR 119, Virtual, 13–18 July 2020; pp. 1144–1152. [Google Scholar]
- Narayan, A.; Roe, P.H.O. Learning graph dynamics using deep neural networks. Ifac-Papersonline 2018, 51, 433–438. [Google Scholar] [CrossRef]
- Seo, Y.; Defferrard, M.; VanderGheynst, P.; Bresson, X. Structured sequence modeling with graph convolutional recurrent networks. In Proceedings of the International Conference on Neural Information, Siem Reap, Cambodia, 13–16 December 2018; Springer: Cham, Switzerland, 2018; pp. 362–373. [Google Scholar]
- Ma, S.; Liu, J.; Zuo, X. Survey on Graph Neural Network. J. Comput. Res. Dev. 2022, 59, 47–80. [Google Scholar]
- Zang, C.; Wang, F. Neural Dynamics on Complex Networks. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, ACM, Virtual Event, 6–10 July 2020; pp. 892–902. [Google Scholar]
- Stanton, I.; Kliot, G. Streaming graph partitioning for large distributed graphs. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’12, New York, NY, USA, 12–16 August 2012; pp. 1222–1230. [Google Scholar]
- Zhang, C.; Wei, F.; Liu, Q.; Tang, Z.G.; Li, Z. Graph edge partitioning via neighborhood heuristic. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; Volume 8, pp. 605–614. [Google Scholar]
- Tsourakakis, C.; Gkantsidis, C.; Radunovic, B.; Vojnovic, M. Fennel: Streaming graph partitioning for massive scale graphs. In Proceedings of the 7th ACM International Conference on Web Search and Data Mining, ACM, New York City, NY, USA, 24–28 February 2014; pp. 333–342. [Google Scholar]
- Karypis, G.; Kumar, V. A fast and high quality multilevel scheme for partitioning irregular graphs. SIAM J. Sci. Comput. 1998, 20, 359–392. [Google Scholar] [CrossRef]
- Xie, C.; Yan, L.; Li, W.J.; Zhang, Z. Distributed Power-Law Graph Computing: Theoretical and Empirical Analysis. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 1673–1681. [Google Scholar]
- Nazi, A.; Hang, W.; Goldie, A.; Ravi, S.; Mirhoseini, A. Gap: Generalizable approximate graph partitioning framework. arXiv 2019, arXiv:1903.00614. [Google Scholar]
- Craig, T. A Treatise on Linear Differential Equations. Nature 1890, 41, 508–509. [Google Scholar]
- Shampine, L.F. Computer Methods for Ordinary Differential Equations and Differential-Algebraic Equations (Book Review); SIAM Review: Philadelphia, PA, USA, 1999; Volume 41, pp. 400–401. [Google Scholar]
- Chen, R.T.Q.; Rubanova, Y.; Bettencourt, J.; Duvenaud, D.K. Neural Ordinary Differential Equations. Adv. Neural Inf. Process. Syst. 2018, 31, 6571–6583. [Google Scholar]
- Zhang, Y.; Guo, Y.; Zhang, Z.; Chen, M.; Wang, S.; Zhang, J. Universal framework for reconstructing complex networks and node dynamics from discrete or continuous dynamics data. Phys. Rev. E 2022, 106, 034315. [Google Scholar] [CrossRef]
- Yu, D.; Zhou, Y.; Zhang, S.; Liu, C. Heterogeneous Graph Convolutional Network-Based Dynamic Rumor Detection on Social Media. Complexity 2022, 2022, 8393736. [Google Scholar] [CrossRef]
- Hwang, J.; Choi, J.; Choi, H.; Lee, K.; Lee, D.; Park, N. Climate Modeling with Neural Diffusion Equations. In Proceedings of the 2021 IEEE International Conference on Data Mining (ICDM), Auckland, New Zealand, 7–10 December 2021. [Google Scholar]
- Wang, F.; Cui, P.; Pei, J.; Song, Y.; Zang, C. Recent Advances on Graph Analytics and Its Applications in Healthcare. In Proceedings of the KDD ’20: 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event, 6–10 July 2020. [Google Scholar]
- Erdős, P.; Rényi, A. On the evolution of random graphs. Publ. Math. Inst. Hung. Acad. Sci. 1960, 5, 17–60. [Google Scholar]
- Barabási, A.-L.; Albert, R. Emergence of scaling in random networks. Science 1999, 286, 509–512. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fortunato, S. Community detection in graphs. Phys. Rep. 2009, 486, 75–174. [Google Scholar] [CrossRef] [Green Version]
- Watts, D.J.; Strogatz, S.H. Collective dynamics of ‘small world’ networks. Nature 1998, 393, 440–442. [Google Scholar] [CrossRef] [PubMed]
- Gao, J.; Barzel, B.; Barabási, A.-L. Author Correction: Universal resilience patterns in complex networks. Nature 2019, 568, E5. [Google Scholar] [CrossRef] [Green Version]
- Alon, U. An Introduction to Systems Biology: Design Principles of Biological Circuits; Chapman & Hall/CRC: London, UK, 2007; 320p, ISBN 1584886420. GBP 30.99. [Google Scholar]
- Tong, Y.; Ahn, I.; Lin, Z. The impact factors of the risk index and diffusive dynamics of a SIS free boundary model. Infect. Dis. Model. 2022, 7, 605–624. [Google Scholar] [CrossRef] [PubMed]
- Jing, X.; Liu, G.; Jin, Z. Stochastic dynamics of an SIS epidemic on networks. J. Math. Biol. 2022, 84, 50. [Google Scholar] [CrossRef]






| Graphs | ||
|---|---|---|
| Random | 400 | 8050 |
| 2000 | 200,160 | |
| Power Law | 400 | 1975 |
| 2000 | 9975 | |
| Community | 400 | 1201 |
| 2000 | 159,866 | |
| Small World | 400 | 6308 |
| 2000 | 5976 |
| Model | Dynamics | Random | Power Law | Community | Small World |
|---|---|---|---|---|---|
| NDCN | SIS Dynamics | 66.8 | 67.6 | 64.1 | 67.4 |
| Mutualistic interaction | 74.8 | 75.8 | 74.6 | 73.2 | |
| Gene Regulation | 82.5 | 78.2 | 83.4 | 74.9 | |
| PGNDL (METIS) | SIS Dynamics | 35.4 | 30.2 | 37.6 | 29.5 |
| Mutualistic interaction | 35.5 | 30.4 | 37.8 | 29.8 | |
| Gene Regulation | 35.4 | 30.2 | 37.9 | 29.9 | |
| PGNDL (D-METIS) | SIS Dynamics | 34.2 | 28.5 | 36.8 | 28.2 |
| Mutualistic interaction | 33.4 | 28.7 | 37.2 | 28.4 | |
| Gene Regulation | 33.9 | 28.5 | 37.1 | 28.4 |
| Model | Dynamics | Random | Power Law | Community | Small World |
|---|---|---|---|---|---|
| NDCN | SIS Dynamics | 207.8 | 234.7 | 223.6 | 179.4 |
| Mutualistic interaction | 198.8 | 240.7 | 260.8 | 276.1 | |
| Gene Regulation | 342.9 | 238.5 | 432.3 | 286.8 | |
| PGNDL (METIS) | SIS Dynamics | 118.3 | 77.3 | 145.3 | 77.0 |
| Mutualistic interaction | 119.2 | 80.1 | 146.6 | 77.5 | |
| Gene Regulation | 118.6 | 79.7 | 147.8 | 77.4 | |
| PGNDL (D-METIS) | SIS Dynamics | 115.7 | 76.7 | 146.2 | 75.1 |
| Mutualistic interaction | 116.9 | 77.8 | 149.2 | 76.2 | |
| Gene Regulation | 116.1 | 77.3 | 148.5 | 77.5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, X.; Zhu, X.; Xu, X.; Zhang, Q.; Liang, A. Parallel Learning of Dynamics in Complex Systems. Systems 2022, 10, 259. https://doi.org/10.3390/systems10060259
Huang X, Zhu X, Xu X, Zhang Q, Liang A. Parallel Learning of Dynamics in Complex Systems. Systems. 2022; 10(6):259. https://doi.org/10.3390/systems10060259
Chicago/Turabian StyleHuang, Xueqin, Xianqiang Zhu, Xiang Xu, Qianzhen Zhang, and Ailin Liang. 2022. "Parallel Learning of Dynamics in Complex Systems" Systems 10, no. 6: 259. https://doi.org/10.3390/systems10060259