

Artificial Intelligence-Based Robust Hybrid Algorithm Design and Implementation for Real-Time Detection of Plant Diseases in Agricultural Environments

Abstract
:Simple Summary
Abstract
1. Introduction
- A robust hybrid model based on 2D-DWT is proposed for the real-time classification of plant leaf diseases with high accuracy.
- Feature groups are extracted for each family by applying 2D-DWT with the biorthogonal, Coiflet, Daubechies, Fejer–Korovkin, and symlet wavelet families to the image dataset consisting of apple, grape, and tomato plants. The extracted feature groups for each wavelet family consist of distinctive features representing each plant leaf disease.
- The features that keep classifier performance high for each wavelet family are selected by the wrapper approach, consisting of the population-based metaheuristic FPA and SVM algorithms. The fitness function is computed by considering both the number of features used in the model and the model’s performance in order to keep the model’s complexity and computation cost at a minimum level.
- The efficiency of the proposed optimization algorithm is determined by comparing it with the particle swarm optimization (PSO) algorithm.
- To overcome the model hyperparameter problem, the CNN classifier is used, which only has a classification layer without a feature extraction layer and uses the lowest number of features that can keep classification performance high.
- For the real-time plant leaf disease classification problem, the model with the best performance is proposed, which includes the 2D-DWT signal processing method based on the “sym7” wavelet family, the wrapper approach consisting of FPA and SVM, and a CNN classifier.
- The proposed model is embedded in the NVIDIA Jetson Nano developer kit on the UAV. Real-time classification tests have been performed on apple, grape, and tomato plants to demonstrate that the proposed model can classify plant leaf diseases in real time with high accuracy.
- The experimental results obtained show that the model has low computational complexity and a minimum computational load; therefore, it can be used in real-time applications that require high classification accuracy.
2. Framework of the Plant Diseases Detection Algorithm
2.1. Discrete Wavelet Transform
2.2. Multiresolution Analysis
2.3. Wavelet Families
2.3.1. Biorthogonal Wavelet
2.3.2. Coiflet Wavelet
2.3.3. Daubechies Wavelet
2.3.4. Fejer–Korovkin Wavelet
2.3.5. Symlets Wavelet
2.4. Two-Dimensional Discrete Wavelet Transform (2D-DWT)
2.5. Flower Pollination Algorithm
- (i)
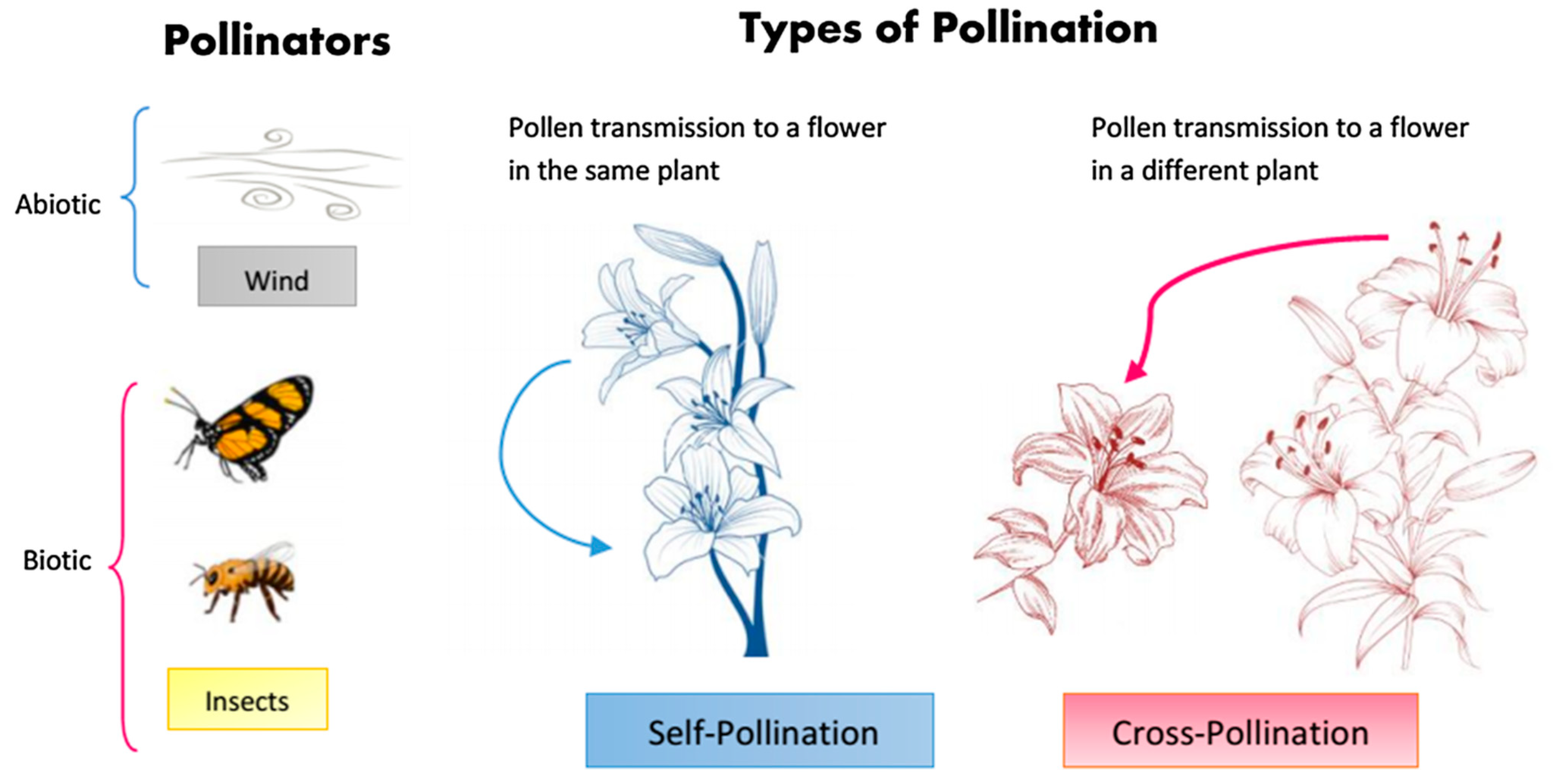
- Global pollination processes are carried out biotically, and pollinators carry pollen in the form of cross-pollination according to their Lévy flight.
- (ii)
- Abiotic pollination can occur in abiotic conditions, such as self-pollination and wind diffusion as local pollination.
- (iii)
- The coefficient called flower constancy is expressed as the probability of reproduction and varies in proportion to the similarity of flower species.
- (iv)
- Global pollination and local pollination are controlled by a switch probability . It is noted that indicates the percentage balance between local and global search in the optimization search field.
2.6. Convolutional Neural Network Classifier
2.7. Performance Metrics for Classification
2.8. Framework of the Proposed Methodology
3. Experimental Results and Discussion
3.1. Dataset
3.2. Applying 2D-DWT with Wavelet Families
3.3. Extraction of Statistical and Entropy-Based Features
3.4. Feature Selection with FPA-SVM Method
3.5. Evaluation of Plant Leaf Disease Classification Models and Discussion
4. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Savary, S.; Ficke, A.; Aubertot, J.; Hollier, C. Crop losses due to diseases and their implications for global food production losses and food security. Food Secur. 2012, 4, 519–537. [Google Scholar] [CrossRef]
- Ons, L.; Bylemans, D.; Thevissen, K.; Cammue, B.P. Combining biocontrol agents with chemical fungicides for integrated plant fungal disease control. Microorganisms 2020, 8, 1930. [Google Scholar] [CrossRef] [PubMed]
- Tewari, V.K.; Pareek, C.M.; Lal, G.; Dhruw, L.K.; Singh, N. Image processing based real-time variable-rate chemical spraying system for disease control in paddy crop. Artif. Intell. Agric. 2020, 4, 21–30. [Google Scholar] [CrossRef]
- Chadha, S.; Sharma, M.; Sayyed, A. Advances in sensing plant diseases by imaging and machine learning methods for precision crop protection. In Microbial Management of Plant Stresses; Woodhead Publishing: Cambridge, UK, 2021; pp. 157–183. [Google Scholar]
- Mohanty, S.P.; Hughes, D.P.; Salathé, M. Using deep learning for image-based plant disease detection. Front. Plant Sci. 2016, 7, 1419. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, N.; Yang, G.; Pan, Y.; Yang, X.; Chen, L.; Zhao, C. A review of advanced technologies and development for hyperspectral-based plant disease detection in the past three decades. Remote Sens. 2020, 12, 3188. [Google Scholar] [CrossRef]
- Barbedo, J.G.A.; Koenigkan, L.V.; Santos, T.T. Identifying multiple plant diseases using digital image processing. Biosyst. Eng. 2016, 147, 104–116. [Google Scholar] [CrossRef]
- Barbedo, J.G.A. Impact of dataset size and variety on the effectiveness of deep learning and transfer learning for plant disease classification. Comput. Electron. Agric. 2018, 153, 46–53. [Google Scholar] [CrossRef]
- Almadhor, A.; Rauf, H.T.; Lali, M.I.U.; Damaševičius, R.; Alouffi, B.; Alharbi, A. AI-driven framework for recognition of guava plant diseases through machine learning from DSLR camera sensor based high resolution imagery. Sensors 2021, 21, 3830. [Google Scholar] [CrossRef]
- Ali, H.; Lali, M.I.; Nawaz, M.Z.; Sharif, M.; Saleem, B.A. Symptom based automated detection of citrus diseases using color histogram and textural descriptors. Comput. Electron. Agric. 2017, 138, 92–104. [Google Scholar] [CrossRef]
- Wen, D.M.; Chen, M.X.; Zhao, L.; Ji, T.; Li, M.; Yang, X.T. Use of thermal imaging and Fourier transform infrared spectroscopy for the pre-symptomatic detection of cucumber downy mildew. Eur. J. Plant Pathol. 2019, 155, 405–416. [Google Scholar] [CrossRef]
- Singh, V.; Misra, A.K. Detection of plant leaf diseases using image segmentation and soft computing techniques. Inf. Process. Agric. 2017, 4, 41–49. [Google Scholar] [CrossRef] [Green Version]
- Saeed, F.; Khan, M.A.; Sharif, M.; Mittal, M.; Goyal, L.M.; Roy, S. Deep neural network features fusion and selection based on PLS regression with an application for crops diseases classification. Appl. Soft Comput. 2021, 103, 107164. [Google Scholar] [CrossRef]
- Ozguven, M.M.; Altas, Z. A new approach to detect mildew disease on cucumber (Pseudoperonospora cubensis) leaves with image processing. J. Plant Pathol. 2022, 104, 1–10. [Google Scholar] [CrossRef]
- Tan, L.; Lu, J.; Jiang, H. Tomato leaf diseases classification based on leaf images: A comparison between classical machine learning and deep learning methods. AgriEngineering 2021, 3, 542–558. [Google Scholar] [CrossRef]
- Kamal, K.C.; Yin, Z.; Wu, M.; Wu, Z. Depthwise separable convolution architectures for plant disease classification. Comput. Electron. Agric. 2019, 165, 104948. [Google Scholar]
- Atila, Ü.; Uçar, M.; Akyol, K.; Uçar, E. Plant leaf disease classification using EfficientNet deep learning model. Ecol. Inform. 2021, 61, 101182. [Google Scholar] [CrossRef]
- Li, Y.; Nie, J.; Chao, X. Do we really need deep CNN for plant diseases identification. Comput. Electron. Agric. 2020, 178, 105803. [Google Scholar] [CrossRef]
- Thangaraj, R.; Anandamurugan, S.; Kaliappan, V.K. Automated tomato leaf disease classification using transfer learning-based deep convolution neural network. J. Plant Dis. Prot. 2021, 128, 73–86. [Google Scholar] [CrossRef]
- Too, E.C.; Yujian, L.; Njuki, S.; Yingchun, L. A comparative study of fine-tuning deep learning models for plant disease identification. Comput. Electron. Agric. 2019, 161, 272–279. [Google Scholar] [CrossRef]
- Darwish, A.; Ezzat, D.; Hassanien, A.E. An optimized model based on convolutional neural networks and orthogonal learning particle swarm optimization algorithm for plant diseases diagnosis. Swarm Evol. Comput. 2020, 52, 100616. [Google Scholar] [CrossRef]
- Zhong, J.; Huang, Y. Time-frequency representation based on an adaptive short-time Fourier transform. IEEE Trans. Signal Process. 2010, 58, 5118–5128. [Google Scholar] [CrossRef]
- Li, L.; Cai, H.; Han, H.; Jiang, Q.; Ji, H. Adaptive short-time Fourier transform and synchrosqueezing transform for non-stationary signal separation. Signal Process. 2020, 166, 107231. [Google Scholar] [CrossRef]
- Kim, C.H.; Aggarwal, R. Wavelet transforms in power systems. Part 1: General introduction to the wavelet transforms. Power Eng. J. 2000, 14, 81–87. [Google Scholar]
- Grossmann, A.; Morlet, J. Decomposition of Hardy functions into square integrable wavelets of constant shape. SIAM J. Math. Anal. 1984, 15, 723–736. [Google Scholar] [CrossRef] [Green Version]
- Mallat, S.G. A theory for multiresolution signal decomposition: The wavelet representation. IEEE Trans. Pattern Anal. Mach. Intell. 1989, 11, 674–693. [Google Scholar] [CrossRef] [Green Version]
- Keinert, F. Biorthogonal wavelets for fast matrix computations. Appl. Comput. Harmon. Anal. 1994, 1, 147–156. [Google Scholar] [CrossRef] [Green Version]
- Monzón, L.; Beylkin, G.; Hereman, W. Compactly supported wavelets based on almost interpolating and nearly linear phase filters (coiflets). Appl. Comput. Harmon. Anal. 1999, 7, 184–210. [Google Scholar] [CrossRef] [Green Version]
- Daubechies, I. Ten Lectures on Wavelets; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 1992; ISBN 0-89871-274-2. [Google Scholar]
- Cohen, A.; Sun, Q. An arithmetic characterization of the conjugate quadrature filters associated to orthonormal wavelet bases. SIAM J. Math. Anal. 1993, 24, 1355–1360. [Google Scholar] [CrossRef]
- Daubechies, I. Orthonormal bases of compactly supported wavelets. Commun. Pure Appl. Math. 1988, 41, 909–996. [Google Scholar] [CrossRef] [Green Version]
- Daubechies, I. The wavelet transform, time-frequency localization and signal analysis. IEEE Trans. Inf. Theory 1990, 36, 961–1005. [Google Scholar] [CrossRef] [Green Version]
- Nielsen, M. On the construction and frequency localization of finite orthogonal quadrature filters. J. Approx. Theory 2001, 108, 36–52. [Google Scholar] [CrossRef] [Green Version]
- Mallat, S. A Wavelet Tour of Signal Processing, 2nd ed.; Elsevier: Berkeley, CA, USA, 1999; ISBN 978-0-12-466606-1. [Google Scholar]
- Gonzalez, R.C.; Woods, R.E. Digital Image Processing, 4th ed.; Pearson Education: Rotherham, UK, 2002; ISBN 978-0-13-335672-4. [Google Scholar]
- Yang, X.S. Flower Pollination Algorithm for Global Optimization. In International Conference on Unconventional Computing and Natural Computation; Springer: Berlin, Germany, 2012; pp. 240–249. [Google Scholar]
- Abdel-Basset, M.; El-Shahat, D.; El-Henawy, I.; Sangaiah, A.K. A modified flower pollination algorithm for the multidimensional knapsack problem: Human-centric decision making. Soft Comput. 2018, 22, 4221–4239. [Google Scholar] [CrossRef]
- Abdel-Basset, M.; Shawky, L.A. Flower pollination algorithm: A comprehensive review. Artif. Intell. Rev. 2019, 52, 2533–2557. [Google Scholar] [CrossRef]
- Gu, J.; Wang, Z.; Kuen, J.; Ma, L.; Shahroudy, A.; Shuai, B.; Liu, T.; Wang, X.; Wang, G.; Cai, J.; et al. Recent advances in convolutional neural networks. Pattern Recognit. 2018, 77, 354–377. [Google Scholar] [CrossRef] [Green Version]
- Ma, C.; Zhang, H.H.; Wang, X. Machine learning for big data analytics in plants. Trends Plant Sci. 2014, 19, 798–808. [Google Scholar] [CrossRef]
- Karasu, S.; Saraç, Z. The effects on classifier performance of 2D discrete wavelet transform analysis and whale optimization algorithm for recognition of power quality disturbances. Cogn. Syst. Res. 2022, 75, 1–15. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Wavelet Types | Scaling Function | Horizontal Wavelet | Vertical Wavelet | Diagonal Wavelet |
|---|---|---|---|---|
| Biorthogonal spline, bior2.4 |  |  |  |  |
| Coiflets, coif1 |  |  |  |  |
| Daubechies, db5 |  |  |  |  |
| Fejer-Korovkin, fk18 |  |  |  |  |
| Symlets, sym7 |  |  |  |  |
| Wavelet Family | Filter Length |
|---|---|
| Biorthogonal | (1.) 1, 3, 5, (2.) 2, 4, 6, 8, (3.) 1, 3, 5 |
| Coiflet | 1, 2, 3, 4, 5 |
| Daubechies | 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 |
| Fejer–Korovkin | 4, 6, 8, 14, 18, 22 |
| Symlet | 2, 3, 4, 5, 6, 7, 8 |
| 1 | 13 | 25 | 37 | 49 | 61 | 73 | 85 | |
| 2 | 14 | 26 | 38 | 50 | 62 | 74 | 86 | |
| 3 | 15 | 27 | 39 | 51 | 63 | 75 | 87 | |
| 4 | 16 | 28 | 40 | 52 | 64 | 76 | 88 | |
| 5 | 17 | 29 | 41 | 53 | 65 | 77 | 89 | |
| 6 | 18 | 30 | 42 | 54 | 66 | 78 | 90 | |
| 7 | 19 | 31 | 43 | 55 | 67 | 79 | 91 | |
| 8 | 20 | 32 | 44 | 56 | 68 | 80 | 92 | |
| 9 | 21 | 33 | 45 | 57 | 69 | 81 | 93 | |
| 10 | 22 | 34 | 46 | 58 | 70 | 82 | 94 | |
| 11 | 23 | 35 | 47 | 59 | 71 | 83 | 95 | |
| 12 | 24 | 36 | 48 | 60 | 72 | 84 | 96 |
| Label | Feature Name | Feature Expression |
|---|---|---|
| Arithmetic mean | ||
| Entropy | ||
| Standard deviation | ||
| Skewness | ||
| Kurtosis | ||
| Energy | ||
| MRV mean | ||
| MCV mean | ||
| Standard deviation of MRV | ||
| Standard deviation of MCV | ||
| MRV entropy | ||
| MCV entropy |
| Parameters | FPA-SVM | PSO-SVM |
|---|---|---|
| Number of solutions | 30 | 30 |
| Maximum number of iterations | 50 | 50 |
| Number of features | 96 | 96 |
| Threshold | 0.7 | 0.7 |
| Other parameters | switch probability = 0.4 levy component = 1.5 | cognitive factor = 2 social factor = 2 inertia weight = 1 |
| Fitness function | maximization of classifier performance & minimization of the number of selected features | |
| Wavelets | Num. | Selected Features | Accuracy (%) | |||
|---|---|---|---|---|---|---|
| CNN | SVM | KNN | ||||
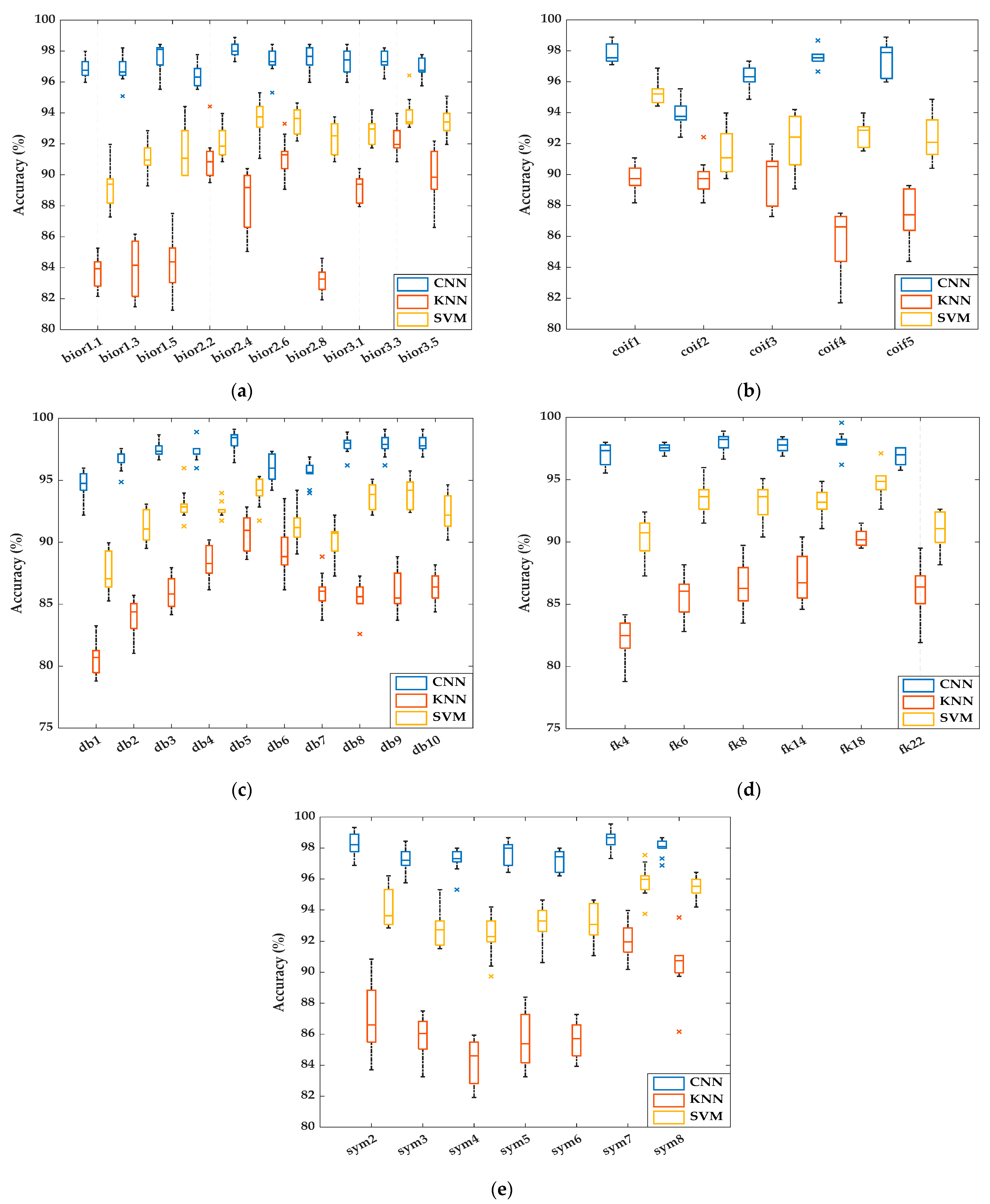
| Biorthogonal (bior) | 1.1 | 24 | 3, 4, 5, 14, 15, 16, 23, 24, 26, 33, 36, 45, 47, 48, 55, 56, 65, 75, 80, 85, 87, 88, 89, 92 | 96.90 ± 0.09 | 89.26 ± 0.36 | 83.66 ± 0.04 |
| 1.3 | 23 | 8, 17, 20, 22, 23, 25, 26, 28, 32, 37, 41, 44, 45, 52, 58, 60, 62, 63, 65, 74, 77, 84, 85 | 96.76 ± 0.11 | 91.05 ± 0.02 | 83.88 ± 0.07 | |
| 1.5 | 26 | 3, 4, 6, 15, 16, 21, 22, 27, 28, 29, 34, 37, 40, 43, 45, 48, 63, 64, 65, 69, 71, 76, 83, 90, 91, 94 | 97.68 ± 0.69 | 91.56 ± 0.63 | 84.22 ± 0.16 | |
| 2.2 | 17 | 4, 6, 28, 29, 34, 35, 41, 47, 50, 52, 55, 61, 62, 64, 65, 76, 83 | 96.45 ± 0.20 | 92.14 ± 0.27 | 91.00 ± 0.96 | |
| 2.4 | 21 | 1, 4, 5, 8, 23, 27, 28, 30, 34, 36, 41, 42, 47, 56, 57, 58, 65, 66, 87, 92, 93 | 98.08 ± 0.02 | 93.53 ± 0.33 | 88.50 ± 0.78 | |
| 2.6 | 19 | 4, 5, 9, 11, 16, 21, 23, 28, 31, 32, 33, 37, 40, 41, 52, 53, 57, 58, 75 | 97.34 ± 0.47 | 93.53 ± 0.11 | 91.12 ± 0.07 | |
| 2.8 | 21 | 10, 17, 19, 25, 28, 29, 33, 35, 37, 41, 47, 66, 67, 69, 70, 81, 82, 83, 84, 88, 95 | 97.50 ± 0.29 | 92.37 ± 0.07 | 83.21 ± 0.04 | |
| 3.1 | 20 | 1, 2, 3, 4, 5, 9, 15, 16, 19, 24, 26, 28, 40, 52, 61, 67, 70, 76, 82, 89 | 97.34 ± 0.13 | 92.90 ± 0.07 | 89.13 ± 0.04 | |
| 3.3 | 19 | 4, 5, 8, 16, 23, 26, 28, 29, 38, 52, 56, 62, 71, 74, 77, 78, 86, 87, 93 | 97.34 ± 0.13 | 93.95 ± 0.80 | 92.21 ± 0.20 | |
| 3.5 | 20 | 2, 4, 14, 16, 20, 21, 22, 28, 36, 37, 40, 41, 43, 46, 47, 51, 52, 58, 62, 72 | 96.90 ± 0.13 | 93.39 ± 0.13 | 90.00 ± 0.60 | |
| Coiflets (coif) | 1 | 24 | 4, 5, 8, 11, 14, 15, 16, 19, 28, 34, 35, 49, 50, 52, 58, 61, 62, 64, 68, 70, 84, 85, 89, 91 | 97.77 ± 0.22 | 95.29 ± 0.36 | 89.69 ± 0.07 |
| 2 | 14 | 2, 4, 12, 28, 34, 41, 50, 52, 59, 62, 64, 76, 83, 93 | 93.86 ± 0.11 | 91.38 ± 0.47 | 89.87 ± 0.42 | |
| 3 | 18 | 2, 4, 5, 6, 7, 8, 26, 29, 43, 45, 52, 56, 62, 64, 70, 76, 79, 96 | 96.32 ± 0.22 | 92.17 ± 0.54 | 89.89 ± 0.27 | |
| 4 | 23 | 7, 8, 17, 18, 21, 26, 28, 34, 35, 37, 42, 45, 49, 56, 57, 62, 65, 67, 80, 86, 88, 90, 95 | 97.57 ± 0.09 | 92.63 ± 0.11 | 85.87 ± 1.27 | |
| 5 | 19 | 4, 5, 18, 26, 27, 30, 36, 50, 51, 52, 59, 69, 70, 71, 72, 77, 83, 87, 89 | 97.54 ± 0.11 | 92.37 ± 0.27 | 87.30 ± 0.47 | |
| Daubechies (db) | 1 | 21 | 5, 8, 17, 18, 19, 25, 26, 28, 35, 36, 37, 44, 45, 53, 56, 65, 72, 77, 82, 83, 95 | 94.60 ± 0.51 | 87.48 ± 0.13 | 80.71 ± 0.31 |
| 2 | 22 | 2, 4, 11, 12, 16, 17, 20, 24, 27, 32, 37, 45, 52, 58, 59, 60, 64, 67, 78, 80, 88, 96 | 96.70 ± 0.49 | 91.27 ± 0.02 | 84.02 ± 0.65 | |
| 3 | 23 | 3, 4, 7, 15, 19, 21, 25, 28, 35, 39, 42, 50, 51, 52, 53, 67, 68, 75, 78, 80, 81, 93, 96 | 97.43 ± 0.22 | 93.04 ± 0.60 | 85.94 ± 0.11 | |
| 4 | 19 | 4, 12, 23, 26, 28, 29, 33, 34, 36, 37, 50, 53, 58, 60, 65, 67, 70, 87, 95 | 97.34 ± 0.09 | 92.59 ± 0.27 | 88.44 ± 0.27 | |
| 5 | 21 | 3, 4, 8, 14, 23, 26, 28, 32, 40, 41, 46, 48, 50, 58, 65, 70, 72, 75, 82, 83, 87 | 98.19 ± 0.42 | 94.11 ± 0.58 | 90.67 ± 0.04 | |
| 6 | 19 | 2, 4, 10, 21, 26, 28, 32, 38, 39, 41, 46, 47, 64, 72, 76, 82, 83, 91, 93 | 95.92 ± 0.16 | 91.38 ± 0.25 | 89.24 ± 0.60 | |
| 7 | 18 | 4, 6, 7, 8, 17, 19, 21, 23, 28, 32, 33, 36, 41, 58, 61, 64, 72, 85 | 95.63 ± 0.20 | 90.29 ± 0.56 | 86.05 ± 0.22 | |
| 8 | 27 | 1, 2, 4, 8, 12, 16, 22, 24, 25, 27, 28, 29, 32, 42, 50, 54, 56, 67, 73, 76, 82, 87, 88, 92, 94, 95, 96 | 97.88 ± 0.33 | 93.62 ± 0.02 | 85.60 ± 0.67 | |
| 9 | 24 | 3, 4, 7, 8, 10, 22, 28, 29, 32, 40, 41, 43, 45, 48, 50, 54, 56, 59, 74, 79, 87, 90, 91, 94 | 97.88 ± 0.22 | 93.93 ± 0.16 | 86.07 ± 0.20 | |
| 10 | 22 | 1, 4, 8, 17, 18, 19, 24, 26, 28, 36, 38, 42, 44, 46, 50, 68, 77, 82, 86, 87, 88, 90 | 97.88 ± 0.11 | 92.30 ± 0.11 | 86.41 ± 0.13 | |
| Fejer-Krovkin (fk) | 4 | 24 | 7, 8, 9, 16, 17, 20, 21, 23, 26, 28, 35, 37, 42, 45, 57, 61, 65, 69, 75, 79, 80, 86, 88, 96 | 96.99 ± 0.22 | 90.31 ± 0.47 | 82.19 ± 0.71 |
| 6 | 20 | 4, 5, 10, 11, 23, 27, 28, 30, 31, 32, 33, 37, 44, 52, 53, 55, 57, 58, 71, 75 | 97.52 ± 0.09 | 93.62 ± 0.13 | 85.69 ± 0.20 | |
| 8 | 23 | 3, 4, 8, 11, 21, 28, 32, 35, 38, 39, 40, 42, 45, 56, 67, 72, 73, 77, 81, 83, 91, 92, 94 | 97.97 ± 0.20 | 93.21 ± 0.47 | 86.58 ± 0.02 | |
| 14 | 21 | 3, 10, 11, 15, 17, 24, 26, 28, 29, 31, 32, 49, 53, 67, 68, 75, 76, 77, 80, 82, 91 | 97.70 ± 0.04 | 93.15 ± 0.18 | 87.17 ± 0.33 | |
| 18 | 23 | 4, 5, 9, 10, 12, 14, 17, 21, 25, 26, 27, 28, 35, 52, 62, 63, 65, 69, 70, 71, 73, 74, 79 | 97.99 ± 0.11 | 94.75 ± 0.11 | 90.33 ± 0.18 | |
| 22 | 21 | 2, 28, 29, 35, 36, 40, 41, 45, 46, 51, 53, 58, 64, 65, 69, 70, 79, 85, 86, 91, 94 | 96.81 ± 0.16 | 90.96 ± 0.56 | 86.03 ± 0.31 | |
| Symlets (sym) | 2 | 25 | 2, 4, 11, 13, 17, 22, 24, 28, 29, 35, 38, 64, 65, 69, 71, 72, 75, 76, 79, 80, 81, 87, 90, 92, 93 | 98.28 ± 0.18 | 94.13 ± 0.40 | 87.14 ± 0.13 |
| 3 | 21 | 2, 4, 6, 7, 8, 9, 19, 25, 28, 32, 35, 46, 52, 59, 65, 71, 75, 81, 84, 85, 89 | 97.21 ± 0.11 | 92.95 ± 0.47 | 85.83 ± 0.45 | |
| 4 | 20 | 3, 5, 11, 15, 19, 26, 27, 28, 35, 50, 60, 68, 69, 70, 74, 75, 76, 85, 87, 96 | 97.21 ± 0.56 | 92.28 ± 0.31 | 84.22 ± 0.29 | |
| 5 | 24 | 3, 4, 6, 11, 12, 14, 19, 26, 28, 31, 32, 39, 46, 48, 52, 47, 65, 66, 67, 83, 86, 88, 90, 91 | 97.68 ± 0.13 | 93.24 ± 0.60 | 85.65 ± 0.18 | |
| 6 | 20 | 4, 11, 27, 28, 35, 37, 38, 39, 53, 54, 56, 58, 69, 70, 71, 72, 77, 83, 86, 91 | 97.23 ± 0.13 | 93.15 ± 0.29 | 85.71 ± 0.11 | |
| 7 | 23 | 1, 4, 5, 8, 16, 21, 22, 26, 28, 34, 36, 40, 44, 45, 46, 47, 50, 52, 57, 80, 82, 87, 94 | 99.55 ± 0.13 | 97.54 ± 0.25 | 93.97 ± 0.04 | |
| 8 | 23 | 4, 13, 16, 28, 30, 35, 48, 50, 52, 63, 65, 67, 68, 69, 73, 76, 79, 82, 88, 90, 92, 93, 95 | 98.06 ± 0.29 | 95.47 ± 0.16 | 90.42 ± 0.58 | |
| Wavelets | Num. | Selected Features | Accuracy (%) | |||
|---|---|---|---|---|---|---|
| CNN | SVM | KNN | ||||
| Biorthogonal (bior) | 1.1 | 19 | 5, 11, 19, 26, 28, 29, 32, 40, 41, 45, 56, 62, 63, 64, 70, 75, 85, 87, 96 | 91.71 ± 0.04 | 84.93 ± 1.09 | 80.40 ± 0.36 |
| 1.3 | 21 | 3, 4, 5, 9, 11, 14, 15, 19, 21, 25, 27, 39, 46, 62, 63, 74, 76, 77, 84, 91, 93 | 92.03 ± 0.29 | 81.96 ± 0.02 | 74.28 ± 0.18 | |
| 1.5 | 23 | 3, 5, 8, 9, 10, 26, 28, 29, 31, 34, 37, 40, 41, 49, 56, 59, 62, 66, 79, 81, 87, 91, 92 | 92.90 ± 0.25 | 84.64 ± 0.54 | 78.17 ± 0.02 | |
| 2.2 | 17 | 1, 2, 4, 16, 26, 27, 28, 52, 53, 65, 69, 70, 78, 85, 86, 87, 96 | 91.11 ± 0.09 | 86.85 ± 0.78 | 85.31 ± 0.20 | |
| 2.4 | 18 | 3, 4, 5, 6, 17, 24, 26, 27, 28, 36, 40, 47, 53, 69, 76, 79, 80, 87 | 92.41 ± 0.02 | 86.42 ± 0.13 | 85.55 ± 0.04 | |
| 2.6 | 15 | 4, 16, 44, 47, 50, 52, 57, 60, 69, 70, 73, 76, 80, 81, 89 | 88.14 ± 0.18 | 82.34 ± 0.16 | 79.19 ± 0.63 | |
| 2.8 | 19 | 12, 16, 23, 28, 35, 41, 42, 43, 45, 51, 59, 66, 67, 72, 73, 76, 79, 90, 96 | 93.10 ± 0.45 | 87.32 ± 0.02 | 81.49 ± 0.22 | |
| 3.1 | 20 | 1, 9, 12, 14, 15, 16, 20, 24, 28, 29, 31, 32, 34, 57, 63, 77, 87, 88, 92, 94 | 92.96 ± 0.09 | 86.42 ± 0.13 | 82.47 ± 0.20 | |
| 3.3 | 21 | 1, 2, 6, 12, 13, 29, 35, 37, 40, 44, 52, 53, 57, 62, 64, 67, 70, 77, 83, 86, 89 | 92.79 ± 0.09 | 85.29 ± 0.33 | 78.23 ± 0.47 | |
| 3.5 | 19 | 2, 5, 7, 12, 14, 16, 28, 31, 38, 42, 51, 60, 66, 67, 72, 79, 83, 89, 92 | 92.74 ± 0.20 | 87.16 ± 0.65 | 83.21 ± 0.27 | |
| Coiflets (coif) | 1 | 19 | 3, 4, 10, 11, 17, 35, 36, 37, 50, 56, 59, 61, 68, 73, 84, 88, 89, 92, 95 | 92.23 ± 0.09 | 85.29 ± 0.22 | 79.71 ± 0.22 |
| 2 | 22 | 4, 13, 14, 15, 24, 28, 33, 35, 36, 39, 50, 52, 53, 58, 66, 68, 69, 76, 87, 89, 93, 96 | 92.94 ± 0.27 | 87.92 ± 0.18 | 85.58 ± 0.16 | |
| 3 | 20 | 1, 4, 6, 7, 13, 19, 21, 26, 28, 29, 45, 46, 52, 63, 68, 71, 76, 79, 82, 90 | 93.17 ± 0.04 | 89.44 ± 0.20 | 85.64 ± 0.02 | |
| 4 | 17 | 4, 12, 17, 20, 23, 26, 36, 46, 50, 52, 53, 56, 57, 58, 72, 79, 95 | 93.43 ± 0.01 | 89.33 ± 0.09 | 85.71 ± 0.02 | |
| 5 | 17 | 8, 16, 18, 20, 23, 24, 28, 31, 32, 33, 39, 42, 43, 49, 72, 76, 79 | 91.58 ± 0.27 | 84.44 ± 0.16 | 78.83 ± 0.02 | |
| Daubechies (db) | 1 | 16 | 4, 5, 11, 17, 28, 35, 37, 39, 44, 51, 52, 56, 65, 88, 91, 95 | 93.70 ± 0.42 | 84.84 ± 0.33 | 80.82 ± 0.13 |
| 2 | 19 | 8, 16, 17, 20, 27, 28, 35, 36, 37, 48, 52, 57, 60, 63, 64, 65, 80, 87, 88 | 91.71 ± 1.07 | 85.71 ± 0.20 | 81.83 ± 0.11 | |
| 3 | 19 | 4, 7, 8, 24, 26, 28, 32, 34, 35, 36, 46, 53, 54, 58, 61, 76, 83, 87, 91 | 91.40 ± 0.02 | 85.60 ± 0.47 | 78.81 ± 0.56 | |
| 4 | 23 | 4, 12, 17, 22, 23, 26, 35, 40, 41, 42, 44, 50, 51, 54, 55, 60, 62, 63, 65, 67, 72, 76, 94 | 94.21 ± 0.11 | 89.55 ± 0.36 | 83.54 ± 0.71 | |
| 5 | 21 | 4, 8, 17, 22, 23, 24, 26, 28, 31, 40, 43, 58, 64, 65, 67, 72, 73, 80, 81, 88, 89 | 93.79 ± 0.20 | 89.75 ± 0.56 | 85.69 ± 0.18 | |
| 6 | 24 | 4, 6, 16, 17, 19, 21, 22, 26, 28, 29, 32, 35, 38, 41, 43, 53, 75, 76, 79, 80, 82, 86, 90, 91 | 94.87 ± 0.04 | 90.15 ± 0.29 | 87.00 ± 0.18 | |
| 7 | 19 | 5, 7, 10, 12, 14, 15, 21, 26, 28, 37, 40, 50, 57, 59, 65, 83, 89, 92, 94 | 93.28 ± 0.38 | 86.87 ± 0.09 | 81.77 ± 0.25 | |
| 8 | 17 | 4, 14, 17, 18, 19, 24, 26, 28, 29, 32, 34, 50, 62, 65, 66, 73, 80 | 91.56 ± 0.25 | 84.10 ± 0.29 | 78.21 ± 0.16 | |
| 9 | 18 | 5, 22, 26, 28, 35, 36, 37, 39, 44, 46, 47, 56, 62, 77, 86, 88, 92, 93 | 92.65 ± 0.01 | 84.30 ± 0.02 | 79.04 ± 0.33 | |
| 10 | 22 | 5, 9, 11, 12, 14, 15, 16, 26, 36, 37, 40, 46, 47, 53, 55, 60, 68, 70, 80, 91, 92, 93 | 93.72 ± 0.07 | 85.87 ± 0.13 | 78.17 ± 0.31 | |
| Fejer-Krovkin (fk) | 4 | 19 | 10, 12, 17, 28, 29, 32, 41, 43, 58, 72, 76, 78, 83, 85, 87, 88, 93, 94, 96 | 91.89 ± 0.47 | 82.63 ± 0.36 | 79.01 ± 0.13 |
| 6 | 20 | 4, 7, 17, 22, 25, 32, 34, 35, 37, 39, 44, 47, 48, 53, 54, 61, 64, 80, 86, 90 | 90.60 ± 0.38 | 82.50 ± 0.11 | 77.09 ± 0.27 | |
| 8 | 21 | 2, 6, 8, 16, 28, 36, 39, 40, 42, 48, 51, 59, 60, 64, 68, 69, 70, 71, 72, 91, 93 | 92.23 ± 0.25 | 85.93 ± 0.42 | 79.24 ± 0.02 | |
| 14 | 16 | 3, 15, 19, 26, 28, 31, 32, 48, 52, 55, 57, 58, 62, 72, 77, 85 | 90.93 ± 0.07 | 84.24 ± 0.38 | 79.44 ± 0.16 | |
| 18 | 20 | 5, 8, 15, 16, 24, 26, 31, 34, 37, 49, 52, 61, 62, 76, 79, 80, 85, 88, 92, 94 | 92.88 ± 0.11 | 86.47 ± 0.29 | 80.49 ± 1.34 | |
| 22 | 21 | 4, 7, 8, 9, 20, 21, 22, 25, 26, 34, 45, 51, 52, 62, 64, 69, 75, 76, 81, 84, 95 | 92.74 ± 0.36 | 87.29 ± 0.45 | 81.98 ± 0.27 | |
| Symlets (sym) | 2 | 20 | 4, 5, 9, 11, 21, 23, 26, 28, 29, 32, 35, 41, 46, 52, 67, 69, 73, 79, 80, 88 | 91.89 ± 0.02 | 83.86 ± 0.02 | 78.41 ± 0.63 |
| 3 | 19 | 2, 4, 5, 12, 15, 21, 28, 37, 43, 44, 45, 51, 57, 62, 65, 73, 76, 94, 95 | 92.61 ± 0.38 | 87.18 ± 0.33 | 82.74 ± 0.13 | |
| 4 | 18 | 3, 17, 19, 21, 26, 28, 40, 52, 54, 60, 65, 72, 74, 79, 85, 90, 92, 95 | 91.56 ± 0.13 | 85.89 ± 0.16 | 80.75 ± 0.49 | |
| 5 | 23 | 10, 16, 17, 18, 21, 22, 26, 28, 29, 31, 39, 56, 64, 72, 75, 81, 82, 85, 91, 92, 93, 95, 96 | 93.41 ± 0.09 | 87.96 ± 0.33 | 80.96 ± 0.25 | |
| 6 | 16 | 4, 16, 17, 21, 27, 28, 37, 45, 60, 61, 66, 67, 68, 77, 80, 92 | 91.36 ± 0.16 | 86.96 ± 0.11 | 83.28 ± 0.22 | |
| 7 | 18 | 5, 9, 16, 19, 20, 28, 41, 47, 50, 52, 64, 67, 70, 78, 80, 78, 90, 95 | 90.33 ± 0.02 | 83.59 ± 0.02 | 79.50 ± 0.25 | |
| 8 | 15 | 4, 23, 28, 29, 32, 39, 46, 51, 52, 60, 67, 70, 76, 78, 88 | 90.13 ± 0.18 | 86.65 ± 0.25 | 84.04 ± 1.09 | |
| Feature Selection Method | Wavelet | Classifier | Accuracy (%) | Precision (%) | Recall (%) | F1 score (%) |
|---|---|---|---|---|---|---|
| PSO-SVM | db6 | CNN | 94.87 | 95.06 | 94.61 | 94.77 |
| SVM | 90.15 | 90.21 | 89.62 | 89.73 | ||
| KNN | 87.00 | 87.64 | 85.86 | 86.26 | ||
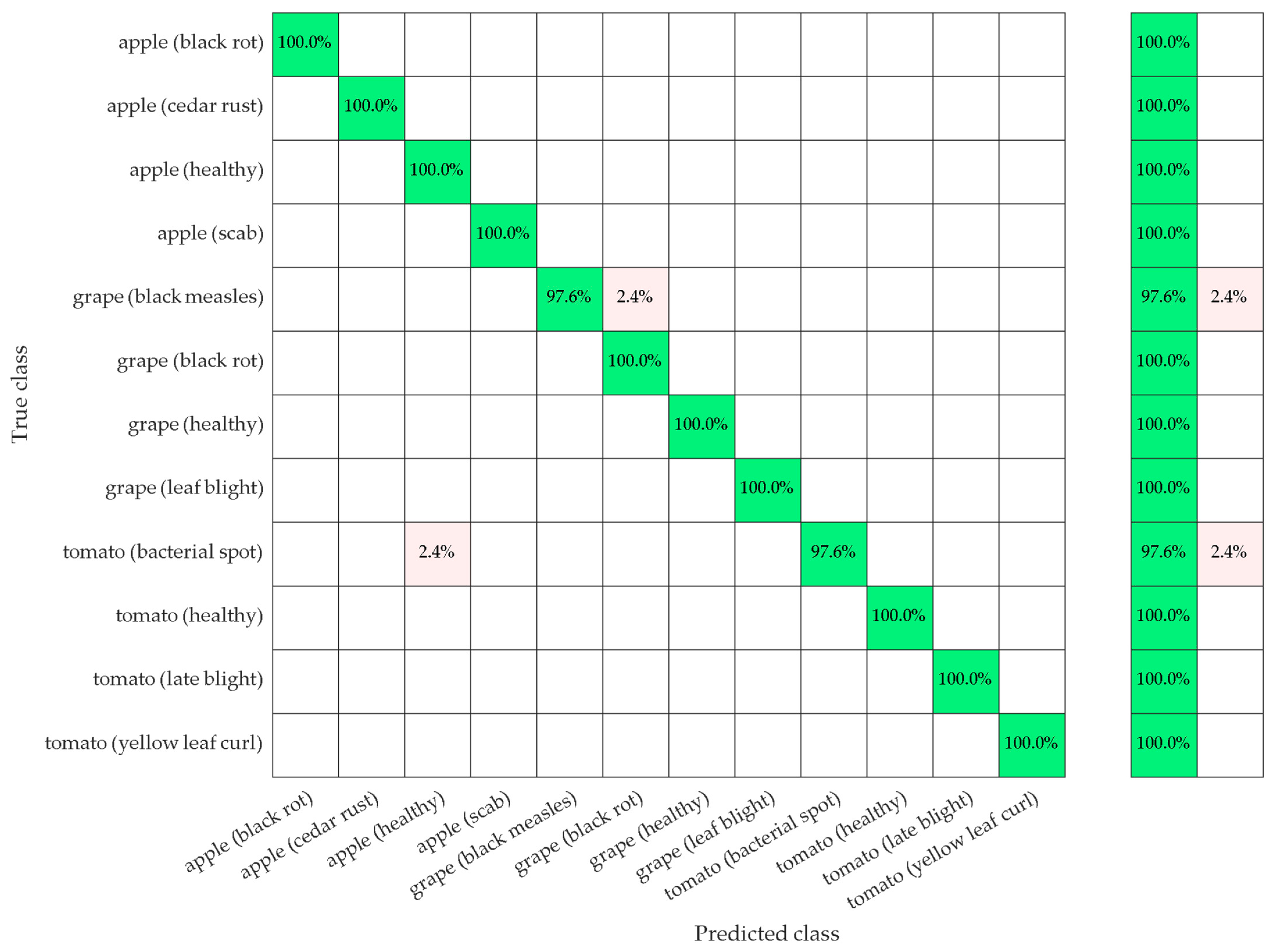
| FPA-SVM (proposed) | sym7 | CNN | 99.55 | 99.52 | 99.60 | 99.56 |
| SVM | 97.54 | 97.58 | 96.44 | 96.92 | ||
| KNN | 93.97 | 94.25 | 93.82 | 93.84 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yağ, İ.; Altan, A. Artificial Intelligence-Based Robust Hybrid Algorithm Design and Implementation for Real-Time Detection of Plant Diseases in Agricultural Environments. Biology 2022, 11, 1732. https://doi.org/10.3390/biology11121732
Yağ İ, Altan A. Artificial Intelligence-Based Robust Hybrid Algorithm Design and Implementation for Real-Time Detection of Plant Diseases in Agricultural Environments. Biology. 2022; 11(12):1732. https://doi.org/10.3390/biology11121732
Chicago/Turabian StyleYağ, İlayda, and Aytaç Altan. 2022. "Artificial Intelligence-Based Robust Hybrid Algorithm Design and Implementation for Real-Time Detection of Plant Diseases in Agricultural Environments" Biology 11, no. 12: 1732. https://doi.org/10.3390/biology11121732