
Phylogenomic Analyses of the Genus Pseudomonas Lead to the Rearrangement of Several Species and the Definition of New Genera

 , , and
, , and 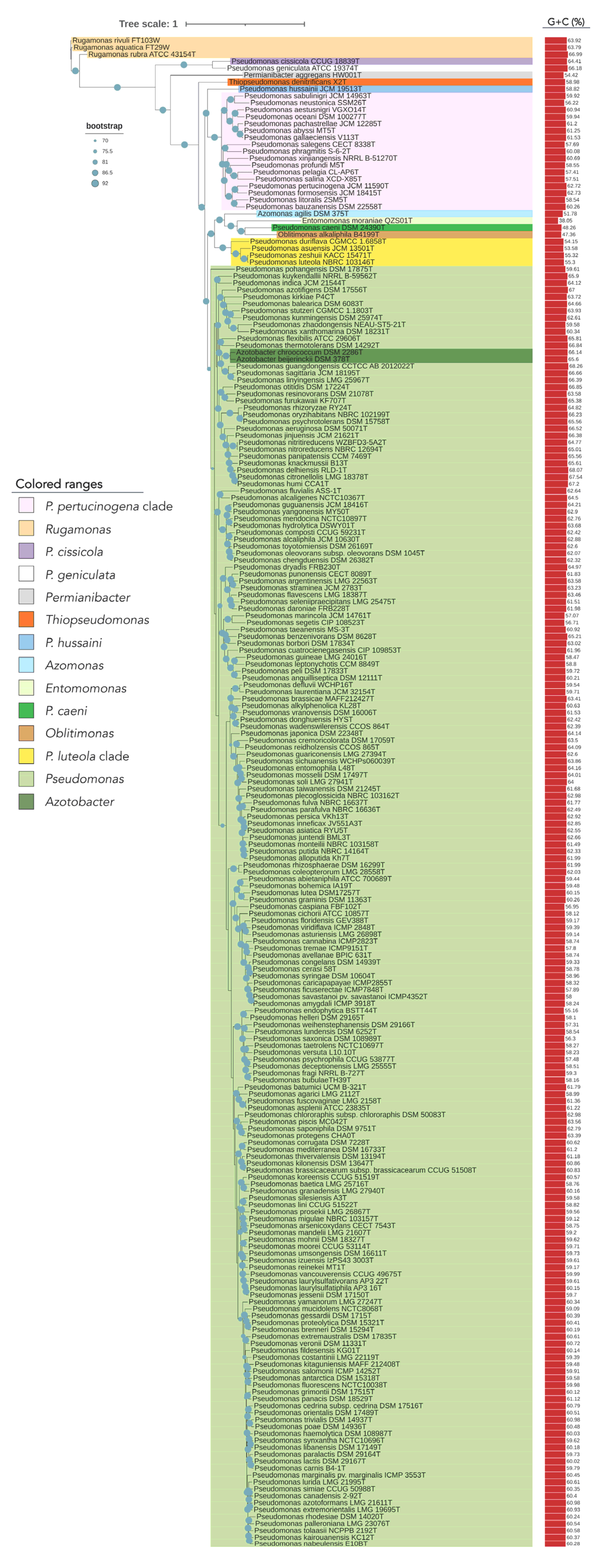{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:Simple Summary
Abstract
1. Introduction
2. Materials and Methods
2.1. Genome Sequence Data and Annotation
2.2. Phylogenetics and Phylogenomics
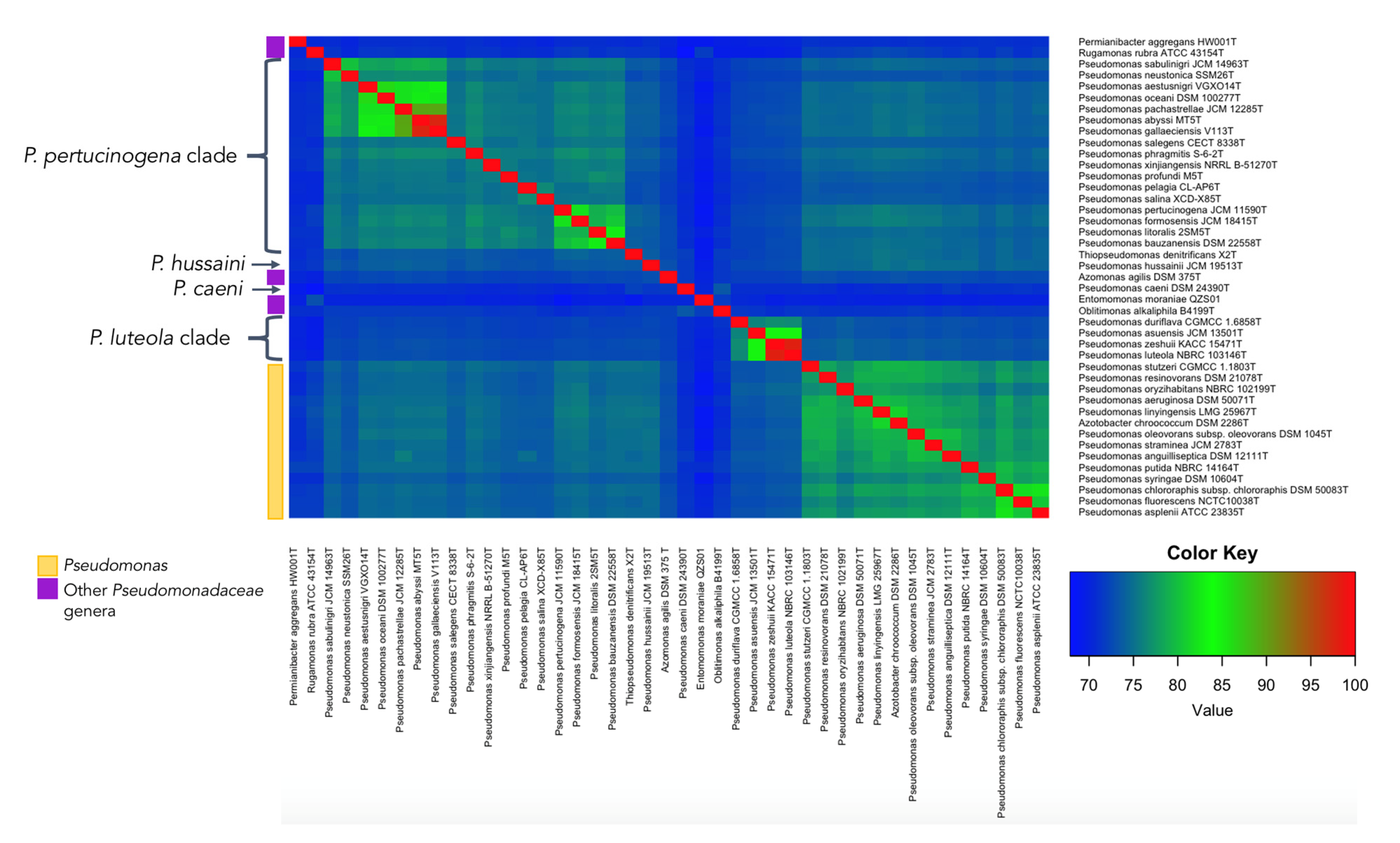
2.3. OGRI Analyses
2.4. Comparative Genomics and a Genome Wide Association Study (GWAS)
3. Results and Discussion
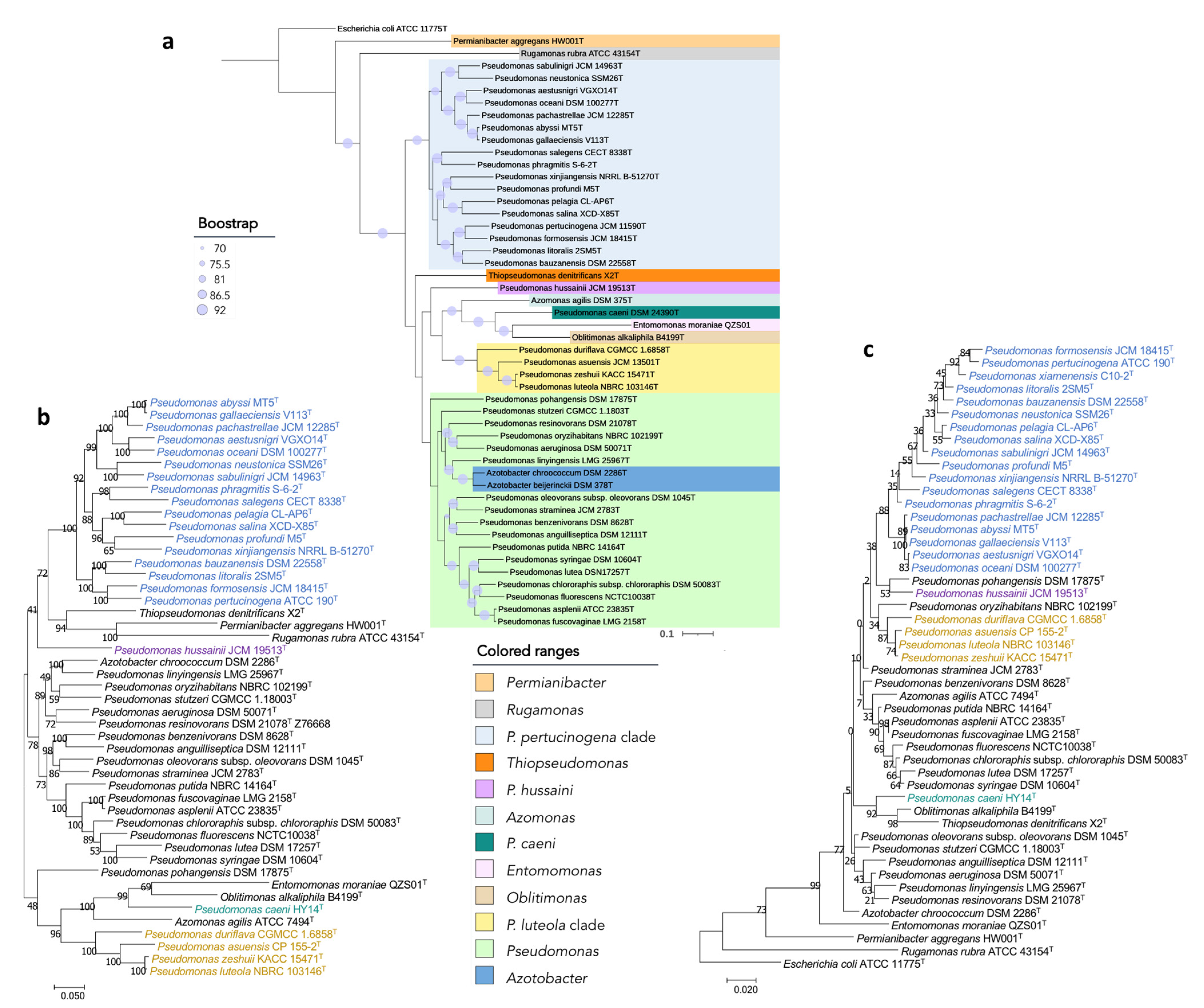
3.1. Phylogenomics in Pseudomonadaceae
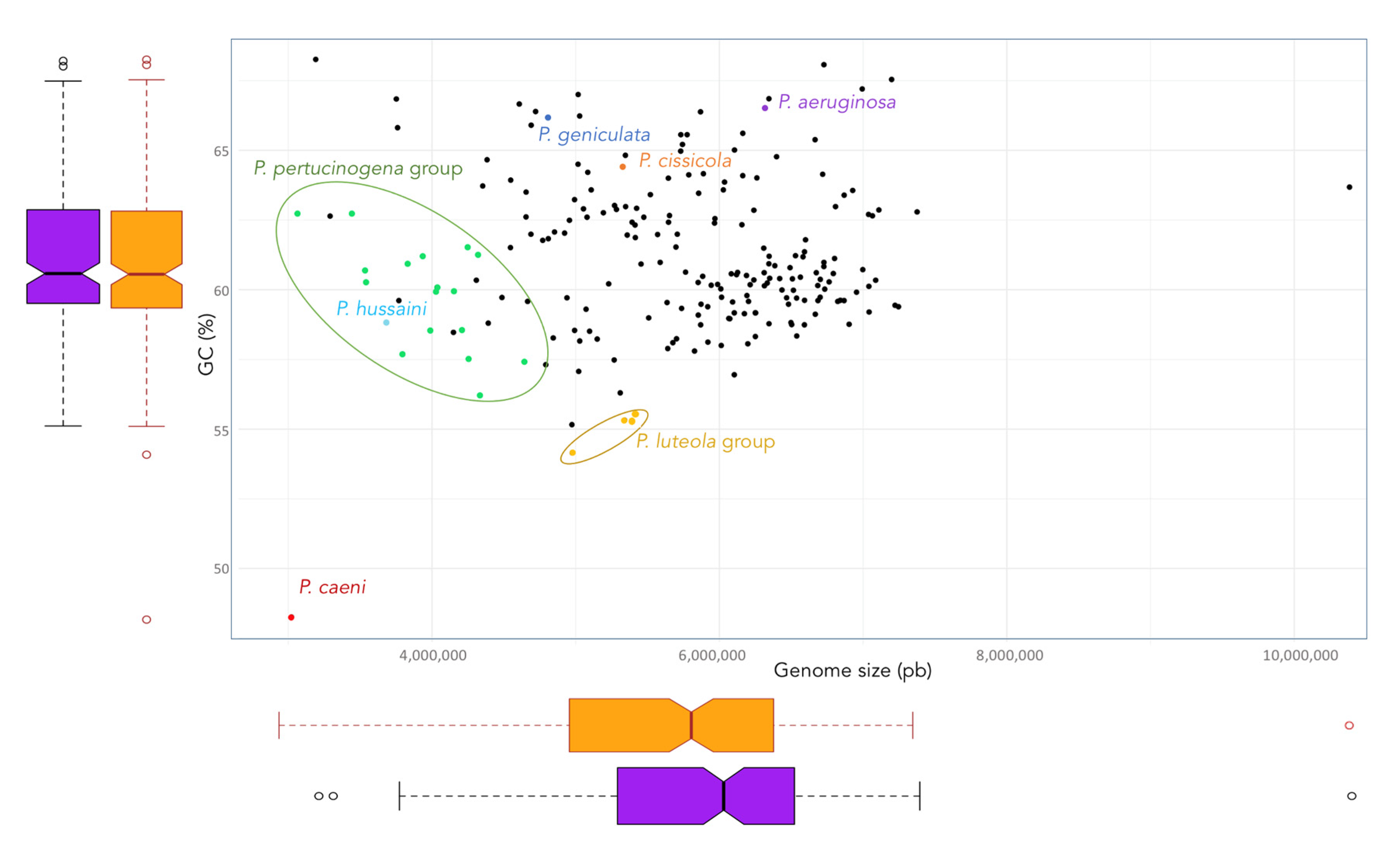
3.2. Taxonomic Status of Phylogenetically Distant Lineages and Clades
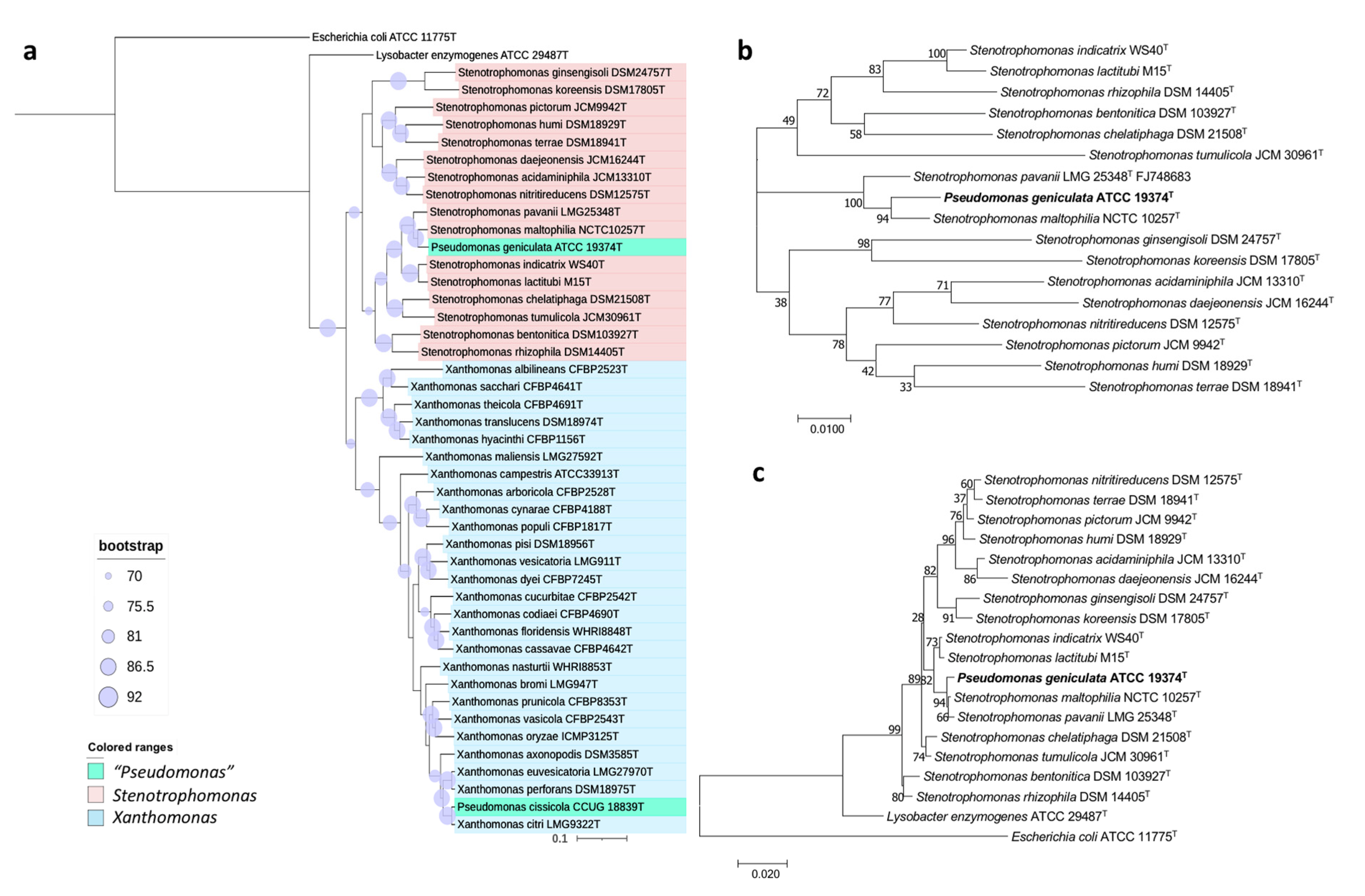
3.2.1. Pseudomonas geniculata
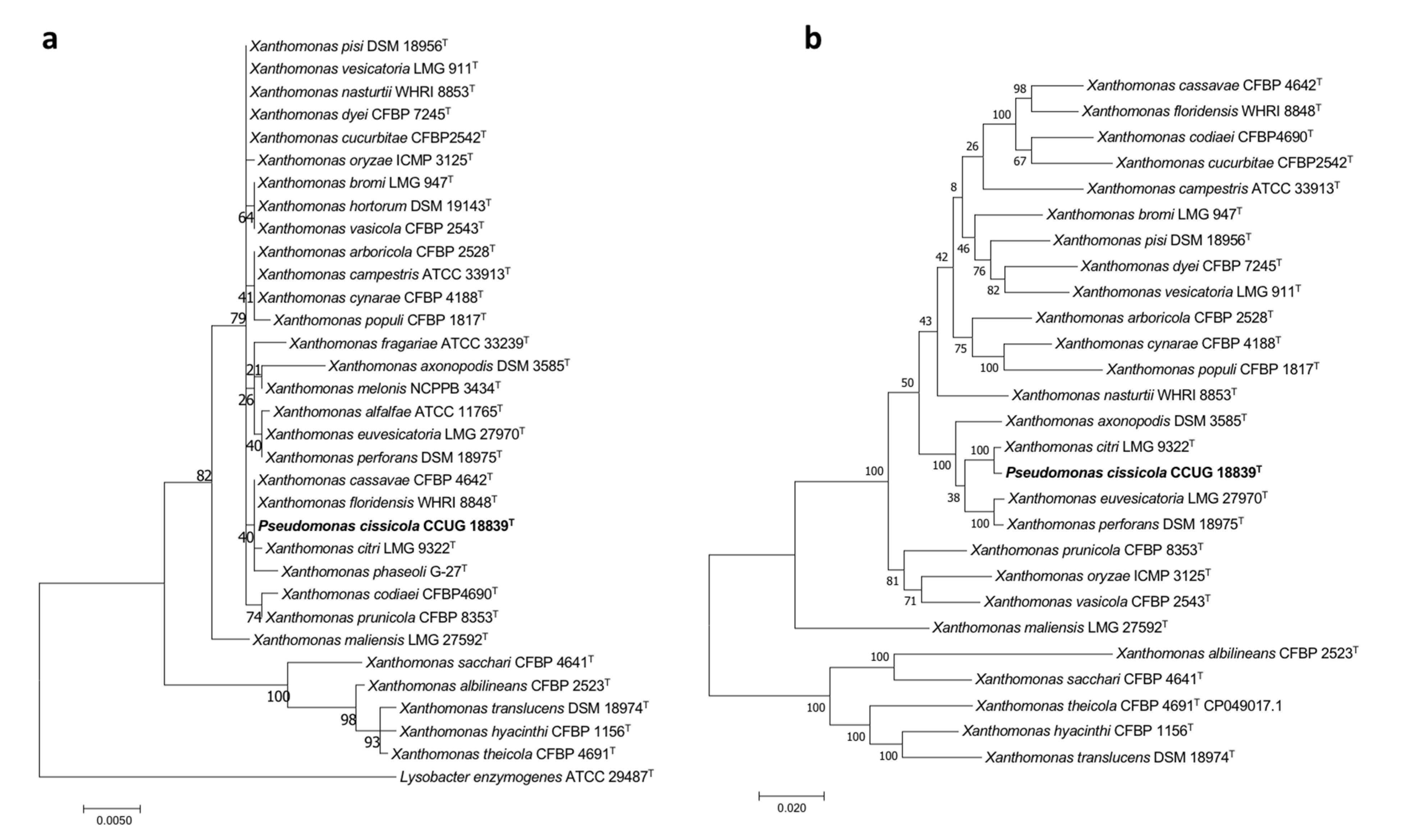
3.2.2. Pseudomonas cissicola
3.2.3. Pseudomonas caeni
3.2.4. P. hussainii
3.2.5. Pseudomonas luteola Clade
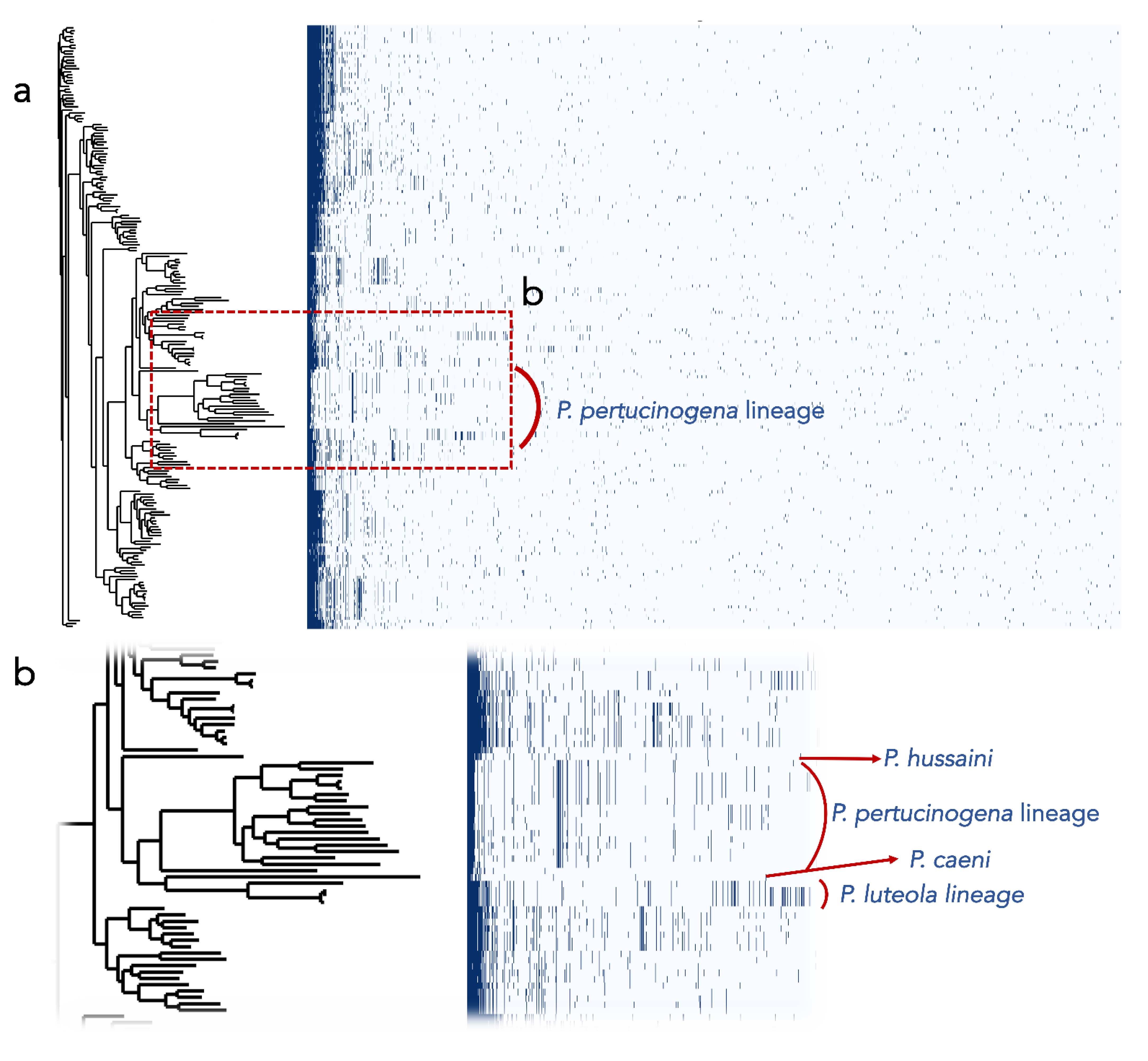
3.2.6. Pseudomonas pertucinogena Clade
4. Conclusions
5. Description of New Taxa
5.1. Description of Stenotrophomonas geniculata comb. nov.
5.2. Description of Denitrificimonas gen. nov.
5.3. Description of Denitrificimonas caeni comb. nov.
5.4. Description of Parapseudomonas gen nov.
5.5. Description of Parapseudomonas hussainii comb. nov.
5.6. Description of Chryseomonas asuensis comb. nov.
5.7. Description of Chryseomonas duriflava comb. nov.
5.8. Description of Neopseudomonas gen. nov.
5.9. Description of Neopseudomonas abyssi comb. nov.
5.10. Description of Neopseudomonas aestusnigri comb. nov.
5.11. Description of Neopseudomonas bauzanensis comb. nov.
5.12. Description of Neopseudomonas formosensis comb. nov.
5.13. Description of Neopseudomonas litoralis comb. nov.
5.14. Description of Neopseudomonas neustonica comb. nov.
5.15. Description of Neopseudomonas oceani comb. nov.
5.16. Description of Neopseudomonas pachastrellae comb. nov.
5.17. Description of Neopseudomonas pelagia comb. nov.
5.18. Description of Neopseudomonas pertucinogena comb. nov.
5.19. Description of Neopseudomonas phragmitis comb. nov.
5.20. Description of Neopseudomonas profundi comb. nov.
5.21. Description of Neopseudomonas sabulinigri comb. nov.
5.22. Description of Neopseudomonas salegens comb. nov.
5.23. Description of Neopseudomonas salina comb. nov.
5.24. Description of Neopseudomonas xinjiangensis comb. nov.
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Silby, M.W.; Winstanley, C.; Godfrey, S.A.; Levy, S.B.; Jackson, R.W. Pseudomonas genomes: Diverse and adaptable. FEMS Microbiol. Rev. 2011, 35, 652–680. [Google Scholar] [CrossRef] [Green Version]
- Saati-Santamaría, Z.; Selem-Mojica, N.; Peral-Aranega, E.; Rivas, R.; García-Fraile, P. Unveiling the Genomic Potential of Pseudomonas type Strains for Discovering New Natural Products. Microb. Genomics. under review.
- Peix, A.; Ramírez-Bahena, M.H.; Velázquez, E. Historical evolution and current status of the taxonomy of genus Pseudomonas. Infect Genet. Evol. 2009, 9, 1132–1147. [Google Scholar] [CrossRef] [PubMed]
- Peix, A.; Ramírez-Bahena, M.H.; Velázquez, E. The current status on the taxonomy of Pseudomonas revisited: An update. Infect. Genet. Evol. 2018, 57, 106–116. [Google Scholar] [CrossRef]
- Saati-Santamaría, Z.; Rivas, R.; Kolarik, M.; García-Fraile, P. A New Perspective of Pseudomonas—Host Interactions: Distribution and Potential Ecological Functions of the Genus Pseudomonas Within the Bark Beetle Holobiont. Biology 2021, 10, 164. [Google Scholar] [CrossRef]
- Behzadi, P.; Baráth, Z.; Gajdács, M. It’s not easy being green: A narrative review on the microbiology, virulence and therapeutic prospects of multidrug-resistant Pseudomonas aeruginosa. Antibiotics 2021, 10, 42. [Google Scholar] [CrossRef] [PubMed]
- David, B.V.; Chandrasehar, G.; Selvam, P.N. Pseudomonas fluorescens: A plant-growth-promoting rhizobacterium (PGPR) with potential role in biocontrol of pests of crops. In Crop Improvement through Microbial Biotechnology; Elsevier: Amsterdam, The Netherlands, 2018; pp. 221–243. [Google Scholar]
- Jiménez-Gómez, A.; Saati-Santamaría, Z.; Kostovcik, M.; Rivas, R.; Velázquez, E.; Mateos, P.F.; García-Fraile, P. Selection of the Root Endophyte Pseudomonas brassicacearum CDVBN10 as Plant Growth Promoter for Brassica napus L. Crops. Agronomy 2020, 10, 1788. [Google Scholar] [CrossRef]
- Teoh, M.C.; Furusawa, G.; Singham, G.V. Multifaceted interactions between the pseudomonads and insects: Mechanisms and prospects. Arch. Microbiol. 2021, 203, 1891–1915. [Google Scholar] [CrossRef] [PubMed]
- Saati-Santamaría, Z.; Rivas, R.; Kolařik, M.; García-Fraile, P. Associations Between Bark Beetles and Pseudomonas. In Developmental Biology in Prokaryotes and Lower Eukaryotes; Villa, T.G., de Miguel Bouzas, T., Eds.; Springer: Cham, Switzerland, 2021. [Google Scholar]
- Anzai, Y.; Kim, H.; Park, J.Y.; Wakabayashi, H.; Oyaizu, H. Phylogenetic affiliation of the pseudomonads based on 16S rRNA sequence. Int. J. Syst. Evol. Microbiol. 2000, 50, 1563–1589. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lalucat, J.; Mulet, M.; Gomila, M.; García-Valdés, E. Genomics in bacterial taxonomy: Impact on the genus Pseudomonas. Genes 2020, 11, 139. [Google Scholar] [CrossRef] [Green Version]
- Inkpen, S.A.; Douglas, G.M.; Brunet, T.D.P.; Leuschen, K.; Doolittle, W.F.; Langille, M.G. The coupling of taxonomy and function in microbiomes. Biol. Philos. 2017, 32, 1225–1243. [Google Scholar] [CrossRef]
- Bortolus, A. Error cascades in the biological sciences: The unwanted consequences of using bad taxonomy in ecology. AMBIO A J. Hum. Environ. 2008, 37, 114–118. [Google Scholar] [CrossRef]
- Mulet, M.; Lalucat, J.; García-Valdés, E. DNA Sequence–Based analysis of the Pseudomonas species. Environ. Microbiol. 2010, 12, 1513–1530. [Google Scholar] [PubMed] [Green Version]
- Saati-Santamaría, Z.; López-Mondéjar, R.; Jiménez-Gómez, A.; Díez-Méndez, A.; Větrovský, T.; Igual, J.M.; García-Fraile, P. Discovery of phloeophagus beetles as a source of Pseudomonas strains that produce potentially new bioactive substances and description of Pseudomonas bohemica sp. nov. Front. Microbiol. 2018, 9, 913. [Google Scholar] [CrossRef] [Green Version]
- Peral-Aranega, E.; Saati-Santamaría, Z.; Kolařik, M.; Rivas, R.; García-Fraile, P. Bacteria belonging to Pseudomonas typographi sp. nov. from the bark beetle Ips typographus have genomic potential to aid in the host ecology. Insects 2020, 11, 593. [Google Scholar] [CrossRef]
- Richter, M.; Rosselló-Móra, R. Shifting the genomic gold standard for the prokaryotic species definition. Proc. Natl. Acad. Sci. USA 2009, 106, 19126–19131. [Google Scholar] [CrossRef] [Green Version]
- Chun, J.; Oren, A.; Ventosa, A.; Christensen, H.; Arahal, D.R.; da Costa, M.S.; Trujillo, M.E. Proposed minimal standards for the use of genome data for the taxonomy of prokaryotes. Int. J. Syst. Evol. Microbiol. 2018, 68, 461–466. [Google Scholar] [CrossRef] [PubMed]
- Lee, M.D. GToTree: A user-friendly workflow for phylogenomics. Bioinformatics 2019, 35, 4162–4164. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hördt, A.; López, M.G.; Meier-Kolthoff, J.P.; Schleuning, M.; Weinhold, L.M.; Tindall, B.J.; Göker, M. Analysis of 1000+ type-strain genomes substantially improves taxonomic classification of Alphaproteobacteria. Front. Microbiol. 2020, 11, 468. [Google Scholar] [CrossRef]
- Carro, L.; Nouioui, I.; Sangal, V.; Meier-Kolthoff, J.P.; Trujillo, M.E.; del Carmen Montero-Calasanz, M.; Goodfellow, M. Genome-based classification of micromonosporae with a focus on their biotechnological and ecological potential. Sci. Rep. 2018, 8, 1–23. [Google Scholar]
- Nouioui, I.; Carro, L.; García-López, M.; Meier-Kolthoff, J.P.; Woyke, T.; Kyrpides, N.C.; Göker, M. Genome-based taxonomic classification of the phylum Actinobacteria. Front. Microbiol. 2018, 9, 2007. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wittouck, S.; Wuyts, S.; Lebeer, S. Towards a genome-based reclassification of the genus Lactobacillus. Appl. Environ. Microbiol. 2019, 85, e02155-18. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kimes, N.E.; López-Pérez, M.; Flores-Félix, J.D.; Ramirez-Bahena, M.H.; Igual, J.M.; Peix, A.; Velázquez, E. Pseudorhizobium pelagicum gen. nov., sp. nov. isolated from a pelagic Mediterranean zone. Syst. Appl. Microbiol. 2015, 38, 293–299. [Google Scholar] [CrossRef] [PubMed]
- Menéndez, E.; Flores-Félix, J.D.; Ramírez-Bahena, M.H.; Igual, J.M.; García-Fraile, P.; Peix, A.; Velázquez, E. Genome analysis of Endobacterium cerealis, a novel genus and species isolated from Zea mays roots in North Spain. Microorganisms 2020, 8, 939. [Google Scholar] [CrossRef]
- Ma, Y.; Wu, X.; Li, S.; Tang, L.; Chen, M.; An, Q. Proposal for reunification of the genus Raoultella with the genus Klebsiella and reclassification of Raoultella electrica as Klebsiella electrica comb. nov. Res. Microbiol. 2021, 103851, in press. [Google Scholar] [CrossRef] [PubMed]
- Hesse, C.; Schulz, F.; Bull, C.T.; Shaffer, B.T.; Yan, Q.; Shapiro, N.; Loper, J.E. Genome-based evolutionary history of Pseudomonas spp. Environ. Microbiol. 2018, 20, 2142–2159. [Google Scholar] [CrossRef]
- Nikolaidis, M.; Mossialos, D.; Oliver, S.G.; Amoutzias, G.D. Comparative analysis of the core proteomes among the Pseudomonas major evolutionary groups reveals species-specific adaptations for Pseudomonas aeruginosa and Pseudomonas chlororaphis. Diversity 2020, 12, 289. [Google Scholar] [CrossRef]
- Aziz, R.K.; Bartels, D.; Best, A.A.; DeJongh, M.; Disz, T.; Edwards, R.A.; Zagnitko, O. The RAST Server: Rapid annotations using subsystems technology. BMC Genomics 2008, 9, 1–15. [Google Scholar] [CrossRef] [Green Version]
- Gurevich, A.; Saveliev, V.; Vyahhi, N.; Tesler, G. QUAST: Quality assessment tool for genome assemblies. Bioinformatics 2013, 29, 1072–1075. [Google Scholar] [CrossRef]
- Wickham, H. ggplot2. Wiley Interdiscip. Rev. Comput. Stat. 2011, 3, 180–185. [Google Scholar] [CrossRef]
- Kumar, S.; Stecher, G.; Tamura, K. MEGA7: Molecular evolutionary genetics analysis version 7.0 for bigger datasets. Mol. Biol. Evol. 2016, 33, 1870–1874. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jiménez-Gómez, A.; Saati-Santamaría, Z.; Igual, J.M.; Rivas, R.; Mateos, P.F.; García-Fraile, P. Genome insights into the novel species Microvirga brassicacearum, a rapeseed endophyte with biotechnological potential. Microorganisms 2019, 7, 354. [Google Scholar] [CrossRef] [Green Version]
- Yoon, S.H.; Ha, S.M.; Kwon, S.; Lim, J.; Kim, Y.; Seo, H.; Chun, J. Introducing EzBioCloud: A taxonomically united database of 16S rRNA gene sequences and whole-genome assemblies. Int. J. Syst. Evol. Microbiol. 2017, 67, 1613. [Google Scholar] [CrossRef] [PubMed]
- Na, S.I.; Kim, Y.O.; Yoon, S.H.; Ha, S.M.; Baek, I.; Chun, J. UBCG: Up-to-date bacterial core gene set and pipeline for phylogenomic tree reconstruction. J. Microbiol. 2018, 56, 280–285. [Google Scholar] [CrossRef] [PubMed]
- Letunic, I.; Bork, P. Interactive Tree of Life (iTOL): An online tool for phylogenetic tree display and annotation. Bioinformatics 2007, 23, 127–128. [Google Scholar] [CrossRef] [Green Version]
- González-Dominici, L.I.; Saati-Santamaría, Z.; García-Fraile, P. Genome Analysis and Genomic Comparison of the Novel Species Arthrobacter ipsi Reveal Its Potential Protective Role in Its Bark Beetle Host. Microb. Ecol. 2021, 81, 471–482. [Google Scholar] [CrossRef]
- Pritchard, L.; Glover, R.H.; Humphris, S.; Elphinstone, J.G.; Toth, I.K. Genomics and taxonomy in diagnostics for food security: Soft-rotting enterobacterial plant pathogens. Anal Methods 2016, 8, 12–24. [Google Scholar]
- Warnes, G.R.; Bolker, B.; Bonebakker, L.; Gentleman, R.; Liaw, W.H.A.; Lumley, T.B. gplots: Various R Programming Tools for Plotting Data. R Package Version 3.0.4. 2020. Available online: https://CRAN.R-project.org/package=gplots (accessed on 1 February 2021).
- Auch, A.F.; von Jan, M.; Klenk, H.P.; Göker, M. Digital DNA-DNA hybridization for microbial species delineation by means of genome-to-genome sequence comparison. Stand. Genomic Sci. 2010, 2, 117–134. [Google Scholar] [CrossRef] [Green Version]
- Meier-Kolthoff, J.P.; Auch, A.F.; Klenk, H.P.; Göker, M. Genome sequence-based species delimitation with confidence intervals and improved distance functions. BMC Bioinform. 2013, 14, 60. [Google Scholar] [CrossRef] [Green Version]
- Kim, D.; Park, S.; Chun, J. Introducing EzAAI: A pipeline for high throughput calculations of prokaryotic average amino acid identity. J. Microbiol. 2021, 59, 476–480. [Google Scholar] [CrossRef]
- Seemann, T. Prokka: Rapid prokaryotic genome annotation. Bioinformatics 2014, 30, 2068–2069. [Google Scholar] [CrossRef]
- Gautreau, G.; Bazin, A.; Gachet, M.; Planel, R.; Burlot, L.; Dubois, M.; Vallenet, D. PPanGGOLiN: Depicting microbial diversity via a partitioned pangenome graph. PLoS Comput. Biol. 2020, 16, e1007732. [Google Scholar] [CrossRef] [Green Version]
- Brynildsrud, O.; Bohlin, J.; Scheffer, L.; Eldholm, V. Rapid scoring of genes in microbial pan-genome-wide association studies with Scoary. Genome Biol. 2016, 17, 1–9. [Google Scholar] [CrossRef] [Green Version]
- Huerta-Cepas, J.; Forslund, K.; Coelho, L.P.; Szklarczyk, D.; Jensen, L.J.; Von Mering, C.; Bork, P. Fast genome-wide functional annotation through orthology assignment by eggNOG-mapper. Mol. Biol. Evol. 2017, 34, 2115–2122. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ramos, P.L.; Van Trappen, S.; Thompson, F.L.; Rocha, R.C.; Barbosa, H.R.; De Vos, P.; Moreira-Filho, C.A. Screening for endophytic nitrogen-fixing bacteria in Brazilian sugar cane varieties used in organic farming and description of Stenotrophomonas pavanii sp. nov. Int. J. Syst. Evol. Microbiol. 2011, 61, 926–931. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hu, F.P.; Young, J.M.; Stead, D.E.; Goto, M. Transfer of Pseudomonas cissicola (Takimoto 1939) Burkholder 1948 to the genus Xanthomonas. Int. J. Syst. Evol. Microbiol. 1997, 47, 228–230. [Google Scholar] [CrossRef] [Green Version]
- Parkinson, N.; Cowie, C.; Heeney, J.; Stead, D. Phylogenetic structure of Xanthomonas determined by comparison of gyrB sequences. Int. J. Syst. Evol. Microbiol. 2009, 59, 264–274. [Google Scholar] [CrossRef] [Green Version]
- Holmes, B.; Steigerwalt, A.G.; Weaver, R.E.; Brenner, D.J. Chryseomonas luteola comb. nov. and Flavimonas oryzihabitans gen. nov., comb. nov., Pseudomonas-like species from human clinical specimens and formerly known, respectively, as groups Ve-1 and Ve-2. Int. J. Syst. Evol. Microbiol. 1987, 37, 245–250. [Google Scholar] [CrossRef] [Green Version]
- Anzai, Y.; Kudo, Y.; Oyaizu, H. The phylogeny of the genera Chryseomonas, Flavimonas, and Pseudomonas supports synonymy of these three genera. Int. J. Syst. Evol. Microbiol. 1997, 47, 249–251. [Google Scholar] [CrossRef] [Green Version]
- Chester, F.D. A Manual of Determinative Bacteriology; The MacMillan Co.: New York, NY, USA, 1901. [Google Scholar]
- Xiao, Y.P.; Hui, W.; Wang, Q.; Roh, S.W.; Shi, X.Q.; Shi, J.H.; Quan, Z.X. Pseudomonas caeni sp. nov., a denitrifying bacterium isolated from the sludge of an anaerobic ammonium-oxidizing bioreactor. Int. J. Syst. Evol. Microbiol. 2009, 59, 2594–2598. [Google Scholar] [CrossRef] [Green Version]
- Hameed, A.; Shahina, M.; Lin, S.Y.; Liu, Y.C.; Young, C.C. Pseudomonas hussainii sp. nov., isolated from droppings of a seashore bird, and emended descriptions of Pseudomonas pohangensis, Pseudomonas benzenivorans and Pseudomonas segetis. Int. J. Syst. Evol. Microbiol. 2014, 64, 2330–2337. [Google Scholar] [CrossRef] [Green Version]
- Reddy, G.S.; Garcia-Pichel, F. Description of Pseudomonas asuensis sp. nov. from biological soil crusts in the Colorado plateau, United States of America. J. Microbiol. 2015, 53, 6–13. [Google Scholar] [CrossRef]
- Liu, R.; Liu, H.; Feng, H.; Wang, X.; Zhang, C.X.; Zhang, K.Y.; Lai, R. Pseudomonas duriflava sp. nov., isolated from a desert soil. Int. J. Syst. Evol. Microbiol. 2008, 58, 1404–1408. [Google Scholar] [CrossRef]
- Wei, Y.; Mao, H.; Xu, Y.; Zou, W.; Fang, J.; Blom, J. Pseudomonas abyssi sp. nov., isolated from the abyssopelagic water of the Mariana Trench. Int. J. Syst. Evol. Microbiol. 2018, 68, 2462–2467. [Google Scholar] [CrossRef]
- Sánchez, D.; Mulet, M.; Rodríguez, A.C.; David, Z.; Lalucat, J.; García-Valdés, E. Pseudomonas aestusnigri sp. nov., isolated from crude oil-contaminated intertidal sand samples after the Prestige oil spill. Syst. Appl. Microbiol. 2014, 37, 89–94. [Google Scholar] [CrossRef]
- Zhang, D.C.; Liu, H.C.; Zhou, Y.G.; Schinner, F.; Margesin, R. Pseudomonas bauzanensis sp. nov., isolated from soil. Int. J. Syst. Evol. Microbiol. 2011, 61, 2333–2337. [Google Scholar] [CrossRef]
- Lin, S.Y.; Hameed, A.; Liu, Y.C.; Hsu, Y.H.; Lai, W.A.; Young, C.C. Pseudomonas formosensis sp. nov., a gamma-proteobacteria isolated from food-waste compost in Taiwan. Int. J. Syst. Evol. Microbiol. 2013, 63, 3168–3174. [Google Scholar] [CrossRef] [PubMed]
- Pascual, J.; Lucena, T.; Ruvira, M.A.; Giordano, A.; Gambacorta, A.; Garay, E.; Macián, M.C. Pseudomonas litoralis sp. nov., isolated from Mediterranean seawater. Int. J. Syst. Evol. Microbiol. 2012, 62, 438–444. [Google Scholar] [CrossRef] [PubMed]
- Jang, G.I.; Lee, I.; Ha, T.T.; Yoon, S.J.; Hwang, Y.J.; Yi, H.; Hwang, C.Y. Pseudomonas neustonica sp. nov., isolated from the sea surface microlayer of the Ross Sea (Antarctica). Int. J. Syst. Evol. Microbiol. 2020, 70, 3832–3838. [Google Scholar] [CrossRef]
- Wang, M.Q.; Sun, L. Pseudomonas oceani sp. nov., isolated from deep seawater. Int. J. Syst. Evol. Microbiol. 2016, 66, 4250–4255. [Google Scholar] [CrossRef] [PubMed]
- Romanenko, L.A.; Uchino, M.; Falsen, E.; Frolova, G.M.; Zhukova, N.V.; Mikhailov, V.V. Pseudomonas pachastrellae sp. nov., isolated from a marine sponge. Int. J. Syst. Evol. Microbiol. 2005, 55, 919–924. [Google Scholar] [CrossRef] [Green Version]
- Hwang, C.Y.; Zhang, G.I.; Kang, S.H.; Kim, H.J.; Cho, B.C. Pseudomonas pelagia sp. nov., isolated from a culture of the Antarctic green alga Pyramimonas gelidicola. Int. J. Syst. Evol. Microbiol. 2009, 59, 3019–3024. [Google Scholar] [CrossRef]
- Kawai, Y.; Yabuuchi, E. Pseudomonas pertucinogena sp. nov., an organism previously misidentified as Bordetella pertussis. Int. J. Syst. Evol. Microbiol. 1975, 25, 317–323. [Google Scholar]
- Li, J.; Wang, L.H.; Xiang, F.G.; Ding, W.L.; Xi, L.J.; Wang, M.Q.; Xiao, Z.J.; Liu, J.G. Pseudomonas phragmitis sp. nov., isolated from petroleum polluted river sediment. Int. J. Syst. Evol. Microbiol. 2020, 70, 364–372. [Google Scholar] [CrossRef]
- Sun, J.; Wang, W.; Ying, Y.; Zhu, X.; Liu, J.; Hao, J. Pseudomonas profundi sp. nov., isolated from deep-sea water. Int. J. Syst. Evol. Microbiol. 2018, 68, 1776–1780. [Google Scholar] [CrossRef] [PubMed]
- Kim, K.H.; Roh, S.W.; Chang, H.W.; Nam, Y.D.; Yoon, J.H.; Jeon, C.O.; Bae, J.W. Pseudomonas sabulinigri sp. nov., isolated from black beach sand. Int. J. Syst. Evol. Microbiol. 2009, 59, 38–41. [Google Scholar] [CrossRef] [PubMed]
- Amoozegar, M.A.; Shahinpei, A.; Sepahy, A.A.; Makhdoumi-Kakhki, A.; Seyedmahdi, S.S.; Schumann, P.; Ventosa, A. Pseudomonas salegens sp. nov., a halophilic member of the genus Pseudomonas isolated from a wetland. Int. J. Syst. Evol. Microbiol. 2014, 64, 3565–3570. [Google Scholar] [CrossRef] [PubMed]
- Zhong, Z.P.; Liu, Y.; Hou, T.T.; Liu, H.C.; Zhou, Y.G.; Wang, F.; Liu, Z.P. Pseudomonas salina sp. nov., isolated from a salt lake. Int. J. Syst. Evol. Microbiol. 2015, 65, 2846–2851. [Google Scholar] [CrossRef]
- Liu, M.; Luo, X.; Zhang, L.; Dai, J.; Wang, Y.; Tang, Y.; Li, J.; Sun, T.; Fang, C. Pseudomonas xinjiangensis sp. nov., a moderately thermotolerant bacterium isolated from desert sand. Int. J. Syst. Evol. Microbiol. 2009, 59, 1286–1289. [Google Scholar] [CrossRef] [Green Version]







Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Saati-Santamaría, Z.; Peral-Aranega, E.; Velázquez, E.; Rivas, R.; García-Fraile, P. Phylogenomic Analyses of the Genus Pseudomonas Lead to the Rearrangement of Several Species and the Definition of New Genera. Biology 2021, 10, 782. https://doi.org/10.3390/biology10080782
Saati-Santamaría Z, Peral-Aranega E, Velázquez E, Rivas R, García-Fraile P. Phylogenomic Analyses of the Genus Pseudomonas Lead to the Rearrangement of Several Species and the Definition of New Genera. Biology. 2021; 10(8):782. https://doi.org/10.3390/biology10080782
Chicago/Turabian StyleSaati-Santamaría, Zaki, Ezequiel Peral-Aranega, Encarna Velázquez, Raúl Rivas, and Paula García-Fraile. 2021. "Phylogenomic Analyses of the Genus Pseudomonas Lead to the Rearrangement of Several Species and the Definition of New Genera" Biology 10, no. 8: 782. https://doi.org/10.3390/biology10080782