1. Introduction
Detection networks based on deep convolutional neural networks have become the most popular algorithms among researchers in the area of pavement distress detection [
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12]. With the development of deep learning theory and the improvement of computer hardware performance, the depth and breadth of detection networks have been increasing to achieve superior accuracy, along with a rapid increase in the number of parameters. Currently, the most powerful Transformer-based neural network has reached 600 million parameters [
13]. In order to avoid overfitting and to obtain a robust model, the training data must be sufficient in quantity and diversity. There are many strategies to prevent overfitting during the training of the detection model, such as batch normalization [
14], drop out, drop connect [
15], early stopping, weight decay, etc. There is another more effective and intuitive strategy that can be implemented before model training, which is the data augmentation, but the current data augmentation algorithm is very effective for datasets with balanced data distribution and has limited improvement for datasets with “long tail” distribution.
There are various pavement distresses on a road section; however, the quantity difference between pavement distress is often significant. For example, while the number of the common crack category is high, the number of sealed cracks or potholes is relatively small, and the data distribution of the distress shows a long-tail distribution, which is a kind of unbalanced data performance. As shown in
Figure 1, the frequency of different categories of distress is used as the basis for ranking, from high to low, with the head of the curve being the most common distress and the tail being the distress that occurs less frequently, forming a curve similar to a “long tail” shape. As the detection model undergoes more training epochs, it eventually converges on the training set losses. However, this improvement does not extend well to the test set, as it exhibits weak generalization and performs poorly, particularly for tail data.
To improve the problem of long-tailed datasets, the most intuitive means of tackling the problem is to augment the tailed data. The conventional methods are to apply affine transformations to the data, such as rotation, translation, mirroring, etc., or to change the image hue, add Gaussian noise [
16] or image blurring, in addition to other means of augmentation [
17], all of which can expand the number of tail data and bridge the problem of insufficient samples in the tail. However, conventional methods for data augmentation require the reuse of all or part of the image content of the original data, and do not introduce new perspectives or content, with limited improvement in intra-class diversity for the tail data [
18,
19]. Therefore, this enhancement algorithm is more suitable for head data, or datasets with more balanced data distribution. However, for tail data, although the quantity can be boosted using such methods, the diversity enhancement is rather weak and cannot effectively avoid model overfitting.
Deep learning-based image generation algorithms can generate random noise into a specified category of images or edit certain features of an image, and this kind of uncertain image generation can enhance the diversity of images. At present, the dominant image generation algorithms are VAE [
20], GAN [
21], Diffusion Model [
22], and others. Some scholars have carried out research on the pavement image augmentation based on the above algorithms and have attained some progress, but there are still some drawbacks. For example, the generated image quality is poor with low resolution, the training is difficult to converge, the model collapses, or the complexity of the model is too high.
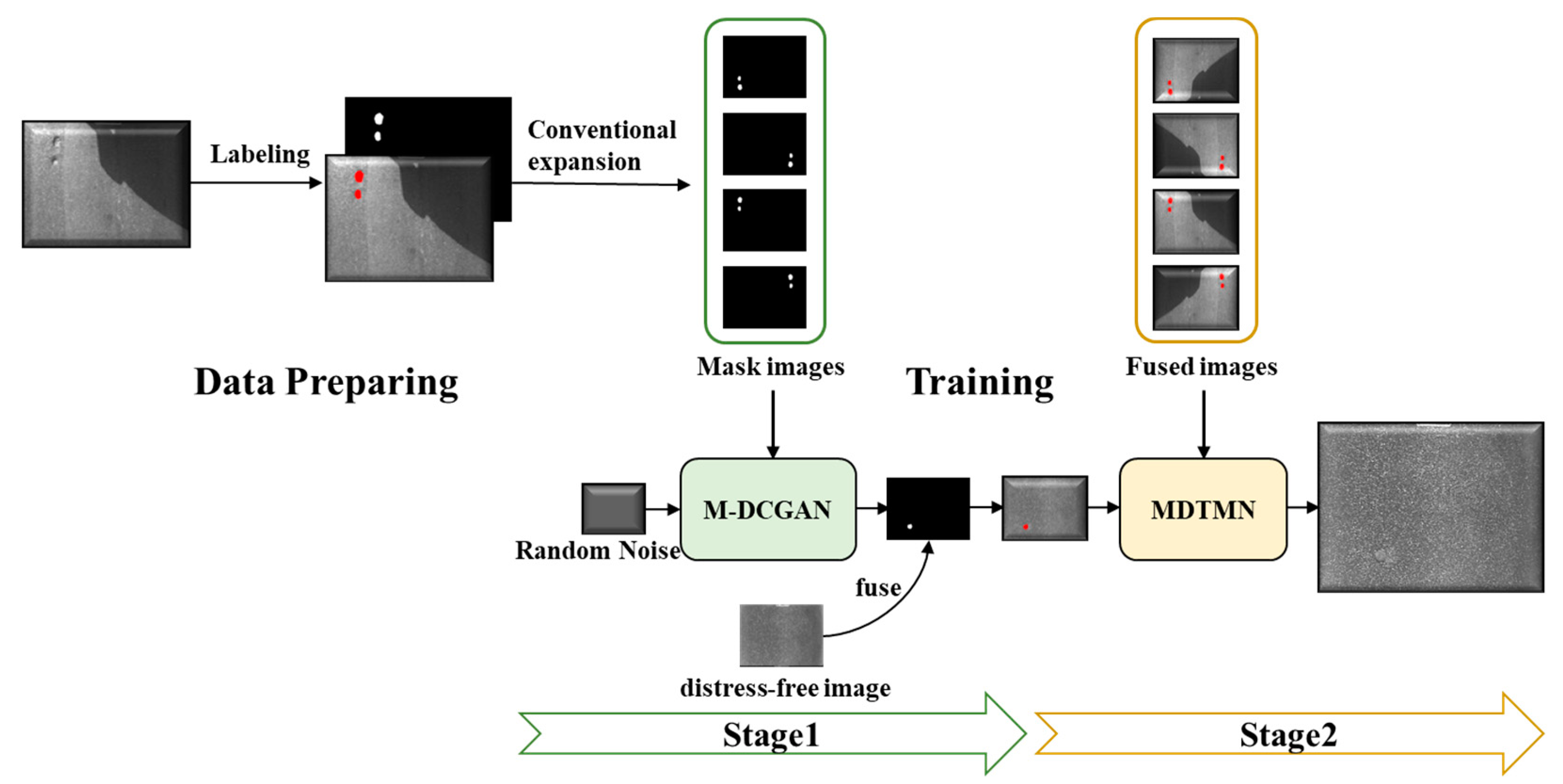
In this work, we propose a novel two-stage approach for pavement distress image augmentation, as shown in
Figure 2. In this approach, in the first stage, we propose a self-attentive mechanism-based distress mask generation network, M-DCGAN (Mask-DCGAN), for learning distress features from a small number of labelled distress images and autonomously generating synthetic distress masks that fit the distress geometries. In the second stage, the mask images generated in the first stage are fused with the distress-free pavement images to become prototype images for pavement distress image generation. In addition, a texture synthesis network with multiple receptive fields, MDTMN (Mask-to-Distress Texture Mapping Network), is designed to generate a prototype image into a synthetic image with relatively realistic pavement distress texture.
To demonstrate the effectiveness of the proposed MDTMN, three different types of generation algorithms, namely Pix2Pix [
23], CPN [
24], and CycleGAN [
25], are selected for comparison experiments, which are divided into two parts: qualitative and quantitative evaluations. The comparison experiment verified that the images generated by the proposed method outperformed those generated by other algorithms in terms of image quality and diversity.
Furthermore, to prove the effectiveness of the data augmentation model proposed in this paper, pixel-level detection of pavement distress was conducted for the tail data. The experiments were carried out with the dataset not augmented, the dataset augmented by the conventional method, and the dataset augmented by the proposed method, and finally, the detection model achieved the best detection accuracy on the dataset augmented by the proposed algorithm.
The contributions of this paper are summarized as follows:
We propose a two-stage pavement distress augmentation approach and accompany each stage with a specific task generation algorithm (M-DCGAN and MDTMN). The M-DCGAN generates a mask that matches the geometric characteristics of the distress in one stage, and in the second stage the generated mask will be filled by the MDTMN with a context-sensitive distress texture. This two-stage pavement distress image generation algorithm allows the generation of high-quality images while enhancing image diversity;
Our proposed image augmentation algorithm can simultaneously obtain a distress mask image with pixel-level labelling (one-stage output) and a corresponding pavement distress image (two-stage output), which can be utilized directly as a dataset for pavement distress semantic segmentation algorithms. It reduces the cost of manual labelling and provides more accurate labelled data as well;
The proposed method focuses on diversifying the original dataset, which effectively improves the performance of the detection model.
2. Related Work
The size of network structures in novel deep learning networks is constantly being increased to extract more effective features, resulting in a significant increase in the number of parameters. In comparison with previous small-sized neural networks, the new structures require more data to be involved in the training. Therefore, how to perform effective data augmentation has also become an active research issue in recent years.
In previous studies, the common means used were random rotation, translation and mirroring, which were used to enhance the geometric invariance of the CNN-based models by applying affine transformations to the images [
26]. Based on the above approaches, Auto-Augment [
27] uses reinforcement learning algorithms to learn how to combine basic image augmentation algorithms to form more complex image augmentation strategies. The most critical drawback of this combination of algorithms for data augmentation strategies is the high computational cost of the search combination. Inspired by the drop out strategy in the model training, an augmentation strategy by masking some of the information in the image can also improve the robustness of the model [
28].
The YOLO family [
29,
30,
31] of detection algorithms has been well known to researchers for its fast and accurate detection, not only in terms of network structure, but also the accompanying data augmentation algorithms. YOLOv4 introduces the Mosaic data augmentation method, which combines four different images into one large image and then splits the large image into four parts as part of the training set. YOLOv5 introduces the Cut-Mix data augmentation method, which overlays a part of one image onto another to create a new hybrid image. This method expands the training set and can better handle inter-target occlusions, improving the robustness of the model. Both YOLOv4 and YOLOv5 use the Mix-Up data augmentation approach to generate a new training image by randomly selecting two training images and mixing their pixel and label information in a certain ratio. This approach can extend the training set and improve the detection accuracy of the model for small targets.
The output of the above image data augmentation methods all contains part or entire representations of the original data, and the diversity of the inter-class data is not augmented. Considering the above drawbacks, the researcher used a GAN-based image generation algorithm to generate synthetic images that conform to the prior distribution by learning the feature distribution of known samples [
32,
33,
34,
35]. The generation of synthetic images is random in nature and can be used as supplementary data to enhance the diversity of the dataset. However, the drawbacks are also significant; the quality of the generated images is poor, the image size is too small, model collapse tends to occur when training is inadequate, and the representation of synthetic images does not conform to natural patterns. Training with such synthetic images does not effectively improve the accuracy and robustness of the detection model. Despite this, there are already many algorithms that can generate high quality images, such as Big-GAN [
36] and diffusion model. However, these algorithms generally require high-performance computers, especially in terms of requiring high numbers of high-performance GPUs to support training and are not cost-effective if only used for data augmentation tasks. In addition, these algorithms require large amounts of high-quality training data, which is in conflict with the original purpose of image data augmentation. Most importantly, the time to generate a single high-quality image often exceeds 10 s, which is not suitable for high-volume data augmentation. This paper addresses the shortcomings of these algorithms and redesigns the image generation model to obtain better quality augmented data that can be used directly for training.
4. Two-Stage Augmentation Approach and Algorithms
This paper divides the complex pavement distress image enhancement procedure into two stages, and in each stage the relevant algorithm is designed to complete the corresponding processing task. As shown in
Figure 2, this section describes in detail the algorithms designed in each stage.
4.1. Pavement Distress Mask Generation Network (M-DCGAN)
In the first stage, a self-attention-based generative adversarial network, M-DCGAN, is designed for distress mask image generation in this study. Since the training data of M-DCGAN is a simple pavement distress mask image, it will not be disturbed by other approximate semantics in the pavement image.
4.1.1. An Improved Generator and Discriminator
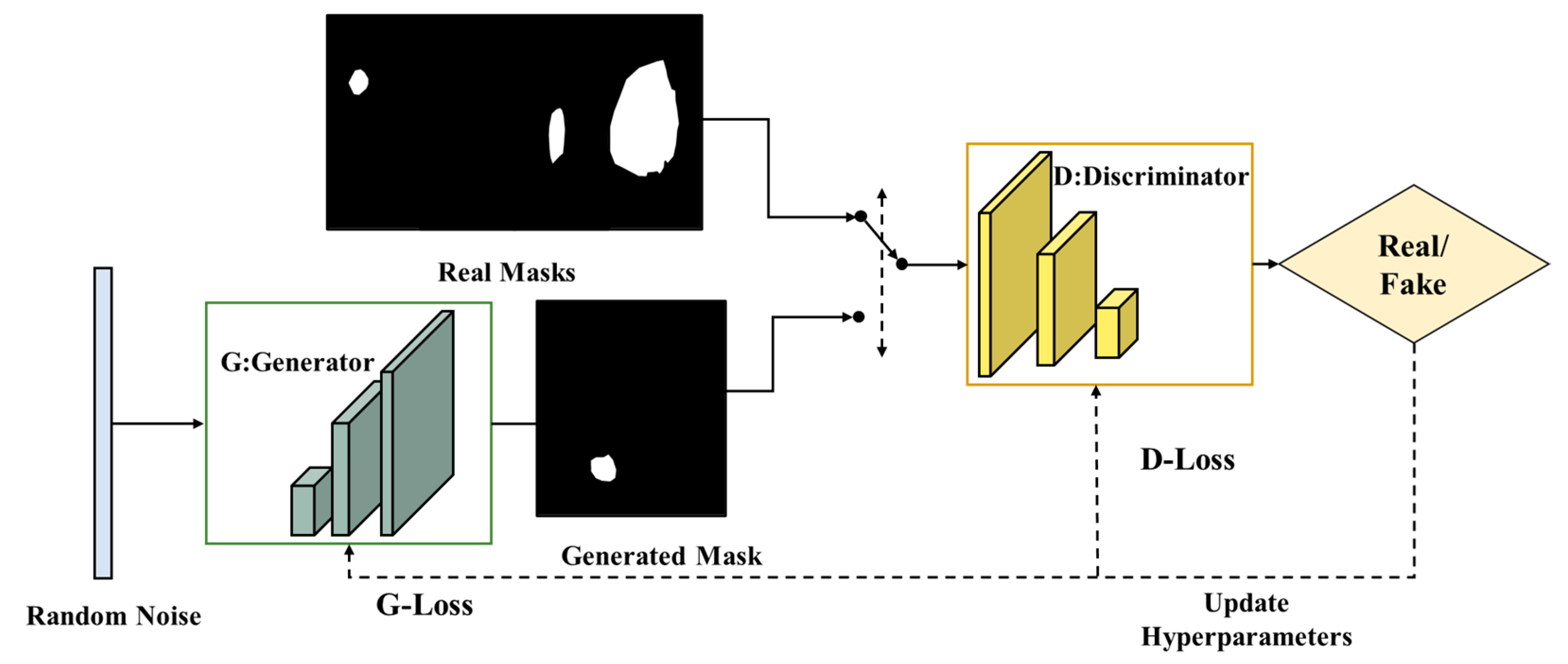
M-DCGAN is based on the DCGAN framework and is designed to generate two-dimensional random noise matrices into distress mask images. DCGAN is an image generation algorithm that employs unsupervised representational learning with a combination of deep convolutional neural networks and generative adversarial networks internally, as shown in
Figure 5. It is an improved algorithm to the vanilla GAN and can output better high-quality images. However, the following drawbacks remain:
Limited number of transposed convolutional layers and only images sized 64 × 64 can be generated;
Correlation between channels in the feature map is not fully exploited;
Gradient disappearance still occurs during training.
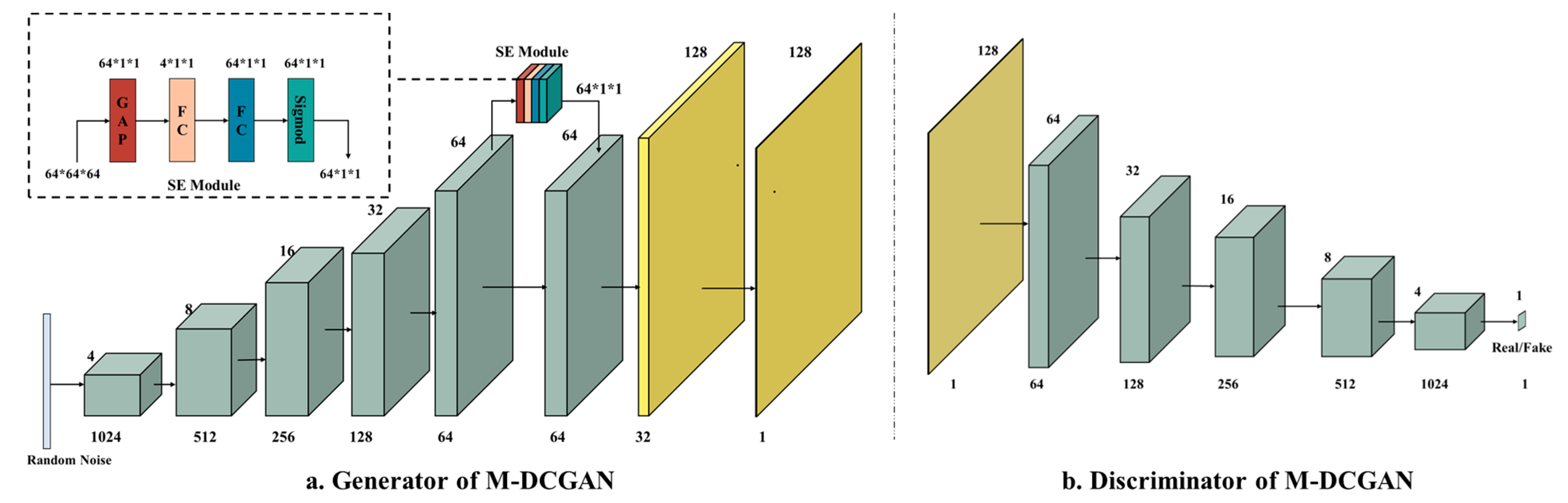
To address the above drawbacks, this paper makes a slight modification to DCGAN for the task of distress mask generation by redesigning the network structure and loss function to build Mask-DCGAN (M-DCGAN). The redesigned generator and discriminator are shown in
Figure 6a,b. In the generator network, the green part is the network structure of the original DCGAN. The random noise is transformed into a feature map of size 1024 × 4 × 4 by transposed convolution. The final image of size 128 × 128 is generated by transposed convolution with step size 2, transposed convolution kernel size 4 × 4 and padding operation 1, which completes the step-by-step scale-up operation of two times the original size. The output size of the transposed convolution is calculated from Equation (1):
where stride and kernel denote the step size and convolution kernel size, respectively.
As illustrated in
Figure 6a, a self-attention-based SE module is added to the M-DCGAN generator to exploit the weight relationships of different channels in the features. This module, which is placed between the fifth transposed convolutional layer and the sixth, can autonomously calculate the weight coefficients of each of the 64 channels and then perform a weighted dot multiplication operation with the feature map to assign the weights to each channel, enhancing the features with high contributions and weakening the irrelevant features.
As illustrated in
Figure 6b, as the size of the generated image was increased by a factor of two, the discriminator was adapted accordingly, increasing the size of the input image to 128 × 128 pixels, while the trailing fully connected layer was replaced with a convolutional layer.
4.1.2. Model Training
The deep learning models involved in this paper are trained on a GPU server with the following configuration: CPU: Intel Xeon, GPU: Rtx2080 × 8, 64 G of RAM, 5 TB of hard disk, and Ubuntu 14 as the operating system. The model was trained using the WGAN (Wasserstein GAN) loss function to address training instability and to avoid model collapse. The rest of the configuration items are as follows: the optimizer is Adam, the learning rate is set to 0.0002, the cut-off parameter is set to 0.01, the batch size is set to 64, the number of rounds of discriminator training per batch is set to 5, and the overall number of training epochs is set to 200.
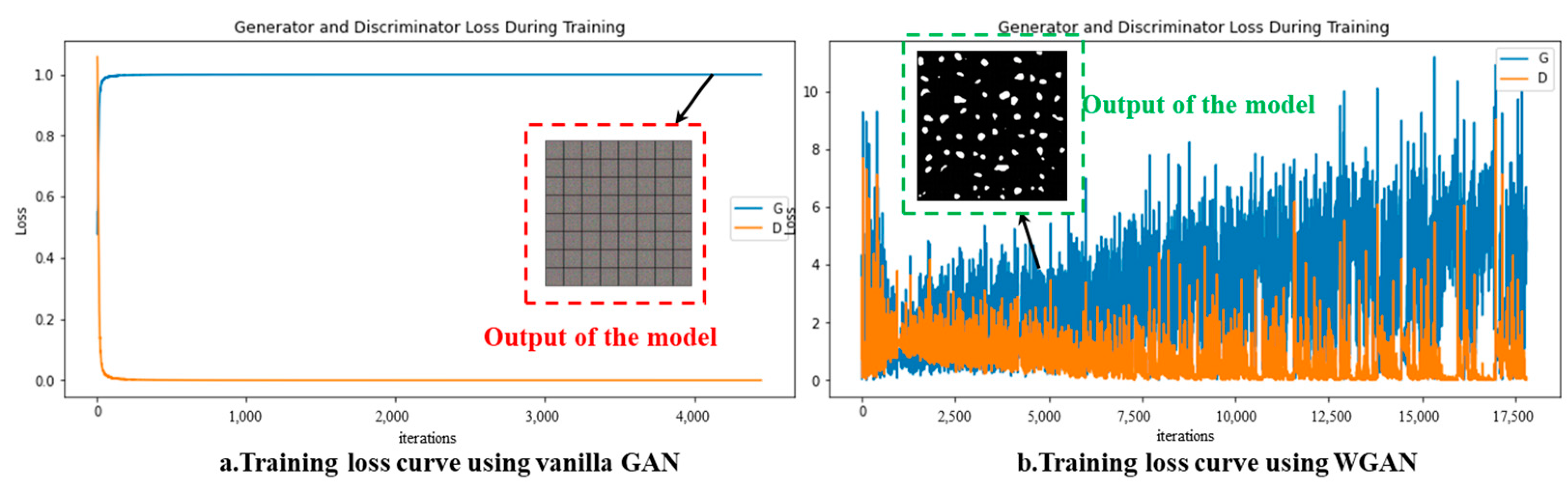
In order to compare the WGAN loss function and vanilla GAN loss function, the two loss functions are used for training, as shown in
Figure 7. The
Figure 7a shows the loss function of vanilla GAN, and the generator loss and discriminator loss have not changed since the first few rounds, and the training is basically at a halt, which is due to the disappearance of the gradient during back propagation. In
Figure 7b, the loss function of WGAN is used, and the loss curve oscillates during training but conforms to the training rule of generative adversarial network, and the loss also tends to converge. What is more concerning is that the gradient passed in the network is always maintained and the training does not stagnate. In addition, the images generated by the model with the same number of iterations can also reflect the training effect of the model. With respect to the images in the red box in
Figure 7a, it can be seen that the background and foreground are not generated correctly, and still present a random noise appearance, while the green dashed box in
Figure 7b shows that the background has all been generated into a black background, and the distress masks of different shapes and sizes in the foreground have been generated properly.
4.1.3. Evaluation of the Generation Results of M-DCGAN
A batch quantity of random noise can be generated into the same number of distress mask images using the trained M-DCGAN model. In order to show the complete distribution of the generated images of a batch and to facilitate the evaluation of the generated results, both the generated images and the training data will be presented and evaluated in an 8 × 8 patchwork, as shown in
Figure 8. It can be observed from
Figure 8 that after the 15th epoch, the generated distress masks are already very close to the real masks, but after 100 epochs, the angularity of the masks gradually increases and image artefacts appear, which is due to model over-fitting.
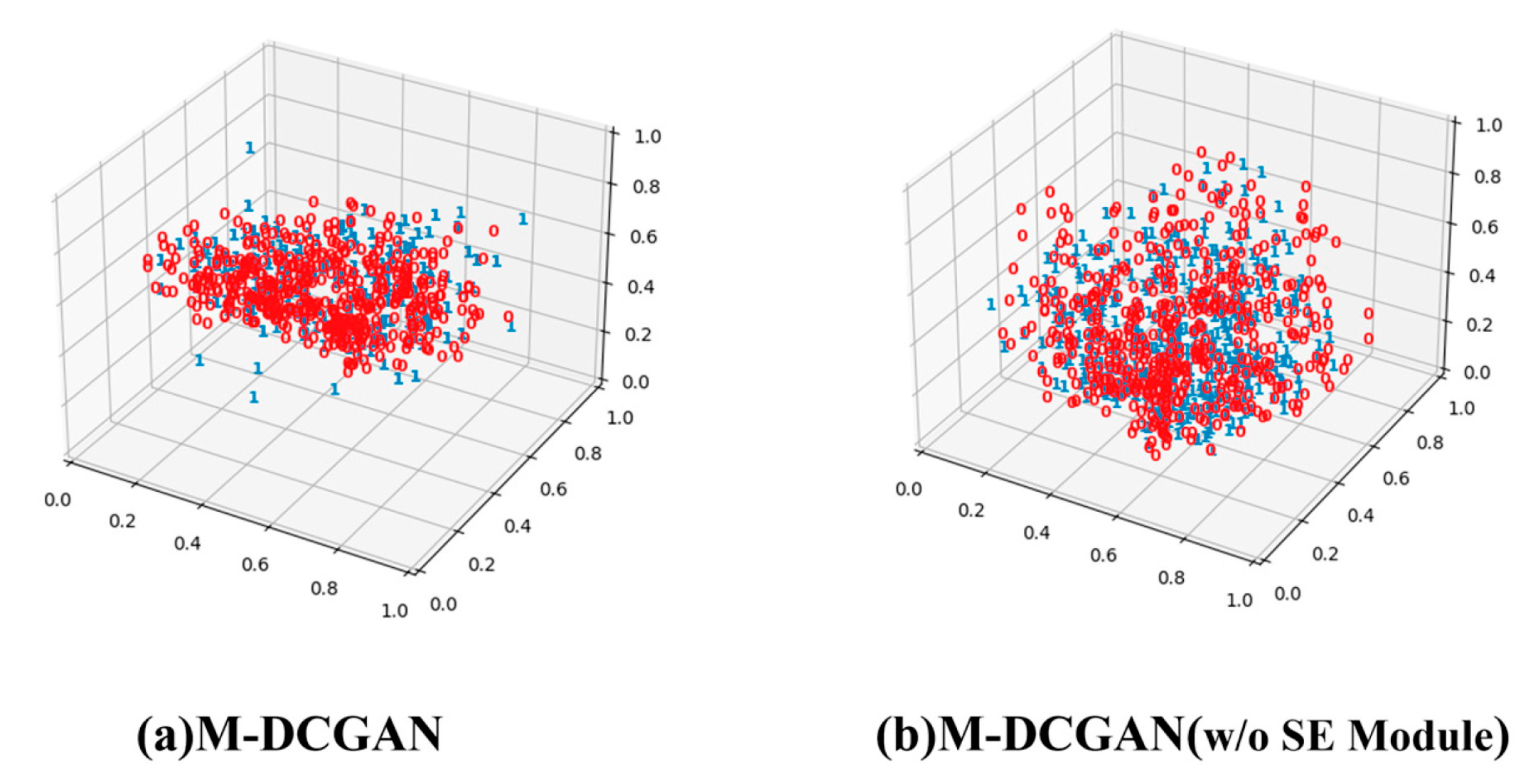
Generative adversarial generative network itself is an unsupervised learning algorithm, and its generation results are not unique. In addition, the real pavement pothole morphology is not constant, and it is difficult to evaluate the generation results with quantitative metrics. To verify whether the distribution of M-DCGAN generated images and training samples are close, this subsection uses 500 generated images and 500 real mask images to form a validation dataset, and assigns “0” and “1” labels, respectively, and then uses t-SNE [
38] (T-distributed Stochastic Neighbor Embedding). The visualization results are shown in
Figure 9. The two types of data have an overall distribution that is similar to each other, which proves that the M-DCGAN generator can effectively learn the image distribution of the distress masks and generate the images with similar distribution and appearance of the distress masks. Moreover, to verify the effectiveness of the SE module,
Figure 9a,b show the distribution of the generated results with and without the SE module, respectively. Evidently, the generated results of the model with the SE module are closer to the real data.
4.2. Mask-to-Distress Texture Mapping Network (MDTMN)
The most of pavement images are distress-free pavement images, and such images are usually eliminated from the dataset before the training of detection models, which will result in wasted cost of collection and storage. The MDTMN designed in this paper can effectively use distress-free images or non-target class pavement distress images to generate images with the specified class of distress.
4.2.1. Input Data of MDTMN
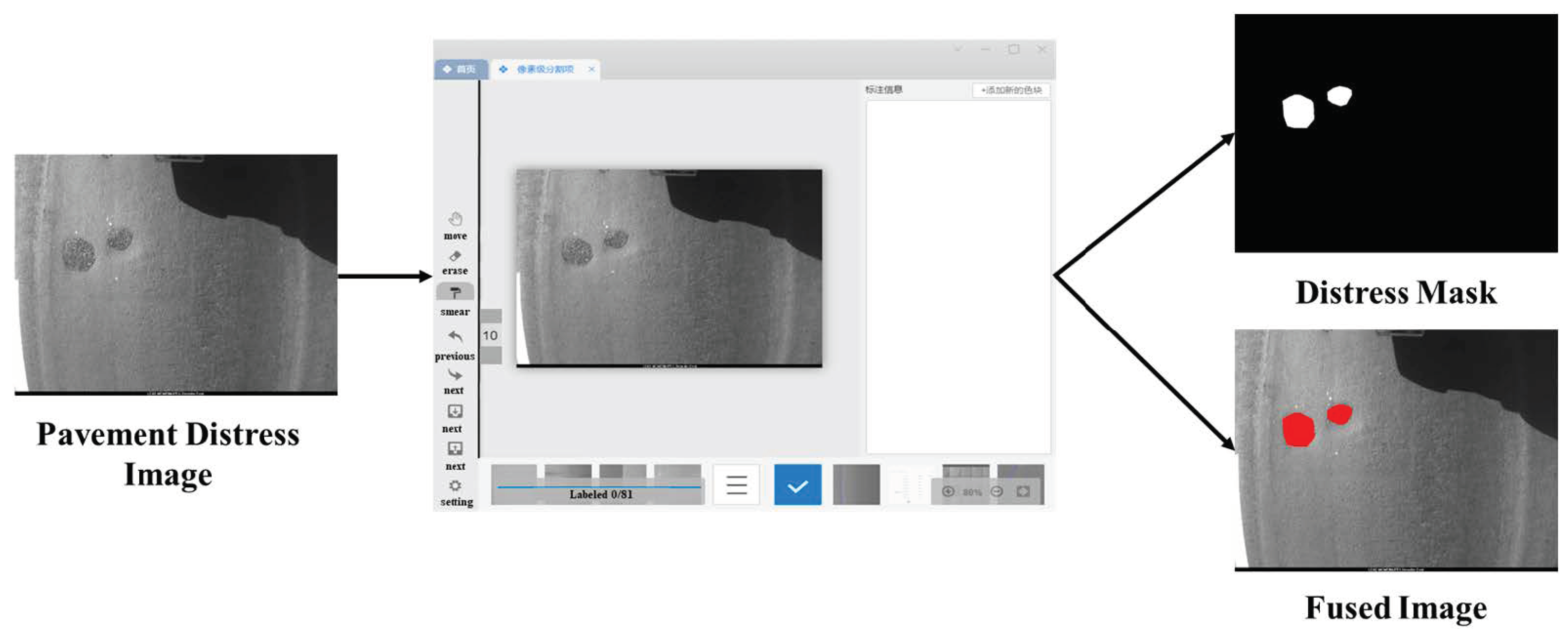
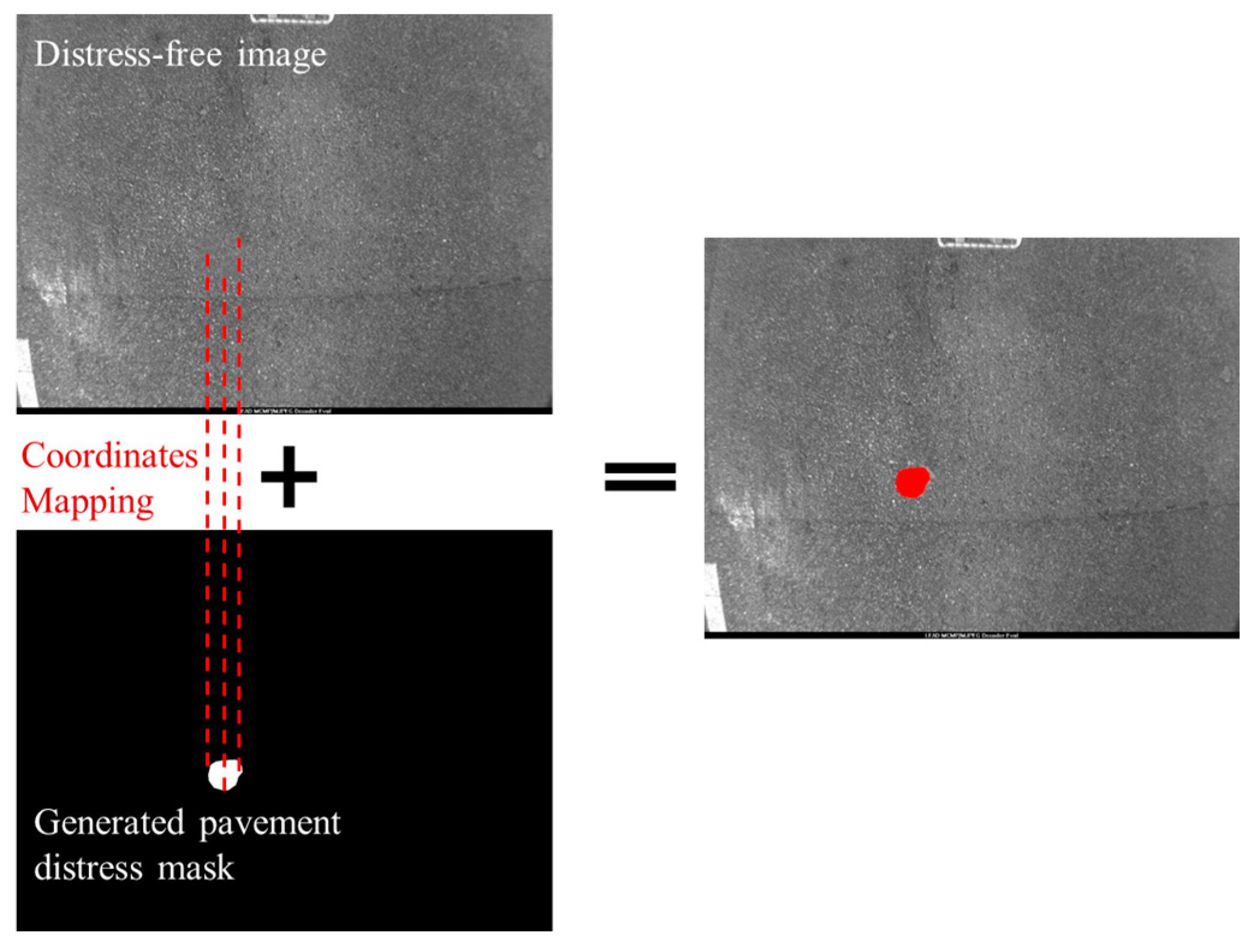
The mask generated by M-DCGAN needs to be fused with the distress-free image before it can be used as an input for distress texture generation, because the distress mask image and the original image have the same size. The fusion of the two images is to map the coordinates of the white pixels in the distress mask region to the original image, and then replace the pixels in the corresponding coordinate region of the original image with red pixels with pixel values of (255, 0, 0), as shown in
Figure 10. The reason for using pure red pixels is to distinguish them from the original pixels in the image and highlight the distress region to be generated.
4.2.2. MDTMN Architecture
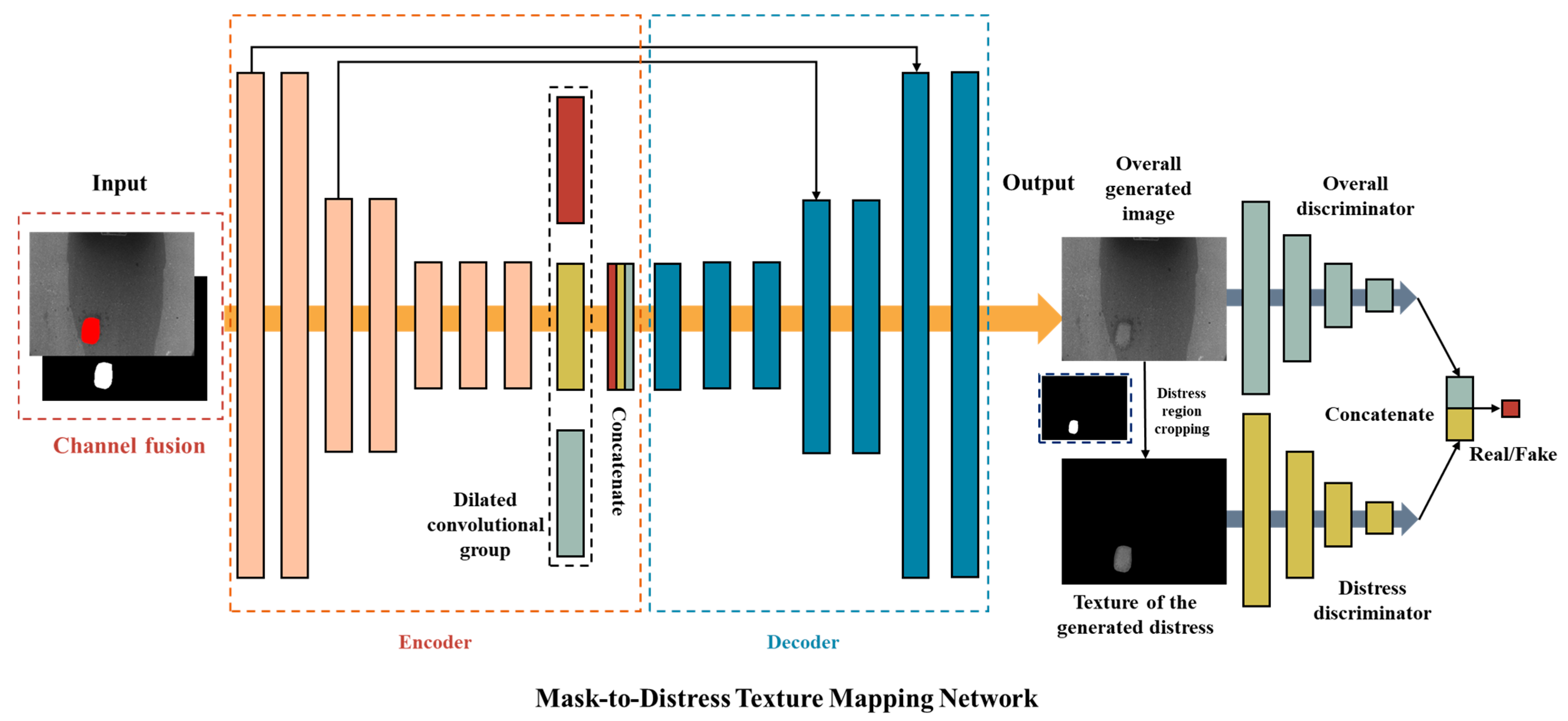
The overall structure of MDTMN is illustrated in
Figure 11. At the input of MDTMN, the mask fusion image is channel fused with the mask image to form a four channels image, and then sent to the encoder for feature extraction and compression. After compression, the features are extracted at multiple scales under different receptive fields by the dilated convolution group in the middle section, and the extracted features are concatenated and sent to the decoder again for level-by-level feature and image size recovery. In order to ensure that the generated image can maintain more image details, skip connections are also added in the first and third convolutional layers of the network to introduce more low-level semantic information into the high-level features. The final output is a pavement image of the masked area generated as pavement distress.
The discriminator is divided into two sub-discriminators: the overall discriminator and the distress discriminator, respectively. They extract the features of the complete generated image and the distress image with only the distress area simultaneously, and then output the individual image features for feature concatenation. After this, the concatenated features pass through the fully connected layer and the sigmoid function activation, and finally, are converted into the probability of the image being fake or real. In the initialization of the training discriminator, the real image and the distress features of the real image are labeled as “real”, and the generated image and the generated distress are labeled as “fake”. The structural parameters of the overall network are shown in
Table 1a–c.
From the details of the network structure in
Table 1a, it can be seen that the encoder in the red dashed box in
Figure 10 employs a step-by-step convolution to extract the features from the original image, which directly responds to the exponentially increasing number of output feature map channels. There is a special parallel step of the dilated convolution operation group. MDTMN uses a total of three different dilated rates of 2, 6, and 12, and the receptive field can reach 5 × 5 pixels, 12 × 12 pixels, and 25 × 25 pixels, respectively. The outstanding advantage of the dilated convolution is to enlarge the receptive field of the network without introducing additional parameters by filling 0-valued pixels at specified positions to the convolution kernel.
The two discriminators described in
Table 1b gradually compress the image into a 1024-dimensional feature vector by a convolution operation with a step size of 2. The two vectors are output as the probability of the real image by the feature concatenation and full connection operation in the table in
Table 1c.
4.2.3. Loss Function
The input content of MDTMN in this section is the fused pavement image, which differs from M-DCGAN, where the input is random noise. The difference between the two network structures is also large, especially given that the MDTMN uses two discriminators, so although they are the same generative adversarial network, the loss function is different.
Since two discriminators are being used, two loss functions are introduced simultaneously: the Mean Squared Error (MSE) loss function and the vanilla GAN loss function. MSE is defined as the mean of the 2-Norm squared of n samples x in a batch and the corresponding n outputs y. It can be used to compare the difference between two types of images in a batch, as in Equation (2).
The common MSE loss is modified by converting it into a loss function for the MDTMN generator so that it focuses on the quality of distress generation in the masked region, as shown in Equation (3).
where
is the distress mask image,
denotes the generated image, and
denotes the original image. By matrix dot product of the mask with the generated image and the filled image, respectively, the region filled by the generator and the original distress region can be obtained, and by comparing the gap between these two regions, the loss of the generator can be obtained.
The loss of the discriminator is calculated by the vanilla GAN Loss formula, as in Equation (4):
where
D denotes the discriminator network of two branches that discriminate the overall image and partial distress generation, respectively.
When training is performed using a two-stage training model, the first stage training generator that uses a loss function of Equation (3), the second stage using the overall synchronization of training requires the combination of two loss functions as Equation (5).
where α is the hyperparameter set to 0.1.
4.2.4. Training Parameters Configuration
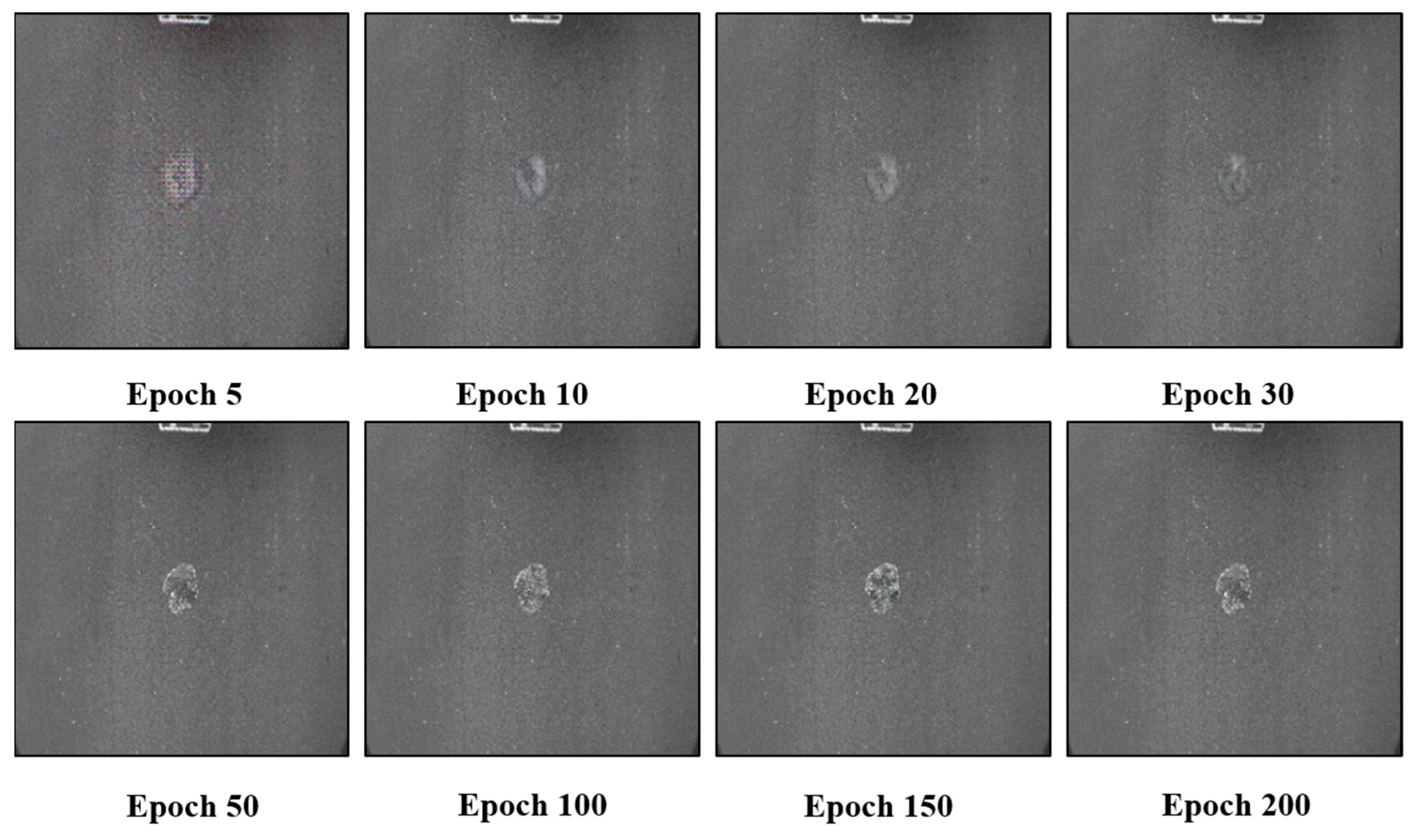
The training data are fused images, and the image size is resized to 256 × 256 in order to improve the training speed, the optimizer is selected as Adam, where the learning rate is set to 0.001, the number of generator training epochs is set to 100, the total epochs is set to 200, and the number of batches is set to 64. A total of 1600 images are used for the training, and the remaining 200 images in the dataset are used as the test set. The results of the periodic generation of the model in training are shown in
Figure 12. The outline of the potholes already appeared from the 5th epoch, and the internal structure of the potholes gradually became clear as the training epochs increased, and the generated images are very close to the real potholes after 50 epochs.
4.2.5. Qualitative Evaluation
For the comparison of network performance, in addition to the MDTMN model in this paper, three more deep learning algorithms, CPN, Cycle-GAN, and PIX2PIX, are selected for comparison. Two types of test data are adopted: one is the test set image with real potholes, as shown in
Figure 13, and the other is the image without potholes in the pavement image, which needs to be generated by the model autonomously, as shown in
Figure 13.
Figure 14 shows that among the four generation models, only CPN does not generate pavement distress. This is primarily because its training and network design do not generate semantically for the mask of the specified region. Instead, it uses the global random mask generation method. It can be seen that since there are many pavements context in the figure, the CPN focuses more attention on the generation of pavement context, and its generated images also generate the mask into pavement context. Cycle-GAN is an unsupervised generative adversarial network because it does not strictly restrict the generation semantic and the hidden variables are not sufficiently separated. Although the cyclic bidirectional generation is used for training, its generation semantic is still disturbed by other hidden variables, and even though the contours of the potholes in the generated images can be seen, the overall image quality is poor and blurred, and there is more additional noise. Only MDTMN and PIX2PIX can generate the pits correctly, among which MDTMN has the best quality of pits generation, closest to the original pothole image, the clearest contours, and the most details inside the pothole. The last row shows an image with two potholes masks. Although both MDTMN and PIX2PIX generate the double potholes correctly, the former is slightly more realistic than the latter. For the small pothole at the bottom right, the interior generated by PIX2PIX is close to off-white, but the actual interior color is gray-black, and only MDTMN is closer.
Figure 14 shows the results of generating the original pavement image without pothole lesions by each model. The MDTMN still generates good results, and although there is no GT image for comparison, the details inside the generated potholes are still rich, and especially, there is no “model collapse” phenomenon. The MDTMN model can generate different details of potholes distress according to different masks. The best performance in the test of freely generated distress images is MDTMN, whereas CPN still fails to generate potholes, and Cycle-GAN’s still suffers from implicit semantic interference generating images that still contain a lot of noise.
4.2.6. Quantitative Evaluation
The generated results of MDTMN are already very close to the real pavement distress images in terms of visual perception, but still need to be evaluated quantitatively. In this section, four evaluation indexes, PSNR, SSIM, FID, and LPIPS, are used to evaluate them in terms of SNR, structural similarity, and visual perception, respectively.
The LPIPS (Learned Perceptual Image Patch Similarity) of the four metrics uses depth features for the perceptual metric of two images. The calculation procedure is as follows, the reference image and the generated image
x and
x0 are fed into the underlying network
F for feature extraction of a total of
L layers, and then feature normalization is performed, where the features of the lth layer can be expressed as
, the scaling channel is activated using vector
and then the L2 distance is calculated, mean in space, and summed over the lth layer, as in Equation (6).
The evaluation of the generated results of these four models is shown in
Table 2.
The performance metrics of each model with reference images are shown in
Table 2, in which MDTMN leads all models. However, in PSNR, it is only slightly ahead of PIX2PIX. Likewise, slightly behind are CPN and Cycle-GAN, which have the worst visual effect, and have the lowest scores for all evaluation metrics. It is worth noting the score of PSNR. Although MDTMN achieves a better generation effect, the highest score in this item is indeed the result of CPN algorithm, because it only focuses on the difference of pixel values and is not sensitive to the image structure and semantic distribution, so this score cannot be used to evaluate the quality of generated images alone.
To evaluate the gap between autonomously generated distress and real pavement distress, since there are no paired GT images, this paper follows the batch images from the perspective of visual perception, and the comparison results in
Table 3 show that MDTMN is optimal in both visual perception proximity scores, proving that its generated images are closest to the real distress.
4.3. Pixel-Wise Pavement Distress Detection Test
To demonstrate the effectiveness of data augmentation, this paper uses the semantic segmentation network BiseNet to perform pixel-level distress detection on the original 102 pothole images (90 images for training) and 850 crack images (770 images for training) at the beginning. Then, the pothole images augmented by the conventional algorithm, the synthetic pothole images augmented by the proposed algorithm, and different combinations between them will can be inserted into the training set at different training stages. More specifically, to quantify the improvement of detection performance by the number of augmented images, the original images were augmented to 300 images by the conventional and proposed algorithms, respectively. Following each round of model training, the training set was progressively expanded by incorporating 100 pothole images generated by various augmentation techniques. This procedure was iteratively performed until all augmented images in the training set were used. The results are reported in
Table 4.
From the detection performance evaluation in
Table 4, we obtain the highest IoU from the model using all 600 augmented images, reaching 0.8365, which is 1.7 times higher than the performance of the model only using the original images. The IoU boost is fastest when the number of images is boosted to twice the original images, and then the IoU boost becomes slower as the amount of data gradually increases.
In addition, when the training data is the result of a single augmentation algorithm, the detection model performs better on the proposed datasets of different magnitudes. When the training data is a mixed dataset, the detection model with a larger proportion of images augmented by the proposed algorithm in the training set has a better IoU performance of the model. Accordingly, it can be concluded that the model performance is not simply positively correlated with the number of images in the dataset, and enhancing the diversity of augmented images is a more effective means to improve the performance and robustness of detection models.
5. Conclusions
In this paper, a new two-stage image augmentation approach is proposed, in which the augmentation of pavement distress mask images is conducted in the first stage, and in the second stage, the distress-free images are first fused with the mask images, and then the distress masks in their fused images are generated to generate pavement distress to complete the image augmentation of semantic content. Moreover, M-DCGAN and MDTMN are designed for different tasks in the two phases. These two generation networks can work together in combination or separately, resulting in better performance than using the same type of algorithms. In addition, since the generation approach of the pavement distress images is based on the distress mask generation, it can be naturally used as the well-labeled training data for the semantic segmentation model, which saves a lot of labor. This approach can leverage the full range of data in the dataset, including images without pavement distress. When comparing the datasets augmented by traditional algorithms for detection experiments, the augmented datasets using the proposed algorithm can lead to better performance of the detection model. This image augmentation model with associated generative model is generic and can be used to augment other similar datasets as well.
Furthermore, data augmentation is a performance-demanding task for algorithms. Augmentation algorithms need to find a balance between computational complexity and efficiency. The proposed algorithms are based on the SE module, DCGAN, and U-net. All three network structures are well known for their low computational complexity and high efficiency. Therefore, the proposed algorithms possess these advantages as well.

 ,
, 














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}