
A Variable Attention Nested UNet++ Network-Based NDT X-ray Image Defect Segmentation Method


Abstract
:1. Introduction
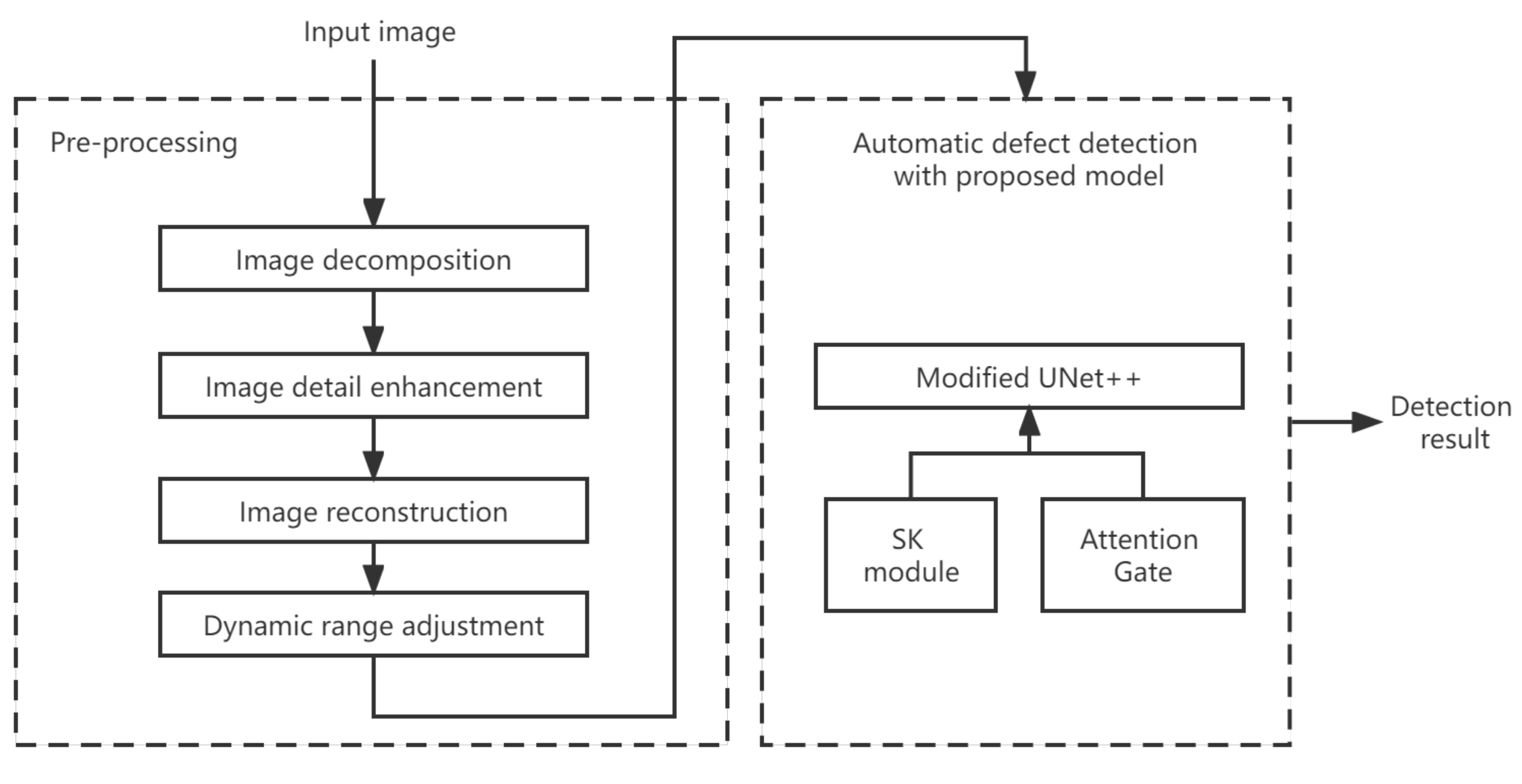
2. Methods Section: Algorithm
2.1. Image Pre-Processing
2.1.1. Image Decomposition and Reconstruction
2.1.2. Image Detail Enhancement
2.1.3. Reduced Dynamic Range
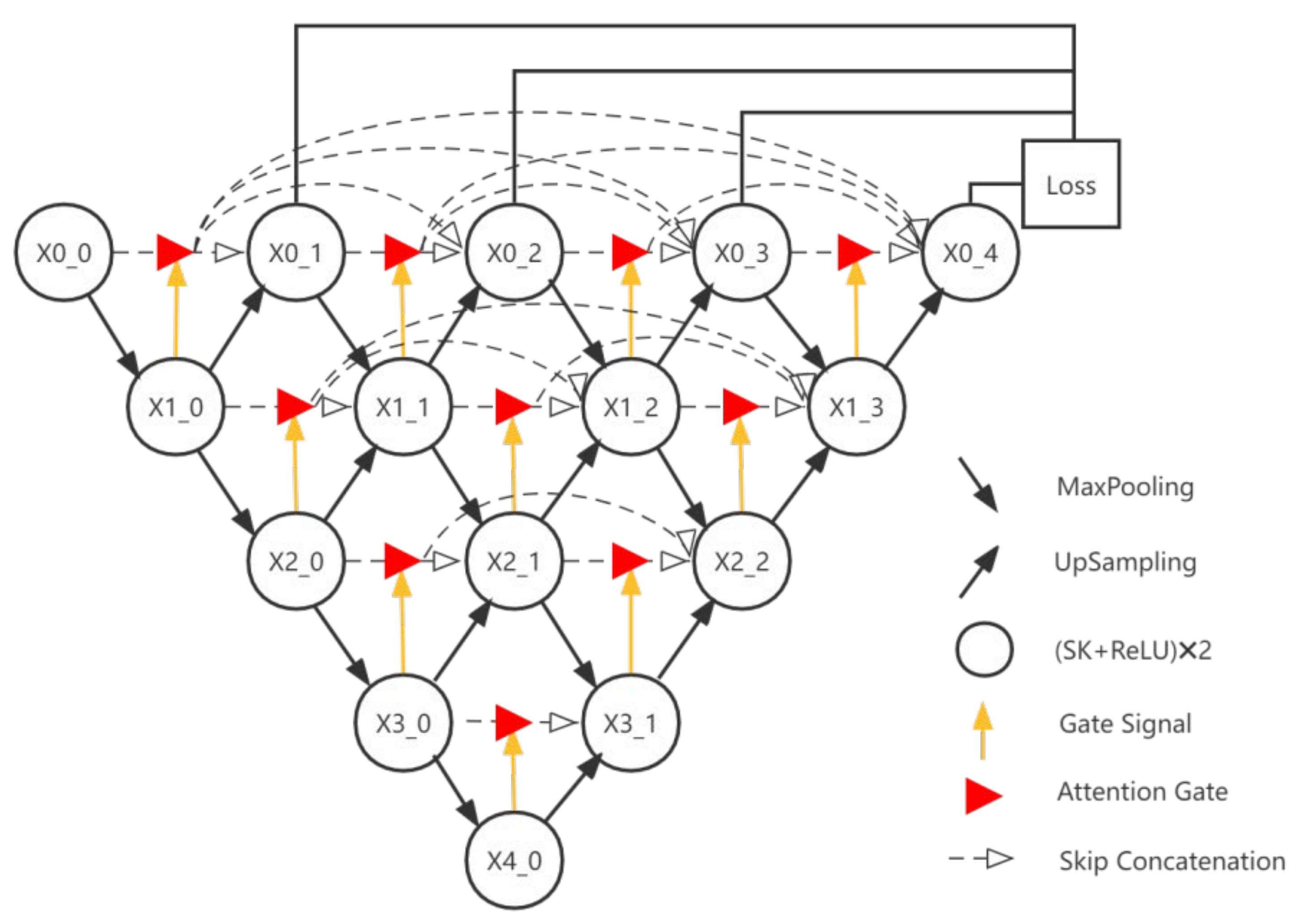
2.2. Defect Segmentation Network
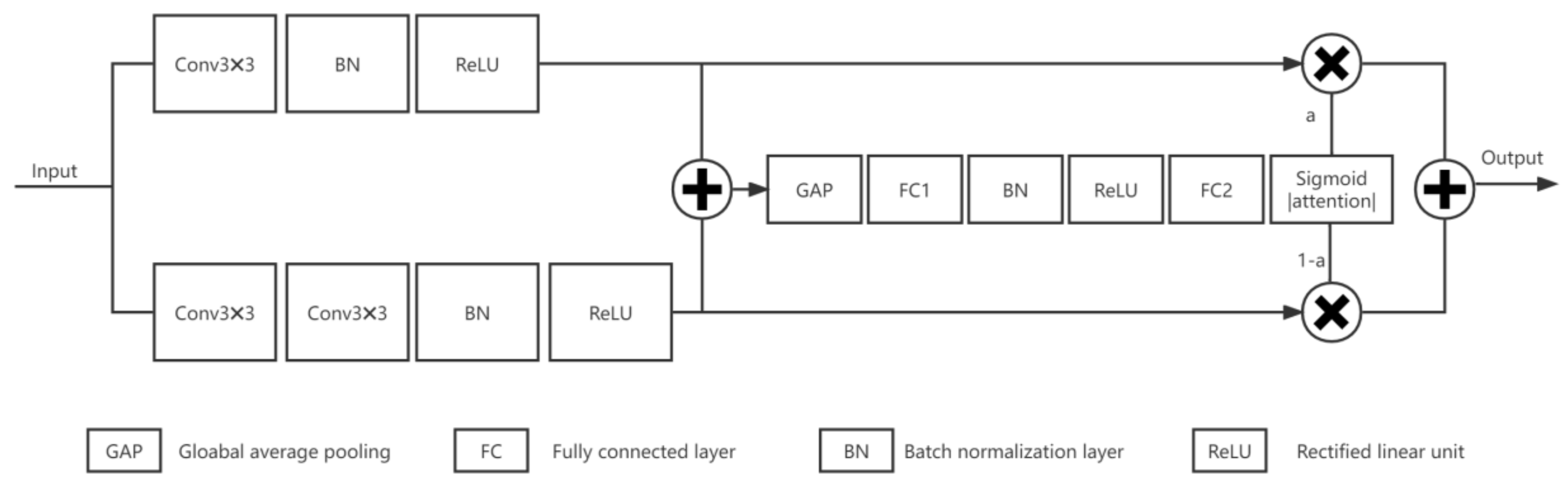
- The traditional convolutional blocks are replaced by SK blocks, and the convolutional blocks with a perceptual field of 5 in the SK blocks are replaced by two 3x3 convolutions in series, which not only improve the depth of the network but also reduce the computation and the number of parameters. By using the SK block, the perceptual field can be automatically adjusted to utilize the feature information extracted at different scales more effectively.
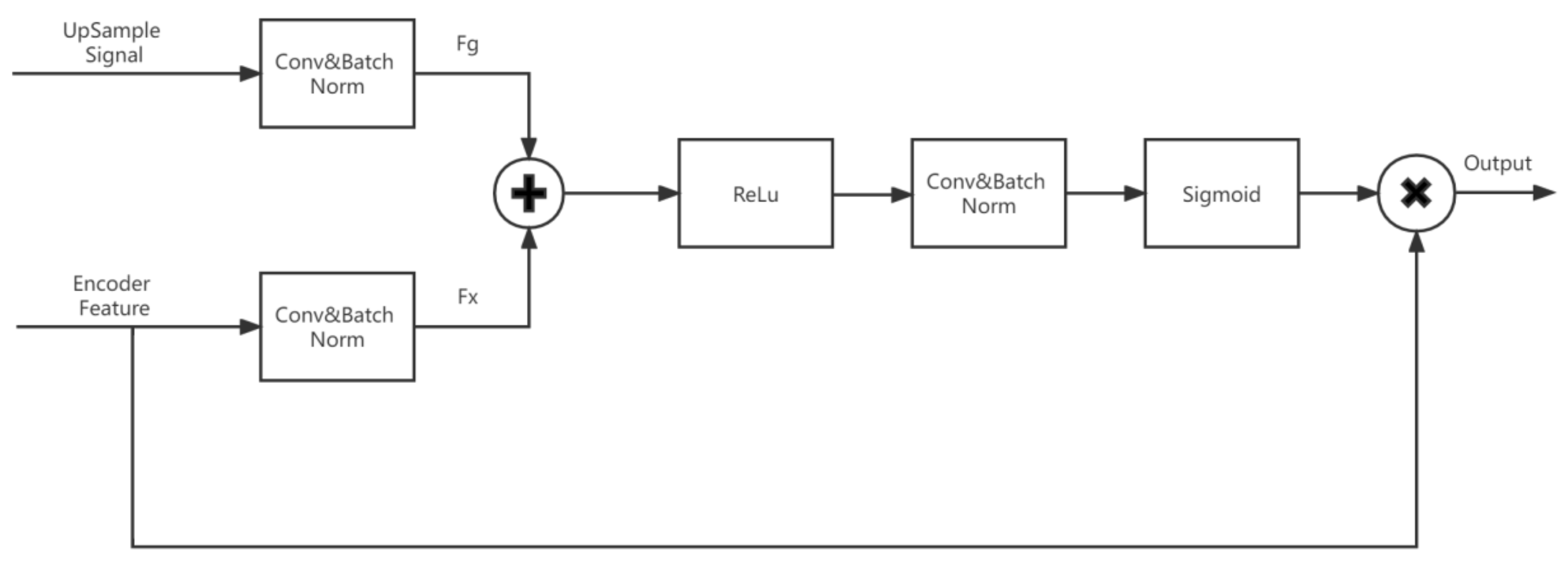
- Adding attention gates between nested convolutional blocks enables increase of the weight of the target region while suppressing background regions that are not relevant to the segmentation task.
- It enables model pruning during testing by introducing deep supervision, which can reduce a large number of model parameters and thus speed up the model segmentation.
3. Experimental Section
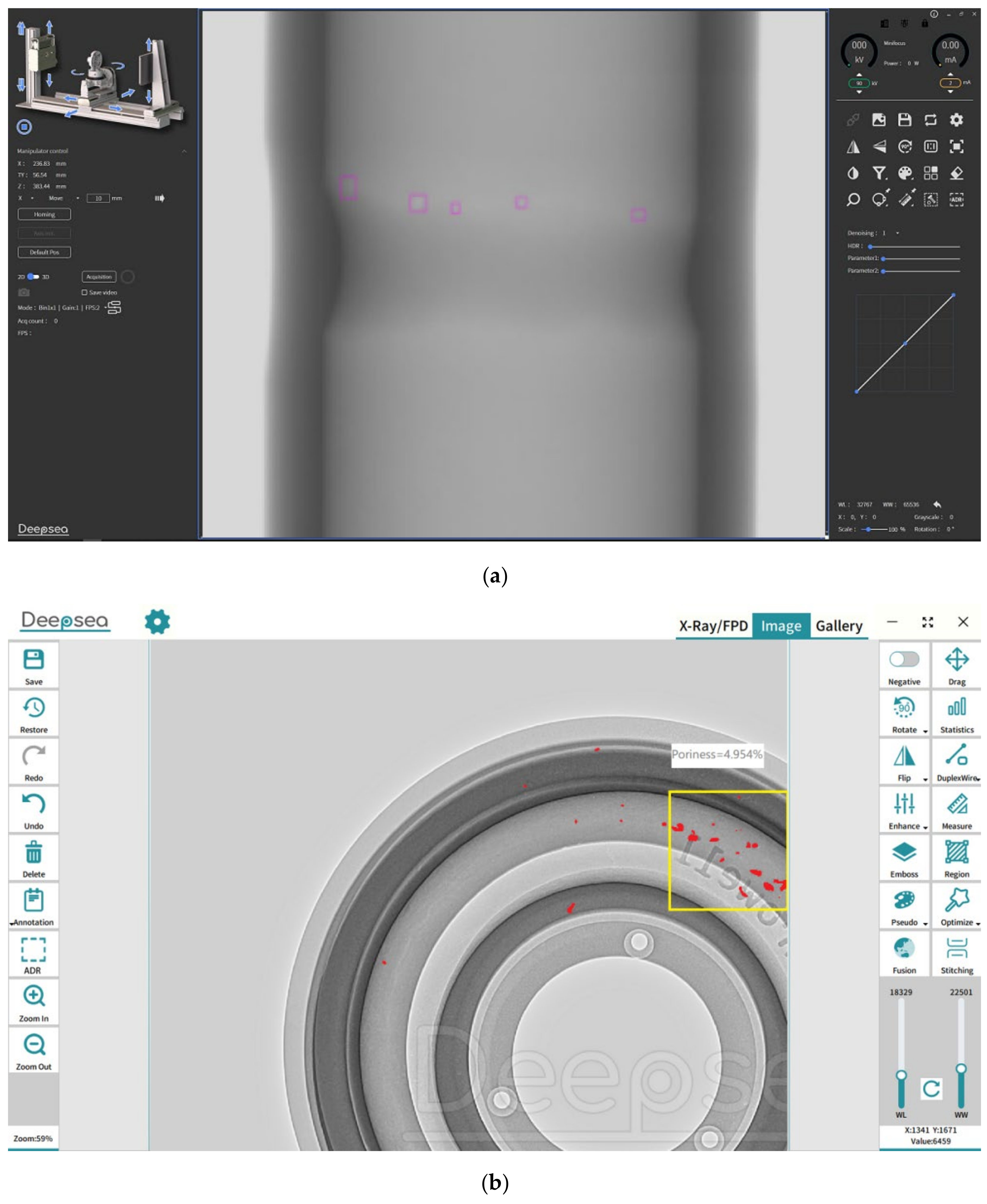
3.1. Experimental Equipment and Database
- Most of the castings are aluminum alloy parts for automobiles, such as engine cylinder heads, steering knuckles, shock absorbers, valves, power supply housings, etc. A small portion are magnesium alloy parts for 3C products, such as Bluetooth headset metal frames, laptop bezels, etc.
- Welds are stainless steel/titanium alloy, collected from rocket engine ducts, aircraft seat bases, gas pipe welds, etc. A small portion are steel welds from 3C.
- Open the image, perform manual annotation, outline each defect and save it as a json label file.
- Open a json file and convert the json into a mask label image.
- After the conversion is completed, a label folder is generated, including the original image img.png, label image label.png, label visualization image label_viz.png, txt file of label name, and yaml format label name file.
- Image bits. Most modern flat panel detectors output 16-bit images, older detectors are 12 or 14 bit, and earlier image intensifiers are 8 or 10 bit. The database uses the original 16-bit image with the addition of a pre-processed 16-bit image and an 8-bit image.
- Image resolution. Depending on the specifications of the flat panel detector, there is no uniform specification for the resolution of the images in the database. The pixel sizes of most images are 3072 × 3072, 1536 × 1536, 2000 × 2000, which users can choose according to their needs and can even be freely cropped if necessary.
- Image format. The 10-bit, 12-bit, 14-bit, and 16-bit images in the database use the industry standard image format, i.e., DICONDE format, and also keep a copy in TIFF format. 8-bit images are saved in PNG format.
3.2. Experimental Setup
3.3. Segmentation Evaluation Metrics
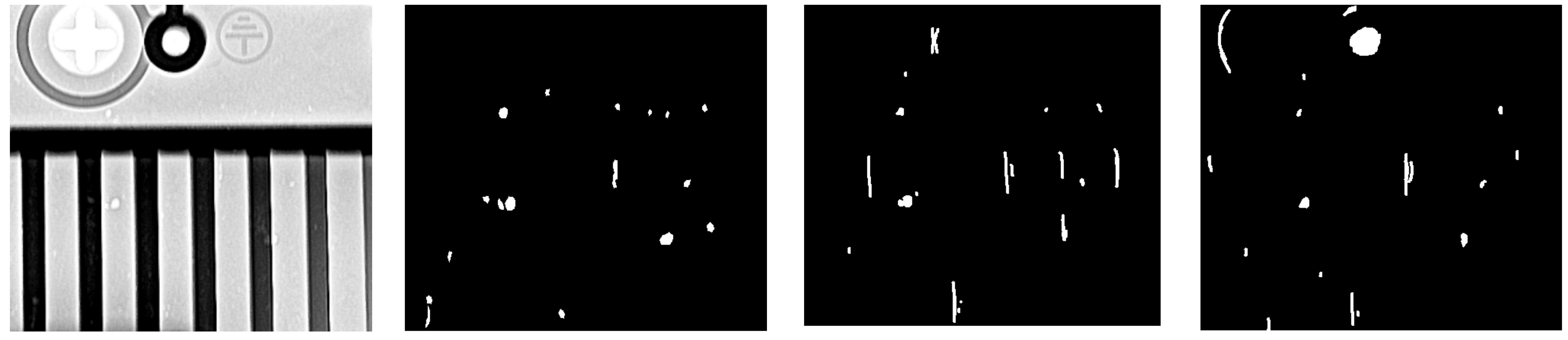
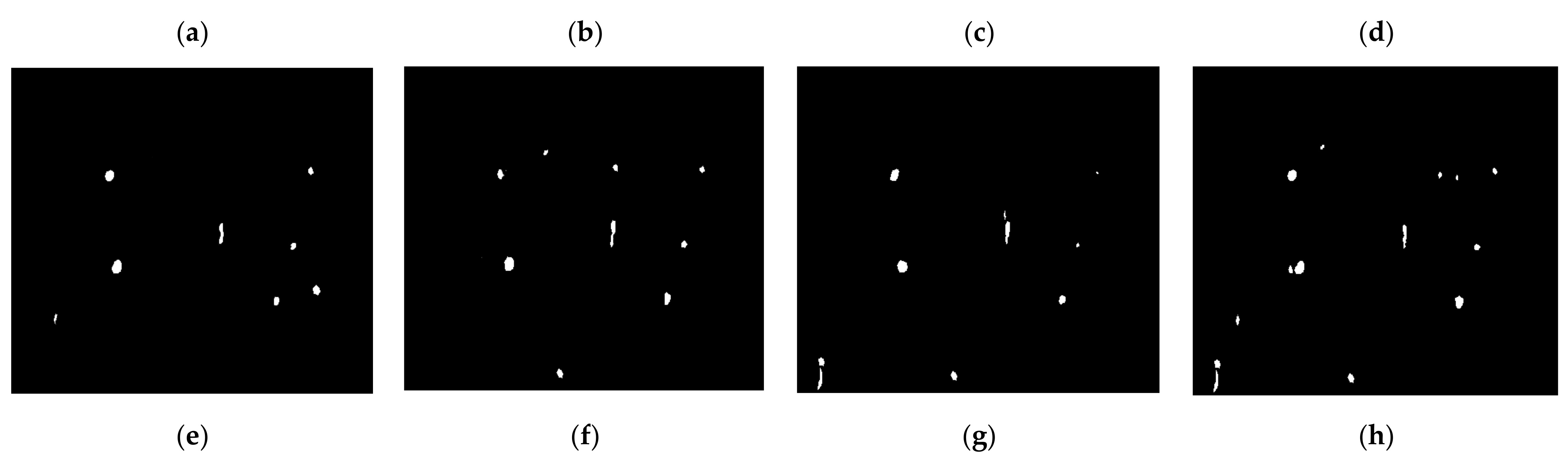
3.4. Segmentation Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Mery, D. Automatic Defect Detection in Aluminium Castings using Radioscopic Image Sequences. Met. Cast. Technol. 2003, 49, 1. [Google Scholar]
- Hangai, Y.; Kawato, D.; Ando, M.; Ohashi, M.; Morisada, Y.; Ogura, T.; Fujii, H.; Nagahiro, R.; Amagai, K.; Utsunomiya, T.; et al. Nondestructive observation of pores during press forming of aluminum foam by X-ray radiography. Mater. Charact. 2022, 170, 110631. [Google Scholar] [CrossRef]
- Fadel, N.; Al-Hameed, W.; Ahmed, M.K. Non Destructive Testing For Detection abnormal Object in The X-Ray Images. J. Phys. Conf. Ser. 2020, 1660, 012104. [Google Scholar] [CrossRef]
- Mery, D.; Filbert, D. Automated flaw detection in aluminum castings based on the tracking of potential defects in a radioscopic image sequence. IEEE Trans. Robot. Autom. 2002, 18, 890–901. [Google Scholar] [CrossRef] [Green Version]
- Mery, D. Automated radioscopic testing of aluminum die castings. Mater. Eval. 2006, 64, 135–143. [Google Scholar]
- Da Silva, R.R.; Mery, D. State-of-the-art of weld seam inspection by radiographic testing. Image Processing Mater. Eval. 2007, 6, 643–647. [Google Scholar]
- Connolly, C. X-ray systems for security and industrial inspection. Sens. Rev. 2008, 28, 194–198. [Google Scholar] [CrossRef]
- Pieringer, C.; Mery, D. Flaw detection in aluminium die castings using simultaneous combination of multiple views. Insight-Non-Destr. Test. Cond. Monit. 2010, 52, 548–552. [Google Scholar] [CrossRef]
- Mery, D.; Lillo, I.; Loebel, H.; Riffo, V.; Soto, A.; Cipriano, A.; Aguilera, J.M. Automated fish bone detection using X-ray imaging. J. Food Eng. 2011, 105, 485–492. [Google Scholar] [CrossRef]
- Mery, D. Inspection of complex objects using multiple-X-ray views. IEEE/ASME Trans. Mechatron. 2014, 20, 338–347. [Google Scholar] [CrossRef]
- Wang, Z. Automatic localization and segmentation of the ventricles in magnetic resonance images. IEEE Trans. Circuits Syst. Video Technol. 2020, 31, 621–631. [Google Scholar] [CrossRef]
- Wang, Z. A new approach for segmentation and quantification of cells or nanoparticles. IEEE Trans. Ind. Inform. 2016, 12, 962–971. [Google Scholar] [CrossRef]
- Mery, D.; Hahn, D.; Hitschfeld, N. Simulation of defects in aluminium castings using CAD models of flaws and real X-ray images. Insight-Non-Destr. Test. Cond. Monit. 2005, 47, 618–624. [Google Scholar] [CrossRef]
- Mery, D.; Arteta, C. Automatic defect recognition in x-ray testing using computer vision. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017. [Google Scholar]
- Mery, D.; Pieringer, C. Computer Vision for X-ray Testing: Imaging, Systems, Image Databases, and Algorithms, 2nd ed; Springer International Publishing: Cham, Switzerland, 2021. [Google Scholar]
- Liu, L.; Ouyang, W.; Wang, X.; Fieguth, P.; Chen, J.; Liu, X.; Pietikäinen, M. Deep learning for generic object detection: A survey. Int. J. Comput. Vis. 2020, 128, 261–318. [Google Scholar] [CrossRef] [Green Version]
- Mery, D.; Pieringer, C. Deep Learning in X-ray Testing. In Computer Vision for X-ray Testing; Springer: Cham, Switzerland, 2021; pp. 275–336. [Google Scholar]
- Mery, D. Aluminum casting inspection using deep object detection methods and simulated ellipsoidal Defects. Mach. Vis. Appl. 2021, 32, 1–16. [Google Scholar] [CrossRef]
- Tokime, R.; Maldague, X.; Perron, L. Automatic Defect Detection for X-Ray inspection: Identifying defects with deep convolutional network. In Proceedings of the Canadian Institute for Non-destructive Evaluation (CINDE), Edmonton, AB, Canada, 18–20 June 2019. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for Biomedical Image Segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, 2015. [Google Scholar]
- Li, X.; Chen, H.; Qi, X.; Dou, Q.; Fu, C.W.; Heng, P.A. H-DenseUNet: Hybrid densely connected UNet for liver and tumor segmentation from CT volumes. IEEE Trans. Med. Imaging 2018, 37, 2663–2674. [Google Scholar] [CrossRef] [Green Version]
- Tokime, R.B.; Maldague, X.; Perron, L. Automatic Defect Detection for X-ray inspection: A U-Net approach for defect segmentation. In Proceedings of the Digital Imaging and Ultrasonics for NDT Conference 2019, New Orleans, LA, USA, 23–25 July 2019. [Google Scholar]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Cham, Switzerland, 2018; pp. 3–11. [Google Scholar]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. Unet++: Redesigning skip connections to exploit multiscale features in image segmentation. IEEE Trans. Med. Imaging 2019, 39, 1856–1867. [Google Scholar] [CrossRef] [Green Version]
- Li, C.; Tan, Y.; Chen, W.; Luo, X.; Gao, Y.; Jia, X.; Wang, Z. Attention unet++: A nested attention-aware u-net for liver ct image segmentation. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020. [Google Scholar]
- Gite, S.; Mishra, A.; Kotecha, K. Enhanced lung image segmentation using deep learning. Neural Comput. Appl. 2022, 1–15. [Google Scholar] [CrossRef]
- Zhou, Q.; Wang, Q.; Bao, Y.; Kong, L.; Jin, X.; Ou, W. LAEDNet: A Lightweight Attention Encoder–Decoder Network for ultrasound medical image segmentation. Comput. Electr. Eng. 2022, 99, 107777. [Google Scholar] [CrossRef]
- Tahira, A.M.; Chowdhury, M.E.H.; Khandakar, A.; Rahman, T.; Qiblawey, Y.; Khurshid, U.; Kiranyaz, S.; Ibtehaz, N.; Sohel Rahman, M.; Al-Maadeed, S.; et al. COVID-19 infection localization and severity grading from chest X-ray images. Comput. Biol. Med. 2021, 139, 105002. [Google Scholar] [CrossRef]
- Diniz, J.O.B.; Dias Júnior, D.A.; da Cruz, L.B.; da Silva, G.L.F.; Ferreira, J.L. Heart segmentation in planning CT using 2.5 D U-Net++ with attention gate. Comput. Methods Biomech. Biomed. Eng. Imaging Vis. 2022; 1–9, in press. [Google Scholar] [CrossRef]
- Jia, Y.; Liu, L.; Zhang, C. Moon Impact Crater Detection Using Nested Attention Mechanism Based UNet++. IEEE Access 2021, 9, 44107–44116. [Google Scholar] [CrossRef]
- Yang, X.; Li, X.; Ye, Y.; Zhang, X.; Zhang, H.; Huang, X.; Zhang, B. Road detection via deep residual dense u-net. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019. [Google Scholar]
- Liu, B.; Zhang, X.; Gao, Z.; Chen, L. Weld defect images classification with vgg16-based neural network. In International Forum on Digital TV and Wireless Multimedia Communications; Springer: Singapore, 2017. [Google Scholar]
- Tang, Z.; Tian, E.; Wang, Y.; Wang, L.; Yang, T. Nondestructive defect detection in castings by using spatial attention bilinear convolutional neural network. IEEE Trans. Ind. Inform. 2020, 17, 82–89. [Google Scholar] [CrossRef]
- Lin, T.; Dollár, P.; Girshick, R.; He, K. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Du, W.; Shen, H.; Fu, J.; Zhang, G.; He, Q. Approaches for improvement of the X-ray image defect detection of automobile casting aluminum parts based on deep learning. NDT E Int. 2019, 107, 102144. [Google Scholar] [CrossRef]
- Du, W.; Shen, H.; Fu, J.; Zhang, G.; Shi, X.; He, Q. Automated detection of defects with low semantic information in X-ray images based on deep learning. J. Intell. Manuf. 2021, 32, 141–156. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Yang, J.; Zhao, Z.; Zhang, H.; Shi, Y. Data augmentation for X-ray prohibited item images using generative adversarial networks. IEEE Access 2019, 7, 28894–28902. [Google Scholar] [CrossRef]
- Mery, D. Aluminum casting inspection using deep learning: A method based on convolutional neural networks. J. Nondestruct. Eval. 2020, 39, 1–12. [Google Scholar] [CrossRef]
- Niu, S.; Li, B.; Wang, X.; Lin, H. Defect image sample generation with GAN for improving defect recognition. IEEE Trans. Autom. Sci. Eng. 2020, 17, 1611–1622. [Google Scholar] [CrossRef]
- Mery, D.; Riffo, V.; Zscherpel, U.; Mondragón, G.; Lillo, I.; Zuccar, I.; Lobel, H.; Carrasco, M. GDXray: The database of X-ray images for nondestructive testing. J. Nondestruct. Eval. 2015, 34, 1–12. [Google Scholar] [CrossRef]
- Deepsea Precision Co., Ltd. Shenzhen City, China. Available online: http://www.shenhaijingmi.com/ (accessed on 2 April 2022).
- ASTM E2339-15. Standard Practice for Digital Imaging and Communication in Nondestructive Evaluation (DICONDE), 2015 Edition. 1 December 2015. Available online: https://www.astm.org/e2339-15.html (accessed on 1 April 2022).
- Intel Corporation. Stylized as Intel, Is an American Multinational Corporation and Technology Company Headquartered in Santa Clara, California, USA. Available online: https://www.intel.com/ (accessed on 1 April 2022).
- Nvidia. Nvidia Corporation Is an American multinational Technology Company Incorporated in Delaware and Based in Santa Clara, California, USA. Available online: https://www.nvidia.com/ (accessed on 1 April 2022).















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Types | Methods and Brief Description | Advantages | Disadvantages |
|---|---|---|---|
| Unsupervised | Median and morphological filters, Ref [12] | Very easy to implement. | Does not work well on images with slightly complex backgrounds. |
| Defect detection based on traditional algorithms, Ref [4] | Better performance than simple morphological and threshold. | Poor results on complex background images. | |
| Supervised | LBP descriptor with an SVM-linear classifier, Ref [16] | Simple features and framework structure. | Not a pixel-level defect segmentation. |
| U-Net, Ref [21] | Thicker features, defect fusion at different scales. | The evaluation score of 80% indicates that the system needs modification for better performance. | |
| Proposed method | Developed HDR pre-processing to enhance more details, large quantity and huge variety of images for training | A little bit time-consuming; it is still acceptable for practical applications. |
| Device Name | Brand/Model | Basic Configuration |
|---|---|---|
| X-ray emission device (macro-focus) | Gulmay/CF500 | 500 kV, focus size 0.4/1.0 mm |
| X-ray emission device (micro-focus) | WorX/XWT-225-CT | 225 kV, focal size 5 μm |
| X-ray receiver device (flat panel detector) | Deepsea/DS4343HR | 430 mm ∗ 430 mm, pixel size 139 μm |
| Workstation Software | Deepsea/DeepVISION | GPU-based architecture |
| Types | Sample Name | Amount |
|---|---|---|
| Castings | engine cylinder heads | 10,500 |
| steering knuckles | 8602 | |
| shock absorbers | 15,610 | |
| valves | 9500 | |
| power supply housings | 6500 | |
| 3C products and others | 18,805 | |
| Welds | rocket engine ducts | 12,655 |
| aircraft seat bases | 5431 | |
| gas pipe welds | 25,820 | |
| steel welds from 3C and others | 12,907 |
| The Original Image | The Label Image | The Label Visualization Image |
|---|---|---|
 |  |  |
| Models | IoU | Dice | #Parameters | Time per Epoch |
|---|---|---|---|---|
| Median and morphological filters, Ref [3] | 0.3012 | 0.4630 | -- | -- |
| Defect detection based on traditional algorithms, Ref [4] | 0.4155 | 0.5871 | -- | -- |
| Mask R-CNN | 0.7360 | 0.8479 | 25.3 M | 38 s |
| U-Net | 0.7251 | 0.8406 | 32.5 M | 16 s |
| Standard UNet++ | 0.7629 | 0.8656 | 35.6 M | 39 s |
| Proposed Method | 0.8924 | 0.9431 | 36.8 M | 42 s |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, J.; Kim, J.H. A Variable Attention Nested UNet++ Network-Based NDT X-ray Image Defect Segmentation Method. Coatings 2022, 12, 634. https://doi.org/10.3390/coatings12050634
Liu J, Kim JH. A Variable Attention Nested UNet++ Network-Based NDT X-ray Image Defect Segmentation Method. Coatings. 2022; 12(5):634. https://doi.org/10.3390/coatings12050634
Chicago/Turabian StyleLiu, Jiayin, and Jae Ho Kim. 2022. "A Variable Attention Nested UNet++ Network-Based NDT X-ray Image Defect Segmentation Method" Coatings 12, no. 5: 634. https://doi.org/10.3390/coatings12050634