1. Knowledge Representations: Individual Differences in Novel Problem Solving
Research on novel problem solving (i.e., problems with which the solver is not already familiar) is incredibly diverse, with problem solving being studied in the context of intelligence and reasoning (e.g.,
Bethell-Fox et al. 1984;
Carpenter et al. 1990;
Snow 1980), analogical transfer (e.g.,
Cushen and Wiley 2018;
Gick and Holyoak 1980), expertise (e.g.,
Chi et al. 1981;
Novick 1988;
Wiley 1998), and even skill acquisition (e.g.,
Anderson 1987;
Patsenko and Altmann 2010). Separately, these domains have addressed different aspects of problem solving (e.g., learning, transfer, knowledge, individual differences, strategy use, etc.) but the lack of communication across those areas has left a large hole in our understanding of how all of these complex processes interact with each other. In particular, studies involving reasoning tasks primarily focus on the role of stable individual differences, such as working memory capacity (WMC;
Ackerman et al. 2005;
Jarosz and Wiley 2012;
Unsworth et al. 2014). In contrast, studies using classic problem-solving tasks or domain-specific tasks (e.g., physics problems) have focused more on strategies and knowledge (
Chi et al. 1981;
Holyoak and Koh 1987;
Novick 1988). Although individual differences in reasoning and problem solving (
Kubricht et al. 2017;
Ricks et al. 2007;
Sohn and Doane 2003,
2004) have been studied from both a working memory and a knowledge perspective, there remain questions about how the two interact.
2. Working Memory Capacity and Problem Solving
Much of the early work that investigated individual differences in problem solving used tasks designed to measure fluid intelligence (Gf) because they have a great degree of variability and are intended to be novel, and thus they should not be driven by individual differences in knowledge (
Carroll 1993). These tasks were helpful in trying to isolate the non-knowledge-based cognitive processes that contributed to reasoning and problem solving. Early work in this area used tasks such as geometric analogies (
Bethell-Fox et al. 1984) or Raven’s Advanced Progressive Matrices (RAPM;
Raven et al. 1962) to assess Gf. In many of these tasks, the stimuli are a series of shapes and patterns that change according to rules. The objective of the task is to extract the rules and apply them. An example of a figural analogy problem is shown in
Figure 1.
Though there are currently many different theories that postulate different structures for working memory (
Baddeley 2000;
Barrouillet et al. 2004;
Cowan 2005;
Oberauer et al. 2003;
Unsworth 2016),
Unsworth (
2016) suggested three components that make up WMC: primary memory, attentional control, and retrieval from secondary memory. Each of these subcomponents may play an important role in the relationship between WMC and Gf (
Unsworth et al. 2014), and together explain virtually all of their shared variance. For example, the capacity account (
Carpenter et al. 1990) of the WMC and Gf relationship would argue that primary memory allows one to hold the various rules, objects, or goals and subgoals required in a temporary storage space during problem solving. According to the distraction account (
Jarosz and Wiley 2012;
Wiley et al. 2011), attentional control provides the necessary resources to focus on desired information while ignoring irrelevant or distracting information coming from within or between problems. Retrieval from secondary memory is the process of retrieving previously learned information and can be useful in retrieving rules and transformations that correctly led to previous solutions, a key process in the learning account (
Verguts and De Boeck 2002). Each of these components explains unique variance in WMC (
Unsworth 2016;
Unsworth et al. 2014;
Unsworth and Spillers 2010) and appear to uniquely contribute to problem solving and reasoning (
Unsworth et al. 2014). However, although these subcomponents can fully explain WMC’s relationship with Gf, WMC does not account for all of the variability found in Gf tasks (
Ackerman et al. 2005;
Kane et al. 2005;
Oberauer et al. 2005).
Although the role of WMC has been heavily studied within reasoning tasks, the mechanistic role it plays during solution and how WMC processes differ from other cognitive processes involved in reasoning tasks remain unclear.
Kovacs and Conway (
2016) argue that Gf is unlikely to be a unitary construct and, rather, performance on Gf tasks reflects multiple basic processes that are necessary for most Gf tasks. Given that WMC is also comprised of more basic processes and that the shared processes between WMC and Gf do not account for all of the variability in Gf (
Ackerman et al. 2005;
Kovacs and Conway 2016;
Unsworth et al. 2014), other mechanisms must be considered to fully understand individual differences in reasoning and problem solving.
5. The Present Study
Although the combination of several literatures has provided information on how knowledge and WMC contribute to and interact during problem solving, there are several research questions that have remained unanswered. Of primary concern are the differential problem-solving processes accounted for by WMC and knowledge. WMC clearly contributes to problem solving, but the mechanisms through which it acts remain under debate (
Carpenter et al. 1990;
Verguts and De Boeck 2002;
Wiley et al. 2011). Because WMC may contribute to knowledge at the encoding stage as well as the retrieval stage, it is important to identify what is breaking down when a solver fails to find or transfer a solution.
To start to isolate knowledge-specific problem-solving processes from general cognitive processes (e.g., attention) in the present study, several changes were made to existing methods in the problem-solving domain. Concerns with analogical transfer stimuli (i.e., using a small sample of fairly difficult problems) were resolved by using a figural analogy task. This ensures that there are multiple target and source problems, as well as making it easier to create problem isomorphs. Additionally, a reasoning task contains more active problem solving than when solely using classical analogical transfer materials. This ensures that there is enough variability in the task that individual differences in problem-solving skill will still be measured.
To keep track of knowledge and transfer throughout the task, stimuli were constructed such that all problems could be decomposed into rules. For example, one problem may require two objects to swap locations, a rotation of those objects, as well as a size change. Another problem may only require a rotation and a size change. Problems were considered unique based upon the combination of rules. To test the effects of increased knowledge on problem solving and transfer, participants first learned a select set of individual rules during a training phase, then were tested on more complex problems involving multiple rules.
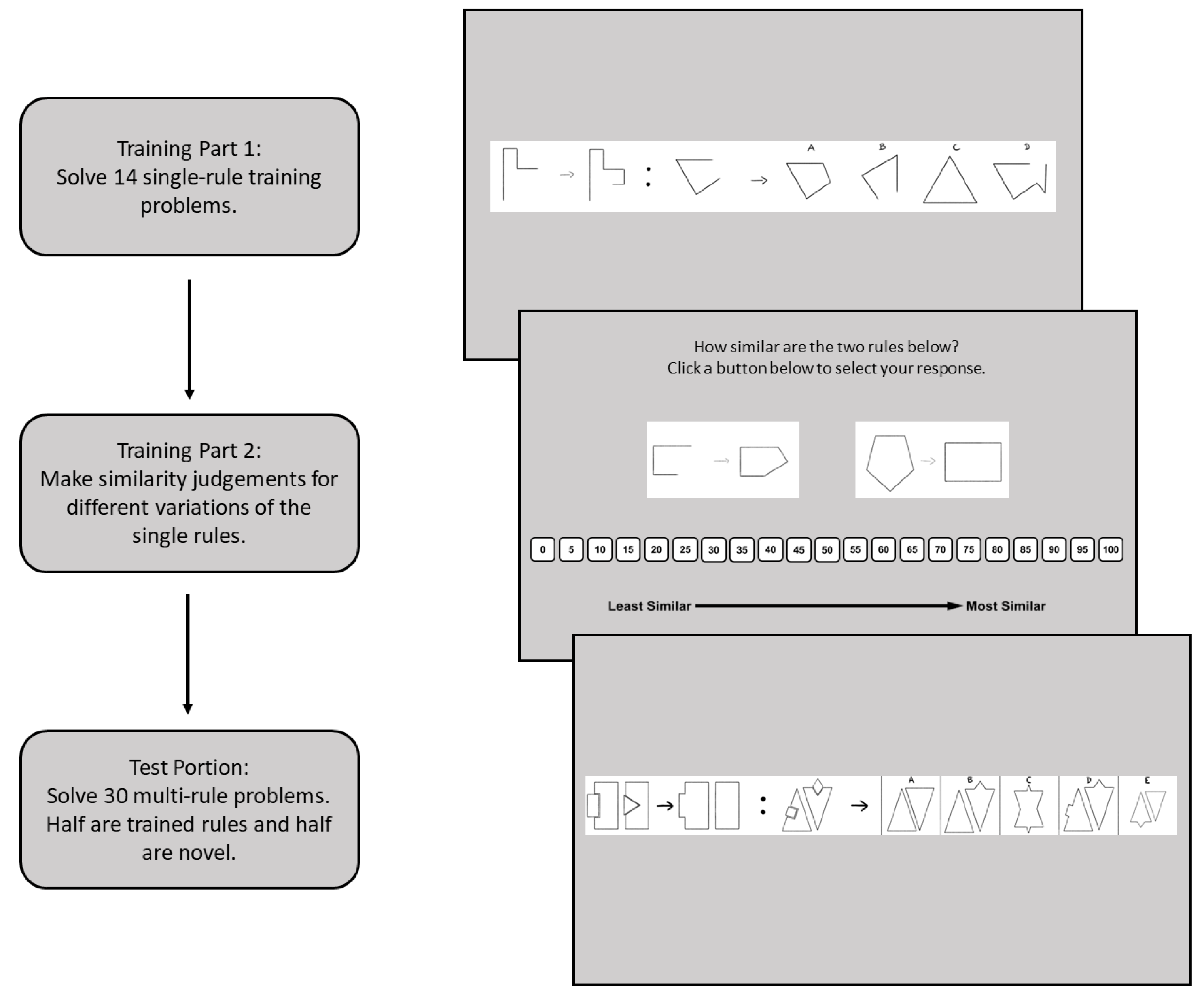
Figure 2 provides an illustration of the general procedure.
To avoid biasing participants towards a particular representation of the rule, participants were not given the rule explicitly. Rather, rules were learned by solving simple problems that contained only one of those rules, (e.g., a problem where the answer is a single size change). The single-rule problems were designed to be solved fairly easily, such that participants could induce the rule on their own. This was accomplished by only using one rule, reducing the visual complexity of items compared to the standard figural analogies task, and reducing the number of response options from five to four. Furthermore, two variations of each rule were shown during the training phase.
During the test portion, participants solved items that included at least two rules. Half of the test items were comprised of only the rules given in the training portion, and the other half were comprised of entirely new rules. If participants were able to successfully transfer the rules learned in the training portion, even in a context where multiple pieces of information must be used, then participants should have higher accuracy on the test items that were comprised of the trained rules when compared to the items that consist of new rules.
Both the expertise literature and the analogical transfer literature have demonstrated that knowledge representations are crucial to knowledge being used, with an emphasis on structure and less emphasis on surface features being particularly beneficial for transferring that knowledge. As such, the representation quality of the rules may be critically important. To measure this, participants were asked to rate numerically how similar they thought two problems were. Participants were shown only the A:B component of a problem rather than the full version with A:B :: C:? so that they could focus on the rule and not on problem solving. The A:B components they saw came from the rules shown in the initial training phase problems. This ensured that participants were making similarity judgements on items for which they had successfully induced the rule previously. Of primary interest was how closely the individual rated slightly different versions of the same rules compared to completely different rules. For example, did the solver rate a 90-degree rotation rule and a 45-degree rotation rule as equally different when compared to a rotation rule and a size-change rule, or did they treat the two versions of the rotation rule as equally similar as two different 90-degree rotation problems? Where participants fell on this spectrum was used to assess their representation, with participants ranging from more general representations (the 90-degree rotation and 45-degree rotation were very similar) to more item-specific, less general representations (the 90-degree rotation and 45-degree rotation were treated as completely separate rules).
If rule representations do indeed help to facilitate retrieval, then more general representations should correlate with higher accuracy on the trained-rule problems. Ratings on the rule representation measure may also correlate with performance on novel-rule problems because the processes that facilitate the generation of general representations may also play a role in other reasoning processes. However, it is expected that there would be a stronger relationship for the trained-rule problems because the novel-rule problems should not be drawing on retrieval processes as much.
The final set of factors to consider is the role of individual differences in WMC and reasoning. It is unclear whether WMC and/or Gf help to develop more general representations, but it is reasonable to expect that WMC and Gf will interact with the training. Because WMC may play a large role in initially learning the rules and then later facilitating the retrieval of those rules during problem solving, WMC should have a stronger relationship with accuracy for the trained items, and Gf should have a stronger relationship with accuracy for the novel items. Furthermore, relationships between the individual differences measures and the rule representation measures can be investigated. Specifically, one question is whether or not the rule representation measure can explain unique variability on the figural analogies task, or if WMC/Gf determine the quality of the representation. If the rule representation measure does uniquely explain performance on the figural analogies task after accounting for WMC and Gf, then this would provide a novel measure that could potentially explain solution transfer. If, however, the knowledge representation measure can be explained by WMC/Gf, then this would provide some further specificity on why WMC and/or Gf explain performance. Whether rule representations correlate or are predicted by WMC or Gf will also be investigated. This will help to further clarify if rule representations are truly unique, share some processes with WMC and/or Gf, or can be entirely explained by WMC and/or Gf.
7. Results
Composite scores were generated for the WMC and Gf measures by taking performance on the two tasks (operation span and symmetry span for WMC and paper folding and letter series for gf),
z-transforming the scores, and then taking the average of the two tasks
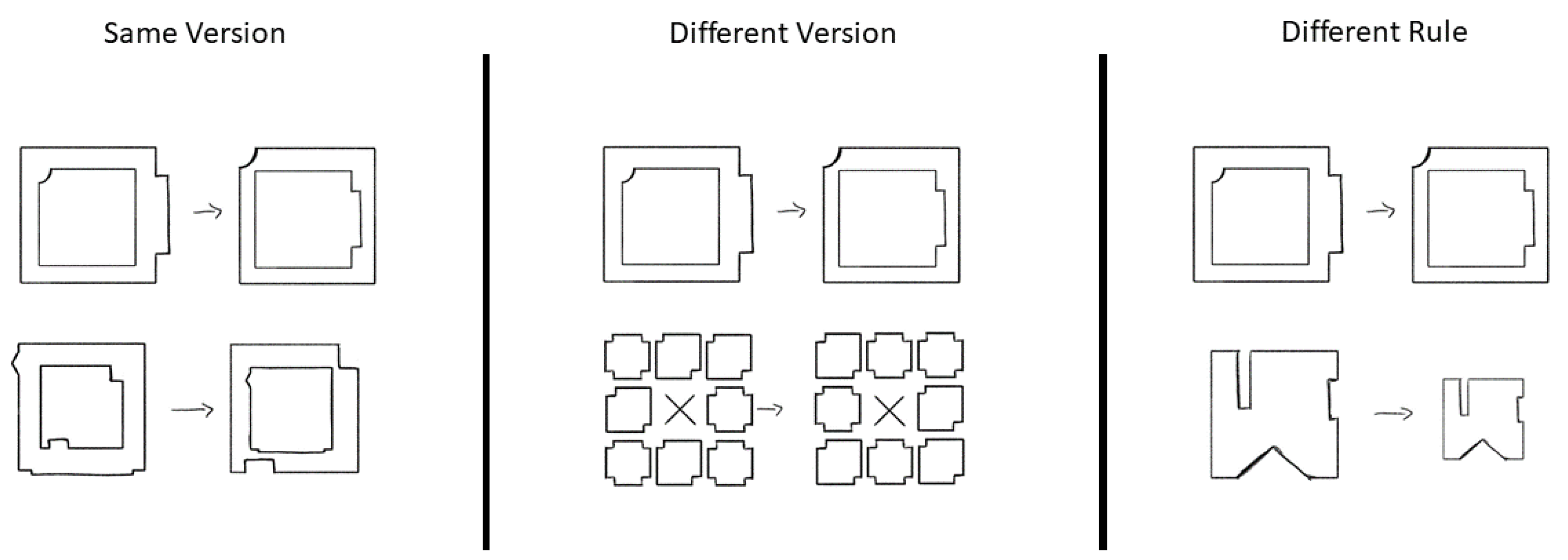
1. For the modified figural analogies task, three rule-representations scores were generated from the RSJT, one score for each type of comparison (i.e., the same rule and the same version of the rule, or “same version”; the same rule but a different version of the rule, or “different version”; or a different rule and different version, or “different rule”). These were calculated by first recentering all the scores for each participant such that their minimum score became −1 and their highest score became 1. The recentering was performed across all of their judgement scores and was not split by type of comparison. This was carried out to account for participants using the scale differently
2. Next, the average score was taken for each type of comparison for each participant, producing three scores: their average same-version comparison score, different-version comparison score, and different-rule comparison score. The primary measure of focus was their average score for the different-version comparisons. If participants have a positive value for their different-version score from the RSJT, then this would indicate that they are treating the different-version items similar to the same-version items, suggesting their representation of that rule is more general and that they are not treating different versions as entirely different rules. Conversely, if their different-version score is negative, then this would indicate that they are treating the different-version rules as separate rules.
7.1. Summary Statistics and Correlations
All summary statistics are included in
Table 1 and the correlations between all tasks are shown in
Table 2. The RSJT scores were split by the two stimulus sets in
Table 1 so that reliability could be calculated for each set. Reliability was calculated using Cronbach’s alpha at the item level for the figural analogies test items, letter series, and the RSJT same-version and different-version scores (averaged across each rule, treating it as an item). Split-half reliability was used for paper folding and the RSJT different-rule scores. Split-half reliability was used for the RSJT different-rule scores because they could not be averaged by rule, as two rules were shown in the different-rule comparisons. Parallel-forms reliability was used for operation span and symmetry span.
7.2. Predicting Figural Analogies Accuracy with Training, RSJT Scores, WMC, and Gf
The first set of analyses investigated whether accuracy on the figural analogies test items changed as a function of training, the participant’s rule representation as measured by the RSJT different-version scores, and the WMC and Gf measures. To determine this, generalized linear mixed-effects models (GLMM) were used to predict item accuracy on the test items with the fixed effects hierarchically introduced. A logit link function was used to predict the binary accuracy data. The maximum random effects structure included random intercepts for subject and item, with random slopes added for training for both subject and item. The general procedure for the models was to include all fixed effects and the maximum random effects structure initially and to then gradually reduce the complexity of the random effects structure if the model failed to converge or was singular (
Bates et al. 2015;
Matuschek et al. 2017). The structure could be reduced by removing correlation parameters or removing random effects that failed to explain a significant portion of variance (i.e., if variance was not greater than zero at α = 0.20). All binary predictors were coded using sum contrast coding (−1, 1) and all continuous predictors were
z-transformed.
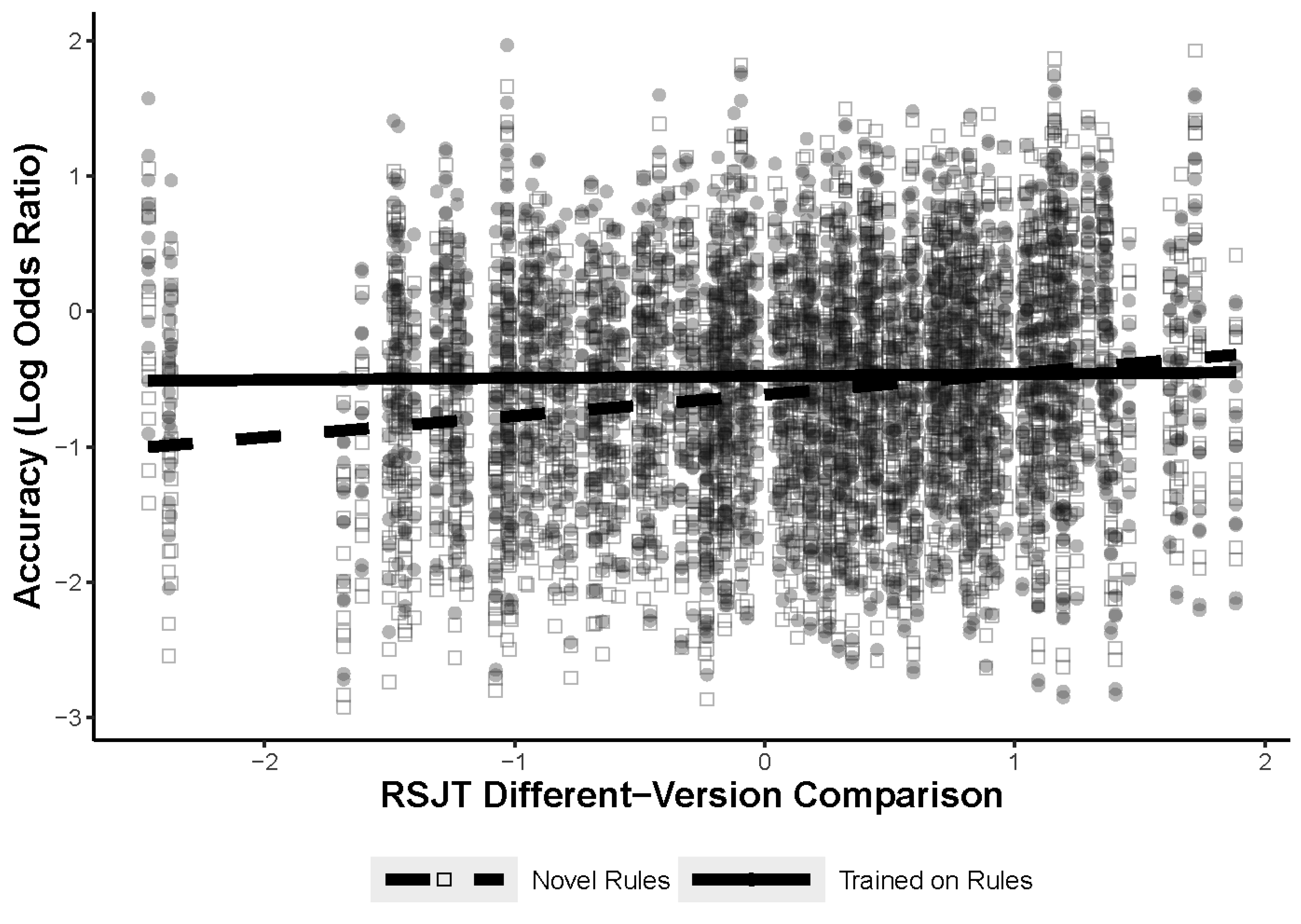
The first model predicted figural analogy accuracy with fixed effects for the training (items comprised of previously seen or novel rules) and the participants’ RSJT different-version score with a test for an interaction between RSJT different-version scores and training. The results of the model, Model 1, are shown in
Table 3. There was a significant interaction between the training manipulation and RSJT different-version scores, shown in
Figure 6; however, the relationship was in the opposite direction of what was predicted. The interaction illustrates a small relationship between RSJT different-version scores and accuracy, but only when participants are solving problems comprised of novel rules. The RSJT scores did not predict accuracy at all for the trained items. It is worth noting that only three participants fell outside of −1.7 standard deviations away from the mean for the RSJT different-version scores but were within −2.5 standard deviations. The removal of these participants did not change the results of the model.
The next analysis introduced the WMC and Gf composite measures into the GLMM. WMC and Gf were added into the models to determine if rule representations accounted for unique variance or if they could be explained by other processes. Both WMC and Gf measures were included because prior work investigating analogical transfer has shown that Gf may contribute to building representations (
Kubricht et al. 2017), but WMC was not accounted for in that study.
WMC and Gf were added on top of the RSJT different-version scores, with WMC and Gf also tested for interactions with training. Because the inclusion of interaction terms can make it difficult to interpret main effects, nonsignificant interactions were removed for the final model, Model 4. However, the WMC and Gf models with all interaction terms are also included. All models’ results are shown in
Table 3. For WMC, shown in Model 2, there was no significant interaction with training, though WMC did predict accuracy on the figural analogies task. For Gf, in Model 3, there was also no significant interaction, but Gf did predict accuracy on the figural analogies task. The interaction between RSJT different-version scores and training did remain significant after including both Gf and WMC, indicating that the RSJT scores were measuring something unique from Gf and WMC.
7.2.1. Interim Discussion: Task Learning
The interaction between RSJT different-version scores and training was in an unexpected direction. These results may indicate that processes that would normally be beneficial in solving figural analogies problems become less important or less likely to be used when participants have been trained on the rules. This is similar to findings in the expertise literature, where dependence on other cognitive processes, such as working memory, decreases as expertise increases. The lack of an interaction between WMC and training was also unexpected, given prior work showing that the relationship between performance on Gf tasks and WMC changes depending on whether items are comprised of novel or previously seen rules (
Harrison et al. 2015;
Loesche et al. 2015;
Wiley et al. 2011). However, it has also been noted that participants learn throughout a task, even if all of the rules are novel, and that the frequency of rules used can bias participants’ expectations and use of rules (
Verguts and De Boeck 2002). Therefore, a post hoc analysis was conducted to investigate the relationship of WMC and training on accuracy while also accounting for learning throughout the task.
7.2.2. Task Learning Post Hoc Analysis
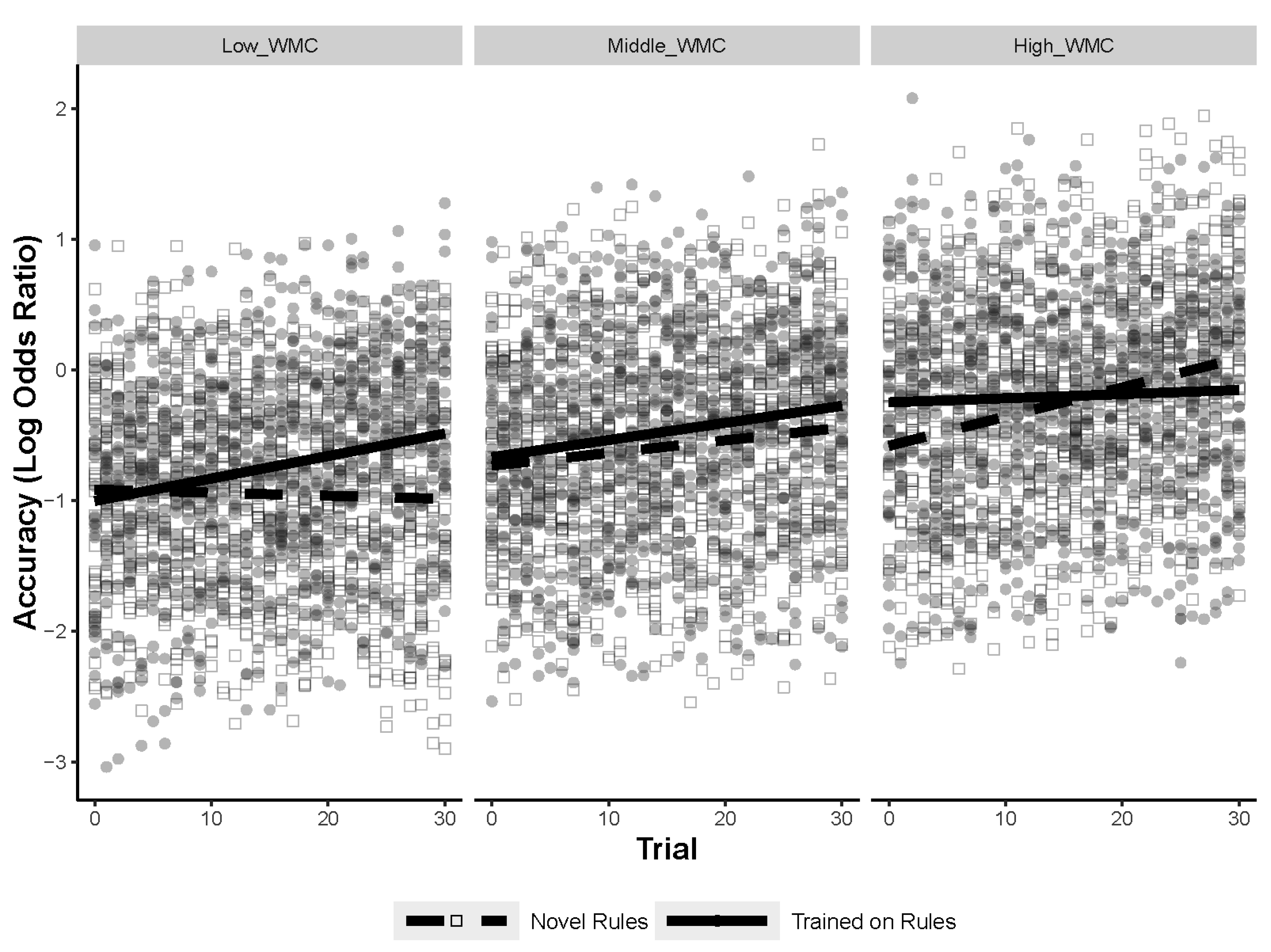
Learning throughout the task was assessed using trial number, so a separate analysis tested for a three-way interaction between WMC, training, and trial number, while predicting accuracy on the figural analogies task. The results of the GLMM are shown in
Table 4. The three-way interaction was significant (
p = .003), as shown in
Figure 7. Post hoc comparisons demonstrated that WMC and trial continued to interact for the novel-rule items (
p = .021) but not for the trained-rule items (
p = .07). However, there was still a main effect of WMC (
p < .001) and trial (
p = .02) for the trained-rule items (even with the interaction term removed). The models for the post hoc comparisons can be found in
Appendix A. The results of the three-way interaction and the post hoc comparisons suggest that high-WMC individuals improve on the novel-rule items over time whereas the low-WMC individuals do not. Although the interaction term between WMC and trial was not significant for the trained-rule items, the main effects of WMC and trial indicate that high-WMC individuals were more likely to solve trained-rule items, but both high and low-WMC individuals improved on the trained-rule items over time. Notably, there were no significant interactions with Gf for training and trial number, so these results appear to be unique to WMC.
7.3. Predicting RSJT Different-Version Scores
After investigating the relationship between memory retrieval and accuracy, a closer look at the rule representation measure was conducted to determine if WMC and/or Gf could explain the ability to generate more general rule representations. The second analysis used a linear mixed-effects model (LMM) to predict the RSJT different-version scores for each rule, with the WMC and Gf measures used as predictors. The random effects structure included random intercepts for subject and rule. The
p-values were generated using the lmertest package in R. The results of the model can be found in
Table 5. Neither Gf nor WMC predicted the RSJT different-version scores.
7.3.1. Interim Discussion: Further Investigating the RSJT Scores
The lack of a relationship between RSJT different-version scores and figural analogies accuracy on trained items, as well as the fact that RSJT same-version scores appeared to better correlate with figural analogy accuracy, prompted a deeper inspection of the RSJT scores and what they may actually measure. The original intention with the RSJT was to use the different version comparison scores only, because it was assumed that most participants would rate the same-version comparisons as very close to 1 and the different-rule comparisons as very close to −1, reducing those measures to be at the ceiling or at the floor. Although same-version comparisons were rated the highest on average and the different-rule comparisons were rated the lowest on average, there were no ceiling or floor effects, thus making these other RSJT scores potentially meaningful.
It is also possible that different processes are beneficial when solving an item that has two very similar rules included in a single item. The two types of figural analogy items, distinct-rule items (items comprised of all unique rules) and paired-rule items (items where two versions of the same rule appear in the same item), were originally developed to help control for difficulty across the two sets and to allow for a larger set of items by repeating rules. This requires the solver to be open to different variations of a rule and to not be overly fixated on a single element of the rule. Yet, it also requires that the solver does not over-generalize such that they cannot distinguish between the two highly similar rules. As such, the following analyses explore both the other two RSJT measures and their impact on different types of items.
7.3.2. Further Investigating the RSJT Scores Post Hoc Analyses
The first analysis sought to determine if each of the three RSJT scores measure different constructs. The three measures were used as simultaneous predictors in a GLMM predicting figural analogies accuracy. The results are shown in
Table 6. The RSJT same-version and RSJT different-rule measures did uniquely predict accuracy, but the RSJT different-version did not predict accuracy, congruent with prior analyses.
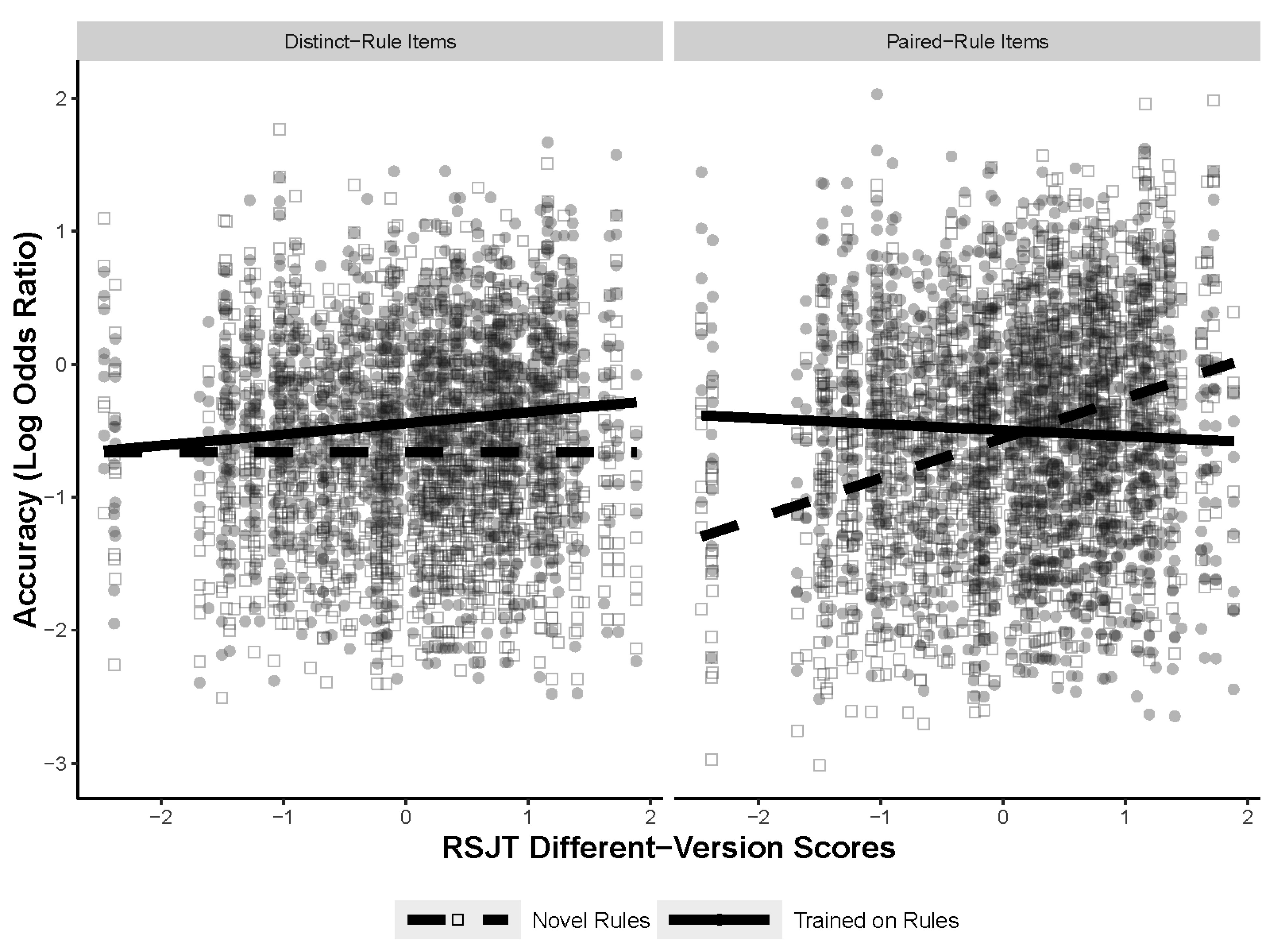
The next analysis explored whether the type of figural analogy item being solved contributed to the predictiveness of the RSJT measures. To test if the type of problem mattered, three mixed-effects models were run, each with a different RSJT measure. The models tested for a three-way interaction between the RSJT measure, training, and the type of figural analogy item (distinct or paired) with random intercepts for subject and item, and random slopes for training for both subject and item. The final models are shown in
Table 7. The type of figural analogies item only interacted with the RSJT different-version measurements.
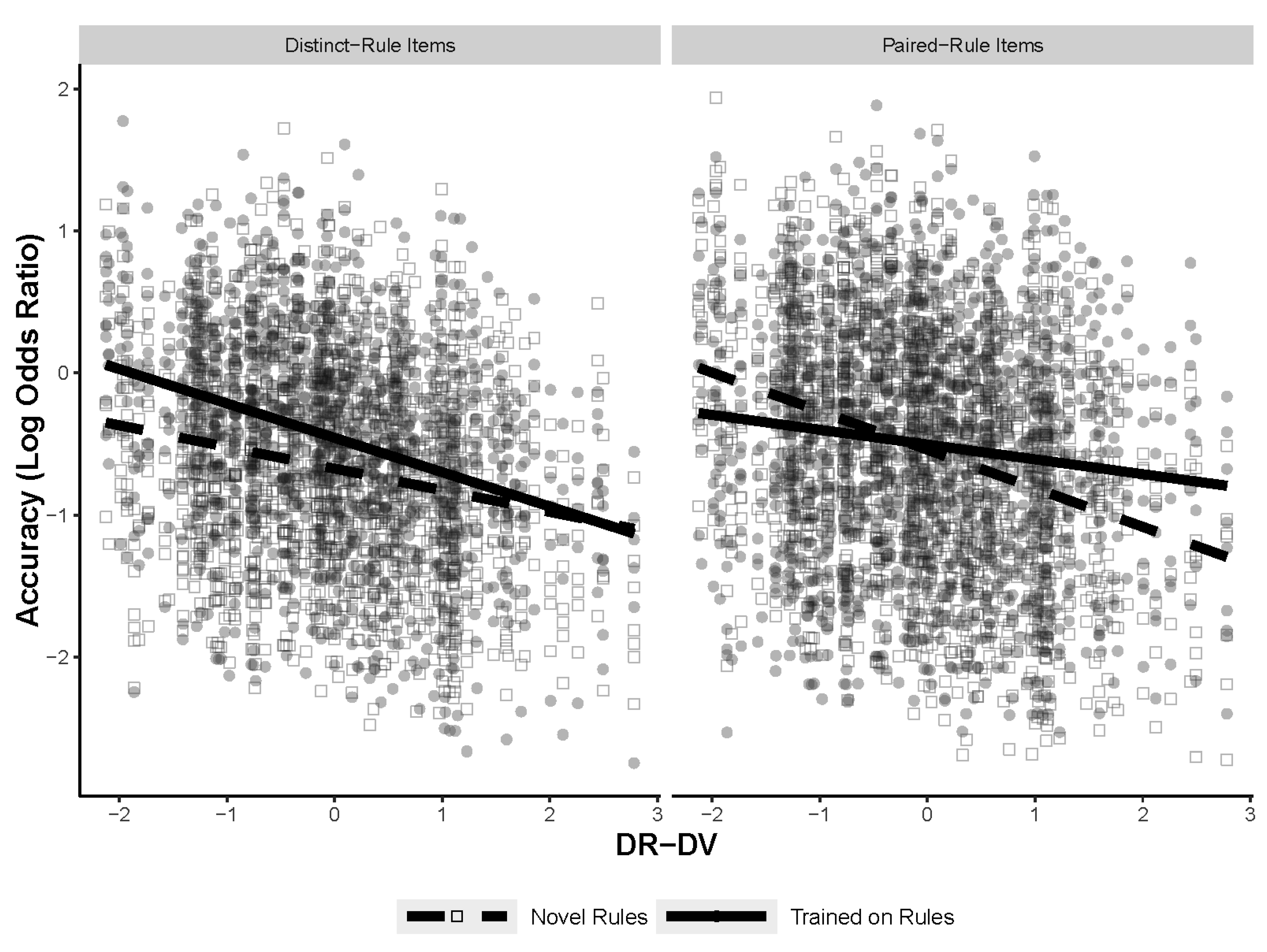
Figure 8 shows the three-way interaction between RSJT different version, training, and type of figural analogy item. Post hoc comparisons specified that the significant differences in slopes were between the novel paired-rule items and the trained paired-rule items, as well as the novel paired-rule items and the novel distinct items. All the models for the post hoc comparisons can be found in
Appendix A. The results indicate that how an individual rates different versions of the same rule does predict accuracy on the figural analogies task, but only for novel paired-rule items. Furthermore, this interaction was not significant with the RSJT same-version or different-rule measures, suggesting that this is particular to the different version measure. Notably, the results found with the three-way interaction likely explain the effect found in the first analysis, with RSJT different version interacting with training. Finally, the lack of a main effect of item type, as well as a two-way interaction between training (namely in the same version and different rule models that do not include the three-way interaction term), indicate that the type of item did not contribute to overall accuracy and is also not responsible for any of the training effects.
7.3.3. Interim Discussion: Measuring Different Version Relative to Same Version and Different Rule
The original different-version measure represented an individual’s average score for the different-version comparisons after rescaling all of their scores from −1 to 1. Although this method also provides measures for same-version and different rule, it fails to account for participant and item effects, it does not take into account the spread of an individual’s ratings (only the average), and it does not provide any information on how an individual rates different-version comparisons relative to the same version or different rule. For example, some participants may rate different-version rule comparisons as similar, but they may also rate different-rule comparisons as similar, suggesting that they have a general propensity toward calling all rules similar. Alternatively, participants may view same-version rules as being equally as distinct as different-version rules. Although all participants included in the sample needed to have a significant difference between the same-version and different-rule conditions to be included, the current measures do not provide information on how large of a difference there exists between the same-version and different-version comparisons, as well as the different-version and different-rule comparisons.
7.3.4. Relative Rule Post Hoc Analysis
To better address ratings of different-version rules relative to the other two rule comparison types, new measures were generated using a mixed-effects model. The linear mixed- effect model predicted raw similarity judgement ratings with type of comparison (same version, different version, different rule) as a fixed effect. The random effects included random intercepts for item and participant, with random slopes for type of comparison for each participant. Type of comparison was dummy-coded as two variables, same version–different version and different rule–different version, with same version coded as 1 for the same version–different version measure and different rule coded as 1 for the different rule–different version measure, and everything else coded as 0. The random slopes for the same version–different version and different rule–different version measures for each participant were extracted and used as predictors in a series of analyses. The same version–different version and different rule–different version measures represented the difference between the two types of comparisons. Individuals with higher (positive) values for the same version–different version measure on average rated same-version comparisons as higher than different-version comparisons, whereas individuals with lower (negative) values rated different-version comparisons as being closer to same-version comparisons. For the different rule–different version measure, individuals with larger (positive) values rated different-version comparisons as closer to different-rule comparisons, whereas individuals with lower (negative) values rated different-version comparisons as different from different-rule comparisons. Because the new measures produced some outliers for those measures (beyond 2.5 standard deviations away from the mean), some participants were removed for subsequent analyses. This resulted in a final sample of 215 participants. The correlations between the new RSJT measures, the old RJST measures, figural analogies accuracy, WMC, and Gf are in included in
Table 8.
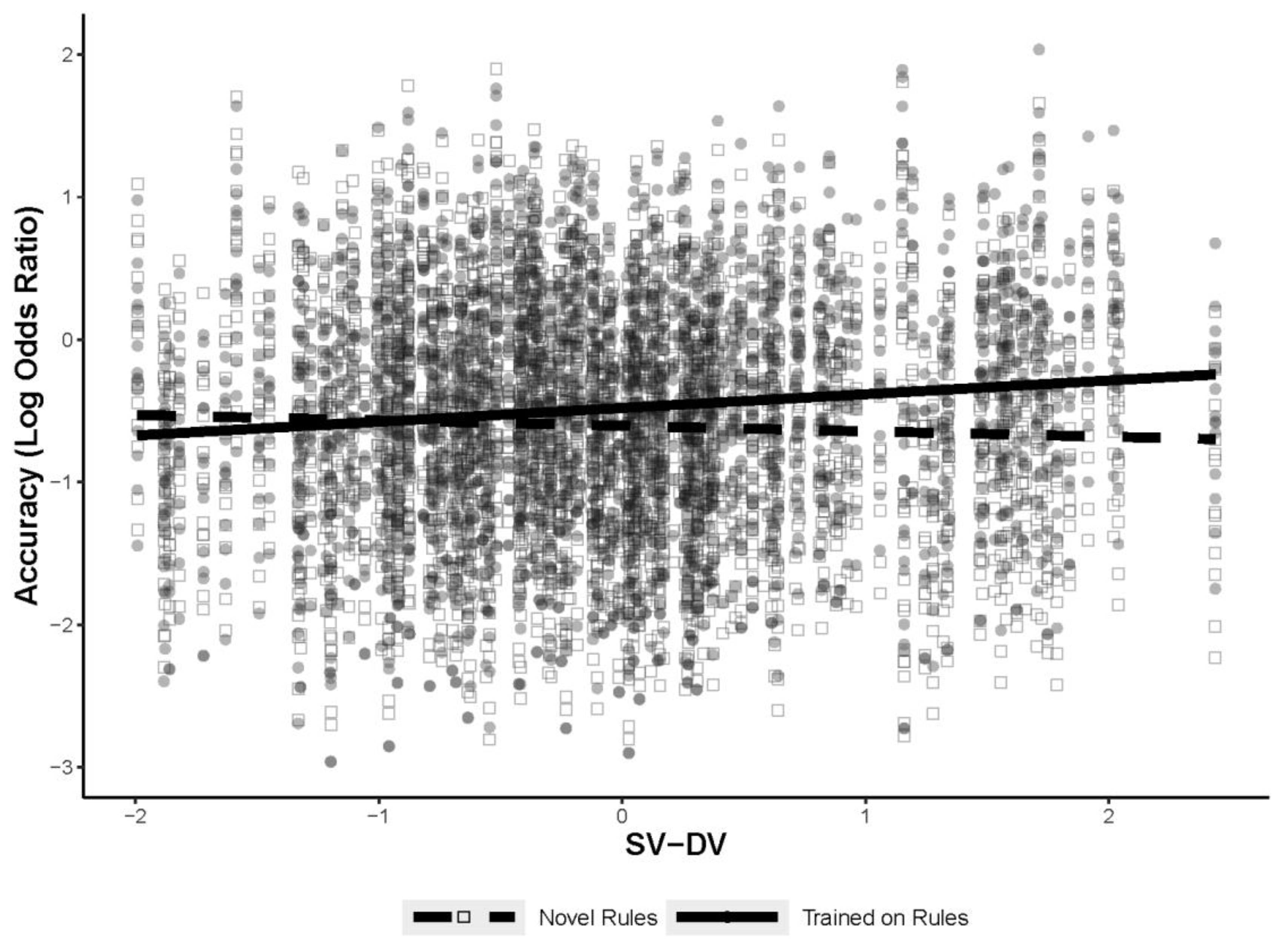
The first analysis used a GLMM to predict figural analogy accuracy as a function of the two new measures, the training manipulation, WMC, and Gf, with a test for an interaction between the two new measures and the training manipulation. The random effects structure was identical to previous analyses, with random intercepts for subject and item, with random slopes added for training for both subject and item. The same version–different version and different rule–different version measures were
z-transformed prior to including them in the model. The final model is shown in
Table 9. There was a significant interaction between the same version–different version measure and training, but not for the different rule–different version measure. The interaction is shown in
Figure 9. The interaction indicated a positive relationship between the same version–different version measure and figural analogies accuracy for the trained items only. Thus, individuals that tend to rate different-version comparisons as different from same-version comparisons show improved accuracy for the trained-rule items. These results are the opposite of what was found previously when just using the RSJT different version measure. Although there was no significant interaction with the different rule–different version measure, it did predict figural analogy accuracy as a main effect, with a larger difference between different version and different rule scores corresponding with higher accuracy on the figural analogies test items.
The next analysis tested for interactions between the two new RSJT measures, the training manipulation, and item type (distinct vs. paired rules). The final models are shown in
Table 10. There was a significant interaction between all three measures when different rule–different version was included, but not when same version–different version was included. The results of the interaction are shown in
Figure 10. Post hoc comparisons indicated that the only significant difference in slopes was between the novel paired-rule items and the trained paired-rule items. The full models for the post hoc comparisons are located in
Appendix A. These results are largely congruent with previous results showing a significant three-way interaction between different-version scores, training, and item type. Compared to the previous analyses, the current model specifies that not only is it higher different-version scores that predict accuracy on novel paired-rule items, but that higher different-version scores relative to different-rule scores predict accuracy on novel paired-rule items.
8. Discussion
8.1. Knowledge Representations and Transfer
Although both knowledge representations and WMC did predict success during the figural analogies task, the results did not align with a priori predictions. It was assumed that the presence of general rule representations would better facilitate transfer, as measured by the RSJT different-version scores. However, although RSJT different-version scores did interact with the training manipulation, they only predicted accuracy on novel items, not the trained items. This was opposite of what was expected. The original reasoning was that generalized rule representations would facilitate retrieval, but it is possible that the training or even the RSJT itself helped most participants conceptualize the rules in a way that was useful, thus leaving retrieval of the trained rules to depend on other processes, such as WMC. That being said, the analyses that included same version–different version measure did provide some support for rule representations facilitating retrieval. The same version–different version measure only predicted accuracy for the trained-rule items, not the novel-rule items. However, it also showed a positive relationship, suggesting that individuals who treat different-version comparisons as being less similar than the same-version comparisons had improved accuracy on the figural-analogy-trained items. This is also contrary to what was expected. Although these interactions differed from expectations, they did remain significant once WMC and Gf were introduced into the models. This indicates that the RSJT can uniquely explain variance on novel and trained figural analogies items beyond what Gf and WMC can explain.
The interaction between training and RSJT different-version scores also increased when accounting for the type of figural analogy item (distinct vs. paired rules). It is likely that the initial two-way interaction between training and RSJT different-version scores is driven by the three-way interaction with figural analogy items, and that in truth RSJT different-version scores really only predict novel paired-rule items. However, the relationship was positive, congruent with the initial hypotheses of the study. Mentally representing two versions of the same rule as closely similar, as opposed to treating them as distinct rules, corresponded with higher accuracy on novel problems where two versions of the same rule were included. Furthermore, the different rule–different version analyses indicated that it may be more important that individuals treat different-version comparisons as different from different rules than it is for different-version comparisons to be treated as similar to same-version comparisons. Notably, the fact that the RSJT different-version scores, as well the different rule–different version scores, only predicted novel items suggests that individuals with a propensity to treat different versions of the same rule as more similar, but still as separate rules, may have an easier time inducing related, but slightly different rules when they are exposed to them for the first time. It is likely that the training or the RSJT helped participants induce and develop representations to a point where individual differences in RSJT different-version scores no longer mattered for solving the trained-rule problems.
Unlike the RSJT different-version scores, WMC did appear to explain transfer, showing interactions with the training manipulation when accounting for learning across the task. Both high- and low-WMC individuals improved on trained rules over time, but high-WMC individuals were more likely to solve trained items correctly than low-WMC individuals. Furthermore, high-WMC individuals improved on the novel-rules items as they progressed, with performance increasing as they solved more items. Low-WMC individuals did not show this benefit, appearing to struggle on novel items throughout the task. It is possible that high-WMC individuals improved on the novel items by learning the rules and using them later in the task (
Harrison et al. 2015;
Loesche et al. 2015;
Verguts and De Boeck 2002), or they may have simply improved in solving novel problems, learning new strategies or becoming more comfortable with the task (
Klauer et al. 2002;
Tomic 1995). The low-WMC individuals did not improve on the novel problems over time, suggesting that they struggled to induce the rules at all, or that they may need substantially more practice before they begin to benefit from learned rules.
These results are congruent with prior work in multiple ways. First, the fact that high-WMC individuals were able to benefit from trained rules more than low-WMC individuals indicates that WMC is important for retrieving previously learned information (
Loesche et al. 2015;
Unsworth 2016). Second, only the high-WMC individuals improved on novel items over time, whereas both low- and high-WMC individuals improved on the trained items over time, indicating that WMC also contributes to learning throughout the task (
Harrison et al. 2015;
Unsworth 2016). Finally, because the high-WMC individuals were generally better at solving novel items and low-Gf individuals did not improve at the novel items over time, WMC seems important for initially inducing the rules (
Carpenter et al. 1990). Although these results support several explanations for the role of WMC in Gf tasks, it is worth noting that the findings only became apparent after testing for the three-way interaction with trial number. Furthermore, these results fail to replicate studies showing a stronger relationship between WMC and repeated rules (items wherein the combination of rules has been seen previously) on the RAPM (
Loesche et al. 2015;
Harrison et al. 2015) or studies showing the opposite, where WMC better predicts novel (unique combinations) RAPM items (
Wiley et al. 2011). Taking into consideration learning across the task, as well as accounting for individual rules rather than just unique combinations of rules, may explain the mixed findings on the role of WMC in Gf tasks.
Finally, it is worth noting that WMC may play a large role in how well the rules are initially learned. Previous work with analogical transfer has found that Gf may explain the ability to develop more general representations that are more easily transferred (
Kubricht et al. 2017). However, WMC and Gf are highly correlated and so it is possible that the high-Gf individuals in Kubricht et al.’s study did not benefit from the training manipulation because they were also high in WMC, thus learning the source problem better. This would explain why WMC is shown to explain transfer in the current study and not Gf. Yet, it is worth noting that
Cushen and Wiley (
2018) found that WMC only explained the completeness of an individual’s summary of the source problem when performance on the Remote Associates Test was not accounted for. Thus, although WMC may be important for retrieving learned rules, other processes may still be important in helping to generate more general representations, especially in cases of more complex learned information.
8.2. The Rule-Similarity Judgement Task
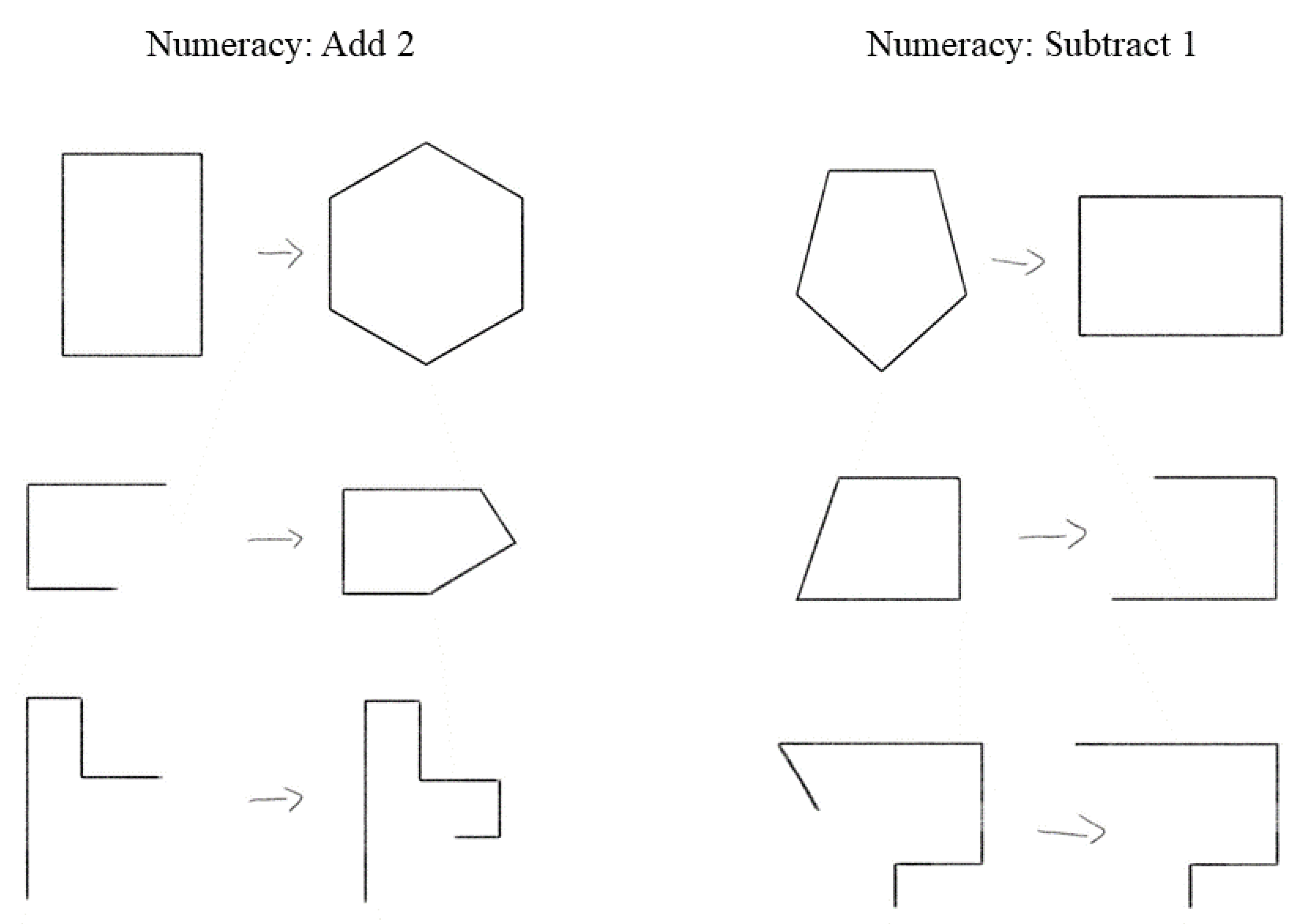
The original intention with the RSJT was to only use the different-version scores, but the same-version and different-rule scores ultimately did provide meaningful information, as did the difference-score measures, with each predicting figural analogies accuracy differently and uniquely. As many of these analyses were post hoc considerations, it is thus worth considering what processes these measures are tapping into. The RSJT same-version measure was the best predictor of figural analogies accuracy overall, even though it did not interact with any of the training manipulations. Because it was comparing two identical rules, it is possible that the measure is tapping into an individual’s propensity to let surface features of the items factor into their similarity judgements. For example, consider
Figure 4, which utilizes a numeracy rule. In this case, all of the items look slightly different. Some are just lines, some make a whole shape, and some include both aspects. Thus, even though they all increase an edge by two or lose an edge by one, some participants may have been accounting for surface features, with this potentially affecting their ability to solve figural analogy problems. Given that the same-version measure did predict accuracy and did also correlate with paperfolding and the Gf composite measure, it may be that a reliance on surface features is something that generally correlates with accuracy on Gf tasks. Furthermore, because the same version–different version measure did not correlate with figural analogy accuracy, Gf, WMC, or even the RSJT same version measure, but did correlate with the different-version and different-rule scores, it does appear that the RSJT same-version measure is tapping into something unique that happens when same-version comparisons are made.
The same version–different version and different rule–different version difference scores showed complementary as well as distinct findings from the RSJT same-version, different-version, and different-rule scores. The same version–different version measure was the only measure to predict trained-rule items and it predicted positively, indicating that representing different-version comparisons as less similar to same-version was beneficial, rather than what was originally hypothesized. The different rule–different version measure did support the initial findings with the RSJT different-version scores, but further specified that it was beneficial for accuracy on novel paired-rule items to represent different-version comparisons as more similar than different-rule comparisons. The same version–different version and different rule–different version measures indicate that generally treating the three comparisons as different is beneficial for accuracy. Although the same version–different version measures and the different rule–different version measures better target the difference between the three types of comparisons, it appears that all five measures produced by the RSJT measure slightly different propensities and further work will need to be conducted to better understand the differences and the similarities between all of the measures.
Although the RSJT did explain some transfer when using the same version–different version measure, it is possible that the RSJT did not explain transfer in the expected way because the measure was designed to look at the abstractness of the rule representations. Prior work has primarily looked at whether the representations include all the necessary information that is needed for transfer or mapping (
Cushen and Wiley 2018), rather than looking at the quality of a representation that includes all the necessary information. Lacking information may produce a more salient effect with transfer, whereas the quality of a whole representation may matter less. Ultimately, more information is needed on the three RSJT measures to ascertain what they are actually measuring and why they are distinct from WMC and Gf, in order to determine the role of rule representations in novel problem solving and transfer.
8.3. Conclusions
In conclusion, individual differences in knowledge representations and WMC play independent roles in reasoning performance. WMC appears to be important for both learning and retrieving rules, as well as contributing to novel problem solving. However, beyond WMC, individual differences in knowledge representations were able to explain some aspects of performance via retrieval as well as for novel problems. The results indicate that there may be a happy medium with knowledge representations, wherein an individual will want to recognize similarities when present while also understanding distinctions between rules. Furthermore, the propensity to develop a more general or stimuli-specific knowledge representation was not explained by WMC and Gf. Thus, understanding what prompts individuals to build better representations may be key to not only understanding novel reasoning but problem solving as a whole.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}









