
Predicting Time-to-Healing from a Digital Wound Image: A Hybrid Neural Network and Decision Tree Approach Improves Performance

Abstract
:Simple Summary
Abstract
1. Introduction
1.1. Motivation
1.2. Previous Efforts
1.2.1. Traditional Computer Vision Methods Using Wound Images
1.2.2. Deep Learning Models Using Wound Images
1.3. Our Approach
Principal Contribution of this Work
2. Materials and Methods
2.1. Overview of Our Computational Approach
2.1.1. Our Approach for Obtaining Phase 1 Features
2.1.2. Approach for Obtaining Phase 2 Features
2.1.3. Regression
2.2. Wound Image Datasets
2.2.1. Ulcer Wound Superpixel Data Set
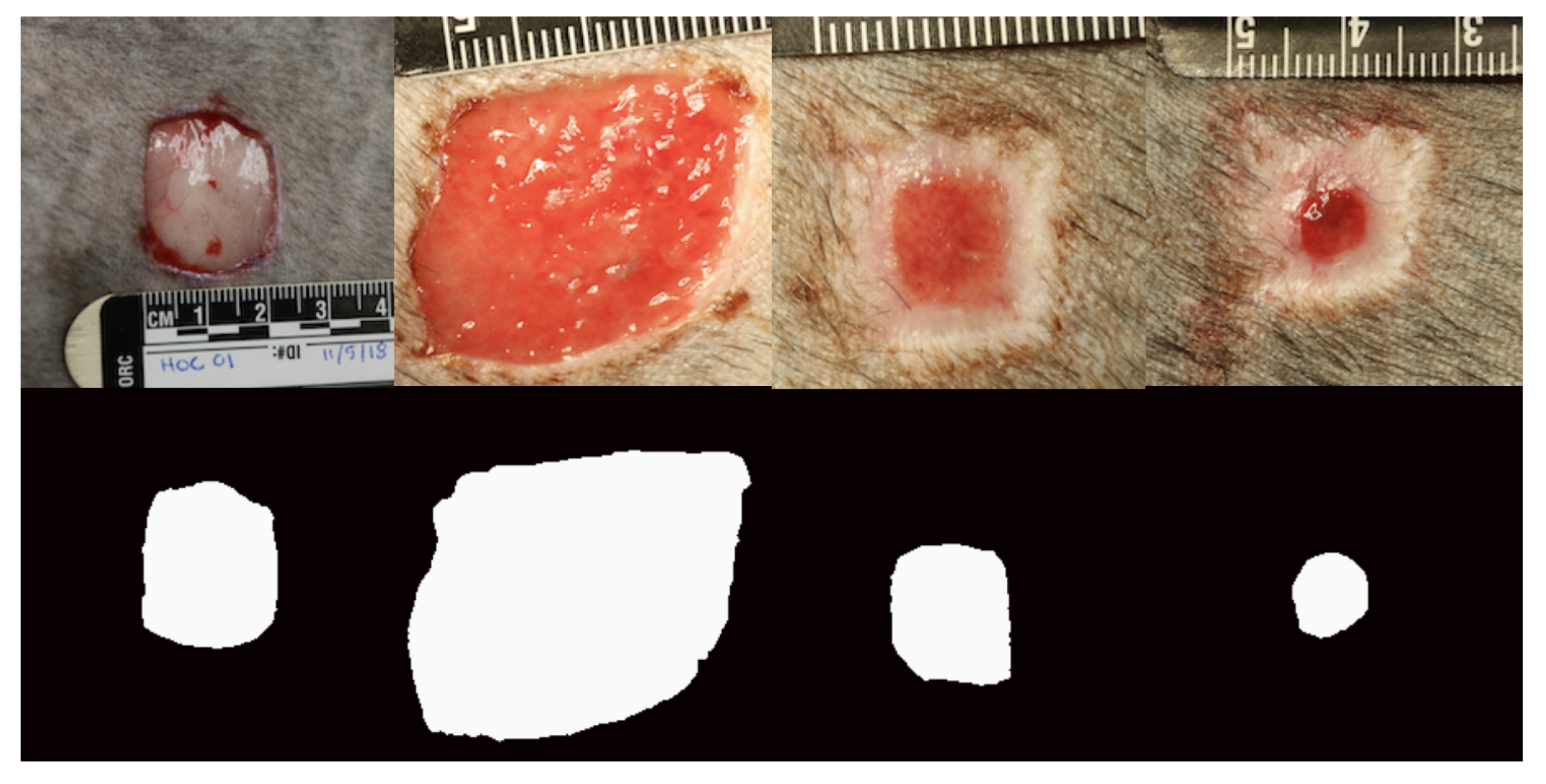
2.2.2. Dog Wound Healing Image Set
2.3. Image Augmentation and Annotation
2.3.1. Augmentor
2.3.2. Pixel Annotation
2.4. Superpixel Classifier Model Architecture
2.5. Segmentation
2.6. SegNet Model Architecture
2.7. U-Net Model Architecture
2.8. Feature Engineering and Extraction
2.8.1. Feature Extraction from a Superpixel Model
2.8.2. Feature Extraction from Segmentation Models
Inner Layer Encoding
Wound Area Calculation
2.8.3. PCA Reduction in Segmentation Feature Vectors
2.9. How We Obtained the Dependent Variable for Regression Training
2.10. Regression Model Training
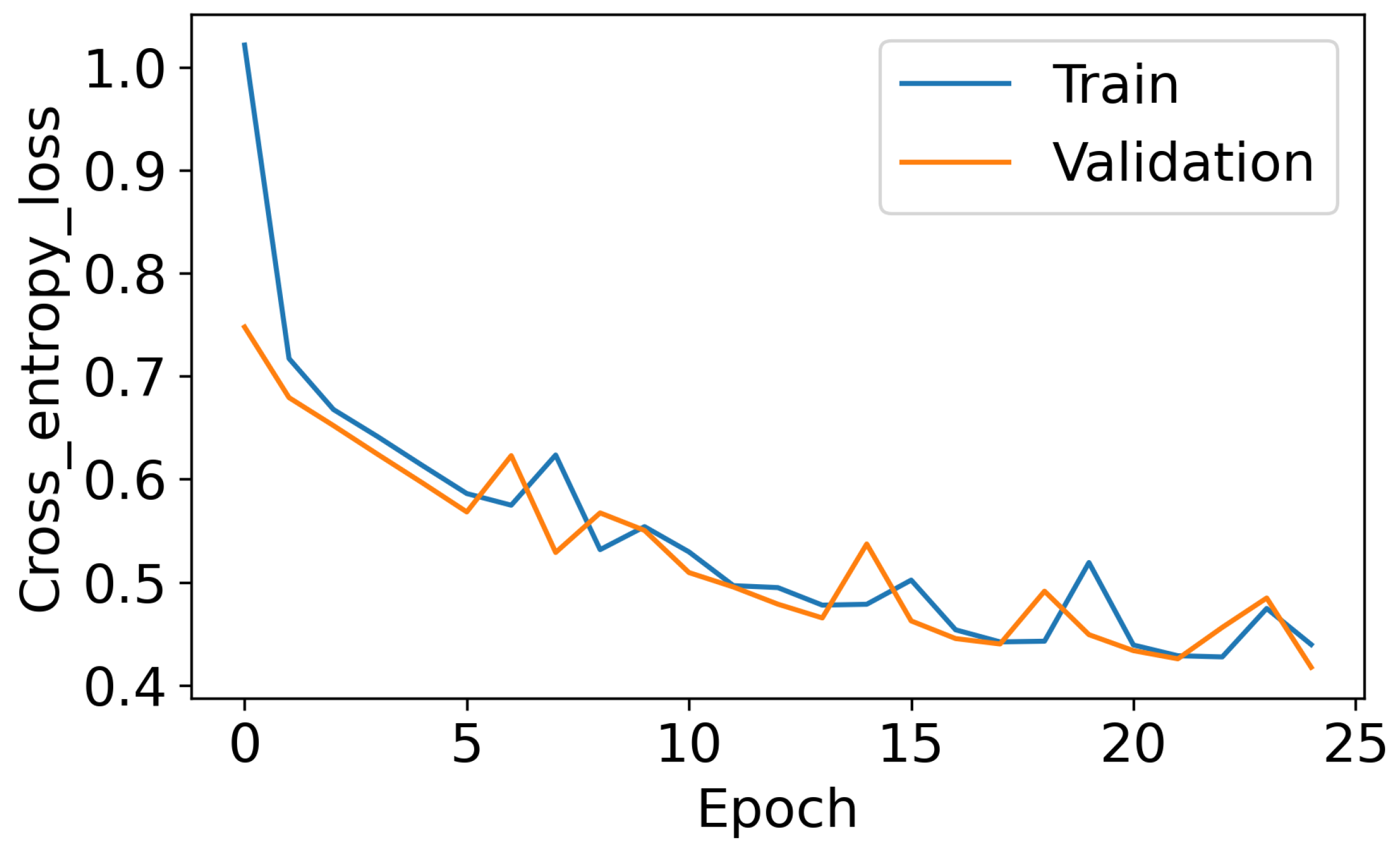
2.11. Model Training, Tuning, and Evaluation
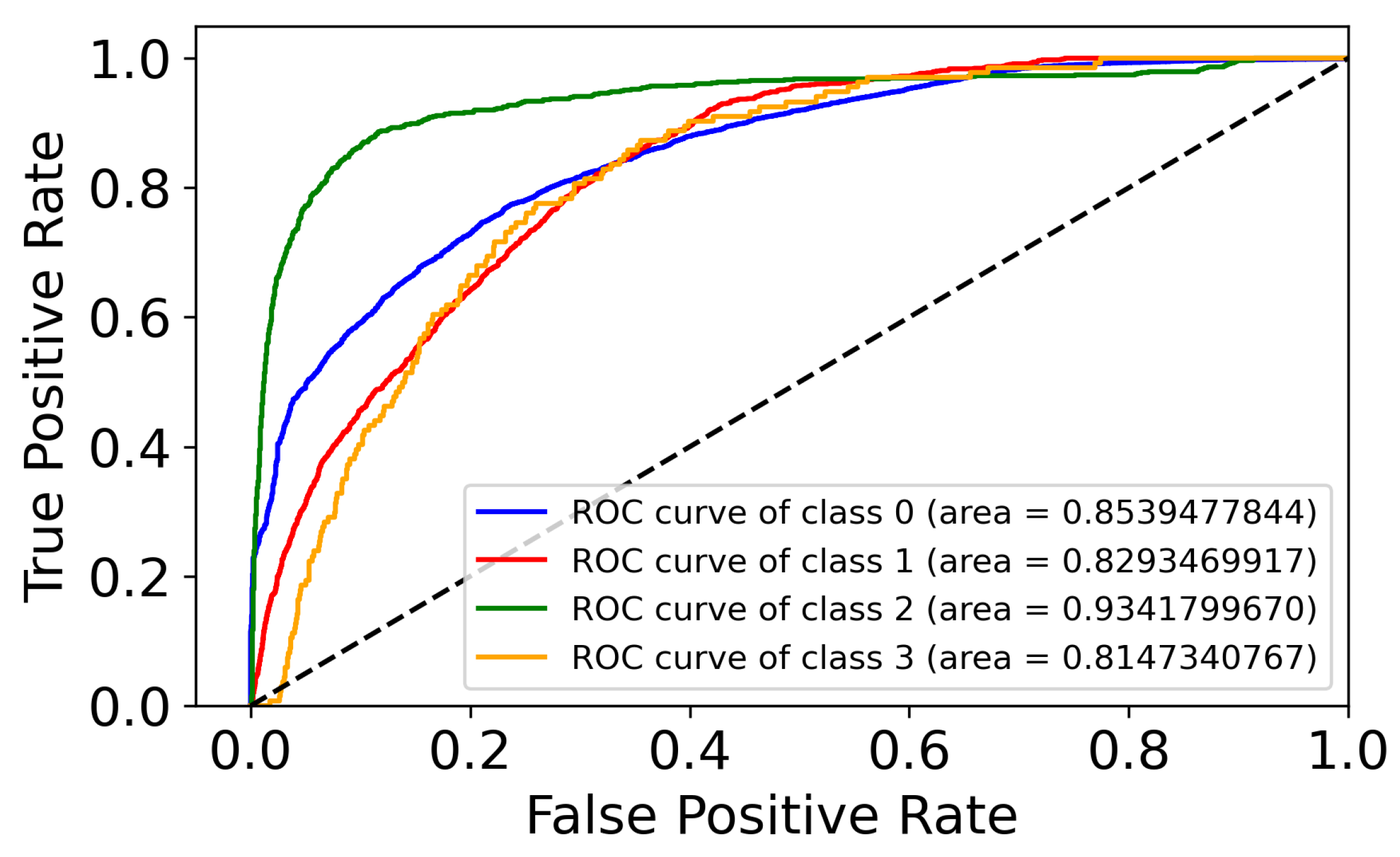
2.11.1. Superpixel Classifier
2.11.2. Binary Pixel-Level Segmentation
2.11.3. Regression Using Decision Trees or Gaussian Process
2.11.4. Regression Using a Deep Neural Network
2.11.5. Confidence Interval Estimation
3. Results
3.1. Superpixel Tissue-Type Classification Performance
3.2. Binary Segmentation (Phase 1, Step 2) Model Performance to Find the Best Four Models
3.3. Time-to-Healing Prediction Performance without Phase 2 Features
3.4. Time-to-Healing Prediction Performance including Phase 2 Features
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AIS | augmented image set |
| AUROC | area under the receiver operating characteristic curve |
| CV | cross-validation |
| FCN | fully convolutional network |
| MLP | multi-layer perceptron |
| OIS | original image set |
| PCA | principal components analysis |
| px | pixel |
| coefficient of determination | |
| ReLU | rectified linear unit |
References
- Branski, L.K.; Gauglitz, G.G.; Herndon, D.N.; Jeschke, M.G. A review of gene and stem cell therapy in cutaneous wound healing. Burns 2009, 35, 171–180. [Google Scholar] [CrossRef]
- McLister, A.; McHugh, J.; Cundell, J.; Davis, J. New Developments in Smart Bandage Technologies for Wound Diagnostics. Adv. Mater. 2016, 28, 5732–5737. [Google Scholar] [CrossRef]
- Sen, C.K.; Gordillo, G.M.; Roy, S.; Kirsner, R.; Lambert, L.; Hunt, T.K.; Gottrup, F.; Gurtner, G.C.; Longaker, M.T. Human skin wounds: A major and snowballing threat to public health and the economy. Wound Repair Regen. 2009, 17, 763–771. [Google Scholar] [CrossRef]
- Falcone, M.; Angelis, B.D.; Pea, F.; Scalise, A.; Stefani, S.; Tasinato, R.; Zanetti, O.; Paola, L.D. Challenges in the management of chronic wound infections. J. Glob. Antimicrob. Resist. 2021, 26, 140–147. [Google Scholar] [CrossRef]
- Grey, J.E.; Enoch, S.; Harding, K.G. Wound assessment. BMJ 2006, 332, 285–288. [Google Scholar] [CrossRef]
- Seaman, M.; Lammers, R. Inability of patients to self-diagnose wound infections. J. Emerg. Med. 1991, 9, 215–219. [Google Scholar] [CrossRef]
- Wang, C.; Yan, X.; Smith, M.; Kochhar, K.; Rubin, M.; Warren, S.M.; Wrobel, J.; Lee, H. A unified framework for automatic wound segmentation and analysis with deep convolutional neural networks. In Proceedings of the 37th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Milan, Italy, 25–29 August 2015; pp. 2415–2418. [Google Scholar] [CrossRef]
- Veredas, F.J.; Luque-Baena, R.M.; Martín-Santos, F.J.; Morilla-Herrera, J.C.; Morente, L. Wound image evaluation with machine learning. Neurocomputing 2015, 164, 112–122. [Google Scholar] [CrossRef]
- Blanco, G.; Traina, A.J.M.; Traina, C., Jr.; Azevedo-Marques, P.M.; Jorge, A.E.S.; de Oliveira, D.; Bedo, M.V. A superpixel-driven deep learning approach for the analysis of dermatological wounds. Comput. Methods Programs Biomed. 2020, 183, 105079. [Google Scholar] [CrossRef] [PubMed]
- Anisuzzaman, D.M.; Patel, Y.; Rostami, B.; Niezgoda, J.; Gopalakrishnan, S.; Yu, Z. Multi-modal wound classification using wound image and location by deep neural network. Sci. Rep. 2022, 12, 20057. [Google Scholar] [CrossRef]
- Bloice, M.D.; Roth, P.M.; Holzinger, A. Biomedical image augmentation using Augmentor. Bioinformatics 2019, 35, 4522–4524. [Google Scholar] [CrossRef] [PubMed]
- Zhang, R.; Tian, D.; Xu, D.; Qian, W.; Yao, Y. A Survey of Wound Image Analysis Using Deep Learning: Classification, Detection, and Segmentation. IEEE Access 2022, 10, 79502–79515. [Google Scholar] [CrossRef]
- Berezo, M.; Budman, J.; Deutscher, D.; Hess, C.T.; Smith, K.; Hayes, D. Predicting Chronic Wound Healing Time Using Machine Learning. Adv. Wound Care 2022, 11, 281–296. [Google Scholar] [CrossRef]
- Sullivan, T.P.; Eaglstein, W.H.; Davis, S.C.; Mertz, P. The pig as a model for wound healing. Wound Repair Regen. 2001, 9, 66–76. [Google Scholar] [CrossRef] [PubMed]
- Volk, S.W.; Bohling, M.W. Comparative wound healing—Are the small animal veterinarian’s clinical patients an improved translational model for human wound healing research? Wound Repair Regen. 2013, 21, 372–381. [Google Scholar] [CrossRef] [PubMed]
- Stockman, G.; Shapiro, L.G. Computer Vision, 1st ed.; Prentice Hall: Hoboken, NJ, USA, 2001. [Google Scholar]
- Gupta, S.; Arbelaez, P.; Malik, J. Perceptual Organization and Recognition of Indoor Scenes from RGB-D Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 564–571. [Google Scholar] [CrossRef]
- Silberman, N.; Hoiem, D.; Kohli, P.; Fergus, R. Indoor Segmentation and Support Inference from RGBD Images. In Proceedings of the Computer Vision–ECCV 2012, Florence, Italy, 7–13 October2012; Fitzgibbon, A., Lazebnik, S., Perona, P., Sato, Y., Schmid, C., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 746–760. [Google Scholar]
- Song, B.; Sacan, A. Automated wound identification system based on image segmentation and Artificial Neural Networks. In Proceedings of the International Conference on Bioinformatics and Biomedicine, Philadelphia, PA, USA, 4–7 October 2012; pp. 1–4. [Google Scholar] [CrossRef]
- Hettiarachchi, N.; Mahindaratne, R.; Mendis, G.; Nanayakkara, H.; Nanayakkara, N.D. Mobile based wound measurement. In Proceedings of the Point-of-Care Healthcare Technologies, Bangalore, India, 16–18 January 2013; pp. 298–301. [Google Scholar]
- Fauzi, M.F.A.; Khansa, I.; Catignani, K.; Gordillo, G.; Sen, C.K.; Gurcan, M.N. Computerized segmentation and measurement of chronic wound images. Comput. Biol. Med. 2015, 60, 74–85. [Google Scholar] [CrossRef] [PubMed]
- Cui, C.; Thurnhofer-Hemsi, K.; Soroushmehr, R.; Mishra, A.; Gryak, J.; Dominguez, E.; Najarian, K.; Lopez-Rubio, E. Diabetic Wound Segmentation using Convolutional Neural Networks. In Proceedings of the 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Berlin, Germany, 23–27 July 2019; pp. 1002–1005. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Yuan, Y.; Chao, M.; Lo, Y.C. Automatic Skin Lesion Segmentation Using Deep Fully Convolutional Networks With Jaccard Distance. IEEE Trans. Med. Imaging 2017, 36, 1876–1886. [Google Scholar] [CrossRef] [PubMed]
- Milletari, F.; Navab, N.; Ahmadi, S.A. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In Proceedings of the 4th International Conference on 3D Vision, Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar]
- Goyal, M.; Yap, M.H.; Reeves, N.D.; Rajbhandari, S.; Spragg, J. Fully convolutional networks for diabetic foot ulcer segmentation. In Proceedings of the International Conference on Systems, Man, and Cybernetics, Banff, AB, Canada, 5–8 October 2017; pp. 618–623. [Google Scholar] [CrossRef]
- Liu, X.; Wang, C.; Li, F.; Zhao, X.; Zhu, E.; Peng, Y. A framework of wound segmentation based on deep convolutional networks. In Proceedings of the 10th International Congress on Image and Signal Processing, Biomedical Engineering and Informatics, Shanghai, China, 14–16 October 2017; pp. 1–7. [Google Scholar]
- Wang, C.; Anisuzzaman, D.M.; Williamson, V.; Dhar, M.K.; Rostami, B.; Niezgoda, J.; Gopalakrishnan, S.; Yu, Z. Fully automatic wound segmentation with deep convolutional neural networks. Sci. Rep. 2020, 10, 21897. [Google Scholar] [CrossRef] [PubMed]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18 –23 June 2018; pp. 4510–4520. [Google Scholar]
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Süsstrunk, S. SLIC Superpixels Compared to State-of-the-Art Superpixel Methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2274–2282. [Google Scholar] [CrossRef] [PubMed]
- Kurach, L.M.; Stanley, B.J.; Gazzola, K.M.; Fritz, M.C.; Steficek, B.A.; Hauptman, J.G.; Seymour, K.J. The Effect of Low-Level Laser Therapy on the Healing of Open Wounds in Dogs. Vet. Surg. 2015, 44, 988–996. [Google Scholar] [CrossRef] [PubMed]
- Rasmussen, C.E.; Williams, C.K.I. Gaussian Processes for Machine Learning; MIT Press: Cambridge, MA, USA, 2005. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Beucher, S. The Watershed Transformation Applied To Image Segmentation. Scanning Microsc. 1992, 6, 299–314. [Google Scholar]
- Bradski, G.; Kaehler, A. OpenCV. Dr. Dobb’s J. 2000, 3, 122–125. [Google Scholar]
- McCulloch, W.S.; Pitts, W. A logical calculus of the ideas immanent in nervous activity. Bull. Math. Biophys. 1943, 5, 115–133. [Google Scholar] [CrossRef]
- Stiller, C.; Lappe, D. Gain/cost controlled displacement-estimation for image sequence coding. In Proceedings of the International Conference on Acoustics, Speech, and Signal Processing, Toronto, ON, Canada, 14–17 May 1991; pp. 2729–2730. [Google Scholar] [CrossRef]
- Jiang, D.; Qu, H.; Zhao, J.; Zhao, J.; Liang, W. Multi-level graph convolutional recurrent neural network for semantic image segmentation. Telecommun. Syst. 2021, 77, 563–576. [Google Scholar] [CrossRef]
- Wei, Q. Machine Learning for Precision Medicine: Application to Cancer Chemotherapy Response Prediction and Wound Healing Status Assessment. Ph.D. Thesis, Oregon State University, Corvallis, OR, USA, 2021. [Google Scholar]
- Ruder, S. An overview of gradient descent optimization algorithms. arXiv 2016, arXiv:1609.04747. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning; Springer Series in Statistics; Springer: New York, NY, USA, 2001. [Google Scholar]
- Anwar, T.; Zakir, S. Effect of Image Augmentation on ECG Image Classification Using Deep Learning. In Proceedings of the International Conference on Artificial Intelligence, Islamabad, Pakistan, 5–7 April 2021; pp. 182–186. [Google Scholar] [CrossRef]
- Elgendi, M.; Nasir, M.U.; Tang, Q.; Smith, D.; Grenier, J.P.; Batte, C.; Spieler, B.; Leslie, W.D.; Menon, C.; Fletcher, R.R.; et al. The Effectiveness of Image Augmentation in Deep Learning Networks for Detecting COVID-19: A Geometric Transformation Perspective. Front. Med. 2021, 8, 629134. [Google Scholar] [CrossRef]
- Kehrel, B.E. Blood platelets: Biochemistry and physiology. Hamostaseologie 2003, 23, 149–158. [Google Scholar]
- Duda, R.O.; Hart, P.E. Use of the Hough Transformation to Detect Lines and Curves in Pictures. Commun. Assoc. Comput. Mach. 1972, 15, 11–15. [Google Scholar] [CrossRef]
- Pepys, M.B.; Hirschfield, G.M. C-reactive protein: A critical update. J. Clin. Investig. 2003, 111, 1805–1812. [Google Scholar] [CrossRef]
- Vidarsson, G.; Dekkers, G.; Rispens, T. IgG Subclasses and Allotypes: From Structure to Effector Functions. Front. Immunol. 2014, 5, 520. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Architecture | Set | Precision | Recall | Dice |
|---|---|---|---|---|
| SegNet-1 | AIS | 0.955 | 0.953 | 0.921 |
| SegNet-1 | OIS | 0.962 | 0.710 | 0.773 |
| SegNet-2 | AIS | 0.933 | 0.906 | 0.887 |
| SegNet-2 | OIS | 0.740 | 0.920 | 0.787 |
| U-Net-1 | AIS | 0.962 | 0.950 | 0.916 |
| U-Net-1 | OIS | 0.946 | 0.883 | 0.878 |
| U-Net-2 | AIS | 0.930 | 0.937 | 0.890 |
| U-Net-2 | OIS | 0.952 | 0.948 | 0.919 |
| Model | Arch. | PCA? | Feat. | CV | Test | L.C.I. | U.C.I. |
|---|---|---|---|---|---|---|---|
| GPR | U-Net-1 | Yes | 344 | 0.916 | 0.773 | 0.751 | 0.799 |
| GPR | U-Net-2 | No | 3138 | 0.791 | 0.762 | 0.739 | 0.781 |
| GPR | SegNet-1 | Yes | 406 | 0.904 | 0.778 | 0.749 | 0.797 |
| XGBoost | U-Net-1 | Yes | 344 | 0.919 | 0.766 | 0.749 | 0.775 |
| XGBoost | U-Net-2 | No | 3138 | 0.867 | 0.795 | 0.774 | 0.821 |
| XGBoost | SegNet-1 | Yes | 406 | 0.922 | 0.839 | 0.825 | 0.852 |
| XGBoost | SegNet-2 | no | 1570 | 0.890 | 0.811 | 0.799 | 0.826 |
| RFR | U-Net-1 | yes | 344 | 0.914 | 0.770 | 0.765 | 0.785 |
| RFR | U-Net-2 | no | 3138 | 0.848 | 0.782 | 0.769 | 0.803 |
| RFR | SegNet-1 | yes | 406 | 0.916 | 0.831 | 0.817 | 0.851 |
| RFR | SegNet-2 | no | 1570 | 0.893 | 0.797 | 0.781 | 0.818 |
| Model | Arch. | Phase | Feat. | CV | Test | L.C.I. | U.C.I. |
|---|---|---|---|---|---|---|---|
| XGBoost | SegNet-1 | 1 and 2 | 410 | 0.966 | 0.863 | 0.851 | 0.875 |
| XGBoost | SegNet-1 | 1 | 406 | 0.922 | 0.839 | 0.825 | 0.852 |
| XGBoost | SegNet-1 | 2 | 4 | 0.603 | 0.042 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kolli, A.; Wei, Q.; Ramsey, S.A. Predicting Time-to-Healing from a Digital Wound Image: A Hybrid Neural Network and Decision Tree Approach Improves Performance. Computation 2024, 12, 42. https://doi.org/10.3390/computation12030042
Kolli A, Wei Q, Ramsey SA. Predicting Time-to-Healing from a Digital Wound Image: A Hybrid Neural Network and Decision Tree Approach Improves Performance. Computation. 2024; 12(3):42. https://doi.org/10.3390/computation12030042
Chicago/Turabian StyleKolli, Aravind, Qi Wei, and Stephen A. Ramsey. 2024. "Predicting Time-to-Healing from a Digital Wound Image: A Hybrid Neural Network and Decision Tree Approach Improves Performance" Computation 12, no. 3: 42. https://doi.org/10.3390/computation12030042