Hardware Support for Security in the Internet of Things: From Lightweight Countermeasures to Accelerated Homomorphic Encryption


Abstract
:1. Introduction
2. Concrete Motivation Examples and the Need for Hardware Protections
3. Countering Simple Power Analysis during Cryptographic Computations
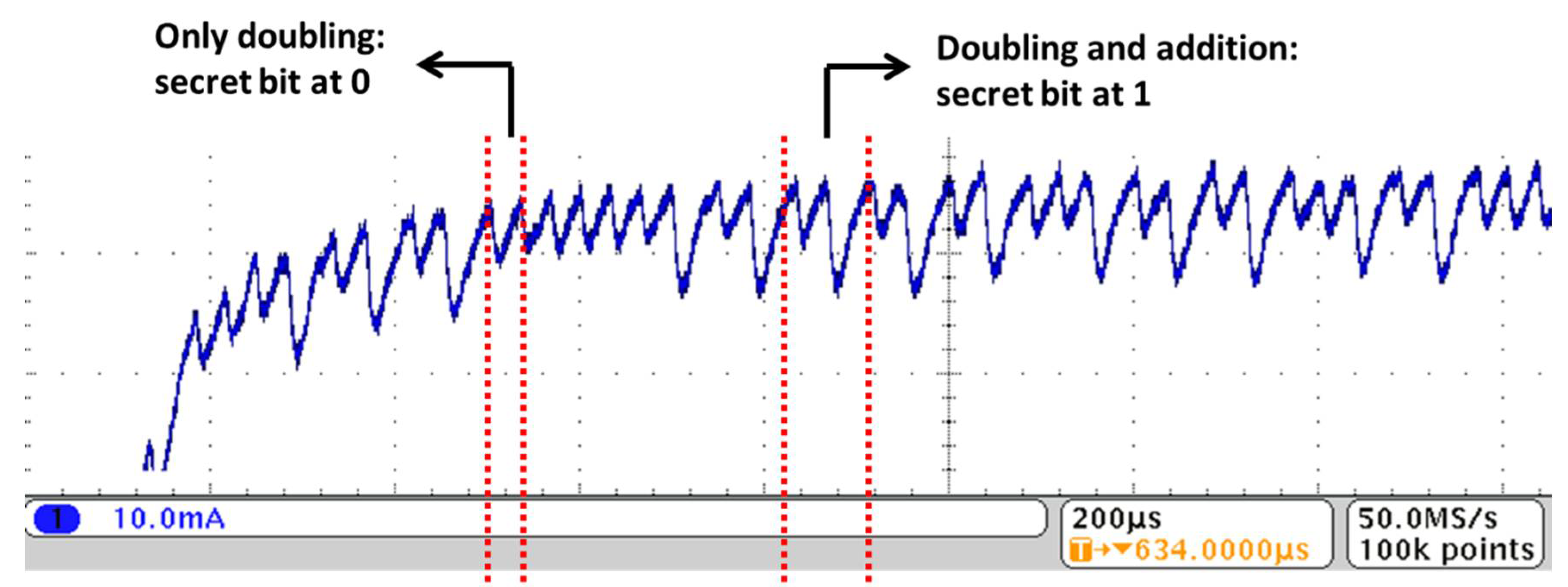
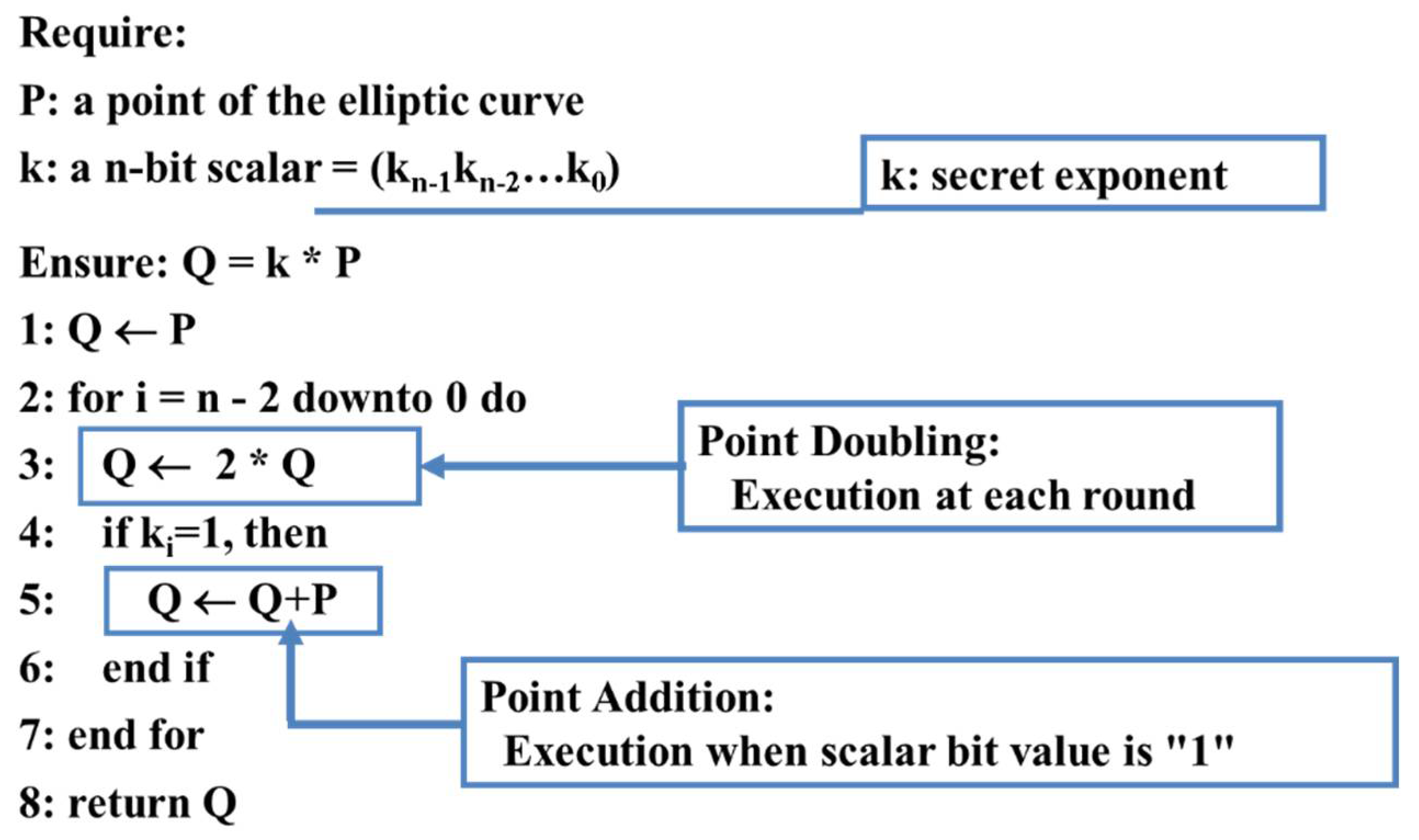
3.1. Some More Background on Hardware-Based Attacks and Countermeasures
3.2. Proposed Approach: Basic Idea
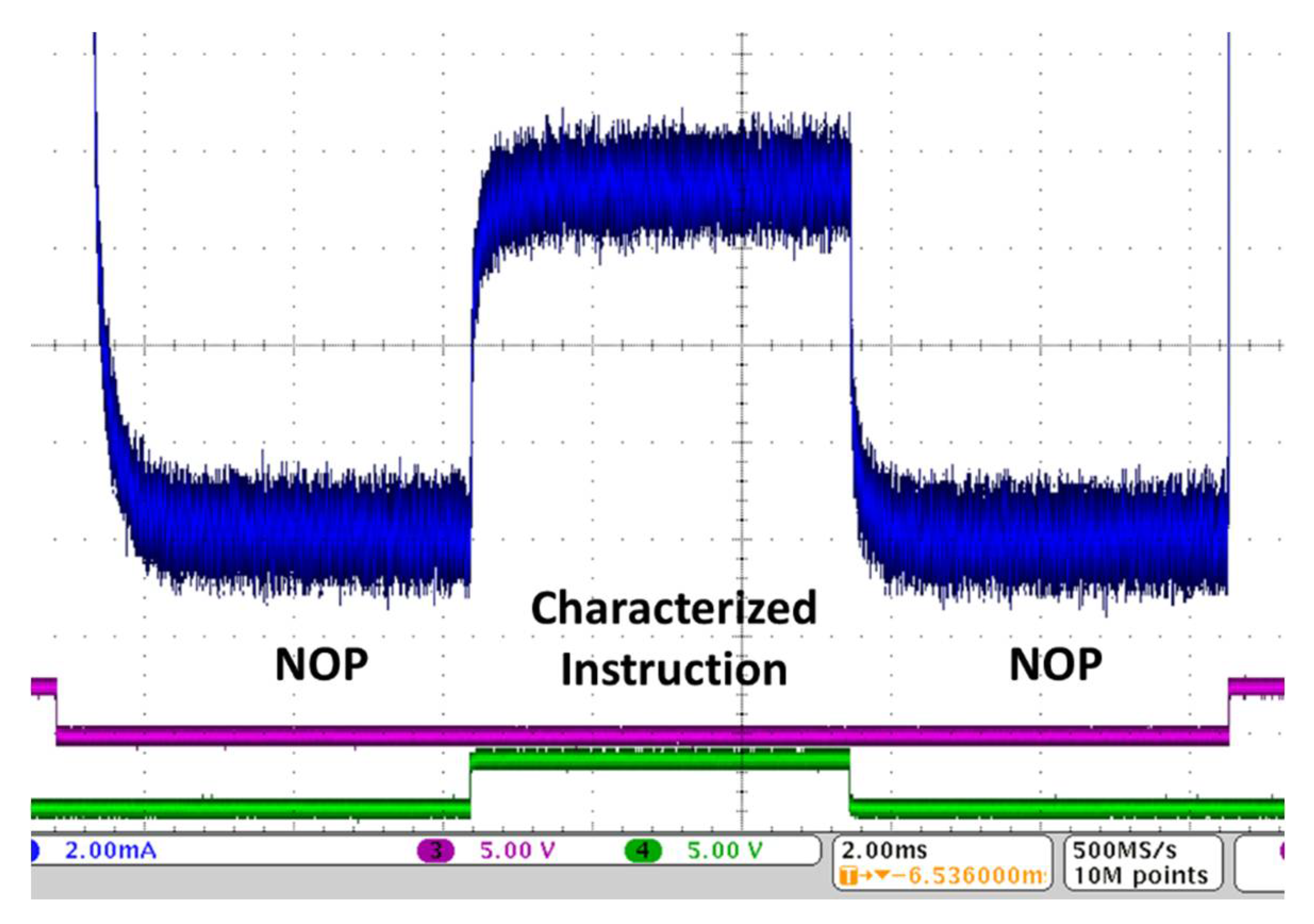
3.3. Proposed Approach: General Purpose Processor Characterization
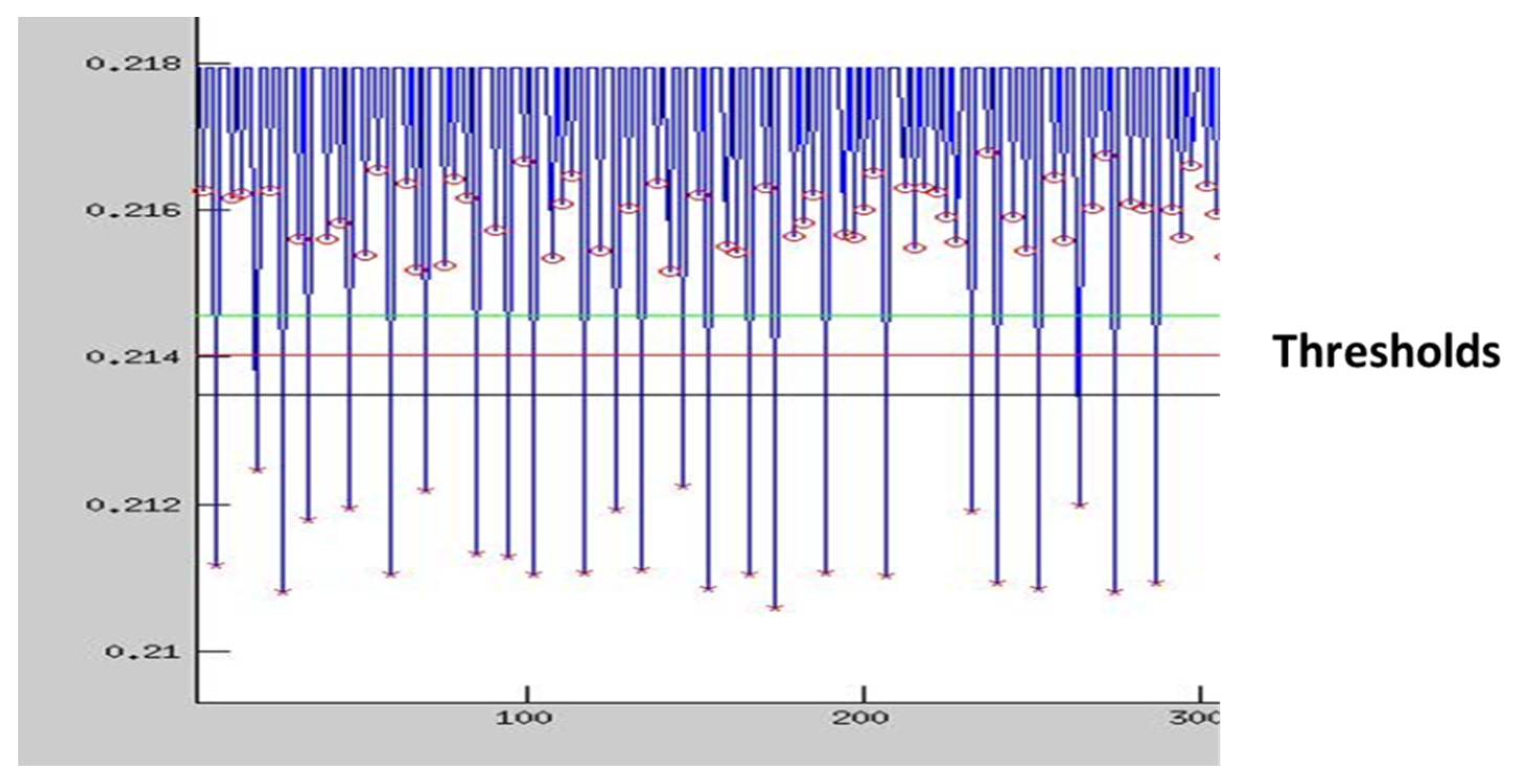
3.4. Automated SPA
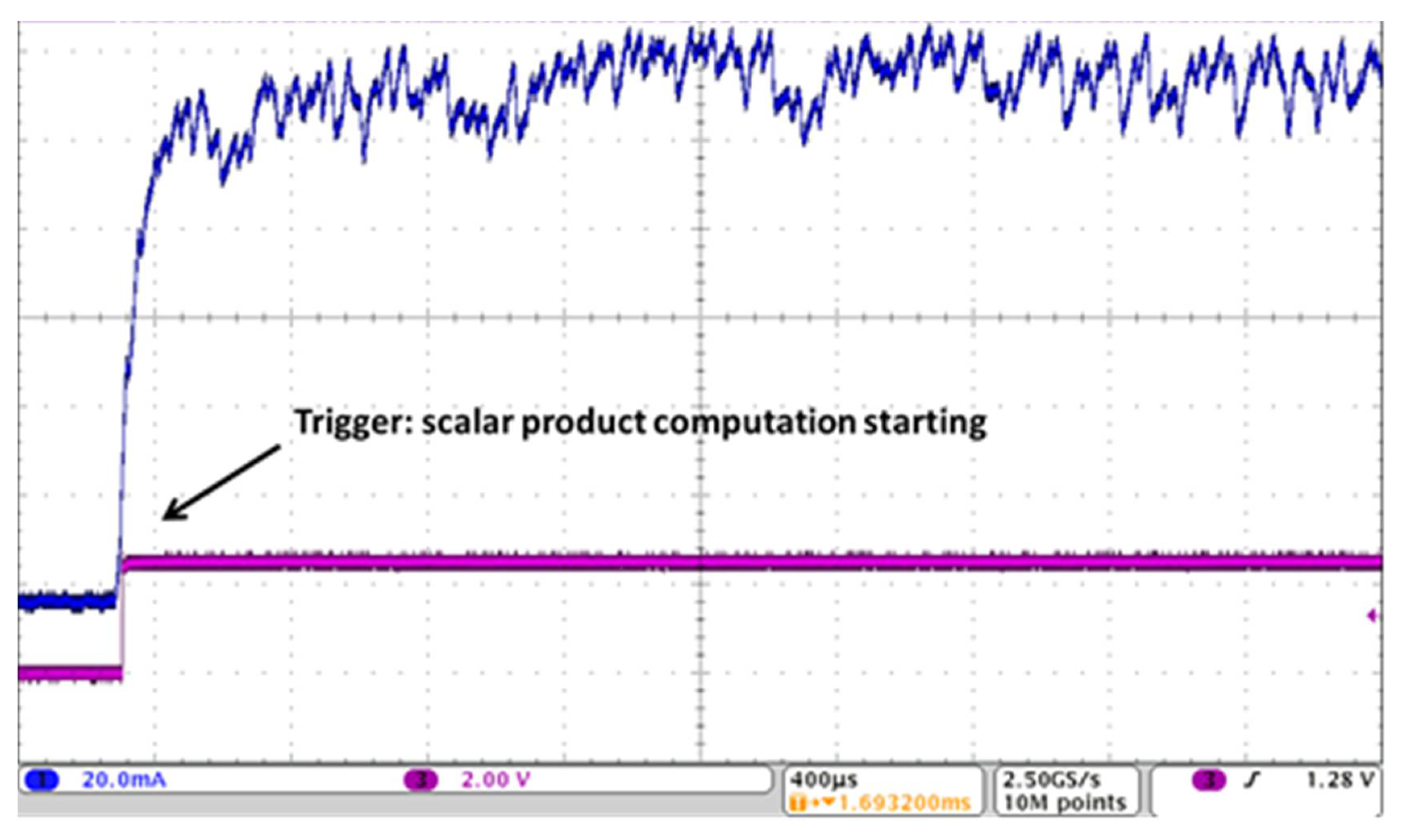
3.5. Results Obtained from a Case Study
4. Accelerating Homomorphic Encryption
4.1. Background and Acceleration Objectives
4.2. Acceleration Approach: Principles
- Level 1: decomposition of large degree polynomials, reconstruction, and modular reduction;
- Level 2: generation of the RNS basis used to decompose the coefficients;
- Level 3: polynomial multiplication;
- Level 4: RNS transformation, coefficient multiplication, modular reduction, and inverse RNS transformation.
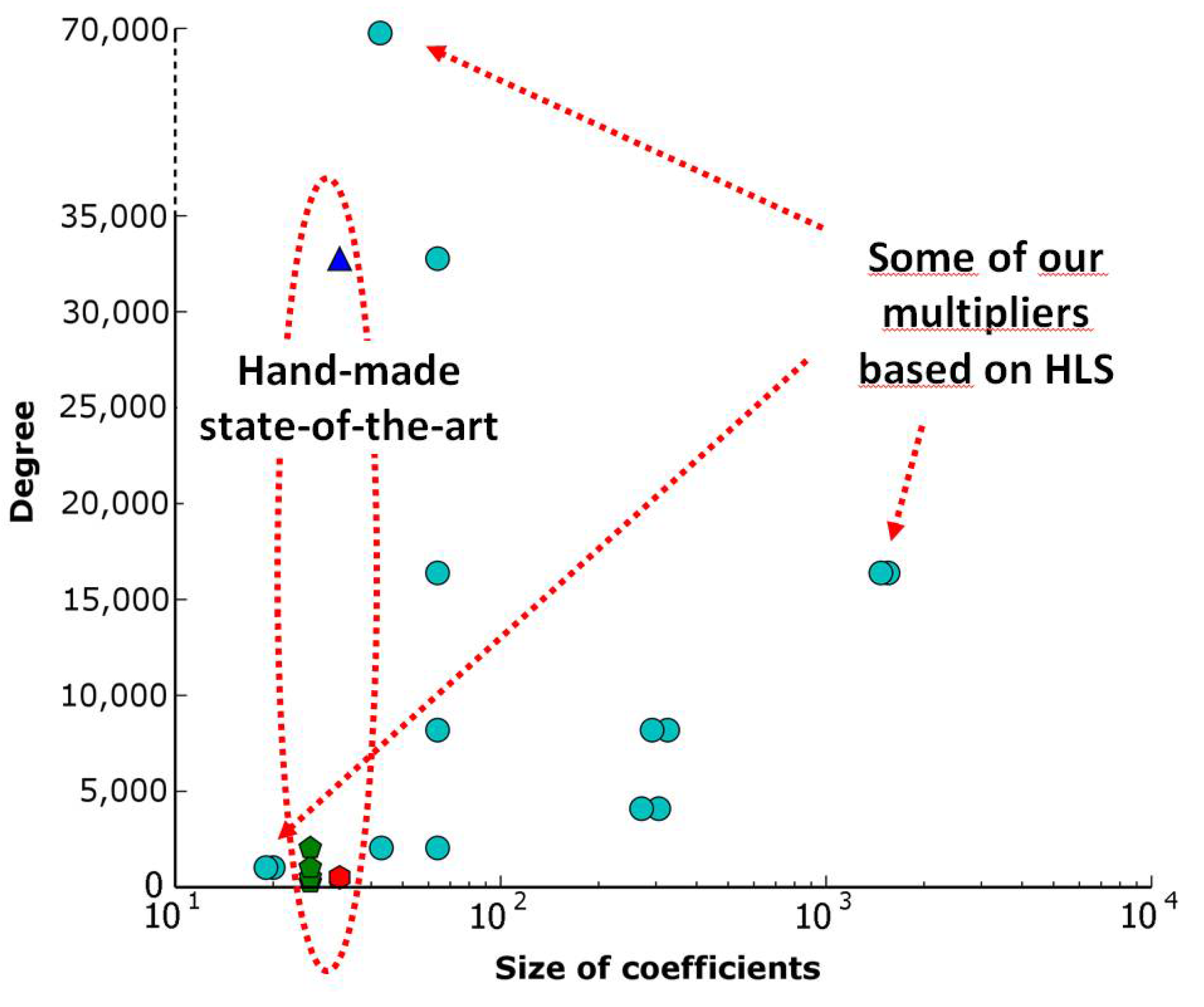
4.3. Proposed Approach: Results for the Modular Polynomial Multiplier
4.4. Proposed Approach: Generalization
5. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Internet of Things Research Study, Hewlett Packard Entreprise. 2015. Available online: http://files.asset.microfocus.com/4aa5-4759/en/4aa5-4759.pdf (accessed on 30 November 2017).
- Ronen, E.; Shamir, A. Extended functionality attacks on IoT devices: The case of smart lights. In Proceedings of the IEEE European Symposium on Security and Privacy (EuroS&P), Saarbrücken, Germany, 21–24 March 2016; pp. 3–12. [Google Scholar]
- Olawumi, O.; Väänänen, A.; Haataja, K.; Toivanen, P. Security issues in smart home and mobile health system: Threat analysis, possible countermeasures and lessons learned. Int. J. Inf. Technol. Secur. 2017, 9, 31–52. [Google Scholar]
- Moore, C.; O’Neill, M.; O’Sullivan, E.; Doröz, Y.; Sunar, B. Practical homomorphic encryption: A survey. In Proceedings of the IEEE International Symposium on Circuits and Systems (ISCAS), Melbourne, VIC, Australia, 1–5 June 2014; pp. 2792–2795. [Google Scholar]
- Bar El, H.; Choukri, H.; Naccache, D.; Tunstall, M.; Whelan, C. The sorcerer’s apprentice guide to fault attacks. Proc. IEEE 2006, 94, 370–382. [Google Scholar] [CrossRef]
- Lepoint, T.; Naehrig, M. A comparison of the homomorphic encryption schemes FV and YASHE. In Proceedings of the 7th International Conference on Cryptology in Africa, Progress in Cryptology—AFRICACRYPT 2014, Marrakesh, Morocco, 28–30 May 2014; pp. 318–335. [Google Scholar]
- Jayet-Griffon, C.; Cornelie, M.-A.; Maistri, P.; Elbaz-Vincent, P.H.; Leveugle, R. Polynomial Multipliers for Fully Homomorphic Encryption on FPGA. In Proceedings of the 2015 International Conference on ReConFigurable Computing and FPGAs (ReConFig), Mexico City, Mexico, 7–9 December 2015; pp. 1–6. [Google Scholar]
- Doröz, Y.; Öztürk, E.; Savas, E.; Sunar, B. Accelerating LTV Based Homomorphic Encryption in Reconfigurable Hardware. In Cryptographic Hardware and Embedded Systems—CHES 2015; Güneysu, T., Handschuh, H., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2015; Volume 9293. [Google Scholar]
- Chen, D.D.; Mentens, N.; Vercauteren, F.; Roy, S.; Cheung, R.; Pao, D.; Verbauwhede, I. High-Speed Polynomial Multiplication Architecture for Ring-LWE and SHE Cryptosystems. IEEE Trans. Circ. Syst. 2015, 62, 157–166. [Google Scholar]
- Black Hat USA 2015: The Full Story of How That Jeep Was Hacked. Available online: https://www.kaspersky.com/blog/blackhat-jeep-cherokee-hack-explained/9493/ (accessed on 21 November 2017).
- Lethal Medical Device Hack Taken to Next Level. Available online: https://www.cso.com.au/article/404909/lethal_medical_device_hack_taken_next_level (accessed on 21 November 2017).
- Firmware Update to Address Cybersecurity Vulnerabilities Identified in Abbott’s (Formerly St. Jude Medical’s) Implantable Cardiac Pacemakers: FDA Safety Communication. Available online: https://www.fda.gov/medicaldevices/safety/alertsandnotices/ucm573669.htm (accessed on 21 November 2017).
- Koeune, F.; Standaert, F.X. A Tutorial on Physical Security and Side-Channel Attacks. In Foundations of Security Analysis and Design III; Aldini, A., Gorrieri, R., Martinelli, F., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2005; Volume 3655. [Google Scholar]
- Ronen, E.; Shamir, A.; Achi-Or Weingarten, A.; O’Flynn, C. IoT goes nuclear: Creating a ZigBee chain reaction. In Proceedings of the IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–24 May 2017; pp. 195–212. [Google Scholar]
- Rivest, R.L.; Shamir, A.; Adleman, L. A method for obtaining digital signatures and public-key cryptosystems. Commun. ACM 1978, 21, 120–126. [Google Scholar] [CrossRef]
- Miller, V. Use of elliptic curves in cryptography. In Proceedings of the Advances in Cryptology (CRYPTO), Santa Barbara, CA, USA, 11–15 August 1986; pp. 417–426. [Google Scholar]
- Koblitz, N. Elliptic curve cryptosystems. Math. Comput. 1987, 48, 203–209. [Google Scholar] [CrossRef]
- Backenstrass, T.; Blot, M.; Pontié, S.; Leveugle, R. Protection of ECC computations against Side-Channel Attacks for lightweight implementations. In Proceedings of the 1st IEEE International Verification and Security Workshop, Sant Feliu de Guixols, Catalunya, Spain, 4–6 July 2016; pp. 2–7. [Google Scholar]
- Rivest, R.L.; Adleman, L.; Dertouzos, M.L. On data banks and privacy homomorphisms. In Foundations of Secure Computation; Academia Press: New York, NY, USA, 1978; pp. 169–179. [Google Scholar]
- Gentry, C. A Fully Homomorphic Encryption Scheme. Ph.D. Dissertation, Stanford University, Stanford, CA, USA, 2009. [Google Scholar]
- Brakerski, Z.; Gentry, C.; Vaikuntanathan, V. (Leveled) fully homomorphic encryption without bootstrapping. In Proceedings of the ACM 3rd Innovations in Theoretical Computer Science Conference (ITCS), Cambridge, MA, USA, 8–10 January 2012; pp. 309–325. [Google Scholar]
- Smart, N.P.; Vercauteren, F. Fully homomorphic encryption with relatively small key and ciphertext sizes. In Proceedings of the 13th international conference on Practice and Theory in Public Key Cryptography (PKC’10), Paris, France, 26–28 May 2010; pp. 420–443. [Google Scholar]
- Garner, H.L. The residue number system. IRE Trans. Electron. Comput. 1959, EC-8, 140–147. [Google Scholar] [CrossRef]
- Gathen, J.; Gerhard, J. Modern Computer Algebra, 3rd ed.; Cambridge University Press: New York, NY, USA, 2013. [Google Scholar]
- Pontié, S.; Bourge, A.; Prost-Boucle, A.; Maistri, P.; Muller, O.; Leveugle, R.; Rousseau, F. HLS-based methodology for fast iterative development applied to Elliptic Curve arithmetic. In Proceedings of the Euromicro/IEEE Conference on Digital System Design (DSD), Limassol, Cyprus, 31 August–2 September 2016; pp. 511–518. [Google Scholar]
- Mkhinini, A.; Maistri, P.; Leveugle, R.; Tourki, R. HLS design of a hardware accelerator for homomorphic encryption. In Proceedings of the IEEE International Symposium on Design and Diagnostics of Electronic Circuits and Systems (DDECS), Dresden, Germany, 19–21 April 2017. [Google Scholar]
- Prost-Boucle, A. Augh Project. TIMA Laboratory, 2016. Available online: http://tima.imag.fr/sls/research-projects/augh/ (accessed on 30 November 2017).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Instruction | Difference to NOP |
|---|---|
| rsubic %0, %0:1000, 5 | +11.76 mA |
| mulh %0, %0:1000, %1:−2 | −7.6 mA |
| addic %0, %0:1000, 1 | +1.63 mA |
| addic %0, %0:1000, −20 | +3.28 mA |
| xori %0, %0:1000, −20 | +11.24 mA |
| bsrli %0, %0:1000, 5 | −5.04 mA |
| flt %0:5.264, %1:15 | −5.08 mA |
| lhu %0, %0:1000, %1:−2 | −9.32 mA |
| Source | Degree | Coeff. Size | Platform | Slice LUT | Slice Register | DSP | Bram | Latency |
|---|---|---|---|---|---|---|---|---|
| [9] | 1024 | 26 | Spartan 6 | 10,801 | 3176 | 0 | 0 | 40.98 µs |
| This work | 1024 | 26 | Spartan 6 | 182 | 114 | 3 | 10 | 69.10 µs |
| [8] | 32,768 | 32 | Virtex 7 | 219,192 | 90,789 | 139 | 768 | 9.51 ms |
| This work | 32,768 | 32 | Virtex 7 | 13,568 | 7680 | 192 | 792 | 13.71 ms |
| [7] | 512 | 32 | Virtex 7 | 252,341 | 130,826 | 512 | 2048 | 4.11 µs |
| This work | 512 | 32 | Virtex 7 | 7032 | 920 | 368 | 0 | 5.27 µs |
| This work | 512 | 32 | Virtex 7 | 171 | 102 | 3 | 3 | 66.41 µs |
| Degree | Coefficient Size | Slice LUT | Slice Register | DSP | Bram |
|---|---|---|---|---|---|
| 256 | 493 | 230 | 720 | 3 | 15 |
| 256 | 7681 | 280 | 792 | 9 | 19 |
| 512 | 12,289 | 501 | 890 | 15 | 31 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Leveugle, R.; Mkhinini, A.; Maistri, P. Hardware Support for Security in the Internet of Things: From Lightweight Countermeasures to Accelerated Homomorphic Encryption. Information 2018, 9, 114. https://doi.org/10.3390/info9050114
Leveugle R, Mkhinini A, Maistri P. Hardware Support for Security in the Internet of Things: From Lightweight Countermeasures to Accelerated Homomorphic Encryption. Information. 2018; 9(5):114. https://doi.org/10.3390/info9050114
Chicago/Turabian StyleLeveugle, Régis, Asma Mkhinini, and Paolo Maistri. 2018. "Hardware Support for Security in the Internet of Things: From Lightweight Countermeasures to Accelerated Homomorphic Encryption" Information 9, no. 5: 114. https://doi.org/10.3390/info9050114