1. Introduction
In the near future, every object we own will be addressable via IP, which will allow the same objects to have access to the Internet, exchanging information with the outside world. It is expected that in 2020 there will be as much as 26 billion units connected to the Internet [
1]. The novelty in all this concerns the fact that this technology is not limited to involving the classic devices, but also makes smart objects that are not.
The scenarios we are going to face are unimaginable; health, education, transport, every aspect of our lives will undergo radical changes, even our own homes will become smart [
2]. The fridge could tell us that it is better to throw eggs away because they are no longer fresh, the washing machine could propose a more efficient way to wash clothes, entire buildings could work together to save energy or other resources.
It is this very principle of “connection between things” which is the basis of the Internet of Things [
3].
However, while on the one hand it is true that we have a multitude of extremely useful scenarios, there are also considerable security and privacy issues [
4].
Certainly, we are not talking about an apocalyptic prospective, but if in everyday life a hacker is able to block our computer, just think about the damage it could make if it decided to block our home doors. This problem is further enhanced by the heterogeneity of the devices, making it more difficult to control and detect security flaws.
If it is already difficult to accept that an object possesses intelligence and can interface with us, the thought that it can revolt against us, causing substantial damage, could make it even more difficult to spread IoT systems.
We then argue that a good way to address this problem is through the concept of trust [
5]. The key point is in fact that users do not trust these systems; they do not know them or what they can do. The concept of trust comes spontaneously into play.
With this work, we want to propose a general IoT system able to adapt to the specific user and its disposition towards this technology, with the aim of (1) identifying the acceptance limit that the user has and (2) pushing the user to accept more this technology.
After introducing a theoretical model, we will introduce a possible implementation in a simulative context, with the aim of showing how it works.
Being a general model, it can be applied to any IoT system.
The rest of the paper is organized as follows:
Section 2 analyzes the state of the art, pointing out that it is necessarily a user centric design for IoT systems;
Section 3 provides a theoretical framework for trust, control, and feedback, also showing the computational model we used;
Section 4 describes how we implemented the model in the simulation of
Section 5;
Section 6 comments on the results of the simulation;
Section 7 concludes the work, resuming all the key points.
2. Distrust in the IoT
How would we like an IoT system to be? What features should it have or should be elicited? The IoT systems represent a wide variety of technologies, so it is not easy to identify in detail the common characteristics. However, in a high-level vision, some key aspects often and recurrently come into play.
When we talk about the characteristics of the IoT, the main topic is that of
security [
6,
7,
8,
9] with the meaning of computer science. A device must be secure, and the reason is clear: if we give the green light to such a pervasive technology, able to enter deeply into every aspect of our life, it is fundamental that there are no security breaches. Are we sure that the toaster is not going to steal the money from our bank account? Can a hacker take the control of my television? Security mainly relies on encryption to solve its problems.
Then
privacy comes into play. In this new world, having objects exchanging impressive amounts of information, more than can concretely be processed [
10], it is not clear which information will be shared and with whom [
11]. We need a new way to deal with privacy, since the classical approach of authentication [
12] and policies cannot work properly in such a huge and heterogeneous environment. Facing privacy is necessary, but still not enough.
A third element is
trust. Usually it is applied to solve the problem of identifying trustworthy devices in a network, separating them from the malicious ones [
13]. By the way, the authors of [
14] provide a review of the use of trust in IoT systems. The same authors identify that trust “helps people overcome perceptions of uncertainty and risk and engages in user acceptance”. In fact, when we have autonomous tools able to take various different decisions and these decisions involve our own goals and results, we have to be worried not just about their correct functioning (for each of these decisions) but also about their autonomous behavior and the role it plays for our purposes.
All these components are valid and fundamental to an IoT system. However, a further point should be emphasized. Although an IoT device requires only the connection and interfacing with the outside world to be defined as such, and then the possibility of being addressed and of exchanging information with the outside world, they are not independent systems, but on the contrary these systems continually interact with users, they relate to them in a very strong way: the user is at the center of everything. In fact, reasoning in view of the goals that these objects possess, the common purpose is to make life better for users, be they the inhabitants of a house, a city, patients/doctors in a hospital, or the workers of a facility.
The user becomes the fundamental point in all of this. A technology can be potentially perfect and very useful but, if people do not accept it, each effort is useless and it goes out of use. It is necessary to keep in mind how much the user is willing to accept an IoT system and to what extent he wants to interface with it.
We would like to focus on this last point, the concept of “user acceptance”.
As Ghazizadeh [
15] says “technology fundamentally changes a person’s role, making the system performance progressively dependent on the integrity of this relationship. … In fact, automation will not achieve its potential if not properly adopted by users and seamlessly integrated into a new task structure”.
Furthermore, Miranda et al. [
16] talk about Internet of People (IoP). In fact, they reiterate that technology must be integrated into the users’ daily lives, which are right at the center of the system. They focus on the fact that IoT systems must be able to adapt to the user, taking people’s context into account and avoiding user intervention as much as possible. Similarly, Ashraf [
17] talks about autonomy in the Internet of things, pointing out that in this context it is necessary to minimize user intervention.
Thus, the acceptance of a new technology seems to be the key point, which is not always obvious. It is not easy for users to understand how a complex technology like this reasons and works. Often it is not clear what it is able to do and how it does it.
So it is true that security, privacy, and trust work together to increase reliance on IoT systems. However, it is necessary to keep users in the center of this discussion.
The reasons why the user may not grant high trust levels are the fears that (a) the task is not carried out in the expected way; (b) that it is not completed at all; or (c) even that damage is produced. All this becomes more and more complicated if we think that these devices can operate in a network that has a theoretically infinite number of nodes! Who do they cooperate with? What are the purposes of these additional devices? You get into a very complex system, difficult to understand and manage.
In short, the overall picture of the functions that they perform is going to complicate a lot. As a whole, the devices have a computational power and a huge amount of data available; they could be able to identify solutions that we had not even imagined. How can we be sure in such a scenario that these systems will realize the state of the world that coincides with what we would like? What if our computer decides to shut down because we worked too much? What if home heating does not turn on because the whole city is consuming too much energy? Surely, we talk about tasks that have their usefulness, but it is not said that the concept of utility the devices possess coincides with ours.
Which goals are we interested in delegating to these systems? Are we sure that they can understand them as we do?
To this purpose Kranz [
18] studies a series of use cases in order to provide some guidelines for embedding interfaces into people’s daily lives.
Economides [
19] identifies a series of characteristics that an IoT system must possess in order to be accepted by users. However, he does not provide a clear methodology about how these characteristics should be estimated and computed.
What we would like is on the one hand that the system is adaptive to the user, comparing the expectations of the latter with what it estimates. On the other hand, we would like the user to adapt to the system, trying to make it accept increasing levels of autonomy.
It is therefore proposed, first of all, a division of the devices’ tasks into increasing levels of autonomy. In order to operate, the devices must continuously estimate the level of autonomy that the user grants them.
In this way, the relationship between an IoT device and the user starts at a level of complexity that the user knows well and can manage, moving eventually to higher levels if the user allows it, i.e., if the trust it has towards the device is sufficient.
In all this it becomes fundamental to identify the levels of user trust. Trust therefore becomes a key concept.
3. Trust, Control, and Feedback
Consider a situation in which a given agent X needs a second agent Y to perform a task for him and must decide whether or not to rely on him. In this case X assumes the role of trustor and Y of trustee. The reasons why he would like to delegate that task can be different; in general, X believes that delegating the task could have some utility.
The cognitive agents in fact decide whether or not to rely on others to carry out their tasks on the basis of the expected utility and of the trust they have in who will perform those tasks. As for the utility, it must be more convenient for the trustor that someone else will carry out the task, otherwise he will do it by himself (in such cases as he can do it). Here we are not interested in dwelling on this point and for simplicity we consider that it is always convenient to rely on others, that is, the expected utility when X asks an agent Y to perform a task is always higher than if X would have done it alone.
The fundamental point of the question is that when an agent Y, cognitive or not, performs a task for me, if Y is to some extent an autonomous agent, I do not know how Y intends to complete his task, nor if he will actually manage to do it.
In this context, the concepts of trust and control intertwine in a very special way. In fact, the more control there is, the less trust we have. Vice versa when we trust we need less control we can allow greater autonomy. So although control is an antagonist of trust, somehow it helps trust formation [
20].
When, in fact, the level of trust is not enough for the trustor to delegate a task to the trustees, control helps to bridge this gap, so that a lower level of trust is required. The more I trust an agent Y, the more I will grant him autonomy to carry out actions. But if I do not trust him enough, I need to exercise control mechanisms over his actions.
For instance, it was shown that [
21] when the users’ experience with autonomous systems involves completely losing control of the decisions, the trust they have in these systems decreases. It is then necessary to lead the user to gradually accept levels of ever-greater autonomy.
We can find control into two different ways. It is in fact possible:
Ensure that the task is successfully accomplished and that the desired goal is achieved. This can be done by asking the trustee for feedback on its work. The feedback must be provided before the operation ends, in order to be able to modify that work.
Actively handle the possible unforeseen event (intervention).
In this way, the feedback is a lighter form of control (less invasive), which may or may not result in the active involvement of the trustor. It has a fundamental role in overcoming the borderline cases in which the trust level would not be enough to delegate a task, but the trustor delegates it anyway thanks to this form of control. In the end, it can result in the definitive acceptance of the task (or in its rejection, and then results in trustor intervention and a consequent trust decrement).
3.1. Trust: A Multilayered Concept
Different cognitive ingredients can be used to produce a trust evaluation. The first one is direct experience, in which the trustor X evaluates the trustee Y exploiting the past interactions it had with Y. The clear advantage of this approach is that it uses direct information; there is no intermediary, so the evaluation could be more reliable (we are supposing that X is able to evaluate Y’s performance more than others). However, it requires a certain number of interactions to produce a good evaluation and initially X should trust Y without any clues to do so (the cold start problem). Please consider that this evaluation could depend on many different factors, and that X is able to perceive their different contributions.
It is also possible to rely on second-hand information, exploiting recommendation [
22] or reputation [
23]. In this case, there is the advantage of having a ready to use evaluation, provided that a third agent Z in X’s social network knows Y and interacted with Y in the past. The disadvantage is that this evaluation introduces uncertainty due to the Z’s ability and its benevolence: how much can I trust Z as an evaluator?
Lastly, it is possible to use some mechanisms of knowledge generalization, such as the categories of belonging [
24]. A category is a general set of agents—doctors, thieves, dogs, and so on—whose members have common characteristics, determining their behavior or their ability/willingness. If I am able to associate Y to a category and I know the average performance of the members belonging to that category concerning the specific task interesting me, I can exploit this evaluation to decide whether to trust Y. The advantage is that I can evaluate every node of my network, even if no one knows it. The disadvantage is that the level of uncertainty due to this method can be high, depending on the variability inside the category and its granularity. A practical example in the context of IoT is that I could believe that the devices produced by a given manufacturer are better than the others and then I could choose to delegate my task to them.
Since in this work we are not strictly interested in how to produce trust evaluations but in their practical applications, we will just rely on direct experience. This allows not introducing further uncertainty caused by the evaluation.
In this paper, trust is taken into account for two aspects. The first is that of autonomy. Similarly to [
25] (in the cited work, the authors use a wheelchair, which in this case is not an IoT device, but an autonomous system endowed with smart functionalities and different autonomy levels.), where however authors are not working with IoT devices, tasks are grouped/categorized into several autonomy levels. A user, based on his personal availability, will assign a certain initial level of autonomy to a device. This level can positively or negatively change over time, depending on the interactions that the user has.
It becomes therefore essential to understand what a device can do, based on the current level of autonomy. Then the first contribution of this work is the identification and classification of the autonomy levels to which an IoT device can operate. Applying the concept of trust and control defined by Castelfranchi and Falcone [
20], we defined 5 levels, numbered from 0 to 1:
Level 0: to operate according to its basic function; for example, a fridge will just keep things cool. This implies that it is not going to communicate with other devices and it is not going beyond its basic task. Proceeding in the metaphor of the fridge, it cannot notice that something is missing; it does not even know what it contains.
Level 1: to communicate with other agents inside and outside the environment, but just in a passive way (i.e., giving information about the current temperature).
Level 2: to autonomously carry out tasks, but without cooperating with other devices; again, thinking of a fridge, if a product needs a temperature below 5 degrees and another one above 7, it can autonomously decide which temperature to set, always keeping in mind that the main goal is to maximize the user’s utility.
Level 3: to autonomously carry out tasks cooperating with other devices. The cooperation is actually a critical element, as it involves problems like the partners’ choice, as well as recognition of merit and guilt. Although we are not going to cover this part, focusing just on the device which started the interaction, it is necessary to point it out. Again, thinking of the fridge, if it is not able to go below a certain temperature because it is hot in the house, it can ask the heating system to lower the temperature of the house. This needs a complex negotiation between two autonomous systems. They need to understand what the user priority is; this is not so easy to solve. Furthermore, it must also be considered that the systems in question must be able to communicate, using common protocols. This can happen if the devices use a standard of communication, enabling interoperability. Smart houses are valid examples of communication between different devices (differently from smart houses, in this work there is no centralized entity. We deal with an open system, in which the intelligence is distributed on the individual devices.).
Level 4: this level is called over-help [
26], which stands for the possibility of going beyond the user’s requests, proposing solutions that he could not even imagine: the same fridge could notice from our temperature that we have the fever, proceeding then to cancel the dinner with our friends and booking a medical examination. This type of interaction may be too pervasive.
It is easy to understand that these kinds of tasks require an increasing level of autonomy. The level 0 is the starting level. Basically, the device limits itself to doing elementary functions, which are the ones it is supposed to do. Then there is no issue for the user. But it is not certain that it is going to accept the next levels.
A trust value is associated with each level i, with i going from 0 to 4, representing the user disposition towards the tasks of that level. The trust values for the autonomy are defined as real numbers in range [0, 1].
These trust values are related to each other: the higher level “i + 1” always has a trust value equal to or less than the previous one i. Moreover, we suppose that there is influence between them, so that when a device selects a task belonging to level i and this is accepted, both the trust value on level i and on the next level “i + 1” will increase, according to the Formulas (1) and (2). Here the new trust value at level i, , is computed as the sum of the old trust value plus the constant increment. Similarly, the new trust value on level “i + 1”, , is computed as the sum of the old trust value plus half of the constant increment.
Note that “
i + 1” exists only if
i is smaller than 4; when
i is equal to 4, Formula (2) is not taken into consideration.
When instead there is a trust decrease since the task is interrupted, even the trust in the following levels is decremented. Formula (3) describes what happens to the autonomy trust value of level
i, while Formula (4) shows what happen to the higher levels:
In Formula (4) is the index of the maximal level defined in the system. Here, in particular, it is equal to 4.
The two variables
increment and
penalty are real values that can assume different values in range [0, 1]. According to [
27] we chose to give a higher weight to negative outcomes than the positive ones, as trust is harder to gain than to lose.
What has been said so far concerns the aspect of autonomy. However, it is necessary to take into consideration that a device can fail when doing a task. Failures are due to multiple causes, both internal and external to the device itself. A device can fail because a sensor detected a wrong measurement, because it did not arrive to do the requested action in time, because it did something differently from what the user expected, or because a second partner device was wrong. All of this is modeled through the dimension called efficiency.
What matters to us in this case is that each device has a certain error probability on each level. Although these values are expected to grow as the level increases, it is not said that is so; there may be mistakes that affect lower level tasks but not upper level tasks.
It is therefore necessary to have a mechanism able to identify which levels create problems, without necessarily blocking the subsequent levels.
Depending on the device’s performance, the trust values concerning
efficiency, defined as real numbers in range [0, 1], will be updated in a similar way to autonomy. Given that we are still dealing with trust and both efficiency and autonomy are modeled in the same way, for the sake of simplicity, we used the same parameters as autonomy: with a positive interaction, the new trust value
is computed as the sum of the old trust value
and “
increment” while, in case of failure, it is decreases of “
penalty”. The Formulas (5) and (6) describe this behavior:
Differently from the autonomy, for the efficiency we change just the trust value of the considered level.
The described trust model works in a similar way for the user. The only difference is that the user has its own constants to update trust: user-increment and user-penalty, defined as real numbers in range [0, 1]. Thus, to get the user’s model, it is just necessary to replace increment with user-increment and penalty with user-penalty in Formulas (1)–(6).
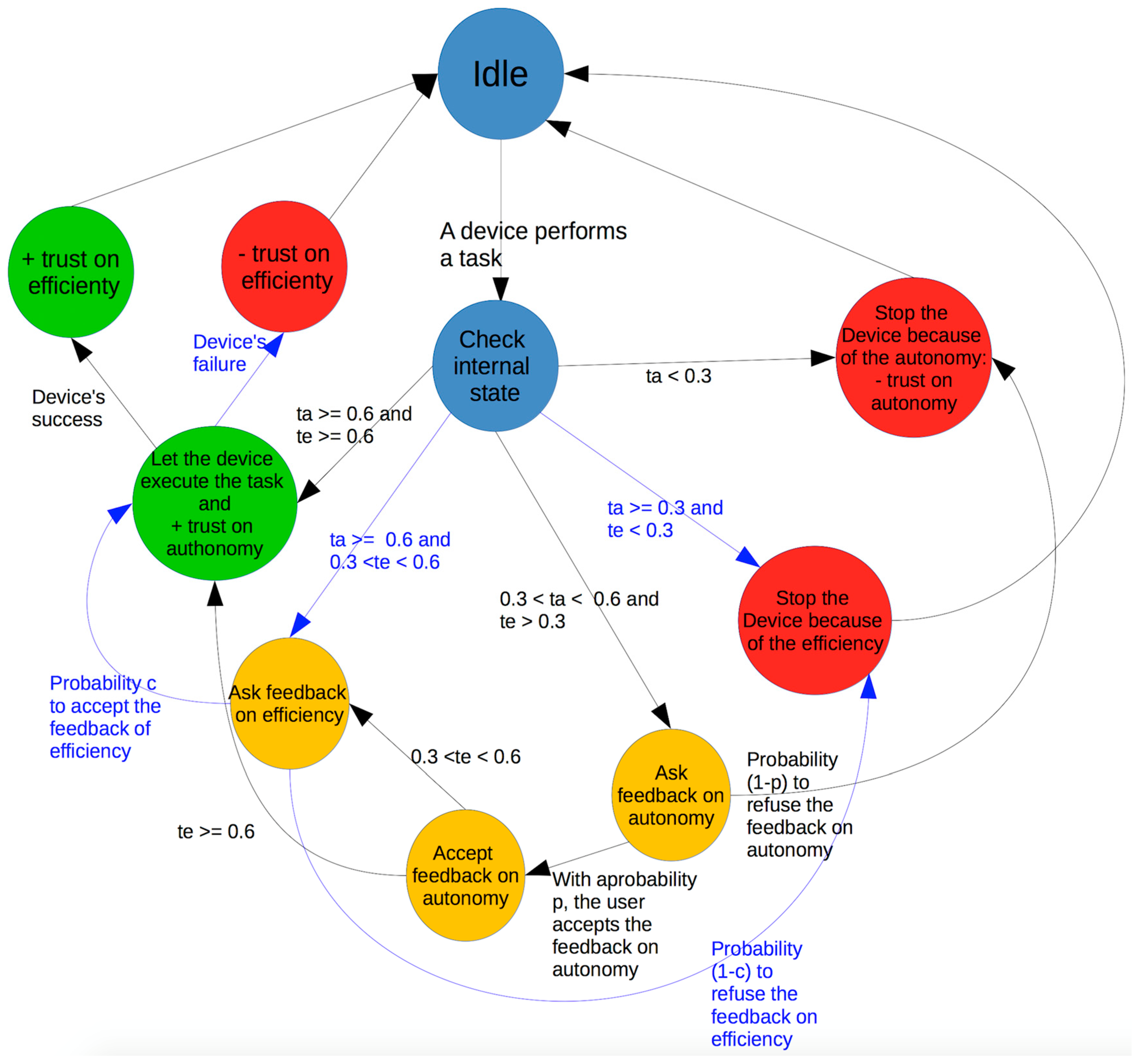
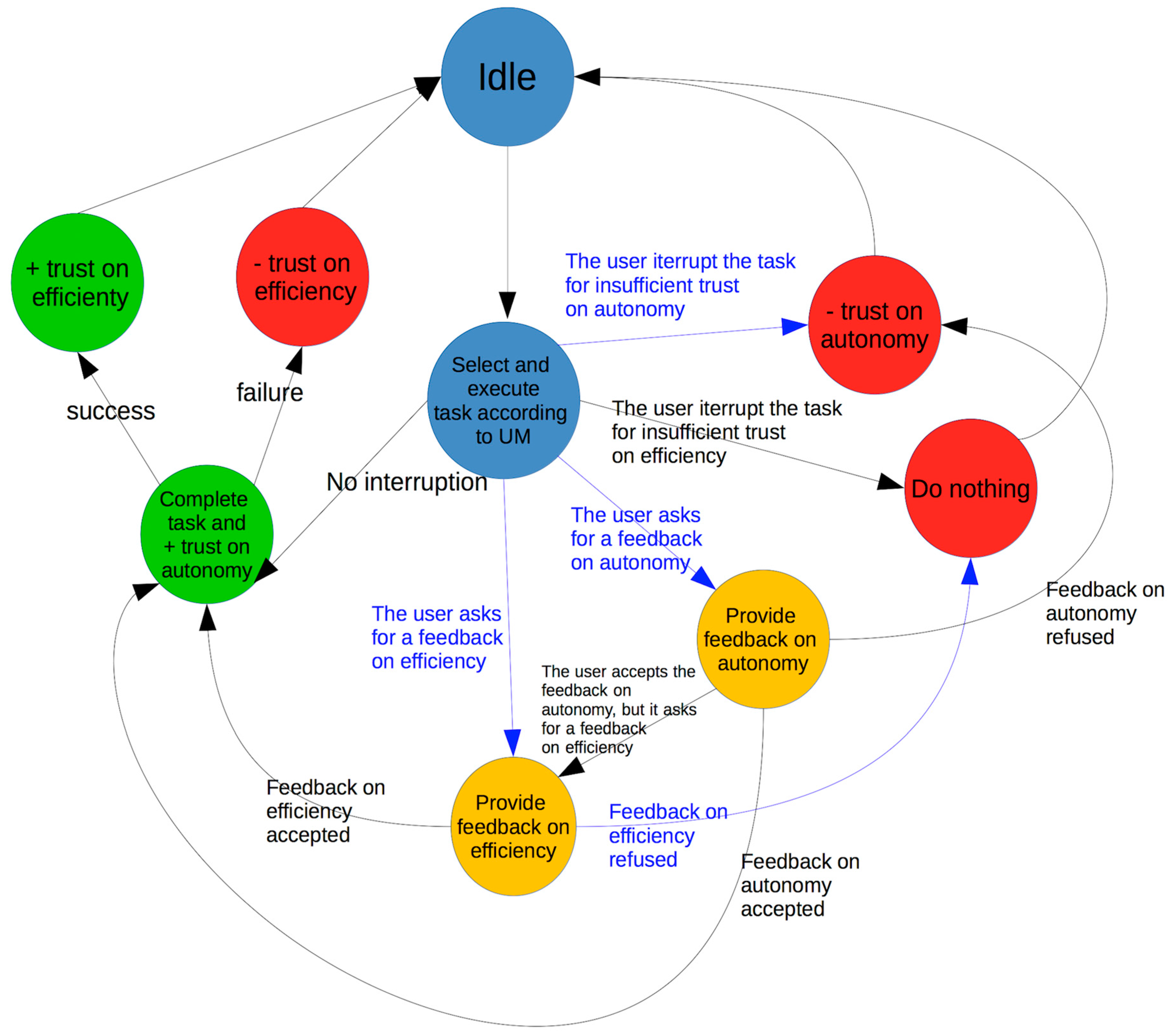
4. The Model
In the realized model a single user U is located in a given environment and interacts with a predefined series of IoT devices, which can perform different kinds of action. The basic idea is that the devices will exploit the interaction with the user U in order to increase the autonomy U grants them.
The simulation is organized in rounds, called ticks, and on each tick U interacts with all of these devices.
The user U has a certain trust threshold in the various autonomy levels. First of all, the device needs to identify this limit value and operate in its range, periodically trying to increase it so that they will have an always-increasing autonomy.
When U makes a positive experience with a device on a given autonomy level it can access, the trust U has on that level increases. We argue that even the trust on the very next level will increase. When this trust value overcomes a threshold, then the devices may attempt to perform tasks belonging to that level. In this case the user, given his trust value on that level, can:
Accept the task: if the trust value is enough, it simply accepts the task.
Ask for feedback: if the trust value is within a given range of uncertainty, and the user is not sure whether to accept the task or not, it then asks for feedback. This feedback will be accepted with a given probability.
Refuse the task: if the trust value is too low, the task is blocked.
This is what happens to autonomy. The efficiency dimension has a similar behavior, with the difference that if the trust on a given level increases, it will not affect the higher levels; it is not given that if a device performs properly on a set of tasks, it will do the same on the higher level; nor is it true that if it performs badly on a level, it will do the same on the higher one. Each level is completely independent of the others. Again, given the specific trust value on that level, the user can:
Accept the task.
Ask for a feedback.
Refuse the task.
5. Simulations
The simulations were realized using NetLogo [
28], an agent-based framework. Given the model described above, we analyzed four different scenarios. The aim was to understand if the described algorithm works and, interacting with a given user having a specific initial disposition towards the devices, actually leads to the user acceptance of new autonomy levels.
Therefore, we investigate a series of concrete scenarios that can happen while interacting with IoT systems, observing their evolution and the final level of autonomy achieved.
In the first of them we will check what happens when there is no error, that is, we assume that the devices are able to get the expected result, producing the state of the world the user wants. Here the efficiency of the devices will always be maximum, therefore the relevant aspect will be that of autonomy.
In later experiments, we considered that the execution of a task can be affected by errors: a sensor reporting wrong information, a partner device making a mistake, a different way to get the same result, or even a delay in getting the result can be considered by the user as a mistake. Here we focus on the relationship between autonomy and efficiency.
For convenience, in the following experiments we will indicate the values of trust or error in the various levels with the form in which the subscript stands for the level.
As we want to understand which is the final result of the model, we need to grant the system enough time to reach each of them; we are not interested in the intermediate states. In order to do so, the experiments’ duration is 1000 runs; we will show the final values of trust after that period. Moreover, in order to eliminate the small differences randomly introduced in the individual experiments, we will show below the average results among 100 equal setting simulations. In particular, we will analyze the aggregate trust values that the user has (the values estimated for each device are aggregated into a single value) in autonomy and efficiency.
5.1. First Experiment
The first experiment analyzes the case in which the devices make no mistake. In this situation, we just focus on the aspect of autonomy, while the efficiency plays a secondary role.
Experimental setting:
Number of devices: 10
Error probability: [0 0 0 0 0]
Penalty = user-penalty = 0.1
Increment = user-increment = 0.05
User profile = (cautious, normal, open-minded)
Feedback acceptance probability: 0%, 25%, 50%, 75%, 100%
Duration: 1000 time units
th-min = 0.3
Th-max = 0.6
Initial trust values for efficiency: [0.5 0.5 0.5 0.5 0.5]
Before starting the discussion of the experiment, we discuss the choice of the simulation parameters, especially for the user.
We did not investigate different values of penalty and increment (and the corresponding user-penalty and user-increment), but we made a few considerations for determining their values. First, they need to be sufficiently small to provide a stable trust evaluation, as high values would lead to an unstable evaluation, too dependent on the last experience. Second, since humans are more influenced by negative outcomes than positive outcomes [
29],
penalty and
user-penalty should be respectively greater than
increment and
user-increment. Third, as the devices need to estimate the user’s trust values, it is very useful that their parameters coincide. A more complete solution would require that the devices estimate the user’s values at runtime. However, this is beyond the aims of the experiment.
As for user profiles, these affect the initial levels of confidence in the autonomy of the devices:
The cautious user is the most restrictive; its initial values are [1 0.75 0.5 0.25 0]. This means that at the beginning only the first two task levels can be executed.
The normal user has slightly higher values: [1 1 0.75 0.5 0.25]. With this user it is possible to perform the first 3 task levels.
The last type of user is the open-minded: [1 1 1 0.75 0.5]. Since this user is the most open towards the devices, it will be possible to immediately execute the first 4 levels of the task, but not the last one.
In the following experiment, we are going to show what happens to the cautious user, as it is the most restrictive. Then, if necessary, we will show the differences for the other users.
We chose to set the efficiency trust values to 0.5, which represents an intermediate condition. The user does not possess any clues nor has an internal predisposition that could lead him to trust more or less a specific device on a specific level. Therefore, he needs to build experience to calibrate these values.
Concerning the choice of th-min and Th-max, there is only the constraint that the first should be smaller than the second. We chose 0.3 and 0.6, respectively, in order to divide the trust degree in three intervals of similar size.
In the above tables, we can see what happens to the user after the interaction with the devices. Each row represents the trust values that a user with a given percentage of feedback acceptance has on the five task levels.
As we can see from the values of autonomy and efficiency (respectively
Table 1 and
Table 2), in this situation the designated algorithm allows the optimal trust levels to be reached.
This is just the ideal case, but it is also the proof that the whole mechanism works. The device can estimate the user’s trust values and they first try to adapt to them. After that, there is a continuous phase of adaptation, both for the devices and for the user: the devices continuously try to modify the user’s trust values. At the end, it will be possible to execute the tasks belonging to any level.
It is worth noting that the final results are independent of the percentage of feedback acceptance and the user profile. These parameters do not influence the final value, but the time needed to get it. Those that we saw are in fact the final results, after 1000 runs. We did not analyze the way the trust levels change during this time window. The feedback acceptance probability for the autonomy influences the speed at which these values are reached, so that a “more willing to innovate” user will reach those values first. For instance,
Table 3 shows what happens in the first experiment after only 250 runs. Here we can see significant differences, due precisely to the fact that users with a lower feedback acceptance probability need more time to reach the final values.
After a sufficiently long time, they all will converge, reaching the same final value; the ending point is always the same.
7. Conclusions
In this work, we propose a model for the users’ acceptance of IoT systems. In fact, while the current literature is working on their security and privacy aspects, very little effort has been made from the user’s point of view and his/her interaction with the IoT systems. This is actually a key topic, as even the most sophisticated technology needs to be accepted by the users, otherwise it simply will not be used.
The model we proposed uses the concepts of trust and control as a starting point, with particular reference to the feedback.
The first contribution of this work is a precise classification of the tasks an IoT device can do according to the autonomy the user grants. We defined 5 levels of autonomy, depending on the functionalities a device has; the execution of a task belonging to a certain level assumes that it is also possible to execute (at least according to autonomy) the tasks of the previous levels.
Basing on this classification, we provided a theoretical framework for the device–user relationship, formalizing their interaction. It is in fact a complex interaction: on the one hand, the device must adapt to the user, on the other hand, it must ensure that the user adapts to it. The realized model perfectly responds to these needs.
We proved this by the means of simulation, implementing the proposed model and showing that it works and it allows enhancing user’s trust on the devices and consequently the autonomy the devices have.
In a further step, we tested the model in the presence of various kinds of error, due to different reasons. In particular, we considered three kinds of error: the incremental one, in which the error probability increases just because the complexity of the task increases; a hardware error (for instance a non-functioning sensor or actuator), which in the specific case influences low-level tasks; an error due to the cooperation with other devices (wrong partner choice, wrong coordination, etc.), affecting the penultimate level. Even in these cases the model works; however, in the last case some limits can be presented on the execution of high level tasks.
The entire work provides some hints and interesting considerations about the user’s acceptance of IoT systems. Their designers should keep in mind this analysis in the design phase. It is worth noting that these results have been obtained focusing not on the specific characteristics of the device, intrinsic in its nature and bound to a specific domain, but on what it is authorized to do based on the autonomy granted to it. This means that these results are applicable to IoT systems in general, regardless of the domain.





{kind=link}
{kind=link}