
Exploring Community Awareness of Mangrove Ecosystem Preservation through Sentence-BERT and K-Means Clustering
 ,
,  and
and
Abstract
:1. Introduction
- Matching the document with a lexicon of awareness expression markers [9];
2. Related Works
2.1. Bidirectional Encoder Representation from Transformer (BERT)
2.2. Sentence-BERT
2.3. K-Means Clustering
- External indices: It evaluates clustering results by comparing cluster memberships assigned by a clustering algorithm with previously known knowledge, such as class labels;
- Internal indices: It evaluates the goodness of a cluster structure by focusing on the intrinsic information on the data itself, such as its similarity.
3. Methodology
3.1. Twitter Scrapping
3.2. Text Preprocessing
3.2.1. Data Cleaning
- Remove the hashtag by replacing it with “<hashtag>,”;
- Remove the link or web address by replacing it with “<link>,”;
- Remove the handler or mention by replacing it with “<user>.”;
- Remove the emoticon or emoji by replacing it with “<emoji>.”;
- Remove single characters, numbers, punctuation, and special characters that are unnecessary in analysis.
3.2.2. Tokenization
3.2.3. Filtering
3.2.4. Stemming
3.2.5. Remove Duplicates Data
3.3. Word Embedding Using Sentence-BERT
3.4. Trend Topic Analysis Based on -Means Clustering
3.4.1. Finding the Optimal Number of Clusters
3.4.2. Optimizing the Clustering Process
3.4.3. Evaluation
3.4.4. Cluster Labeling
3.4.5. Trend Topic Visualization
4. Results and Discussions
4.1. Optimal Number of Clusters
4.2. -Means Clustering Based on Optimal Number of Clusters
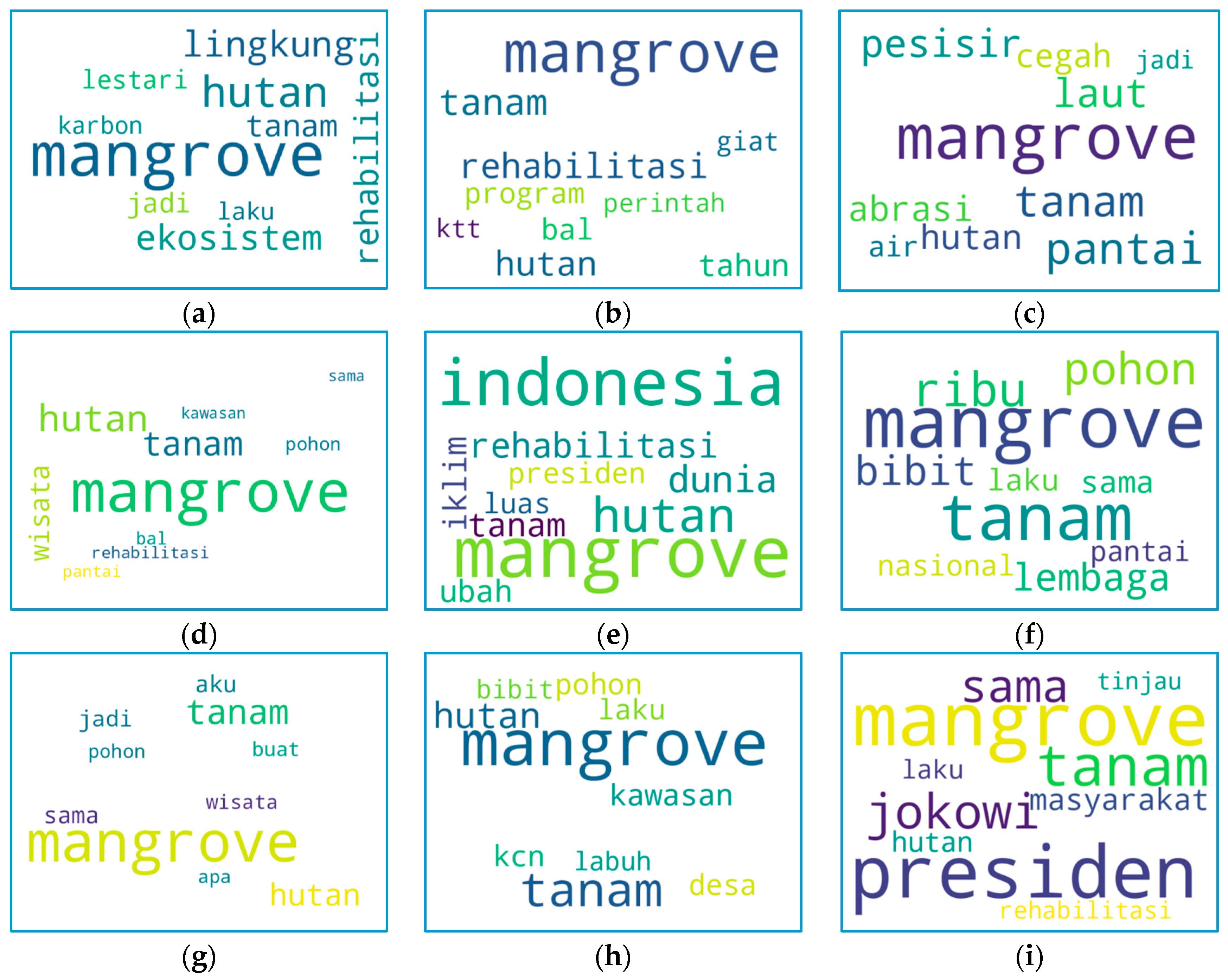
4.3. Cluster Labeling
- Topic 1 contains tweets about mangrove rehabilitation, an ecosystem improvement that benefits society and the environment (e.g., by reducing carbon emissions);
- Topic 2 contains tweets about the government’s program for rehabilitating mangrove forests in preparation for the G-20 Summit;
- Topic 3 contains tweets about real community action in preventing abrasion by planting mangrove trees along the coast;
- Topic 4 contains tweets about the potential for coastal tourism areas and mangrove forests;
- Topic 5 contains tweets about actions to build mangrove centers in Indonesia to deal with climate change;
- Topic 6 contains tweets about the actual actions of the national government in planting mangrove tree seedlings;
- Topic 7 contains tweets about actual community action in replanting mangrove forests;
- Topic 8 contains tweets about the potential of mangrove tourism villages;
- Topic 9 contains tweets about the President’s visit to the mangrove forest in preparation for the G-20 Summit.
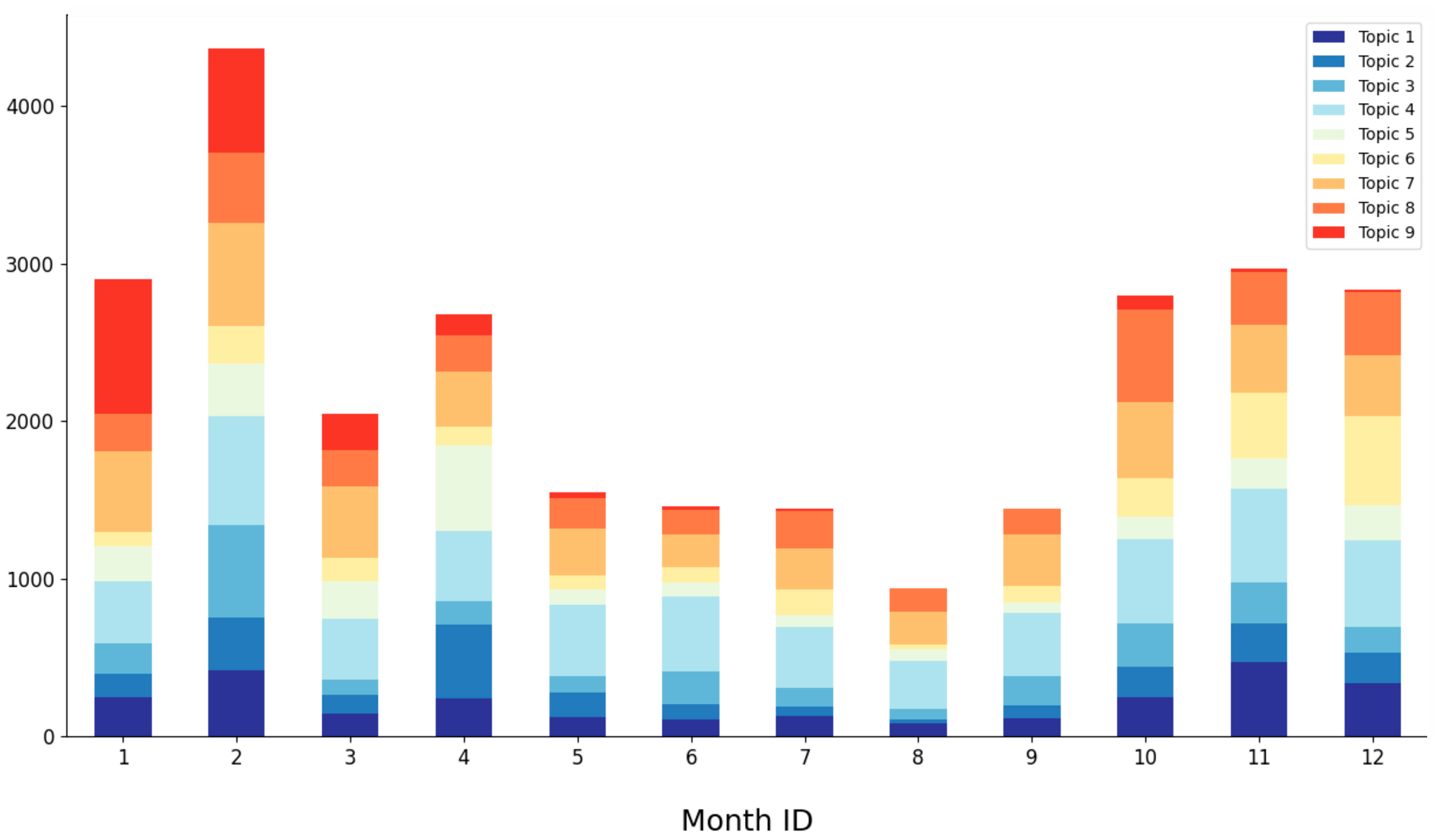
4.4. Trend Topic Visualization
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Reyes-Menendez, A.; Saura, J.R.; Alvarez-Alonso, C. Understanding #worldenvironmentday user opinions in twitter: A topic-based sentiment analysis approach. Int. J. Environ. Res. Public. Health 2018, 15, 2537. [Google Scholar] [CrossRef] [PubMed]
- Karami, A.; Shah, V.; Vaezi, R.; Bansal, A. Twitter Speaks: A Case of National Disaster Situational Awareness. J. Inf. Sci. 2019, 46, 313–324. [Google Scholar] [CrossRef]
- D’andrea, E.; Ducange, P.; Bechini, A.; Renda, A.; Marcelloni, F. Monitoring the Public Opinion about the Vaccination Topic from Tweets Analysis. Expert Syst. Appl. 2019, 116, 209–226. [Google Scholar] [CrossRef]
- Boon-Itt, S.; Skunkan, Y. Public perception of the COVID-19 pandemic on twitter: Sentiment analysis and topic modeling study. JMIR Public Health Surveill. 2020, 6, e21978. [Google Scholar] [CrossRef] [PubMed]
- Chandrasekaran, R.; Mehta, V.; Valkunde, T.; Moustakas, E. Topics, Trends, and Sentiments of Tweets about the COVID-19 Pandemic: Temporal Infoveillance Study. J. Med. Internet Res. 2020, 22, e22624. [Google Scholar] [CrossRef] [PubMed]
- Bian, J.; Zhao, Y.; Salloum, R.G.; Guo, Y.; Wang, M.; Prosperi, M.; Zhang, H.; Du, X.; Ramirez-Diaz, L.J.; He, Z.; et al. Using social media data to understand the impact of promotional information on laypeople’s discussions:a case study of lynch syndrome. J. Med. Internet Res. 2017, 19, e414. [Google Scholar] [CrossRef] [PubMed]
- Patel, K.D.; Zainab, K.; Heppner, A.; Srivastava, G.; Mago, V. Using Twitter for diabetes community analysis. Netw. Model. Anal. Health Inform. Bioinform. 2020, 9, 36. [Google Scholar] [CrossRef]
- Abbar, S.; Zanouda, T.; Berti-Equille, L.; Borge-Holthoefer, J. Using Twitter to Understand Public Interest in Climate Change: The Case of Qatar. In Proceeding of the Tenth International AAAI Conference on Web and Social Media Social Web for Environmental and Ecological Monitoring, Cologne, Germany, 17–20 May 2016; pp. 168–177. [Google Scholar]
- Lenoir, P.; Moulahi, B.; Azé, J.; Bringay, S.; Mercier, G.; Carbonnel, F. Raising awareness about cervical cancer using twitter: Content analysis of the 2015 #smearforsmear campaign. J. Med. Internet Res. 2017, 19, e344. [Google Scholar] [CrossRef] [PubMed]
- Xie, Q.; Zhou, Y.; Xin, L.; Qianqian, X.; Lucheng, H. Twitter Data Mining for the Social Awareness of Emerging Technologies. In Proceedings of the 2017 Portland International Conference on Management of Engineering and Technology (PICMET), Portland, OR, USA, 9–13 July 2017; pp. 1–10. [Google Scholar] [CrossRef]
- Reimers, N.; Gurevych, I. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 3982–3992. [Google Scholar] [CrossRef]
- Wu, J. Cluster Analysis and K-Means Clustering: An Introduction. In Advances in K-Means Clustering, A Data Mining Thinking; Springer: Berlin/Heidelberg, Germany, 2012; pp. 1–16. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Subakti, A.; Murfi, H.; Hariadi, N. The performance of BERT as data representation of text clustering. J. Big Data 2022, 9, 15. [Google Scholar] [CrossRef] [PubMed]
- Hu, W.; Xu, D.; Niu, Z. Improved K-Means Text Clustering Algorithm Based on BERT and Density Peak. In Proceedings of the 2021 2nd Information Communication Technologies Conference, ICTC 2021, Nanjing, China, 7–9 May 2021; pp. 260–264. [Google Scholar] [CrossRef]
- Kaliyar, R.K. A Multi-layer Bidirectional Transformer Encoder for Pre-trained Word Embedding: A Survey of BERT. In Proceeding of the 10th International Conference on Cloud Computing, Data Science & Engineering (Confluence), Noida, India, 29–31 January 2020; pp. 336–340. [Google Scholar]
- Sinaga, K.P.; Yang, M.S. Unsupervised K-Means clustering algorithm. IEEE Access 2020, 8, 80716–80727. [Google Scholar] [CrossRef]
- Sammouda, R.; El-Zaart, A. An Optimized Approach for Prostate Image Segmentation Using K-Means Clustering Algorithm with Elbow Method. Comput. Intell. Neurosci. 2021, 2021, 4553832. [Google Scholar] [CrossRef] [PubMed]
- Bhatt, B. Scrape Twitter Data or Tweets in Python Using Snscrape Module. Available online: https://github.com/bhattbhavesh91/twitter-scrapper-snscrape (accessed on 3 September 2022).
- George, L.; Sumathy, P. An integrated clustering and BERT framework for improved topic modeling. Int. J. Inf. Technol. 2023, 15, 2187–2195. [Google Scholar] [CrossRef] [PubMed]
- Jeremy, N.H.; Suhartono, D. Automatic personality prediction from Indonesian user on twitter using word embedding and neural networks. Procedia Comput. Sci. 2021, 179, 416–422. [Google Scholar] [CrossRef]
- Khan, A.; Shah, Q.; Uddin, M.I.; Ullah, F.; Alharbi, A.; Alyami, H.; Gul, M.A. Sentence embedding based semantic clustering approach for discussion thread summarization. Complexity 2020, 2020, 4750871. [Google Scholar] [CrossRef]
- Zhu, L.; Luo, D. A Novel Efficient and Effective Preprocessing Algorithm for Text Classification. J. Comput. Commun. 2023, 11, 1–14. [Google Scholar] [CrossRef]
- Reimers, N.; Gurevych, I. Making Monolingual Sentence Embeddings Multilingual using Knowledge Distillation. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 4512–4525. Available online: https://github.com/facebookresearch/ (accessed on 15 December 2023).
- Koto, F.; Lau, J.H.; Baldwin, T. INDOBERTWEET: A Pretrained Language Model for Indonesian Twitter with Effective Domain-Specific Vocabulary Initialization. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 10660–10668. Available online: https://huggingface.co/huseinzol05/ (accessed on 15 December 2023).
- Xie, Q.; Zhang, X.; Ding, Y.; Song, M. Monolingual and multilingual topic analysis using LDA and BERT embeddings. J. Informetr. 2020, 14, 101055. [Google Scholar] [CrossRef]
- Shi, C.; Wei, B.; Wei, S.; Wang, W.; Liu, H.; Liu, J. A quantitative discriminant method of elbow point for the optimal number of clusters in clustering algorithm. EURASIP J. Wirel. Commun. Netw. 2021, 2021, 31. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Tweet in Indonesian (in English) |
|---|---|
| 1 | Keberadaan hutan mangrove dapat mencegah terjadinya abrasi dan erosi pantai (The existence of mangrove forests can prevent coastal abrasion and erosion) |
| 2 | Pesona kawasan taman hutan raya mangrove jadi venue penting di even G20 Bali (The beauty of the mangrove forest park area is essential to the G20 Bali event) |
| 3 | Ayo Sob, kita dukung rehabilitasi mangrove yang melibatkan masyarakat di Provinsi Kepulauan Bangka Belitung (Come on, friend, let us support mangrove rehabilitation involving the Bangka Belitung Islands Province community) |
| 4 | Kelompok Rehabilitasi Ekosistem Pesisir Kampung Yensawai Ajak Wisatawan Asing Tanam Karang, Lamun, Terumbu Karang dan Mangrove (Yensawai Village Coastal Ecosystem Rehabilitation Group Invites Foreign Tourists to Plant Coral, Seagrass, Coral Reefs and Mangroves) |
| 5 | Mangrove adalah salah satu pembahasan penting dalam Presidensi G20 Indonesia 2022, mencakup issu lingkungan dunia (Mangroves are one of the critical discussions in Indonesia’s 2022 G20 Presidency, covering world environmental issues) |
| 6 | Selamat Hari Mangrove Internasional, Ayo Jaga hutan Mangrove kita (Happy International Mangrove Day! Let’s protect our mangrove forests) |
| 7 | Restorasi mangrove teguhkan komitmen hadapi dampak perubahan iklim (Mangrove restoration strengthens commitment to facing the impacts of climate change) |
| Month_ID | Period | Number of Tweets |
|---|---|---|
| 1 | September 2021 | 1467 |
| 2 | October 2021 | 1390 |
| 3 | November 2021 | 1370 |
| 4 | December 2021 | 922 |
| 5 | January 2022 | 1417 |
| 6 | February 2022 | 2762 |
| 7 | March 2022 | 2885 |
| 8 | April 2022 | 2670 |
| 9 | May 2022 | 2879 |
| 10 | June 2022 | 4307 |
| 11 | July 2022 | 2012 |
| 12 | August 2022 | 2590 |
| Total number of Tweets = 26,671 | ||
| Pre-Trained Model | Coherence Score | Silhouette Score |
|---|---|---|
| distiluse-base-multilingual-cased-v2 | 0.453 | 0.036 |
| IndoBERTweet | 0.383 | 0.018 |
| Topic ID | Label | Keywords |
|---|---|---|
| 1 | Benefits of mangrove ecosystem rehabilitation | mangrove, lingkungan, rehabilitasi, lestari, hutan, karbon, tanam, jadi, ekosistem mangrove, environment, rehabilitation, sustainable, forest, carbon, planting, ecosystem |
| 2 | Government program for mangrove forests in the context of the G-20 Summit | mangrove, tanam, rehabilitasi, giat, tanam, program, pemerintah, ktt, hutan, tahun mangrove, planting, rehabilitation, active, planting, program, government, summit, forest, year |
| 3 | The function of mangrove forests is to prevent abrasion | mangrove, pesisir, cegah, jadi, laut, abrasi, tanam, air, hutan, pantai [mangrove, coastal, prevent, so, sea, abrasion, planting, water, forest, beach] |
| 4 | Mangrove forest ecotourism | [mangrove, hutan, Kawasan, pohon, sama, tanam, wisata, rehabilitasi, pantai] mangrove, forest, area, tree, same, planting, tourism, rehabilitation, beach |
| 5 | Mangrove forests and their relation to climate change | mangrove, indonesia, iklim, presiden, luas, dunia, hutan, tanam, ubah, luas mangrove, indonesia, climate, president, area, world, forest, plant, change, area |
| 6 | Public center of mangrove ecosystem | mangrove, pohon, ribu, bibit, laku, sama, tanam, Pantai, nasional, lembaga mangrove, tree, thousand, seeds, sell, same, plant, beach, national, institution |
| 7 | Replanting mangrove forests | mangrove, tanam, hutan, wisata, hutan, pohon, apa, sama, jadi, buat mangrove, planting, forest, tourism, forest, tree, what, same, so, make |
| 8 | Mangrove tourist village | mangrove, bibit, hutan, pohon, laku, kawasan, desa, labuh, tanam, kcn mangrove, seedling, forest, tree, practice, area, village, anchor, planting, kcn |
| 9 | President’s visit to mangrove forests in the context of the G-20 Summit | mangrove, tinjau, laku, tanam, masyarakat, jokowi, presiden, hutan, rehabilitasi, sama mangrove, review, sell, plant, community, jokowi, president, forest, rehabilitation, same |
| Example of Tweet in Indonesian (in English) | Topic ID |
|---|---|
| Rehabilitasi mangrove, konservasi maupun tata kelolanya sangat penting sebagai suistainable development (Mangrove rehabilitation, conservation, and management are crucial for sustainable development) | 1 |
| Makanya bakal ada showcase konservasi di Bali loh selama rangkaian acara #KickOffG20, showcase ini jg jadi bagian rehabilitasi & konservasi mangrove (That’s why there will be a conservation showcase in Bali during the #KickOffG20 event series; this showcase will also be part of mangrove rehabilitation and conservation.) | 2 |
| Tanam Mangrove, Kurangi Potensi Abrasi di Daerah Pesisir Pantai (Planting mangroves reduces the potential for abrasion in coastal areas.) | 3 |
| Sejauh mata memandang, hamparan mangrove yang tampak menghijau menjadi penyejuk mata di siang hari yang cukup terik di kawasan ekowisata Karongsong di pesisir pantai Indramayu, Jabar. (The verdant mangroves extend as far as the eye can see, refreshing the eyes on a hot day in the Karongsong ecotourism area on the coast of Indramayu, West Java). | 4 |
| Mangrove yang kaya karbon di kepulauan Indonesia harus menjadi komponen strategi prioritas tinggi untuk mitigasi perubahan iklim (Carbon-rich mangroves in the Indonesian archipelago should be a high-priority strategy component for climate change mitigation) | 5 |
| Pemerintah sudah merehabilitasi mangrove di lahan 110 ribu hektar dari rencana yang sudah ditargetkan 600 ribu hektar (The government has rehabilitated mangroves on 110 thousand hectares of land from the planned target of 600 thousand hectares) | 6 |
| Ini merupakan penanaman #mangrove yang dilakukan minggu lalu, dalam rangka menyambut peringatan Hari Mangrove Sedunia di pesisir Pantai Tirang, Jawa Tengah (This is a #mangrove planting that was carried out last week to welcome the commemoration of World Mangrove Day on the coast of Tirang Beach, Central Java.) | 7 |
| The Sungai Kupah Tourism Village management is holding a Mangrove Edu camp throughout West Kalimantan to celebrate World Mangrove Day. #mangroveeducamp (The Sungai Kupah Tourism Village management is holding a Mangrove Edu camp throughout West Kalimantan to celebrate World Mangrove Day. #mangroveeducamp) | 8 |
| Jelang G20 Presiden Tinjau Hutan Mangrove (Ahead of G20, President Visits Mangrove Forests) | 9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kusumaningrum, R.; Khoerunnisa, S.F.; Khadijah, K.; Syafrudin, M. Exploring Community Awareness of Mangrove Ecosystem Preservation through Sentence-BERT and K-Means Clustering. Information 2024, 15, 165. https://doi.org/10.3390/info15030165
Kusumaningrum R, Khoerunnisa SF, Khadijah K, Syafrudin M. Exploring Community Awareness of Mangrove Ecosystem Preservation through Sentence-BERT and K-Means Clustering. Information. 2024; 15(3):165. https://doi.org/10.3390/info15030165
Chicago/Turabian StyleKusumaningrum, Retno, Selvi Fitria Khoerunnisa, Khadijah Khadijah, and Muhammad Syafrudin. 2024. "Exploring Community Awareness of Mangrove Ecosystem Preservation through Sentence-BERT and K-Means Clustering" Information 15, no. 3: 165. https://doi.org/10.3390/info15030165