The effectiveness of artificial intelligence (AI) models is closely tied to the quality and quantity of data utilized in their training. With the abundance of information available on various devices, including mobile and servers, there is an opportunity to glean valuable insights. Federated learning (FL) is an innovative machine learning (ML) approach that leverages decentralized data and computational resources to deliver more tailored and flexible applications while upholding the privacy of users and organizations. By utilizing FL, it is possible to uphold data protection laws and regulations, thereby ensuring that privacy is not compromised. FL has demonstrated exceptional results in numerous analysis tasks, such as image classification, object detection, and action recognition [
1,
2,
3], indicating its robustness and effectiveness in these areas. To elaborate further, FL allows data to remain on individual devices (cross-device) or servers (cross-silo) rather than being centralized, thereby avoiding potential privacy breaches. This approach enables users to keep their data safe and secure while still contributing to the training of ML models. Moreover, FL can handle large and diverse datasets, which often lead to improved accuracy in analysis tasks. As a result, FL has emerged as a promising technique that can revolutionize the way AI models are trained and deployed, all while maintaining the privacy and security of users’ data. FL has distinct characteristics when compared to distributed learning. Firstly, communication in FL is often slower and less stable. Secondly, FL involves participants with heterogeneous devices, which vary in terms of their computing capabilities. Lastly, privacy and security are emphasized more in FL. Although most studies assume that both participants and servers are trustworthy, this may not always be the case in reality.
Several studies have been conducted to offer a comprehensive understanding of the current state of FL, its potential applications, and the ongoing efforts to overcome its challenges and limitations [
4,
5,
6,
7,
8,
9,
10,
11]. These studies explore various methods and techniques, such as optimization algorithms for efficient model aggregation, privacy-preserving mechanisms, and adaptive learning strategies. While these works acknowledge the potential benefits of FL, such as collaborative ML across decentralized data sources, privacy preservation, and empowering edge devices, they predominantly focus on the theoretical aspects. However, they lack practical and experimental analysis. Therefore, further research and development are needed to incorporate more practical implementations and experimental evaluations to validate the theoretical findings and provide real-world insights into the effectiveness and scalability of existing FL systems [
12,
13,
14].
However, implementing and deploying FL systems can be even more challenging due to a variety of factors such as high communication costs, heterogeneity in data, regulations, and tasks across different participating organizations, the autonomy and redundancy of processing nodes, and the potential for data poisoning incidents. This study aims to address these challenges by analyzing and validating the FL system architecture against these key issues. The contributions of this work can be categorized as follows:
Overall, this study seeks to contribute to the overall understanding of the challenges faced by FL systems and provide solutions to improve their efficiency, scalability, and security. The outcomes of this study could have significant implications for the development and deployment of FL systems in various domains, including healthcare, finance, robotics and education.
1.1. Communication Efficiency and System-Specific Challenges
In developing federated networking methodologies, the communication overhead must be considered as an important constraint. Although a comprehensive review of communication-efficient distributed learning methods is beyond the scope of this article, we can identify several general directions for addressing this issue. These directions can be roughly divided into two categories: (a) local updating methods and (b) compression schemes. Reducing the communication overhead is essential to make FL flexible against the explosive growth of datasets. To achieve this goal, reducing the number of communication rounds and improving the model upload speed have been effective efforts to further minimize the update time. Recently, several methods have been proposed to improve communication efficiency [
15,
16,
17,
18]. The communication between the server and the clients is intended to be as small as possible in order to reduce the upload time. This is achieved by allowing, in distributed settings, a variable number of local updates to be applied in parallel on each machine during each round of communication. This makes the amount of computation versus communication much more flexible. In practice, these methods drastically improve performance and have been shown to achieve significant speedups over traditional distributed approaches. For federation environments, optimizations allowing flexible local updates and low client participation are common.
In particular, the research on FL has focused on increasing communication efficiency and accelerating model updates. McMahan et al.’s [
19] pioneering work introduced the concept of averaging local stochastic gradient descent updates to increase the calculated quantity of each client between communication rounds. Nishio and Yonetani’s [
16] FedCs framework aimed to integrate as many available clients as possible in each training round by using maximum mean discrepancy. Yurochkin et al.’s [
15] Bayesian nonparametric FL framework could aggregate local models without extra parameters, achieving satisfactory accuracy with only one communication round. To accelerate model updates, structured and sketched update strategies were proposed to reduce communication pressure [
19]. Jiang and Ying’s [
20] adaptive method for local training adjusted the local training epochs based on the server’s decision, reducing local training time when the loss is small. Liu et al. [
21] utilized momentum gradient descent to consider previous gradient information in each local training epoch to accelerate convergence speed. However, these algorithms may not be suitable for all federal settings, and more flexible communication-efficient methods need to be explored for high efficiency demands in digital forensics.
On the other hand, model compression schemes such as sparsification, subsampling, and quantization can significantly reduce the size of messages communicated in each round, complementing local update methods that reduce the total number of communication rounds. However, these compression schemes face challenges in federated environments, such as low device participation, non-independent and identically distributed (non-IID) local data, and local updating schemes. To address these challenges, recent works have proposed strategies such as enforcing sparsity and low-rank in updating models, using structured random rotation for quantization [
18], applying lossy compression and dropout to reduce server-device communication [
22], and using Golomb lossless encoding [
23]. Recent studies, employ online knowledge distillation approaches, also called codistillation, for communication-efficient FL. Unlike transferring model updates, codistillation focuses on transmitting the local model prediction on a public dataset that is accessible to multiple clients. This method proves beneficial in reducing communication costs, particularly when the size of the local model exceeds the size of the public data [
24,
25,
26].
Federated networks often have significant system heterogeneity, with devices varying in terms of hardware, network connectivity, and battery power. This variability can lead to unbalanced training times and introduce issues such as stragglers, which are more common in federated networks than in centralized systems. To address these issues, methods have been proposed that focus on (a) resource allocation for heterogeneous devices and (b) fault tolerance for devices that are prone to being offline. Previous works have focused on allocating resources properly to heterogeneous devices in FL. This includes motivating high-quality devices to participate [
27], exploring novel device sampling policies based on systems resources [
16], studying training accuracy and convergence time with heterogeneous power constraints [
28], considering the impact of resource heterogeneity on training time [
29], and designing fairness metrics to impel fair resource allocation [
30]. However, it is also worth considering actively sampling a set of small but sufficiently representative devices based on the underlying statistical structure. Authors in [
31] address the challenges of statistical and system heterogeneity in multi-device environments, by adopting a user-centered approach. The proposed aggregation algorithm incorporates accuracy- and efficiency-aware device selection and enables model personalization to devices.
On the other side, fault tolerance becomes crucial as some participating devices may drop out before completing the training iteration. Strategies to deal with this issue include resisting device drop out through low participation [
32], ignoring failed devices [
33], and designing a secure aggregation protocol [
34] that is tolerant against arbitrary dropouts. The literature has also taken stragglers into account and allowed devices to spend different local update computation times, utilized a cache structure to store unreliable user updates [
35], and designed fault-tolerant methods for devices prone to being offline [
36].
1.2. Data-Specific Challenges
As previously mentioned, one of the key challenges in FL is to handle heterogeneity in terms of data. In real-world scenarios, the clients usually have significant heterogeneity among their local data distributions and dataset size since each client identically collects the local data based on its own preferences, resources, and sampling pool. The non-IID data cause inconsistencies among the local models’ objectives that affect the aggregation process and lead to the global model’s divergence and poor performance. More specifically, due to the different data distributions, the local training algorithms have different optimal points from the global optimal point and therefore there are local drifts between the global model and the local models. The traditional machine learning approach assumes that data are identically independent, which is not the case for non-IID data. As we keep training local models with heterogeneous local data and aggregate them to produce the global model, the divergence among the parameters of these models will accumulate and will lead to a skewed global model with poor performance [
37]. Based on data distribution over the sample and feature spaces, FL approaches can be typically categorized in horizontal, vertical, and hybrid schemes. In short, horizontal federated learning uses datasets with the same feature space across all devices, Vertical federated learning uses different datasets of different feature space to jointly train a global model, while hybrid FL is a combination of the first two (in terms of feature and sample distribution).
The main categories of non-IID data include (i) label distribution skew, where the distribution of labels is different across different nodes; (ii) feature distribution skew, where the distribution of features is different across different nodes; (iii) the same label but different features, where the same label is used for different features across different nodes; (iv) same features but different label, where the same features are used for different labels across different nodes; and (v) quantity skew, where the amount of data available at local nodes is different [
38].
The case ‘same label but different features’, knows as concept drift, is mainly related to vertical FL where the clients share overlapped sample IDs with different features. However, the experiments conducted follow a horizontal FL approach, where the clients share the same feature space but own different sample IDs. Moreover, the case “same features but different label”, known as concept shift, is not applicable in the presented test case as the clients share common knowledge about a task. Based on these observations, the possible non-IID data distribution types for our tools are label distribution skew, feature distribution skew, and quantity skew.
To address this problem, researchers have proposed modifying the local training mode, adding extra procedures to the data pre-processing stage, or focusing on a global model. These approaches involve different hyperparameter choices and are aimed at improving the training of a single global model on the non-IID data.
The FedAvg [
19], the most common FL algorithm, does not guarantee global models’ convergence under the non-IID data settings as it does not consider the inconsistency between the local and global models. There have been some studies trying to develop effective FL strategies for non-IID data distributions by addressing the client drift. Mohri et al. [
39] emphasized the importance of fairness and improved the global model to cope with a mixture of different clients. Wang, X. et al. [
40] discussed the convergence behavior of FL based on gradient-descent in non-IID data background and provided different convergence theorems for FedAvg in non-IID situations. While the FedProx [
5] algorithm, inspired by FedAvg, adds a proximal term to the local objective to force the local updates to be closer to the global model. FedProx was proposed as a modification to the FedAvg method to ensure convergence in practice. The algorithm has been evaluated on four datasets (
https://leaf.cmu.edu/, accessed on 15 June 2023), where the data distribution among the clients imposes statistical heterogeneity. MNIST and FEMNIST datasets were used for the image classification task, the Sentiment140 for text sentiment analysis and the dataset of “The Complete Works of William Shakespeare” for next-character prediction. Moreover, FedNova [
41] improves the FedAvg in the aggregation phase by normalizing and scaling the local updates of each client according to their number of local epochs to ensure that all the local updates influence the global model equally and prevent biases. The method was evaluated on a non-IID partitioned CIFAR-10 dataset (
https://www.cs.toronto.edu/~kriz/cifar.html, accessed on 15 June 2023) for image classification. SCAFFOLD algorithm [
42] applies a variance reduction technique to estimate the update direction of the global model and the update direction of each local model, calculate the drift of local training and correct the local updates by adding this drift to the training process. Huang, Shea et al. [
43] introduced clustering thought with FL, while hierarchical heterogeneous horizontal frameworks [
44] were used to overcome data heterogeneity. Data augmentation and personalization were also explored to make the data across clients more similar. Lastly, the FedOpt strategy [
45] allows the usage of adaptive optimizers, including ADAGRAD, and ADAM [
46] to improve the convergence of the global model.
In a recent study [
47], researchers introduced a novel approach, named as MOON, where they propose a local model constrastive loss comparing representations of global and local models from successive FL rounds. This technique aims to improve the training of individual parties by conducting contrastive learning in the model-level, specifically in the feature representation space, pushing the current local representation closer to the global representation and further away from the previous local one. Similarly, authors in [
48] proposed a distillation-based regularization method, named FedAlign, that promotes local learning generality while maintaining excellent resource efficiency.
In our experiments, we focused on investigating how the statistical data distribution heterogeneity affects the convergence and performance of the global aggregated model. For each tool, we built distributed local datasets with different types and levels of heterogeneity to simulate realistic FL scenarios.
1.3. Privacy-Related Challenges
FL systems are designed to improve data privacy since the gradient information is shared between the FL participants, while the transmission of raw data is not required. However, research studies reveal that FL does not guarantee adequate privacy and security to the system. Research has shown that even a small fraction of gradients can expose sensitive information about local data in FL, and sharing model updates during training can also pose a risk to privacy [
49,
50]. For instance, there is evidence about FL attacks that are able to retrieve speaker information from the transferred gradients when training FL systems for automatic speech recognition applications [
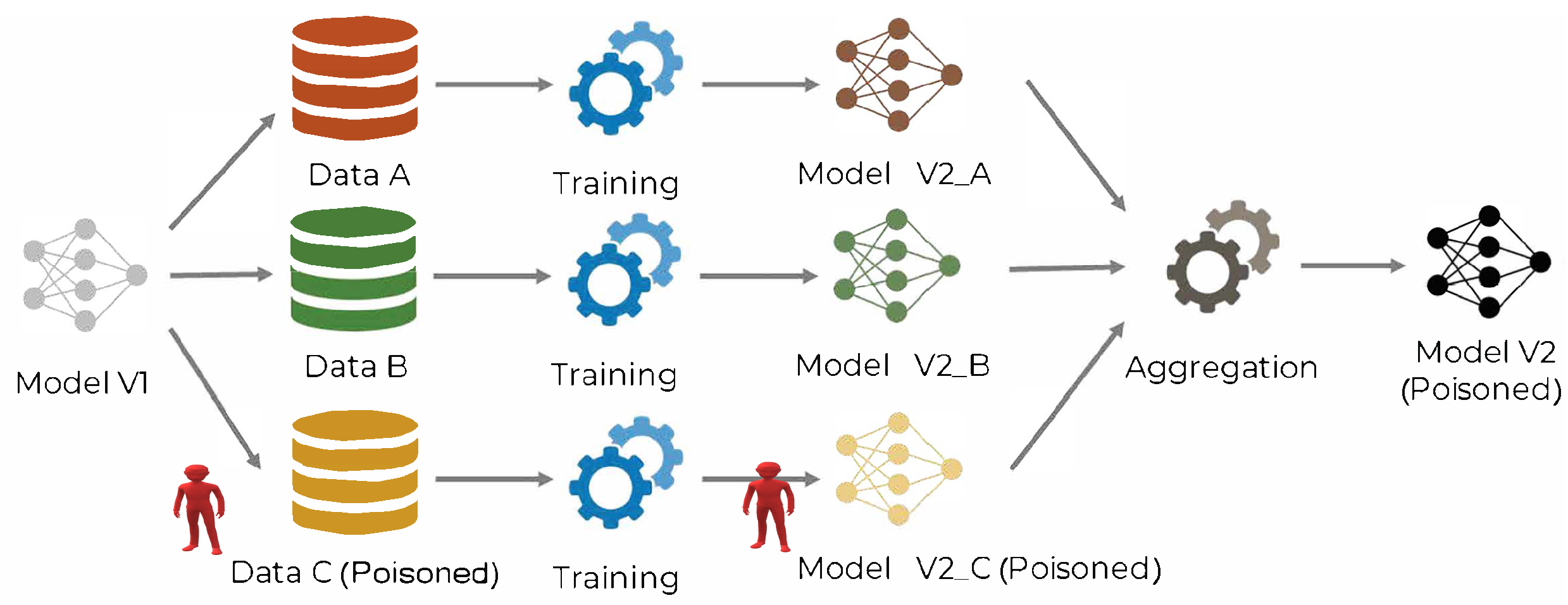
51]. To mitigate these threats and ensure the privacy and security of FL, it is important to investigate potential attacks on the FL network and develop defense mechanisms. Some relevant studies provide useful strategies for protecting FL against such attacks. During the training phase of FL networks, attacks that occur are known as poisoning attacks. These attacks can impact either the dataset or the local model, with the goal of modifying the behavior of the FL network in an undesirable way and distorting the global ML model’s accuracy and performance. As it is already stated, attackers can exploit the communication protocol amongst different participants to perform malicious actions, which can target either the data of each client (data poisoning attack) or the shared model parameters (model poisoning attack). Data poisoning attacks compromise the integrity of training data, while model poisoning attacks target partial or full model replacement during training. In an FL system, attacks can be performed by either the central server or the participating clients of the FL system.
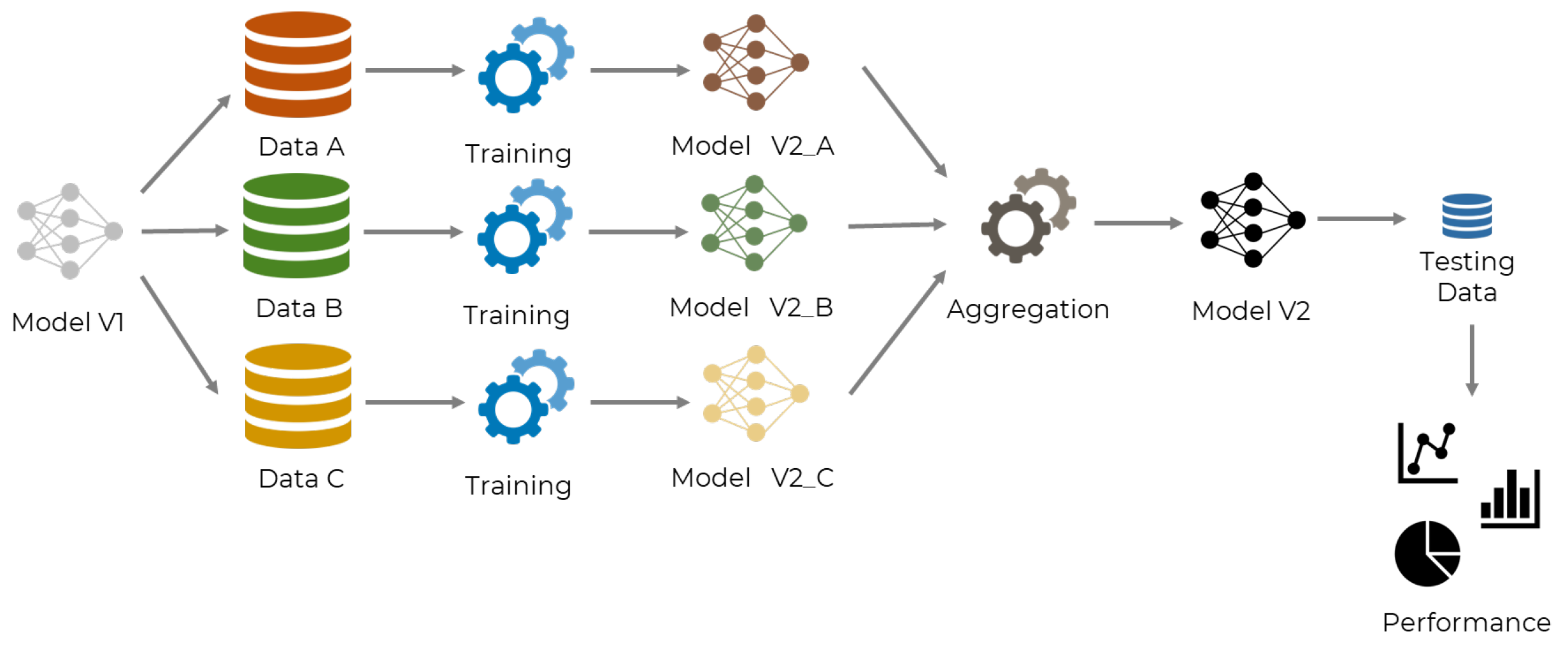
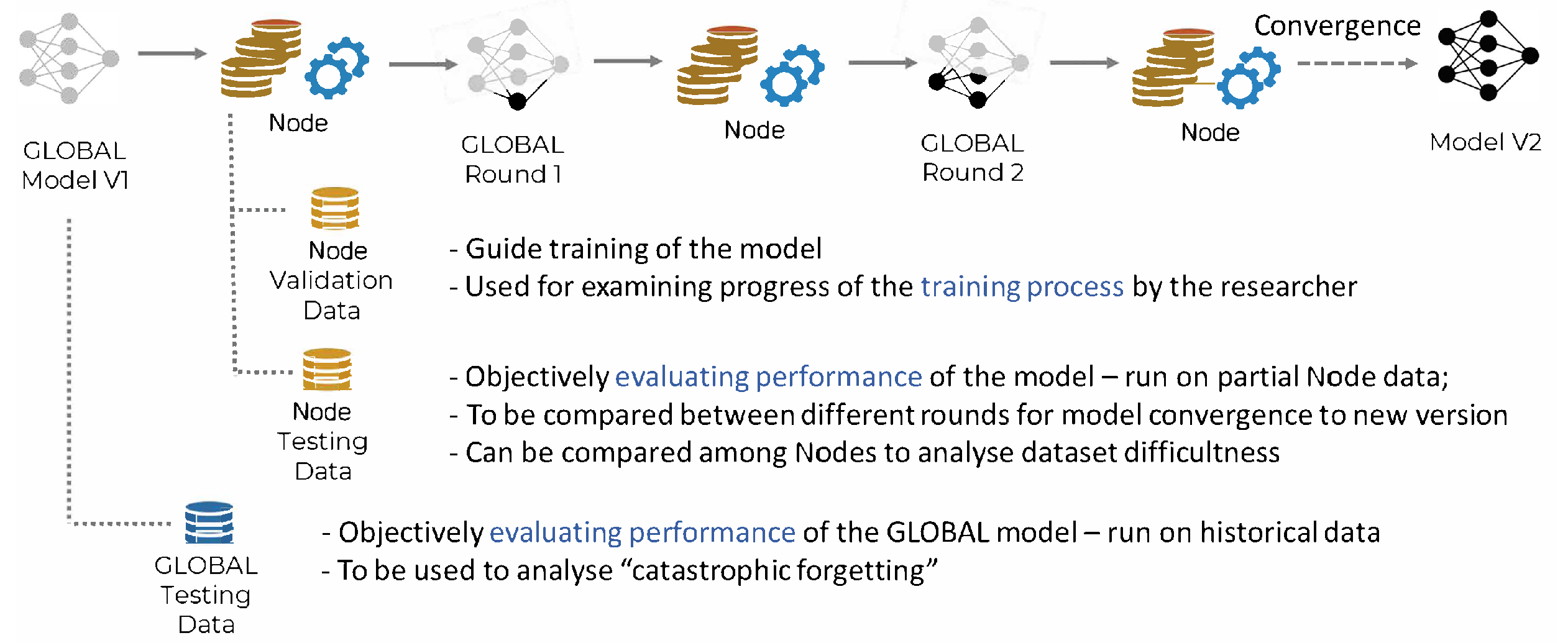
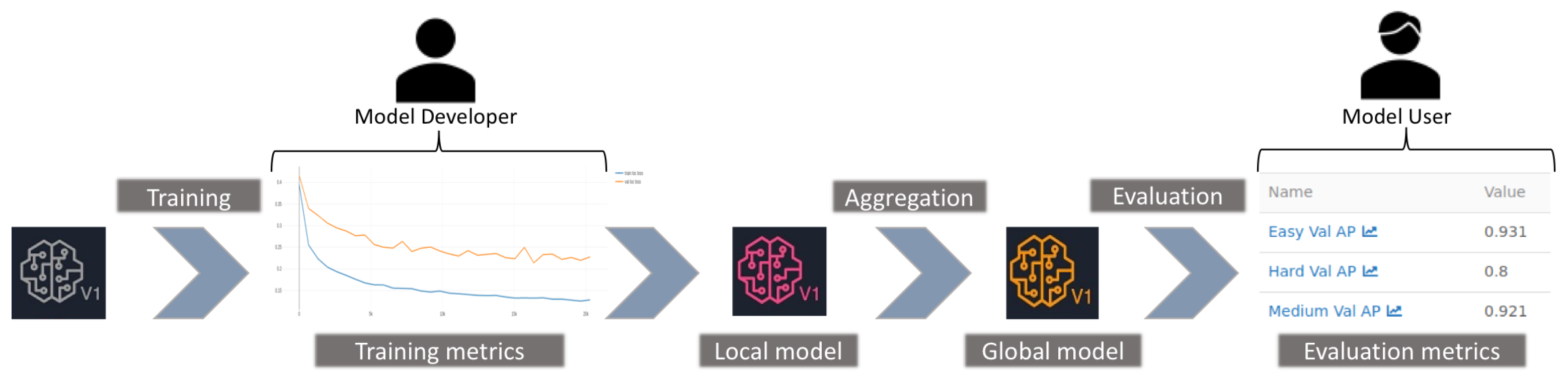
Figure 1 shows that data poisoning is performed at local data collection, while model poisoning is sourced at the local model training process.
In the case of data poisoning attacks, the attacker aims to degrade the performance of a set of target nodes by injecting corrupted/poisoned data into nodes. Label flipping is a data poisoning attack in which malicious nodes change the labels of samples either arbitrarily or with a specific pattern. In the first case, a different label is randomly assigned to a sample in such a way that the global performance of the FL model is reduced. In the second case, the malicious node assigns specific labels to a set of records with a clear purpose in mind. Due to the vast number of participants involved in the FL system, it is not guaranteed who is an honest as well as a credible entity and who is a malicious actor.
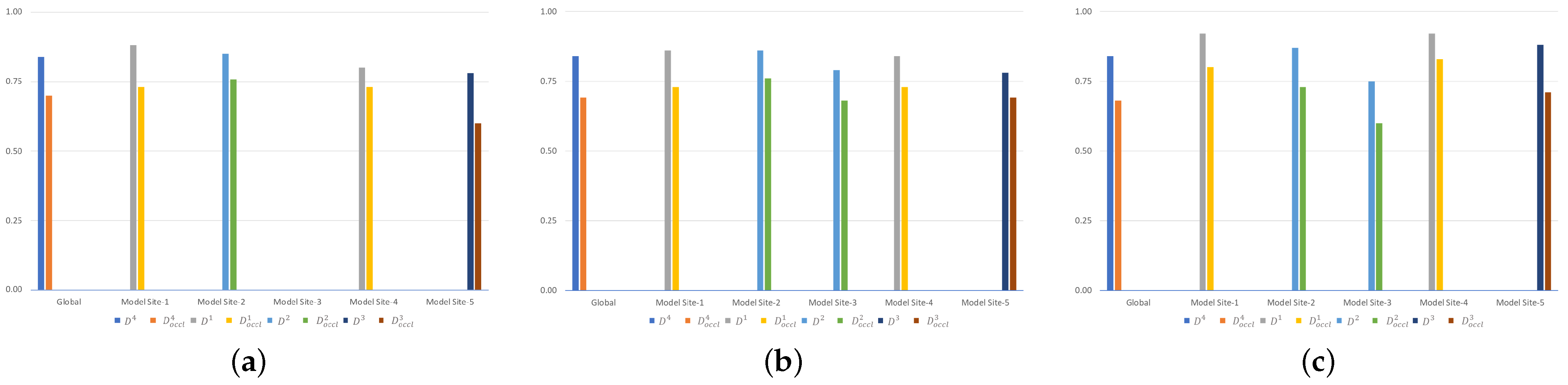
The impact of data poisoning attacks in image classification tasks is investigated in [
52] using the benchmark dataset MNIST and CIFAR-10. Specifically, this work studies the impact of data poisoning attacks on FL models regarding various percentages of malicious participants, random and targeted label flipping, and the time of the attack. A higher percentage of malicious nodes results in higher degradation of the model performance. Moreover, a targeted data poisoning attack is detected more difficult. Finally, the time that an attack is performed is a crucial aspect, while a model that is trained with malicious nodes up to a point can converge if enough time is given. The paper in [
53] presents two variants of data poisoning attack, namely model degradation and targeted label attacks. Both of those attacks are based on synthetic images generated by generative adversarial networks (GANs). Through experiments, it is observed that the GAN-based attacks manage to fool common federated defenses. Specifically, the model degradation attack provokes around
accuracy degradation, while the targeted label attack results in label misclassification of
. The authors also introduce a mechanism to mitigate these attacks, which is based on clean label training on server side. A distributed backdoor attack as a data poisoning attack on FL systems is proposed in [
54]. A local trigger is chosen by each adversary instead of a common global one. During inference, attackers exploit the local triggers to form global ones. This work compares this kind of attack to a centralised approach, and they conclude that it is more persistent than the centralised scenarios.
The design of a robust defence mechanism against data poisoning attacks in FL systems is a challenging task since most of them are attack-specific that have been designed for a specific type of attack and they do not work well for other types [
55,
56,
57]. The case of non-IID data among FL clients introduces other challenges in the procedure of developing an efficient defence mechanism against data poisoning attacks. Specifically, the work in [
58] presents that the non-IID data increases the difficulty of an accurate defence against data poisoning attacks. When the data are not identically distributed among FL participants, each client has its own data distribution, therefore bringing its unique contribution to the common FL model, which is misleading for most defence mechanisms. Regarding the model poisoning attacks, participants’ private information can be extracted from the sharable weights throughout the training process. Therefore, sensitive information can be revealed either to third-party or to the central server.
Many mechanisms have been developed to enhance the privacy of FL, such as secure multiparty computation (SMC) or differential privacy (DP). The aforementioned techniques provide privacy for the cost of decreased ML model performance. A challenge that should be faced during the development of a secure FL system is understanding and balancing the trade-off between the privacy-preserving level and the achieved ML performance. The authors in [
59] evaluates the performance of the proposed FL system under various settings of differential privacy as a privacy preserving technique and configurations of the FL nodes, investigating the trade-off between those components and achieved model performance. Specifically, they demonstrate how the model performance is affected at different level of DP, when the number of participants increases as well as in the case of imbalanced client data. Beyond providing an adequate level of privacy, it is also essential to implement computationally cheap FL methods, communication efficient as well as tolerant dropped devices without compromising accuracy.
The various privacy approaches of an FL system can be grouped into two categories, which are global privacy and the local privacy. In the former, the central server is a trusted party and the model updates generated at each round are considered as private to all untrusted participants except the central server. In the latter, all the participants may be malicious, and, therefore, the updates are also private to the server. A very common approach to prevent leakage of private client data from the shared parameters is the utilization of the secure aggregation mechanism of FL. In the last few years, various FL designs have been introduced that use secure aggregation protocols under various setups. Bonawitz in [
60] introduces a secure aggregation mechanism for FL, which can tolerate client dropouts. This method uses Shamir’s Secret Sharing [
61] and symmetric encryption to prevent the server from accessing individual model updates. The limitation of this approach lies in the fact that it requires at least four communication rounds between each client and the aggregator in each iteration. Bonawitz’s protocol is utilized by the works VerifyNet [
62] and VeriFL [
63], which add an extra verification level on top of [
60]. The additional verifiability guarantees the correctness of the aggregation. However, those methods require a trusted party to create private keys for all clients. Trying to reduce the overhead of [
60], the algorithm in [
64,
65] present secure aggregation mechanisms with polylogarithmic communication and computation complexity. The main differences in [
60] are that those methods replace the star-like topology of the FL network with random subgroups of clients as well as the secret sharing is only performed for a set of clients and not for all of them. Both methods [
64,
65] demand three rounds of communication interaction between the server and the clients. Another approach that reduces the communication and computation overhead compared to [
60] is the Turbo-Aggregate [
66]. Specifically, this method utilizes a circular communication topology. The FastSecAgg [
67] method uses Fast Fourier transform multi-secret sharing for secure aggregation. FastSecAgg is robust against adversaries which adaptively corrupt clients during the execution of FL procedures.
Several survey works have been published in the last past years with the aim to review and summarize the latest papers related on adversarial attacks and threats on FL system as well as the possible defense mechanisms. The authors in [
68] present an extensive review of the various threats that can be applied to a FL system as well as their corresponding countermeasures. Specifically, they provide several taxonomies of adversarial attacks and their defense methods, depicting a general picture of the vulnerabilities of FL and how to overcome them. The threats that can introduce vulnerabilities to trustworthy FL system, across different stages of the development procedure are introduced in [
69]. This work analyses the attacks that can be performed by a malicious participant in FL during data processing, model training, deployment and inference. Additionally, the authors of this paper aim to assist on the selection of the most appropriate defense mechanism by discussing specific technical solution to realize the various aspects of trustworthy FL. The work [
70] provides a review to the concept of FL, threat models, and two major attacks, namely poisoning attacks and inference attacks, by highlighting the intuitions, key techniques, and fundamental assumptions of the attacks. Some years after, a more comprehensive survey on privacy and robustness in FL is conducted and presented in [
71]. The authors of this work review the various threat models, privacy attacks, and poisoning attacks as well as their corresponding defenses. Finally, the paper [
72] demonstrates a comprehensive study regarding the security and privacy aspects that need to be considered in a FL setup. The results obtained from this research indicate that communication bottlenecks, poisoning, and backdoor attacks are the most specific security threats, while the inference-based attacks are the most crucial to the FL privacy.

 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}