

Semi-Supervised Model for Aspect Sentiment Detection

Abstract
:1. Introduction
- The first contribution of the current study is that a new mechanism is proposed to utilize these sentence level representations for that task of aspect category detection.
- The second contribution is that, by combining this mechanism with word-level similarity measurement, a new model for the aspect category detection is proposed.
- The final contribution of the current study is that a new semi-supervised model for aspect sentiment detection is proposed.
2. Related Works
3. Materials and Methods
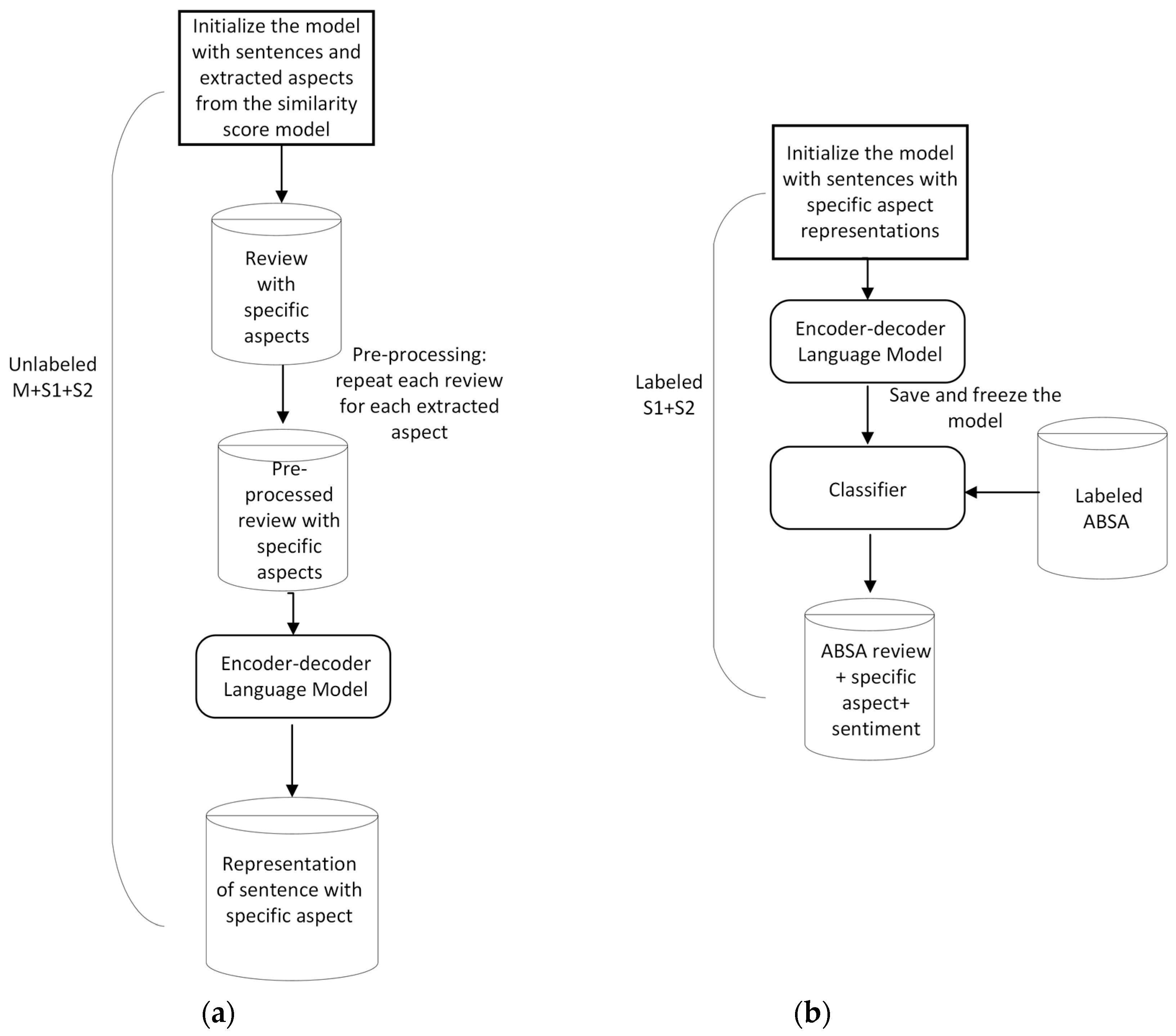
3.1. Proposed Aspect Sentiment Classification Model
3.2. Sentiment Detection Model
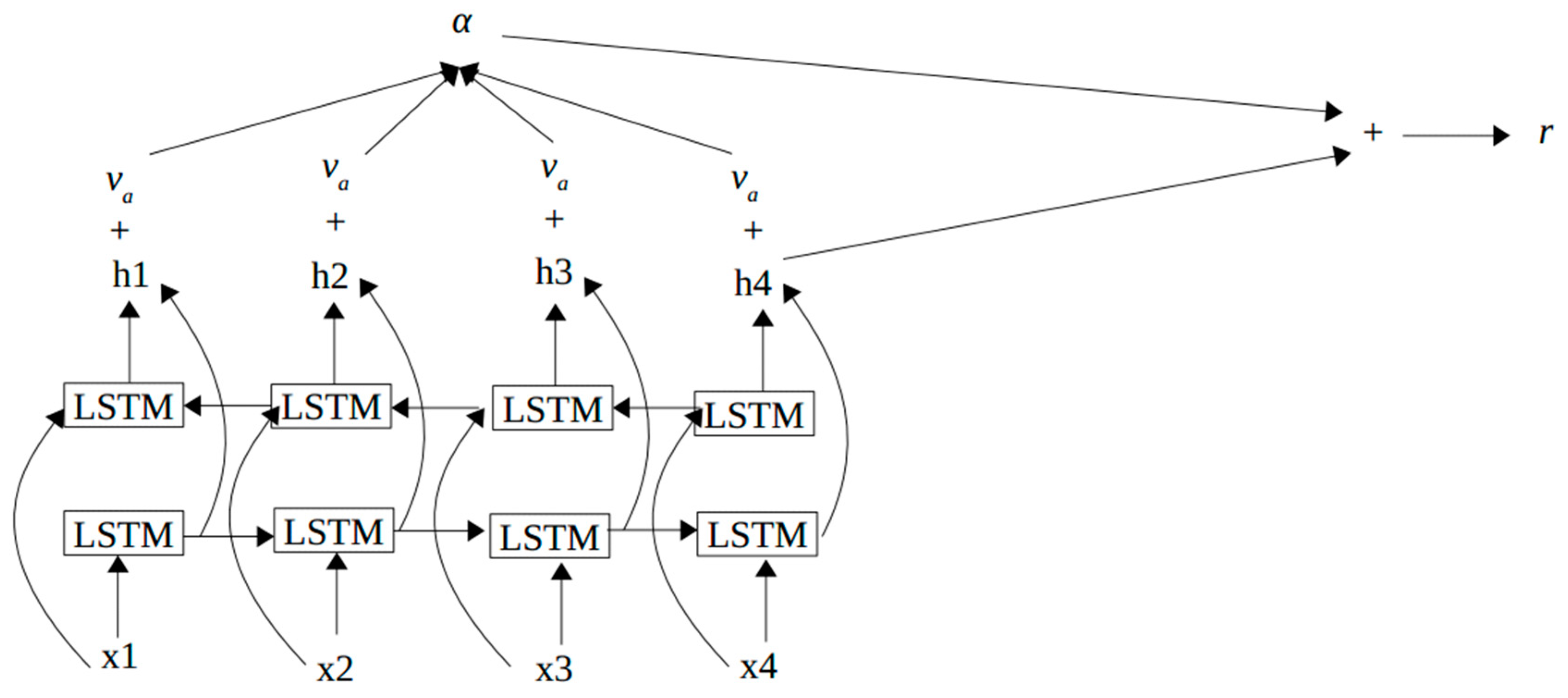
3.3. Attentional LSTM
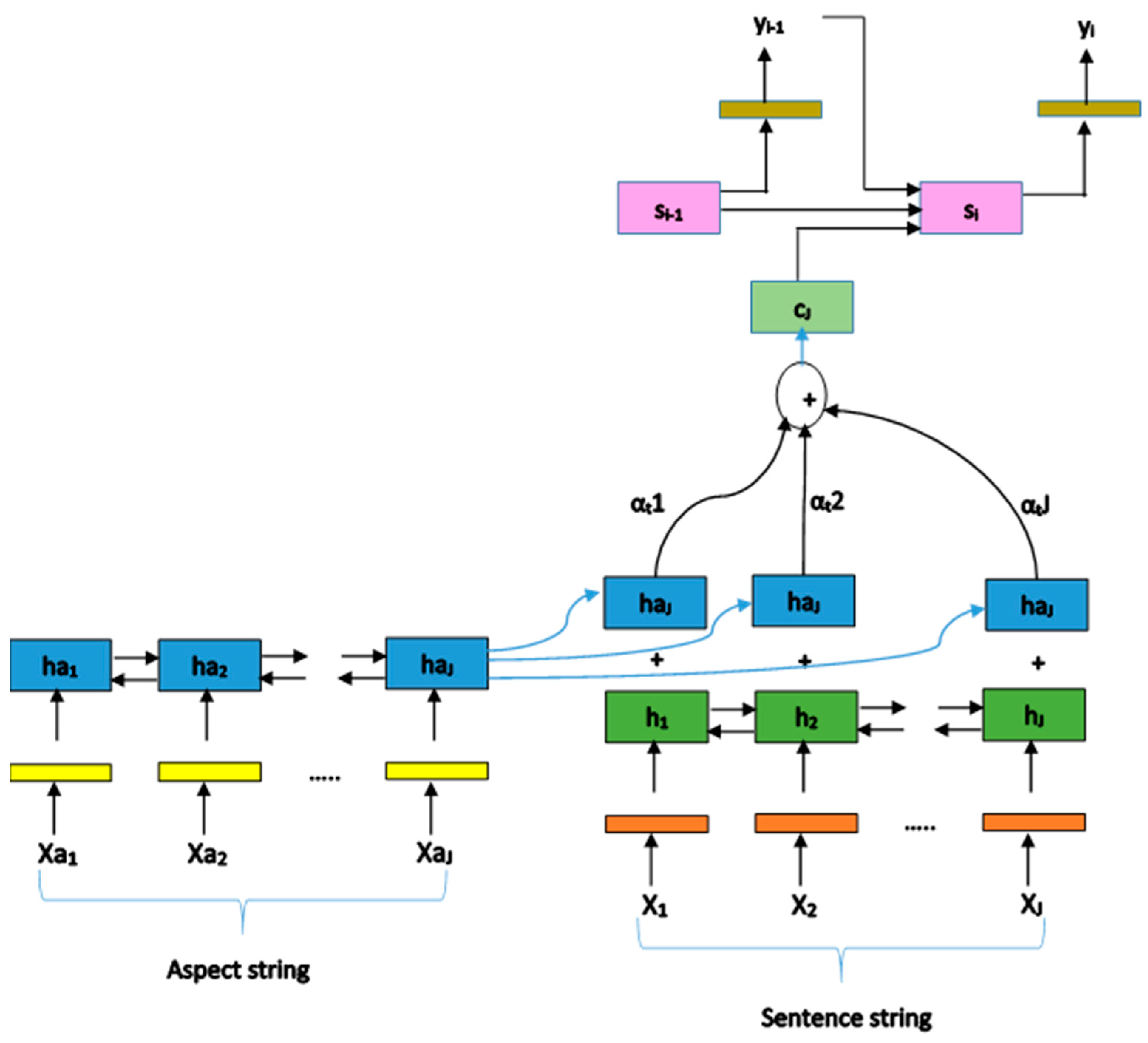
3.4. Encoder–Decoder Model
3.5. Aspect-Embedded Attentional Encoder–Decoder (AE-AED) Model
3.6. Model Selection
4. Results
5. Discussion
6. Future Works and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Madhoushi, Z.; Hamdan, A.R.; Zainudin, S. Sentiment analysis techniques in recent works. In Proceedings of the 2015 Science and Information Conference (SAI), London, UK, 28–30 July 2015; IEEE: Piscataway, NJ, USA. [Google Scholar]
- Madhoushi, Z.M.Z.; Hamdan, A.R.; Zainudin, S. Aspect-Based Sentiment Analysis Methods in Recent Years. Asia Pac. J. Inf. Technol. Multimed. 2019, 8, 79–96. [Google Scholar] [CrossRef]
- Ibrahim, S.A.; Bakar, A.A.; Yaakub, M.R.; Darwich, M. Beyond Sentiment Classification: A Novel Approach for Utilizing Social Media Data for Business Intelligence. Int. J. Adv. Comput. Sci. Appl. IJACSA 2020, 11, 437–441. [Google Scholar]
- Awwalu, J.; Abu Bakar, A.; Yaakub, M.R. Hybrid N-gram model using Naïve Bayes for classification of political sentiments on Twitter. Neural Comput. Appl. 2019, 31, 9207–9220. [Google Scholar] [CrossRef]
- Al-Ghuribi, S.M.; Noah, S.A.M.; Tiun, S. Unsupervised Semantic Approach of Aspect-Based Sentiment Analysis for LargeScale User Reviews. IEEE Access 2020, 8, 218592–218613. [Google Scholar] [CrossRef]
- Adel, H.; Dahou, A.; Mabrouk, A.; Elaziz, M.A.; Kayed, M.; El-Henawy, I.M.; Alshathri, S.; Ali, A.A. Improving Crisis Events Detection Using DistilBERT with Hunger Games Search Algorithm. Mathematics 2022, 10, 447. [Google Scholar] [CrossRef]
- Chennafi, M.E.; Bedlaoui, H.; Dahou, A.; Al-Qaness, M.A.A. Arabic Aspect-Based Sentiment Classification Using Seq2Seq Dia-lect Normalization and Transformers. Knowledge 2022, 2, 388–401. [Google Scholar] [CrossRef]
- Sachan, D.S.; Zaheer, M.; Salakhutdinov, R. Revisiting LSTM Networks for Semi-Supervised Text Classification via Mixed Objective Function. Proc. AAAI Conf. Artif. Intell. 2019, 33, 6940–6948. [Google Scholar] [CrossRef]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 2020, 21, 5485–5551. [Google Scholar]
- Li, Y.; Pang, X.; Pang, M. Adversarial Attacks on Word2vec and Neural Network. In Proceedings of the 2018 International Conference on Algorithms, Computing and Artificial Intelligence, Sanya, China, 21–23 December 2018. [Google Scholar]
- Gu, Y.; Gu, M.; Long, Y.; Xu, G.; Yang, Z.; Zhou, J.; Qu, W. An enhanced short text categorization model with deep abundant representation. World Wide Web 2018, 21, 1705–1719. [Google Scholar] [CrossRef]
- Alec Radford, R.J. Ilya Sutskever, Learning to Generate Reviews and Discovering Sentiment. arXiv 2017, arXiv:1704.01444. [Google Scholar]
- Truşcǎ, M.M.; Wassenberg, D.; Frasincar, F.; Dekker, R. A Hybrid Approach for Aspect-Based Sentiment Analysis using Deep Contextual Word Embeddings and Hierarchical Attention. In Proceedings of the Web Engineering: 20th International Conference, ICWE 2020, Helsinki, Finland, 9–12 June 2020; pp. 365–380. [Google Scholar] [CrossRef]
- Lal, M.; Asnani, K. Aspect Extraction & Segmentation in Opinion Mining. Int. J. Eng. Comput. Sci. 2017, 3. Available online: http://www.ijecs.in/index.php/ijecs/article/view/461 (accessed on 1 January 2023).
- Marrese-Taylor, E.; Matsuo, Y. Replication issues in syntax-based aspect extraction for opinion mining. arXiv 2017, arXiv:1701.01565. [Google Scholar]
- Nguyen, H.T.; Vo, Q.H.; Nguyen, M.L. A Deep Learning Study of Aspect Similarity Recognition. In Proceedings of the 2018 10th International Conference on Knowledge and Systems Engineering (KSE), Ho Chi Minh City, Vietnam, 1–3 November 2018. [Google Scholar]
- Pablos, A.G.; Cuadros, M.; Rigau, G. V3: Unsupervised Generation of Domain Aspect Terms for Aspect Based Sentiment Analysis. In Proceedings of the 8th International Workshop on Semantic Evaluation (SemEval 2014), Dublin, Ireland, 23–24 August 2014; pp. 833–837. [Google Scholar] [CrossRef]
- Poria, S.; Chaturvedi, I.; Cambria, E.; Bisio, F. Sentic LDA: Improving on LDA with semantic similarity for aspect-based sentiment analysis. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 4465–4473. [Google Scholar]
- Blair-Goldensohn, S.; Hannan, K.; McDonald, R.; Neylon, T. Building a Sentiment Summarizer for Local Service Reviews. In Proceedings of the WWW 2008 Workshop: NLP in the Information Explosion Era (NLPIX 2008), Beijing, China, 22 April 2008. [Google Scholar]
- De Albornoz, J.C.; Plaza, L.; Gervás, P.; Díaz, A. A Joint Model of Feature Mining and Sentiment Analysis for Product Review Rating. In Advances in Information Retrieval; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Tan, C.; Lee, L.; Tang, J.; Jiang, L.; Zhou, M.; Li, P. User-level sentiment analysis incorporating social networks. In Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 21–24 August 2011; pp. 1397–1405. [Google Scholar] [CrossRef]
- Wei, W.; Gulla, J. Sentiment Learning on Product Reviews via Sentiment Ontology Tree. In Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics, Uppsala, Sweden, 11–16 July 2010; pp. 404–413. [Google Scholar]
- Appel, O.; Chiclana, F.; Carter, J.; Fujita, H. Cross-ratio uninorms as an effective aggregation mechanism in sentiment analysis. Knowl. Based Syst. 2017, 124, 16–22. [Google Scholar] [CrossRef]
- Wang, W.; Pan, S.J.; Dahlmeier, D.; Xiao, X. Recursive Neural Conditional Random Fields for Aspect-based Sentiment Analysis. arXiv 2016, arXiv:1603.06679. [Google Scholar] [CrossRef]
- Cheng, J.; Zhao, S.; Zhang, J.; King, I.; Zhang, X.; Wang, H. Aspect-level Sentiment Classification with HEAT (HiErarchical ATtention) Network. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; pp. 97–106. [Google Scholar] [CrossRef]
- Ma, Y.; Peng, H.; Khan, T.; Cambria, E.; Hussain, A. Sentic LSTM: A Hybrid Network for Targeted Aspect-Based Sentiment Analysis. Cogn. Comput. 2018, 10, 639–650. [Google Scholar] [CrossRef]
- Fan, F.; Feng, Y.; Zhao, D. Multi-grained Attention Network for Aspect-Level Sentiment Classification. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018. [Google Scholar] [CrossRef]
- Pontiki, M.; Galanis, D.; Pavlopoulos, J.; Papageorgiou, H.; Androutsopoulos, I. Suresh ManandharSemEval-2014 Task 4: Aspect Based Sentiment Analysis. In Proceedings of the 8th International Workshop on Semantic Evaluation (SemEval 2014), Dublin, Ireland, 23–24 August 2014. [Google Scholar]
- Pontiki, M.; Galanis, D.; Papageorgiou, H.; Manandhar, S.; Androutsopoulos, I. SemEval-2015 Task 12: Aspect Based Sentiment Analysis. In Proceedings of the 9th International Workshop on Semantic Evaluation (SemEval 2015), Denver, CO, USA, 4–5 June 2015; Association for Computational Linguistics: Stroudsburg, PA, USA. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Tang, D.; Qin, B.; Feng, X.; Liu, T. Effective LSTMs for Target-Dependent Sentiment Classification. arXiv 2015, arXiv:1512.01100. [Google Scholar]
- Saias, J. Sentiue: Target and Aspect based Sentiment Analysis in SemEval-2015 Task 12; Association for Computational Linguistics: Stroudsburg, PA, USA, 2015. [Google Scholar] [CrossRef]
- Kiritchenko, S.; Zhu, X.; Cherry, C.; Mohammad, S. NRC-Canada-2014: Detecting Aspects and Sentiment in Customer Reviews. In Proceedings of the 8th International Workshop on Semantic Evaluation (SemEval 2014), Dublin, Ireland, 23–24 August 2014. [Google Scholar] [CrossRef]
- Guerini, M.; Gatti, L.; Turchi, M. Sentiment Analysis: How to Derive Prior Polarities from SentiWordNet. arXiv 2013, arXiv:1309.5843. [Google Scholar]
- Warriner, A.B.; Kuperman, V.; Brysbaert, M. Norms of valence, arousal, and dominance for 13,915 English lemmas. Behav. Res. Methods 2013, 45, 1191–1207. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data | Positive | Negative | Neutral |
|---|---|---|---|
| Restaurants—Train | 61.46% | 10.73% | 21.76% |
| Restaurants—Test | 78.95% | 11.94% | 21.45% |
| Data | Positive | Negative | Neutral |
|---|---|---|---|
| Restaurants—Train | 72.43% | 24.36% | 3.20% |
| Restaurants—Test | 53.72% | 40.96% | 5.32% |
| Laptop—Train | 55.87% | 38.75% | 5.36% |
| Laptop—Test | 57.00% | 34.66% | 8.32% |
| Restaurants—Test | 71.68% | 24.77% | 3.53% |
| Data | Implicit Sentiment |
|---|---|
| S1-LP | 22% |
| S1-RS | 24% |
| S2-LP | 23% |
| S2-RS | 26% |
| Model/Domain | Laptop | Restaurant | Hotel |
|---|---|---|---|
| Bi-LSTM-2L | 84.43% | 85.21% | 83.93% |
| Bi-GRU-2L | 83.37% | 83.58% | 80.49% |
| Data | Implicit Sentiment |
|---|---|
| S1-LP | 22% |
| S1-RS | 24% |
| S2-LP | 23% |
| S2-RS | 26% |
| Reference | Model Name | Accuracy |
|---|---|---|
| [17] | V3 | 47.21% |
| [33] | NRC-Can | 82.92% |
| [25] | Hierarchical Attention | 85.10% |
| Proposed approach | AE-AED | 84.87% |
| Reference | Model Name | Laptop | Restaurant | Hotel |
|---|---|---|---|---|
| [17] | V3 | 68.38% | 69.46% | 71.09% |
| [32] | Sentiue | 79.34% | 78.69% | 85.84% |
| [31] | TD-BLSTM | 82.7% | - | - |
| [24] | Recursive Neural Conditional Random Fields | 79.44% | 84.14% | - |
| [25] | Hierarchical Attention | 85.11% | 80.50% | - |
| [26] | Joint Aspect Sentiment Model | - | 74.11% | - |
| Proposed approach | AE-AED | 84.43% | 85.21% | 85.57% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Madhoushi, Z.; Hamdan, A.R.; Zainudin, S. Semi-Supervised Model for Aspect Sentiment Detection. Information 2023, 14, 293. https://doi.org/10.3390/info14050293
Madhoushi Z, Hamdan AR, Zainudin S. Semi-Supervised Model for Aspect Sentiment Detection. Information. 2023; 14(5):293. https://doi.org/10.3390/info14050293
Chicago/Turabian StyleMadhoushi, Zohreh, Abdul Razak Hamdan, and Suhaila Zainudin. 2023. "Semi-Supervised Model for Aspect Sentiment Detection" Information 14, no. 5: 293. https://doi.org/10.3390/info14050293